
Сканировать в текст
Ошибка: количество входящих данных превысило лимит в 3.
Чтобы продолжить, вам необходимо обновить свою учетную запись:
Ошибка: общий размер файла превысил лимит в 100 MB.
Чтобы продолжить, вам необходимо обновить свою учетную запись:
Ошибка: общий размер файла превысил абсолютный лимит в 8GB.
Для платных аккаунтов мы предлагаем:
Премиум-пользователь
- Вплоть до 8GB общего размера файла за один сеанс конвертирования
- 200 файлов на одно конвертирование
- Высокий приоритет и скорость конвертирования
- Полное отсутствие рекламы на странице
- Гарантированный возврат денег
Купить сейчас
Бесплатный пользователь
- До 100 Мб общего размера файла за один сеанс конвертирования
- 5 файлов на одно конвертирование
- Наличие объявлений
Мы не может загружать видео с Youtube.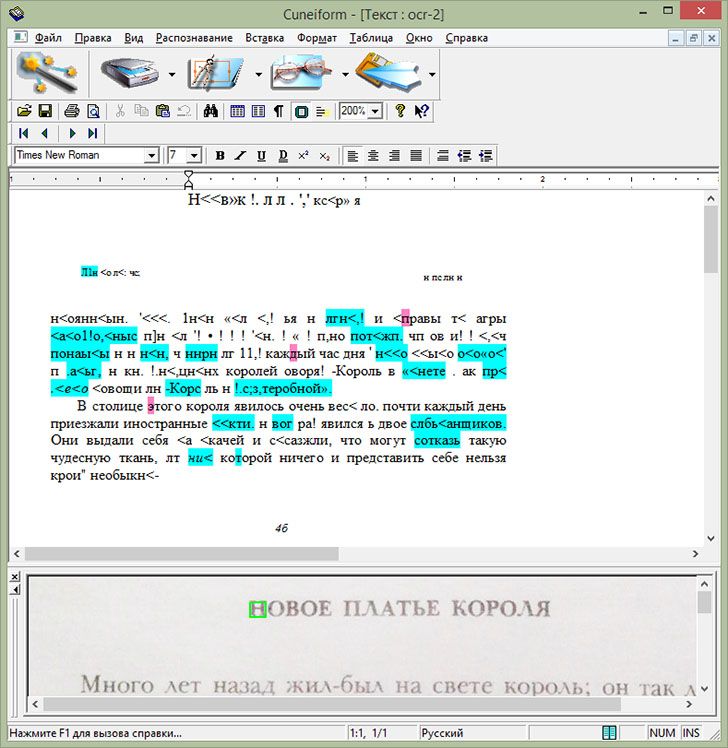
FineReader – распознавание текста. Microsoft Office
FineReader – распознавание текста
Ввести со сканера текст в компьютер – задача не слишком трудная. Однако работать с таким текстом невозможно: как и любое сканированное изображение, страница с текстом представляет собой графический файл – обычную картинку. Отсюда возникают проблемы: во-первых, в графическом формате страница занимает слишком много места, и, скажем, отсканированная книга не на каждый жесткий диск поместится. И вторая, самая главная проблема: сканированный текст можно будет только читать, но не редактировать и не вставлять его фрагменты в создаваемый вами документ. Ведь сам сканер распознавать буквы именно как буквы не умеет: они для него – всего лишь пятна и точки черного цвета.
К счастью, на свете существуют программы, способные перевести сканированный текст из графического в текстовый формат – программы распознавания текста или OCR.
Современная OCR должна уметь многое: распознавать тексты, набранные не только определенными шрифтами (именно так работали распознавалки первого поколения), но и самыми экзотическими, вплоть до рукописных.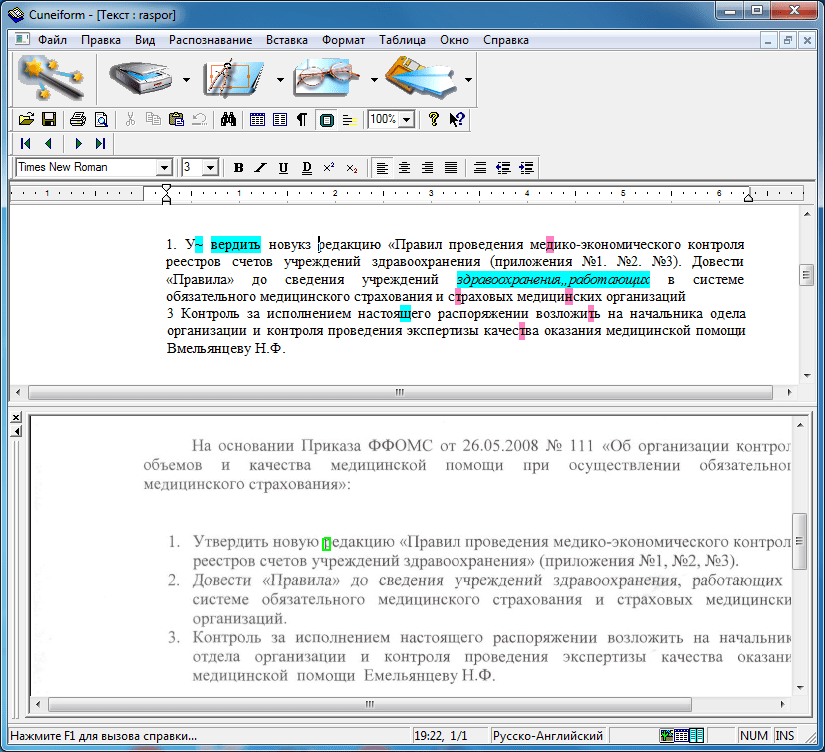
Как видим, для того чтобы получить электронную, готовую к редактированию копию любого печатного текста, программе OCR необходимо выполнить «цепочку» из множества отдельных операций:
Сканирование. За эту работу отвечает, собственно, не программа OCR, а встроенное в систему программное обеспечение вашего сканера. Именно с его помощью вы можете задать нужные вам параметры сканирования – например, разрешение (рекомендуется 300 dpi), цветовой режим (для простых текстов достаточно черно-белого или LineArt) – и выделить ту область документа, которую вам необходимо «скопировать» в компьютер.
Сегментация. Полученную со сканера «картинку» подхватывает OCR-программа. Но до распознавания еще далеко – сначала надо отделить текстовые элементы от графики, да и текст в ряде случаев разбить на отдельные куски (например, при многоколоночной верстке).
Распознавание. На этом этапе текст переводится из графической формы в обычную текстовую.
Проверка орфографии и правка. Встроенная система проверки орфографии «проходится» по тексту, проверяя и корректируя последствия работы системы распознавания. Спорные слова и символы выделяются особым предупреждающим цветом. Потом наступает очередь пользователя, который также может внести свою лепту в этот ответственный процесс.
Сохранение. Для дальнейшей обработки документ должен быть передан «на поруки» соответствующей программе – как правило, одному из продуктов семейства Microsoft Office. Или сохранен в формате, соответствующем его содержанию: текст – в DOC или RTF, таблица – в XLS. .. Да и встроенную графику желательно в документе оставить…
.. Да и встроенную графику желательно в документе оставить…
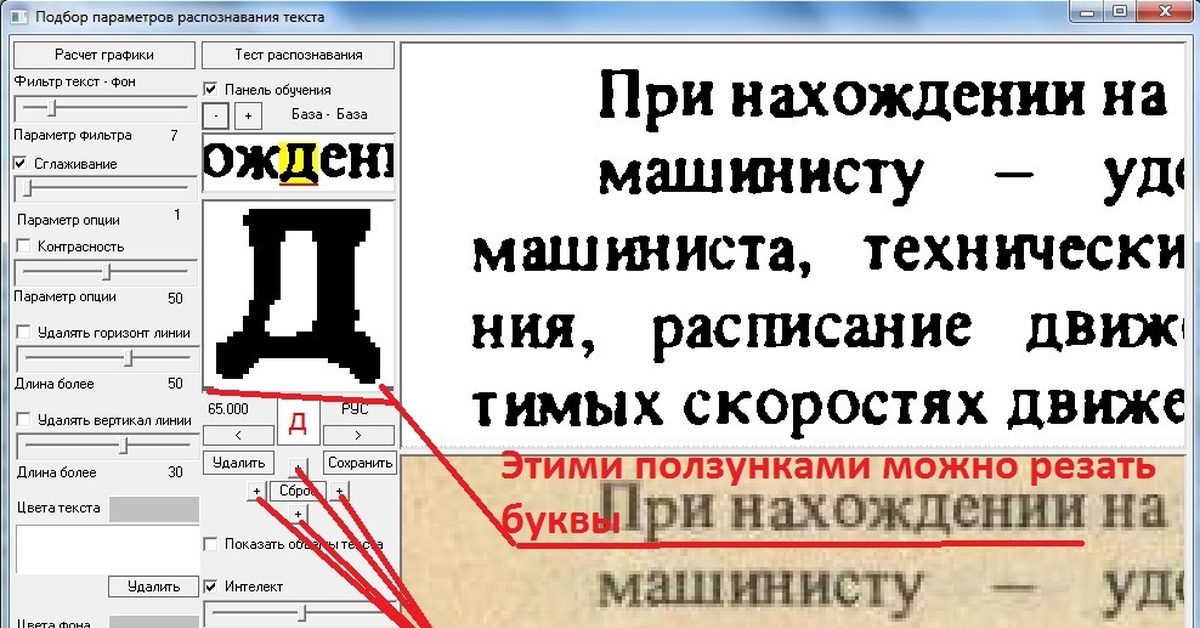
Все эти операции в большинстве программ OCR могут выполняться как в автоматическом, с помощью программы-мастера, так и в ручном режиме, по отдельности. С двумя первыми и последней операциями с легкостью справится любая программа распознавания. А вот весь процесс целиком по зубам, увы, только нескольким продуктам, разработанным в нашей стране. Тут надо сделать небольшую поправку: на самом деле корректно работать с русским языком умеют практически все современные «распознавалки», вне зависимости от того, где они были разработаны. Более того, в состав Microsoft Office-2003 уже включена абсолютно бесплатная программа распознавания Microsoft Office Document Scanning! Однако для российских пользователей само понятие «программа распознавания текста» чаще всего неразрывно связано с программой FineReader. Ибо компания ABBYY смогла не просто создать удобный для пользователя и качественный продукт, но и, самое главное, удачно «раскрутить» его.
Одним из козырей FineReader является поддержка неимоверного количества языков распознавания – 176, в числе которых вы найдете экзотические и древние языки, и даже популярные языки программирования (Basic, С/C++, COBOL, Fortran, Java, Pascal)! Так что FineReader сможет без запинки справиться с древнегреческим свитком или с бледными распечатками исходных текстов программ, сделанных вашими предками лет 30 назад. Как ни странно, большинство пользователей на деле интересуется совсем другим. Офисных работников интересует распознавание типовых форм документов, студентов – возможность быстро «передрать» для реферата многостраничный текст из учебника, сканируя и распознавая книжный разворот целиком, бухгалтеров – возможность автоматического распознавания таблиц и документов на бланках… Все это и многое другое FineReader умеет… или не все, а только частично, в зависимости от модификации продукта. Далеко не все возможности из нашего перечня включены в самую простую модификацию программы, которую вы можете получить бесплатно вместе со сканером.
После завершения распознавания страницы FineReader предложит пользователю выбор: сканировать и распознавать дальше (для многостраничного документа) или сохранить полученный текст в одном из множества популярных форматов – от документов Microsoft Office до HTML или PDF. Можно, впрочем, сразу же перебросить документ в Word или Excel и уже там исправить все огрехи распознавания (без них обойтись просто невозможно). При этом FineReader полностью сохраняет все особенности форматирования документов и графическое оформление.
