
Распознать почерк по фото онлайн
Перевод рукописи в печатный текст при помощи приложения на телефоне, называется OCR — оптическим распознаванием символов. Технология развивается с 1933 года и сейчас легко превращает письма, книги, газеты, другие рукописи или печатные издания в тексты, которые можно отредактировать на компьютере. Из этой статьи вы узнаете, как распознать почерк врача или другие рукописи онлайн по фотографии.
Как разобрать текст по фотографии
Чтобы распознавание текста с помощью камеры проходило быстро, желательно предоставлять чистые документы, написанные понятным почерком без исправлений, а также использовать качественный сканер. Также важно правильно выбрать приложение для преобразования рукописей, гарантирующее точность полученных символов.
Для чего вам может понадобится данная функция? Она достаточно часто упрощает жизнь студентов. Например, вам не хочется долго и муторно набирать текст, который нужно набрать вручную и в инете негде скопировать? Отлично! Самое время воспользоваться данным приложением.
Для того, чтобы воспользоваться данной услугой, вам всего лишь нужно установить на свой смартфон приложение. Они доступны в магазинах Google Play и App Store. Можно воспользоваться и онлайн-сервисами, но учтите, что их функции несколько ограничены. Далее расскажем о нескольких популярных программах.
Простой OCR — распознает почерк
И одно из популярнейших приложений — Simple OCR для мобильных устройств Android. Преобразовывает текста на нескольких языках. Учтите, что если в вашем документе есть необычные шрифты, некачественные или цветные картинки, может выйти некачественный результат. Также отметим, что она не распознает символы с надстрочными и подстрочными составляющими (например, буква ё).
Как пользоваться:
- Запустите приложение Простой OCR;
- Затем выберите снимок из галереи или сделайте фото;
- Выделите область, которую необходимо перевести в текстовый вариант, и нажмите на синюю кнопку;
- Дождитесь сканирования текста;
- Результат сканирования рукописного текста из фотографии.

В приложении можно сохранять отсканированные тексты в разных форматах и пользоваться встроенным редактором.
Text Scanner распознаватель текста
Еще одно несложное приложение, с помощью которого ваш смартфон станет и сканером, и переводчиком. Приложение поддерживает более 100 мировых языков, качественно распознает символы и тексты, поэтому оно так популярно.
Что мы получим с OCR Text Scanner:
- извлечение текста с картинками;
- обрезку и корректировку изображений для лучшего распознавания написанного;
- редактирование текста;
- возможность делиться текстом с другими пользователями;
- сохранение истории сканирования;
- извлечение телефонных номеров, электронных адресов, URL-ссылок с картинок.
Исходя из этого, чтобы преобразовать рукописный текст, его так же как и в предыдущем случае нужно сфотографировать камерой мобильного телефона на Android или iOS.
Итог выдается в том же расположении, что и оригинал, что уменьшает время на обработку текста.
Приложение подходит и для книжного формата и для небольших надписей.
Google Lens распознает рукописный текст
Итак, вы сделали записи, а теперь хотите их оцифровать. Для этого компания Google представила обновленное приложение Google Lens, которое помогает перенести рукописный текст в редактор через гаджет.
Приложение доступно на нескольких языках, но русский в нем пока не поддерживается. Поэтому, чтобы работать с сервисом, укажите в настройках английский язык как системный. Для этого зайдите в «Настройки» смартфона, выберите раздел «Язык и клавиатура».
- В устройствах с IOS надо открыть «Настройки», «Общие», «Язык и регион», «Язык iPhone» и отметить английский.
- Теперь у вас есть работающее приложение Google Lens, включенное на гаджете и доступное в меню Google Фото.
- Осталось выбрать раздел текст.
- Наведите на них камеру мобильного телефона и выделите на экране часть текста. Выберите опцию «Копировать на компьютер».

Перенос текста с одного мобильного устройства на другое возможен только с помощью последней версии браузера Chrome. На смартфоне и ПК должен быть открыт один и тот же аккаунт. В приложении есть и другие обновления, например, перевод и озвучивание иностранных текстов (только на устройствах с Android), поиск слов и словосочетаний.
Заключение
В Сети есть множество инструментов по OCR распознаванию рукописей, поэтому выбрать лучшую программу не так просто. Мы рассмотрели 3 самых удобных и доступных на наш взгляд приложения по преобразованию текстов.
Итак, чтобы превратить рукопись в печатный эквивалент — выполнимая задача, но в ней есть ряд сложностей. Результат зависит от качества изображения (размера, контрастности, освещенности). Как правило, полученный текст нуждается в небольшой корректировке, после которой его можно использовать.
Оценка статьи:
Загрузка…Распознать почерк врача онлайн по фото
Врачи любят выписывать рецепты размашистым, но непонятным ни для кого почерком. Это их профессиональная особенность! Иногда они настолько увлекаются каллиграфией, что их письмо не могут разобрать даже опытные расшифровщики — работники аптек😊. Здесь будут представлены все инструменты, распознающие врачебный почерк только лишь по изображению онлайн.
Это их профессиональная особенность! Иногда они настолько увлекаются каллиграфией, что их письмо не могут разобрать даже опытные расшифровщики — работники аптек😊. Здесь будут представлены все инструменты, распознающие врачебный почерк только лишь по изображению онлайн.
ScreenOCR поможет узнать, что написал доктор в рецепте
Перед походом в аптеку людям необходимо самим разобраться, какие препараты нужно купить. В этом случае далеко не всегда удаётся прочитать почерк врача. Попробуйте использовать для этого специальное мобильное приложение ScreenOCR на Андроид. Оно предназначается для перевода написанного на бумаге от руки текста в печатный. Определяет слова и сразу же отображает текст на экране. Программа поможет определить написанные буквы на бумаге шариковой ручкой даже иностранный текст. В нём доступен перевод на 20 языков.
Для его использования необходимо открыть приложение и выбрать кнопку на экране для загрузки изображения или создания нового фото. Чтобы сделать снимок онлайн, наведите камеру на текст и сделайте фото. Приложение моментально узнает, что написано при помощи экрана и выведет нужный текст на скрин телефона или планшета. ScreenOCR гарантирует точность распознавания насколько это возможно. Текст с одинаковым качеством будет распознан на разных языках.
Приложение моментально узнает, что написано при помощи экрана и выведет нужный текст на скрин телефона или планшета. ScreenOCR гарантирует точность распознавания насколько это возможно. Текст с одинаковым качеством будет распознан на разных языках.
Разработчики данного приложения гарантируют конфиденциальность всех изображений, которые были распознаны пользователем. Кроме вас никто больше не увидит данные, которые определила программа. Программа гибко настраивается, в ней можно задать автоопределение, и она будет автоматически определять текст на фото и через камеру. Кроме этого в ScreenOCR есть встроенный редактор, в котором можно обрезать, поворачивать и изменять созданные скриншоты.
Это интересно: определить название камня по фото.
Распознавание почерка врача в «ПростойOCR»
Эта программа по функциям схожа с предыдущей. В ней организован умный алгоритм распознавания написанного текста. «ПростойOCR» на Андроид хорошо приспособлен к сложно распознаваемому тексту, точно узнает все слова и выводит их на экран. Поддерживает загрузку изображений из галереи смартфона. А также определитель почерка способен работать напрямую с Google Drive и прочими облачными сервисами. Распознанные шрифты можно отправить на свой удалённый диск.
Поддерживает загрузку изображений из галереи смартфона. А также определитель почерка способен работать напрямую с Google Drive и прочими облачными сервисами. Распознанные шрифты можно отправить на свой удалённый диск.
Приложение также работает с многими популярными языками. Написанные от руки буквы легко будут определены программным алгоритмом и отображены в электронном виде в выбранном вами шрифте. Умеет узнавать слова даже на повреждённой бумаге и с пропущенными буквами. Для распознавания почерка врача необходимо открыть определитесь онлайн и навести камеру на текст, который нужно идентифицировать. Для создания снимка нажмите на кнопку «Screen».
Мобильное приложение «ПростойOCR» способно определять PDF документы и конвертировать их в другой формат. Можно отметить быструю работу с текстом и шрифтом. С ним можно не бояться, что шрифт врача будет не распознан. Теперь вы сможете это делать онлайн по фотографии. А также делиться результатом в других приложениях и мессенджерах. Приложение умеет определять шрифт сразу по нескольких изображениям — пакетная обработка данных.
Приложение умеет определять шрифт сразу по нескольких изображениям — пакетная обработка данных.
Определение текста врача онлайн на ПК
Зачем врачи умышленной пишут непонятно — для многих остаётся загадкой. Возможно они слепо следуют установленным за долгое время признакам профессиональных докторов. И хотят всеми возможными способами приобщиться к этой сфере деятельности. Но теперь у пользователей есть сразу несколько эффективных дешифраторов, которые будут показывать понятный и привычный печатный текст, вместо написанных замысловатых «загогулин».
Используйте онлайн-сервис https://img2txt.com/ru. Для работы с ним понадобится один снимок неопознанного текста.
Сделать его можно при помощи мобильного телефона. А если нужно распознать опись на компьютере, передайте файл через мессенджеры или почту. Изображение также может быть передано по ссылке.
- Для этого нужно раскрыть соответствующую вкладку и указать адрес фала в Интернете.
- После успешной загрузки файла нажмите на кнопку «Загрузить».
На следующей странице появится печатный текст из картинки, которую вы предоставили сервису. Его можно скопировать для вставки в другой цифровой документ. Или сохранить копию в блокноте на ПК или другом устройстве.
Все ваши попытки определения значения написанного по картинке на сайте будут сохранены до определённого момента. Но это не значит, что они будут доступны для других пользователей. Эти данные будут сохранены в секрете. И останутся на сайте сроком на 1 месяц. После этого автоматически будут удалены из серверов сервиса. Доступно несколько языков для определения. Его нужно выбирать при каждом распознавании на сайте. Полученный документ можно переводить на другие языки.
Бесплатный онлайн конвертер текста в печатный
Очередной сервис будет полезен пользователям, которые не получили должного результата другими описанными способами. Онлайн-программа Onlineconverter будет полезна для определения непонятного письма врача. При этом все её функции совершенно бесплатны. Оптическое распознавание одинаково хорошо распознаёт практически любой предоставленный написанный текст. Это может быть фотография, созданная на телефоне или печатный текст, где буквы видны очень плохо.
Оптическое распознавание одинаково хорошо распознаёт практически любой предоставленный написанный текст. Это может быть фотография, созданная на телефоне или печатный текст, где буквы видны очень плохо.
Онлайн конвертер имеет также другие полезные функции для работы с текстом. И умеет преобразовывать разные графические и текстовые форматы. Для конвертации можно выбрать другой язык, отличный от языка оригинала. После загрузки файла на сайт, на экране появится синяя кнопка, при помощи которой можно добавлять ещё несколько файлов к имеющимся. Ещё ниже расположена кнопка «Распознать», по нажатию которой начинается определение документа в режиме онлайн.
- Приложение не начнёт работать, пока поля формы не будут заполнены. К обязательным относится язык результата. Выберите его в форме слева. И ниже нажмите на кнопку для распознавания.
- Анализ плохо читаемого текста продлится не более 10 секунд.
- После чего на экране появится необходимый для вас результат в готовом для загрузки файле.

- Его также можно изменять при оформлении определения текста.
- Доступные форматы: Word, PDF, Text.
- После скачивания файла его можно будет найти в папке «Загрузки» вашего ПК. Или среди папок через файловый менеджер в мобильном телефоне.
Определитель текста Crifra-r.ru
К сожалению, не всегда удаётся узнать, что хотел сказать нам врач, когда писал рецепт или описывал диагноз. Ведь нередко они заходят слишком далеко и шрифт на бумаге получается никем и ничем нечитаемым. В этом случае можно обратиться только к единственному носителю зашифрованной информации — самому врачу.
Или попытайтесь использовать ещё один онлайн-сервис — www.cifra-r.ru/character-recognition.php. Чтобы им воспользоваться, на главной странице необходимо выбрать кнопку «Обзор». После чего найти созданную фотографию через проводник Windows. Когда файл будет загружен на сервер сайта останется нажать на кнопку «Распознать». И результат покажется в нижнем пустом поле. Его можно будет скопировать и отправить в другие приложения.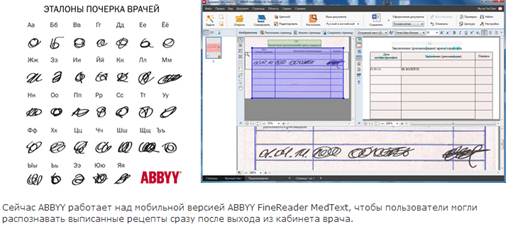
Видеоинструкция
Узнать, что написал врач на том или ином документе онлайн по картинке можно через описанные выше приложения и сайты. А чтобы узнать причины такого письма — посмотрите этот увлекательный ролик.
Автор Дмитрий Опубликовано Обновлено
Что такое оптическое распознавание символов? – Azure Cognitive Services
- Чтение занимает 2 мин
В этой статье
Служба оптического распознавания символов (OCR) позволяет извлекать печатный или рукописный текст из изображений, например фото вывесок и продуктов, а также из документов — счетов, ведомостей, финансовых отчетов, статей и т. д. Технологии OCR Майкрософт поддерживают извлечение печатного текста на нескольких языках. Чтобы приступить к работе, ознакомьтесь с этим руководством.
Эта документация включает статьи следующих видов:
- Краткие руководства — пошаговые инструкции, которые помогут вам вызвать службу и быстро получить результат.
- Практические руководства — содержат инструкции для более специфического или специализированного использования службы.
API чтения
API чтения службы Компьютерное зрение — это новейшая технология оптического распознавания символов Azure (узнайте о новых возможностях), которая позволяет извлекать печатный текст (на нескольких языках), рукописный текст (только на английском языке), цифры и символы валют из изображений и многостраничных PDF-документов. Она оптимизирована для извлечения текста из изображений с большим объемом текста и многостраничных PDF-документов на различных языках. API поддерживает обнаружение печатного и рукописного текста в одном изображении или документе.
Требования к входным данным
При вызове Read в качестве входных данных используются изображения и документы. Для них действуют следующие требования:
- Поддерживаемые форматы файлов: JPEG, PNG, BMP, PDF и TIFF
- Для файлов PDF и TIFF обрабатывается до 2000 страниц (только первые две страницы для бесплатного уровня доступа).
- Размер файла должен быть менее 50 МБ (6 МБ для бесплатного уровня доступа), размер измерений — не менее 50 x 50 пикселей и не более 10 000 x 10 000 пикселей.
Поддерживаемые языки
API чтения поддерживают всего 73 языка для текста стиля печати. См. полный список языков, поддерживаемых OCR. Распознавание рукописного текста поддерживается исключительно для английского языка.
Основные возможности
Функция Read API включает следующие функции.
- Извлечение печатного текста на языках 73
- Извлечение рукописного текста на английском языке
- Текстовые строки и слова с указанием местоположения и оценки достоверности
- Необходимость в распознавании языка отсутствует
- Поддержка смешанных языков, смешанный режим (печать и рукописный ввод)
- Выбор страниц и диапазонов страниц из больших, многостраничных документов
- Естественный порядок чтения текстовых строк
- Классификация рукописных сегментов для строк текста
- Функция доступна как контейнер Distroless Docker для локального развертывания
Узнайте, как использовать функции OCR.
Использование облачного API или развертывание в локальной среде
Для большинства клиентов рекомендуется использовать облачные версии API чтения версии 3.x: их легко интегрировать и начать с ними работу. Azure и служба Компьютерное зрение обеспечивают масштабирование, производительность, безопасность данных и соответствие требованиям, а вы можете сосредоточиться на обслуживании своих клиентов.
