
Конвертировать изображение в Excel с распознанием текста
Конвертер изображений в Excel — это программа , которая позволяет пользователям обрабатывать данные изображений. Wondershare PDFelement – Редактор PDF-файлов — одна из лучших программ для конвертирования изображений в Excel, которая определенно заслуживает вашего внимания. Существуют различные методы преобразования изображений в лист Excel. Это очень важное умение, так как программа Excel широко используется в корпоративной среде. Если вы хотите научиться конвертировать изображения в Excel, советуем выбрать правильную программу, чтобы решить этот вопрос раз и навсегда.
Скачать Бесплатно Скачать Бесплатно КУПИТЬ СЕЙЧАС КУПИТЬ СЕЙЧАС
Конвертирование изображения в Excel с помощью PDFelement
Процесс преобразования изображения в Excel в PDFelement организован достаточно просто. Данная программа рекомендуется для выполнения этой задачи благодаря своей надежности и удобству. Ниже приведен список необходимых действий. Обратите внимание, что OCR (распознавание текста) — это основная функция, которую вам необходимо использовать.
Данная программа рекомендуется для выполнения этой задачи благодаря своей надежности и удобству. Ниже приведен список необходимых действий. Обратите внимание, что OCR (распознавание текста) — это основная функция, которую вам необходимо использовать.
Шаг 1. Откройте изображение
Чтобы открыть PDF-файл, запустите PDFelement и перетащите файл в окно программы. Также вы можете нажать кнопку «Создать PDF» для выбора файла изображения и открытия его в программе.
Шаг 2. Выполните распознавание текста
PDF-файл уже создан — он автоматически создается в программе после открытия изображения. Нажмите кнопку «Преобразовать» > «OCR», чтобы включить функцию распознавания текста. Выберите язык содержимого вашего изображения, и его текст станет редактируемым.
Шаг 3. Преобразуйте изображение в Excel
После завершения распознавания запустите процесс преобразования изображения в Excel, нажав кнопку «В Excel» во вкладке «Конвертировать». По завершении конвертирования вы сможете найти сконвертированный excel-файл в выбранной вами выходной папке.
Конвертирование изображений в Excel с помощью PDF Converter Pro
PDF Converter Pro — одна из лучших программ, которые можно использовать для конвертации PDF-файлов. Благодаря удобному интерфейсу даже начинающие пользователи с легкостью работают в программе. Настоятельно рекомендуется всем, кто не может найти подходящую программу для работы с PDF.
Шаг 1. Загрузка изображения для конвертирования
После открытия перейдите во вкладку «Создать PDF» и добавьте изображения, нажав кнопку «Добавить файлы» в нижней части экрана.
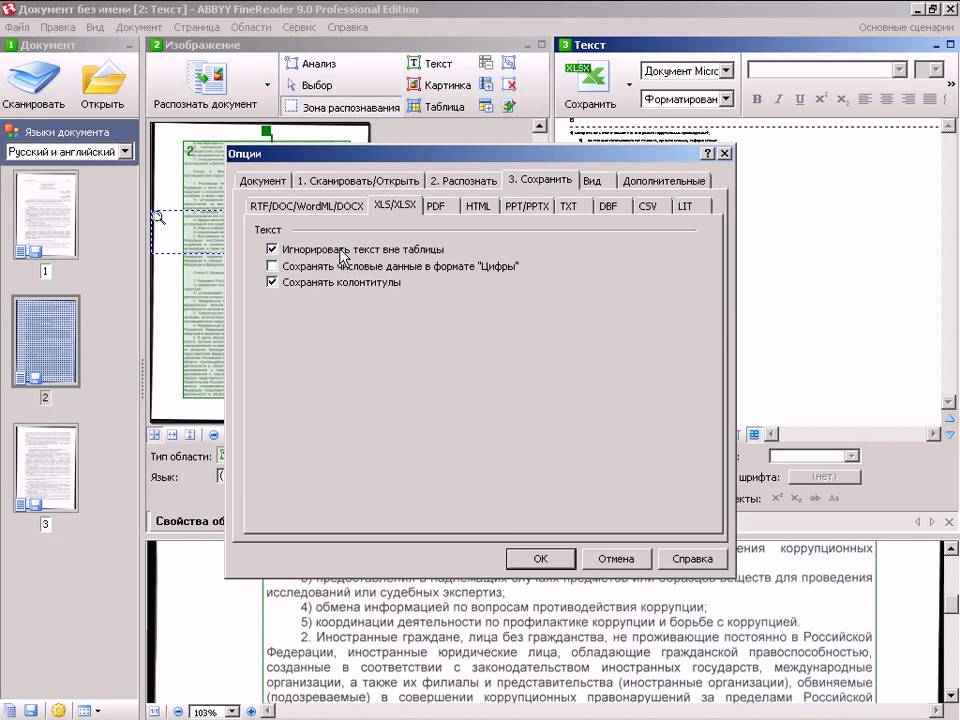
Шаг 2. Настройки распознавания текста изображения в Excel
Загрузите созданное PDF-изображение во вкладке «Конвертировать PDF». Нажмите кнопку «Дополнительные настройки» в правой части экрана. Откройте вкладку «OCR», выберите опцию распознавания текста, а затем выберите язык текста изображения из списка.
Шаг 3. Конвертирование изображения в таблицу Excel
Выберите Microsoft Excel в качестве выходного формата для преобразования. Нажмите кнопку «Конвертировать» как только все настройки будут установлены.
Нажмите кнопку «Конвертировать» как только все настройки будут установлены.
Лучший конвертер изображений в Excel — PDFelement
PDFelement — лучший выбор, если вы ищете удобную программу для работы с PDF. Важная особенность этой программы — интуитивно понятный интерфейс, который помогает пользователям преодолевать сложности, которые возникают при работе в других программах. Приложение позволяет свободно открывать и заполнять PDF-файлы, созданные на основе XFA. Работать с PDF-файлами еще не никогда не было так просто. Программа доступна на 9 разных языках, что существенно увеличивает ее охват. Выбрав PDFelement, вы не пожалеете.
Скачать Бесплатно Скачать Бесплатно
Мощная функция автоматического распознавания форм позволяет с легкостью обрабатывать формы.
Извлекайте данные легко, эффективно и точно с помощью функции извлечения данных из форм.
Преобразование стопок бумажных документов в цифровой формат с помощью функции распознавания текста для лучшего архивирования.
Редактируйте документы, не изменяя шрифты и форматирование.
Совершенно новый дизайн, позволяющий вам оценить содержащиеся в нем рабочие документы.
PDFelement — это синоним надежности и удобства. Приложение, которое подходит всем пользователям. Программа задает стандарт, которому должен следовать каждый бизнес, чтобы не оставаться в стороне от современных веяний. Многие пользователи отказываются от Adobe Acrobat в пользу PDFelement, т.к. данная программа существенно превосходит все остальные PDF-ридеры по уровню надежности. Это единственная программа, в которой вы можете быть полностью уверены. Также это отличный PDF-редактор со следующими характеристиками:
- Очень высокая надежность. Удобные функции добавления, удаления, поворачивания, изменения размера графических элементов в PDF.
- Защищать PDF-файлы еще не никогда не было так просто.
 Вы можете с легкость добавлять пароли к вашим PDF-файлам.
Вы можете с легкость добавлять пароли к вашим PDF-файлам. - Возможность конвертировать PDF в различные форматы, включая HTML, текст и изображения.
- Удобная работа с PDF-формами. Извлекайте данные из PDF-форм и экспортируйте в формат CSV.
Советы: Что такое OCR?
OCR обозначает «оптическое распознавание символов». Это встроенная в PDFelement технология, которая позволяет преобразовывать изображения и другие нередактируемые файлы в редактируемый текстовый формат. Например, на изображении с большим количеством текста бывает сложно найти нужную информацию. Для таких случаев и создана функция распознавания текста (OCR). PDFelement поможет извлечь данные и преобразовать текст из изображений в редактируемый формат. Узнайте больше о том, как работает OCR.
Данные, полученные в результате распознавания, могут использоваться и обрабатываться таким же образом, как обычный текст. Главное преимущество функции OCR в PDFelement — высокая надежность. Кроме того, инструмент прост в использовании и не создает никаких проблем в работе.
Распознавание текста на арабском языке
Содержание
- Сервисы для распознавания текста — подборка лучших
- Finereaderonline.com
- Sodapdf.com
- WinScan2PDF
- Free Online OCR
- Microsoft OneNote
- Readiris
- Img2txt.com
- OCR CuneiForm
- TextGrabber 6
- Топ-3 программы для распознавания PDF на арабском 2020
- Лучшие программы, поддерживающие арабское распознавание текста
- 1. Sakhr Software
- 2. Readiris
- 3. Jina Arabic OCR
- Как использовать PDFelement OCR
- Шаг 1. Откройте PDF-файл.
- Шаг 2. Используйте OCR
- Шаг 3. Редактировать или конвертировать
- Распознавание текста онлайн — ТОП-9 сервисов
- Как пользоваться
- Abbyy Finereader
- Как пользоваться
- Распознавание текста онлайн без регистрации
- Online OCR
- Как пользоваться
- Free Online OCR
- Как пользоваться
- OCR Convert
- Как пользоваться
- Free OCR
- Как пользоваться
- I2OCR
- Как пользоваться
- Яндекс OCR
- Convertio
- Как пользоваться
- Заключение
- Распознавание текста онлайн — ТОП-9 сервисов: 5 комментариев
- ТОП-10 Сервисов и программ для бесплатного онлайн распознавания текста
- Таблица: общие данные
- Finereaderonline.
 com
com - Sodapdf.com
- Convertio.co
- Convertonlinefree.com
- Imgonline.com.ua
- Img2txt.com
- Onlineocr.net
- Microsoft Office Lens
- ВИДЕО: Introducing Office Lens Android, iOS (Как пользоваться приложением)
- Introducing Office Lens Android, iOS
- TextGrabber 6
- Видео
Сервисы для распознавания текста — подборка лучших
Заказчик прислал сканы рабочих документов, в университете скинули фотку конспекта? Когда-то тексты умели распознавать только сканеры и то далеко не все. Сейчас же даже приложения на смартфоне могут перевести визуальный текст в редактируемый документ. А в этом материале ищем лучшие сервисы по распознаванию текста для вашего компьютера и смартфона тоже.
Finereaderonline.com
Компания ABBYY идет в плане распознавания текстов и обработки цифровых документов впереди всех. В арсенале их софта даже цифровые подписи, которые почти невозможно отличить от настоящих. Finereaderonline поддерживает почти 200 языков, работает быстро и онлайн — ничего не надо устанавливать. Можно выбрать разные форматы для сохранения текста, обработка текста происходит очень быстро и достаточно точно. Единственный нюанс — лимит на загрузку файлов до 100 Мб. Но никто не запрещает вам загрузить несколько документов подряд. Сервис работает полностью онлайн, русифицирован и интуитивно понятен в управлении.
Можно выбрать разные форматы для сохранения текста, обработка текста происходит очень быстро и достаточно точно. Единственный нюанс — лимит на загрузку файлов до 100 Мб. Но никто не запрещает вам загрузить несколько документов подряд. Сервис работает полностью онлайн, русифицирован и интуитивно понятен в управлении.
Sodapdf.com
Еще один неплохой сервис, хотя тут нам предлагают скачать прогу отдельно. Правда, чуть менее обученный, чем софт от ABYYY — Sodapdf знает только 46 языков. Впрочем, если вам не нужно переводить с ацтекского или зулу, то проблем не возникнет. Программа условно бесплатная — есть триальная версия, полный функционал стоит от 7 до 17 евро в месяц в зависимости от пакета. Soda умеет конвертировать разные форматы, распознавать тексты, ставить электронные подписи и имеет большой набор инструментов для работы с PDF файлами и изображениями.
WinScan2PDF
Элементарная, простая маленькая утилита, которая состоит из трех кнопок: «выбрать источник», «сканировать» и подтвердить или отменить операцию. Поддерживает 23 языка, работает с многостраничными файлами и сохраняет обработанный файл в формате PDF. У этой программы есть одна особенность — она не работает с готовыми файлами и считывает документы только с подключенного сканера.
Поддерживает 23 языка, работает с многостраничными файлами и сохраняет обработанный файл в формате PDF. У этой программы есть одна особенность — она не работает с готовыми файлами и считывает документы только с подключенного сканера.
Free Online OCR
Не такой симпатичный, как Finereader, но тоже вполне умелый онлайн-сервис. Англоязычный, слегка устаревший интерфейс, в котором, впрочем, несложно разобраться. Free Online OCR поддерживает 106 языков и распознает текст с большинства самых популярных форматов файлов: JPEG, PNG, GIF, BMP, TIFF, PDF, DjVu. Сохранять готовые доки может не только в PDF, но и в стандарных doc и txt. Кроме текста, может распознать математические уравнения, правильно форматировать текст в колонках и столбцах или обработать только выделенный фрагмент. Качество распознавания довольно высокое даже c картинок низкого качества.
Microsoft OneNote
Распознавание текста здесь скорее дополнительная фича, а не основная задача. Вы можете вставить картинку в текущую запись OneNote и правой кнопкой мыши выбрать «Копировать текст из рисунка». Цифровая записная книжка от Microsoft однозначно не подойдет для обработки больших файлов, документов и постоянной работы с файлами. Но может помочь в мелких повседневных задачах — перевести небольшой текст с картинки, скриншота, рекламного макета, чтобы не вводить вручную. Качество распознавания у OneNote не очень высокое, а добавлять в файл многостраничные документы неудобно. Но OneNote и не для этого все-таки.
Цифровая записная книжка от Microsoft однозначно не подойдет для обработки больших файлов, документов и постоянной работы с файлами. Но может помочь в мелких повседневных задачах — перевести небольшой текст с картинки, скриншота, рекламного макета, чтобы не вводить вручную. Качество распознавания у OneNote не очень высокое, а добавлять в файл многостраничные документы неудобно. Но OneNote и не для этого все-таки.
Readiris
Мощный и удобный конкурент ABBYY FineReader. Быстро и очень чисто распознает даже едва различимые тексты, при этом поддерживает 137 языков, включая русский. Работает очень быстро и легко обрабатывает даже большие объемы текста. Сохраняет исходное форматирование, не игнорируя кавычки, размеры шрифта и стиль написания. Может почистить текст от помарок и предложить исправления в словах. Знает символы, уравнения. Контактирует со сканерами, облачными сервисами, поддерживает кучу форматов. В общем, полноценный и удобный сервис, который не умеет разве что редактировать итоговый файл PDF. Правда, за полный инструментарий придется платить, но есть бесплатная триальная версия.
