
Как Выполнить Распознавание Текста в PDF Файлах и Файлах Изображений
OCR или оптическое распознавание символов – это вычислительный процесс, который преобразует символы на основе изображений в редактируемый или доступный для поиска текст. Обычно он используется для отсканированных файлов PDF, или даже для файлов изображений, содержащих текст. OCR очень полезно при преобразовании физических документов или нередактируемых цифровых файлов в PDF файлы, с которыми Вы действительно можете работать, используя редактор PDF или программу для чтения PDF. Некоторые варианты использования OCR:
- Преобразование бумажных счетов фактур в цифровой формат
- Сканирование и преобразование заполненных вручную форм
- Преобразование содержимого из неинтерактивного состояния в интерактивное, например преобразование книги в электронную книгу.
Каким бы ни был сценарий, давайте не будем забывать, что наиболее важным аспектом выбора инструмента для распознавания текста является уровень точности. Для этого мы рекомендуемWondershare PDFelement – Редактор PDF-файлов, который доступен как для систем Windows, так и для Mac и может похвастаться одним из самых высоких показателей точности распознавания текста в отрасли. Кроме того, он позволяет преобразовывать текст на основе изображений в формат с возможностью поиска или редактирования в зависимости от цели преобразования.
Для этого мы рекомендуемWondershare PDFelement – Редактор PDF-файлов, который доступен как для систем Windows, так и для Mac и может похвастаться одним из самых высоких показателей точности распознавания текста в отрасли. Кроме того, он позволяет преобразовывать текст на основе изображений в формат с возможностью поиска или редактирования в зависимости от цели преобразования.
- Часть 1. Как Оптически Распознать Документ или Изображение в PDFelement
- Часть 2. Как Извлечь Оптически Распознанный Конвертированный Документ
- Часть 3. Как Извлечь Сразу Несколько Оптически Распознанных Документа
- Часть 4. Как Редактировать Отсканированные Документы с Помощью OCR
Часть 1. Как Оптически Распознать Документ или Изображение в PDFelement
Выполнить распознавание текста в документе несложно, потому что PDFelement точно сообщает Вам, что делать. В тот момент, когда Вы открываете нередактируемый PDF файл или используете Создать PDF для преобразования изображения в PDF, он распознает это и предлагает Вам установить плагин OCR и выполнить OCR.
Скачать Бесплатно Скачать Бесплатно КУПИТЬ СЕЙЧАС КУПИТЬ СЕЙЧАС
1. Для файлов изображений используйте кнопку «Создать PDF» на странице приветствия, чтобы добавить свои JPG, PNG и т.д., нажмите «Создать», чтобы преобразовать их в PDF и открыть в PDFelement. Для нередактируемых PDF файлов просто используйте опцию «Открыть файлы», чтобы извлечь файл из папки.
2. Как только файл откроется, Вы увидите сообщение «Выполнить распознавание текста» на панели уведомлений над документом. При нажатии на нее, появится запрос с просьбой скачать и установить плагин OCR. Выполните эти действия.
3. После установки, программа будет готова к оптическому распознаванию текста PDF файла. Нажмите кнопку уведомления, чтобы выполнить распознавание текста. На этот раз Вы увидите другое окно с двумя разделами параметров: в разделе «Параметры сканирования» выберите между редактируемым и доступным для поиска; в разделе «Диапазон страниц» выберите «Все», «Текущие» или укажите диапазон номеров страниц, которые необходимо преобразовать.
4. Теперь Ваш файл будет преобразован в соответствии с Вашими настройками.
Часть 2. Как Извлечь Оптически Распознанный Конвертированный Документ
Теперь, когда файл доступен для чтения или поиска, Вы можете редактировать его, извлекать текст и выполнять несколько других действий. Но как его экспортировать? Мы расскажем об этом далее.
Скачать Бесплатно Скачать Бесплатно КУПИТЬ СЕЙЧАС КУПИТЬ СЕЙЧАС
1. Поскольку теперь это файл PDF, дальнейшее преобразование не требуется. Вы можете экспортировать файл, перейдя в Файл→Сохранить как. Мы используем эту опцию, чтобы сохранить исходный PDF файл на основе изображений и использовать другое имя для преобразованного файла.
2. Если Вам нужно напрямую поделиться им по электронной почте или загрузить в облачное хранилище, Вы можете использовать значок «Поделиться» вверху или использовать «Файл»→«Поделиться», чтобы получить доступ к этой функции. Это действие запустит Ваш почтовый клиент по умолчанию или Ваш браузер. Вы можете заполнить остальные поля электронной почты или войти в свою учетную запись облачного хранилища и сохранить там PDF файл.
Вы можете заполнить остальные поля электронной почты или войти в свою учетную запись облачного хранилища и сохранить там PDF файл.
3. Еще один способ экспортировать PDF файл с оптическим распознаванием текста – распечатать его. Используйте для этого команду Файл→Печать.
Теперь Вы можете выполнить эти два процесса для любого PDF файла на основе изображения или файла изображения, содержащего текст. Но как обрабатывать несколько файлов одновременно? PDFelement Pro также позволяет это делать, как описано в следующем разделе.
Часть 3. Как Извлечь Сразу Несколько Оптически Распознанных Документа
PDFelement Pro также предлагает функцию пакетной обработки для распознавания текста и многие другие функции. Чтобы использовать эту функцию, следуйте нашим инструкциям.
Скачать Бесплатно Скачать Бесплатно КУПИТЬ СЕЙЧАС КУПИТЬ СЕЙЧАС
1. На вкладке «Инструмент» Вы увидите параметр «Пакетная обработка» на панели инструментов. Щелкните на него, чтобы открыть диалоговое окно пакетной обработки.
2. Слева Вы увидите различные параметры, такие как «Преобразовать», «Создать» и «Оптимизировать». Щелкните на OCR на боковой панели.
3. Вы можете перетащить файлы в это окно или использовать кнопку «Добавить файлы» в правом верхнем углу.
4. После того, как Ваши файлы были импортированы, Вы можете выбрать язык, диапазон страниц и другие параметры, такие как возможность поиска/редактирования. По завершении, нажмите «Применить», и все файлы будут преобразованы в соответствии с указанными Вами настройками.
Используя этот процесс, Вы можете мгновенно преобразовать сотни файлов с помощью функции OCR, что позволит Вам быстро оцифровать рабочие документы.
Часть 4. Как Редактировать Отсканированные Документы с Помощью OCR
После того, как оптическое распознавание было выполнено и файл стал доступным для редактирования, Вы можете редактировать его так же, как любой другой файл PDF. Это означает, что Вы можете контролировать каждый элемент в файле, будь то текст, изображения, гиперссылки, встроенные объекты, водяные знаки, верхние/нижние колонтитулы и т. д. Вот процесс редактирования отсканированного документа после распознавания текста.
д. Вот процесс редактирования отсканированного документа после распознавания текста.
1. Предполагаем, что Вы уже выполнили оптическое распознавание, поэтому теперь Вы можете перейти на вкладку «Редактировать» вверху.
2. Это отобразит различные инструменты редактирования для различных компонентов. Например, если Вы хотите отредактировать фрагмент текста, нажмите на значок «Текст». Вы также можете редактировать текст в режиме строки или абзаца.
3. Находясь в режиме редактирования текста, Вы можете выбрать любое слово, фразу, предложение или абзац в документе и либо удалить его, либо что-то добавить, либо изменить его.
4. Чтобы редактировать изображения, просто нажмите на значок изображения и выберите изображение. У Вас будет возможность заменить, повернуть, изменить положение и т.д.