Контейнер Docker для API чтения (предварительная версия) позволяет развертывать новые возможности OCR в собственной локальной среде. Контейнеры соответствуют конкретным требованиям к безопасности и управлению данными.
Предупреждение
Более не рекомендуется использовать службу RecognizeText Компьютерного зрения 2.0. Вместо нее следует использовать API чтения, рассмотренный в этой статье. Существующим клиентам следует перейти на использование API чтения.
Конфиденциальность и безопасность данных
Как и в случае со всеми другими Cognitive Services, разработчикам, использующим API компьютерного зрения, следует учитывать политику корпорации Майкрософт касательно клиентских данных. Дополнительные сведения см. на странице о Cognitive Services Центра управления безопасностью Майкрософт.
Дальнейшие действия
7 лучших бесплатных инструментов для распознавания текста для преобразования изображений в текст
Возьмите отсканированное изображение (или сделайте снимок с помощью мобильной камеры), и программа Presto — OCR преобразует эти изображения в текст. Это скорость искусственного интеллекта на работе.
Это скорость искусственного интеллекта на работе.
Программное обеспечение для оптического распознавания символов (OCR) конвертировать картинки в текст. Программное обеспечение OCR анализирует документ и сравнивает его со шрифтами, хранящимися в их базе данных, и / или отмечая особенности, характерные для символов. Некоторые программы OCR также проверяют орфографию, чтобы «угадать» нераспознанные слова. Трудно достичь 100% -ной точности, но именно к этому стремятся большинство программ.
Программное обеспечение для оптического распознавания текста может быть быстрым способом для студентов, исследователей и офисных работников. Так что давайте поиграем еще с несколькими и найдем лучшее программное обеспечение для распознавания текста для ваших нужд.
1. OCR с использованием Microsoft OneNote
Microsoft OneNote имеет расширенные функции распознавания текста, которые работают как с изображениями, так и с рукописными заметками.
- Перетащите отсканированное изображение или сохраненное изображение в OneNote.
Вы также можете использовать OneNote для клип часть экрана или изображение в OneNote.
- Щелкните правой кнопкой мыши на вставленной картинке и выберите Копировать текст с картинки, Скопированный оптически распознанный текст попадает в буфер обмена, и теперь вы можете вставить его обратно в OneNote или в любую программу, например Word или Notepad.
OneNote также может извлечь текст из многостраничной распечатки одним щелчком мыши. Вставьте многостраничную распечатку в OneNote и затем щелкните правой кнопкой мыши на текущей выбранной странице.
- Нажмите Скопируйте текст с этой страницы распечатки захватить текст только с этой выбранной страницы.
- Нажмите Копировать текст со всех страниц распечатки скопировать текст со всех страниц одним снимком, как показано ниже.
Обратите внимание, что точность распознавания также зависит от качества фотографии. Вот почему оптическое распознавание рукописного ввода все еще немного нечетко для OneNote и другого программного обеспечения для распознавания текста на рынке. Тем не менее, это одна из ключевых функций в OneNote
Тем не менее, это одна из ключевых функций в OneNote
13 лучших новых функций OneNote, которые вы еще не пробовали
13 лучших новых функций OneNote, которые вы еще не пробовали
Microsoft добавила много новых привилегий в OneNote для Windows 10. Вот лучшие новые функции OnenNote в OneNote, которые вы, возможно, пропустили.
Прочитайте больше
Вы должны использовать при каждой возможности.
Хотите узнать, как OneNote сравнивается с платным программным обеспечением для распознавания текста? Прочитайте наше сравнение OneNote и OmniPage
Сравнение бесплатного и платного программного обеспечения для распознавания текста: сравнение Microsoft OneNote и Nuance OmniPage
Сравнение бесплатного и платного программного обеспечения для распознавания текста: сравнение Microsoft OneNote и Nuance OmniPage
Программное обеспечение сканера OCR позволяет преобразовывать текст в изображениях или PDF-файлах в редактируемые текстовые документы. Достаточно ли хорош инструмент OCR, например OneNote? Давайте разберемся!
Достаточно ли хорош инструмент OCR, например OneNote? Давайте разберемся!
Прочитайте больше
,
2. SimpleOCR
Трудность, с которой я столкнулся при распознавании рукописного ввода с использованием инструментов MS, могла бы найти решение в SimpleOCR. Но программное обеспечение предлагает распознавание рукописного ввода только в качестве 14-дневной бесплатной пробной версии. Хотя машинное распознавание печати не есть какие-то ограничения.
Программное обеспечение выглядит устаревшим, поскольку оно не обновлялось с версии 3.1, но вы все равно можете попробовать его из-за его простоты.
- Настройте его для чтения непосредственно со сканера или путем добавления страницы (JPG, TIFF, BMP форматы).
- SimpleOCR предлагает некоторый контроль над преобразованием посредством выделения текста, выбора изображения и функций игнорирования текста.
- Преобразование в текст берет процесс в этап проверки; пользователь может исправить несоответствия в преобразованном тексте, используя встроенную проверку орфографии.
- Преобразованный файл может быть сохранен в формате DOC или TXT.
SimpleOCR был в порядке с обычным текстом, но его обработка многостолбцовых макетов была разочарованием. На мой взгляд, точность преобразования инструментов Microsoft была значительно выше, чем у SimpleOCR.
Скачать: SimpleOCR для Windows (бесплатно, платно)
3. Сканирование фотографий
Photo Scan — это бесплатное приложение для оптического распознавания символов Windows 10, которое можно загрузить из Магазина Microsoft. Приложение, созданное Define Studios, поддерживает рекламу, но это не портит впечатления. Приложение представляет собой сканер для оптического распознавания символов и считыватель QR-кодов.
Укажите в приложении изображение или распечатку файла. Вы также можете использовать веб-камеру своего компьютера, чтобы на нее можно было посмотреть изображение. Распознанный текст отображается в соседнем окне.
Функция преобразования текста в речь является основным моментом. Нажмите на значок динамика, и приложение прочитает вслух то, что оно только что отсканировало.
Нажмите на значок динамика, и приложение прочитает вслух то, что оно только что отсканировало.
Не очень хорошо с рукописным текстом, но распознавание печатного текста было адекватным. Когда все сделано, вы можете сохранить текст OCR в нескольких форматах, таких как текст, HTML, Rich Text, XML, формат журнала и т. Д.
Скачать: Сканирование фотографий (бесплатная покупка в приложении)
4. (a9t9) Бесплатное приложение для распознавания Windows
(a9t9) Бесплатное программное обеспечение OCR — это универсальное приложение для платформы Windows. Таким образом, вы можете использовать его с любым устройством Windows, которое у вас есть. Существует также онлайн-аналог OCR, использующий тот же API.
(a9t9) поддерживает 21 язык для анализа ваших изображений и PDF в текст. Приложение также можно бесплатно использовать, а поддержку рекламы можно удалить с помощью покупки в приложении. Как и большинство бесплатных программ распознавания текста, это идея для печатных документов, а не для рукописного текста.
Скачать: a9t9 Бесплатное распознавание текста (бесплатная покупка в приложении)
5. Capture2Text
Capture2Text — это бесплатное программное обеспечение для оптического распознавания символов для Windows 10, которое предоставляет вам комбинации клавиш для быстрого распознавания текста на экране. Это также не требует никакой установки.
Используйте сочетание клавиш по умолчанию WinKey + Q активировать процесс распознавания. Затем вы можете использовать мышь, чтобы выбрать часть, которую вы хотите захватить. Нажмите Enter, и тогда выбор будет оптически распознан. Захваченный и преобразованный текст появится во всплывающем окне, а также будет скопирован в буфер обмена.
Capture2Text использует механизм распознавания текста Google и поддерживает более 100 языков. Он использует Google Translate для преобразования захваченного текста на другие языки. Заглянуть внутрь настройки настроить различные параметры, предоставляемые программным обеспечением.
Скачать: Capture2Text (бесплатно)
6. Простой экран OCR
Easy Screen OCR не является бесплатным. Но я упоминаю об этом здесь, потому что это быстро и удобно. Вы также можете свободно использовать его для до 20 раз без подписки. Программное обеспечение работает из системного трея или панели задач. Щелкните правой кнопкой мыши значок Easy Screen OCR и выберите Захватить из меню. Сделайте снимок экрана любого изображения, веб-сайта, видео, документа или чего-либо еще на экране, перетаскивая курсор мыши.
Easy Screen OCR затем отображает диалоговое окно с тремя вкладками. На вкладке «Снимок экрана» вы можете просмотреть захваченный текст. Нажмите кнопку OCR, чтобы прочитать текст с картинки. Оптически преобразованный текст теперь можно скопировать с вкладки «Текст» диалогового окна.
Вы можете установить языки распознавания для распознавания текста в настройках программного обеспечения. Больше, чем Поддерживается 100 языков в качестве программного обеспечения используется механизм распознавания текста Google.
Скачать: Easy Screen OCR ($ 9 в месяц)
Также: OCR с Google Docs
Если вы находитесь за пределами своего компьютера, попробуйте использовать функции оптического распознавания текста на Google Диске. Google Docs имеет встроенную программу OCR, которая может распознавать текст в Файлы JPEG, PNG, GIF и PDF. Но все файлы должны быть 2 МБ или меньше, а текст должен быть 10 пикселей или выше. Google Диск также может автоматически определять язык в отсканированных файлах, хотя точность с нелатинскими символами может быть невелика.
- Войдите в свою учетную запись Google Drive.
- Нажмите на Новый> Загрузка файла, Кроме того, вы также можете нажать на Мой диск> Загрузить файлы,
- Найдите файл на вашем ПК, который вы хотите конвертировать из PDF или изображения в текст. Нажмите на открыто Кнопка для загрузки файла.
- Документ теперь находится на вашем Google Диске. Щелкните правой кнопкой мыши на документе и нажмите Открыть с помощью> Документов Google,
- Google преобразует ваш PDF или файл изображения в текст с помощью OCR и открывает его в новом документе Google.
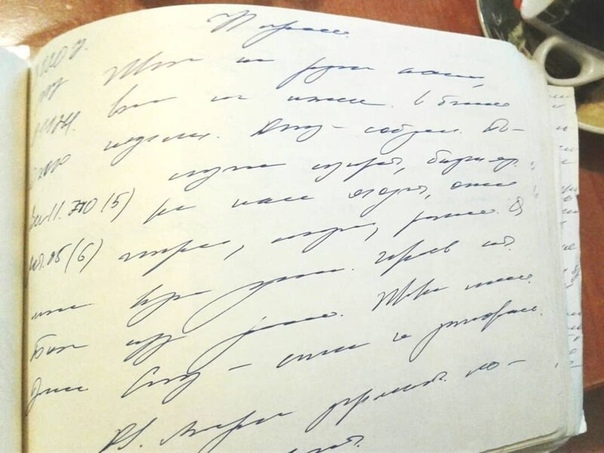 Текст редактируемый, и вы можете исправить части, в которых OCR не смог правильно его прочитать.
Текст редактируемый, и вы можете исправить части, в которых OCR не смог правильно его прочитать. - Вы можете скачать настроенные документы в нескольких форматах, которые поддерживает Google Drive. Выбери из Файл> Скачать как меню.
Бесплатное программное обеспечение для распознавания текста, которое вы можете выбрать
Хотя бесплатные инструменты были адекватны печатному тексту, они не справились с обычным рукописным текстом. Мое личное предпочтение в использовании неявного распознавания текста связано с Microsoft OneNote, потому что вы можете сделать его частью рабочего процесса ведения заметок. Сканирование фотографий — это универсальное приложение для Магазина Windows, которое поддерживает разрывы строк с диапазоном форматов документов, которые можно сохранить.
Но не позволяйте завершить здесь поиск бесплатных конвертеров OCR. Есть много других альтернативных способов распознавания текста и изображений. И мы поместили несколько онлайн инструментов OCR
4 бесплатных онлайн-инструмента для распознавания текста
4 бесплатных онлайн-инструмента для оптического распознавания текста
Благодаря достижениям в технологии оптического распознавания текста преобразование текста и изображений из отсканированного документа PDF в редактируемые текстовые форматы стало проще. Мы протестировали несколько бесплатных онлайн-инструментов для распознавания текста, поэтому вам не придется этого делать.
Мы протестировали несколько бесплатных онлайн-инструментов для распознавания текста, поэтому вам не придется этого делать.
Прочитайте больше
на тест раньше. Держите их рядом тоже.
Кредит изображения: nikolay100 / Depositphotos
Узнайте больше о: преобразование файлов, редактор изображений, распознавание текста.
6 приложений для Mac, чтобы уменьшить отвлекающие факторы и помочь вам сосредоточиться
Как бесплатно конвертировать рукописный текст в печатный-2 Самых простых способа
Существует ли программа для быстрого и эффективного преобразования рукописного текста в печатный (обновлено 2021)? Конечно: PDFelement позволяет конвертировать рукописи в печатный текст без каких-либо проблем, характерных для других программ. Так что если у вас есть PDFelement, вам не о чем беспокоиться. С помощью этой программы вы сможете сканировать рукописи и превращать их в текст, а также выполнять много других задач, которые существенно упростят процесс вашей работы с PDF-файлами.
Конвертирование рукописного текста в печатный с помощью PDFelement
Шаг 1. Загрузка PDF-документа
Для открытия файла перетащите PDF с рукописью в интерфейс программы. Это один из самых простых способов открыть файл.
Шаг 2. Включение функции распознавания текста
Как правило, рукописные документы обрабатываются в виде отсканированных файлов. После открытия отсканированного PDF-файла на экране появится уведомление с предложением выполнить распознавание текста. Нажмите кнопку «Иструмент»> «OCR», чтобы открыть диалоговое окно распознавания. Выберите режим «Редактируемый текст» и нажмите кнопку «Изменить язык», чтобы выбрать язык рукописного содержимого для выполнения распознавания текста.
Шаг 3. Конвертирование рукописного текста в печатный
После выполнения распознавания файл станет редактируемым. Таким образом, вы можете нажать «Конвертировать»> «В текст» для того, чтобы преобразовать файл на основе рукописного текста в файл с печатным текстом. При необходимости перед преобразованием вы также можете нажать кнопку «Редактировать», чтобы отредактировать содержимое вашего файла. Чтобы узнать больше о том, как редактировать PDF, нажмите здесь.
При необходимости перед преобразованием вы также можете нажать кнопку «Редактировать», чтобы отредактировать содержимое вашего файла. Чтобы узнать больше о том, как редактировать PDF, нажмите здесь.
PDFelement – одна из лучших программ, делающих работу с PDF простой и безопасной. Приложение делает преобразование отсканированной рукописи очень простым процессом. Распознавание рукописей и превращение их в печатный текст – еще одна важная функция, реализованная в PDFelement. Работая в этой программе, вы можете быть уверены в отличном результате. Программа PDFelement отличается простотой использования и является одним из лучших способов выполнения различных задач. PDFelement оснащен множеством функций – от самых простых до продвинутых – которые позволяют существенно облегчить вашу жизнь.
Важно: Рукопись, которую вы собираетесь преобразовать в печатный текст, должна быть написана печатными буквами. Даже Adobe Acrobat не может преобразовывать рукописи в редактируемый текст. Если вам нужно преобразовать письменные буквы, попробуйте программное обеспечение ICR – Intelligent Character Recognition.
Если вам нужно преобразовать письменные буквы, попробуйте программное обеспечение ICR – Intelligent Character Recognition.
Вам также может понравиться: Как конвертировать PNG в Word >>
Сканирование рукописного текста в печатный
Преобразование рукописных заметок в текст выглядит очень впечатляюще. Вы можете использовать эту программу, высоко оцененную пользователями со всего мира, для преобразования рукописей в печатный текст. PDFelement делает сложные процессы, связанные с PDF, простыми, надежными и безопасными. Лучшая часть PDFelement заключается в том, что данная программа не требует подключения к интернету для работы в отличие от других программ.