Правда, за полный инструментарий придется платить, но есть бесплатная триальная версия.
Img2txt.com
Приятный дизайн, понятный интерфейс и высокая скорость обработки текста — что еще нужно для работы? Продвинутые алгоритмы распознавания помогают считывать документы даже плохого качества. Молниеносно конвертирует большие объемы текста, но при желании можно выбрать отдельную область файла для работы. Есть интеграция с Google Documents, хороший инструментарий для работы с документами PDF. Маловато языков — всего 35, но для основных задач этого может вполне хватить.
OCR CuneiForm
Шустро и тщательно распознает сфотографированные или отсканированные тексты, графические файлы. Старается сохранить исходную структуру текста, элементов и шрифты. Переводит все в редактируемые форматы на выбор. В общем, стандартный набор функционала. И, что самое главное, полностью бесплатный.
TextGrabber 6
Полностью бесплатное приложение для смартфонов за авторством компании ABBYY. Собственно, этим все сказано — в TextGrabber 6 все хорошо с распознаванием текста, есть встроенный модуль переводчика. Программа работает с помощью камеры и на распознавание, и на перевод. Поддерживает кучу языков, работает быстро и выглядит приятно.
Собственно, этим все сказано — в TextGrabber 6 все хорошо с распознаванием текста, есть встроенный модуль переводчика. Программа работает с помощью камеры и на распознавание, и на перевод. Поддерживает кучу языков, работает быстро и выглядит приятно.
Источник
Топ-3 программы для распознавания PDF на арабском 2020
Распознавание арабского текста доступно не во всех программах. Это один из способов, который тоже можно использовать. Распознавание PDF на арабском языке может привести к проблемам, так как не все программы предлагают этот вариант. Для бесплатного распознавания арабского текста онлайн существует множество веб-сайтов, которые можно использовать. Однако для достижения наилучших результатов следует использовать программное обеспечение. PDFelement это программа с лучшими возможностями распознавания текста.
Лучшие программы, поддерживающие арабское распознавание текста
Мы настоятельно рекомендуем указанные ниже несколько программ, использующих функции распознавания текста на арабском языке.
1. Sakhr Software
Это лучшая программа для бесплатного распознавания арабского текста, поскольку она позволяет пользователям преодолевать подобные проблемы. Программа может похвастаться отличным интерфейсом и производительностью. Функциональные возможности программы безупречны, поэтому ее смогут использовать даже новички. Для распознавания и преобразования PDF на арабском языке в Word эта программа работает наилучшим образом. Ее легко загрузить и использовать. Настоятельно рекомендуется всем начинающим пользователям.
Плюсы
Минусы
2. Readiris
Это приложение для распознавания арабского текста гарантирует, что вы получите результат, соответствующий вашим требованиям. Это одна из лучших программ, которая может гарантировать, что пользователям не придется искать другие подобные программы. В программе много функций для распознавания арабского текста, поэтому мы настоятельно ее рекомендуем. Для любого пользователя эта программа покажется удобной и выполняющей свою задачу очень качественно.
Плюсы
Минусы
3. Jina Arabic OCR
Это еще одна программа, которая выполняет распознавание текста на арабском языке с большой тщательностью и совершенством. Настоятельно рекомендуется как одна из программ, обеспечивающих быстрое и качественное выполнение работы. Это один из способов точного распознавания текста на арабском языке.
Плюсы
Минусы
Как использовать PDFelement OCR
Шаг 1. Откройте PDF-файл.
Загрузите отсканированный PDF-файл или PDF-файл на основе изображений в программу. Для этого вы можете перетащить его или нажать кнопку «Открыть файл».
Шаг 2. Используйте OCR
Перейдите в «Конвертировать»> «OCR», чтобы убедиться, что выполняется распознавание. Перед выполнением этой функции важно убедиться, что плагин OCR загружен и установлен. В новом всплывающем окне выберите режим «Текст с возможностью поиска» или «Редактируемый текст», нажмите кнопку «Изменить язык», чтобы выбрать нужный язык и продолжить.
Шаг 3. Редактировать или конвертировать
После выполнения распознавания вы можете нажать кнопку «Редактировать», чтобы отредактировать контент по своему усмотрению. Узнайте больше о том, как редактировать PDF-файлы здесь. Или выберите выходной формат на вкладке «Преобразовать», чтобы преобразовать его в файл другого формата. Узнайте больше о том, том, как конвертировать PDF-файлы здесь.
Источник
Распознавание текста онлайн — ТОП-9 сервисов
Распознавание текста с картинки, OCR (optical character recognition), то есть превращение картинки в текст доступно бесплатно на многих сайтах в режиме онлайн. Но везде свое качество и свои ограничения на количество распознаваемых картинок.
Я проверила с десяток онлайн-сервисов и составила рейтинг лучших.
Для примера распознавала фотографию документа, который есть у каждого – свидетельство ИНН физического лица (разрешением 1275×1750 пикселей).
| Сервис | Нужна регистрация | Рейтинг | Адрес |
|---|---|---|---|
| да | 3 | https://drive. google.com/drive google.com/drive | |
| Abbyy Finereader | да | 5 | https://finereaderonline.com/ru-ru |
| Online OCR2 | — | 5 | http://www.onlineocr.net |
| Free Online OCR | — | 2 | https://www.newocr.com |
| OCR Convert | — | 4 | http://www.ocrconvert.com |
| Free OCR | — | 1 | www.free-ocr.com |
| I2OCR | — | 4 | http://www.i2ocr.com |
| Яндекс ОCR | Распознает и переводит. | 5 | https://translate.yandex.ru/ocr |
| Convertio | Работает своеобразно | 3 | https://convertio.co/ru/ocr/ |
В Google можно распознавать неограниченное количество картинок, лишь бы они поместились на Google Drive. Нужно просто открыть картинку с Google диска с помощью Google Документов, и она автоматически распознается.
Качество исходника рекоменовано не меньше 10 пикселей по высоте для строки.
Как пользоваться
Abbyy Finereader
В Abbyy Finereader Online самый удобный интерфейс, хорошее качество, но доступна только ознакомительная версия – можно распознать не более 10 страниц за две недели. (200 страниц в месяц стоят 299р). Для использования сервиса нужно зарегистрироваться (можно войти через аккаунты социальных сетей). Кроме того, полученный текст можно там же перевести на другой язык с помощью машинного перевода.
| Входные форматы | PDF, TIF, JPEG, BMP, PCX, PNG |
| Выходные форматы | Word, Excel, Power Point, Open Document, RTF, Adobe PDF, Text Plain, Fb2, Epub |
| Размер файла | До 100Мб |
| Ограничения | 10 картинок на две недели |
| Качество | Качество распознавания свидетельства инн оказалось хорошее. Примерно как у Online OCR – какие-то части документа лучше распознались тем сервисом, а какие-то – этим. Примерно как у Online OCR – какие-то части документа лучше распознались тем сервисом, а какие-то – этим. |
Результат распознавания Finereader. (ФИО и город распознаны, но стерты вручную)
Как пользоватьсяРаспознавание текста онлайн без регистрации
Online OCR
Online OCR http://www.onlineocr.net/ – единственный наряду с Abbyy Finereader сервис, который позволяет сохранять в выходном формате картинки вместе с текстом. Вот как выглядит распознанный вариант с выходным форматом Word:
Результат распознавания в Online OCR (ФИО и дата распознаны, но стерты вручную)
| Входные форматы | PDF, TIF, JPEG, BMP, PCX, PNG, GIF |
| Выходные форматы | Word, Excel, Adobe PDF, Text Plain |
| Размер файла | До 5Мб без регистрации и до 100Мб с ней |
| Ограничения | Распознает не более 15 картинок в час без регистрации |
| Качество | Качество распознавания свидетельства инн оказалось хорошее.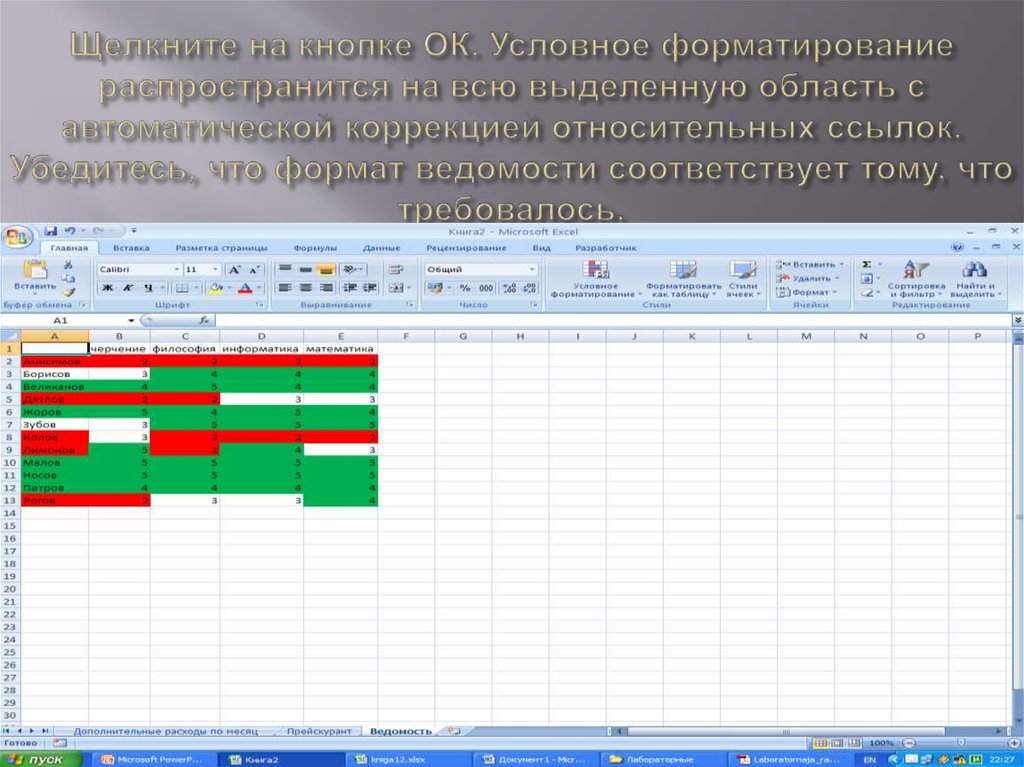 Примерно как у Abbyy Finereader – какие-то части документа лучше распознались тем сервисом, а какие-то – этим. Примерно как у Abbyy Finereader – какие-то части документа лучше распознались тем сервисом, а какие-то – этим. |
Внизу появится ссылка на выходной файл (текст с картинками) и окно с текстовым содержимым
Free Online OCR
Free Online OCR https://www.newocr.com/ позволяет выделить часть изображения. Выдает результат в текстовом формате (картинки не сохраняются).
| Входные форматы | PDF, DjVu JPEG, PNG, GIF, BMP, TIFF |
| Выходные форматы | Text Plain (PDF и Word тоже можно загрузить, но внутри них все равно текст без форматирования и картинок). |
| Размер файла | До 5Мб без регистрации и до 100Мб с ней |
| Ограничения | Ограничения на количество нет |
| Качество | Качество распознавания свидетельства инн плохое. |
Как пользоватьсяМожно распознавать как все целиком, так и выделить часть изображения для распознавания.

OCR Convert
OCR Convert http://www.ocrconvert.com/ txt
| Входные форматы | Многостраничные PDF, JPG, PNG, BMP, GIF, TIFF |
| Выходные форматы | Text Plain |
| Размер файла | До 5Мб общий размер файлов за один раз. |
| Ограничения | Одновременно до 5 файлов. Сколько угодно раз. |
| Качество | Качество распознавания свидетельства инн среднее. (ФИО распознано частично). Лучше, чем Google, хуже, чем Finereader |
Free OCR
Free OCR www.free-ocr.com распознал документ хуже всех.
| Входные форматы | PDF, JPG, PNG, BMP, GIF, TIFF |
| Выходные форматы | Text Plain |
| Размер файла | До 6Мб |
| Ограничения | У PDF-файла распознается только первая страница |
| Качество | Качество распознавания свидетельства инн низкое – правильно распознано только три слова. |
I2OCR
I2OCR http://www.i2ocr.com/ неплохой сервис со средним качеством выходного файла. Отличается приятным дизайном, отсутствием ограничений на количество распознаваемых картинок. Но временами зависает.
| Входные форматы | JPG, PNG, BMP, TIF, PBM, PGM, PPM |
| Выходные форматы | Text Plain (PDF и Word тоже можно загрузить, но внутри них все равно текст без форматирования и картинок). |
| Размер файла | До 10Мб |
| Ограничения | нет |
| Качество | Качество распознавания свидетельства инн среднее – сравнимо с OCR Convert. Замечено, что сервис временами не работает. |
Яндекс OCR
Недавно обнаружила этот сервис, и он мне очень понравился качеством и простотой использования. Вообще то он предназначен для перевода загруженной картинки, но его можно использоваться и для распознавания текста с картинки. Регистрации не требует, ограничений на количество изображений нет. В данный момент находится в стадии бета-тестирования.
Регистрации не требует, ограничений на количество изображений нет. В данный момент находится в стадии бета-тестирования.
Просто перейдите на https://translate.yandex.ru/ocr, загрузите картинку (можно перетащить) и щелкните “Открыть в Переводчике”. Откроется как текст с картинки, так и перевод в правом поле.
Перетащите картинку Результат распознавания
Convertio
Convertio hhttps://convertio.co/ru/ocr/ работает своеобразно, поэтому сравнивать его тяжело. В целом не понравился. Свидетельство ИНН, загруженное целиком, он не распознал совсем, так как плохо выделяет текст среди картинок. Не распозналось ни одного слова! Для его проверки я вырезала текстовый кусочек из ИНН и распознала его – это удалось сделать.
К тому же временами он зависает в попытках что-либо распознать.
Замечено, что при распознавании сервис временами зависает, возможно ваши картинки ставятся в большую очередь на бесплатном тарифе.
Как пользоватьсяВырезанный и распознанный кусок (целиком не распознается):
Результат работы Convertio
Заключение
Лучше всего документ распознал Abbyy Finereader и Online OCR. Кроме того, эти сервисы сохраняют форматирование файла: где нет текста, оставляют картинки и компонуют их с распознанным текстом. Из новых сервисов хорош Яндекс OCR.