Данный текст является ознакомительным фрагментом.
Продолжение на ЛитРесГлава 18 Система распознавания текста FineReader
Система
распознавания
одна из
наиболее
перспективных
областей
применения
искусственного
интеллекта. Существует
решение,
максимально
приближенное
к
человеческой
способности
читать: оно
построено на
принципах,
сформулированных
в результате
наблюдений
за
поведением
животных и человека.
Это
технология
целостного,
целенаправленного
и
адаптивного
восприятия.
Существует
решение,
максимально
приближенное
к
человеческой
способности
читать: оно
построено на
принципах,
сформулированных
в результате
наблюдений
за
поведением
животных и человека.
Это
технология
целостного,
целенаправленного
и
адаптивного
восприятия.
Процесс обработки FineReader осуществляется в несколько этапов:
1. Сканирование.
2. Выделение блоков на изображении.
3. Распознавание.
Затем нужно проверить ошибки и сохранить результат распознавания (передать его в другое приложение, например в текстовый редактор WORD, в Буфер и т.п.).
FineReader
это система
оптического
распознавания
текстов. Она
преобразует
полученное с
помощью
сканера
графическое
изображение (картинку)
в текст (то
есть в коды
букв, “понятные”
компьютеру). Основные
модификации
Standard, Professional,
Рукопись.
Основные
модификации
Standard, Professional,
Рукопись.
Функции, обеспечиваемые модификациями FineReader
| Функции | Standard | Professional | Рукопись |
| Типы распознаваемых текстов | Печатные |
Печатные, рукописные |
|
| Распознавание штрих-кода | нет | да | да |
| Возможность обучения новым символам | да | да | да |
Распознавание
многоколоночного
текста с
картинками
и таблицами. Сохранение
оформления
в формате RTF
Сохранение
оформления
в формате RTF |
да | да | да |
| Интернет: сохранение документа в формате HTML | да | да | да |
| Поддержка языков | |||
| Встроенная программа проверки орфографии | да | да | да |
| Распознавание многоязычных документов | да | да | да |
| Создание новых языков |
нет |
да | да |
| Распознавание таблиц | |||
| Распознавание таблиц, сохранение результатов в форматах RTF, CSV, XLS, DBF | да | да | да |
| Ручная и автоматическая сегментация таблиц | да | да | да |
| Пост-редактор распознанных таблиц | да | да | да |
В
библиотеках
следует,
конечно,
применять
профессиональные
версии
программ (это
замечание
касается
любых
программ).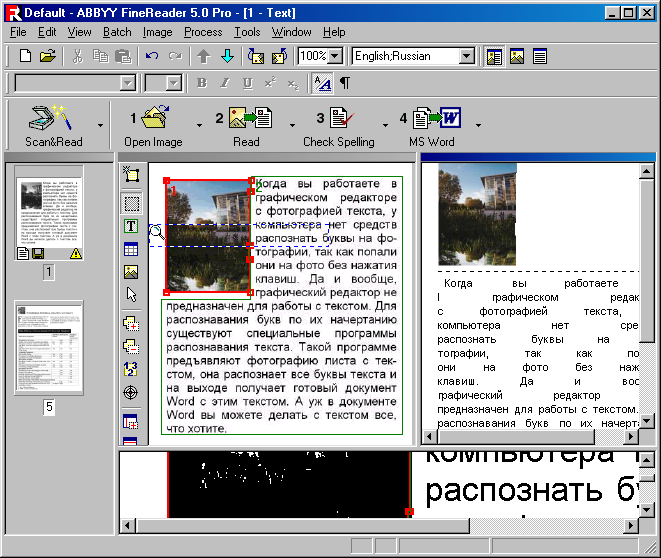 Если есть
возможность,
а главное
уровень
решаемых
задач, то
необходимо
приобретать
модификацию
Рукопись.
Если есть
возможность,
а главное
уровень
решаемых
задач, то
необходимо
приобретать
модификацию
Рукопись.
Библиотекарям приходится сканировать именно тексты, которые должны быть потом распознаны и превращены в текстовый файл. Если же сканер используется для выполнения платных услуг по сканированию и распознавание не требуется, то можно использовать программы, предназначенные только для сканирования и сохранения картинки.
Для большего комфорта работы необходимо, чтобы программа была связана с подключенным к ней сканером: меню Сервис Выбор сканера.
О планшетных сканерахНаиболее
универсальный
и наиболее
распространенный
тип сканера.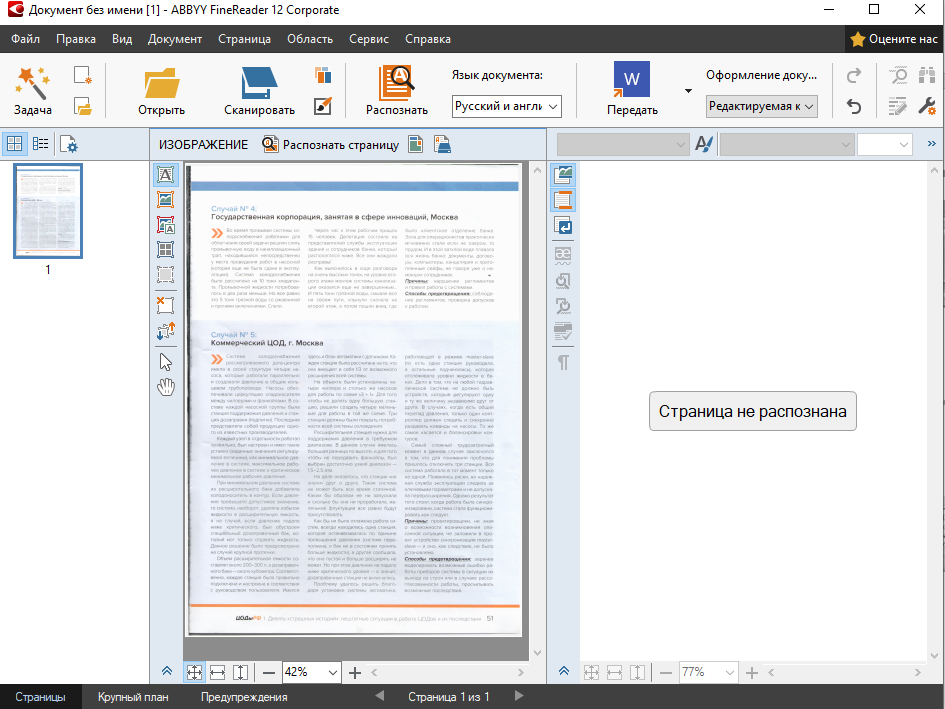 Как правило,
обеспечивает
высокое
разрешение
при средней и
высокой
скорости
сканирования.
Как правило,
обеспечивает
высокое
разрешение
при средней и
высокой
скорости
сканирования.
Планшетные сканеры делятся на две группы:
1. Для работы в офисе и дома.
Как правило, эти сканеры обладают максимальным оптическим разрешением 300 dpi, обычно достаточным для систем распознавания текстов и проведения простых работ по вводу фотографий для любительских фотоальбомов или дизайна страниц в Интернете. Они могут подключаться через параллельный порт, собственную ISA или PSI карту, или SCSI. Обычно имеют максимальную область сканирования A4.
2. Профессиональные сканеры.
Цветные.
Оптическое
разрешение 600 dpi
и выше. Имеют SCSI
интерфейс.
Зачастую
комплектуются
модулем для
сканирования
слайдов.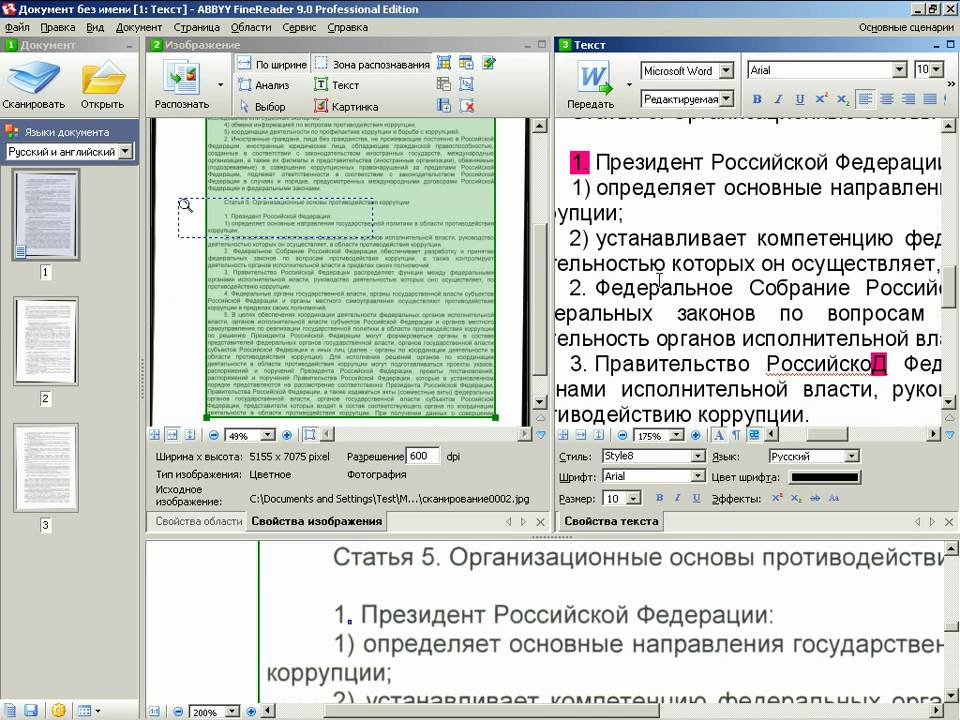 Область
сканирования
от Legal до A3.
Область
сканирования
от Legal до A3.
Некоторые модели сканеров могут дополнительно комплектоваться устройством автоматической подачи бумаги (Automat Document Feeder ADF). Как правило, они производятся только для моделей, имеющих либо SCSI, либо другой достаточно быстрый интерфейс с компьютером.
При выборе модели сканера необходимо обращать внимание на следующие моменты:
1. Если предполагается сканировать толстые книги, желательно, чтобы крышка сканера это позволяла не была жестко закреплена, а могла выдвигаться.
2. Если
сканер
снабжен
автоподатчиком,
необходимо
проследить,
как сканер и
его драйвер
обрабатывают
ситуацию
перекоса
бумаги в
лотке
автоподатчика. Сканер
должен
позволять
легко
разрешать
эту проблему.
Сканер
должен
позволять
легко
разрешать
эту проблему.
3. Следует обращать внимание на шум, производимый при сканировании. Некоторые дешевые сканеры довольно шумные, что может доставить массу неудобств при работе в офисе или дома.
О листовых сканерахПрименяются обычно в офисе или дома для сканирования отдельных листов. Однако существуют модели, у которых снимается нижняя часть, что позволяет сканировать книги и журналы, но при этом качество изображения, как правило, резко снижается. Из-за невысокой скорости и среднего качества изображения применяются при эпизодической работе.
До
недавнего
времени
листовые
сканеры
служили
дешевой
альтернативой
планшетным. Дополнительным
стимулом при
покупке
может
служить
экономное
использование
рабочего
пространства.
Существуют
модели для
сканирования
как черно-белых,
так и цветных
изображений.
Обычно
максимальная
область
сканирования
A 4.
Дополнительным
стимулом при
покупке
может
служить
экономное
использование
рабочего
пространства.
Существуют
модели для
сканирования
как черно-белых,
так и цветных
изображений.
Обычно
максимальная
область
сканирования
A 4.
При выборе данной модели сканера необходимо обращать внимание на следующие моменты:
1. Сканер должен легко “захватывать” бумагу из лотка.
2. Как сканер и его драйвер обрабатывают ситуацию перекоса бумаги в лотке. Сканер должен позволять легко разрешать эту проблему.