5. Точно так же есть варианты добавления или редактирования ссылок, водяных знаков, фона и многого другого.
Почему PDFelement?
В заключение, давайте попробуем ответить на этот очень важный вопрос. Причина, по которой это важно, заключается в том, что Вы можете использовать другой редактор PDF с функцией распознавания текста, но он может быть неточным или выходить за рамки Вашего бюджета. Вот некоторые из причин, по которым стоит подумать о переходе на PDFelement:
Причина, по которой это важно, заключается в том, что Вы можете использовать другой редактор PDF с функцией распознавания текста, но он может быть неточным или выходить за рамки Вашего бюджета. Вот некоторые из причин, по которым стоит подумать о переходе на PDFelement:
Скачать Бесплатно Скачать Бесплатно КУПИТЬ СЕЙЧАС КУПИТЬ СЕЙЧАС
- Точный – Высокоточное распознавание текста на более чем 20 языках с поддержкой многоязычного распознавания текста
- Быстрый – Скорость преобразования – одна из лучших в отрасли
- Интуитивно понятный – Новым пользователям не нужно обучаться работать с PDFelement, что упрощает переход на эту программу
- Обширный – В PDFelement можно найти почти все функции самых известных в мире редакторов PDF
- Обновляемый – PDFelement получает постоянные обновления версий, как второстепенные, так и основные, которые позволяют достигать новых показателей производительности и взаимодействия с пользователем.

Наконец, давайте попробуем ответить на некоторые вопросы, которые могут у Вас возникнуть по оптическому распознаванию текста и связанным темам.
Часто Задаваемые Вопросы
На 100% ли точное распознавание текста?
Ни один инструмент распознавания текста не обеспечивает 100% точности для всех типов текстового содержимого. Например, если текст написан от руки и плохо читается, его очень трудно прочитать человеку, не говоря уже о распознавании текста. Однако для печатного текста распознавание текста максимально точное. Таким образом, он чрезвычайно полезен при преобразовании отсканированных файлов, содержащих печатный текст и другие символы.
Могу ли я использовать OCR для рукописных заметок?
Как уже упоминалось, почерк должен быть разборчивым, чтобы функция распознавания текста работала точно. Курсивное письмо преобразовать труднее всего, но уровень точности намного выше, если почерк понятен. Помните, что чем четче текст и чем он удобнее для человеческого глаза, тем точнее распознается текст.
Могу ли я напрямую сканировать документ в редактируемый PDF файл?
Да, PDFelement предлагает эту функцию. Чтобы использовать ее, Вы можете нажать Файл→Создать→Со сканера. Откроется диалоговое окно настроек сканирования, в котором Вы увидите кнопку «Сканировать». Щелкните по нему, и сканер отсканирует документ, после чего PDFelement импортирует его и преобразует с помощью плагина OCR.
Распознавание отсканированного текста в Word – Сканирование текста и графики. Вывод документа на печать
Разделы: Информатика, Конкурс «Презентация к уроку»
Загрузить презентацию (1,2 МБ)
Внимание! Предварительный просмотр слайдов используется исключительно в ознакомительных целях и может не давать представления о всех возможностях презентации. Если вас заинтересовала данная работа, пожалуйста, загрузите полную версию.
Цели урока:
- Образовательные:
- Воспитательные: воспитание информационной культуры учащихся, внимательности, аккуратности, дисциплинированности, усидчивости.
- Развивающие: развитие познавательных интересов, навыков работы на компьютере, самоконтроля, умения конспектировать.
Задачи урока:
- Научить студентов работать со сканерами различных производителей.
- Научить студентов применять знания работы со сканером, и программой FineRiader в курсовом и дипломном проектировании;
- Продолжить отработку умений и навыков по работе в программе MS Word;
- Отработка понятийный аппарат, символику по данной теме;
- Вырабатывать умение творчески и логически мыслить;
- Расширить кругозор студентов.
Оборудование: Мультимедийный проектор, компьютер, компьютерная презентация.
План урока (90 минут):
- Орг. момент. (10 мин)
- Проверка домашнего задания.

- Теоретическая часть. (10 мин)
- Постановка задачи для практической работы. (5 мин)
- Выполнение практической работы. (30 мин)
- Закрепление знаний. (5 мин)
- Домашнее задание. (5 мин)
- Подведение итогов урока. (5 мин)
Ход урока
I. Организационный момент.
Приветствие, проверка присутствующих. Объяснение хода урока.
II. Проверка домашнего задания.
Проводится в виде защиты студентами доклада на тему сканирования.
Студенты на предыдущем занятии делятся на три группы. Каждая группа получила домашнее задание подготовить реферат на определенную тему. Проводится защита реферата одним из членов команды.
III. Теоретическая часть.
Преобразованием графического изображения в текст занимаются специальные программы распознавания текста (Optical Character Recognition — OCR).
Возможно, самая известная программа для распознавания текстов — это FineReader от компании ABBYY. Именно эту программу чаще всего вспоминают, когда речь заходит о системах распознавания.
Именно эту программу чаще всего вспоминают, когда речь заходит о системах распознавания.
FineReader — омнифонтовая система оптического распознавания текстов. Это означает, что она позволяет распознавать тексты, набранные практически любыми шрифтами, без предварительного обучения. Особенностью программы FineReader является высокая точность распознавания и малая чувствительность к дефектам печати, что достигается благодаря применению технологии «целостного целенаправленного адаптивного распознавания».
FineReader имеет массы дополнительных функций, которые простому пользователю, возможно, и без надобности, но зато производят впечатление на определенные группы покупателей. Так, одним из козырей FineReader является поддержка неимоверного количества языков распознавания — 176, в числе которых вы найдете экзотические и древние языки, и даже популярные языки программирования.
Но далеко не все возможности включены в самую простую модификацию программы, которую вы можете получить бесплатно вместе со сканером. Пакетное сканирование, грамотная обработка таблиц и изображений — для всего этого стоит приобрести профессиональную версию программы.
Пакетное сканирование, грамотная обработка таблиц и изображений — для всего этого стоит приобрести профессиональную версию программы.
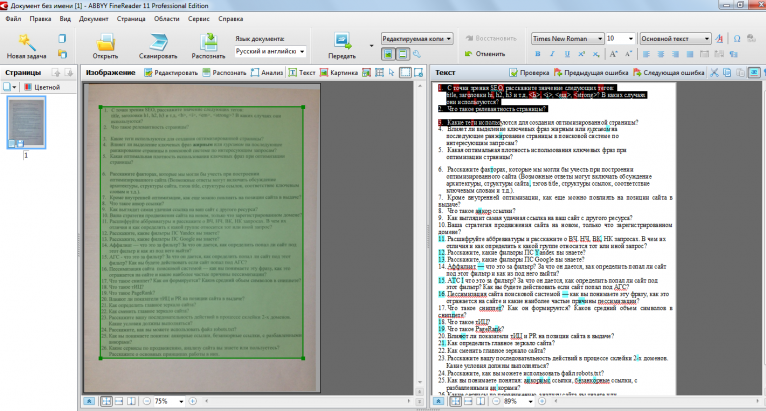
Все версии FineReader, от самой простой до самой мощной, объединяет удобный интерфейс. Для запуска процесса распознавания вам достаточно просто положить документ в сканер и нажать единственную кнопку (мастер Scan & Read) на панели инструментов программы. Все дальнейшие операции — сканирование, разбивку изображения на «блоки» и, наконец, собственно распознавание программа выполнит автоматически. Пользователю останется только установить нужные параметры сканирования.