Шаг 1. Подключение сканера
После запуска PDFelement нажмите кнопку «Иструмент» на вкладке «OCR». Затем выберите сканер для подключения. Вы также можете выбрать необходимые настройки и нажать «Сканировать».
Шаг 2. Сканирование рукописного текста в печатный
Отсканированный PDF-файл будет открыт в PDFelement после завершения сканирования. Если в шаге 2 вы выбрали опцию «Распознать текст (OCR)», то текст созданного PDF-файле уже будет доступен для редактирования. Затем вы можете преобразовать файл в текстовый файл с помощью кнопки «В текст» на вкладке «Конвертирование». При необходимости перед преобразованием вы также можете нажать кнопку «Редактировать», чтобы отредактировать содержимое вашего файла. Чтобы узнать больше о том, как редактировать PDF, нажмите здесь.
Если в шаге 2 вы выбрали опцию «Распознать текст (OCR)», то текст созданного PDF-файле уже будет доступен для редактирования. Затем вы можете преобразовать файл в текстовый файл с помощью кнопки «В текст» на вкладке «Конвертирование». При необходимости перед преобразованием вы также можете нажать кнопку «Редактировать», чтобы отредактировать содержимое вашего файла. Чтобы узнать больше о том, как редактировать PDF, нажмите здесь.
Лучшая программа для конвертирования рукописного текста в печатный
PDFelement – несомненно, лучшая программа, которую можно использовать для преодоления проблем, возникающих при работе с PDF в других программах. С PDFelement обработка PDF перестает быть сложной задачей. PDFelement гарантирует потрясающие результаты работы. Это одна из лучших программ, представленных на рынке. PDFelement создан командой профессионалов, которые регулярно обновляют программу, поэтому работая в ней, вы можете быть уверены в отличном результате.
PDFelement – это программа, которая способна изменить ваше представление о работе с PDF-файлами. Загрузите программу, чтобы убедиться, что здесь отсутствуют все те сложности, которые возникают при использовании некачественных программ. Стоит однажды попробовать PDFelement, и она станет одной из ваших любимых программ. В случае возникновения каких-либо сложностей вы в любой момент можете связаться с командой разработчиков. Техническая поддержка 24/7 позволяет справиться с ними без труда. Все функции PDFelement доступны даже при загрузке бесплатной версии.
Загрузите программу, чтобы убедиться, что здесь отсутствуют все те сложности, которые возникают при использовании некачественных программ. Стоит однажды попробовать PDFelement, и она станет одной из ваших любимых программ. В случае возникновения каких-либо сложностей вы в любой момент можете связаться с командой разработчиков. Техническая поддержка 24/7 позволяет справиться с ними без труда. Все функции PDFelement доступны даже при загрузке бесплатной версии.
PDFelement обладает интуитивно понятным интерфейсом, поэтому подходит даже для новичков. В программу встроены сотни полезных функций для обработки PDF-файлов. PDFelement позволяет с легкостью открывать даже зашифрованные PDF-файлы. Вы также можете защитить свои файлы, чтобы они не были изменены или испорчены в результате несанкционированного доступа. С PDFelement ваши PDF-файлы всегда в безопасности. Сложно оставаться равнодушным к этой программе – она действительно потрясающая.
- С помощью этой программы вы можете решать самые распространенные задачи.
 Среди них удобное открытие, сохранение и печать PDF-файлов.
Среди них удобное открытие, сохранение и печать PDF-файлов. - Программу также можно использовать для работы с графическими элементами PDF-файлов: с ее помощью вы можете удалять, перемещать и поворачивать их.
- Функция распознавания текста в данной программе не имеет аналогов по своему уровню. С ее помощью вы гарантированно сможете преобразовать изображения в редактируемый текст.
- Данная программа будет особенно полезна для корпоративных пользователей. Приложение позволяет добавлять номера и элементы страниц, включая сквозную нумерацию.
Расшифровка почерка врачей онлайн по фото
О почерке врачей слагают анекдоты и шутки. И в действительности, часто мы получаем такие рецепты, прочитать которые самим возможно разве что при почерковедческой экспертизе. Однако, несмотря на это фармацевты в аптеке легко разбирают рецепты и выдают по ним правильные лекарства. Обычно, когда врач выдаёт рецепт, он на словах вам произносит всё, что записывает там. Но людям свойственно забывать, особенно тем, кто в данный момент заботится о своём здоровье. И поэтому возникаете необходимость прочитать рецепт снова. Расшифровка непонятного почерка врачей в режиме онлайн по фото может стать одним из решений данной проблемы. И в этой статье мы рассмотрим способы, которые позволяют это сделать.
Обычно, когда врач выдаёт рецепт, он на словах вам произносит всё, что записывает там. Но людям свойственно забывать, особенно тем, кто в данный момент заботится о своём здоровье. И поэтому возникаете необходимость прочитать рецепт снова. Расшифровка непонятного почерка врачей в режиме онлайн по фото может стать одним из решений данной проблемы. И в этой статье мы рассмотрим способы, которые позволяют это сделать.
OCR — простой онлайн-сканер рецептов врачей по фото
Разработчики позиционируют это приложение как самый точный распознаватель написанного текста. Так ли это на самом деле, каждому придётся убедиться самостоятельно, так как результаты во многом зависит от почерка врача и качества фотографии рецепта. В бесплатной версии присутствует реклама и имеется ограничение на количество сканирований. Но для пробы хватит с лихвой.
Каким образом работать с программой, чтобы расшифровать рецепт:
- Скачайте ОСК сканер на своё устройство с Android по этой ссылке и запустите.
 Если появятся запросы на разрешения использования функций телефона, например, камеры или файловой системы, то нужно согласиться.
Если появятся запросы на разрешения использования функций телефона, например, камеры или файловой системы, то нужно согласиться. - Приложение называется «Простой OCR» и насколько он прост видно сразу — минимум кнопок и функции. На стартовой странице нажмите на иконку в виде плюса, чтобы добавить документы на сканирование.
- Рецепт врача можно добавить как из галереи устройства, так и из камеры. Выберите удобный вам вариант и загрузите фото рецепта.
- Затем предстоит обработать фото. Нужно добиться того, чтобы оно имело правильное положение, не перевёрнутое, и что бы на нём был виден только текст, без лишних элементов. Для поворота внизу есть элементы управления, а для обрезки — рамка, двигая границы которой, можно обрезать изображение.
- Когда изображение готово, нажмите на синюю кнопку со стрелкой внизу справа.
- На распознавание нужно некоторое время, которое зависит от объёма и качества текста. В результате вы увидите распознанный текст, который при необходимости сможете отредактировать, перевести, скопировать, конвертировать в .
 pdf и произвести с ним другие операции.
pdf и произвести с ним другие операции.
Это может быть полезным: Поиск по фото с телефона в Яндексе.
«Сканер текста» — поможет расшифровать почерк врача
Это приложение имеет одну из самых больших оценок пользователей, а также множество положительных отзывов, что говорит о высоком качестве распознавания разнообразного текста. Есть бесплатная и премиум версии с дополнительным возможностями. Для большинства целей хватит и бесплатной.
Приложение так и называется — «Сканер текста«, и скачать его можно на устройство под управлением Android по этой ссылке. Установите и запустите. При запросе на разрешения использования функция телефона, следует согласиться для корректной работы.
Каким образом работать с онлайн-приложением, чтобы расшифровать почерк в рецепте от врача по фотографии:
- После запуска вы сразу увидите камеру. Обратите внимание, что здесь есть возможность использовать зум, а также настроить яркость. Для этого есть опции внизу экрана.

- Если вы фотографируете при плохом свете, то можно включить вспышку.
- Если фото рецепта врача находится на вашем устройстве, то вы можете загрузить его через галерею.
- Сфотографируйте рецепт или загрузите его из галереи. Добейтесь наилучшего качества фото — хороший свет, чёткие буквы и на фото должен быть только текст. Это значительно влияет на качество распознавания.
- После загрузки фото оно сразу отправляется на распознавание. Это займёт несколько секунд, и в результате вы увидите распознанный напечатанный текст, с которым можно выполнять разнообразные операции.
Вам это может быть интересно: Гугл переводчик по фото онлайн с английского на русский.
Text Scanner — сканирует и распознаёт любой рукописный текст по фото
Ещё одно приложение для смартфона для распознавания текста, которое заслужило высокие оценки пользователей и множество положительных отзывов. Программа с простым и не примечательным названием Text Scanner. Это также условно бесплатное приложение, бесплатных функций которого хватит для решения большинства задач.
По мнению некоторых пользователей — это один из лучших инструментов для целей распознавания текста онлайн по фото, который качественно и быстро справляется со своей задачей. При этом он обладает простым и интуитивным интерфейсом.
Порядок действий для работы с расшифровщиком непонятного почерка врачей:
- Традиционно начинать следует со скачивания приложения на Android — Text Scanner. После установки и запуска следует обязательно согласиться со всеми запросами и предоставить все необходимые разрешения.
- Вы увидите стартовую страницу, на которой внизу справа есть кнопка фотоаппарата, а вверху слева — кнопка галереи. Первая для того, чтобы сделать фото рецепта врача, а второе — чтобы загрузить фото из галереи, если оно у вас есть.
- В камере есть возможность использовать вспышку, если вы делаете фото в плохом освещении, а также кнопка затвора, которая, собственно, и делает фото.

- Когда фото будет загружено в приложение, вы можете нажать на кнопку «Crop» для того, чтобы обрезать. На фото не должно быть ничего, кроме текста рецепта.
- Обрезка осуществляется перетаскиванием рамки. Также есть инструменты для поворота и отражения изображения.
- Когда всё готово, нажмите «Scan» и дождитесь результатов распознавания. Через несколько секунд вы увидите распознанный текст.
Данный метод не потребует от вас установки приложений на устройство. Для его реализации понадобится только браузер в смартфоне, планшете или компьютере. Сервис отличается высоким качеством обработки фото с текстом, имеет множество дополнительных функций, а также совершенно бесплатный.
Порядок работы с сервисом:
- Фото с рецептом врача вы должны иметь на вашем устройстве. Перейдите в браузере на страницу сервиса по этой ссылке https://tools.pdf24.org/ru/ocr-pdf.
- Нажмите кнопку «Выбрать файлы» и выберите на устройстве файл с фотографией рецепта.

- Дождитесь загрузки фото, и потом вы увидите дополнительные опции. Здесь обаятельно нужно выбрать язык распознавания, а также включить опцию «Рукописные страницы«. Остальные опции не обязательны — их изменение на ваше усмотрение. Когда всё будет готово, нажмите кнопку «Начать OCR«. Начнётся распознавание текста.
- Дождитесь завершения распознавания. И затем вы увидите возможность скачать обработанный текст. Текст скачается в формате .pdf, если настройки выше были оставлены по умолчанию.
Какие есть риски и проблемы при расшифровке врачебного рецепта
Если вы когда-либо распознавали текст с помощью специальных программ, например, Fine Reader, широко распространённого в офисах, то вы могли заметить, что за этим софтом приходится перечитывать и иногда исправлять ошибки. И здесь речь идёт о платной и профессиональной программе и при работе с печатным текстом.
Что же говорить о рукописном тексте распознанном бесплатными приложениями, особенно, если он написан очень непонятным почерком? К сожалению, во многих случаях при работе с такими текстами качество оставляет желать лучшего. Даже громоздкий Fine Reader редко может нормально воспринять рукописный текст.
Это что касается проблем. Но есть и определённые риски. Так, рецепт врача — это крайне важный документ, неправильная расшифровка которого может негативно повлиять на ваше здоровье и даже жизнь. Поэтому, если вы попытались распознать рецепт с помощью описанных выше способов и получили какой-то вразумительный результат, не спешите бежать в аптеку и покупать необходимые лекарства. Есть вероятность ошибки. Даже одна буква в данном случае имеет значение. А если в точной дозировке лекарства будет значительная ошибка, то это может оказаться катастрофическим для вас.
Лучший способ расшифровки рецепта обратиться к фармацевту в аптеке. В крайнем случае можно снова прийти к своему доктору за пояснением или созвониться с ним.
Видео-инструкция
В данном видео вы узнаете, как происходит расшифровка сложного почерка врачей в режиме онлайн по фотографии рецепта.
Какие есть программы для распознавания текста рукописного текста?
Оцифровка написанного от руки текста — проблема, которая появилась несколько лет назад и остается актуальной. Почерк очень сильно отличается, поэтому сложно создать программу, которая сможет распознавать любой из существующих. Кроме того, многие люди пишут очень неразборчиво, из-за чего часть букв сливается и становится непонятной утилите. На сегодняшний день не существует ПО, которое с 90-100% вероятностью сможет разобраться написанный от руки текст.
Единственным вариантом является программа для распознавания рукописного текста, доступная по этой ссылке http://idr.in.ua/info/rukopisniy-tekst.html. Обратите внимание, что она платная и распознает только разборчиво написанные слова (примеры приведены по указанной ссылке).
Автор считает, что эти материалы могут вам помочь:
Распознавание отсканированного текста
Если вам необходимо распознать не рукописный, а напечатанный текст, изучите представленный ниже вариант ПО.
ABBYY FineReader Online
ABBYY FineReader более 10 лет поставляет различные утилиты для работы с отсканированным текстом. Первые программы работали не очень качественно, но современные алгоритмы, позволяют распознавать 95-100% отсканированного текста на знакомом программе языке. Утилита работает с самыми популярными языками планеты.
ПО, разрабатываемое компанией ABBYY FineReader платное, но если у вам необходимо распознать всего несколько листов, вы можете воспользоваться пробной версией программы.
По этой ссылке https://finereaderonline.com/ru-ru, вы можете перейти в онлайн-версию программы для распознавания печатного текста. В пробном режиме обрабатывается не более 5 страницы в месяц, после регистрации добавляется еще 10 страниц. Если вас интересуют большие объемы — приобретайте подписку. Если вам нужно распознать всего около 50-100 страниц можно зарегистрироваться несколько раз.
Для распознавания достаточно загрузить PDF-файл или картинку. После обработки файла, вы получите текст, который можно или скопировать, или выгрузить в одном из доступных форматов.
Как легко выполнить распознавание рукописного ввода с помощью глубокого обучения
Хотите распознавать рукописные формы? Этот блог представляет собой исчерпывающий обзор новейших методов распознавания рукописного ввода с использованием глубокого обучения. Мы рассмотрели последние исследования и статьи по состоянию на 2020 год. Мы также создаем устройство для чтения рукописного ввода с нуля.
Nanonets OCR API имеет много интересных вариантов использования. Чтобы узнать больше, поговорите со специалистом по ИИ Nanonets.
Запланировать звонок
Введение
Ожидается, что объем рынка оптического распознавания символов (OCR) составит 13 долларов США.38 миллиардов к 2025 году при росте на 13,7% в годовом исчислении. Этот рост обусловлен быстрой оцифровкой бизнес-процессов с использованием OCR для снижения затрат на рабочую силу и экономии драгоценных человеко-часов. Хотя OCR считается решенной проблемой, есть один ключевой компонент – распознавание рукописного ввода или распознавание рукописного текста (HTR), которое по-прежнему считается сложной задачей. Большая разница в стилях рукописного ввода у разных людей и низкое качество рукописного текста по сравнению с печатным текстом создают значительные препятствия для преобразования его в машиночитаемый текст.Тем не менее, это важная проблема, которую необходимо решить для многих отраслей, таких как здравоохранение, страхование и банковское дело.