Кроме того, эти сервисы сохраняют форматирование файла: где нет текста, оставляют картинки и компонуют их с распознанным текстом. Из новых сервисов хорош Яндекс OCR.
Хуже всего сработал Free OCR – он распознал всего три слова.
Распознавание текста онлайн — ТОП-9 сервисов: 5 комментариев
СПАСИБО! И меня очень выручили… по поиску в яндексе мои попытки тоже были безуспешные, а статья помогла и выбрала отличный ресурс, который преобразовал все 30 страниц) к слову, нужно было очень быстро и срочно!)))
если есть такая возможность то напишите пожалуйста
есть страничка
на ней картинки с текстом
конкретно адреса электронной почты
https://www.math.fsu.edu/People/faculty.php
вопрос можно ли вытащить каким то средствами текст этих адресов
согласен что это не хорошо но увы нужно
сделайте скриншот, да распознайте картинку. Правда, качество там не очень
спасибо admin за относительно свежую статью и рейтинг про
«OCR сервис онлайн»
мне для научной статьи на англ. только изображения бесплатно нашлись. pdf/doc нет.
только изображения бесплатно нашлись. pdf/doc нет.
Здравствуйте, предлагаю протестировать сервис распознавания текста https://onlineocr.org/ru и по возможности добавить в свой список https://itlang.ru/raspoznavanie-teksta-onlajn/
1. Сервис распознает текст на изображениях лучше, чем 80% других аналогичных сервисов.
2. Абсолютно бесплатный сервис, неограниченное количество распознаваний текста.
Надеюсь, ваши посетители останутся довольны качеством распознавания текста в дальнейшем.
Источник
ТОП-10 Сервисов и программ для бесплатного онлайн распознавания текста
программа распознавания текста онлайн
В незапамятные времена, когда на компьютерах была установлена культовая XP, распознавать текст на изображении умели только сканеры и специализированные программы для профессионалов. Однако все изменилось. Теперь даже смартфоны умеют распознавать текст. Естественно, при помощи специализированных приложений. Но скачать их можно совершенно бесплатно.
А еще есть различные сервисы для распознавания текстов онлайн. В наше время любой желающий может просто зайти на сайт, загрузить туда нужное изображение и на выходе получить качественный и вполне читабельный текст. А какие сервисы считаются лучшими? В этом нам предстоит разобраться. Вот таблица с лучшими сервисами и мобильными приложениями, позволяющими быстро распознать текст на картинке.
Таблица: общие данные
Читайте также: Уменьшаем размер изображения в формате JPG: ТОП-5 Простых простых способов
Finereaderonline.com
Sodapdf.com
Convertio.co
Convertonlinefree.com
Imgonline.com.ua
Img2txt.com
Onlineocr.net
Microsoft Office Lens (Win, Android, iOS)
TextGrabber 6 (iOS)
Text Fairy (Android)
А теперь рассмотрим все то, что было представлено в таблице подробнее. Только так можно будет понять, какой из сервисов лучше.
Только так можно будет понять, какой из сервисов лучше.
Finereaderonline.com
Вероятно, один из лучших онлайн-сервисов для распознавания текста на изображении. Сервис запущен известной компанией ABBYY, которая занимается разработкой специального софта для сканирования и распознавания текста.
Поддерживается 193 языка. Есть даже возможность распознавать немецкий шрифт XIX века. Форматы для сохранения готового текста разнообразны. Есть не только форматы MS Office. Сам процесс считывания и преобразования происходит довольно быстро.
Еще один хороший сервис для распознавания текста. Отличается более интересным дизайном, чем продукт от ABBYY и не таким богатым набором опций. Так, в активе данного сервиса всего 46 языков. Количество поддерживаемых форматов тоже ограничено.
Зато можно загружать файлы куда большего размера. То же относится и к диапазону обрабатываемых изображений. Также сервис умеет конвертировать форматы, объединять PDF и делать многое другое.
Также сервис умеет конвертировать форматы, объединять PDF и делать многое другое.
Convertio.co
Отличный сервис для распознавания текста. Он умеет работать с различными форматами изображения. А вот сохранять готовый текст может только в DOCX, PLX, PDF и TXT. Не очень впечатляющий набор. Количество распознаваемых языков тоже не впечатлит. Их очень мало.
Пользователю доступно для распознавания только 10 страниц. Для того, чтобы этого ограничения не было, придется пройти процесс регистрации в системе. Он прост и не составит проблемы даже для новичков. Тем более, что сайт полностью на русском языке.
Convertonlinefree.com
Читайте также: ТОП-10 сервисов для проверки текста на орфографию и пунктуацию
Сервис обладает весьма топорным дизайном начала нулевых. Но при этом работает быстро и имеет приличное количество поддерживаемых форматов для сохранения готового текста. Также у него есть возможность считывать изображения приличного разрешения.
У сервиса весьма интересная система лимита. Он способен распознать текст только на первых 20 страницах из всех загруженных за один раз. Потом придется загружать заново. Так намного удобнее, чем лимит на размер файла.
Читайте также: Как в Ворде сделать одну страницу альбомной: Самые простые способы с пошаговой инструкцией 2018 года (+Отзывы)
Сервис распознавания текста от украинских разработчиков. Это наиболее быстрый ресурс. Скорость обработки составляет от 20 до 60 секунд. В зависимости от сложности текста и качества изображения. Есть несколько алгоритмов работы OCR, что не может не радовать.
В распоряжении сервиса огромное количество языков и возможность загрузки файла объемом до 100 Мб. Помимо этого, сайт может конвертировать изображение в любой формат. Хотя сам сервис поддерживает их не много.
Еще один сайт, предоставляющий услуги по распознаванию текстов. Дизайн этого онлайн-сервиса вполне современный, что, вероятно, и привлекает пользователей. С характеристиками тоже все не так плохо.
С характеристиками тоже все не так плохо.
Сервис умеет работать с различными форматами изображений (кроме самых редких) и документами PDF. Для сохранения готового текста используются форматы DOCX, XLS, PDF, TXT, ODF. При этом скорость работы довольно приличная.
Onlineocr.net
Читайте также: Поиск по картинке в Гугл (Google) Как правильно пользоваться сервисом? +Отзывы
Простой и ненавязчивый, но в то же время вполне современный дизайн этого сайта делает работу с ним весьма приятной. А вот с характеристиками дела обстоят не очень хорошо. Сервис поддерживает крайне малое количество форматов изображений.
А форматов для сохранения готового текста и вовсе всего три штуки. Зато сервис совершенно бесплатен и работает с довольно высокой скоростью. Не радует только максимальный размер загружаемого файла – всего 15 Мб. Придется повторять процедуру много раз.
Microsoft Office Lens
Читайте также: Как изменить формат фотографии: Подробные инструкции к нескольким редакторам
А это уже приложение для смартфона, которое умеет распознавать текст с использованием камеры аппарата. Задумка, конечно, хороша, но было бы гораздо лучше, если б разработкой этой программы не занималась компания Microsoft.
Задумка, конечно, хороша, но было бы гораздо лучше, если б разработкой этой программы не занималась компания Microsoft.
Детище Билла Гейтса имеет уникальную «суперспособность» – портить все, к чему прикасается. И в этом приложении авторы незабвенной Windows 10 остались верны традициям. Приложение работает из рук вон плохо: частые вылеты, фризы и глюки.
Что до качества распознавания текста, то оно ужасно. Приложение справляется со своими функциями через раз. А иногда такого увидит в изображении, что глаза начинают кровоточить. Тем не менее, иногда программа работает четко. Неизвестно, от чего это зависит.
Особенно раздражает постоянные предложения поделиться распознанным текстом и воспользоваться для этого туповатым облачным сервисом OneDrive. А от обилия рекламы и вовсе в глазах рябит. Что же делать – бесплатное приложение.
ВИДЕО: Introducing Office Lens Android, iOS (Как пользоваться приложением)
Introducing Office Lens Android, iOS
ТОП-10 Сервисов и программ для бесплатного онлайн распознавания текста
TextGrabber 6
Читайте также: Горячие клавиши Эксель: Подборка всех комбинаций
Отличное приложение для распознавания текста, созданное для аппаратов на iOS. Утилиту можно совершенно бесплатно скачать в AppStore. Разработкой программы занималась легендарная компания ABBYY. Этим и объясняется высокое качество.
Утилиту можно совершенно бесплатно скачать в AppStore. Разработкой программы занималась легендарная компания ABBYY. Этим и объясняется высокое качество.
По сути, это универсальная программа. Она имеет встроенный модуль переводчика с большого количества языков и собственно блок распознавания текста с камеры устройства. Кстати, перевод с помощью камеры также возможен.
Работает приложение почти идеально. Тексты распознаются с высоким процентом успеха. Перевод очень мало похож на машинный. В общем, по-другому у компании ABBYY и быть не может. ВладельцыiPhone точно должны установить себе эту программу.
TextGrabber 6 может похвастаться полным отсутствием рекламного контента. Также есть интеграция с самыми популярными облачными сервисами. Но назойливой просьбы воспользоваться ими и в помине нет.
Источник
Видео
УРОК АРАБСКОГО ЯЗЫКА – короткие рассказы – 1
Как настроить программу ABBYY FineReader 14 распознавать Арабский текст
Новости на арабском языке. Разбор текста.
Разбор текста.
Читаем арабские тексты без огласовок
Арабский текст в Adobe Photoshop?
Диалог на арабском языке. Включите субтитры!
Распознавание текста. Перевести картинку и пдф в ворд. Лучшие методы
Учить арабский язык. Арабский мультфильм с субтитрами جابر بن حيان “Джабир ибн Хайан” часть 1
Диалог на АРАБСКОМ для начинающих | Знакомство (включите субтитры)
Изучай арабский: 200 фраз на арабском
Как перенести таблицу с фотографии в ворд
Конвертер JPG в DOC
Конвертировать JPG в DOC
Этот онлайн-конвертер document позволяет конвертировать файлы из JPG в DOC в высоком качестве. Мы поддерживаем множество различных форматов файлов, таких как PDF, DOCX, PPTX, XLSX и другие. Используя технологию конвертации online-convert.com, вы получаете точные результаты конвертирования.
Ошибка: количество входящих данных превысило лимит в 3.
Чтобы продолжить, вам необходимо обновить свою учетную запись:
Ошибка: общий размер файла превысил лимит в 100 MB.
Чтобы продолжить, вам необходимо обновить свою учетную запись:
Ошибка: общий размер файла превысил абсолютный лимит в 8GB.
Для платных аккаунтов мы предлагаем:
- Вплоть до 8GB общего размера файла за один сеанс конвертирования 200 файлов на одно конвертирование Высокий приоритет и скорость конвертирования Полное отсутствие рекламы на странице Гарантированный возврат денег
- До 100 Мб общего размера файла за один сеанс конвертирования 5 файлов на одно конвертирование Обычный приоритет и скорость конвертирования Наличие объявлений
Мы не может загружать видео с Youtube.
Чтобы конвертировать в обратном порядке из DOC в JPG, нажмите здесь:
Конвертер DOC в JPG
Оцените конвертирование DOC с помощью тестового файла JPG
Не впечатлило? Нажмите на ссылку, чтобы конвертировать наш демонстрационный файл из формата JPG в формат DOC:
Конвертирование JPG в DOC с помощью нашего тестового файла JPG.
JPG (Joint Photographic Experts Group JFIF format)
Фото и изображения, которые необходимо передать по электронной почте или выложить в Интернет, должны быть сжаты с целью уменьшения времени их выгрузки и загрузки, а также с целью экономии ресурсов Интернет-канала. Для этого обычно используют изображения в формате JPG. Сжатие с потерями равномерно по всему изображению, причем чем ниже степень сжатия, тем более четким становится изображение.
Что такое JPG?
DOC (Microsoft Word Binary File Format)
Используемый текстовыми редакторами на компьютерах формат DOC (Document) прочно ассоциируется с программой Microsoft Word. Изначально этот формат представлял собой простой текст, однако в настоящее время пользователи могут вставлять в файлы DOC гиперссылки, изображения, менять поля, выравнивание и т.п. При своем создании файлы DOC покрывали все нужны пользователей, связанные с редактированием.
Что такое DOC?
Преобразование изображений в таблицы в Приложение Office
Эта статья предназначена для людей с нарушениями зрения, использующих программы чтения с экрана совместно с продуктами Office. Она входит в набор содержимого Специальные возможности Office. Дополнительные общие сведения см. на домашней странице службы поддержки Microsoft.
Она входит в набор содержимого Специальные возможности Office. Дополнительные общие сведения см. на домашней странице службы поддержки Microsoft.
С помощью Приложение Office VoiceOver (встроенного в iOS устройства чтения с экрана) можно сделать снимок элемента, который отображает данные в формате таблицы, и извлечь таблицу из рисунка. Вы можете открыть извлеченную таблицу в Excel для редактирования, скопировать таблицу или сделать так, чтобы VoiceOver прочитал содержимое таблицы. Вы также узнаете, как извлекать таблицы из сохраненного изображения.
Новые возможности Microsoft 365 становятся доступны подписчикам Microsoft 365 по мере выхода, поэтому в вашем приложении эти возможности пока могут отсутствовать. Чтобы узнать о том, как можно быстрее получать новые возможности, станьте участником программы предварительной оценки Office.
В этой статье предполагается, что вы используете VoiceOver — средство чтения с экрана, встроенное в iOS. Дополнительные сведения об использовании VoiceOver см. на странице Универсальный доступ в продуктах Apple.
на странице Универсальный доступ в продуктах Apple.
В этом разделе
Преобразование изображения в таблицу
С помощью Приложение Office камеры телефона можно сделать снимок таблицы, например на доске, и преобразовать изображение в таблицу, которую можно изменить в Excel. Вы также можете скопировать извлеченную таблицу и в нее, например, в сообщение электронной почты. Вы также можете использовать существующее изображение, например изфотографий .
Примечание: Чтобы использовать Приложение Office сделать снимок, необходимо разрешить приложению доступ к камере. Это можно сделать в Приложение Office параметрах.
Извлекать таблицу из изображения и открывать ее в Excel
В области Приложение Office коснитесь в нижней части экрана четырьмя пальцами. Фокус перемещается на строку навигации в нижней части экрана.