FineReader работает со сканерами через TWAIN-интерфейс. Это единый международный стандарт, введенный в 1992 году для унификации взаимодействия устройств для ввода изображений в компьютер (например, сканера) с внешними приложениями.
Качество распознавания во многом зависит от того, насколько хорошее изображение получено при сканировании. Качество изображения регулируется установкой основных параметров сканирования: типа изображения, разрешения и яркости.
Сканирование в сером является оптимальным режимом для системы распознавания. В случае сканирования в сером режиме осуществляется автоматический подбор яркости. Если Вы хотите, чтобы содержащиеся в документе цветные элементы (картинки, цвет букв и фона) были переданы в электронный документ с сохранением цвета, необходимо выбрать цветной тип изображения. В других случаях используйте серый тип изображения.
Оптимальным разрешением для обычных текстов является — 300 dpi и 400–600 dpi для текстов, набранных мелким шрифтом (9 и менее пунктов).
После завершения распознавания страницы FineReader предложит пользователю выбор: сканировать и распознавать дальше (для многостраничного документа) или сохранить полученный текст в одном из множества популярных форматов — от документов Microsoft Office до HTML или PDF. Можно, впрочем, сразу же перебросить документ в Word или Excel, и уже там исправить все огрехи распознавания (без ни обойтись просто невозможно). При этом FineReader полностью сохраняет все особенности форматирования документа и его графическое оформление.
IV. Постановка задачи для практической работы.
Теперь потренируемся работать с программой ABBYY FineReader.
Демонстрация презентации.
Прежде чем начать сканирование необходимо настроить программу (процесс настройки программы подробно изложен в презентации)
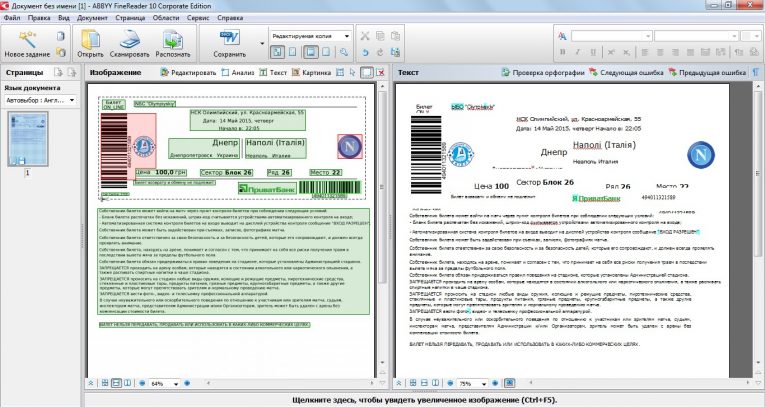
Блоки — это заключенные в рамку участки изображения. Блоки выделяют для того, чтобы указать системе, какие участки, отсканированной страницы, надо распознавать и в каком порядке. Также по ним воспроизводится исходное оформление страницы. Блоки разных типов имеют различные цвета рамок.
Рис. 1. Блоки (текст и картинка)Текст — блок используется для обозначения текста. Он должен содержать только одноколоночный текст. Если внутри текста содержатся картинки, выделите их в отдельные блоки.
Таблица — этот блок используется для обозначения таблиц или текста, имеющего табличную структуру. При распознавании программа разбивает данный блок на строки и столбцы и формирует табличную структуру. В выходном тексте данный блок передается таблицей.
В выходном тексте данный блок передается таблицей.
Картинка — этот блок используется для обозначения картинок. Он может содержать картинку или любую другую часть текста, которую Вы хотите передать в распознанный текст в качестве картинки.
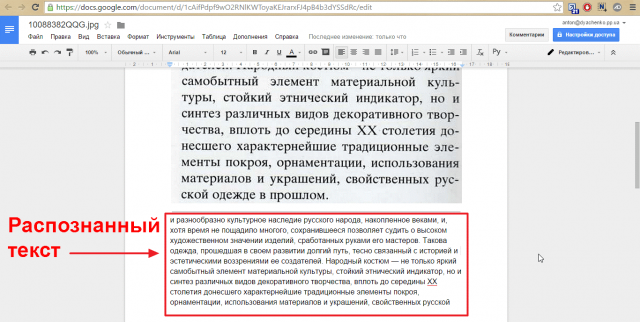
Результаты распознавания можно сохранить в файл, передать во внешнее приложение, не сохраняя на диск или скопировать в буфер обмена.
Прежде чем распознанный текст передавать в MS Word необходимо произвести проверку распознанного текста.
Рис. 2. Процесс проверки распознанного текстаРаспознанный текст можно отправить в Microsoft Word. Для этого щелкните кнопку Передать в MS Word. Запуститься программа Microsoft Word и откроется распознанный текст, который вы можете редактировать и форматировать, сохранить в файл.
Рис. 3. Передача распознанного текста в MS WordV. Выполнение практической работы
Учащиеся выполняют задание.
VI. Закрепление знаний
Закрепление знаний
Компьютерное тестирование.
VII. Домашнее задание.
Подготовка материалов для сканирования. Реферат по другому предмету.
VII. Подведение итогов урока
Подведение итога урока. Выставление оценок.
На уроке мы познакомились с программами OCR, научились распознавать отсканированное изображение с помощью программы ABBYY FineReader 5.0.
Литература.
- Е.В. Михеева. — Учебник «Информационные технологии в профессиональной деятельности» — М.: Издательский центр «Академия», 2004.
- Е.В. Михеева. — Учебник «Практикум по информационным технологиям в профессиональной деятельности» — М.: Издательский центр «Академия», 2004.
Приложение 1. Приложение содержит в себе «Карту занятия».
OCR-конвейер для обработки документов / Хабр
Сегодня я расскажу о том, как создавалась система для переноса текста из бумажных документов в электронную форму. Мы рассмотрим два основных этапа: выделение областей с текстом на сканах документов и распознавание символов в них. Кроме того, я поделюсь сложностями, с которыми пришлось столкнуться, способами их решения, а также вариантами развития системы.
Мы рассмотрим два основных этапа: выделение областей с текстом на сканах документов и распознавание символов в них. Кроме того, я поделюсь сложностями, с которыми пришлось столкнуться, способами их решения, а также вариантами развития системы.
Первичным переводом документа в электронную форму является его сканирование или фотографирование, в результате которого получается графический файл в виде фотографии или скана. Однако такие файлы, особенно высокого разрешения, занимают много места на диске, и текст в них невозможно редактировать. В связи с этим, целесообразно извлекать текст из графических файлов, что успешно делается с применением OCR.
Про OCR и цели
Оптическое распознавание символов (OCR) — перевод изображений машинописного, рукописного или печатного текста в электронные текстовые данные. Обработка данных при помощи OCR может применяться для самых различных задач:
- извлечение данных и размещение в электронной базе банковских, бухгалтерских, юридических документов;
- сканирование печатных документов с последующей возможностью редактирования;
- перенос исторических документов и книг в архивы;
- распределение печатного материала по темам;
- индексирование и поиск отсканированного печатного материала.

В настоящее время все больше организаций переходят от бумажной формы документооборота к электронной. На одном из моих недавних проектов для компании с большими объемами бумажных документов, требовалось перенести информацию, накопившуюся в сканах (около нескольких петабайт), в электронную форму и добавить возможность обработки новых отсканированных документов.
Мы выяснили, что использование готовых продуктов для решения нашей задачи приводило бы к большим затратам и низкой производительности, вызванной ограничениями объемов обрабатываемых документов. Поэтому мы решили разработать собственную систему OCR по принципу конвейера (OCR-pipeline), в которой последовательно выполняются следующие операции:
- загрузка скана документа;
- извлечение слов и строк из скана;
- распознавание символов в словах и строках;
- формирование электронного документа.