Источник: – https://www.semanticscholar.org/paper/Handwriting-recognition-on-form-document-using-and-Darmatasia-Fanany/Последние достижения в области глубокого обучения, такие как появление архитектур трансформаторов, быстро- отслеживали наш прогресс в распознавании рукописного текста. Распознавание рукописного текста называется интеллектуальным распознаванием символов (ICR) из-за того, что алгоритмы, необходимые для решения ICR, требуют гораздо большего интеллекта, чем решение общего OCR.
В этой статье мы узнаем о задаче распознавания рукописного текста, ее тонкостях и способах ее решения с помощью методов глубокого обучения.
Хотите извлечь данные из рукописных форм? Зайдите в Nanonets и начните создавать модели OCR бесплатно!
Проблемы с распознаванием рукописного ввода- Огромное разнообразие и неоднозначность штрихов от человека к человеку
- Стиль рукописного ввода отдельного человека также меняется время от времени и непоследователен
- Низкое качество исходного документа / изображения из-за деградация с течением времени
- Текст в печатных документах располагается по прямой линии, тогда как людям не нужно писать строку текста по прямой линии на белой бумаге
- Рукописный почерк затрудняет разделение и распознавание символов
- Рукописный текст может иметь переменное вращение справа, что контрастирует с печатным текстом, где весь текст расположен ровно
- Сбор хорошего помеченного набора данных для изучения стоит недешево по сравнению с синтетическими данными
Оцифровка рецептов пациента – главная проблема в сфере здравоохранения / фармацевтики.Например, компания «Рош» ежедневно обрабатывает миллионы петабайт медицинских PDF-файлов. Еще одна область, в которой обнаружение рукописного текста имеет ключевое значение, – это набор пациентов и оцифровка форм. Добавив распознавание почерка в свой набор услуг, больницы / фармацевтические учреждения могут значительно улучшить взаимодействие с пользователем.
СтрахованиеКрупная страховая отрасль получает более 20 миллионов документов в день, и задержка в обработке претензии может серьезно повлиять на компанию.Документ о претензиях может содержать различные стили почерка, и чистая ручная автоматизация обработки претензий полностью замедлит конвейер.
Источник: – https://www.researchgate.net/figure/mages-of-handwritten-bank-cheques- from-different-countries-a-Brazilian-1-b-American_fig2_226705617 Банковское делоЛюди выписывают чеки на регулярной основе, и чеки по-прежнему играют важную роль в большинстве безналичных операций. Во многих развивающихся странах нынешняя процедура обработки чеков требует, чтобы служащий банка считывал и вручную вводил информацию, представленную на чеке, а также проверял такие записи, как подпись и дата.Поскольку в банке каждый день приходится обрабатывать большое количество чеков, система распознавания рукописного текста может сэкономить затраты и часы работы человека
Онлайн-библиотекиОгромные объемы исторических знаний оцифровываются путем загрузки сканированных изображений доступ ко всему миру. Но это усилие не очень полезно до тех пор, пока текст в изображениях не будет идентифицирован, который можно индексировать, запрашивать и просматривать. Распознавание почерка играет ключевую роль в оживлении документов средневековья и 20 века, открыток, исследований и т. Д.
МетодыМетоды распознавания рукописного ввода можно в общих чертах разделить на два следующих типа:
- Онлайн-методы : – Онлайн-методы включают цифровое перо / стилус и имеют доступ к информации о штрихе, местонахождении пера во время текста записывается, как показано на правом рисунке выше. Поскольку они, как правило, содержат много информации о потоке написанного текста, их можно классифицировать с довольно высокой точностью, и разграничение между разными символами в тексте становится намного более четким
- Offline методы : – Offline методы вовлекать распознавание текста после того, как он записан, и, следовательно, не будет иметь информации о штрихах / направлениях, задействованных во время написания, с возможным добавлением некоторого фонового шума из источника i.электронная бумага.
В реальном мире не всегда возможно / масштабируемо носить цифровое перо с датчиками для сбора информации о штрихах, и, следовательно, задача распознавания текста в автономном режиме является гораздо более актуальной проблемой. Итак, теперь мы обсудим различные методы решения проблемы распознавания офлайн-текста.
МетодыПервоначальные подходы к решению распознавания рукописного ввода включали методы машинного обучения, такие как скрытые марковские модели (HMM), SVM и т. Д.После предварительной обработки исходного текста выполняется извлечение признаков для определения ключевой информации, такой как петли, точки перегиба, соотношение сторон и т. Д. Отдельного символа. Эти сгенерированные функции теперь передаются классификатору, например, HMM, для получения результатов. Производительность моделей машинного обучения довольно ограничена из-за фазы извлечения функций вручную и их ограниченной способности к обучению. Шаг извлечения функций варьируется для каждого отдельного языка и, следовательно, не масштабируется. С появлением глубокого обучения значительно улучшилась точность распознавания почерка.Давайте обсудим несколько известных исследований в области глубокого обучения для распознавания рукописного ввода
Многомерные рекуррентные нейронные сетиRNN / LSTM, которые, как мы знаем, могут иметь дело с последовательными данными для выявления временных закономерностей и получения результатов. Но они ограничены работой с одномерными данными и, следовательно, не будут напрямую применяться к данным изображений. Для решения этой проблемы авторы в этой статье предложили многомерную структуру RNN / LSTM, как показано на рисунке ниже
Ниже приводится разница между обычной RNN и многомерной RNN.В обычной RNN скрытый уровень говорит, что я получает состояние от предыдущего скрытого слоя во время i-1. В многомерной RNN, например, в двумерной RNN, скрытый слой (i, j) получает состояния от нескольких предыдущих скрытых слоев, то есть (i-1, j) и (i, j-1), и, таким образом, захватывает контекст из обоих высота и ширина изображения, которые имеют решающее значение для получения четкого представления сети о локальном регионе. Это дополнительно расширяется для получения информации не только от предыдущих уровней, но и от будущих уровней, подобно тому, как BI-LSTM получает информацию от t-1 и t + 1.Точно так же скрытый слой 2D MDRNN i теперь может получать информацию (i-1, j), (i, j-1), (i + 1, j), (i, j + 1), таким образом захватывая контекст во всех направлениях
Вся структура сети показана выше. Используется MDLSTM, который представляет собой не что иное, как замену блока RNN блоком LSTM из вышеупомянутого обсуждения MDRNN. Входные данные разделены на блоки размером 3×4, которые теперь передаются в слои MDSTM. Сеть имеет иерархическую структуру, состоящую из уровней MDLSTM, за которыми следуют уровни прямой связи (ANN) в тандеме. Затем окончательный результат преобразуется в 1D-вектор и передается в функцию CTC для генерации выходных данных.
Временная классификация коннекционистов (CTC) – это алгоритм, используемый для решения таких задач, как распознавание речи, распознавание рукописного текста и т. Д.где доступны только входные данные и выходная транскрипция, но отсутствуют детали выравнивания, то есть как конкретная область в звуке для речи или конкретная область в изображениях для рукописного ввода выравнивается по определенному символу. Простая эвристика, такая как присвоение каждому персонажу одной и той же области, не сработает, поскольку количество места, которое занимает каждый персонаж, варьируется от руки к человеку и время от времени.
Для нашего сценария использования распознавания рукописного текста рассмотрим области входного изображения для конкретного предложения как входные X = [ x 1, x 2,…, x ** T ], тогда как ожидаемый результат будет Y = [ y 1, y 2,…, y ** U ].Предполагается, что по заданному X мы найдем точный Y. Алгоритм CTC работает, принимая входные данные X и предоставляя распределение по всем возможным Y, используя которое мы можем сделать прогноз для окончательного результата.
CTC использует базовый символ, скажем – для различения повторяющихся символов и повторяющихся символов в области ввода. Например, конкретный символ может охватывать несколько областей ввода, и, таким образом, CTC будет выводить один и тот же символ последовательно. Пример: – Ввод james и вывод CTC – jjaammmees.Окончательный результат получается путем сворачивания повторяющихся выходных данных, и, следовательно, мы получаем james. Но теперь, чтобы представить повторяющиеся символы, скажем «l» в приветственном слове, нам нужно иметь разделение, и, таким образом, все выходные данные разделяются дефисом (-). Теперь вывод для hello может быть h-ee-ll-lll-oo, который, если свернуть, станет hello, а не helo. Более подробную информацию о том, как работает CTC, можно увидеть здесь CTC.
При декодировании вывода CTC на основе простой эвристики наивысшей вероятности для каждой позиции мы можем получить результаты, которые могут не иметь никакого смысла в реальном мире.Чтобы решить эту проблему, мы могли бы использовать другой декодер, чтобы улучшить результаты. Давайте обсудим различные типы декодирования
- Декодирование наилучшего пути : – Это общее декодирование, которое мы обсуждали до сих пор. В каждой позиции мы берем результат модели и находим результат с наибольшей вероятностью.
- Декодирование поиска луча : – Вместо получения одного выходного сигнала из сети каждый раз при поиске луча предлагается сохранить несколько выходных трактов с наивысшими вероятностями и расширить цепочку за счет новых выходных сигналов и отбрасывать тракты с меньшей вероятностью, чтобы размер луча оставался постоянным. .Результаты, полученные с помощью этого подхода, более точны, чем при использовании жадного подхода.
- Поиск по лучу с помощью языковой модели : – Поиск по лучу обеспечивает более точные результаты, чем поиск по сетке, но все же он не решает проблему получения значимых результатов. Чтобы решить эту проблему, мы можем использовать языковую модель вместе с поиском луча с использованием как вероятностей модели, так и языковой модели для получения окончательных результатов.
Более подробную информацию о создании точных результатов декодирования можно найти в этой статье.
Encoder-Decoder and Attention NetworksМодели Seq2Seq, имеющие сети Encoder-decoder, в последнее время стали популярными для решения задач распознавания речи. машинный перевод и т. д. и, таким образом, были расширены для решения варианта использования распознавания рукописного ввода путем развертывания дополнительного механизма внимания.Давайте обсудим некоторые плодотворные исследования в этой области.
Сканировать, посещать и читатьВ этой основополагающей работе «Сканировать, посещать и читать» (SAR) авторы предлагают использовать модель, основанную на внимании, для сквозного распознавание почерка. Основным вкладом исследования является автоматическая транскрипция текста без разбиения на строки в качестве этапа предварительной обработки, что позволяет сканировать всю страницу и давать результаты.
SAR использует архитектуру на основе MDLSTM, аналогичную той, которую мы обсуждали выше, с одним небольшим изменением на последнем уровне.После последнего линейного слоя, то есть последнего блока Sum на рисунке выше, карты функций сворачиваются в вертикальном измерении, и для получения выходных данных применяется окончательная функция softmax.
Архитектура SAR состоит из архитектуры MDLSTM, которая действует как средство извлечения признаков. Последний модуль сворачивания с выходом softmax и потерей CTC заменяется модулем внимания и декодером LSTM. Используемая модель внимания представляет собой гибридную комбинацию внимания, основанного на содержании, и внимания на основе местоположения, что более подробно объясняется в следующей статье.Модули декодера LSTM берут предыдущее состояние, предыдущую карту внимания и функции кодера для генерации окончательного выходного символа и вектора состояния для следующего предсказания.
Convolve, Attend and SpellВ этой статье предлагается основанная на внимании модель «последовательность-последовательность» для распознавания рукописных слов. Предлагаемая архитектура состоит из трех основных частей: кодировщика, состоящего из CNN и двунаправленного ГРУ, механизма внимания, предназначенного для сосредоточения внимания на соответствующих функциях, и декодера, образованного однонаправленным ГРУ, способного записать соответствующее слово, персонаж за персонажем.
Кодировщик использует CNN для извлечения визуальных характеристик. Предварительно обученная архитектура VGG-19-BN используется в качестве средства извлечения признаков. Входное изображение преобразуется в карту характеристик X, которая затем преобразуется в X ‘путем разделения всех каналов по столбцам и объединения их для получения последовательной информации. X ‘далее преобразуется в H с помощью двунаправленного GRU. GRU – это нейронная сеть, аналогичная LSTM по своей природе, и может захватывать временную информацию.
Кроме того, модель внимания используется при прогнозировании выходных данных декодера.В статье рассматриваются два различных типа исследуемых механизмов внимания.
- Content-based Attention : – Идея заключается в том, чтобы найти сходство между текущим скрытым состоянием декодера и картой функций из кодировщика. Мы можем найти наиболее коррелированные векторы признаков в карте признаков кодировщика, которые можно использовать для предсказания текущего символа на текущем временном шаге. Более подробную информацию о том, как работает механизм внимания, можно увидеть здесь. Внимание
- На основе местоположения Внимание : – Главный недостаток механизмов определения местоположения на основе содержимого заключается в том, что существует неявное предположение, что информация о местоположении встроена в выходные данные кодировщик.В противном случае невозможно различить выводимые символы, которые повторяются из декодера. Например, рассмотрим слово Charmander, символ a повторяется в нем дважды, и без информации о местоположении декодер не сможет предсказать их как отдельные символы. Чтобы облегчить это, прогнозируется текущий символ и его выравнивание с использованием как выходных данных кодировщика, так и предыдущего выравнивания. Более подробную информацию о том, как работает посещаемость на основе местоположения, можно увидеть здесь.
Декодер однонаправленный многослойный ГРУ.На каждом временном шаге t он получает входные данные из предыдущего временного шага и вектор контекста от модуля внимания. Полиномиальное декодирование и сглаживание меток исследуются при обучении для улучшения возможностей обобщения.
Модели трансформаторовХотя сети кодировщиков-декодеров довольно хорошо справляются с достижением результатов распознавания рукописного ввода, они имеют узкое место в обучении из-за задействованных уровней LSTM и, следовательно, не могут быть распараллелены. В последнее время преобразователи стали довольно успешными и заменили LSTM в решении различных задач, связанных с языком.Давайте теперь обсудим, как модели на основе трансформаторов могут быть применены для распознавания рукописного ввода.
Обращайте внимание на то, что вы читаетеВ этой работе авторы предложили использовать архитектуру на основе трансформатора с использованием слоев многоголового внимания и самовнимания как на визуальной, так и на текстовой стадиях и, таким образом, могут научиться распознавать символы. как языковые зависимости декодируемых последовательностей символов. Поскольку знание языка встроено в саму модель, нет необходимости в каких-либо дополнительных этапах постобработки с использованием языковой модели и, следовательно, есть возможность предсказывать выходные данные, которые не являются частью словаря.Для этого кодирование текста происходит на уровне символов, а не слов. Поскольку архитектура трансформера позволяет обучать модель параллельно для каждого региона или персонажа, процесс обучения значительно упрощается.
Сетевая архитектура состоит из следующих компонентов
- Визуальный кодировщик : – Для извлечения соответствующих функций и применения многоголового визуального самовосприятия к различным местоположениям символов
- Текстовый транскрибер : – Он выполняет задачу по принятию ввод текста, его кодирование, применение самовнимания многоголового языка и взаимное внимание как к визуальным, так и к текстовым функциям.
Магистраль Resnet50 используется для дополнительных функций, как показано на рисунке выше. Выходные данные трехмерной карты признаков от Resnet50 Fc передаются в модуль временного кодирования, который меняет форму на 2d, сохраняя ту же ширину и, следовательно, форму (f x h, w). Он подается в полностью связанный слой для уменьшения формы до (f, w), и в результате получается Fc ‘. Кроме того, к Fc ‘добавляется позиционное кодирование TE, чтобы сохранить информацию о местоположении, как упомянуто в документе Transformer, написанном Vaswani.Более подробную информацию о том, как спроектирована архитектура трансформатора, можно увидеть здесь. Выходные данные проходят через полностью связанный слой, чтобы получить окончательную карту объектов с формой (f, w). Окончательный результат проходит через многоглавый модуль внимания с 8 головами, чтобы получить визуально насыщенную карту функций
Text TranscriberВходной текст проходит через кодировщик, который генерирует встраивание уровня символов. Эти вложения комбинируются с временным расположением аналогично тому, как это делается в Visual Encoder с использованием модуля Temporal Encoder.Этот результат затем передается в модуль самовосприятия с несколькими головками, который похож на модуль внимания в визуальном кодировщике. Текстовые функции, генерируемые визуальными элементами из визуального кодировщика, передаются в модуль взаимного внимания, задача которого состоит в том, чтобы выровнять и объединить изученные функции как из изображений, так и из входных текстов. Выходные данные передаются через функцию softmax, чтобы получить окончательный результат.