Проводите пальцем влево или вправо, пока не услышите “Действия”, а затем дважды коснитесь экрана. Откроется меню Действия.
Проводите пальцем влево, пока не услышите “Изображение в таблицу”, а затем дважды коснитесь экрана. Активируется режим камеры.
Активируется режим камеры.
Выполните одно из указанных ниже действий.
Чтобы сделать снимок с помощью камеры устройства, назначите камеру на таблицу, а затем проводите пальцем вправо, пока не услышите “Сделать снимок”, а затем дважды коснитесь экрана.
Чтобы выбрать существующий рисунок, проводите пальцем вправо, пока не услышите “Галерея” и имя нужного рисунка, а затем дважды коснитесь экрана.
Если изображения нет в коллекции, проводите пальцем вправо, пока не услышите “Выбрать фотографию из библиотеки”, а затем дважды коснитесь экрана. Откроется приложение Фотографии. Найдите изображение и дважды коснитесь экрана, чтобы выбрать его.
Вы услышите: “Верхний левый угол”. Теперь вы можете обрезать изображение, если нужно, чтобы на изображении была только таблица. Проводите пальцем вправо, пока не найдете нужный обрезный лад, а затем дважды коснитесь экрана и удерживайте палец, чтобы настроить область обрезки. Возможно, вам понадобится кто-то, кто поможет вам в этом.
После этого проводите пальцем вправо, пока не услышите “Готово”, а затем дважды коснитесь экрана. Начнется Приложение Office обработка изображения.
После извлечения таблицы вы услышите звуковой сигнал и количество столбцов и строк в таблице. Чтобы прочитать содержимое строк таблицы, проведите пальцем вправо. Вы услышите содержимое ячейки и ее положение в таблице.
Чтобы открыть таблицу в Excel, проводите пальцем вправо, пока не услышите “Открыть в Excel”, а затем дважды коснитесь экрана. Таблица откроется в Excel. Вы услышите: “Содержимое формулы”. Теперь таблицу можно редактировать и сохранять в формате Excel файла.
Если вы услышите сообщение “Все равно открыть”, а не “Содержимое формулы”, это означает, что Приложение Office обнаружены возможные ошибки, например орфографию. Чтобы продолжить, не просматривая таблицу, дважды коснитесь экрана.
Чтобы просмотреть возможные ошибки в таблице:
Проводите пальцем вправо, пока не услышите “Рецензирование”, а затем дважды коснитесь экрана.
Фокус перемещается в ячейку с подозрительной ошибкой, и вы услышите текущее содержимое ячейки. Чтобы исправить возможные ошибки, используйте экранную клавиатуру, а затем проводите пальцем влево, пока не услышите сообщение “Готово, кнопка”, а затем дважды коснитесь экрана.
Если в ячейке нет ничего исправить, проводите пальцем вправо, пока не дойдете до кнопки Игнорировать, а затем дважды коснитесь экрана.
Фокус перемещается в следующую ячейку с возможной ошибкой. Просмотрите содержимое ячейки и примите меры, как пошаговому действию выше. После завершения проверки таблица откроется в Excel.
После того как вы закончили редактировать таблицу в Excel, коснитесь верхней части экрана четырьмя пальцами. Вы услышите имя таблицы. Проводите пальцем вправо, пока не услышите “Закрыть файл”, а затем дважды коснитесь экрана.
Если у вас естьMicrosoft 365 подписка и вы подключены к OneDrive, файл будет сохранен автоматически. В противном случае вы будете оповещены о том, что нужно сохранить изменения. Чтобы сохранить таблицу, например на телефоне, проводите пальцем вправо, пока не услышите “Сохранить, многослойный”, а затем дважды коснитесь экрана.
Чтобы сохранить таблицу, например на телефоне, проводите пальцем вправо, пока не услышите “Сохранить, многослойный”, а затем дважды коснитесь экрана.
Фокус будет в текстовом поле Имя файла. Если вы хотите изменить имя, введите новое имя с помощью экранной клавиатуры, проводите пальцем вправо, пока не услышите “Готово”, а затем дважды коснитесь экрана.
Проведите пальцем влево или вправо, чтобы найти расположение для сохранения, а затем дважды коснитесь экрана. Проводите пальцем вправо, пока не услышите “Сохранить”, а затем дважды коснитесь экрана. Файл будет сохранен, а фокус вернется на вкладку Главная.
Извлечение таблицы из изображения и ее копирование
В области Приложение Office коснитесь в нижней части экрана четырьмя пальцами. Фокус перемещается на строку навигации в нижней части экрана.
Проводите пальцем влево или вправо, пока не услышите “Действия”, а затем дважды коснитесь экрана. Откроется меню Действия.
Проводите пальцем влево, пока не услышите “Изображение в таблицу”, а затем дважды коснитесь экрана. Активируется режим камеры.
Активируется режим камеры.
Выполните одно из указанных ниже действий.
Чтобы сделать снимок с помощью камеры устройства, назначите камеру на таблицу, а затем проводите пальцем вправо, пока не услышите “Сделать снимок”, а затем дважды коснитесь экрана.
Чтобы выбрать существующий рисунок, проводите пальцем вправо, пока не услышите “Галерея” и имя нужного рисунка, а затем дважды коснитесь экрана.
Если изображения нет в коллекции, проводите пальцем вправо, пока не услышите “Выбрать фотографию из библиотеки”, а затем дважды коснитесь экрана. Откроется приложение Фотографии. Найдите изображение и дважды коснитесь экрана, чтобы выбрать его.
Вы услышите: “Верхний левый угол”. Теперь вы можете обрезать изображение, если нужно, чтобы на изображении была только таблица. Проводите пальцем вправо, пока не найдете нужный обрезный лад, а затем дважды коснитесь экрана и удерживайте палец, чтобы настроить область обрезки. Возможно, вам понадобится кто-то, кто поможет вам в этом.
После этого проводите пальцем вправо, пока не услышите “Готово”, а затем дважды коснитесь экрана. Начнется Приложение Office обработка изображения.
После извлечения таблицы вы услышите звуковой сигнал и количество столбцов и строк в таблице. Чтобы прочитать содержимое строк таблицы, проведите пальцем вправо. Вы услышите содержимое ячейки и ее положение в таблице.
Чтобы скопировать таблицу, проводите пальцем вправо, пока не услышите “Копировать текст”, а затем дважды коснитесь экрана. Вы услышите: “Таблица скопирована”. Теперь вы можете в таблицу, в которой ее использовать, например в сообщении электронной почты или на PowerPoint слайде.
Если вы услышите сообщение “Копировать все равно”, а не “Таблица скопирована”, это означает, что Приложение Office обнаружены возможные ошибки, например орфографию. Чтобы продолжить, не просматривая таблицу, дважды коснитесь экрана.
Чтобы просмотреть возможные ошибки в таблице:
Проводите пальцем вправо, пока не услышите “Рецензирование”, а затем дважды коснитесь экрана.
Фокус перемещается в ячейку с подозрительной ошибкой, и вы услышите текущее содержимое ячейки. Чтобы исправить возможные ошибки, используйте экранную клавиатуру, а затем проводите пальцем влево, пока не услышите сообщение “Готово, кнопка”, а затем дважды коснитесь экрана.
Если в ячейке нет ничего исправить, проводите пальцем вправо, пока не дойдете до кнопки Игнорировать, а затем дважды коснитесь экрана.
Фокус перемещается в следующую ячейку с возможной ошибкой. Просмотрите содержимое ячейки и примите меры, как пошаговому действию выше. После завершения проверки таблица будет скопирована.
Чтобы выйти из таблицы, проводите пальцем вправо, пока не услышите “Закрыть”, а затем дважды коснитесь экрана. Вы услышите: “Оповещение, отменить таблицу?” Проводите пальцем вправо, пока не услышите “Да”, а затем дважды коснитесь экрана.
Фокус вернется в режим камеры. Вы услышите: “Отмена”. Чтобы вернуться в меню Действия, дважды коснитесь экрана.
См. также
С помощью Приложение Office с помощью TalkBack (встроенного в Android программы чтения с экрана) можно сделать снимок элемента, который отображает данные в формате таблицы, и извлечь таблицу из рисунка. Вы можете открыть извлеченную таблицу в Excel для редактирования, скопировать таблицу или сделать так, чтобы TalkBack прочитал содержимое таблицы. Вы также узнаете, как извлекать таблицы из сохраненного изображения.
Вы можете открыть извлеченную таблицу в Excel для редактирования, скопировать таблицу или сделать так, чтобы TalkBack прочитал содержимое таблицы. Вы также узнаете, как извлекать таблицы из сохраненного изображения.
Новые возможности Microsoft 365 становятся доступны подписчикам Microsoft 365 по мере выхода, поэтому в вашем приложении эти возможности пока могут отсутствовать. Чтобы узнать о том, как можно быстрее получать новые возможности, станьте участником программы предварительной оценки Office.
В этой статье предполагается, что вы используете TalkBack — средство чтения с экрана, встроенное в Android. Дополнительные сведения об использовании TalkBack см. на странице Специальные возможности в Android.
В этом разделе
Преобразование изображения в таблицу
С помощью Приложение Office камеры телефона можно сделать снимок таблицы, например на доске, и преобразовать изображение в таблицу, которую можно изменить в Excel. Вы также можете скопировать извлеченную таблицу и в нее, например, в сообщение электронной почты. Вы также можете использовать существующее изображение, например из приложения Мультимедиа,Фотографии или Галерея в зависимости от вашего устройства.
Вы также можете использовать существующее изображение, например из приложения Мультимедиа,Фотографии или Галерея в зависимости от вашего устройства.
Примечание: Чтобы использовать Приложение Office сделать снимок, необходимо разрешить приложению доступ к камере. Это можно сделать в Приложение Office параметрах.
Извлекать таблицу из изображения и открывать ее в Excel
В области Приложение Office проведите пальцем вниз, а затем вверх. Фокус перемещается на строку навигации в нижней части экрана.
Проводите пальцем влево или вправо, пока не услышите “Действия”, а затем дважды коснитесь экрана. Откроется меню Действия.
Проводите пальцем влево, пока не услышите “Изображение в таблицу”, а затем дважды коснитесь экрана. Активируется режим камеры.
Выполните одно из указанных ниже действий.
Чтобы сделать снимок с помощью камеры устройства, назначите камеру на таблицу, а затем проводите пальцем вправо, пока не услышите “Сделать снимок”, а затем дважды коснитесь экрана.
Чтобы выбрать существующий рисунок, проводите пальцем вправо, пока не услышите “Галерея” и имя нужного рисунка, а затем дважды коснитесь экрана.
Если изображения нет в коллекции, проводите пальцем вправо, пока не услышите “Выбрать фотографию из библиотеки”, а затем дважды коснитесь экрана. Откроется приложение для сохраненных изображений. Вам может быть предложено разрешить приложению доступ к изображениям. Найдите изображение и дважды коснитесь экрана, чтобы выбрать его.
Вы услышите: “Обрезать изображение”. Теперь вы можете обрезать изображение, если нужно, чтобы на изображении была только таблица. Проводите пальцем вправо, пока не найдете нужный обрезный лад, а затем дважды коснитесь экрана и удерживайте палец, чтобы настроить область обрезки. Возможно, вам понадобится кто-то, кто поможет вам в этом.
После этого проводите пальцем вправо, пока не услышите “Подтвердить”, а затем дважды коснитесь экрана. Начнется Приложение Office обработка изображения.
После извлечения таблицы вы услышите: “Таблица, извлеченная из изображения”. Чтобы прочитать содержимое строк таблицы, проведите пальцем вправо. Вы услышите содержимое ячейки и ее положение в таблице.
Чтобы прочитать содержимое строк таблицы, проведите пальцем вправо. Вы услышите содержимое ячейки и ее положение в таблице.
Чтобы открыть таблицу в Excel, проводите пальцем вправо, пока не услышите “Открыть в Excel”, а затем дважды коснитесь экрана. Таблица откроется в Excel. Вы услышите: “Книга, редактирование”. Теперь таблицу можно редактировать в формате Excel файла.
Если вы услышите сообщение “Значок оповещения”, а не “Книга, редактирование”, это означает, что Приложение Office обнаружены возможные ошибки, например орфографическая ошибка в таблице. Чтобы продолжить, не просматривая таблицу, проводите пальцем вправо, пока не услышите “Все равно открыть”, а затем дважды коснитесь экрана.
Чтобы просмотреть возможные ошибки в таблице:
Проводите пальцем вправо, пока не услышите “Просмотреть все”, а затем дважды коснитесь экрана.
Фокус перемещается в ячейку с подозрительной ошибкой, и вы услышите текущее содержимое ячейки. Чтобы исправить ошибку, используйте экранную клавиатуру, а затем проводите пальцем влево, пока не услышите сообщение “Готово, кнопка”, а затем дважды коснитесь экрана.
Если в ячейке нет ничего исправить, проводите пальцем вправо, пока не дойдете до кнопки Игнорировать, а затем дважды коснитесь экрана.
Фокус перемещается в следующую ячейку с возможной ошибкой. Просмотрите содержимое ячейки и примите меры, как пошаговому действию выше. После завершения проверки таблица откроется в Excel.
После редактирования таблицы в Excel проведите пальцем вниз, а затем влево. Если у вас естьMicrosoft 365 подписка и вы подключены к OneDrive, файл будет сохранен автоматически. В противном случае вы будете оповещены о том, что нужно сохранить изменения.
Чтобы сохранить таблицу, например на телефоне, проводите пальцем вправо, пока не услышите “Сохранить”, а затем дважды коснитесь экрана. Фокус перемещается в текстовое поле имя файла. Дважды коснитесь экрана и при необходимости измените имя с помощью экранной клавиатуры.