Извлечение слов и строк
Перед распознаванием символов из изображения документа целесообразно извлечь части, которые ограничивают слова или строки текста. Способов извлечения много. Существует два основных подхода — нейросетевой и с использованием компьютерного зрения. Остановимся на них подробнее.
Способов извлечения много. Существует два основных подхода — нейросетевой и с использованием компьютерного зрения. Остановимся на них подробнее.
В последнее время для детекции слов на изображениях все активнее применяются нейронные сети. При помощи сетей семейства resnet можно выделить прямоугольные рамки с текстом. Однако если документы содержат много слов и строк, то данные сети работают довольно медленно. Мы установили, что вычислительные затраты в этих случаях существенно превышают затраты с использованием методов компьютерного зрения.
Кроме того, нейронные сети resnet имеют сложную архитектуру и применительно к данной задаче их сложнее обучить, так как они больше предназначены для классификации изображений и обнаружения небольшого количества блоков текста. Их использование значительно замедлило бы разработку конвейера и в некоторых случаях снизило бы производительность. Поэтому мы решили остановиться на методах детекции строк посредством компьютерного зрения, в частности, на методе Максимальных Стабильных Экстремальных Регионов (MSER) [1].
Примеры MSER-детекции строк в документах
В ходе MSER-детекции текст в бинаризованном изображении скана предварительно «размазывается» в пятна. На основе субпиксельных вычислений полученные пятна ограничиваются связными областями и обрамляются в прямоугольные рамки. Таким образом, происходит сжатие исходных данных — из скана с документом извлекаются изображения, ограничивающие слова и строки. Стоит отметить, что данный метод не зависит от цвета извлекаемого текста. Важно лишь только то, чтобы он был достаточно контрастен по отношению к фону.
OCR AI
Следующим этапом после MSER-извлечения изображений с текстом является распознавание символов в них. В последнее время исследования в области AI показали, что распознавание символов на изображениях успешней всего выполняется на основе глубокого машинного обучения. В частности, используются нейронные сети, содержащие много уровней (глубокие нейронные сети), которые способны самостоятельно накапливать признаки и представления в обрабатываемых данных.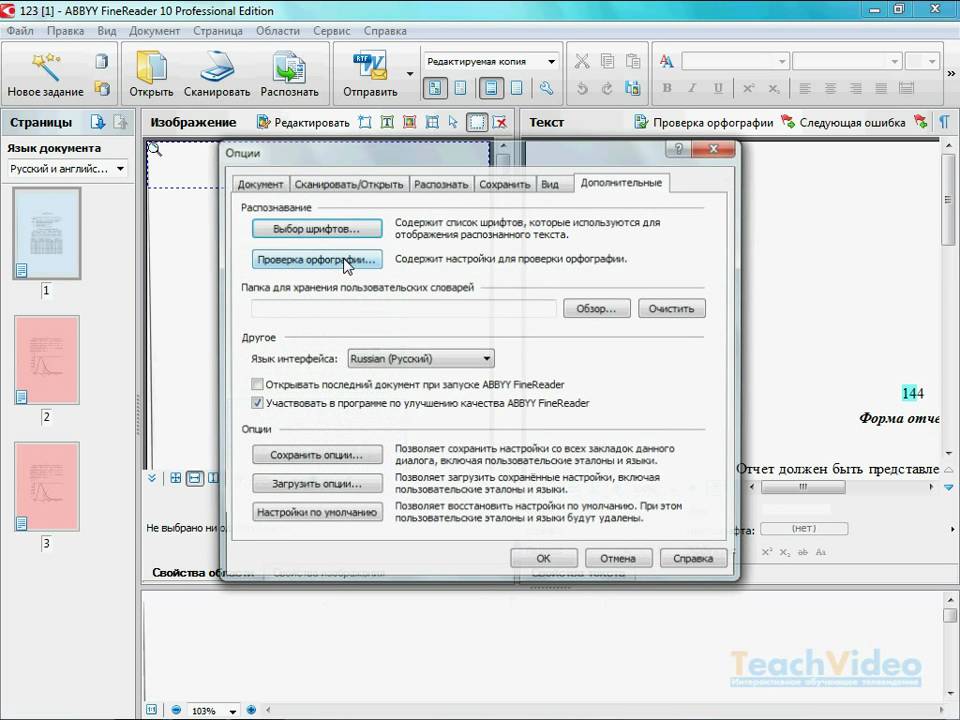
Генерация данных для обучения
Нейронные сети глубокого обучения, как правило, требуют больших объемов обучающих выборок для качественного распознавания. Ручная разметка и сбор обучающих данных занимают много времени и требуют больших трудозатрат, поэтому все чаще используются готовые датасеты или искусственно генерируются уже размеченные данные. При формировании обучающих выборок для устойчивости системы OCR к искажениям важно использовать как наборы строк хорошего качества, так и строки с различными эффектами и искажениями, обусловленные особенностями сканирования или плохим качеством печати в документах.
В качестве обучающей выборки мы использовали датасет University of Washington (UW3), состоящий из более чем 80K строк из сканированных страниц с современным деловым и научным английским языком. Однако набор геометрических и фотометрических искажений, а также количество используемых шрифтов в строках оказались недостаточными. Поэтому мы решили дополнить обучающую выборку искусственно сгенерированными строками при помощи разработанного автоматического генератора строк текста разного шрифта, цвета, фона, интерлиньяжа и т. п. Использовались 10 наиболее популярных шрифтов, встречающихся в документах: Times New Roman, Helvetica, Baskerville, Computer Modern, Arial и другие.
Поэтому мы решили дополнить обучающую выборку искусственно сгенерированными строками при помощи разработанного автоматического генератора строк текста разного шрифта, цвета, фона, интерлиньяжа и т. п. Использовались 10 наиболее популярных шрифтов, встречающихся в документах: Times New Roman, Helvetica, Baskerville, Computer Modern, Arial и другие.
Дополнительной универсальности относительно шрифтов удалось достичь благодаря использованию информации из Font Map, в которой взаимное расположение шрифтов определяет их сходство — чем ближе два шрифта друг к другу, тем более они похожи. Для дообучения сети было дополнительно отобрано 10 шрифтов на карте, наиболее удаленных от тех, на которых модель уже обучена.
Карта шрифтов Font Map fontmap.ideo.com
Архитектура сети CNN
Входные данные для обучения и распознавания сети — это части изображений сканов со строками или словами, извлеченные на этапе MSER-детекции. Выходные данные — это упорядоченные наборы символов, формирующие текст в электронном формате.
Для распознавания символов в картинках эффективно используются сверточные нейронные сети CNN [2], формирующие представления частей изображений подобно зрительной системе человека.
Сверточная нейронная сеть обычно представляет собой чередование сверточных и пулинговых слоев, объединенных в сверточные блоки (сonvolutional blocks) и полносвязных слоев на выходе (fully connected layers). В сверточном слое веса объединяются в так называемые карты признаков (feature maps). Каждый из нейронов карты признаков связан с частью нейронов предыдущего слоя.
Сети CNN базируются на математических операциях свертки (convolutions) и последующих сокращениях размерности (pooling) с применением пороговых функций, исключающих отрицательные значения весов. Карты признаков после всех преобразований в сверточных блоках конкатенируются в единый вектор (concatenation) на вход полносвязной сети. Рассмотрим операции свертки и сокращения размерности подробнее.