При оценке тестовых данных транскрипции недоступны. Таким образом, в качестве входных данных передается только начальный токен , а первый предсказанный символ возвращается в систему, которая выводит второй предсказанный символ.Этот процесс вывода повторяется в цикле до тех пор, пока не будет создан символ конца последовательности
Рукописный текст Генерация – это задача создания реально выглядящего рукописного текста и, таким образом, может использоваться для дополнения существующих наборов данных. Как мы знаем, глубокое обучение требует большого количества данных для обучения, в то время как получение огромного корпуса помеченных изображений рукописного ввода для разных языков является сложной задачей.Чтобы решить эту проблему, мы можем использовать Generative Adversarial Networks для генерации обучающих данных. Давайте обсудим здесь одну из таких архитектур.
ScrabbleGANScrabbleGAN следует полу-контролируемому подходу для синтеза изображений рукописного текста, которые универсальны как по стилю, так и по лексике. Он может создавать изображения различной длины. Генератор также может управлять результирующим стилем текста, что позволяет нам решить, должен ли текст быть курсивным или указать, насколько толстым / тонким должен быть штрих пера.
Архитектура состоит из полностью сверточного генератора, основанного на BigGAN.Для каждого символа во входных данных выбирается соответствующий фильтр, и все значения объединяются вместе, которые затем умножаются на вектор шума z, который управляет созданным стилем текста. Как видно выше, области, генерируемые для каждого отдельного символа, перекрываются, что помогает генерировать связанный рекурсивный текст, а также обеспечивает гибкость при использовании символов разного размера. Например, m занимает большую часть пространства, в то время как e и t занимают ограниченную площадь. Чтобы сохранить один и тот же стиль для всего слова или предложения, вектор стиля z остается постоянным для всех символов.
Сверточный дискриминатор, основанный на архитектуре BigGAN, используется для классификации того, выглядит ли стиль создания изображений поддельным или реальным. Дискриминатор не полагается на аннотации уровня символа и, следовательно, не основан на условном GAN класса. Преимущество этого состоит в том, что нет необходимости в помеченных данных, и, следовательно, данные из невидимого корпуса, которые не являются частью обучающих данных, могут использоваться для обучения дискриминатора. Наряду с дискриминатором распознаватель текста R обучен классифицировать, имеет ли сгенерированный текст реальный смысл или является тарабарщиной.Распознаватель основан на архитектуре CRNN с удаленной повторяющейся головкой, чтобы сделать распознаватель немного слабее и не распознавать текст, даже если он нечеткий. Текст, сгенерированный на выходе R, сравнивается с входным текстом, переданным генератору, и соответствующий штраф добавляется к функции потерь.
Выходы, сгенерированные ScrabbleGAN, показаны ниже.
Наборы данных: –- IAM : – Набор данных IAM содержит около 100 тыс. Изображений слов из английского языка со словами, написанными 657 разными авторами.Наборы для обучения, тестирования и проверки содержат слова, написанные взаимоисключающими авторами Ссылка: – http://www.fki.inf.unibe.ch/databases/iam-handwriting-database
- CVL : – Набор данных CVL состоит из семи рукописные документы, написанные примерно 310 участниками, в результате чего было получено около 83 тысяч слов, разделенных на обучающие и тестовые наборы Ссылка: – https://cvl.tuwien.ac.at/research/cvl-databases/an-off-line-database-for -writer-retrieval-writer-identity-and-word-spotting /
- RIMES : – Содержит около 60 тысяч изображений французского языка, написанных 1300 авторами, что соответствует примерно 5 письмам, написанным каждым человеком.Ссылка: – http://www.a2ialab.com/doku.php?id=rimes_database:start
Частота ошибок символов : – Вычисляется как расстояние Левенштейна, которое сумма замен символов (Sc), вставок (Ic) и удалений (Dc), необходимых для преобразования одной строки в другую, деленная на общее количество символов в наземной истине (Nc)
Word Error Rate : – Он вычисляется как сумма замен слов (Sw), вставок (Iw) и удалений (Dw), которые требуются для преобразования одной строки в другую, деленной на общее количество слов в основной истине (Nw)
. Обучите свою собственную модель распознавания рукописного текстаТеперь давайте посмотрим, как мы можем обучить нашу собственную модель распознавания рукописного текста.Мы будем обучаться на наборе данных IAM, но вы также можете обучить модель на своем собственном наборе данных. Давайте обсудим шаги, необходимые для его настройки.
DataЧтобы загрузить регистр набора данных IAM отсюда. После регистрации скачайте файл words.tgz отсюда. Он содержит набор данных с изображениями рукописных слов. Также скачайте отсюда файл аннотации words.txt.
Если вы хотите использовать свой собственный набор данных, вам необходимо следовать структуре данных набора данных IAM.
Выше показано, как выглядит структура папок набора данных AIM. Здесь a01, a02 и т. Д. Представляют родительские папки, каждая из которых имеет подпапки данных. В каждой подпапке есть набор изображений, в которых имя папки добавляется в качестве префикса к имени файла.
Кроме того, нам понадобится файл аннотации, в котором будут указаны пути к файлам изображений и соответствующие транскрипции. Рассмотрим, например, изображение выше с обозначением текста, ниже будет представление слов в файле аннотаций.txt
a01-000u-01-00 ok 156 395932 441 100 VBG nominating
- a01-000u-01-00 -> идентификатор слова для строки в форме a01-000u
- ok / err -> индикатор качества вывода сегментации
- 156 -> уровень серого для бинаризации строки, содержащей это слово
- 395932 441 100 -> ограничивающая рамка вокруг этого слова в формате x, y, w, h
- VBG -> грамматический тег для это слово. Здесь глагол Gerund
- назначает -> транскрипция для этого слова
Мы будем тренировать архитектуру на основе CRNN с потерей CTC.CNN используется для извлечения визуальных характеристик, которые передаются в RNN, а потеря CTC применяется к концу с жадным декодером для получения вывода.
ОбучениеОтсюда мы будем использовать код CRNN для обучения нашей модели. Следуйте инструкциям ниже, чтобы подготовить данные
python checkDirs.py
Выполните указанную выше команду, и вы должны увидеть результат, как показано ниже:
[OK] слов /
[OK] слов / a01 / a01-000u /
[OK] слов.txt
[OK] test.png
[OK] words / a01 / a01-000u / a01-000u-00-00.png
Теперь все готово для начала обучения.
Перейдите в корневой каталог и выполните
python main.py --train
Результаты После обучения в течение примерно 50 эпох коэффициент ошибок символов (CER) составляет 10,72%, а коэффициент ошибок слов (WER) составляет 26,45%, и, следовательно, точность слов составляет 73,55%. Некоторые из прогнозов можно увидеть на рисунке ниже.
Модель способна точно предсказать персонажей в значительной степени, но в некоторых случаях она страдает, например, ужасно предсказывается так же, как и истории предсказываются как старомодные.Эти проблемы могут быть решены путем использования языковой модели в качестве этапа постобработки вместе с декодером, который может генерировать значимые слова и исправлять простые ошибки.
РезюмеНесмотря на то, что были достигнуты значительные разработки в области технологий, которые помогают лучше распознавать рукописный текст, HTR – далеко не решенная проблема по сравнению с OCR и, следовательно, еще не широко используется в промышленности. Тем не менее, учитывая темпы развития технологий и появление таких моделей, как трансформаторы, мы можем ожидать, что модели HTR вскоре станут обычным явлением.
Чтобы получить больше информации по этой теме, вы можете начать отсюда.
Вам могут быть интересны наши последние сообщения на:
Дополнительная литература
Обновление:
Добавлены дополнительные материалы для чтения о распознавании рукописного ввода с использованием глубокого обучения.
Распознавание рукописного ввода – обзор
6 Моделирование языка
Языковые модели имеют множество применений, включая тегирование части речи (PoS), синтаксический анализ, машинный перевод, распознавание рукописного ввода, распознавание речи и поиск информации.Статистическая языковая модель представляет собой распределение вероятностей по последовательностям строк / слов и присваивает вероятность каждой строке на языке. Пусть V – конечный словарь, а V * – набор строк на языке, определенном с помощью V. Например, V = {естественный, язык, понимание} и V * = {естественный, язык, понимание, естественный язык, естественное понимание, понимание языка, естественный язык,…}. Функция распределения вероятностей p для этого языка удовлетворяет:
∑x∈V * p (x) = 1 и p (x) ≥0 для всех x∈V *
Как построить или выучить p ? Один из способов – использовать обучающую выборку примеров предложений, чтобы выучить p , используя оценок максимального правдоподобия .Затем мы можем использовать p для вычисления вероятностей для любого предложения на языке.
Мы используем обозначение x 1 x 2 … x n для обозначения предложения длиной n , где x 1 003 – первое слово, x x 2 – второе слово и так далее. Построение фразы, по одному слову за раз, рассматривается как случайный процесс. Рассмотрим последовательность случайных величин X1, X2,…, Xn, каждая из которых случайным образом принимает значение из множества V *.Пусть x 1 x 2 … x n будет предложением на языке. Если мы предположим, что слова в предложении x 1 x 2 … x n соответствуют случайным величинам X1, X2,…, Xn, наша цель – модель p ( X 1 = x 1 , X 2 = x 2 ,…, X n = x 904) .Эта совместная вероятность слов вычисляется с использованием цепного правила:
(1) p (x1x2… xn) = ∏iq (xi∣x1x2… xi − 1)
Например, p (приложения для поиска информации) = q (информация) × q (поиск ∣ информация) × q (приложения ∣ поиск информации). Мы оцениваем распределение вероятностей q , используя количество вхождений фраз в обучающих данных. Например:
q (приложения∣информационный поиск) = count (информационные поисковые приложения) count (информационный поиск)
Хотя эти числа могут быть легко вычислены в обучающих данных, есть две проблемы.Во-первых, существует слишком много возможных фраз. Во-вторых, очень маловероятно, что данные обучения предоставят подсчет для надежной оценки вероятностей всех возможных фраз на языке. Марковское предположение используется для преодоления этих проблем. Марковское предположение выполняется в модели, если на значения в любом состоянии влияют только значения непосредственно предшествующих или небольшого числа непосредственно предшествующих состояний. Скрытая марковская модель (HMM) является примером, в котором выполняется предположение Маркова.Используя предположение Маркова, уравнение. (1) переписывается как:
(2) p (x1x2… xn) ≈∏ip (xi∣xi − kx (i − k) + 1x (i − k) + 2… xi − 1), 1≤k Когда k = 1, значения текущего состояния зависят только от непосредственно предшествующего состояния (он же марковский процесс первого порядка). Аналогично, когда k = 2, значения текущего состояния зависят только от двух непосредственно предшествующих состояний (также известный как марковский процесс второго порядка). Мы аппроксимируем каждый компонент в произведении уравнения. (2) как: (3) p (xi∣x1x2… xi − 1) ≈q (xi∣xi − kx (i − k) + 1x (i − k) + 2… xi − 1), 1≤ k Значение k , выбранное в уравнении.(3) определяет тип языковой модели. Например, k = 0 дает модель языка униграммы : p (x1x2… xn) ≈∏iq (xi) В модели униграммы вероятность наблюдения данного слова не зависит от контекста. . Последними в данном случае являются слова, предшествующие данному слову. Аналогично, при установке k = 1 и k = 2, биграмм и триграммы создаются языковые модели p (x1x2… xn) ≈∏iq (xi∣xi − 1) p (x1x2… xn ) ≈∏iq (xi∣xi − 2xi − 1) Согласно модели биграмм вероятность наблюдения данного слова зависит от непосредственно предшествующего слова.Точно так же в модели триграммы слово зависит от двух непосредственно предшествующих слов. Проблемы с разреженными данными – серьезная проблема для языкового моделирования. Количество параметров велико, и данные обучения могут не отражать истинное распределение фраз на языке. Кроме того, для многих фраз числитель и знаменатель могут быть очень маленькими или даже нулевыми. Чтобы обойти эти проблемы, значения параметров сглаживаются с использованием методов линейной интерполяции и дисконтирования.Методы линейной интерполяции оценивают значения параметров с помощью линейной комбинации оценок максимального правдоподобия из моделей униграмм, биграмм и триграмм как: q (xi∣xi − 2xi − 1) = λ1qml (xi∣xi − 2, xi − 1) + λ2qml (xi∣xi − 1) + λ3qml (xi) , где λ 1 + λ 2 + λ 3 = 1, λ i 9044 для всех i и q мл обозначает оценку параметров методом максимального правдоподобия.Значения λ 1 , λ 2 и λ 3 определяются путем оптимизации функции, домен которой ( λ 1 , λ 2 , λ 3 ). После построения языковой модели, как мы ее оцениваем? Недоумение – одна из таких мер. Концептуально значение недоумения показывает, сколько вариантов выбора доступно для выбора следующего слова x i +1 для частичного предложения x 1 x 2 … x i .Следовательно, языковая модель с меньшей степенью сложности считается более сложной по сравнению с моделью с большей степенью сложности. Интуитивно хорошая языковая модель должна назначать более высокие вероятности часто наблюдаемым предложениям и более низкие значения – редко встречающимся. ПОКАЗЫВАЕТ 1-10 ИЗ 16 ССЫЛОК СОРТИРОВАТЬ ПО Релевантности Наибольшее влияние Статьи Недавность Закрытые сверточные рекуррентные нейронные сети для многоязычной архитектуры распознавания рукописного ввода 9000 – распознавание рукописного ввода, альтернатива многомерной долгосрочной краткосрочной памяти (MD-LSTM) рекуррентным нейронным сетям, основанная на сверточном кодировщике входных изображений и двунаправленном декодере LSTM, предсказывающем последовательности символов.Развернуть Совместная сегментация строк и транскрипция для сквозного рукописного распознавания абзацев Действительно ли многомерные повторяющиеся слои необходимы для распознавания рукописного текста? Внимание – все, что вам нужно Эффективные подходы к нейронному машинному переводу на основе внимания Нейронный машинный перевод путем совместного обучения выравниванию и преобразованию Нам доставляет большое удовольствие представить этот специальный выпуск, посвященный новейшим достижениям в области область анализа и распознавания документов. В условиях, когда в мире происходят огромные потрясения из-за пандемии COVID-19, особенно впечатляет анализ качества проводимых исследований перед лицом таких проблем.Мы поздравляем авторов, которые представили успешные материалы, и благодарим рецензентов, которые усердно работали в сжатые сроки. В результате открытого конкурса статей, который был широко распространен, мы получили 29 заявок, которые были признаны соответствующими. Мы поощряем вклады по любой теме под широкой эгидой IJDAR. Каждая публикация была передана одному из нас в качестве приглашенного редактора, который старался избегать любых потенциальных конфликтов интересов. Мы запросили обзоры у экспертов в данной области, следуя стандартной практике журнала.После тщательного рассмотрения, которое в некоторых случаях продлилось до двух или трех раундов, мы в конечном итоге приняли 9 статей для публикации в этом специальном выпуске. Они отражают как диапазон исследований в этой области сегодня, так и глубину изучаемых проблем. В некоторых статьях этого выпуска рассматриваются технические проблемы, возникающие при обработке исторических изображений документов в различных периодах времени и на разных языках. Некоторые из них посвящены основным этапам конвейера анализа документов (например,g., поиск и сегментирование текстовых строк), в то время как другие пытаются извлечь информацию более высокого уровня из сложных изображений документа. В одной статье рассматриваются проблемы распознавания рукописного ввода в Интернете. Многие используют различные формы глубокого обучения как подход, который оказывается мощным и адаптируемым для анализа документов, в то время как в одной статье, с другой стороны, избегают машинного обучения из соображений вычислительной эффективности. Все они отражают современное состояние. Теперь мы переходим к предоставлению краткого обзора каждой статьи, включенной в этот специальный выпуск. Мартин Холечек предлагает интегрированную систему для извлечения информации из документов в своей статье «Изучение сходства и извлечение информации из структурированных документов». В частности, автор формулирует задачу извлечения информации как задачу классификации слов из 35 классов, и каждый класс слов представляет, например, информационный тег в счете-фактуре, такой как «общая сумма». Для задачи классификации система использует различные контекстные подсказки, такие как расположение поля со словом, результат распознавания слова и все изображение документа.