3. Часто
бывает
полезной
способность
TWAIN-драйвера
сканера
сканировать
в
автоматическом
режиме всю
стопку
документов,
вставленную
в лоток, а не
ждать
команды
после
сканирования
каждого
листа. Как
правило, эта
способность
связана с
другой не
менее важной
автоматическое
определение
того,
кончилась ли
бумага в
лотке.
Как
правило, эта
способность
связана с
другой не
менее важной
автоматическое
определение
того,
кончилась ли
бумага в
лотке.
Из-за невысокого качества получаемого изображения ручные сканеры применяются обычно дома. В отличие от других типов сканеров, позволяют получать хорошее изображение области около корешка книг в жестком переплете.
До недавнего времени они служили дешевой альтернативой планшетным сканерам.
Модели с мотором иногда позволяют достигать лучшего качества сканирования за счет более равномерного перемещения сканера.
Дополнительным
стимулом при
покупке
может
служить
экономное
использование
рабочего
пространства. Существуют
модели,
предназначенные
для
сканирования
черно-белых и
модели для
сканирования
цветных
изображений.
Обычно
максимальная
ширина
сканируемой
области 10 см.
Существуют
модели,
предназначенные
для
сканирования
черно-белых и
модели для
сканирования
цветных
изображений.
Обычно
максимальная
ширина
сканируемой
области 10 см.
При выборе модели сканера необходимо обращать внимание на следующие моменты:
1. Качество
отсканированного
изображения (лучше
всего
текста).
Качество
изображения
не должно
страдать при
более или
менее
равномерном
перемещении
сканера.
Обычно
запоминается
скорость
сканирования
на разных
этапах и
происходит
программная
компенсация
неизбежных
вертикальных
искажений.
Если драйвер
сканера не
умеет
компенсировать
вертикальные
искажения, то
получить
качественное
изображение
текста
практически
невозможно.
2. Проверьте, позволяет ли сканер указывать направление сканирования: слева направо, сверху вниз, справа налево.
3. Часто бывает полезной способность TWAIN-драйвера склеивать куски изображений. К сожалению, ею не всегда можно реально воспользоваться.
Некоторые общие советы на применение сканеров при вводе документов:1. Документация сканера и сопровождающего программного обеспечения должна быть на русском языке.
2. В документации должны быть указаны адреса центров технического обслуживания.
3. Сканер
должен иметь
в комплекте TWAIN-драйвер
совместимый
с той
операционной
системой, в
которой вы
будете его
использовать. Обычно на коробке
сканера при
этом
присутствует
логотип Twain-compliant
или Twain-compatible. Как
правило, все
современные
сканеры
имеют TWAIN-драйвер,
совместимый
с MS Windows’95, 98. Кроме
того, все
сканеры
подключаемые
через SCSI,
одинаково
успешно
работают в MS Windows’95,
98 и Windows NT 4.0.
Проблему
могут
составить
только
сканеры,
подключаемые
через
параллельный
порт или
специальные
карты, при
работе в MS Windows NT 4.0.
Обычно на коробке
сканера при
этом
присутствует
логотип Twain-compliant
или Twain-compatible. Как
правило, все
современные
сканеры
имеют TWAIN-драйвер,
совместимый
с MS Windows’95, 98. Кроме
того, все
сканеры
подключаемые
через SCSI,
одинаково
успешно
работают в MS Windows’95,
98 и Windows NT 4.0.
Проблему
могут
составить
только
сканеры,
подключаемые
через
параллельный
порт или
специальные
карты, при
работе в MS Windows NT 4.0.
4. Обратите
внимание на
диалог с
опциями
сканера,
который
возникает
перед
сканированием.
Желательно,
чтобы в этом
окне была
легко
доступна
опция выбора
типа
сканируемого
изображения (черно-белый,
серый,
цветной). В
идеале еще и
серый с 16
градациями (обычно
только с 256
градациями)
это позволит
включать
встроенный в
систему FineReader автоматический
подбор
яркости при
сканировании
в сером (обычно
серое
изображение
с 16 градациями
сканируется
быстрее за
счет
меньшего
объема
информации,
чем с 256
градациями). Возможность
работать с
серым
изображением
особенно
важна для
библиотек,
так как очень
часто
возникает
необходимость
сканирования
печатных
текстов
разного
качества (бумага,
шрифт и т.д.).
Возможность
работать с
серым
изображением
особенно
важна для
библиотек,
так как очень
часто
возникает
необходимость
сканирования
печатных
текстов
разного
качества (бумага,
шрифт и т.д.).
Окно программы
Окно программы FineReader имеет сложную структуру (оно разбито на несколько кадров, в которых отражаются результаты сканирования, страницы, которые необходимо распознать, результаты распознавания).
Нажмите кнопку с изображением сканера на панели инструментов (сканировать).
Вы
можете
добавлять
отсканированные
страницы в
пакет, по
умолчанию
создаваемый
при запуске
программы,
или открыть
другой пакет (нажмите
кнопку) и
записывать
отсканированные
страницы в
него.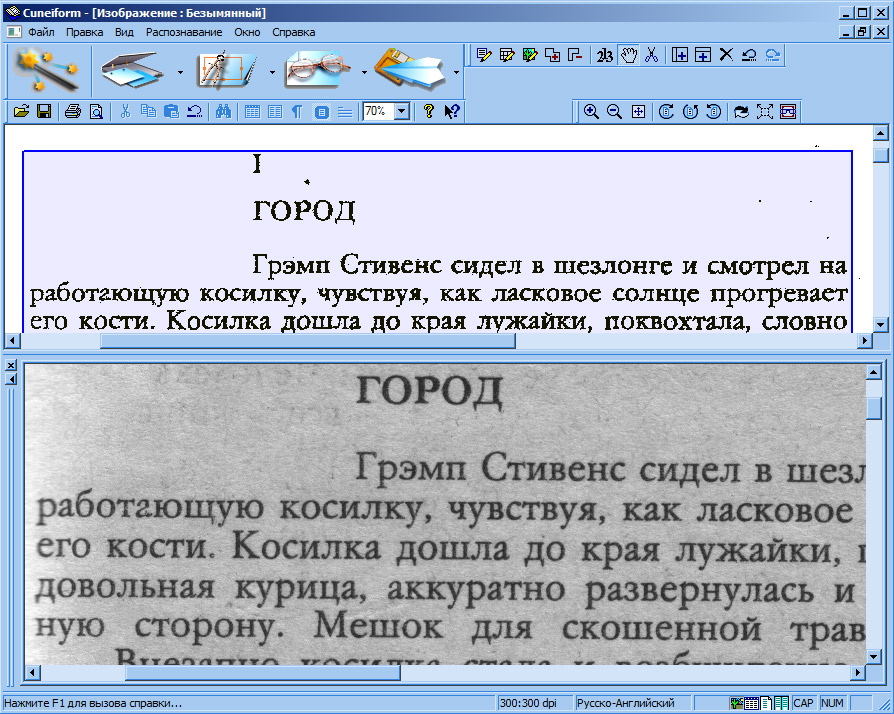
Нажмите стрелку справа от кнопки и из локального меню выберите пункт Сканировать и распознать.
Система отсканирует изображение, выделит на нем блоки, а затем распознает его.
Если у Вас отмечен пункт Открывать последний пакет (меню Сервис, пункт Опции…, закладка Установки), то при загрузке программа будет открывать последний пакет, с которым вы работали в предыдущей сессии.
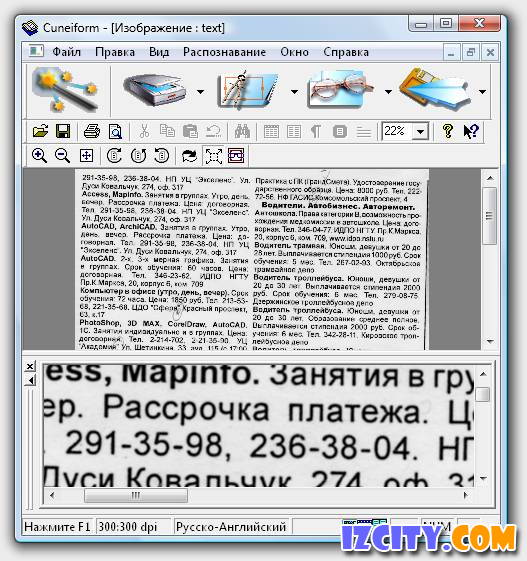
Параметры сканирования:
Яркость: для светлых документов необходимо уменьшить яркость (сделать их темнее), для темных увеличить (сделать их светлее).
Разрешение: 300 dpi для большинства документов; 400600 dpi для документов, набранных мелким шрифтом.
Выбор разрешения это регулировка яркости у всех типов изображения.
 Часто у черно-белых
изображений
регулировка
яркости
осуществляется
не выбором
яркости (brigthness), а
выбором
порога (threshold). Это
ничем не хуже,
однако, если
вы потом
отключите
опцию Показ
диалога TWAIN-драйвера, то
скорее всего
не сможете
регулировать
яркость.
Часто у черно-белых
изображений
регулировка
яркости
осуществляется
не выбором
яркости (brigthness), а
выбором
порога (threshold). Это
ничем не хуже,
однако, если
вы потом
отключите
опцию Показ
диалога TWAIN-драйвера, то
скорее всего
не сможете
регулировать
яркость.
| Особенности входного изображения | Что сделать |
| Светлые или тонкие буквы | Уменьшить яркость (сделать темнее) |
| Темные или толстые буквы | Увеличить яркость (сделать светлее) |
| Глянцевая бумага | Уменьшить яркость |
| Слипшиеся символы | Увеличить яркость |
| Разрывы | Уменьшить яркость |
| Смазанные или заполненные контуры букв | Увеличить яркость |
Обратите
внимание на
скорость
сканирования
в режиме
черно-белого
изображения
(300 dpi). Желательно,
чтобы это
время не
превышало 12
минуты.
Желательно,
чтобы это
время не
превышало 12
минуты.
Обратите внимание на скорость сканирования в режиме цветного изображения (300 dpi). Желательно, чтобы это время не превышало 56 минут. В некоторых дешевых моделях, подключаемых через параллельный порт, это время может достигать огромных значений.
Некоторые
TWAIN-драйверы
при запуске
сканирования
показывают
окно с
сообщением о
том, что идет
разогрев (Warming ) или
калибровка (Calibrating ). Как
правило, это
занимает
около минуты.
Иногда эта
операция
происходит
при каждом
запуске
сканирования,
даже если оно
идет
практически
непрерывно
или
сканируется
предварительное
изображение (Preview). Как
утверждают
разработчики
сканеров, это
необходимо
для более
корректной
цветопередачи. Желательно,
чтобы этого
режима не
было вообще
или чтобы он
был
отключаемым.
Желательно,
чтобы этого
режима не
было вообще
или чтобы он
был
отключаемым.
Повернуть изображение
Распознаваемое изображение должно иметь стандартную ориентацию: текст должен читаться сверху вниз и строки должны быть параллельны нижнему краю экрана.
Вы можете указать программе, чтобы она автоматически подбирала ориентацию страницы.
Если ориентация не подбирается автоматически, повернуть изображение можно вручную:
1. Выделите нужные изображения.
Выделить одну страницу Нажмите на нее мышью.
Выделить несколько страниц подряд Удерживая клавишу SHIFT, нажмите мышью на первую страницу выборки, а затем на последнюю.
2. Выделить несколько страниц не подряд
Удерживая клавишу CTRL, последовательно нажимайте на интересующие страницы.
Нажмите кнопку, с изображением направления, чтобы повернуть изображение на 90.
Из меню Изображение выберите пункт Повернуть на 180, чтобы перевернуть изображение вверх ногами.
Таким же образом можно повернуть активное открытое изображение.