Вычисления в сверточной сети
В сверточном слое входное исходное изображение или карта предыдущего сверточного блока (input data) подвергаются операции свертки (сonvolution) при помощи матрицы небольшого размера (ядра свертки, сonvolution kernel), которую двигают по матрице, описывающей входные данные (input data). Выходными данными (output data) является матрица, состоящая из значений суммы попарных произведений соответствующей части входных данных с ядром свертки. На рисунке показан пример сверточного слоя с ядром свертки размера 3X3.
Выходными данными (output data) является матрица, состоящая из значений суммы попарных произведений соответствующей части входных данных с ядром свертки. На рисунке показан пример сверточного слоя с ядром свертки размера 3X3.
В слое пулинга уменьшается размерность выходных данных сверточного слоя в два этапа.
- Применение функции активации нейронов. Наиболее используемой функцией активации в сверточных нейронных сетях является ReLU, которая заменяет отрицательные значения в матрице нулями. В последнее время доказали свою эффективность ее разновидности — Noisy ReLU, которая заменяет отрицательные значения нулями с добавлением небольшого случайного слагаемого к положительным значениям, и Leaky ReLU, которая заменяет отрицательные значения не нулями, а случайными числами.
- Уменьшение размерности. Полученная после активации матрица разделяется на ячейки, в которых происходит агрегирование значений. Это можно сделать разными способами, но зачастую применяется метод выбора максимального элемента (max-pooling).

На рисунке показан пример слоя пулинга с сокращением размерности в два раза с применением ReLU и max-pooling. Выходные значения передаются на вход следующего сверточного блока или вытягиваются в вектор для полносвязного слоя, если сверточных блоков больше нет.
Архитектура сети для OCR
В нашем случае одних сверточных блоков недостаточно, поскольку обрабатываются большие объемы данных и необходим учет последовательности символов в строках. Поэтому мы использовали гибридную архитектуру, состоящую из
- сверточных блоков CNN, извлекающих представления из изображений;
- блоков долгой кратковременной памяти LSTM [3], каждый из которых состоит из комплекса пороговых функций, позволяющих запоминать представления как на длинные, так и на короткие промежутки времени, а также предотвращать преждевременное «забывание» представлений при обучении;
- классификатора CTC [4], способствующего сохранению последовательности выводимых символов.

Вычислительные эксперименты
В ходе обучения мы провели серию экспериментов относительно наборов строк в обучающих выборках. Выделим основные из них: на основе только сгенерированных строк (10 наиболее популярных шрифтов + 10 шрифтов из Font Map), на основе сгенерированных строк с тремя наиболее используемыми в документах шрифтами (Times New Roman, Helvetica, Computer Modern) со строками из датасета UW3 и на основе сгенерированных строк (10 + 10 шрифтов) со строками из датасета UW3.
Отметим, что к концу итерационного процесса максимальная точность (accuracy) на валидационной выборке практически одинакова. Точность по тестовой выборке, напротив, имеет существенное различие — добавление строк из датасета UW3 к сгенерированным строкам повышает точность распознавания. При этом увеличение количества шрифтов в искусственно сгенерированных строках также несколько увеличивает точность распознавания.
Обучение нейросети происходило по принципу «раннего останова»: через определенное количество итераций выполнялось распознавание случайно выбранного подмножества строк из обучающей (валидационной) выборки. Если в течение нескольких таких проверок максимальное значение точности не изменялось, то итерационный процесс обучения прекращался и сохранялись веса нейронной сети для распознавания строк из документов. Время обучения рассчитывалось от начала итерационного процесса до останова. Использовались графические ускорители GPU Nvidia семейства Tesla (K8 и V100).
Если в течение нескольких таких проверок максимальное значение точности не изменялось, то итерационный процесс обучения прекращался и сохранялись веса нейронной сети для распознавания строк из документов. Время обучения рассчитывалось от начала итерационного процесса до останова. Использовались графические ускорители GPU Nvidia семейства Tesla (K8 и V100).
Рассматривались документы с разрешением сканирования от 96dpi на английском языке, в том числе с присутствием цветного текста. Построенная архитектура позволила достичь точности распознавания символов до 95-99%.
Таким образом, в качестве выходных данных мы получаем символы, объединенные в слова или строки, формирующие электронные документы.
Конвейер
Значительное ускорение обработки документов было достигнуто благодаря организации нашей системы распознавания по принципу конвейера с минимизацией простоев, а также за счет распараллеливания вычислений в CPU и GPU и рационального использования памяти. Система развертывалась с помощью Docker и Kubernetes.
Система развертывалась с помощью Docker и Kubernetes.
Организация системы OCR AI распознавания по принципу конвейера.
Длина прямоугольных блоков, описывающих процедуру обработки, схематично соответствует интервалу времени. Время выполнения каждой из процедур может различаться в зависимости от количества символов в документе.
Load Scan i — загрузка скана i-го документа,
Strokes Detection i — извлечение строк из i-го документа при помощи MSER,
Load Strokes i — OpenCV-предобработка и нормализация извлеченных строк i-го документа и загрузка на вход сети,
AI Recognition i — распознавание символов в строках i-го документа на основе построенной глубокой сети.
Для повышения качества MSER-детекции мы дополнительно применяли математические методы цифровой обработки изображений, которые в том числе исключали нежелательные шумы, естественно возникающие при сканировании бумажных документов. Обработка изображений и MSER-детекция слов и строк реализовывалась на языке Python с использованием библиотеки компьютерного зрения OpenCV.
Для повышения качества обучения, защиты от переобучения и последующего распознавания в нейронной сети AI мы применяли адаптивное обновление весов сети [5], dropout-прореживание [6] и батч-нормализацию [7]. Реализация нейронной сети глубокого обучения также была написана на Python c использованием фреймворка TensorFlow. Вычисления на GPU от Nvidia поддерживались благодаря внедрению технологий CUDA и cuDNN.
Дополнительного прироста производительности предполагается достичь при помощи технологии TensorRT [8], заточенной под оптимальное использование весов сети при вычислениях в GPU, производимых Nvidia (например, таких, как Tesla или k8). При этом веса обученных моделей преобразуются в более сжатый формат с плавающей точкой. Это позволяет более чем в 40 раз повысить скорость вычислений в GPU по сравнению с CPU без видимых потерь точности распознавания.
Что дальше?
Выделим несколько направлений развития нашей системы.
- Сканирование может производиться разными способами и под разным углом.
 Следовательно, систему можно дополнить блоком предобработки скана с детектором границ и углов документа, а также с интеллектуальной фильтрацией для улучшения качества скана.
Следовательно, систему можно дополнить блоком предобработки скана с детектором границ и углов документа, а также с интеллектуальной фильтрацией для улучшения качества скана. - Мы анализировали данные на английском языке. Следовательно, система распознавания может дополняться аналогичными моделями для поддержки нескольких языков.
- Данный конвейер можно применять и для обработки рукописного текста. Стоит отметить, что в этом случае для генерации обучающих выборок целесообразно применять нейронные сети GAN [9], позволяющие генерировать весьма реалистичные данные.
- Большие объемы текстовых данных часто требуют постобработки с использованием natural language processing. Например, машинный перевод или разделение документов по тематикам с применением латентного размещения Дирихле (LDA) [10].