Для интеграции и кодирования этих сигналов объединяются сверточная нейронная сеть на основе графа и преобразователь. Наконец, используя около 25 000 PDF-файлов документов и три различных сценария оценки (включая «запрос-ответ»), автор подтверждает, что предлагаемая система может обеспечить более высокую производительность, чем исходные. В статье Хусейна Мохаммеда, Фолькера Мергнера и Джованни Чотти «Обнаружение шаблонов без обучения для исследования рукописей: эффективный подход к обеспечению возможности поиска в изображениях рукописей» представлен метод обнаружения шаблонов, в котором метод обнаружения ключевых точек сочетается с наивным байесовским методом. метод ближайшего соседа.Эта комбинация реализует надежную структуру определения деталей без какого-либо модуля машинного обучения, требующего обработки больших объемов данных. Предлагаемый метод был применен к двум наборам данных, набору данных изображений рукописного ввода на пальмовых листьях и набору данных изображений средневековых рукописей, и он может найти похожие рукописные узоры и символы на разных изображениях. В статье «Выявление истории: разделение текста палимпсеста с помощью генеративных сетей» Анна Старынска, Дэвид Мессинджер и Ю Конг предлагают технику разделения многослойного текста для рукописей палимпсестов, которые имеют трехслойную структуру по тексту, подтексту и т. Д. и фон.Для данного изображения с подтекстом входное изображение восстанавливается путем оценки подтекстовых и фоновых изображений с помощью структуры генеративной состязательной сети (GAN) и последующего слияния с ними изображения с подтекстом. Авторы применили предложенный метод к изображениям палимпсеста Архимеда после подтверждения ожидаемой производительности предложенного метода на искусственном наборе данных на основе MNIST. В статье Ольфы Мечи, Маруа Мери, Рольфа Ингольда и Наджуа Эсукри Бен Амара «Двухэтапная структура для сегментации текстовых строк в исторических изображениях документов на арабском и латинском языках» представлен двухэтапный метод сегментации текстовых строк на историческом арабском языке. или латинские изображения документов.Во-первых, для сегментации основной области текста используется архитектура глубоких сверточных сетей (FCN). На втором этапе уточняются результаты FCN. Он основан на анализе топологической структуры для извлечения полных текстовых строк (включая компоненты восходящего и нисходящего элементов). Количественные и качественные оценки представлены на большом количестве изображений документов на арабском и латинском языках, собранных из национальных архивов Туниса (ANT), а также других наборов контрольных данных. В статье Антуана Пирроне, Мари Бертон-Эймар и Николаса Журне «Самоконтролируемое глубокое метрическое обучение для поиска фрагментов древних папирусов» представлен метод глубокого метрического обучения для реконструкции древних папирусов с ассоциацией их фрагментов.Предлагаемый подход использует глубокие сверточные сиамские сети для изучения способов, с помощью которых папирологи могут получить полезные предложения по сопоставлению новых данных. В статье экспериментально показано, что предложенный подход с самоконтролем работает лучше, чем метод переноса домена из большого набора данных. «Задавая вопросы о коллекциях рукописных документов» Минеш Мэтью, Луис Гомес, Димостенис Каратсас и К.Дж. Джавахар решает интригующую задачу адаптации визуального ответа на вопрос (VQA) к коллекциям рукописных документов, где полномасштабное распознавание еще невозможно, но где ответ на запрос пользователя может быть передан с помощью выбранных фрагментов изображений из коллекции.Они используют сеть глубокого встраивания для проецирования как слов запроса, так и изображений слов в общее многомерное пространство, которое затем сокращается с помощью анализа основных компонентов (PCA). Результаты тестирования представлены для двух специально подготовленных наборов данных, адаптированных из существующих стандартных наборов данных: HW-SQuAD, который является синтетическим рукописным аналогом, полученным из SQuAD, и BenthamQA, который представляет собой меньший набор реальных отсканированных страниц рукописи, выбранных из Bentham Collection и аннотированных для QA. задача изучается.Также приводится сравнение авторского подхода, основанного на изображениях, и попытки использовать оптическое распознавание символов (OCR) на зашумленных рукописных вводах. В статье «EAML: Ensemble Self-Attention-based Mutual Learning Network для классификации изображений документов» авторы Сохаил Баккали, Зухенг Мин, Микаэль Кустати и Марсал Русинол обращаются к проблеме сочетания визуального стиля с текстовыми функциями для повышения производительности. глубоких CNN при классификации документов. Они используют модуль слияния, основанный на самовнимании, в обучаемой по ансамблю сети, которая одновременно изучает отличительные особенности визуальной и текстовой областей.Эффективность их подхода продемонстрирована посредством тестирования двух стандартных наборов данных: RVL-CDIP, который состоит из сотен тысяч изображений документов в оттенках серого в 16 различных классах, и набора данных Tobacco-3482, который состоит из тысяч изображений документов в 10 различных классах. Они также проводят кросс-наборное тестирование, чтобы продемонстрировать обобщаемость своего подхода. Применение подхода глубокого обучения к анализу макета документа является основной темой доклада Санкета Бисваса, Пау Рибы, Хосепа Льядоса и Умапады Пал «За пределами обнаружения объектов документа: сегментация сложных макетов на уровне экземпляра».Мотивированные недавним успехом в области обнаружения объектов в компьютерном зрении, авторы отмечают, что проблема должна быть пересмотрена в случае документов из-за семантических отношений между различными логическими компонентами, расположенными на странице. Более того, эта работа также использует подход на основе экземпляров, работая на уровне пикселей, в отличие от более традиционного подхода с ограничивающей рамкой, используемого в большинстве других работ. Они проверяют свои идеи с помощью региональной сверточной нейронной сети (Mask-RCNN), используя PubLayNet и HJDataset исторических японских документов со сложными макетами. Статья Яхии Хамди, Хусин Бубакер и Адель Алими «Расширение данных с использованием подходов геометрического, частотного и бета-моделирования для улучшения распознавания рукописного ввода в Интернете» посвящена проблеме нехватки данных для целей обучения в установках глубокого обучения. В статье представлены четыре стратегии увеличения данных для повышения производительности систем распознавания с использованием небольших наборов данных. Четыре стратегии, соответственно, основаны на: вариациях геометрических свойств, вариациях высших гармоник траектории рукописных ударов, введении случайного изменения параметров бета-эллиптической модели рукописных траекторий и, наконец, гибридной стратегии. который сочетает в себе предыдущие.Предлагаемый подход был оценен в контексте многоязычных онлайн-задач распознавания почерка с использованием сквозной архитектуры CNN. Для оценки используются четыре базы данных: ADAB, ALTEC-OnDB, Online KHATT для арабского алфавита и UNIPEN для латинских символов. Мы считаем, что представленное здесь исследование станет ценным ресурсом для тех, кто работает в этой области в ближайшие годы. Еще раз благодарим всех, кто способствовал успеху этого специального выпуска, как авторов, так и рецензентов.Мы также хотим поблагодарить сотрудников журнала Кэтрин Моретти, Гурсимаран Каур, Прию Верму и Мелиссу Фирон за их постоянную поддержку и помощь. Приглашенные редакторы: Josep LLadós. Даниэль Лопрести. Сейичи Учида. Когда встречается термин распознавание рукописного ввода, возникают две вещи: – OCR – механическое или электронное преобразование изображений печатного, рукописного или напечатанного текста в машинно-кодированный текст, будь то из отсканированного документа, фотографии документа, фотографии сцены или из текста субтитров, наложенного на изображение . ICR – это усовершенствованная система оптического распознавания символов или, точнее, система распознавания рукописного ввода , которая позволяет компьютеру изучать шрифты и различные стили рукописного ввода во время обработки для повышения точности и уровней распознавания. Изображение написанного текста можно воспринимать «офлайн» с листа бумаги с помощью оптического сканирования (оптического распознавания символов). В качестве альтернативы, движения кончика пера могут восприниматься «в режиме онлайн», например, с помощью поверхности экрана компьютера на основе пера.Приложения OCR (Offline Recognition) используют пиксельные изображения, полученные с камер или сканеров, в то время как онлайн-системы распознавания анализируют последовательность точек в 2D, которая описывает траекторию кончика цифрового пера. Для автономного распознавания рукописного ввода, т. Е. Для обнаружения почерка на изображении, мы можем использовать API Cloud Vision. Я не буду заниматься автономным распознаванием рукописного ввода и сосредоточусь на распознавании рукописного ввода в реальном времени (онлайн), я хочу обсудить два SDK, которые хорошо подходят для этого: – Технология распознавания рукописного ввода MyScript и управления цифровыми чернилами обеспечивает оптимальные, согласованные результаты с любым цифровым пишущим устройством.Помимо самой полной и точной технологии распознавания текста, MyScript может распознавать сложные математические уравнения, геометрическую графику и нотную запись. Это кроссплатформенный API, поэтому его можно использовать на iOS, Android, Windows и даже в веб-приложениях. MyScript выполняет распознавание в режиме онлайн и работает исключительно с цифровыми чернилами в качестве входных данных. Цифровые чернила можно определить как серию штрихов. Штрих определяется как траектория движения пальца или стилуса с момента касания области письма до его повторного подъема.Он представлен как последовательность 2D-точек ( MyScript может распознавать различные типы контента: текст, математику и графику. Помимо распознавания того, что на самом деле пишет ваш пользователь, этот SDK также может угадывать, что он собирается написать.В случае, если распознанное слово не то, что пользователь намеревался написать, он / она может выбрать альтернативу из списка похожих слов. Myscript не распознает только текст, он также поддерживает математические уравнения и позволяет пользователям рисовать и комментировать графику. 2. Math: – С MyScript Math пользователи могут легко писать математические операции и уравнения, редактировать их при необходимости, набирать их для точного рендеринга и даже решать! MyScript Math, очевидно, поддерживает простые уравнения, но может также похвастаться распознаванием сложных уравнений и формул.Уравнение должно содержать числа и / или дроби и по крайней мере один из следующих операторов или констант: В зависимости от вашего варианта использования может быть полезно выбрать режим отображения вводимых чернил: – 3. Графика: – MyScript Graphics позволяет пользователям рисовать и комментировать все виды диаграмм, диаграмм, планов, концептуальных или интеллектуальных карт. Поддерживаются жесты редактирования, и очень легко получить чистый рендеринг.Благодаря технологии MyScript вы можете не только писать от руки на цифровом устройстве так же легко, как на бумаге, но также можете редактировать свой контент и получать чистый результат. Для разработки с помощью Interactive Ink Sdk для Android вам потребуются: Вы можете найти весь исходный код веб-приложений, ios, android и Windows на GitHub.Исходный код выпущен под лицензией Apache 2.0. Сертификат – это двоичный «ключ», предоставляемый MyScript, который требуется для включения интерактивного рукописного ввода Sdk в приложении: Сертификат встроен в исходный файл , который вы должны включить в свой проект: Чтобы запустить его, просто следуйте следующим инструкциям: Шаг 1: Клонируйте репозиторий MyScript Git, содержащий примеры для платформы Android, и перейдите в корень папки, содержащей приложения : Шаг 2: Замените файл Шаг 3: Откройте каталог Шаг 4: Запустите цель Руководство объясняет некоторые ключевые концепции и предоставляет вам код частей , которые имеют отношение к простой интеграции интерактивных чернил Sdk. Руководство состоит из следующих шагов с их кодом: – Приведенное выше руководство содержит весь необходимый код для интерактивной интеграции SDK. И на этом мы приближаемся к концу Handwriting Recognition Sdk Part -1. Во второй части я расскажу об особенностях WritePad Sdk (Phatware). Таким образом, каждому будет легко выбрать лучший SDK для распознавания рукописного ввода в реальном времени, исходя из своих требований. Люди могут понять содержание изображения, просто посмотрев. Мы воспринимаем текст на изображении как текст и можем его прочитать. Компьютеры работают иначе. Им нужно что-то более конкретное, организованное так, чтобы они могли понять. Именно здесь вступает в действие Optical Character Recognition (OCR). Будь то распознавание автомобильных номеров с камеры или рукописные документы, которые должны быть преобразованы в цифровую копию, этот метод очень полезен. Хотя это не всегда идеально, это очень удобно и позволяет некоторым людям выполнять свою работу намного проще и быстрее. В этой статье мы подробно рассмотрим оптическое распознавание символов и области его применения.Мы также создадим простой скрипт на Python, который поможет нам обнаруживать символы на изображениях и предоставлять их через приложение Flask для более удобной среды взаимодействия. включает в себя обнаружение текстового содержимого на изображениях и преобразование изображений в кодированный текст , который компьютер может легко понять. Изображение, содержащее текст, сканируется и анализируется, чтобы идентифицировать символы в нем.После идентификации символ преобразуется в машинно-кодированный текст. Как это на самом деле достигается? Для нас текст на изображении легко различим, и мы можем обнаруживать символы и читать текст, но для компьютера это все серии точек. Изображение сначала сканируется, а текст и графические элементы преобразуются в растровое изображение, которое по сути представляет собой матрицу из черных и белых точек. Затем изображение предварительно обрабатывается, где яркость и контрастность регулируются для повышения точности процесса. Изображение теперь разделено на зоны, идентифицирующие интересующие области, например, где находятся изображения или текст, и это помогает начать процесс извлечения. Области, содержащие текст, теперь можно разбить на строки, слова и символы, и теперь программное обеспечение может сопоставлять символы с помощью сравнения и различных алгоритмов обнаружения. Конечный результат – это текст на изображении, которое нам дано. Процесс может быть неточным на 100% и может потребоваться вмешательство человека для исправления некоторых элементов, которые не были отсканированы правильно.Исправление ошибок также может быть достигнуто с помощью словаря или даже Natural Language Processing (NLP). Теперь вывод можно преобразовать в другие носители, такие как текстовые документы, PDF-файлы или даже аудиоконтент, с помощью технологий преобразования текста в речь. Ранее оцифровка документов осуществлялась путем ручного набора текста на компьютере. Благодаря OCR этот процесс упрощается, поскольку документ можно сканировать, обрабатывать, а текст извлекать и сохранять в редактируемой форме, например в текстовом документе. Если у вас есть сканер документов на вашем телефоне, например Adobe Scan, вы, вероятно, сталкивались с используемой технологией оптического распознавания текста. Аэропорты также могут использовать OCR для автоматизации процесса распознавания паспортов и извлечения из них информации. Другие варианты использования OCR включают автоматизацию процессов ввода данных, обнаружения и распознавания автомобильных номеров. Для этого проекта OCR мы будем использовать Python-Tesseract или просто PyTesseract , библиотеку, которая является оболочкой для Google Tesseract-OCR Engine. Я выбрал его, потому что он полностью открыт и разрабатывается и поддерживается таким гигантом, как Google. Следуйте этим инструкциям, чтобы установить Tesseract на свой компьютер, поскольку от него зависит PyTesseract. Мы также будем использовать веб-фреймворк Flask для создания нашего простого OCR-сервера, на котором мы можем делать снимки через веб-камеру или загружать фотографии для распознавания символов. Мы также собираемся использовать Pipenv, поскольку он также выполняет настройку виртуальной среды и управление требованиями. Помимо этого, мы также будем использовать библиотеку Pillow, которая является форком Python Imaging Library (PIL) для обработки открытия и обработки изображений во многих форматах в Python. В этом посте мы сконцентрируемся на PyTesseract , хотя есть и другие библиотеки Python, которые могут помочь вам извлекать текст из изображений, например: Начните с установки Pipenv , используя следующую команду через Pip (если вам нужно настроить его, обратитесь к этому). Создайте каталог проекта и запустите проект, выполнив следующую команду: Теперь мы можем активировать нашу виртуальную среду и начать установку наших зависимостей: Если вы не будете использовать Pipenv, вы всегда можете использовать подход Pip и Virtual Environment.