Распознавание
Установка языка распознавания и типа текста:
Язык распознавания и тип текста являются главными параметрами распознавания.
Языки, которые имеют словарную поддержку: английский, голландский, датский, испанский, итальянский, немецкий, норвежский, польский, португальский, русский, украинский, финский французский, шведский.
При распознавании текста на том или ином языке выберите нужный язык из списка на панели Распознавание.
Если нужного языка нет в списке, то выберите значение Другой… и в открывшемся списке найдите нужный язык или выберите несколько языков, слова которых встречаются в распознаваемом тексте.
Тип текста определяется в системе автоматически. Однако для распознавания текстов, напечатанных на пишущей машинке или матричном принтере в черновом режиме, чтобы повысить надежность и скорость распознавания, выберите соответствующее значение в списке на панели инструментов.
Если вы распознавали тексты, напечатанные на пишущей машинке или матричном принтере, то при возвращении к типографскому тексту не забудьте снова выбрать значение Авто.
Открытие изображения:
-
Меню Файл Открыть.
-
Выберите диск и папку, где находятся нужные файлы.
-
Выберите нужные файлы и нажмите OK.
-
Выбранные файлы копируются в текущий пакет.
-
Вы можете указать, чтобы выбранные изображения не копировались, а перемещались в пакет (отметьте пункт Перемещать файлы в пакет).
Тогда при загрузке в текущий пакет выбранные файлы будут копироваться туда, где находится ваш пакет и удаляться оттуда.
Также можно добавлять изображения из буфера или через drag-&-drop.
Запуск распознавания:
-
Выделите нужные страницы в окне пакета. Подведите курсор и щелкните 1 раз левой кнопкой мыши.
-
Нажмите кнопку Распознать открытую страницу. Активизируйте открытое изображение и нажмите кнопку Распознать.
Распознать все нераспознанные страницы:
-
Нажмите стрелку справа от кнопки Распознать и из открывшегося меню выберите пункт Распознать все нераспознанные страницы.
-
Программа выделяет блоки (если они еще не выделены) и распознает изображения.
Установить расположение текста на странице:
Программа FineReader автоматически определяет раскладку текста на странице. Для книг, газет, факсов, отчетов и т.п. подходит положение Автоматическое определение. И только в редких случаях, например при распознавании оглавлений и листингов программ, нужно специально указывать программе, что текст напечатан в одну колонку.
1. Меню Сервис Опции
2. В диалоге Опции выберите закладку Сегментация.
3. В группе Число колонок выберите пункт Одна колонка (для текста, напечатанного в одну колонку с большими промежутками между словами) или Автоматическое определение.
Сохранить результаты распознавания в файл:
1. Если Вы хотите сохранить не все страницы пакета, то выделите нужные в окне Пакет.
2. Нажмите стрелку справа от кнопки Сохранить и в открывшемся меню выберите пункт Сохранить в файл.
3. В открывшемся диалоговом окне выберите диск, каталог и укажите имя и расширение файла, в который хотите экспортировать распознанный текст.
4. Установите переключатель Какие страницы сохранять в положение Все распознанные или Только выделенные.
5. Чтобы записывать каждую страницу в отдельный файл, отметьте пункт Записывать каждую страницу в отдельный файл. Тогда имена, которые эти файлы получат, будут состоять из заданного имени и порядкового номера (1, 2, и т.д.).
6. Нажмите OK.
Вы можете передать результаты распознавания в одно из следующих приложений: MS Word, MS Excel, Corel WordPerfect, Lotus Word Pro или PROMT:
1. Активизируйте окно пакета (нажмите в нем мышью) и нажмите стрелку справа от кнопки Сохранить.
2. В открывшемся меню выберите пункт Передать в Word, Передать в Excel и т.п.
Для выделенных страниц:
1. Если вы хотите передать в другое приложение не все страницы, а только некоторые, то выделите нужные страницы в окне Пакет.
2. Нажмите на стрелку справа от кнопки Сохранить и выберите пункт Мастер сохранения результатов.
3. В открывшемся списке выберите нужное приложение и отметьте пункт Сохранять только выделенные страницы. По нажатию Готово в этом диалоге результаты распознавания передаются в выбранное приложение.
Назад
Проверьте свои знания
Оптическое распознавание символов – это… Что такое Оптическое распознавание символов?
Оптическое распознавание символов (англ. optical character recognition, OCR) — механический или электронный перевод изображений рукописного, машинописного или печатного текста в текстовые данные — последовательность кодов, использующихся для представления символов в компьютере (например, в текстовом редакторе). Распознавание широко используется для конвертации книг и документов в электронный вид, для автоматизации систем учёта в бизнесе или для публикации текста на веб-странице. Оптическое распознавание текста позволяет редактировать текст, осуществлять поиск слова или фразы, хранить его в более компактной форме, демонстрировать или распечатывать материал, не теряя качества, анализировать информацию, а также применять к тексту электронный перевод, форматирование или преобразование в речь. Оптическое распознавание текста является исследуемой проблемой в областях распознавания образов, искусственного интеллекта и компьютерного зрения.
Системы оптического распознавания текста требуют калибровки для работы с конкретным шрифтом; в ранних версиях для программирования было необходимо изображение каждого символа, программа одновременно могла работать только с одним шрифтом. В настоящее время больше всего распространены так называемые «интеллектуальные» системы, с высокой степенью точности распознающие большинство шрифтов. Некоторые системы оптического распознавания текста способны восстанавливать исходное форматирование текста, включая изображения, колонки и другие нетекстовые компоненты.
История
В 1929 году Густав Таушек (Gustav Tauschek) получил патент на метод оптического распознавания текста в Германии, после чего за ним последовал Гендель (Paul W. Handel), получив патент на свой метод в США в 1933. В 1935 году Таушек также получил патент США на свой метод. Машина Таушека представляла собой механическое устройство, которое использовало шаблоны и фотодетектор.
В 1950 году Дэвид Х. Шепард (David H. Shepard), криптоаналитик из агентства безопасности вооружённых сил Соединённых Штатов, проанализировав задачу преобразования печатных сообщений в машинный язык для обработки компьютером, построил машину, решающую данную задачу. После того как он получил патент США, он сообщил об этом в «Вашингтон Дэйли Ньюз» (27 апреля 1951) и в «Нью-Йорк Таймс» (26 декабря 1953). Затем Шепард основал компанию, разрабатывающую интеллектуальные машины, которая вскоре выпустила первые в мире коммерческие системы оптического распознавания символов.
Первая коммерческая система была установлена на «Ридерс Дайджест» в 1955 году. Вторая система была продана компании «Стандарт Ойл» для чтения кредитных карт для работы с чеками. Другие системы, поставляемые компанией Шепарда, были проданы в конце 1950-х годов, в том числе сканер страниц для национальных воздушных сил США, предназначенный для чтения и передачи по телетайпу машинописных сообщений. IBM позже получила лицензию на использование патентов Шепарда.
Примерно в 1965 году «Ридерс Дайджест» и «Ар-Си-Эй» начали сотрудничество с целью создать машину для чтения документов, использующую оптическое распознавание текста, предназначенную для оцифровки серийных номеров купонов «Ридерс Дайджест», вернувшихся из рекламных объявлений. Для печати на документах барабанным принтером «Ар-Си-Эй» был использован специальный шрифт OCR-A. Машина для чтения документов работала непосредственно с компьютером RCA 301 (одна из первых полупроводниковых ЭВМ). Скорость работы машины была 1500 документов в минуту: она проверяла каждый документ, исключая те, которые она не смогла обработать правильно.
Почтовая служба Соединённых Штатов с 1965 года для сортировки почты использует машины, работающие по принципу оптического распознавания текста, созданные на основе технологий, разработанных исследователем Яковом Рабиновым. В Европе первой организацией, использующей машины с оптическим распознаванием текста, был британский почтамт. Почта Канады использует системы оптического распознавания символов с 1971 года. На первом этапе в центре сортировки системы оптического распознавания символов считывают имя и адрес получателя и печатают на конверте штрих-код. Он наносится специальными чернилами, которые отчётливо видимы в ультрафиолетовом свете. Это делается, чтобы избежать путаницы с полем адреса, заполненным человеком, которое может быть в любом месте на конверте.
В 1974 году Рэй Курцвейл создал компанию «Курцвейл Компьютер Продактс», и начал работать над развитием первой системы оптического распознавания символов, способной распознать текст, напечатанный любым шрифтом. Курцвейл считал, что лучшее применение этой технологии — создание машины чтения для слепых, которая позволила бы слепым людям иметь компьютер, умеющий читать текст вслух. Данное устройство требовало изобретения сразу двух технологий — ПЗС планшетного сканера и синтезатора, преобразующего текст в речь. Конечный продукт был представлен 13 января 1976 во время пресс-конференции, возглавляемой Курцвейлом и руководителями национальной федерации слепых.
В 1978 году компания «Курцвейл Компьютер Продактс» начала продажи коммерческой версии компьютерной программы оптического распознавания символов. Два года спустя Курцвейл продал свою компанию корпорации «Ксерокс», которая была заинтересована в дальнейшей коммерциализации систем распознавания текста. «Курцвейл Компьютер Продактс» стала дочерней компанией «Ксерокс», известной как «Скансофт».
Первой коммерчески успешной программой, распознающей кириллицу, была программа «AutoR» российской компании «ОКРУС». Программа начала распространяться в 1992 году, работала под управлением операционной системы DOS и обеспечивала приемлемое по скорости и качеству распознавание даже на персональных компьютерах IBM PC/XT с процессором Intel 8088 при тактовой частоте 4.77 МГц. В начале 90-х компания Hewlett-Packard поставляла свои сканеры на российский рынок в комплекте с программой «AutoR». Алгоритм «AutoR» был компактный, быстрый и в полной мере «интеллектуальный», то есть по-настоящему шрифтонезависимый. Этот алгоритм разработали и испытали ещё в конце 60-х два молодых биофизика, выпускники МФТИ — Г. М. Зенкин и А. П. Петров. Свой метод распознавания они опубликовали в журнале «Биофизика» в номере 12, вып.3 за 1967 год. В настоящее время алгоритм Зенкина-Петрова применяется в нескольких прикладных системах решающих задачу распознавания графических символов.
Текущее состояние технологии оптического распознавания текста
Точное распознавание латинских символов в печатном тексте в настоящее время возможно только если доступны чёткие изображения, такие как сканированные печатные документы. Точность при такой постановке задачи превышает 99%, абсолютная точность может быть достигнута только путем последующего редактирования человеком. Проблемы распознавания рукописного «печатного» и стандартного рукописного текста, а также печатных текстов других форматов (особенно с очень большим числом символов) в настоящее время являются предметом активных исследований.
Точность работы методов может быть измерена несколькими способами и поэтому может сильно варьироваться. К примеру, если встречается специализированное слово, не используемое для соответствующего программного обеспечения, при поиске несуществующих слов, ошибка может увеличиться.
Распознавание символов он-лайн иногда путают с оптическим распознаванием символов. Последний — это офф-лайн метод, работающий со статической формой представления текста, в то время как он-лайн распознавание символов учитывает движения во время письма. Например, в он-лайн распознавании, использующем PenPoint OS или планшетный ПК, можно определить, с какой стороны пишется строка: справа налево или слева направо.
Он-лайн системы для распознавания рукописного текста «на лету» в последнее время стали широко известны в качестве коммерческих продуктов. Алгоритмы таких устройств используют тот факт, что порядок, скорость и направление отдельных участков линий ввода известны. Кроме того, пользователь научится использовать только конкретные формы письма. Эти методы не могут быть использованы в программном обеспечении, которое использует сканированные бумажные документы, поэтому проблема распознавания рукописного «печатного» текста по-прежнему остается открытой. На изображениях с рукописным «печатным» текстом без артефактов может быть достигнута точность в 80 % — 90 %, но с такой точностью изображение будет преобразовано с десятками ошибок на странице. Такая технология может быть полезна лишь в очень ограниченном числе приложений.