Дополнительно
[1]
wiki:en.wikipedia.org/wiki/Maximally_stable_extremal_regions
paper: J. Matas, O. Chum, M. Urban, and T. Pajdla. «Robust wide baseline stereo from maximally stable extremal regions.» Proc. of British Machine Vision Conference, pages 384-396, 2002. cmp.felk.cvut.cz/~matas/papers/matas-bmvc02.pdf
Matas, O. Chum, M. Urban, and T. Pajdla. «Robust wide baseline stereo from maximally stable extremal regions.» Proc. of British Machine Vision Conference, pages 384-396, 2002. cmp.felk.cvut.cz/~matas/papers/matas-bmvc02.pdf
[2]
wiki: en.wikipedia.org/wiki/Convolutional_neural_network
paper: LeCun, Yann; Léon Bottou; Yoshua Bengio; Patrick Haffner (1998). «Gradient-based learning applied to document recognition» (PDF). Proceedings of the IEEE. 86 (11): 2278–2324 yann.lecun.com/exdb/publis/pdf/lecun-01a.pdf
[3]
wiki: en.wikipedia.org/wiki/Long_short-term_memory
paper: Sepp Hochreiter; Jürgen Schmidhuber (1997). «Long short-term memory». Neural Computation. 9 (8): 1735–1780. www.bioinf.jku.at/publications/older/2604.pdf
[4]
wiki: en.wikipedia.org/wiki/Connectionist_temporal_classification
paper: Graves, Alex; Fernández, Santiago; Gomez, Faustino (2006). «Connectionist temporal classification: Labelling unsegmented sequence data with recurrent neural networks». In Proceedings of the International Conference on Machine Learning, ICML 2006: 369–376. www.cs.toronto.edu/~graves/icml_2006.pdf
In Proceedings of the International Conference on Machine Learning, ICML 2006: 369–376. www.cs.toronto.edu/~graves/icml_2006.pdf
[5]
wiki: en.wikipedia.org/wiki/Stochastic_gradient_descent
paper: Diederik, Kingma; Ba, Jimmy (2014). «Adam: A method for stochastic optimization». arxiv.org/pdf/1412.6980.pdf
[6]
wiki: en.wikipedia.org/wiki/Dropout_(neural_networks)
paper: Nitish Srivastava, Geoffrey Hinton, Alex Krizhevsky, Ilya Sutskever and Ruslan Salakhutdinov. «Dropout: A Simple Way to Prevent Neural Networks from Overfitting». Jmlr.org. Retrieved July 26, 2015. jmlr.org/papers/volume15/srivastava14a/srivastava14a.pdf
[7]
wiki: en.wikipedia.org/wiki/Batch_normalization
paper: Ioffe, Sergey; Szegedy, Christian (2015). «Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift» arxiv.org/pdf/1502.03167.pdf
[8]
site: developer.nvidia.com/tensorrt
[9]
wiki: en. wikipedia.org/wiki/Generative_adversarial_network
wikipedia.org/wiki/Generative_adversarial_network
paper: Goodfellow, Ian; Pouget-Abadie, Jean; Mirza, Mehdi; Xu, Bing; Warde-Farley, David; Ozair, Sherjil; Courville, Aaron; Bengio, Yoshua (2014). Generative Adversarial Networks (PDF). Proceedings of the International Conference on Neural Information Processing Systems (NIPS 2014). pp. 2672–2680. papers.nips.cc/paper/5423-generative-adversarial-nets.pdf
[10]
wiki: en.wikipedia.org/wiki/Latent_Dirichlet_allocation
paper: Blei, David M.; Ng, Andrew Y.; Jordan, Michael I (January 2003). Lafferty, John (ed.). «Latent Dirichlet Allocation». Journal of Machine Learning Research. 3 (4–5): pp. 993–1022. www.jmlr.org/papers/volume3/blei03a/blei03a.pdf
Сканирование PDF и оптическое распознавание символов
Обзор
При сканировании физических документов и преобразовании их в PDF все содержимое документа сохраняется в виде изображений.
Наиболее важным компонентом доступности PDF является обеспечение возможности поиска по любому тексту в документе. Средства чтения с экрана и другие вспомогательные технологии не могут считывать текст с изображений или интерпретировать структуру документов, сохраненных в виде изображений. Если вы сканируете документ и сохраняете его в формате PDF, вам необходимо выполнить Оптическое распознавание символов (OCR) на нем в качестве предшественника любых дополнительных проверок доступности. В этой статье подробно рассказывается, как выполнять распознавание текста, а также приводятся советы по созданию более качественных отсканированных документов.
Средства чтения с экрана и другие вспомогательные технологии не могут считывать текст с изображений или интерпретировать структуру документов, сохраненных в виде изображений. Если вы сканируете документ и сохраняете его в формате PDF, вам необходимо выполнить Оптическое распознавание символов (OCR) на нем в качестве предшественника любых дополнительных проверок доступности. В этой статье подробно рассказывается, как выполнять распознавание текста, а также приводятся советы по созданию более качественных отсканированных документов.
Примечание. Эта статья предназначена для PDF-файлов, созданных в результате сканирования или преобразованных из файлов изображений. PDF-файлы, экспортированные из Word и других интерфейсов редактирования контента, уже содержат распознаваемый и доступный для поиска текст.
Инструкции
По возможности избегайте сканирования документов
- Университет штата Орегон имеет доступ ко многим онлайн-журналам, и библиотекарь может найти уже оцифрованную версию ваших ресурсов.

Если необходимо сканировать, начните с источника высокого качества
- OCR лучше всего работает с документами, которые:
- Компьютерный текст
- Высокое разрешение
- Четкий и разборчивый
- По возможности избегайте:
- Почерк
- Примечания на странице, включая подчеркивание и выделение текста, а также примечания на полях
- Документы с разрывами и пятнами
- Сканирование переплета книги
- Если сканируется исходный материал, который можно легко снять с переплета, сделайте это.
- Сканировать элементы в правильной ориентации.
- Используйте настройки сканера не менее 300 dpi для текста и рассмотрите самые высокие настройки, если ваш документ содержит сложные диаграммы, экспоненциальные обозначения или другие нестандартные символы.
- Если сканер предоставляет возможность создания «PDF с возможностью поиска», выберите ее. Это автоматически выполняет OCR во время сканирования.

Как проверить
Проверка живого текста
- Чтобы проверить наличие в PDF фактического распознанного текста, откройте PDF и попытайтесь выделить текст. Если вы можете выделить текст курсором, он распознан. Если вы не можете выделить текст, он является частью изображения и не распознается вспомогательными инструментами.
- Вы также можете проверить это, выполнив текстовый поиск. Используйте ctrl-f, чтобы вызвать поле текстового поиска, и найдите термин, который, как вы знаете, есть в документе.
- На снимке экрана показана отсканированная версия Конституции США без текста, доступного для поиска. Обратите внимание, что текст нельзя выделить. Это изображение содержит текст, написанный сильно стилизованным почерком, на документе со значительным износом. Автоматическое распознавание символов вряд ли правильно идентифицирует текст после запуска инструмента OCR.
- Сравните это со снимком экрана с текстом 27-й поправки, сохраненным в формате PDF с возможностью поиска текста.
 Обратите внимание, что этот текст выделен, как в текстовом процессоре. Первоначально этот документ был изображением, но поскольку в нем используется четкий и разборчивый компьютерный текст, инструмент OCR смог правильно проанализировать текст.
Обратите внимание, что этот текст выделен, как в текстовом процессоре. Первоначально этот документ был изображением, но поскольку в нем используется четкий и разборчивый компьютерный текст, инструмент OCR смог правильно проанализировать текст.
Как выполнить распознавание текста
Если ваш текст доступен для поиска, вы уже выполнили этот шаг! Если ваш текст не доступен для поиска, вот как выполнить распознавание текста.