Проводите пальцем влево, пока не найдете расположение для сохранения файла, а затем дважды коснитесь экрана. Проводите пальцем вправо, пока не услышите “Сохранить”, а затем дважды коснитесь экрана.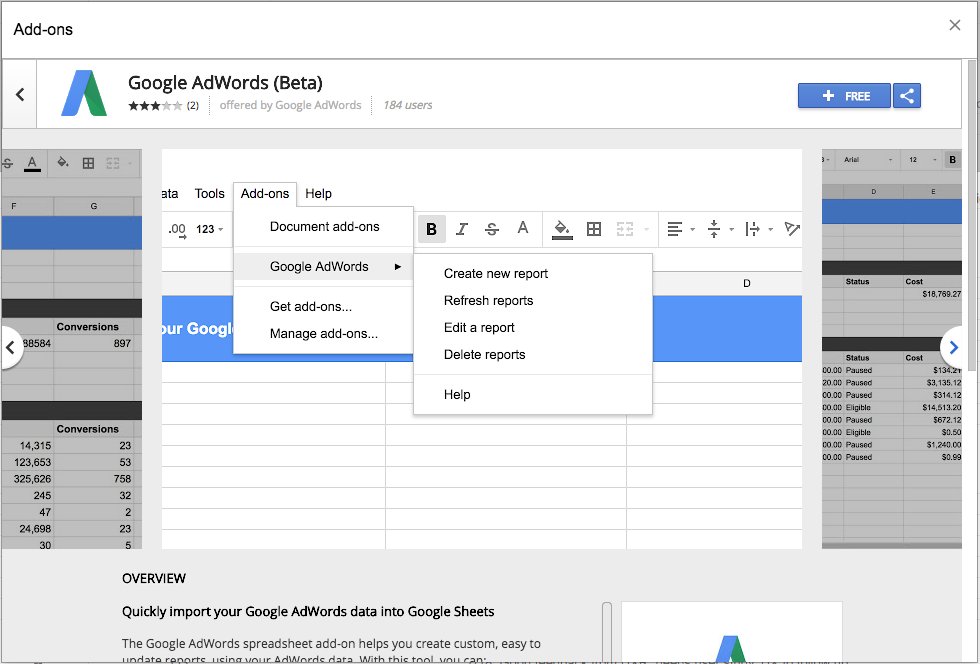
Извлечение таблицы из изображения и ее копирование
В области Приложение Office проведите пальцем вниз, а затем вверх. Фокус перемещается на строку навигации в нижней части экрана.
Проводите пальцем влево или вправо, пока не услышите “Действия”, а затем дважды коснитесь экрана. Откроется меню Действия.
Проводите пальцем влево, пока не услышите “Изображение в таблицу”, а затем дважды коснитесь экрана. Активируется режим камеры.
Выполните одно из указанных ниже действий.
Чтобы сделать снимок с помощью камеры устройства, назначите камеру на таблицу, а затем проводите пальцем вправо, пока не услышите “Сделать снимок”, а затем дважды коснитесь экрана.
Чтобы выбрать существующий рисунок, проводите пальцем вправо, пока не услышите “Галерея” и имя нужного рисунка, а затем дважды коснитесь экрана.
Если изображения нет в коллекции, проводите пальцем вправо, пока не услышите “Выбрать фотографию из библиотеки”, а затем дважды коснитесь экрана. Откроется приложение для сохраненных изображений. Вам может быть предложено разрешить приложению доступ к изображениям. Найдите изображение и дважды коснитесь экрана, чтобы выбрать его.
Вам может быть предложено разрешить приложению доступ к изображениям. Найдите изображение и дважды коснитесь экрана, чтобы выбрать его.
Вы услышите: “Обрезать изображение”. Теперь вы можете обрезать изображение, если нужно, чтобы на изображении была только таблица. Проводите пальцем вправо, пока не найдете нужный обрезный лад, а затем дважды коснитесь экрана и удерживайте палец, чтобы настроить область обрезки. Возможно, вам понадобится кто-то, кто поможет вам в этом.
После этого проводите пальцем вправо, пока не услышите “Подтвердить”, а затем дважды коснитесь экрана. Начнется Приложение Office обработка изображения.
После извлечения таблицы вы услышите: “Таблица, извлеченная из изображения”. Чтобы прочитать содержимое строк таблицы, проведите пальцем вправо. Вы услышите содержимое ячейки и ее положение в таблице.
Чтобы скопировать таблицу, проводите пальцем вправо, пока не услышите “Копировать таблицу”, а затем дважды коснитесь экрана. Вы услышите: “Таблица скопирована”. Теперь вы можете в таблицу, в которой ее использовать, например в сообщении электронной почты или на PowerPoint слайде.
Теперь вы можете в таблицу, в которой ее использовать, например в сообщении электронной почты или на PowerPoint слайде.
Если вы услышите сообщение “Оповещение, значок”, а не “Таблица, скопирована”, это означает, что Приложение Office обнаружены возможные ошибки, например орфографию. Чтобы продолжить, не просматривая таблицу, проводите пальцем вправо, пока не услышите “Все равно Копировать”, а затем дважды коснитесь экрана.
Чтобы просмотреть возможные ошибки в таблице:
Проводите пальцем вправо, пока не услышите “Просмотреть все”, а затем дважды коснитесь экрана.
Фокус перемещается в ячейку с подозрительной ошибкой, и вы услышите текущее содержимое ячейки. Чтобы исправить ошибку, используйте экранную клавиатуру, а затем проводите пальцем влево, пока не услышите сообщение “Готово, кнопка”, а затем дважды коснитесь экрана.
Если в ячейке нет ничего исправить, проводите пальцем вправо, пока не дойдете до кнопки Игнорировать, а затем дважды коснитесь экрана.
Фокус перемещается в следующую ячейку с возможной ошибкой. Просмотрите содержимое ячейки и примите меры, как пошаговому действию выше. После завершения проверки таблица будет скопирована.
Просмотрите содержимое ячейки и примите меры, как пошаговому действию выше. После завершения проверки таблица будет скопирована.
Чтобы выйти из представления таблицы, проведите пальцем вниз, а затем влево. Вы услышите: “Оповещение, отменить таблицу?” Проводите пальцем вправо, пока не услышите “Да”, а затем дважды коснитесь экрана. Фокус вернется в режим камеры.
Чтобы выйти из режима камеры и вернуться в меню Действия, проведите пальцем вниз, а затем влево.
См. также
Техническая поддержка пользователей с ограниченными возможностями
Корпорация Майкрософт стремится к тому, чтобы все наши клиенты получали наилучшие продукты и обслуживание. Если у вас ограниченные возможности или вас интересуют вопросы, связанные со специальными возможностями, обратитесь в службу Microsoft Disability Answer Desk для получения технической поддержки. Специалисты Microsoft Disability Answer Desk знакомы со многими популярными специальными возможностями и могут оказывать поддержку на английском, испанском, французском языках, а также на американском жестовом языке.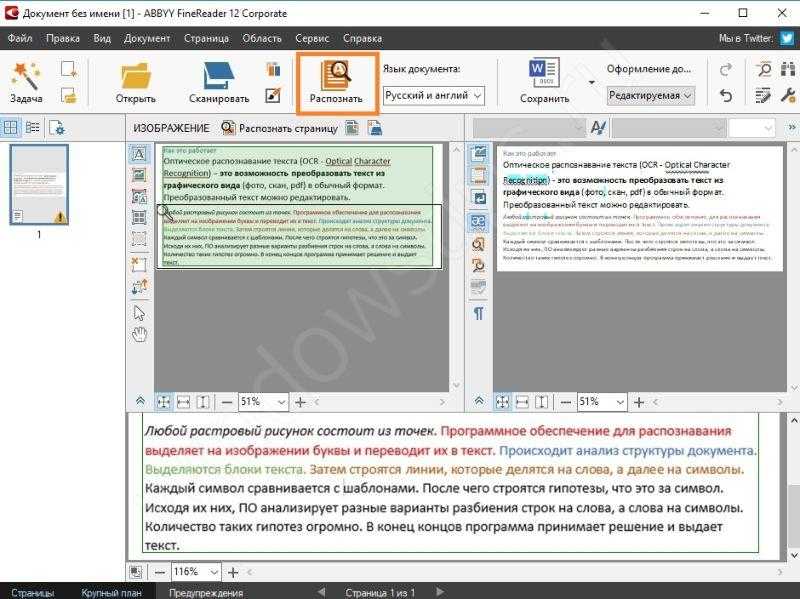 Перейдите на сайт Microsoft Disability Answer Desk, чтобы узнать контактные сведения для вашего региона.
Перейдите на сайт Microsoft Disability Answer Desk, чтобы узнать контактные сведения для вашего региона.
Если вы представитель государственного учреждения или коммерческой организации, обратитесь в службу Disability Answer Desk для предприятий.
Как перенести текст с фото в Word
Процедура копирования и вставки текста в Word или другой текстовый редактор из разных документов и сайтов выполняется очень просто, но бывает, что перенести текст в Word нужно с фото или иного изображения. Перепечатывать его вручную — труд неблагодарный, гораздо проще воспользоваться специальными сервисами и программами для автоматического распознавания текста.
- 1 Как перенести текст с фото в Word онлайн: 5 сервисов
- 1.1 Convertio
- 1.2 Img2txt
- 1.3 Online OCR
- 1.4 Free Online OCR
- 1.5 ABBYY FineReader Online
 3 Microsoft OneNote
3 Microsoft OneNoteКак перенести текст с фото в Word онлайн: 5 сервисов
Прибегают к ним, как правило, для переноса текста с фото в Word в небольших объемах, а также тогда, когда операция носит разовый характер. Подавляющее большинство таких сервисов являются условно-бесплатными, при этом в бесплатном режиме они ограничивают функционал — устанавливают лимиты на объем текста, количество языков, требуют обязательной регистрации и так далее.
Convertio
Хороший сервис для перевода текста с фото в Word, понимает несколько десятков языков, работает с PDF и популярными форматами растровых изображений, позволяет сканировать до 10 страниц в бесплатном режиме. Результат сканирования может быть сохранен в 9 форматов, включая Word.
- На странице сервиса нажмите «Выберите файлы» и укажите изображение на диске. Можно последовательно добавить еще 9 файлов;
- Укажите распознаваемый язык (по умолчанию русский) и формат сохранения;
- Нажмите «Распознать», а затем появившуюся чуть выше кнопку «Скачать».

- Не требует обязательной регистрации.
- Загрузка с Dropbox, Google Drive и по URL.
- Плохо работает с изображениями с многоцветным фоном.
Img2txt
Бесплатный онлайн-сканер текста с фото для Word, поддерживает работу с растровыми изображениями и PDF-документами размером не более 8 Мб.
- Выберите файл нажатием одноименной кнопки;
- Укажите язык распознаваемого текста;
- Нажмите «Загрузить» и дождитесь результата;
- Прокрутите страницу немного вниз, нажмите «Скачать» и укажите формат Word.
- Совершенно бесплатен и не требует регистрации.
- Предпросмотр результатов конвертации текста с фото в Word.
- Может распознавать текст даже из картинок с цветным фоном, но не исключены и ошибки.
- Размер фото не должен превышать 8 Мб.
Online OCR
Этот бесплатный сервис позиционируется как конвертер PDF в Word с оптическим распознаванием, но с таким же успехом он может быть использован как преобразователь текста с фото в Word в режиме онлайн. Без регистрации позволяет вытащить из фото текст в Word до 15 раз в час.
Без регистрации позволяет вытащить из фото текст в Word до 15 раз в час.
- Нажмите кнопку «Файл» и выберите на жестком диске фото;
- Укажите язык распознавания и выходной формат файла DOСX;
- Нажмите «Конвертировать», отредактируйте, если потребуется, текст в поле предпросмотра и скачайте выходной файл.
- Регистрироваться необязательно.
- Распознаёт текст с картинок с цветным фоном с выводом в область предпросмотра.
- Поддерживает распознавание текста с фото в Word в пакетном режиме.
- При извлечении текста из цветного фото текст иногда приходится копировать из области предпросмотра, так как при сохранении даже хорошо распознанного текста в Word в файл вставляется картинка-исходник.
- Разрешение картинки должно быть не менее 200 DPI, в противном случает текст будет содержать много ошибок.
Free Online OCR
Неказистый на вид, но достаточно неплохой англоязычный сервис, позволяющий распознать текст с фото в Word онлайн. В отличие от аналогичных ресурсов, Free Online OCR умеет автоматически определять язык текста на изображении, поддерживается добавление дополнительных локализаций на случай, если фото содержит текст двух языков. Из дополнительных возможностей стоит отметить поворот картинки на 180°, 90° вправо/влево, а также разделение многоколоночного текста на столбцы.
В отличие от аналогичных ресурсов, Free Online OCR умеет автоматически определять язык текста на изображении, поддерживается добавление дополнительных локализаций на случай, если фото содержит текст двух языков. Из дополнительных возможностей стоит отметить поворот картинки на 180°, 90° вправо/влево, а также разделение многоколоночного текста на столбцы.
- Нажмите кнопку выбора файла, а когда его имя появится рядом с кнопкой, нажмите «Preview»;
- Убедитесь, что программа точно определила язык, если нужно, добавьте кликом по полю «Recognition language(s) (you can select multiple)» второй язык.
- Нажмите кнопку «OCR» для запуска процедуры распознавания.
- Проверьте корректность распознавания, в меню выберите Download → DOC.
- Прост и удобен.
- Наличие дополнительных опций.
- Имеется возможность выбрать конкретный участок изображения.
- Нет поддержки пакетного режима.

- Иногда игнорирует второй язык.
- Не поддерживает конвертирование в DOCX.
ABBYY FineReader Online
Наиболее известный и качественный сервис, позволяющий выполнить распознавание текста с фото в Word онлайн. Отличается функциональностью, поддержкой множества языков и девяти форматов, загрузкой файлов с облачных хранилищ, а также сохранением результатов в облачные хранилища.
- Зайдите на сервис с помощью учетной записи Facebook, Google или Microsoft;
- Нажатием одноименной кнопки загрузите изображения с текстом;
- Выберите язык документа и формат сохранения;
- Нажмите «Распознать»;
- Скачайте готовый файл на следующей странице.
- Отличное качество распознавания.
- Пакетный режим.
- Требуется обязательная регистрация.
- В бесплатном режиме можно обработать не более 12 документов.
- Текст в документах Word может нуждаться в дополнительном форматировании.

Программы для преобразования текста с фото в Word
Перед переносом текста с фото в Word онлайн использование программ имеет некоторые преимущества. Так, наиболее мощные из них могут работать в оффлайн режиме, обладая при этом куда более широкими и гибкими настройками OCR. Кроме того, подобные приложения позволяют работать с документами Word напрямую, вставляя в них распознанный текст прямо из буфера обмена.
ABBYY Screenshot Reader
Пожалуй, самый удобный инструмент, позволяющий сконвертировать нераспознанный текст с фото в Word-документ, обычный текстовый файл или передать в буфер обмена для дальнейшего использования. Программой поддерживается около 200 естественных, специальных и формальных языков, захват может производиться целого экрана (с отсрочкой и без), окна и выделенной области. Пользоваться ABBYY Screenshot Reader очень просто.