Ещё одной широко исследуемой проблемой является распознавание рукописного текста. На данный момент достигнутая точность даже ниже, чем для рукописного «печатного» текста. Более высокие показатели могут быть достигнуты только с использованием контекстной и грамматической информации. Например, в процессе распознания искать целые слова в словаре легче, чем пытаться проанализировать отдельные символы из текста. Знание грамматики языка может также помочь определить, является ли слово глаголом или существительным. Формы отдельных рукописных символов иногда могут не содержать достаточно информации, чтобы точно (более 98 %) распознать весь рукописный текст.
Для решения более сложных проблем в сфере распознавания используются как правило интеллектуальные системы распознавания, такие как искусственные нейронные сети.
Программы распознавания
| Название | Лицензия | Операционные системы | Заметки |
|---|---|---|---|
| ExperVision TypeReader & RTK | Коммерческая [уточнить] | Windows, Mac OS X, Unix, Linux, OS/2 | Получала высокие оценки в начале 1990-х. |
| ABBYY FineReader | Коммерческая собственническая | Windows; Linux, Mac OS (не для конечного потребителя) | Для работы с различными языками требуется поддержка соответствующего языка. |
| OmniPage | Коммерческая (Nuance EULA) [уточнить] | Windows, Mac OS | Производство Nuance Communications |
| Readiris | Коммерческая [уточнить] | Windows, Mac OS | Производство бельгийской I.R.I.S. Group. Содержит региональные пакеты для распознавания азиатских языков и языков среднего востока. |
| Persian Reader | Коммерческая [уточнить] | Windows | Специализируется на персидском языке (фарси). |
| Kirtas Technologies Arabic OCR | Коммерческая | Windows | Может распознавать арабские и английские символы на одной странице. |
| Zonal OCR | Коммерческая [уточнить] | Windows | Zonal OCR помогает автоматизировать извлечение данных из компьютерных изображений. |
| ViewWise компании Computhink | Коммерческая [уточнить] | Windows | Система управления документами |
| CuneiForm | BSD | Windows (с GUI), Linux, Mac OS, FreeBSD (CLI) | Промышленная многоязычная система, умеет сохранять форматирование текста и распознаёт запутанные таблицы произвольной структуры |
| GOCR | GPL | Кросс-платформенная | В начальной стадии разработки |
| Microsoft Office Document Imaging | Коммерческая | Windows, Mac OS X | |
| Microsoft Office OneNote 2007 | Коммерческая | Windows | |
| NovoDynamics NovoVerus | Коммерческая | Windows | Специализируется на языках среднего востока |
| Ocrad | GPL | Unix-like, OS/2 | |
| Brainware | Коммерческая [уточнить] | Windows | Извлечение данных из документов и их обработка — например, счета, извещения, накладные и платёжки |
| HOCR | GPL | Linux | Распознавание текстов на иврите |
| OCRopus | Apache | Linux | Расширяемая система распознавания, которая может использовать Tesseract |
| ReadSoft | Коммерческая [уточнить] | Windows | Сканирование, распознавание и классификация деловых бумаг, например, договоров, счетов и платёжных поручений. |
| RelayFax Network Fax Manager компании Alt-N Technologies | Коммерческая [уточнить] | Windows | Многоязычная система, используется для преобразования факсов в доступные для правки форматы документов (doc, pdf и т. д.). |
| Scantron Cognition | Коммерческая [уточнить] | Windows | Для работы с различными языками требуется поддержка соответствующего языка. |
| SILVERCODERS OCR Server | Коммерческая [уточнить] | Linux | Серверная многоязычная система, имеет высокое качество распознавания, может сохранять форматирование текста и распознаёт запутанные таблицы произвольной структуры |
| SimpleOCR | Freeware и коммерческая версии | Windows | |
| SmartScore | Коммерческая [уточнить] | Windows, Mac OS | Для распознавания нотной записи |
| Tesseract | Apache | Windows, Mac OS X, Linux, OS/2 | Разрабатывается компанией Google |
| WeOCR | MIT/X Consortium | Интерфейс: Браузер; Сервер: POSIX, Unix | Платформа для браузерных систем распознавания символов. Страница проекта: WeOCR |
| FreeOCR | Apache | Интерфейс: Браузер; Сервер: POSIX, Unix | Платформа для браузерных систем распознавания символов. Использует Tesseract. Большое количество поддерживаемых языков. Страница проекта: FreeOCR |
| FineReaderOnline.ru | Коммерческая | Интерфейс: Браузер | Online OCR-сервис, позволяющий распознать многоязычный текст из отсканированного документа или фотографии. Конвертирует результат в редактируемые форматы (PDF, PDF/A, DOC, RTF, XLS, TXT). На данный момент до 10 страниц в день можно распознавать бесплатно. |
| OnlineOCR.ru | Коммерческая | Интерфейс: Браузер | Online OCR-сервис, позволяет распознать многоязычный текст из сканированного документа или фотографии. Конвертирует результат в редактируемые форматы (PDF, DOC, XLS, TXT, HTML) |
| NewOCR.com | Коммерческая | Интерфейс: Браузер | Online OCR-сервис, позволяет распознать многоязычный текст из сканированного документа или фотографии. Поддерживает 29 языков (болгарский, каталанский, чешский, датский, голландский, английский, финский, французский, немецкий, греческий, венгерский, индонезийский, итальянский, латышский, литовский, норвежский, польский, португальский, румынский, русский, сербский, словацкий, словенский, испанский, шведский, тагалог, турецкий, украинский, вьетнамский) и распознает текст, отформатированный в несколько колонок. |
| COCR2 | Бесплатная | Windows 9X, ME, 2000, XP | Программа для распознавания упрощенных и традиционных китайских иероглифов. Основное ограничение программы: для каждого иероглифа пользователь должен сам выбирать вариант его распознавания с помощью мыши или клавиатуры. Количество распознаваемых иероглифов довольно велико — более 10 000. |
| RasterID | Коммерческая | Windows 9X, ME, 2000, XP, Vista, Win7 | Программа, позволяющая сканировать и обрабатывать растровые изображения, а также автоматизировать регистрацию отсканированных изображений в электронном архиве или системе документооборота. Позволяет распознавать данные из штампа — основной надписи чертежей — и заносить их в базу данных. Страница разработчика: CSoft |
| LiveOCR | Бесплатная | Интерфейс: Браузер | Cервис оптического распознавания символов, позволяющий файлы форматов JPG, JPEG, BMP, PNG, GIF, содержащих текст, конвертировать в файлы формата RTF. |
| NSOCR | Коммерческая | Windows 9X, ME, 2000, XP, Vista, Win7 | Современная, развивающаяся система оптического распознавания текста. Разрабатывается компанией Nicomsoft. |
| pic2txt | Бесплатная | Интерфейс: Браузер | Система распознавания образов, в том числе текста |
См. также
Ссылки
OCR — технология распознавания сканированного текста, программы и онлайн инструменты
С развитием современных технологий в последние десятилетия 20 века произошла и модернизация доступа к печатному и рукописному тексту. Написанный текст был постепенно заменен печатным, который имеет по сравнению с текстом “на бумаге’ ряд неоспоримых преимуществ (простое редактирование и форматирование)
С распознаванием сканированного текста связано такое понятие, как OCR. OCR является аббревиатурой от английского “Optical Character Recognition” – оптическое распознавание символов. Речь может идти как о механическом, так и об электронном действии. В большинстве случаев, происходит сканирование документа, который затем анализируется компьютерной программой, которая производит распознавание сканированного текста, отдельных его символов и слов.
OCR– технология распознавания сканированного текста
Технология OCR нашла применение во многих сферах деятельности
Цель и смысл распознавания с помощью OCR сканированного текста заключается в быстрой и дешевой передаче печатного или рукописного содержимого в электронный файл. Важно отметить, что машинное распознавание текста в 20-25 раз быстрее, чем ручное переписывание. OCR можно также использовать для переноса таблиц с номерами в компьютер, что может стать очень эффективным инструментом в любой профессии.
OCR-приложение не может сканировать, однако, может распознавать символы и изображения сканированного текста, создавать обычный текст, который можно в дальнейшем обрабатывать. Оригинал документа на бумаге загружается с помощью сканера. Программа для оптического распознавания сканированного текста позволяет определить отдельные блоки (графики, текст, абзацы и так далее), с последующим распознаванием слов и букв.
Довольно часто случается так, что не все символы получается определить. Система OCR для распознавания сканированного текста использует языковые базы данных для сравнивания сканируемых слов. В случае сходства со словом в словаре, программа может исправить или добавить недостающие символы. В случае, если OCR не в состоянии распознать один символ в слове, это не значит, что слово будет помечено как неопознанное. Если это просто неизвестное слово, то оно вносится в словарь с дополнительной корректировкой.
Новые OCR-программы для распознавания сканированного текста оснащены дополнительными функциями для проверки орфографии (как в MS Word), что позволяет улучшить процесс распознавания
Технология распознавания OCR, как процесс оцифровки, используется как для обычных задач (проверка паспортов), так и при проверке регистрационных знаков транспортных средств. В основном, используется при оцифровке книг и текстов, например, для обеспечения возможности поиска или редактирования. Цифровой контент можно впоследствии редактировать, или же озвучить с помощью преобразования текста в голос. OCR часто используется для распознавания капчи (CAPCHA).
CAPTCHA, как правило, тип цифровой защиты форм, чтобы через них не передавались автоматически генерируемые данные. CAPTCHA представляет собой в основном рисунок, который отображает множество алфавитно-цифровых символов, которые пользователь должен ввести вручную. Многие CAPTCHA требуют от пользователя не только простого ввода данных с картинки, но и выполнения математических операция или манипуляций с объектами.
Современные OCR приложения распознавания сканированного текста могут распознавать даже рукописный текст – это актуально для сенсорных устройств, которые позволяют писать текст с помощью специального пера, а не клавиатуры.
Сам процесс распознавания сканированного текста проходит в три стадии: pre-processing (предварительная), само OCR распознавание, post-processing (последующая обработка).
При предварительной обработке целью является подготовить сканированный документ до наилучшего состояния – поворот, очистка от нежелательных точек и др. – так, чтобы последующий процесс распознавания текста был как можно более точным.
В ходе последующей обработки (post-processingu) текст проверяется согласно словарю для данного языка; автоматически, или при помощи пользователя, исправляются ошибки и неправильно распознанные символы.
Краткая история OCR распознавания текста
Вверху – шрифт OCR-A, внизу – OCR-B
Разработка OCR началась около 30 лет назад, тем не менее, эта технология распознавания текста достаточно неизвестная и мало распространенная. В гуманитарных областях, но и точных наук, в большинстве педагогических институтов, практически не используется. В самом начале технология оптического распознавания сканированного текста была связана с двумя крупными компаниями American Bankers Association и Financial Services Idustry, которые стремились к быстрой и качественной обработке финансовых документов, чеков, ценных бумаг. OCR технология была отличным решением, с течением времени, однако, была заменена на более динамичную технику MICR (Magnetic Ink Character Recognition).
В 1966 году в США произошла стандартизация так называемого шрифта OCR-A, который был первым шрифтом, позволяющим машинное чтение. Формы этого шрифта были упрощены, чтобы было само чтение как можно более точным, но шрифт не очень хорошо читается человеческим глазом. Шрифт OCR-A нашел применение в крупных банках. В Европе возникает вскоре после этого (1968) стандартный шрифт OCR-B и его автором был Адриан Фрутигер. Этот стандарт хуже читается машиной, но обеспечивает лучшую читаемость невооруженным глазом.