Настройка Adobe Acrobat
- Добавьте инструмент «Сканирование и распознавание» на панель инструментов Adobe Acrobat. На вкладке Tools найдите Scan & OCR. Нажмите кнопку “Добавить”, и он будет добавлен на боковую панель инструментов. Скорее всего, вы будете использовать Accessibility 9.0008 и Мастер действий на более поздних этапах тестирования специальных возможностей, поэтому добавьте эти инструменты, пока вы здесь. Когда вы добавите инструменты на боковую панель, кнопка Добавить изменится на Открыть , как показано на снимке экрана.
 Вернитесь к своему документу.
Вернитесь к своему документу.
Запустите инструмент OCR
- Выберите «Сканирование и распознавание» на боковой панели.
- Инструмент открывает новую панель инструментов с параметрами сканирования. Выберите Enhance вариант. Убедитесь, что установлен флажок Распознать текст , затем нажмите Улучшить. В зависимости от размера документа это может занять минуту.
При необходимости укажите доступные альтернативы
- Убедитесь, что текст теперь доступен для поиска. Если это не так, запуск Enhance несколько раз иногда дает лучшие результаты. Если после нескольких Enhances текст по-прежнему не распознается, исходное изображение не подходит для распознавания текста.
- Если есть причина, по которой необходимо использовать оригинальный исходный документ (например, изображение оригинальной Конституции предпочтительнее воссоздания на основе шрифта), рассмотрите возможность загрузки как оригинальной, недоступной версии, так и доступной альтернативы.
- Если есть причина, по которой необходимо использовать оригинальный исходный документ (например, изображение оригинальной Конституции предпочтительнее воссоздания на основе шрифта), рассмотрите возможность загрузки как оригинальной, недоступной версии, так и доступной альтернативы.
Видеогиды
PDF-файлы со специальным доступом — сканирование и оптическое распознавание символов
Сканирование PDF-файлов и транскрипт OCR
Чтение и классификация отсканированных документов с использованием глубокого обучения | Шайроз Сохаил
К ужасу многих людей, в мире все еще циркулирует огромное количество бумажных документов. Спрятанные в угловых ящиках, спрятанные в шкафах для документов, переполненные с полок в кабинах — это головная боль, чтобы отслеживать, обновлять и просто хранить. Что, если бы существовала система, в которой вы могли бы сканировать эти документы, генерировать простые текстовые файлы из их содержимого и автоматически классифицировать их по темам высокого уровня? Что ж, технология для всего этого существует, и нужно просто соединить их все вместе и заставить работать как сплоченную систему, что мы и рассмотрим в этой статье. Основными технологиями будут OCR (оптическое распознавание символов) и тематическое моделирование. Давайте начнем!
Основными технологиями будут OCR (оптическое распознавание символов) и тематическое моделирование. Давайте начнем!
Сбор данных
Первое, что мы собираемся сделать, это создать простой набор данных, чтобы мы могли протестировать каждую часть нашего рабочего процесса и убедиться, что он делает то, что должен. должен. В идеале наш набор данных будет содержать отсканированные документы разного уровня разборчивости и периодов времени, а также тему высокого уровня, к которой принадлежит каждый документ. Я не смог найти набор данных с такими точными характеристиками, поэтому мне пришлось работать над созданием собственного. Темами высокого уровня, которые я выбрал, были правительство, письма, курение и патенты. Случайный? В основном они были выбраны из-за наличия большого количества отсканированных документов для каждой из этих областей. Приведенные ниже замечательные источники были использованы для извлечения отсканированных документов по каждой из этих тем:
Правительство/Историческое : OreDocuments
Буква : LettersOfnote
Патенты : Портал к истории Техаса (Университет Северного Техаса)
Shorking : TOBACCO 800
. выбрал около 20 документов, которые были хорошего размера и разборчивы для меня, и поместил их в отдельные папки, определенные темой
выбрал около 20 документов, которые были хорошего размера и разборчивы для меня, и поместил их в отдельные папки, определенные темой
После почти целого дня поиска и каталогизации всех изображений я изменил их размер до 600×800 и преобразовал их в формате .PNG. Готовый набор данных доступен для скачивания здесь.
Некоторые из отсканированных документов, которые мы будем анализироватьНиже приведен простой сценарий изменения размера и преобразования:
Создание конвейера OCR
Оптическое распознавание символов — это процесс извлечения письменного текста из изображений. Обычно это делается с помощью моделей машинного обучения и чаще всего с помощью конвейеров, включающих сверточные нейронные сети. Хотя мы могли бы обучить пользовательскую модель OCR для нашего приложения, для этого потребовалось бы гораздо больше обучающих данных и вычислительных ресурсов. Вместо этого мы будем использовать фантастический API Microsoft Computer Vision, который включает в себя специальный модуль для OCR.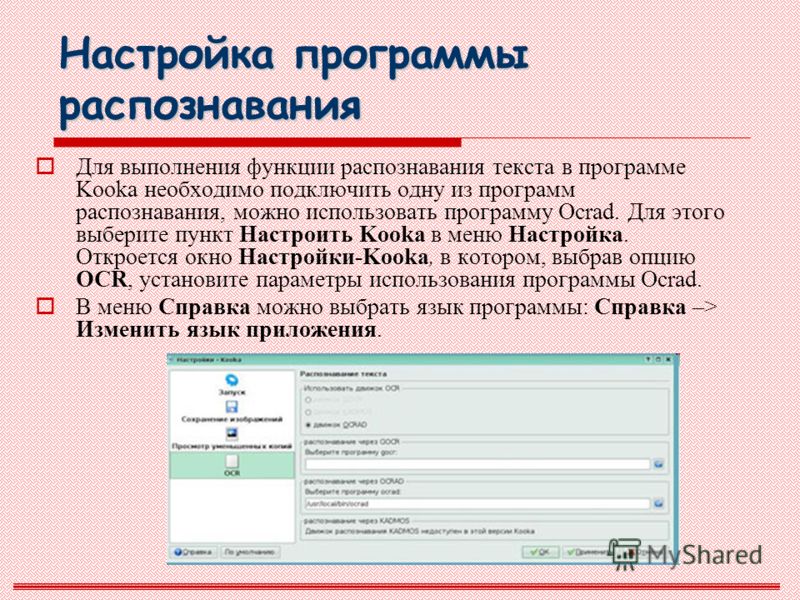 Вам нужно будет зарегистрировать учетную запись бесплатного уровня (достаточную для использования со сканированием документов), и вызов API будет использовать изображение (как изображение PIL) и выводить несколько битов информации, включая местоположение/ориентацию текста на изображении как как и сам текст. Следующая функция примет список изображений PIL и выведет список извлеченных текстов равного размера:
Вам нужно будет зарегистрировать учетную запись бесплатного уровня (достаточную для использования со сканированием документов), и вызов API будет использовать изображение (как изображение PIL) и выводить несколько битов информации, включая местоположение/ориентацию текста на изображении как как и сам текст. Следующая функция примет список изображений PIL и выведет список извлеченных текстов равного размера:
Постобработка
Поскольку в некоторых случаях мы можем захотеть завершить наш рабочий процесс здесь, вместо того, чтобы просто хранить извлеченный текст в виде гигантского списка в памяти, мы также можем записать извлеченные тексты в отдельные файлы .txt с помощью те же имена, что и исходные входные файлы. Хотя технология OCR от Microsoft хороша, иногда она допускает ошибки. Мы можем смягчить некоторые из этих ошибок, используя модуль проверки орфографии. Следующий сценарий принимает входную и выходную папку, считывает все отсканированные документы во входной папке, считывает их с помощью нашего сценария OCR, запускает проверку орфографии и исправление слов с ошибками и, наконец, записывает необработанные файлы . txt в папку. папки вывода.
txt в папку. папки вывода.