Следуйте официальной документации, которая поможет вам начать работу с Pip и виртуальной средой: Примечание : в этом случае вместо Мы планируем реализовать этот проект в 2 фазы. В первом мы создадим сценарий, а в следующем мы создадим приложение Flask, которое будет действовать как интерфейс. После завершения настройки мы можем теперь создать простую функцию, которая берет изображение и возвращает текст, обнаруженный на изображении – это будет ядром нашего проекта: Функция довольно проста, в первых 5 строках мы импортируем Затем мы создаем функцию Давайте посмотрим, как скрипт работает с простым изображением, содержащим некоторый текст: И после запуска фрагмента кода нас приветствует это: Наш простой скрипт OCR работает! Очевидно, это было несколько легко, поскольку это цифровой текст, совершенный и точный, в отличие от рукописного.С библиотекой PyTesseract мы можем сделать гораздо больше, но об этом позже в этом посте. Давайте сначала интегрируем этот скрипт в приложение Flask, чтобы упростить загрузку изображений и выполнение операций распознавания символов. Наш сценарий можно использовать из командной строки, но приложение Flask сделает его более удобным и универсальным. Например, мы можем загружать фотографии через веб-сайт и отображать извлеченный текст на веб-сайте, или мы можем снимать фотографии с помощью веб-камеры и выполнять на них распознавание символов. Если вы не знакомы с фреймворком Flask, это хорошее руководство, которое поможет вам быстро освоиться. Начнем с установки пакета Flask: Теперь давайте определим основной маршрут: Сохраните файл и запустите: Ознакомьтесь с нашим практическим руководством по изучению Git с передовыми практиками, общепринятыми стандартами и включенной памяткой.Прекратите гуглить команды Git и на самом деле выучите ! Если вы откроете браузер и перейдете на Теперь мы создадим папку Давайте также настроим наш Обратите внимание, что теперь мы импортировали Этого достаточно для ускоренного курса Flask, давайте теперь интегрируем наш OCR-скрипт в веб-приложение. Во-первых, мы добавим функциональность для загрузки изображений в наше приложение Flask и передадим их функции Как мы видим в нашей функции Мы проверяем, действительно ли пользователь загрузил файл, и используем функцию Убедившись, что изображение имеет требуемый тип, мы затем передаем его в скрипт распознавания символов, который мы создали ранее. Функция обнаруживает текст на изображении и возвращает его. Наконец, в ответ на загрузку изображения мы визуализируем обнаруженный текст вместе с изображением, чтобы пользователь мог увидеть результаты. Файл Извлеченный текст из изображения выше: {{extract_text}} Jinja позволяют отображать текст в определенных сценариях с помощью тегов Результат: Теперь, если мы продолжим и загрузим наше предыдущее изображение: Да! Наше приложение Flask может интегрировать функцию распознавания текста и отображать текст в браузере. Это упрощает обработку изображений вместо выполнения команд в интерфейсе командной строки каждый раз, когда у нас появляется новое изображение для обработки. Давайте приложим еще несколько изображений, чтобы подробнее изучить пределы нашего простого сценария OCR, поскольку он не будет работать во всех ситуациях. Например, давайте попробуем извлечь текст из следующего изображения, и результат был выделен на изображении: Это свидетельство того, что OCR не всегда на 100% точен и может время от времени нуждаться в вмешательстве человека. Я также проверил сценарий OCR по моему почерку, чтобы увидеть, как он будет работать, и вот результат: Как видите, он не может полностью извлечь текст из моего почерка, как это было с другими изображениями, которые мы видели раньше.Я решил попробовать еще раз, на этот раз с изображением из этого источника, и вот результаты: Распознавание символов на этом изображении намного лучше, чем на том, где я использовал свой собственный почерк. Как вы можете видеть, линии на загруженном изображении более толстые, а контраст между текстом и фоном лучше, и это может быть причиной плохого распознавания моего почерка. Это область для дальнейшего изучения, вы можете получить рукописные заметки от друзей или коллег и посмотреть, насколько хорошо сценарий сможет обнаруживать персонажей.Вы даже можете прикрепить плакаты к мероприятиям и попробовать сканировать их в поисках текста, возможностей много. Python-Tesseract имеет больше возможностей, которые вы можете изучить. Например, вы можете указать язык с помощью флага Это результат сканирования изображения без флага А теперь с флагом Платформа также оптимизирована для лучшего определения языков, как показано на снимках экрана.(Источник изображения). Без флага Ориентация и обнаружение скриптов также входят в число возможностей PyTesseract, и это помогает в обнаружении используемых шрифтов и ориентации текста на данном изображении.Если мы можем сослаться на рукописное изображение, которое мы скачали ранее: На изображении не было информации о номере страницы, поэтому он не был обнаружен. Движок Tesseract способен извлекать информацию об ориентации текста на изображении и повороте. Уверенность в ориентации – это показатель уверенности двигателя в обнаруженной ориентации, которая действует как ориентир, а также показывает, что она не всегда на 100% точна.Раздел сценария обозначает систему письма, используемую в тексте, и за ним также следует маркер уверенности. Если бы мы искали распознанные символы и границы их блоков, PyTesseract достигает этого с помощью Это некоторые из возможностей PyTesseract среди других, такие как преобразование извлеченного текста в PDF-файл с возможностью поиска или вывод HOCR. Мы многого достигли в этом посте, но еще многое предстоит сделать, чтобы усовершенствовать наш проект и подготовить его к работе в реальном мире.Во-первых, мы можем добавить стиль нашему сайту и сделать его более привлекательным для конечного пользователя с помощью CSS. Мы также можем добавить возможность загрузки и сканирования нескольких изображений одновременно и одновременного отображения всего их вывода. Разве это не сделало бы сканирование нескольких документов более удобным? Браузер позволяет нам подключаться к камере машины и снимать изображения, разумеется, с разрешения пользователя. Это может быть очень полезным, особенно на мобильных устройствах. Вместо того, чтобы пользователю нужно было захватывать и сохранять изображение, а затем загружать его на веб-сайт, если мы добавим функцию камеры, мы можем позволить пользователю выполнять операции непосредственно из веб-приложения Flask.Это ускорит процесс сканирования. Предположим, что приложение Flask – это не то, что вы намеревались открыть для своего сканера OCR, вы также можете создать инструмент CLI. Инструмент позволит вам запустить команду, включая местоположение изображения, а затем распечатать вывод сканера на ваш терминал или отправить его в базу данных или API. Если вы выбрали этот путь, Docopt – фантастический инструмент для создания инструментов командной строки с использованием Python. Благодаря Tesseract и библиотеке Python-Tesseract мы смогли сканировать изображения и извлекать из них текст.Это оптическое распознавание символов, которое может быть очень полезно во многих ситуациях. Мы создали сканер, который принимает изображение и возвращает текст, содержащийся в изображении, и интегрировали его в приложение Flask в качестве интерфейса. Это позволяет нам раскрыть функциональность в более знакомой среде и таким образом, чтобы одновременно обслужить несколько человек. Исходный код этого проекта доступен здесь, на Github. Это хорошая база данных для людей, которые хотят опробовать методы обучения.
и методы распознавания образов на реальных данных при минимальных затратах
усилия по предварительной обработке и форматированию. На этом сайте доступны четыре файла: поезд изображений idx3-ubyte.gz:
изображения обучающего набора (9 обратите внимание, что ваш браузер может распаковывать эти файлы, не сообщая вам .
Если загруженные вами файлы имеют больший размер, чем указано выше, они были
несжатый вашим браузером.Просто переименуйте их, чтобы удалить расширение .gz.
Некоторые люди спрашивали меня: «Мое приложение не может открывать ваши файлы изображений».
Эти файлы не имеют стандартного формата изображения. Ты должен написать
ваша собственная (очень простая) программа для их чтения. Формат файла описан
внизу этой страницы. Исходные черно-белые (двухуровневые) изображения из NIST были нормализованы по размеру.
чтобы поместиться в рамку 20×20 пикселей с сохранением соотношения сторон. Результирующий
изображения содержат уровни серого в результате используемого метода сглаживания
алгоритмом нормализации.изображения были центрированы в изображении 28×28
вычисляя центр масс пикселей и переводя изображение
чтобы разместить эту точку в центре поля 28×28. С некоторыми методами классификации (особенно на основе шаблонов,
таких как SVM и K-ближайшие соседи), частота ошибок увеличивается, когда
Цифры центрируются по ограничительной рамке, а не по центру масс. если ты
сделать такую предварительную обработку, вы должны сообщить об этом в своем
публикации. База данных MNIST была создана из специальной базы данных NIST 3 и
Специальная база данных 1, содержащая двоичные изображения рукописных цифр.NIST
первоначально обозначили SD-3 как свой обучающий набор и SD-1 как свой тест
установленный. Однако SD-3 намного чище и легче распознается, чем SD-1. В
Причину этого можно найти в том, что СД-3 собиралась среди
Сотрудники бюро переписи населения, а SD-1 собирали среди старшеклассников.
Чтобы сделать разумные выводы из обучающих экспериментов, необходимо, чтобы
результат не зависит от выбора обучающей выборки и теста среди
полный набор образцов. Поэтому было необходимо создать новую базу данных
путем смешивания наборов данных NIST. Обучающий набор MNIST состоит из 30 000 паттернов из SD-3 и
30 000 паттернов из SD-1. Наш тестовый набор состоял из 5000 паттернов.
из SD-3 и 5000 паттернов из SD-1. Обучающий набор 60000 шаблонов
содержит примеры примерно 250 авторов. Мы убедились, что
наборы писателей обучающей выборки и тестовой выборки не пересекались. SD-1 содержит 58 527 цифровых изображений, написанных 500 разными авторами.
В отличие от SD-3, где блоки данных от каждого писателя появлялись в
последовательность, данные в SD-1 скремблируются.Идентификационные данные писателя для SD-1:
доступны, и мы использовали эту информацию, чтобы расшифровать писателей. Мы тогда
разделить SD-1 на две части: персонажи, написанные первыми 250 авторами, вошли в
наш новый обучающий набор. Остальные 250 писателей попали в наш тест.
установленный. Таким образом, у нас было два набора почти по 30 000 примеров в каждом. Новое обучение
набор был укомплектован достаточным количеством примеров из SD-3, начиная с шаблона #
0, чтобы создать полный набор из 60 000 обучающих шаблонов. Точно так же новый тест
набор был дополнен примерами SD-3, начиная с шаблона №35000, чтобы сделать
полный набор из 60 000 тестовых таблиц.Только подмножество из 10000 тестовых изображений
(5000 с SD-1 и 5000 с SD-3) доступны на этом сайте. Полный
Доступен обучающий набор из 60 000 выборок. Многие методы были протестированы с этим обучающим набором и набором тестов. Здесь
несколько примеров. Подробности о методах будут представлены в следующем
бумага. В некоторых из этих экспериментов использовалась версия базы данных, в которой
входные изображения с перекосом (вычислением главной оси формы
ближайшего к вертикали, и смещая линии так, чтобы
вертикальный).В некоторых других экспериментах обучающая выборка была дополнена
искусственно искаженные версии исходных обучающих выборок. Искажения
представляют собой случайные комбинации сдвигов, масштабирования, перекоса и сжатия. Все целые числа в файлах сначала сохраняются в MSB (с прямым порядком байтов)
формат, используемый большинством процессоров сторонних производителей. Пользователи процессоров Intel и
другие машины с младшим порядком байтов должны перевернуть байты заголовка. Есть 4 файла: train-images-idx3-ubyte: обучающий набор изображений Обучающий набор содержит 60000 примеров, а тестовый набор – 10000 примеров. Первые 5000 примеров тестового набора взяты из оригинала.
Учебный набор NIST. Последние 5000 взяты из оригинального теста NIST.
установленный. Первые 5000 чище и проще, чем последние 5000. Значения меток от 0 до 9. Пиксели сгруппированы по строкам. Значения пикселей от 0 до 255. 0 означает фон.
(белый), 255 означает передний план (черный). Значения меток от 0 до 9. Пиксели сгруппированы по строкам. Значения пикселей от 0 до 255. 0 означает фон.
(белый), 255 означает передний план (черный). Базовый формат магический номер Магическое число – это целое число (сначала MSB). Первые 2 байта всегда
0. Третий байт кодирует тип данных: 4-й байт кодирует размерность вектора / матрицы: 1
для векторов, 2 для матриц …. Размеры в каждом измерении представляют собой 4-байтовые целые числа (сначала старший бит, старший разряд,
как и в большинстве процессоров не Intel). Модель на основе трансформатора для распознавания изображений рукописного текста во Вьетнаме
В этой работе отмечается, что использование случайных искажений во время обучения в качестве увеличения синтетических данных значительно повышает точность модели , предполагая, что двумерные долгосрочные зависимости могут не быть существенными для достижения хорошей точности распознавания, по крайней мере, на нижних уровнях архитектуры.Развернуть От редакции специального выпуска «Расширенные темы анализа и распознавания документов»
Распознавание рукописного ввода Sdk – Часть 1 | by Abhishek Kumar Sah
Распознавание рукописного ввода в реальном времени x; y ), упорядоченных по времени ( t ). Таким образом, цифровые чернила относятся к динамическому процессу, который учитывает, где штрихи начинаются, где штрихи заканчиваются и в каком порядке они были нарисованы. Для платформы Android: –
git clone https://github.com/MyScript/interactive-ink-examples-android.git
cd interactive-ink-examples-android MyCertificate.java в каталоге GetStarted / src / main / java / com / myscript / certificate своим сертификатом . interactive-ink-examples-android как существующий проект Android Studio. Зависимости Gradle должны быть схвачены, и проект должен успешно скомпилироваться. GetStarted . Руководство: –
Простое оптическое распознавание символов Python
Введение
Что такое оптическое распознавание символов?
Оптическое распознавание символов Использование OCR
Что мы будем использовать
Настройка
$ pip install pipenv
$ mkdir ocr_server && cd ocr_server && pipenv install --three
$ оболочка pipenv
$ pipenv установить подушку pytesseract
pipenv install Pillow команда будет иметь вид pip install Pillow . Реализация
Скрипт OCR
попробуйте:
из PIL импорта изображения
кроме ImportError:
импортировать изображение
импорт pytesseract
def ocr_core (имя файла):
"" "
Эта функция будет обрабатывать основную обработку изображений с помощью оптического распознавания текста."" "
text = pytesseract.image_to_string (Image.open (имя файла))
текст возврата
печать (ocr_core ('images / ocr_example_1.png'))
Image из библиотеки Pillow и нашей библиотеки PyTesseract . ocr_core , которая принимает имя файла и возвращает текст, содержащийся в изображении. Веб-интерфейс Flask
$ pipenv установить Flask
из колбы импортная колба
app = Flask (__ имя__)
@ app.route ('/')
def home_page ():
return "Hello World!"