Первые OCR инструменты распознавания текста были очень медленными, и не давали требуемой точности. В основном, они ограничивались распознаванием специальных шрифтов OCR-A и OCR-B, со временем, однако, произошел их огромный бум. В 90-х годах произошло улучшение этой технологии. Увеличение производительности OCR значительно снизило цены на сканеры, технология стала легко доступной.
OCR программы и онлайн сервисы для распознавания текста
Для OCR распознавания сканированного текста можно использовать несколько различных инструментов. Вы можете воспользоваться как интернет приложениями, так и полноценными программами.
За качество надо платить. Попробовать trial-версии платных OCR программ для распознавания текста уже не так просто, как когда-то – их производители уже дали свой ответ на высокий уровень пиратства своего программного обеспечения выходом модели 30-дневных версий своего продукта, которые выполняют свою работу с ограниченными возможностями. К ним относятся два из лидеров на OCR рынке: OmniPage с поддержкой 123 языков, и Readiris с поддержкой ста двадцати языковых наборов. Одним из немногих приложений, которые в последней версии вы можете попробовать на собственной шкуре, ABBYY Fine Reader.
- FreeOCR. Хотя есть много онлайн инструментов для OCR распознавания текста, лучшим решением всегда остаются прикладные программы. Как вариант, можно попробовать воспользоваться бесплатным приложением FreeOCR. Оно не только приносит полновесные варианты распознавания, сохраняя структуру текста, но и поддерживает широкий спектр входных и выходных форматов.
- TopOCR – OCR программа распознавания текста из фотографий и других документов. Программа, которая может отлично распознавать текст с картинки или фотографии, и конвертировать его в читаемый вид. В результате текст можно конвертировать в другие форматы и редактировать. Текст можно конвертировать в форматы TXT, PDF, RTF и HTML.
- ABBYY FineReader. FineReader представляет собой настоящего профессионала и один из очень немногих действительно применимых решений при передаче фотографий, изображений или сканируемого текста. Его сила основана на действительно вдумчивой системе, которая стоит на трех основных столпах. OCR программа сначала разбивает изображение на области, в соответствии узнаваемых структур, те в свою очередь подразделяются на буквы и слова. После того, как текст разбивается на буквы, происходит их распознавание и сравнение целых слов со словарем. Затем выбирается наиболее подходящее решение. Еще один столп говорит о целесообразности, когда каждый текст имеет свой контекст, и на него нужно тоже обратить внимание. Последним и очень важным элементом является адаптация – OCR программа для распознавания текста должна уметь учиться с собственных действий.
Если вы не хотите устанавливать на компьютере программы, то можете использовать онлайн распознавание OCR.
OnlineOCR (www.onlineocr.net). Вероятно, лучший онлайн OCR конвертер, который вы можете встретить (хотя для раскрытия полного спектра функций вам необходимо бесплатно зарегистрироваться, иначе, вы будете ограничены количеством передаваемых документов, их размером и форматом). OnlineOCR поддерживает 32 языка. Сервис обладает отличной точностью распознавания текста и сохранения структуры документа.
NewOCR (www.newocr.com). NewOCR поддерживает 29 языков и анализ структуры текста. Истинное сохранение структуры, однако, не ждите, единственным результатом преобразования является только текст непосредственно в приложении, возможность прямого сохранения в DOC или RTF отсутствует – текст придется копировать вручную. В отличие от OnlineOCR, не нужно регистрироваться, ограничение на размер изображений установлено до 5 МБ. Фундаментальная проблема, однако, возникает при оценке точности транскрипции, тут онлайн распознавание OCR от NewOCR немного хромает.
Free OCR (www.free-ocr.com). Другим бесплатным и доступным онлайн OCR сервисом для распознавания текста является Free OCR. Позволяет конвертировать изображения до 2 МБ и одностраничные PDF, максимально 10 в час. Поддерживает 29 языков, наборов, без регистрации и приносит несравненно более высокую точность, чем предыдущий NewOCR. Структура текста, однако, также не сохраняется и позволяет экспортировать только чистый текст (без форматирования).
Бесплатное онлайн-распознавание текста – Часто задаваемые вопросы
Вы можете загружать любые файлы, содержащие текстовое изображение. Формат графического файла может быть любым из перечисленных ниже: TIF / TIFF (многостраничный TIFF), JPEG / JPG, BMP, PCX, PNG, GIF, PDF (многостраничный PDF) Единственное ограничение: размер файла не должен превышать 15 Мб в свободном доступе. гостевой режим и 200 мб для зарегистрированных пользователей. Для обеспечения хороших результатов распознавания разрешение изображения должно составлять 200 точек на дюйм или выше.
Вы можете загрузить более одного файла одновременно, поместив файлы в ZIP-архив (доступен только для зарегистрированного пользователя).
Если вам необходимо распознать изображение большего размера (более 200 Мб), обратитесь в службу поддержки.
Все документы, распознанные под учетной записью «Гость», автоматически удаляются после завершения процесса. Для зарегистрированных пользователей исходные документы и преобразованные файлы хранятся в списке документов пользователя один месяц
После успешного распознавания текста в документах пользователя появляются ссылки на вновь созданные файлы вывода.Вы можете открыть файл для просмотра или загрузить его на свой компьютер.
Да, это возможно. В параметрах распознавания установите флаг «Многостраничный документ», а в поле для диапазона страниц укажите необходимые страницы через запятую (или диапазон страниц через дефис). Например, «14,26», будут распознаны только 14-я и 26-я страницы. Или будут распознаны “4,9-12”, 4-я, 9-я, 10-я, 11-я и 12-я страницы.
Если в документе есть слова и предложения на разных языках, e.g., на английском и немецком языках, для достижения наиболее точного результата рекомендуется настроить необходимые языки при распознавании текста.
Да, если вы являетесь зарегистрированным пользователем, вы можете загрузить исходное изображение в своем рабочем пространстве.
Время распознавания текста зависит от множества факторов. Прежде всего, это качество изображения. Среднее время распознавания одного файла – несколько секунд.Второй важный фактор – текущая загруженность службы. Если запросы на распознавание поступают от разных пользователей одновременно, создается список ожидания.
Дополнительные страницы OnlineOCR.net можно приобрести в любое время, щелкнув ссылку «Купить страницы». Затем нажмите кнопку «КУПИТЬ», соответствующую количеству страниц, которые вы хотите купить. Все цены указаны в долларах США. OnlineOCR.net использует банковский сервис 2Checkout.com для обеспечения безопасных транзакций.После завершения транзакции вы вернетесь на страницу OnlineOCR.net с подтверждением вашего нового общего количества доступных страниц
Это может быть вызвано несколькими причинами.
1) Иногда возникает проблема со спам-фильтром. Пожалуйста, проверьте папку со спамом, поскольку она помогает в большинстве случаев. Это особенно актуально, когда у вас есть учетная запись электронной почты hotmail, yahoo или gmail.
2) Проверьте, правильно ли вы ввели электронное письмо.
Распознавание текста OCR | Продукция
Automotive
Идентификационные номера автомобилей (VIN) можно сканировать с помощью знакомого интеллектуального устройства на высокой скорости и даже с поврежденными или плохо освещенными кодами VIN в широком диапазоне расстояний и углов.
Подробнее
Healthcare
Фармацевтическая продукция, данные которой не закодированы в штрих-коде, например коды LOT или REF, сканируются с помощью OCR (оптического распознавания символов). Там, где есть штрих-код и текст, программное обеспечение Scandit обрабатывает и то, и другое одновременно.
Подробнее
Post, Parcel & Express
Если этикетка на посылке или пакете настолько повреждена при транспортировке, что штрих-код невозможно сканировать, программное обеспечение OCR (оптическое распознавание символов) может вместо этого прочитать сопроводительный текст. Программное обеспечение OCR интегрировано с SDK сканера штрих-кода для одновременного сканирования штрих-кодов и текста. Наше программное обеспечение сканирует несколько строк текста на многих этикетках за одно сканирование со смарт-устройства.
Узнать больше
Банковское дело
Сотрудники банка, используя знакомые интеллектуальные устройства, оснащенные программным обеспечением Scandit OCR, могут быстро сканировать любой буквенно-цифровой текст, такой как международные номера банковских счетов (IBAN) или номера документов / форм, в рабочие процессы.Клиенты мобильного банкинга могут использовать OCR для сканирования платежных реквизитов в мобильное приложение, избегая подверженного ошибкам ручного ввода важных чисел.
Узнать больше
Air Travel
Сотрудники авиакомпаний и аэропортов могут быстро сканировать машиночитаемые паспорта и удостоверения личности с помощью интеллектуального устройства, оснащенного программным обеспечением Scandit OCR. Например, сотрудники, обслуживающие пассажиров у выхода на посадку, не должны быть привязаны к дорогостоящим подиумам, а вместо этого могут использовать простые смартфоны или планшеты. А авиакомпании могут предложить пассажирам возможность сканировать собственные паспорта дома во время онлайн-регистрации.
Узнать больше
Розничная торговля
Как и в любой цепочке поставок, этикетки на упаковке в розничной торговле повреждаются при транспортировке, поэтому использование программного обеспечения OCR (оптического распознавания символов) для чтения сопроводительного текста вместо штрих-кодов может предотвратить дорогостоящие задержки доставки и отслеживания. Наше программное обеспечение сканирует несколько строк текста на многих этикетках за одно сканирование со смарт-устройства. OCR также используется для проверки личности лиц в цепочке поставок или клиентов, собирающих коллекции без правильного оформления документов.
Подробнее
Что такое OCR? Введение в оптическое распознавание символов
Оптическое распознавание символов (OCR) определяет процесс механического или электронного преобразования сканированных изображений рукописного, набранного или напечатанного текста в машинно-кодированный текст. Думайте об этом как о процессе преобразования аналоговых данных в цифровые.
Из этой вводной статьи вы узнаете о:
- Что такое технология OCR?
- Как работает оптическое распознавание символов?
Вам не нужно быть опытным разработчиком или техническим специалистом, чтобы узнать, что такое OCR, и понять, как оно работает.Здесь мы собираемся объяснить технологию с минимальным количеством технического жаргона.
Если вы уже знаете, что такое OCR, просто перейдите к разделу о том, как оно работает, или начните с примеров того, что вы можете делать с этой технологией.
Что такое OCR?
Поскольку OCR означает оптическое распознавание символов, технология OCR решает проблему распознавания всех видов различных символов. И рукописные, и печатные символы могут быть распознаны и преобразованы в машиночитаемый цифровой формат данных.
Придумайте любой серийный номер или код, состоящий из цифр и букв, которые вам нужно оцифровать. Используя OCR, вы можете преобразовать эти коды в цифровой выход. В этой технологии используется множество различных техник. Проще говоря, сделанное изображение обрабатывается, символы извлекаются, а затем распознаются.
OCR не учитывает фактическую природу объекта, который вы хотите сканировать. Он просто «смотрит» на персонажей, которых вы хотите преобразовать в цифровой формат.Например, если вы отсканируете слово, оно узнает и распознает буквы, но не значение слова.
Как работает оптическое распознавание символов?
Давайте рассмотрим три основных этапа оптического распознавания символов: предварительная обработка изображения; распознавание символов; и постобработка вывода.
Шаг 1. Предварительная обработка изображения в OCR
Программное обеспечениеOCR часто предварительно обрабатывает изображения, чтобы повысить шансы на успешное распознавание. Целью предварительной обработки изображения является улучшение фактических данных изображения.Таким образом подавляются нежелательные искажения и улучшаются определенные характеристики изображения. Эти два процесса важны для следующих шагов.