Подготовка текста для тематического моделирования
Если наш набор отсканированных документов достаточно велик, запись их всех в одну большую папку может затруднить их сортировку, и у нас, вероятно, уже есть какая-то неявная группировка в документах (особенно если они пришли из чего-то вроде картотеки). Если у нас есть приблизительное представление о том, сколько различных «типов» или тем документов у нас есть, мы можем использовать тематическое моделирование, чтобы определить их автоматически. Это даст нам инфраструктуру для разделения идентифицированного текста из OCR на отдельные папки в зависимости от содержимого документа. Тематическая модель, которую мы будем использовать, называется LDA, что означает латентный анализ Дирехле, и здесь есть отличное введение в этот тип модели. Для запуска этой модели нам потребуется немного больше предварительной обработки и организации наших данных, поэтому, чтобы наши сценарии не стали слишком длинными и перегруженными, мы будем предполагать, что отсканированные документы уже были прочитаны и преобразованы в файлы . txt с использованием описанного выше рабочего процесса. . Затем тематическая модель будет считывать эти файлы .txt, классифицировать их по темам, которые мы укажем, и помещать их в соответствующие папки.
txt с использованием описанного выше рабочего процесса. . Затем тематическая модель будет считывать эти файлы .txt, классифицировать их по темам, которые мы укажем, и помещать их в соответствующие папки.
Мы начнем с простой функции для чтения всех выведенных файлов .txt в нашей папке и чтения их в список кортежей с (имя файла, текст). Это поможет нам отслеживать исходные имена файлов после того, как мы разделим их на темы
Далее нам нужно будет убедиться, что все бесполезные слова (те, которые не помогают нам отличить тему конкретного документа). Мы сделаем это, используя три разных метода:
- Удалить стоп-слова
- Убрать теги, знаки препинания, цифры и множественные пробелы
- Фильтрация TF-IDF
Для достижения всего этого (и нашей тематической модели) мы будем использовать пакет Gensim. Приведенный ниже сценарий выполнит необходимые шаги предварительной обработки для списка текста (вывод из приведенной выше функции) и обучит модель LDA.
Использование тематической модели для категоризации документов
После обучения нашей модели LDA мы можем использовать ее для категоризации нашего набора учебных документов (и будущих документов, которые могут появиться) по темам, а затем поместить их в соответствующие папки.
Использование обученной модели LDA для новой текстовой строки требует некоторой возни (на самом деле мне нужна была помощь, чтобы разобраться с этим самому, слава Богу за ТАК), все сложности содержатся в функции ниже:
Наконец, мы’ Нам понадобится другой метод, чтобы получить фактическое название темы на основе индекса темы.
Собираем все вместе
Теперь мы можем объединить все функции, которые мы написали выше, в один сценарий, который принимает входную папку, выходную папку и количество тем. Сценарий будет считывать все отсканированные изображения документов во входной папке, записывать их в файлы .txt, строить модель LDA для поиска тем высокого уровня в документах и организовывать выходные файлы . txt в папки на основе темы документа.
txt в папки на основе темы документа.
Демонстрация
Чтобы доказать, что все вышеперечисленное не было просто длинной тарабарщиной, вот демонстрационное видео системы. Есть много вещей, которые можно улучшить (в первую очередь, отслеживать разрывы строк в отсканированных документах, обрабатывать специальные символы и другие языки, кроме английского, и отправлять запросы к API компьютерного зрения в пакетном режиме, а не по одному), но мы сами прочный фундамент, на котором можно строить улучшения. Для получения дополнительной информации ознакомьтесь с соответствующим репозиторием Github.
Спасибо за внимание!
Как сканировать документы с помощью оптического распознавания символов (OCR) | Услуги информационных технологий
Назначение статьи
В этом разделе вы узнаете, как использовать планшетный сканер и OmniPage для оцифровки
документ с помощью оптического распознавания символов (OCR) с печатного носителя и сохраните его
в редактируемом формате для последующего использования.
Необходимые материалы
Чтобы отсканировать документ, убедитесь, что у вас есть следующее:
- Компьютер
- Планшетный сканер
- Программное обеспечение OCR, такое как OmniPage
- Документ для сканирования
Шаги к разрешению
Важное примечание:
В этом руководстве основное внимание уделяется тому, как использовать сканер и программное обеспечение OCR, оно не касается как настроить и установить новый сканер. Пожалуйста, обратитесь к настройке/установке продукта руководства, прилагаемые к устройству, для получения дополнительной информации об этих шагах.
Большинство программ оптического распознавания символов имеют множество различных функций, которые можно использовать для оцифровки печатных материалов. документы в редактируемый текст. Эти направления представят один из методов достижения
эта цель.
документы в редактируемый текст. Эти направления представят один из методов достижения
эта цель.
- Запуск OmniPage
- На стартовой странице щелкните Сканировать документ .
- После того, как сканер прогреется, изображение предварительного просмотра документа будет отображаться, как показано на рисунке. на изображении ниже.
- Выберите параметр Черно-белое изображение или текст . Затем настройте область в окне так, чтобы был заключен весь нужный текст. Щелкните Сканировать.
- После сканирования страницы вам будет предложено выбрать Остановить загрузку страниц или Добавить больше страниц .
 Выберите вариант, наиболее подходящий для ваших нужд. Повторяйте шаги 4 и 5, пока
все страницы были отсканированы, затем нажмите Прекратить загрузку страниц .
Выберите вариант, наиболее подходящий для ваших нужд. Повторяйте шаги 4 и 5, пока
все страницы были отсканированы, затем нажмите Прекратить загрузку страниц . - Теперь OmniPage будет выполнять оптическое распознавание символов. Нажмите кнопку Automatic на панели инструментов.
- Корректор OCR отобразит любые слова, которые он не распознает, и отобразит их как Подозрительное слово . Если слово/объект допустимо, нажмите Игнорировать , иначе в поле Предложения выберите правильное слово и нажмите Изменить .
- После завершения OCR нажмите кнопку Сохранить в файлы и выберите Сохранить в файлы .
- В диалоговом окне Сохранить в файл выберите место назначения, в которое вы хотите сохранить файл (рабочий стол, флешка и т.д.) и выполните следующие действия:
- В поле Имя файла введите имя вашего файла.
- В разделе Сохранить как выберите Текст.
- В раскрывающемся окне Тип файлов выберите Microsoft Word 2007/2010 (*.docx).
- В разделе Уровень форматирования выберите Flowing Page
- В разделе «Параметры файла» выберите «Создать один файл для всех страниц».
- В разделе Диапазон страниц выберите Все страницы
- Нажмите “ОК”
 Двойной
щелкните файл, чтобы открыть его в Microsoft Word.
Двойной
щелкните файл, чтобы открыть его в Microsoft Word.Дополнительная информация
Точность
Распознавание латинского алфавита, машинописного текста все еще не является 100% точным даже там, где
доступно четкое изображение. Некоторые исследования показывают, что коммерческое программное обеспечение для оптического распознавания символов
от 71% до 98% точности. Важно отметить, что все документы OCR должны
быть проверены как на точность (правильные слова), так и на форматирование. Распознавание руки
печать, рукописный почерк и печатный текст другими шрифтами (особенно в некоторых
Символы восточноазиатского языка, которые имеют много штрихов для одного символа)
области, которые все еще активно разрабатываются издателями программного обеспечения OCR.