- Запустите приложение и выберите область сканирования и язык распознавания;
- Укажите в окошке-панели, куда нужно передать распознанный текст;
- Нажмите в правой части кнопку запуска операции;
- Используйте полученный текст по назначению.

Readiris Pro
«Понимает» более 100 языков, умеет работать с PDF, DJVU и внешними сканерами, с разными типами графических файлов, в том числе многостраничными. Поддерживает интеграцию с популярными облачными сервисами, коррекцию перспективы страницы, позволяет настраивать форматирование. Посмотрим для примера, как скопировать текст с фото в Word в этой сложной на первый взгляд программе.
- Перетащите на окно изображение, после чего будет автоматически произведено распознавание имеющегося на нём текста;
- В меню «Выходной файл» выберите Microsoft Word DOCX и сохраните документ.
- Кликните правой кнопкой мыши по изображению и выберите в контекстном меню Readiris →Convert to Word;
- Получите готовый файл в исходном каталоге.
- Функциональна и удобна.
- Интеграция с облачными сервисами.
- Позволяет конвертировать фото в текст Word через меню Проводника.
- Платная, не лучшим образом справляется с изображениями с разноцветным фоном.
Microsoft OneNote
Если у вас установлен офисный пакет Microsoft, то среди приложений должна быть программа OneNote — записная книжка с поддержкой распознавания текста из картинок. Приложение также входит в состав всех версий Windows 10. Хорошо, взглянем, как перенести текст в Word с ее помощью.
- Запустите OneNote и перетащите на ее окно изображение с текстом;
- Выделив изображение, нажмите по нему правой кнопкой мыши и выберите в меню Поиск текста в рисунках → Свой язык;
- Вызовите контекстное меню для картинки повторно и на этот раз выберите в нём опцию «Копировать текст из рисунка»;
- Вставьте из буфера обмена распознанный текст из рисунка в Word или другой редактор.
- Высокое качество распознавания текста даже на цветном фоне.
- Работа в автономном режиме.
- Бесплатна.
- Не столь удобна, как две предыдущие программы.

- Текст вставляется в Word-документ только через буфер.
- Мало доступных языков (русский есть).
Трудности при копировании текста с фото в Word
Итак, мы разобрали как перевести текст с фото в Word онлайн и с помощью программ, упустив, однако, из вида одну важную деталь. Как бы ни были хороши сервисы и OCR-программы, все они испытывают трудности с распознаванием «экзотических» шрифтов и рукописного текста, возвращая абракадабру или исходное изображение. Поскольку подобные шрифты встречаются редко, разработчики десктопного ПО мало уделяют внимания алгоритмам распознавания с использованием искусственного интеллекта, однако со временем всё меняется и приложения совершенствуются.
Table OCR – Rossum.ai
Сегодня данные являются одной из самых важных валют в деловом мире. Без этого вы не сможете связаться с вашими конкурентами. С его помощью вы сможете автоматизировать бизнес-процессы, добиться большей масштабируемости и получить больше информации для обучения своих сотрудников. Данные — король. Однако первая проблема, с которой мы сталкиваемся, заключается в следующем: как мы собираем данные? Чтобы данные можно было использовать в системах или других процессах, они должны быть в структурированном формате.
Данные — король. Однако первая проблема, с которой мы сталкиваемся, заключается в следующем: как мы собираем данные? Чтобы данные можно было использовать в системах или других процессах, они должны быть в структурированном формате.
Проблема заключается в том, что большинство бизнес-данных в настоящее время хранится в неструктурированных типах данных, таких как документы и таблицы PDF, изображения и другие форматы, из которых машинам трудно считывать данные. Общая цель решения OCR состоит в том, чтобы преобразовать эту неструктурированную информацию в пригодные для использования данные путем цифрового сканирования документа, а затем извлечения и записи данных в этом документе. Этот процесс может позволить вам автоматизировать целые бизнес-процессы, предоставить облачный доступ к документам и привести к повышению производительности и мотивации команды.
Одна невероятно распространенная часть документа, которой вы хотели бы управлять, — это таблицы. Изображения таблиц или PDF-файлы таблиц, содержащие важные данные, исторически были невероятно сложными для понимания машинами. В идеальном мире изображение стола должно быть отсканировано в систему. Затем система идентифицирует строки и столбцы и создаст их, чтобы заполнить соответствующие ячейки соответствующими данными. Затем эта цифровая таблица будет экспортирована в пригодный для использования формат, такой как электронная таблица Excel.
В идеальном мире изображение стола должно быть отсканировано в систему. Затем система идентифицирует строки и столбцы и создаст их, чтобы заполнить соответствующие ячейки соответствующими данными. Затем эта цифровая таблица будет экспортирована в пригодный для использования формат, такой как электронная таблица Excel.
Идеально, но случается очень редко. Это заставляет задуматься, как преобразовать изображения в текст в Excel. Даже дорогие решения OCR, которые обещают функции захвата табличных данных, часто работают очень плохо. Это означает, что вашим сотрудникам придется регулярно приходить и исправлять все ошибки, которые допустила машина. Table OCR — это то, над чем постоянно работает команда Rossum.
Мы обнаружили проблему с инструментами OCR для преобразования изображений в Excel и создали систему, которая теперь может быть лучшим конвертером изображений в Excel. Одним из других замечательных аспектов Rossum является то, что наша таблица OCR происходит в нашем простом в использовании интерфейсе проверки, который позволяет вам быстро и легко уточнять данные, полученные OCR, всего за несколько кликов.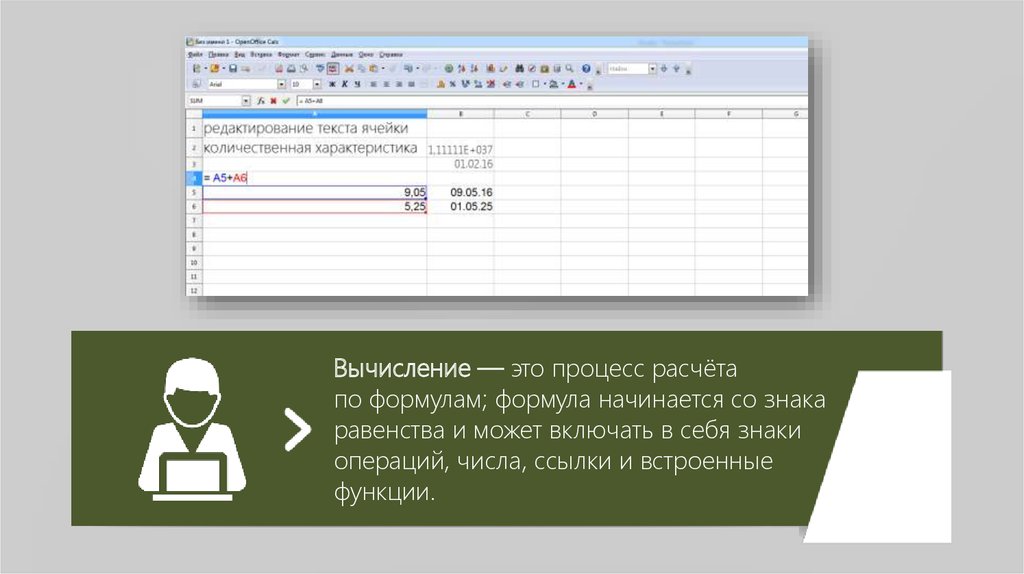 После этого таблицу можно экспортировать в выбранный вами формат.
После этого таблицу можно экспортировать в выбранный вами формат.
Извлечь таблицу из изображения
Цель звучит просто — «извлечь таблицу из изображения», но эксперты годами пытались создать решение, которое могло бы безупречно извлекать данные из изображения таблицы и экспортировать их в структурированный табличный формат. как Эксель. Трудности, которые возникают у машин с такими командами, как «преобразовать изображение в таблицу Excel», не ощущаются сотрудниками-людьми. Вот почему в течение стольких лет вводом данных занимались люди. Они отвечали за выполнение каждой задачи в контрольном списке, включая «извлечение данных из изображения в Excel». Это самая мощная форма сбора данных. Одна из основных проблем использования OCR для таблиц заключается в том, что они изо всех сил пытаются обнаружить таблицу. Подобные системы ищут шаблоны, чтобы знать, на что они смотрят.
Проблема в том, что существует огромное количество различий в способах организации таблиц в изображениях и файлах PDF, что затрудняет изучение шаблонов машинами.
Чтобы решить эту проблему, в 2019 году мы выпустили систему, которая может легко и почти со 100% точностью эффективно извлекать данные из изображений таблиц.
Для достижения этой цели наше решение в значительной степени опирается на машинное обучение и искусственный интеллект. Благодаря нейронным сетям, которые имитируют то, как наш мозг обрабатывает информацию, Rossum обладает уникально мощной способностью собирать данные из всех видов неструктурированных форматов.
Одним из примеров в области управления документами, где эта технология может быть очень полезной, является обработка счетов в отделе кредиторской задолженности. Часто в документах счетов-фактур есть позиции и таблицы. Если у вас есть система, которая может распознавать эти таблицы в счетах-фактурах, вы можете зафиксировать все содержащиеся в них данные. Такой автоматический сбор данных открывает всевозможные возможности для автоматизации ваших бизнес-процессов и открывает новые пути для развития вашего бизнеса.
Таблица OCR API
Хорошо построенный API OCR для таблиц должен иметь возможность сканировать документы и изображения и точно извлекать из них табличные данные. API-интерфейс OCR Rossum специально разработан для точной обработки таблиц из любого канала. Это жизненно важно, если вы хотите иметь возможность использовать данные в этих таблицах для целей автоматизации.
Когнитивные платформы OCR используют ИИ для «чтения» документов, как это делают люди, и могут работать намного быстрее и эффективнее. Хороший API-интерфейс OCR может обрабатывать большие объемы документов и при этом гарантировать, что все данные будут получены, захвачены и экспортированы правильно. Использование решения OCR как части общей стратегии автоматизации может в конечном итоге высвободить время для ваших сотрудников и команд, чтобы они могли сосредоточиться на задачах, которые могут способствовать развитию вашего бизнеса.
Автоматизация также обеспечивает масштабируемость. В прошлом такие команды, как кредиторская задолженность, могли сдерживать рост компании. Эти команды будут быстро перегружены из-за резкого увеличения объема заказов и счетов-фактур, которым необходимо управлять. Это может привести к уходу некоторых членов команды или совершению ошибок, которые могут привести к дальнейшим задержкам. Благодаря автоматизированной системе, работающей на базе API OCR для таблиц, вы можете быть уверены, что колебания объема заказа не нарушат обычные операции, а рост станет намного проще.
Эти команды будут быстро перегружены из-за резкого увеличения объема заказов и счетов-фактур, которым необходимо управлять. Это может привести к уходу некоторых членов команды или совершению ошибок, которые могут привести к дальнейшим задержкам. Благодаря автоматизированной системе, работающей на базе API OCR для таблиц, вы можете быть уверены, что колебания объема заказа не нарушат обычные операции, а рост станет намного проще.
Извлечение таблицы OCR
За прошедшие годы появилось несколько различных методов для достижения точного извлечения таблицы OCR. Python — один из самых популярных и простых в освоении языков программирования. Было написано несколько программ извлечения таблиц из изображения в Excel для преобразования Python, которые позволяют захватывать данные.
Некоторые программисты написали программы OpenCV Python для обнаружения таблиц. В этом случае OpenCV используется вместе с Python. OpenCV — это набор алгоритмов, которые позволяют компьютерной программе обнаруживать объекты и источники данных в изображениях и других документах.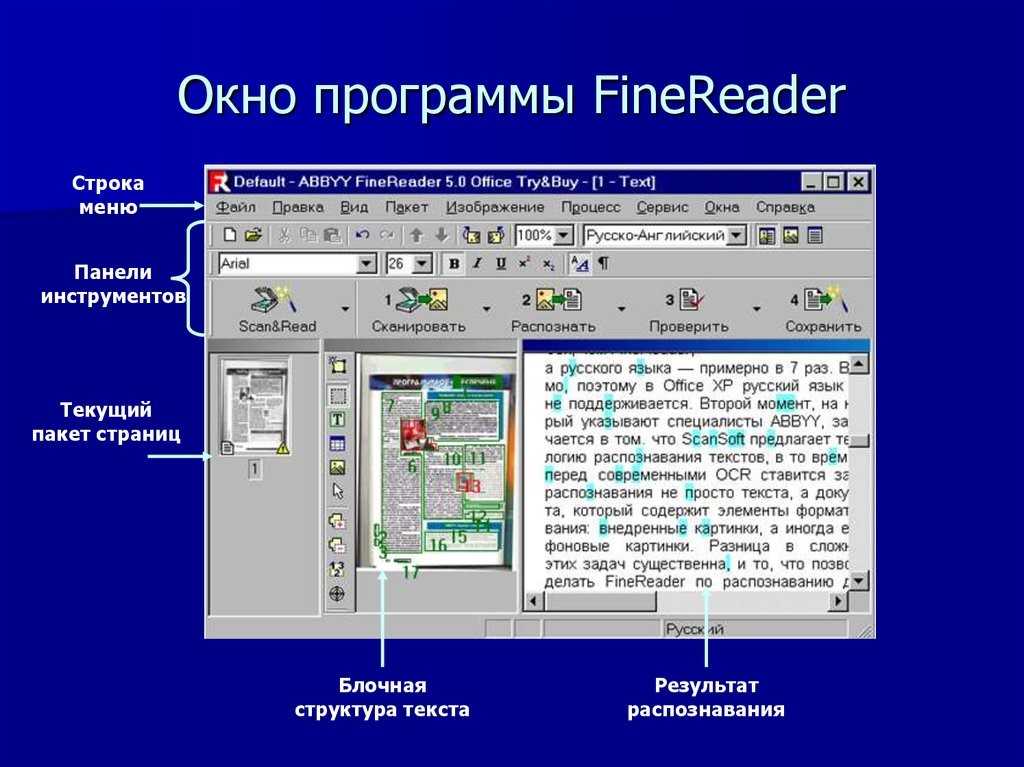 Это касается основ создания программы OCR, но некоторые механизмы сканирования были созданы с использованием не более 30 строк кода.
Это касается основ создания программы OCR, но некоторые механизмы сканирования были созданы с использованием не более 30 строк кода.