Шаг 2: Распознавание символов в OCR
Распознавание знаков номерных знаков
Для фактического распознавания символов важно понимать, что такое «извлечение признаков». Когда входные данные слишком велики для обработки, выбирается только сокращенный набор функций. Ожидается, что выбранные функции будут важными, в то время как те, которые предположительно являются избыточными, игнорируются.При использовании сокращенного набора данных вместо исходного большого, производительность увеличивается.
Для процесса OCR это важно, поскольку алгоритм должен обнаруживать определенные части или формы оцифрованного изображения или видеопотока.
Попробуйте наше демонстрационное приложение Узнайте больше о нашем сканере номерных знаковШаг 3. Постобработка в OCR
Постобработка – это еще один метод исправления ошибок, обеспечивающий высокую точность распознавания текста. Точность можно еще больше повысить, если ограничить вывод лексиконом.Таким образом, алгоритм может вернуться к списку слов, которые могут встречаться, например, в отсканированном документе.
OCR не только используется для определения правильных слов, но также может считывать числа и коды. Это полезно для идентификации длинных цепочек цифр и букв, например серийных номеров, используемых во многих отраслях промышленности.
Чтобы лучше справляться с различными типами входного OCR, некоторые поставщики начали разрабатывать специальные системы OCR. Эти системы могут работать со специальными изображениями, а для повышения точности распознавания, даже более того, они объединили различные методы оптимизации.
Например, они использовали бизнес-правила, стандартные выражения или обширную информацию, содержащуюся в цветном изображении. Эта стратегия объединения различных методов оптимизации называется «ориентированным на приложения» или «настраиваемым ОРС». Он используется в таких приложениях, как OCR для визитных карточек, OCR для счетов и OCR для идентификационных карт.
Примеры использования технологии OCR
Возможности использования программного обеспечения для оптического распознавания символов широко распространены, поскольку OCR можно комбинировать с широким спектром технологий.Вот несколько примеров возможных вариантов использования, включая программное обеспечение для оптического распознавания текста:
1. Процессы идентификации в OCR
Машиносчитываемая зона (МСЗ) в паспорте
Паспорта и удостоверения личности имеют машиночитаемую зону (МСЗ), которую можно сканировать. OCR может ускорить процесс идентификации и регистрации людей. Это полезно для сил безопасности на границах или других контрольно-пропускных пунктах. Его также можно использовать в коммерческих целях для увеличения взаимодействия с клиентами, например, для регистрации в отелях или для регистрации в банках и других компаниях.
Попробуйте наш сканер паспортов и удостоверений личности Узнайте больше о решениях для цифровой идентификации с высоким уровнем безопасности – Бесплатная электронная книга2. Маркетинговые кампании с OCR
Ведущие бренды используют OCR для проведения инновационных и увлекательных кампаний, направленных на привлечение клиентов. Подумайте обо всех кодах ваучера, которые клиенты могут погасить, введя их. Или о числах, напечатанных на внутренней стороне крышки от бутылки, которые вам нужно забрать.
Все эти кампании могут использовать OCR путем интеграции программного обеспечения, которое легко интегрируется в веб-сайты и приложения компании.Таким образом, они минимизируют препятствия при онлайн-регистрации и избавляют клиентов от необходимости вводить ряд цифр и букв.
Посмотрите, как PepsiCo использует OCR в одной из своих маркетинговых кампаний в Турции для сканирования кодов ваучеров внутри пакетов своих популярных чипов, таких как Lays, Ruffles и Doritos:
Маркетинговые кампании с OCR – PepsiCo Turkey
3. OCR в платежных процессах
IBAN Сканирование с OCR
Международный номер банковского счета (IBAN) служит для идентификации банковских счетов за границей.IBAN может быть разной длины и состоять из букв и цифр. Чтобы упростить международные транзакции, банковские приложения могут легко интегрировать программное обеспечение OCR. Таким образом, их клиенты могут сканировать свой IBAN вместо того, чтобы утомительно вводить его.
Попробуйте наш сканер IBAN Связаться с намиИнструменты оптического распознавания текста
Существует множество программ оптического распознавания текста, которые специализируются на одном конкретном сценарии использования, таком как сканирование кредитных карт или сканирование документов. Но OCR может быть полезно во многих сферах нашей жизни.Компаниям часто требуется сочетание решений OCR вместе, и поэтому лучше работать с поставщиками, которые могут выполнять несколько видов сканирования.
Подробнее о технологии оптического распознавания текста
Anyline OCR SDK и демонстрационные приложения
Технология мобильного сканированияAnyline доступна для интеграции в ваше мобильное приложение или веб-сайт в виде кроссплатформенного OCR SDK (комплект для разработки программного обеспечения). Протестируйте наши решения на Android, iOS, Windows и других платформах и устройствах уже сегодня.Приложение Anyline OCR для мобильного сканирования может быть легко интегрировано в любое приложение или на любой веб-сайт. Загрузите наш SDK OCR и получите бесплатную 30-дневную пробную версию, чтобы увидеть, как решения OCR и технология мобильного сканирования оптимизируют рабочие процессы и бизнес-процессы.
Наша демонстрация SDK для мобильного сканирования включает доступ ко всем следующим решениям оптического распознавания текста:
Anyline SDK предоставляет решения для мобильного сканирования с оптическим распознаванием текста для многих различных отраслей и широкого спектра различных сценариев использования.
Получите свое решение сегодня!
Исправление отсканированных документов | Технологии преподавания и обучения
Исправление для доступности более эффективно при запуске с цифровым документом.Идеальная ситуация – начать с исходного документа, который был сохранен в формате PDF надлежащим образом с функциями доступности, такими как теги и использование заголовков в качестве закладок. Если источником является отсканированный документ, который сохраняется / конвертируется в PDF, рабочий процесс значительно усложняется.
Как проверить доступность PDF-текста
Сначала определите, был ли документ PDF создан из цифрового текста или из отсканированного изображения текста. Отсканированное изображение текста недоступно, и к нему необходимо применить оптическое распознавание символов (OCR).Есть два процесса, чтобы указать, будет ли текст доступен для чтения с экрана: щелчок по документу или попытка выделить текст.
Вариант А. Щелкните документ
Часто самый простой способ проверить текст – это щелкнуть документ, чтобы увидеть, выделяется ли текст или вся страница. Открыв документ в Adobe Acrobat, щелкните в любом месте документа. Если выделяется вся страница, скорее всего, это отсканированное изображение. Если отображается курсор, документ PDF содержит текст.
Вариант Б. Попробуйте выделить текст
Альтернативный способ проверить текст в PDF-файле – попытаться выделить весь текст.В верхнем меню навигации Acrobat нажмите «Изменить», а затем «Выбрать все».
Выделенные текстовые элементы. Если текстовые элементы выделены, документ содержит текст. (См. Рисунок 1)
[Рис. 1] Снимок экрана документа в Adobe Acrobat под названием «Фокус на полевой эпидемиологии», на котором показаны выделенные текстовые элементы.Если «Выбрать все» неактивно. Если «Выбрать все» не активен (это происходит, если документ, представляющий собой изображение, уже выделен / выделен или если вы запустили определенный инструмент), нажмите «Редактировать», а затем нажмите «Редактировать текст и изображения»).Или, когда вы нажимаете «Выбрать все», появляется окно с предупреждением о сканированной странице, вы знаете, что документ не содержит текста. Окно предупреждения немедленно предложит вам решить, запускать ли распознавание текста. (Пример снимка экрана см. На Рисунке 2)
[Рис. 2] Скриншот окна Adobe Acrobat с документом в виде изображения, отсканированная версия документа под названием «Оценка достоверности и надежности диагностических и проверочных тестов». Вверху документа появляется окно «Предупреждение о сканированной странице», в котором указано: «Эта страница содержит только изображение.Хотите запустить распознавание текста, чтобы текст на этой странице стал доступным? »Пользователи могут выбрать« Да »или« Нет »для запуска программного обеспечения для распознавания текста.Как создать редактируемый текст в Adobe Acrobat
При создании редактируемого текста процесс начинается с запуска распознавания текста. Если вы проверили наличие текста и появилось окно «Предупреждение о сканированной странице», щелкните ссылку «Да», чтобы запустить распознавание текста.
Как запустить распознавание текста вручную
Чтобы вручную создать редактируемый текст, выполните одно из следующих действий:
- В меню Acrobat нажмите «Редактировать», а затем «Редактировать текст и изображения»
- Нажмите «Редактировать PDF» на панели инструментов (по умолчанию правая сторона экрана), и вам будет предложено начать распознавание текста.
Установить язык и параметры распознавания
Как только вы дадите разрешение, процесс распознавания текста, «Оптическое распознавание символов (OCR)» начнется немедленно.В зависимости от того, запускаете ли вы процесс из окна предупреждения или вручную, он может предложить вам использовать английский в качестве языка документа до или после завершения процесса распознавания текста.
Ручной процесс автоматически преобразует документ в редактируемый текст и изображения.
Если вы используете процесс через окно предупреждения, вы также можете выбрать, для каких страниц распознавать текст, параметры вывода и размер понижающей дискретизации.
- Использовать настройки по умолчанию для всех страниц
- Выберите подходящий язык
- Установить для вывода редактируемый текст и изображения
- Оставьте настройку Downsample To на значение по умолчанию, которое является максимальным значением
См. Рис. 3, где показан снимок экрана с окном предупреждения «Распознать текст».
[Рис. 3] Снимок экрана с окном «Распознать текст» и меню в Adobe Acrobat, которые позволяют пользователям выбирать свои настройки для инструмента оптимального распознавания символов. Пользователи могут выбрать «Все страницы», «Текущая страница» или установить выбор страницы (например, со страницы 1 на страницу 3). Меню «Настройки» содержит «Язык документа» и раскрывающееся меню для вывода инструмента, включая «Изображения с возможностью поиска», «Изображение с возможностью поиска (точное) и« Редактируемый текст и изображения »(выделено на снимке экрана).Кнопки «ОК» и «Отмена» переключают элементы управления в этом окне.Проверить точность и отредактировать текстовые ошибки
Если исходный материал представляет собой отсканированный документ (текст без возможности выбора), необходимо выполнить оптическое распознавание символов (OCR), чтобы преобразовать изображение в редактируемый текст. Adobe Acrobat отлично справляется с распознаванием текста в документе, но почти никогда не будет идеальным. Текст, который часто выглядит растянутым, не будет идентифицирован, а текст в изображениях, диаграммах и графиках часто неверен.
Варианты устранения проблем со сканированными документами
После завершения процесса оптического распознавания текста вам нужно будет просмотреть конечный продукт и исправить любые ошибки. Есть два варианта:
- Экспорт документа и повторное сохранение
- Использование инструмента чтения и редактирования Adobe Acrobat
Вариант 1. Экспорт в Microsoft Word, исправление ошибок и повторное сохранение в формате PDF
Этот параметр может быть самым простым способом исправить текстовые ошибки, особенно если отсканированный документ длинный или явно вызывает проблемы с распознаванием (например,g., размазанный текст, искривленные слова у внутреннего корешка книги и т. д.). Выполните следующие действия, чтобы экспортировать и повторно сохранить документ.
Шаг первый. Щелкните «Файл». Щелкните «Экспорт в». Щелкните «Microsoft Word». Нажмите “Документ Word”
Шаг второй. Выберите место для сохранения документа Word, затем нажмите «Сохранить».
Шаг третий. Откройте сохраненный текстовый документ (желательно с открытым PDF-файлом на другом экране монитора), затем визуально сравните документы и исправьте все ошибки.
Шаг четвертый. Сохраните документ Word как новый файл PDF.