если __name__ == '__main__':
app.run ()
$ python3 app.py
127.0.0.1:5000 или localhost: 5000 , вы должны увидеть «Hello World!» на странице. Это означает, что наше приложение Flask готово к следующим шагам. templates для размещения наших файлов HTML. Давайте продолжим и создадим простой index.html :
app.py , чтобы отобразить наш новый шаблон:
из Flask import Flask, render_template
app = Flask (__ имя__)
@ app.route ('/')
def home_page ():
вернуть render_template ('index.html')
если __name__ == '__main__':
app.run ()
render_template и использовали его для визуализации файла HTML. Если вы перезапустите приложение Flask, вы все равно должны увидеть «Hello World!». на главной странице. ocr_core , которую мы написали выше. Затем мы визуализируем изображение рядом с извлеченным текстом в нашем веб-приложении в результате:
импорт ОС
from flask import Flask, render_template, request
из ocr_core импорт ocr_core
UPLOAD_FOLDER = '/ static / uploads /'
ALLOWED_EXTENSIONS = set (['png', 'jpg', 'jpeg'])
app = Flask (__ имя__)
def allowed_file (имя файла):
возвращение '.'в имени файла и \
filename.rsplit ('.', 1) [1] .lower () в ALLOWED_EXTENSIONS
@ app.route ('/')
def home_page ():
вернуть render_template ('index.html')
@ app.route ('/ upload', methods = ['GET', 'POST'])
def upload_page ():
если request.method == 'POST':
если 'file' отсутствует в request.files:
return render_template ('upload.html', msg = 'Файл не выбран')
file = request.files ['файл']
если file.filename == '':
return render_template ('загрузить.html ', msg =' Файл не выбран ')
если файл и разрешенный_файл (file.filename):
extract_text = ocr_core (файл)
вернуть render_template ('upload.html',
msg = 'Успешно обработано',
извлеченный_текст = извлеченный_текст,
img_src = UPLOAD_FOLDER + file.filename)
elif request.method == 'ПОЛУЧИТЬ':
вернуть render_template ('upload.html')
если __name__ == '__main__':
приложение.запустить()
upload_page () , мы получим изображение через POST и отобразим загружаемый HTML, если запрос GET . allowed_file () , чтобы проверить, имеет ли файл допустимый тип. upload.html будет обрабатывать публикацию изображения и рендеринг результата с помощью механизма шаблонов Jinja, который по умолчанию поставляется с Flask:
Шаблоны
{{msg}}
{% endif%}
Загрузить новый файл
Результат:
{% если img_src%}
{% endif%}
{% если извлеченный_текст%}
{% if%} {% endif%} .Мы также можем передавать сообщения из нашего приложения Flask для отображения на веб-странице в тегах {{}} . Мы используем форму для загрузки изображения в наше приложение Flask. Другие параметры PyTesseract
lang :
pytesseract.image_to_string (Image.open (имя файла), lang = 'fra')
lang : lang : lang скрипт пропустил некоторые французские слова, но после введения флага он смог обнаружить весь французский контент. Перевод невозможен, но все равно впечатляет. Официальная документация Tesseract включает в себя поддерживаемые языки в этом разделе.
печать (pytesseract.image_to_osd (Image.open ('loaded_handwritten.png')))
pytesseract.image_to_boxes (Image.open ('loaded_handwritten.png')) . Чего мы еще не сделали
Заключение
MNIST, Янн ЛеКун, Коринна Кортес и Крис Берджес База данных рукописных цифр
MNIST, Янн ЛеКун, Коринна Кортес и Крис Берджес рукописных цифр Янн ЛеКун, Институт Куранта, Нью-Йоркский университет
Коринна Кортес, Google Labs, Нью-Йорк
Кристофер Дж.К. Берджес, Microsoft Research, Редмонд Воздержитесь от частого доступа к этим файлам из автоматических скриптов. Сделайте копии! ` База данных рукописных цифр MNIST, доступная на этой странице, имеет
обучающий набор из 60 000 примеров и тестовый набор из 10 000 примеров. Это
является подмножеством большего набора, доступного в NIST. Цифры имеют
были нормализованы по размеру и центрированы в изображении фиксированного размера.
поезд-метки-idx1-ubyte.gz:
метки обучающего набора (28881 байт)
t10k-images-idx3-ubyte.gz:
изображения тестового набора (1648877 байт)
t10k-label-idx1-ubyte.gz:
метки тестового набора (4542 байта) КЛАССИФИКАТОР ПРЕДВАРИТЕЛЬНАЯ ОБРАБОТКА СКОРОСТЬ ОШИБОК ИСПЫТАНИЙ (%) Ссылка Линейные классификаторы линейный классификатор (1-слойный NN) нет 12.0 LeCun et al. 1998 линейный классификатор (1-слойный NN) выравнивание 8,4 LeCun et al. 1998 попарный линейный классификатор выравнивание 7,6 LeCun et al. 1998 K-ближайшие соседи K-ближайшие соседи, евклидово (L2) нет 5,0 LeCun et al.1998 K-ближайшие соседи, евклидово (L2) нет 3,09 Kenneth Wilder, U. Chicago K-ближайшие соседи, L3 нет 2,83 Kenneth Wilder, U. Chicago K-ближайших соседей, евклидово (L2) выравнивание 2,4 LeCun et al. 1998 K-ближайшие соседи, евклидово (L2) выравнивание, удаление шума, размытие 1.80 Kenneth Wilder, U. Chicago K-ближайшие соседи, L3 выравнивание, удаление шума, размытие 1,73 Kenneth Wilder, U. Chicago K-ближайшие соседи, L3 выравнивание, удаление шума, размытие, сдвиг на 1 пиксель 1,33 Kenneth Wilder, U. Chicago K-ближайшие соседи, L3 выравнивание, удаление шума, размытие, сдвиг на 2 пикселя 1.22 Kenneth Wilder, U. Chicago K-NN с нелинейной деформацией (IDM) подвижные кромки 0,54 Keysers et al. IEEE PAMI 2007 K-NN с нелинейной деформацией (P2DHMDM) подвижные кромки 0,52 Keysers et al. IEEE PAMI 2007 K-NN, касательное расстояние субдискретизация до 16×16 пикселей 1,1 LeCun et al.1998 K-NN, соответствие контекста формы извлечение контекстных признаков формы 0,63 Belongie et al. IEEE PAMI 2002 Усиленные пни Усиленные пни нет 7,7 Kegl et al., ICML 2009 продукты усиленных культи (3 члена) нет 1,26 Kegl et al., ICML 2009 усиленные деревья (17 листьев) нет 1.53 Kegl et al., ICML 2009 культя на особенностях Хаара Характеристики Хаара 1,02 Kegl et al., ICML 2009 продукт пней на Хааре f. Характеристики Хаара 0,87 Kegl et al., ICML 2009 Нелинейные классификаторы 40 PCA + квадратичный классификатор нет 3,3 LeCun et al.1998 1000 RBF + линейный классификатор нет 3,6 LeCun et al. 1998 SVM SVM, гауссово ядро нет 1,4 SVM полином степени 4 выравнивание 1,1 LeCun et al. 1998 Уменьшенный набор SVM deg 5 полином выравнивание 1.0 LeCun et al. 1998 Virtual SVM deg-9 poly [искажения] нет 0,8 LeCun et al. 1998 Virtual SVM, deg-9 poly, с дрожанием в 1 пиксель нет 0,68 DeCoste and Scholkopf, MLJ 2002 Virtual SVM, deg-9 poly, 1-пиксельное дрожание выравнивание 0,68 DeCoste and Scholkopf, MLJ 2002 Virtual SVM, deg-9 poly, 2-пиксельное дрожание выравнивание 0.56 DeCoste and Scholkopf, MLJ 2002 Нейронные сети 2-слойная сеть NN, 300 скрытых единиц, среднеквадратичная ошибка нет 4,7 LeCun et al. 1998 2-х слойный NN, 300 HU, MSE, [искажения] нет 3,6 LeCun et al. 1998 2-слойный NN, 300 HU выравнивание 1,6 LeCun et al.1998 2-х слойная сеть, 1000 скрытых блоков нет 4,5 LeCun et al. 1998 2-слойный NN, 1000 HU, [искажения] нет 3,8 LeCun et al. 1998 3-х слойная сеть, 300 + 100 скрытых блоков нет 3,05 LeCun et al. 1998 3-х слойный NN, 300 + 100 HU [искажения] нет 2.5 LeCun et al. 1998 3-х слойная сеть, 500 + 150 скрытых блоков нет 2,95 LeCun et al. 1998 3-х слойный NN, 500 + 150 HU [искажения] нет 2,45 LeCun et al. 1998 3-слойный NN, 500 + 300 HU, softmax, кросс-энтропия, спад веса нет 1,53 Hinton, неопубликованный, 2005 2-слойный NN, 800 HU, потеря перекрестной энтропии нет 1.6 Simard et al., ICDAR 2003 2-слойный NN, 800 HU, кросс-энтропия [аффинные искажения] нет 1,1 Simard et al., ICDAR 2003 2-слойный NN, 800 HU, MSE [упругие искажения] нет 0,9 Simard et al., ICDAR 2003 2-слойный NN, 800 HU, кросс-энтропия [упругие искажения] нет 0,7 Simard et al., ICDAR 2003 NN, 784-500-500-2000-30 + ближайший сосед, RBM + обучение NCA [без искажений] нет 1,0 Салахутдинов и Хинтон, AI-Stats 2007 6-слойный NN 784-2500-2000-1500-1000-500-10 (на GPU) [упругие искажения] нет 0,35 Ciresan et al. Neural Computation 10, 2010 и arXiv 1003.0358, 2010 комитет 25 NN 784-800-10 [упругие искажения] нормализация ширины, удаление опилки 0.39 Meier et al. ICDAR 2011 глубокая выпуклая сетка, предварительная тренировка отменена [без искажений] нет 0,83 Deng et al. Interspeech 2010 Сверточные сети Сверточные сети LeNet-1 субдискретизация до 16×16 пикселей 1,7 LeCun et al. 1998 Сверточная сеть LeNet-4 нет 1.1 LeCun et al. 1998 Сверточная сеть LeNet-4 с K-NN вместо последнего слоя нет 1,1 LeCun et al. 1998 Сверточная сеть LeNet-4 с локальным обучением вместо последнего слоя нет 1,1 LeCun et al. 1998 Сверточная сеть LeNet-5, [без искажений] нет 0,95 LeCun et al.1998 Сверточная сеть LeNet-5, [огромные искажения] нет 0,85 LeCun et al. 1998 Сверточная сеть LeNet-5, [искажения] нет 0,8 LeCun et al. 1998 Сверточная сеть Boosted LeNet-4, [искажения] нет 0,7 LeCun et al. 1998 Обучаемый экстрактор признаков + SVM [без искажений] нет 0.83 Lauer et al., Pattern Recognition 40-6, 2007 Обучаемый экстрактор признаков + SVM [упругие искажения] нет 0,56 Lauer et al., Pattern Recognition 40-6, 2007 Обучаемый экстрактор признаков + SVM [аффинные искажения] нет 0,54 Lauer et al., Pattern Recognition 40-6, 2007 неконтролируемые разреженные функции + SVM, [без искажений] нет 0.59 Labusch et al., IEEE TNN 2008 Сверточная сеть, кросс-энтропия [аффинные искажения] нет 0,6 Simard et al., ICDAR 2003 Сверточная сеть, кросс-энтропия [упругие искажения] нет 0,4 Simard et al., ICDAR 2003 large conv. чистая, случайные особенности [без искажений] нет 0,89 Ranzato et al., CVPR 2007 большая усл. нетто, функции отмены [без искажений] нет 0,62 Ranzato et al., CVPR 2007 large conv. чистая, отмена предварительной тренировки [без искажений] нет 0,60 Ranzato et al., NIPS 2006 large conv. чистая, предварительная тренировка без подготовки [упругие искажения] нет 0,39 Ranzato et al., NIPS 2006 large conv.чистая, отмена предварительной тренировки [без искажений] нет 0,53 Jarrett et al., ICCV 2009 большая / глубокая конв. сетка, 1-20-40-60-80-100-120-120-10 [упругие деформации] нет 0,35 Ciresan et al. IJCAI 2011 комитет из 7 конв. сетка, 1-20-П-40-П-150-10 [упругие перекосы] нормализация ширины 0,27 + -0,02 Ciresan et al. ICDAR 2011 комитет 35 усл.сетка, 1-20-П-40-П-150-10 [упругие перекосы] нормализация ширины 0,23 Ciresan et al. CVPR 2012 Список литературы
ФОРМАТЫ ФАЙЛОВ ДЛЯ БАЗЫ ДАННЫХ MNIST
Данные хранятся в очень простом формате файла, предназначенном для хранения векторов.
и многомерные матрицы.Общая информация об этом формате представлена на сайте
конец этой страницы, но вам не нужно читать это, чтобы использовать файлы данных.
train-labels-idx1-ubyte: метки обучающего набора
t10k-images-idx3-ubyte: тестовый набор изображений
t10k-labels-idx1-ubyte: метки тестового набора ФАЙЛ ЭТИКЕТКИ НАБОРА ОБУЧЕНИЯ (train-labels-idx1-ubyte):
[смещение] [тип]
[значение] [описание]
0000 32-битное целое число 0x00000801 (2049)
магическое число (сначала MSB)
0004 32-битное целое число 60000
Количество предметов
0008 байт без знака ??
метка
0009 байт без знака ??
метка
……..
xxxx беззнаковый байт ??
метка ФАЙЛ ИЗОБРАЖЕНИЯ НАБОРА ОБУЧЕНИЯ (train-images-idx3-ubyte):
[смещение] [тип]
[значение] [описание]
0000 32-битное целое число 0x00000803 (2051)
магическое число
0004 32-битное целое число 60000
количество изображений
0008 32-битное целое число 28
количество рядов
0012 32-битное целое число 28
Число столбцов
0016 байт без знака ??
пиксель
0017 байт без знака ??
пиксель
……..
xxxx беззнаковый байт ??
пиксель ТЕСТОВЫЙ НАБОР МЕТКИ ФАЙЛА (t10k-labels-idx1-ubyte):
[смещение] [тип]
[значение] [описание]
0000 32-битное целое число 0x00000801 (2049)
магическое число (сначала MSB)
0004 32-битное целое число 10000
Количество предметов
0008 байт без знака ??
метка
0009 байт без знака ??
метка
……..
xxxx беззнаковый байт ??
метка ФАЙЛ ИЗОБРАЖЕНИЯ ТЕСТОВОГО НАБОРА (t10k-images-idx3-ubyte):
[смещение] [тип]
[значение] [описание]
0000 32-битное целое число 0x00000803 (2051)
магическое число
0004 32-битное целое число 10000
количество изображений
0008 32-битное целое число 28
количество рядов
0012 32-битное целое число 28
Число столбцов
0016 байт без знака ??
пиксель
0017 байт без знака ??
пиксель
……..
xxxx беззнаковый байт ??
пиксель
ФОРМАТ ФАЙЛА IDX
формат файла IDX – это простой формат для векторных и многомерных
матрицы различных числовых типов.
размер в размере 0
размер в размерности 1
размер в размерности 2
…..
размер в размере N
данных
0x08: байт без знака
0x09: байт со знаком
0x0B: короткий (2 байта)
0x0C: int (4 байта)
0x0D: с плавающей запятой (4 байта)
0x0E: двойной (8 байт)