Это может показаться обманчиво простым, но технология разрабатывалась годами и до сих пор не совершенна. Программы Python для распознавания таблиц Tesseract OCR представляют собой еще одну категорию готовых вариантов извлечения таблиц. Это программы на Python, которые используют механизм распознавания текста Tesseract для сканирования. Ограничение использования этих программ «извлечение таблицы из изображения онлайн» заключается в том, что они не являются полностью встроенными решениями. Им не хватает функций безопасности и полной функциональности, необходимой в бизнес-среде.
Тем не менее, вы можете многое узнать об извлечении таблицы OCR, изучив некоторые технические коды, которые делают это возможным.
Глубокое обучение распознаванию структуры таблиц
В основе таких инноваций, как программы Tesseract OCR для распознавания таблиц Python, лежит глубокое обучение. Для создания онлайн-решения OCR таблиц требуется искусственный интеллект. Глубокое обучение является частью дисциплин как машинного обучения, так и более широкого термина искусственного интеллекта.
Для создания онлайн-решения OCR таблиц требуется искусственный интеллект. Глубокое обучение является частью дисциплин как машинного обучения, так и более широкого термина искусственного интеллекта.
По сути, для успешного создания извлеченной таблицы из отсканированного PDF-файла Python-программы требуется система с глубоким обучением. Проще говоря, глубокое обучение относится к процессу обучения компьютеров распознавать закономерности. Нейронные сети — это технология, которая поддерживает глубокое обучение и делает его возможным.
Нейронные сети предназначены для помощи вычислительной системе в обучении и хранении информации таким же образом, как человеческий мозг хранит информацию. Другими словами, нейронные сети позволяют компьютеру «учиться». Почему глубокое обучение имеет значение, когда мы хотим извлечь таблицы из отсканированных PDF-файлов?
Препятствием, возникающим при попытках сканирования изображений для таблиц данных, является изменчивость способа отображения таблиц. Компьютеру может быть очень трудно распознавать закономерности, когда существует так много разных возможностей. Эта задача требует, чтобы компьютер мог использовать более высокий уровень абстрактных рассуждений, чем обычно требуется от систем искусственного интеллекта. Вот почему глубокое обучение распознаванию структуры таблиц так важно для этого обсуждения.
Компьютеру может быть очень трудно распознавать закономерности, когда существует так много разных возможностей. Эта задача требует, чтобы компьютер мог использовать более высокий уровень абстрактных рассуждений, чем обычно требуется от систем искусственного интеллекта. Вот почему глубокое обучение распознаванию структуры таблиц так важно для этого обсуждения.
OCR на таблицу
Когда дело доходит до «бесплатных» вещей, иногда вы получаете то, за что платите. Хотя вы можете найти решение без OCR для таблиц, возможно, вы не получите нужного вам качества. Большинство этих программ очень подвержены ошибкам.
Rossum обеспечивает высококачественное преобразование OCR в таблицу как часть нашего общего решения для интеллектуальной обработки документов (IDP). Если вы хотите по-настоящему раскрыть свои бизнес-данные и создать новые возможности автоматизации, вам нужно выйти за рамки простого сбора данных OCR и использовать комплексное решение IDP, такое как Rossum.
Мы упрощаем преобразование большого количества документов в более полезные формы данных. С Rossum процесс преобразования таблицы OCR в Excel прост и понятен, что экономит ваше время, чтобы вы могли сосредоточиться на развитии своего бизнеса.
С Rossum процесс преобразования таблицы OCR в Excel прост и понятен, что экономит ваше время, чтобы вы могли сосредоточиться на развитии своего бизнеса.
Алгоритм обнаружения таблиц, распознавания ячеек и извлечения текста для преобразования таблиц в изображениях в файлы Excel | от Hucker Marius
Как превратить скриншоты таблицы в редактируемые данные с помощью OpenCV и pytesseract
источник: pixabay Допустим, у вас есть таблица в статье, pdf или изображение, и вы хотите перенести ее в таблицу Excel или фрейм данных, чтобы иметь возможность редактировать ее. Особенно в области предварительной обработки для машинного обучения этот алгоритм будет исключительно полезен для преобразования многих изображений и таблиц в редактируемые данные.
В случае, если ваши данные существуют из текстовых PDF-файлов , уже существует несколько бесплатных решений. Самые популярные из них: табличный , камелот/excalibur , который вы можете найти на https://tabula. technology/, https://camelot-py.readthedocs.io/en/master/, https://excalibur- py.readthedocs.io/en/master/.
technology/, https://camelot-py.readthedocs.io/en/master/, https://excalibur- py.readthedocs.io/en/master/.
Однако что, если ваш PDF-файл основан на изображениях или если вы найдете статью с таблицей в Интернете? Почему бы просто не сделать снимок экрана и не преобразовать его в лист Excel? Поскольку, похоже, не существует бесплатного программного обеспечения с открытым исходным кодом для данных на основе изображений (jpg, png, pdf на основе изображений и т. д.), возникла идея разработать универсальное решение для преобразования таблиц в редактируемые файлы Excel.
Но пока хватит, посмотрим, как это работает.
Алгоритм состоит из трех частей: первая – это обнаружение таблицы и распознавание ячеек с Открытие CV , вторая часть – тщательное распределение ячеек по соответствующей строке и столбцу, а третья часть – извлечение каждой выделенной ячейки с помощью оптического распознавания символов (OCR) с pytesseract .
Как и большинство алгоритмов распознавания таблиц, этот основан на линейной структуре таблицы. Четкие и различимые линии необходимы для правильной идентификации клеток. Таблицы с прерывистыми линиями, пробелами и дырками приводят к худшей идентификации, и ячейки, лишь частично окруженные линиями, не обнаруживаются. Если в некоторых ваших документах есть неработающие строки, обязательно прочитайте эту статью и исправьте строки: Нажмите здесь.
Четкие и различимые линии необходимы для правильной идентификации клеток. Таблицы с прерывистыми линиями, пробелами и дырками приводят к худшей идентификации, и ячейки, лишь частично окруженные линиями, не обнаруживаются. Если в некоторых ваших документах есть неработающие строки, обязательно прочитайте эту статью и исправьте строки: Нажмите здесь.
Во-первых, нам нужны входные данные, в моем случае это скриншот в формате png. Цель состоит в том, чтобы иметь фрейм данных и excel-файл с идентичной табличной структурой, где каждую ячейку можно редактировать и использовать для дальнейшего анализа.
Входные данные для дальнейшего распознавания и извлечения таблицы.Импортируем необходимые библиотеки.
Для получения дополнительной информации о библиотеках:
cv2 — https://opencv.org/
pytesseract — https://pypi.org/project/pytesseract/
import cv2
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import csvtry:
from PIL import Image
except ImportError:
import Image
import pytesseract
Первый шаг — прочитать ваш файл по правильному пути, используя пороговое значение для преобразования входного изображения в двоичное изображение и инвертируя его, чтобы получить черный фон, белые линии и шрифты.
#прочитать ваш файлБинарное перевернутое изображение.
file=r'/Users/ВАШ ПУТЬ/testcv.png'
img = cv2.imread(file,0)
img.shape #пороговое преобразование изображения в двоичное изображение
thresh, img_bin = cv2.threshold(img,128,255,cv2.THRESH_BINARY |cv2.THRESH_OTSU) #инвертирование изображения
img_bin = 255-img_bin
cv2.imwrite('/Users/YOURPATH/cv_inverted.png',img_6bin) Построение изображения для просмотра вывода
plotting = plt.imshow(img_bin,cmap='gray')
plt.show()
Следите за новыми статьями Мариуса Хакера
Следите за новыми статьями Мариуса Хакера Зарегистрировавшись, вы создадите учетную запись Medium, если у вас ее еще нет…
medium.com
Следующий шаг — определить ядро для обнаружения прямоугольных блоков и, следовательно, табличную структуру. Во-первых, мы определяем длину ядра и, следуя вертикальным и горизонтальным ядрам, обнаруживаем позже все вертикальные линии и все горизонтальные линии.
# Длина (ширина) ядра в сотой части общей ширины
kernel_len = np.array(img).shape[1]//100 # Определение вертикального ядра для обнаружения всех вертикальных линий изображения
ver_kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (1, kernel_len)) # Определение горизонтального ядра для обнаружения всех горизонтальных линий изображения 2x2
ядро = cv2.getStructuringElement(cv2.MORPH_RECT, (2, 2))
Следующим шагом является обнаружение вертикальных линий.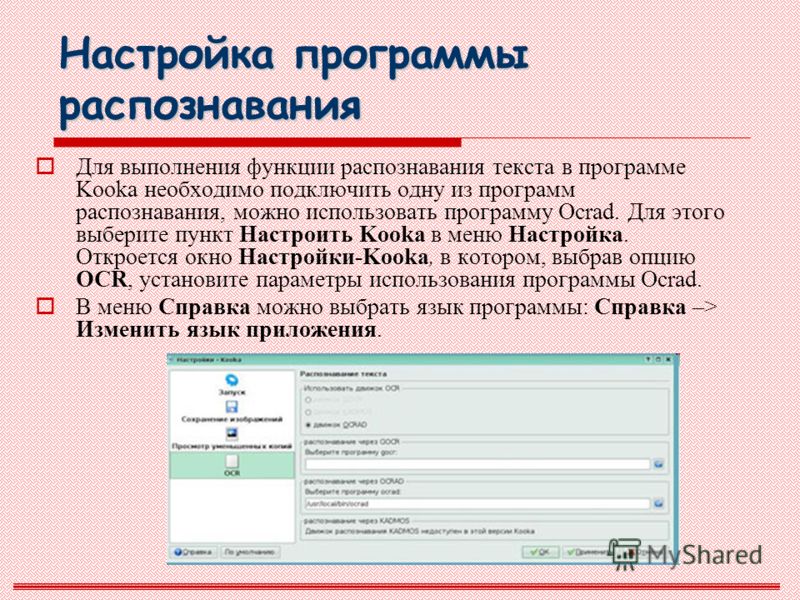
# Использовать вертикальное ядро для обнаружения и сохранения вертикальных линий в jpg .imwrite("/Users/YOURPATH/vertical.jpg",vertical_lines) #Нарисуйте сгенерированное изображение
plotting = plt.imshow(image_1,cmap='gray')
plt.show() Извлеченные вертикальные линии.Теперь то же самое для всех горизонтальных линий.
# Использовать горизонтальное ядро для обнаружения и сохранения горизонтальных линий в jpg .imwrite("/Users/YOURPATH/horizontal.jpg",horizontal_lines) #Постройте сгенерированное изображение
plotting = plt.imshow(image_2,cmap='gray')
plt.show() Извлеченные горизонтальные линии.Мы объединяем горизонтальные и вертикальные линии в третье изображение, взвешивая обе с коэффициентом 0,5. Цель состоит в том, чтобы получить четкую табличную структуру для обнаружения каждой ячейки.
# Объединить горизонтальные и вертикальные линии в новом третьем изображении с одинаковым весом.Извлеченная табличная структура без содержания текста.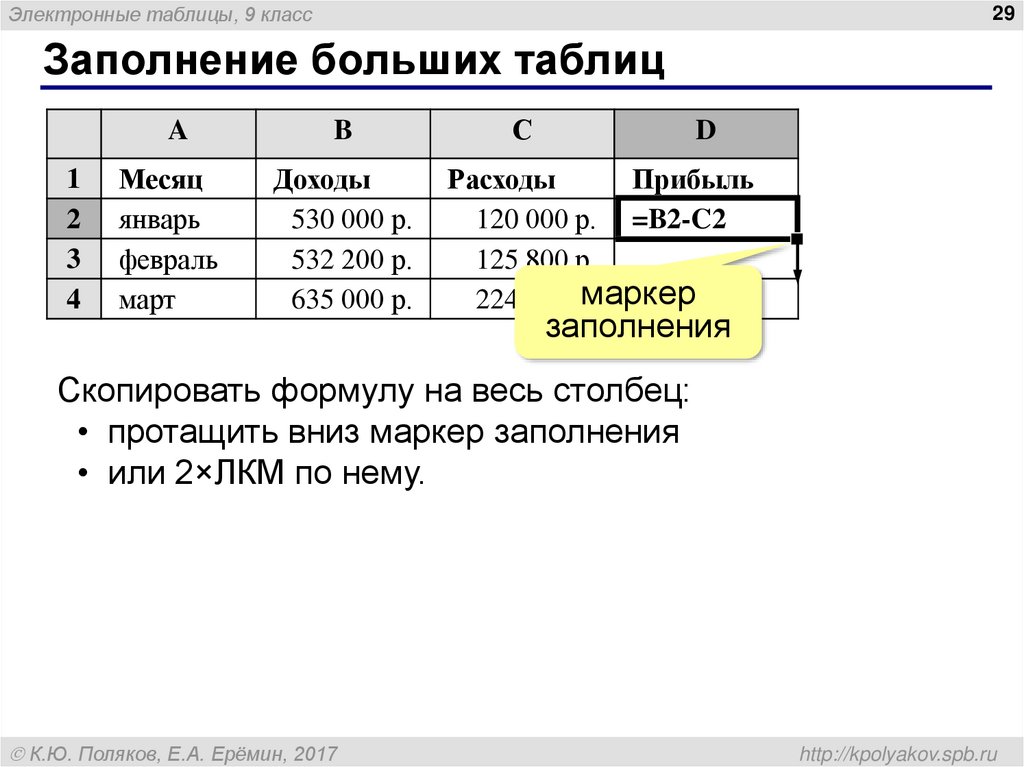
img_vh = cv2.addWeighted(vertical_lines, 0.5, horizontal_lines, 0.5, 0.0) #Эрозия и задержка изображения (img_vh,128,255, cv2.THRESH_BINARY | cv2.THRESH_OTSU)
cv2.imwrite("/Users/ВАШ ПУТЬ/img_vh.jpg", img_vh)bitxor = cv2.bitwise_xor(img,img_vh)
bitnot = cv2.bitwise_not(bitxor) #Построение сгенерированного изображения
plotting = plt.imshow(bitnot,cmap='gray')
plt.show()
Получив табличную структуру, мы используем функцию findContours для обнаружения контуров. Это помогает нам получить точные координаты каждой коробки.