- Office 2016 и более поздние версии. Щелкните «Файл», а затем «Сохранить как Adobe PDF». Нажмите «Параметры» и обязательно установите следующие флажки: «Включить специальные возможности и отображение с тегами Adobe PDF» и «Создать закладки», а затем нажмите «Преобразовать заголовки слов в закладки». Нажмите «ОК», а затем введите имя файла, которое позволит вам отличить исправленный файл от оригинала, а затем нажмите «Сохранить».«
- Office 2010 и 2013. Щелкните «Сохранить как», затем щелкните стрелку раскрывающегося списка рядом с параметром «Тип файла» и, наконец, щелкните «PDF». Щелкните «Параметры» и обязательно установите флажок «Теги структуры документа для обеспечения доступности». Нажмите «ОК», затем введите имя файла, которое позволит вам отличить измененный файл от оригинала, а затем нажмите «Сохранить».
Вариант 2. Используйте параметр Adobe Acrobat «Прочитать вслух и отредактировать»
Эта функция позволяет работать с PDF напрямую.Это может быть отличным решением для коротких документов с четким сканированием, но может быть сложно использовать для длинных документов или документов с большим количеством ошибок.
Шаг первый. В строке меню Acrobat нажмите «Просмотр», затем «Чтение вслух» и, наконец, «Активировать чтение вслух», чтобы включить программу чтения. (Пример снимка экрана см. На рис. 4)
Шаг второй. Вернитесь в «Просмотр» и выберите «Читать только эту страницу» или «Читать до конца документа». Использование того же «Просмотр» и затем щелчок по меню «Прочитать вслух» во время работы инструмента чтения вслух позволит вам приостановить / возобновить и остановить голос.
Шаг третий. Щелкните «Изменить». Нажмите «Редактировать текст и изображения» и используйте функции редактирования Adobe Acrobat, чтобы исправить любой ошибочный текст.
[Рисунок 4] Снимок экрана окна Adobe Acrobat с живым документом и двумя открытыми меню. Зеленая стрелка показывает пользователям, где нажать «Просмотр», чтобы открыть меню «Просмотр». Затем зеленая стрелка показывает пользователям, где нажать «Прочитать вслух» в меню «Просмотр», чтобы переключить пункты меню «Чтение вслух». И, наконец, зеленая стрелка указывает на «Активировать чтение вслух» – параметр, запускающий инструмент Adobe «Чтение вслух».Процесс редактирования текста Adobe Acrobat здесь не рассматривается, но поиск в Интернете может помочь.
Как я могу выполнить оптическое распознавание символов (OCR) в отсканированном документе? – Школа математики
Сначала отсканируйте изображение с помощью сканера (например, Xsane). Убедитесь, что изображение высококонтрастное и не содержит пятнышек, так как это запутает программу.
Настройки Xsane
– XSane-> Настройка-> Тип файла
Проверить:
Уменьшить 16-битное изображение до 8-битного
Установить:
TIFF zip коэффициент сжатия до 1
TIFF 16-битное сжатие изображения без сжатия
TIFF 8-битное сжатие изображения до нет сжатие
Линейное изображение в формате TIFF сжатие без сжатия
Есть несколько вариантов использования Tesseract с Xsane:
– Сканировать в *.tif, затем используйте tesseract в командной строке для OCR
tesseract inputimage.tif outputtext -l eng
– Сканируйте в PDF, затем используйте pdf2tif, затем tesseract.
pdf2tif filename.pdf (создает изображения в формате tif для каждой страницы)
– ocr.sh возьмет все файлы pdf в текущем каталоге и превратит их в txt.
Получите pdf2tif и ocr.sh с: http://www.groklaw.net/articlebasic.php?story=20061210115516438
окр.sh filename-01.tif
– Настройте Xsane-> Setup-> OCR для использования сценария tesseract xsane2tess (требуется каталог tmp в домашнем каталоге пользователя. Вы можете отредактировать сценарий, изменив TEMP_DIR на другое)
Команда OCR = xsane2tess -l eng
Параметр входного файла: -i
Параметр выходного файла: -o
Тессеракт с русским
tesseract <файл> .tif <выходной_файл> -l rus
————————————————- ————————————–
Как профессионально сканировать и распознавать текст с помощью инструментов с открытым исходным кодом
http://www.linux.com/feature/138511
ПРИМЕЧАНИЕ: для работы tesseract файл tiff, в котором он запущен, необходимо переименовать, чтобы он заканчивался на .tif (не .tiff), И это должно быть изображение без альфа-канала. Если вы переименовали файл, а тессеракт по-прежнему не работает, вероятно, проблема в этом.Используйте утилиту преобразования изображений с возможностью удаления альфа-каналов, чтобы повторно сохранить изображение. Для массового преобразования изображений я рекомендую Imagemagick (это gpl и хорошо работает на Mac).
, чтобы отобразить ваше изображение в формате TIFF, выполните:
tesseract inputimage.tif outputtext -l eng
, и вы должны получить файл с именем outputtext.txt.
Tesseract также может использовать библиотеку libtiff. (www.libtiff.org)
Без libtiff Tesseract может читать только несжатые и сжатые G3 файлы TIFF.
Этот код представляет собой необработанный механизм распознавания текста. У него НЕТ АНАЛИЗА РАЗМЕЩЕНИЯ СТРАНИЦЫ, НЕТ ФОРМАТИРОВАНИЯ ВЫХОДА
и НЕТ пользовательского интерфейса. Он может обрабатывать изображение только одного столбца и создавать из него текст. Он может обнаруживать фиксированный шаг по сравнению с пропорциональным текстом. Начиная с версии 2.0, Tesseract полностью поддерживает Unicode (UTF-8) и может распознавать 6
языков “из коробки”.
————————————————- ————————————————– ————-
Что такое оптическое распознавание символов? | Технология оптического распознавания символов
Что такое программное обеспечение технологии оптического распознавания символов (OCR)?
Технология оптического распознавания символов (OCR) – это бизнес-решение для автоматизации извлечения данных из печатного или письменного текста из отсканированного документа или файла изображения и последующего преобразования текста в машиночитаемую форму, которая будет использоваться для обработки данных, такой как редактирование или поиск.
Решения OCR улучшают доступность информации для пользователей
Распространенным применением технологии OCR является автоматическое преобразование изображений PDF, TIFF или JPG в машиночитаемый текстовый файл. Цифровые файлы, обработанные с помощью OCR, такие как квитанции, контракты, счета-фактуры, финансовые отчеты и т. Д., Могут быть:
- Выполнен поиск в большом репозитории, чтобы найти правильный документ
- Просмотрено, с возможностью поиска по каждому документу
- Отредактировано, когда необходимо внести исправления
- Перепрофилировано, извлеченный текст отправлен в другие системы
Как возможности автоматического распознавания текста для ввода данных помогают бизнес-операциям и рабочим процессам
Компании, которые используют возможности оптического распознавания текста для преобразования изображений и PDF-файлов (обычно создаваемых как отсканированные бумажные документы), экономят время и ресурсы, которые в противном случае были бы необходимы для управления данными, недоступными для поиска.После передачи текстовая информация, обработанная с помощью OCR, может быть использована предприятиями более легко и быстро.
Преимущества технологии OCR для предприятий:
- Устранение ручного ввода данных
- Экономия ресурсов за счет способности обрабатывать больше данных быстрее и с меньшим количеством ресурсов
- Снижение ошибок
- Перераспределение физического дискового пространства
- Повышение производительности
Ценность и широта решений для классификации и сбора данных
ВозможностиOCR, способность извлекать машинно-напечатанный текст из цифрового изображения, являются лишь одним аспектом решения для сбора данных.Данные могут быть извлечены из документов во многих различных форматах – напечатанный вручную текст (ICR), флажки (OMR), штрих-коды и т. Д.
Надежные решения для сбора данных обрабатывают документы различных форматов и могут использоваться как с электронными, так и с бумажными документами, устраняя необходимость в бумажных документах и сокращая ручную идентификацию и ввод данных содержимого документа в другие системы.
Используя технологию OCR в решении для сбора данных, предприятия могут:
- Снижение затрат
- Ускорение процессов
- Автоматизация маршрутизации документов и обработки контента
- Централизовать и защитить данные (отсутствие пожаров, взломов или потери документов в подсобных хранилищах)
- Повысьте качество обслуживания, предоставив сотрудникам самую свежую и точную информацию, когда она им нужна
Свяжитесь с нами, чтобы узнать больше о захвате данных и технологии распознавания текста.
Оптическое распознавание символов | Как OCR помогает при чтении? | Разобрался
Ответ:
Оптическое распознавание символов (OCR) играет важную роль в преобразовании печатных материалов в цифровые текстовые файлы. Эти цифровые файлы могут быть очень полезны детям и взрослым, которым трудно читать. Это связано с тем, что цифровой текст можно использовать с программами, поддерживающими чтение различными способами.
OCR был впервые представлен в 1990-х годах. Перенесемся в сегодняшний день, и вы обнаружите, что OCR встроено в программное обеспечение многих программ и устройств, включая некоторые компьютеры, планшеты, телефоны и принтеры.Многие из этих устройств могут автоматически преобразовывать отсканированный или сфотографированный документ в цифровой текст.
Но прежде чем мы углубимся в OCR, давайте поговорим немного о цифровом тексте.
Цифровой текст – один из нескольких форматов, которые делают печатную информацию доступной для большего числа людей. (Другие форматы включают аудио, крупный шрифт и шрифт Брайля.) Цифровой текст особенно полезен для читателей, испытывающих трудности, включая тех, кто имеет различия в обучении, такие как дислексия. Цифровой формат позволяет читателям видеть слова на экране и одновременно слышать их чтение вслух.Это дает больше способов взаимодействия с информацией. Это также может помочь детям развить навыки самостоятельного чтения.
Какая связь между напечатанным на бумаге, цифровым текстом и оптическим распознаванием текста? Один из способов преобразовать печатный материал в цифровой – использовать сканер. Сканер создает фотографию отпечатанного материала. Эту фотографию, часто называемую изображением, можно отобразить на устройстве с экраном.
Но сканирование – это только первый шаг. Фотография сама по себе не позволяет программам выделять слова или добавлять другие функции, которые могут помочь вашей дочери в чтении.Здесь на помощь приходит OCR.
OCR «смотрит» на фотографию (поэтому его название начинается с «оптического») и распознает формы различных букв, цифр и других символов. Он использует распознавание символов для преобразования фотографии документа в текстовый файл. Во многих случаях цифровая версия сохраняет «внешний вид» оригинала.
OCR позволяет вносить изменения в цифровой текст. Что можно сделать с цифровым текстом, зависит от того, какое программное обеспечение для чтения вы используете.Общие варианты включают:
Выделение слов, предложений или абзацев
Произнесение слов вслух, используя преобразование текста в речь
Изменение цветов и размера текста
Размещение цифровых «закладок», которые позволяют пользователям перемещаться по тексту (например, переход непосредственно от содержания к главе четвертой)
По сути, OCR позволяет вам вносить изменения в отсканированный документ и перемещаться с места на место внутри него – так же, как вы можете с любым текстовым документом на вашем компьютере.
Допустим, у вашей дочери есть лист с домашним заданием, который она с трудом читает. Вы можете отсканировать и преобразовать лист с домашним заданием в цифровой текст. Вы можете узнать, как это сделать, посмотрев обучающие материалы на YouTube. (Введите термин «оптическое распознавание символов» в поле поиска.) После преобразования листа в цифровой файл она сможет использовать инструменты на своем компьютере, чтобы помочь ей прочитать его.
Но прежде чем она нырнет, тебе нужно сделать еще кое-что. Внимательно просмотрите весь документ и исправьте все ошибки, которые могло быть допущено программой распознавания текста.Это может занять лота и усилий, если вы сканируете длинный документ. Но это важный шаг в процессе. Без такой проверки цифровой файл может оказаться не очень полезным для вашего ребенка.
Также неплохо узнать, создал ли кто-нибудь уже цифровую версию. Например, Bookshare и Learning Ally имеют большие библиотеки книг и других материалов, преобразованных в цифровые текстовые и / или аудиоформаты.