# Определить контуры для обнаружения следующего блока
контуры, иерархия = cv2.findContours(img_vh, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
Следующая функция необходима для получения последовательности контуров и их сортировки сверху вниз (https://www.pyimagesearch.com/2015/04/20/sorting-contours-using-python-and- opencv/).
def sort_contours(cnts, method="left-to-right"): # инициализируем флаг реверса и индекс сортировки
reverse = False
i = 0 # обрабатываем, нужно ли сортировать в обратном порядке
if method == "справа налево" или метод == "снизу вверх":
reverse = True # обработка, если мы сортируем по координате y, а не по
# x-координата ограничивающей рамки
if method == "сверху вниз" или method == "снизу вверх":
i = 1 # построить список ограничивающих рамок и отсортировать их сверху вниз
# снизу
boundingBoxes = [cv2.boundingRect(c) for c in cnts]
(cnts,boundingBoxes) = zip(*sorted(zip(cnts,boundingBoxes),
key=lambda b:b[1 ][i], reverse=reverse)) # вернуть список отсортированных контуров и ограничивающих рамокe s
return (cnts,boundingBoxes)
# Отсортировать все контуры сверху вниз.
контуры, boundingBoxes = sort_contours(contours, method="сверху вниз")
Дальнейшие шаги необходимы для определения правильного местоположения, что означает правильный столбец и строку, каждой ячейки. Во-первых, нам нужно получить высоту для каждой ячейки и сохранить ее в списке высот. Затем берем среднее с высоты.
Во-первых, нам нужно получить высоту для каждой ячейки и сохранить ее в списке высот. Затем берем среднее с высоты.
# Создание списка высот для всех обнаруженных блоков
heights = [boundingBoxes[i][3] for i in range(len(boundingBoxes))] # Получить среднее значение высот
среднее значение = np.mean(heights)
Затем мы извлекаем позицию, ширину и высоту каждого контура и сохраняем их в списке блоков. Затем мы рисуем прямоугольники вокруг всех наших блоков и строим изображение. В моем случае я сделал это только для блоков шириной меньше 1000 пикселей и высотой 500 пикселей, чтобы игнорировать прямоугольники, которые могут не быть ячейками, например. стол в целом. Эти два значения зависят от размера вашего изображения, поэтому, если ваше изображение намного меньше или больше, вам нужно настроить оба.
# Создать список для хранения всех полей вКаждая ячейка окружена обнаруженными контурами/ коробка.
box = [] # Получить положение (x, y), ширину и высоту для каждого контура и показать контур на изображении
для c в контурах:
x, y, w, h = cv2.boundingRect(c), если (w<1000 и h<500):
image = cv2.rectangle(img,(x,y),(x+w,y+h),(0,255 ,0),2)
box.append([x,y,w,h])ploting = plt.imshow(image,cmap='gray')
plt.show()
Теперь, когда у нас есть каждая ячейка, ее расположение, высота и ширина, нам нужно получить правильное расположение в таблице. Поэтому нам нужно знать, в какой строке и в каком столбце он находится. Пока поле не отличается больше, чем его собственное (высота + среднее значение/2), оно находится в той же строке. Как только разница высот выше текущей (высота + среднее значение/2), мы знаем, что начинается новая строка. Колонки логично расположены слева направо.
#Создание двух списков для определения строки и столбца, в котором ячейка находится (коробка)): if(i==0):
column.append(box[i])
предыдущая=коробка[i] еще:
if(box[i][1]<=previous[1]+mean /2):
column.append(box[i])
предыдущая=box[i] if(i==len(box)-1):
row.append(столбец) else:
row.append(столбец)
столбец=[]
предыдущая = коробка [i]
column.append (box [i]) print (столбец)
print (строка)
Затем мы вычисляем максимальное количество столбцов (ячеек значения), чтобы понять, сколько столбцов наш окончательный кадр данных / таблица буду иметь.
# вычисление максимального количества ячеек countcol = 0
for i in range(len(row)):
countcol = len(row[i])
if countcol > countcol:
countcol = countcol
После того, как максимальное количество ячеек мы сохраняем среднюю точку каждого столбца в списке, создаем массив и сортируем значения.
#Получение центра каждого столбца center = [int(row[i][j][0]+row[i][j][2]/2) для j в диапазоне(len(row[i ])) if row[0]]center=np.array(center)
center.sort()
На данный момент у нас есть все поля и их значения, но, как вы можете видеть в выводе вашего списка строк, значения не всегда сортируются в правильном порядке. Вот что мы делаем дальше относительно расстояния до центра столбцов. Правильную последовательность мы храним в списке finalboxes.
Вот что мы делаем дальше относительно расстояния до центра столбцов. Правильную последовательность мы храним в списке finalboxes.
# Что касается расстояния до центра колонн, то блоки располагаются в соответствующем порядке finalboxes = []for i in range(len(row)):
lis=[]
for k in range(countcol):
lis.append([])
for j in range(len(row[i]) )):
diff = abs(center-(row[i][j][0]+row[i][j][2]/4))
минимум = min(diff)
indexing = list(diff) .index(минимум)
lis[indexing].append(row[i][j])
finalboxes.append(lis)
На следующем шаге мы используем наш список finalboxes. Мы берем каждую коробку на основе изображения, подготавливаем ее к оптическому распознаванию символов, расширяя и разрушая ее, и позволяем pytesseract распознавать содержащиеся в ней строки. Цикл проходит по каждой ячейке и сохраняет значение во внешнем списке.
# из каждой отдельной ячейки/блока на основе изображения строки извлекаются с помощью pytesseract и сохраняются в списке external=[]
для i in range(len(finalboxes)):
для j in range(len(finalboxes) [i])):
inner=''
if(len(finalboxes[i][j])==0):
external.append(' ') else:
для k в диапазоне(len(finalboxes[i ][j])) :
y,x,w,h = finalboxes[i][j][k][0],finalboxes[i][j][k][1], finalboxes[i][j ][k][2],finalboxes[i][j][k][3]
finalimg = bitnot[x:x+h, y:y+w]
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, ( 2, 1))
border = cv2.copyMakeBorder(finalimg,2,2,2,2, cv2.BORDER_CONSTANT,value=[255,255])
resizing = cv2.resize(border, None, fx=2, fy=2, интерполяция=cv2. INTER_CUBIC)
расширение = cv2.dilate (изменение размера, ядро, итерации = 1)
эрозия = cv2.erode (расширение, ядро, итерации = 1)out = pytesseract.image_to_string (эрозия)
if (len (out) == 0):
out = pytesseract.image_to_string(erusion, config='--psm 3')
inner = inner +" "+ out external.append(inner)
Последний шаг — преобразование списка в фрейм данных и сохранение его в excel-файл.
# Создание кадра данных сгенерированного списка OCR .style.set_properties(align="left") #Преобразование в файл excelОкончательный кадр данных в терминале. Окончательный файл excel, содержащий все клетки.
data.to_excel("/Users/YOURPATH/output.xlsx")
Вот и все! Теперь ваша таблица должна быть сохранена в кадре данных и в файле Excel и может использоваться для обработки естественного языка, для дальнейшего анализа с помощью статистики или просто для редактирования. Это работает для таблиц с четкой и простой структурой. В случае, если ваша таблица имеет необычную структуру, в том смысле, что многие ячейки объединены, размер ячеек сильно различается или используется много цветов, алгоритм может быть принят. Кроме того, OCR (pytesseract) почти идеально подходит для распознавания компьютерных шрифтов. Однако если у вас есть таблицы, содержащие рукописный ввод, результаты могут отличаться.
Если вы используете его для своих собственных таблиц, дайте мне знать, как это работает.
Следите за новыми статьями Marius Hucker
Следите за новыми статьями Marius Hucker Зарегистрировавшись, вы создадите учетную запись Medium, если у вас еще нет…
medium. com
com
Также Читать:
Как исправить сломанные строки в распознавании таблиц
Извлечение таблицы с помощью глубокого обучения | Сумья Де | Аналитика Видхья
Создание модели глубокого обучения с помощью TensorFlow для извлечения табличных данных из изображения.
Photo by fabio on UnsplashТаблица — это полезное структурное представление, которое организует данные в строки и столбцы и предназначено для фиксации взаимосвязей между различными элементами и атрибутами в данных.
Таблицы прочно вошли в нашу повседневную жизнь: от простых транзакций до результатов сложного анализа, они стали частью каждой бумаги и документа, где есть даже малейшая необходимость краткого отражения информации.
Технологические достижения в эпоху Интернета и неудобство хранения документов в виде печатных копий вызвали необходимость оцифровки документов, событий, транзакций или любых записей реального мира, включая изображения и другую мультимедийную информацию.
Но использование компьютера имеет большой недостаток. Основная проблема заключается в том, что сегодня в мире существует множество оцифрованных неструктурированных данных, и в этой неструктурированной области эти таблицы не имеют своей первоначальной сути для фиксации отношений; они могут только представить это визуально. С точки зрения человеческого понимания разница между этими визуальными представлениями и структурными представлениями таблиц незначительна. С другой стороны, таблица в неструктурированном виде — не что иное, как заплатка изображения на компьютере.
При решении проблемы нашей основной целью будет понимание таблицы путем выделения ее из неструктурированного формата и восстановления исходной формы с помощью компьютерного зрения.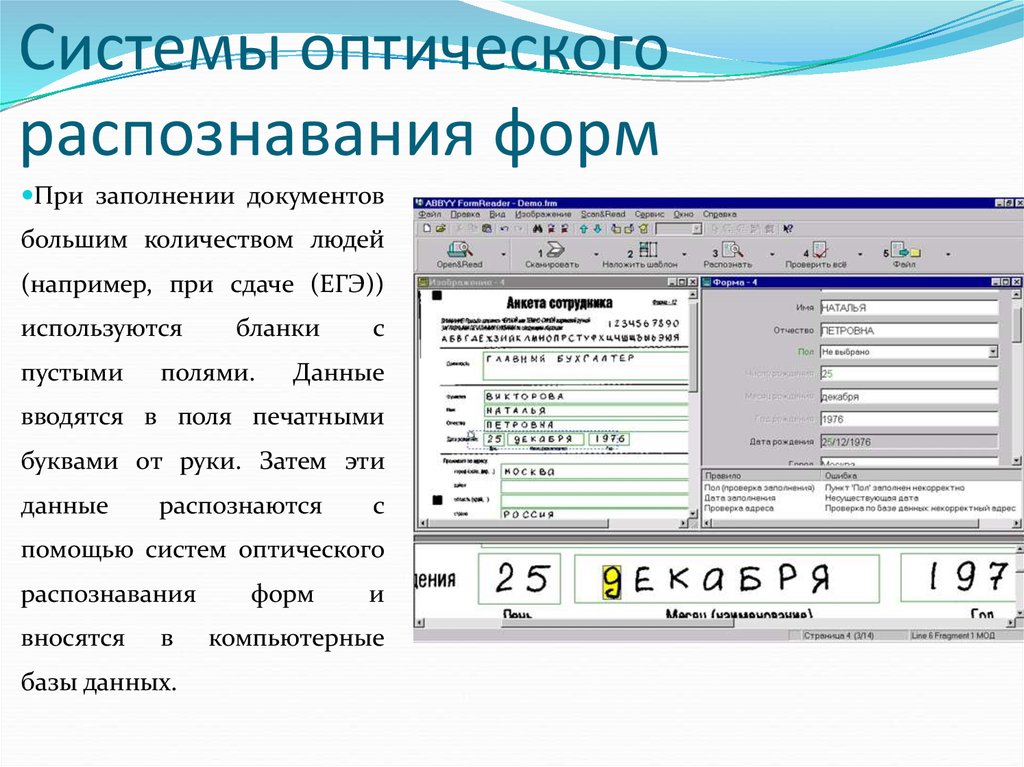
В этом разделе описана структура и представлен общий обзор основных этапов, которые будут рассмотрены в этом блоге.
- Предварительные условия
- Понимание проблемы
- Сбор данных
- Анализ и предварительная обработка
- Related works
- Development
- Conclusions
- Discussions and future works
So, lets get started…
Here is a list of pre-requisites that are needed (or rather , полезно) в создании подобных проектов, основанных на глубоком обучении.
- Виртуальные среды, Python, PIP, концепции машинного и глубокого обучения.
- ТензорФлоу — Посетите официальную документацию, чтобы начать.
- Streamlit — О Streamlit можно узнать из видеоурока от JCharis на Youtube.
 Всегда можно вернуться и узнать то, что требуется!
Всегда можно вернуться и узнать то, что требуется!2.1. Обзор
Целью исследования является разработка системы, которая будет принимать изображение в качестве входных данных и использовать компьютерное зрение для извлечения информации из таблиц, представленных на входном изображении (если таковые имеются). Задачу можно рассматривать как состоящую из четырех основных шагов: i) обнаружение присутствия таблицы на изображении, ii) локализация таблицы на изображении, iii) декодирование структурных отношений между ячейками таблицы и iv) понимание текста внутри каждой ячейки.
Эта задача может быть наивной для пятилетнего ребенка, но если мы совершим более глубокий прыжок в бездну наших мыслей, мы поймем, что обнаружение стола, локализация его на листе бумаги не подчиняется каким-либо жестким правилам. Это автоматически выполняется зрительной корой (абстрагированной от нашего сознательного понимания) как часть нашего познания.
2.2. Использование глубокого обучения
Уже более десяти лет компьютерное зрение признает потенциал глубокого обучения.

В этом исследовании мы будем использовать сверточные нейронные сети (модель глубокого обучения, основанную на совместном использовании параметров) для решения проблемы обнаружения и локализации таблицы на заданном изображении и использовать предопределенный алгоритм OCR для извлечения текста из обнаруженных стол.
Обнаружение и локализация стола могут быть сформулированы как задача сегментации изображения, в которой система должна отделить область таблицы от остальной части изображения, ожидая маскированного изображения стола.
2.3. Ограничения проблемы
Некоторые из основных ограничений, которыми необходимо управлять для этой проблемы:
i) низкая задержка — Поскольку решение предназначено для применения к большому фрагменту изображений документов, модель не должна принимать очень долго извлекать.

ii) изменение данных — Это одно из ключевых ограничений в этой области. В эту эпоху Интернета и IoT модель должна принимать потоковые данные из различных источников и должна обрабатывать различные типы преобразованных изображений (срезанные, повернутые, зашумленные и т. д.).
iii) умеренные требования к пространству — разработанная модель должна иметь низкие требования к памяти. Чтобы устройства могли получить доступ к модели, она должна быть доступна либо напрямую через приложение (небольшое ограничение памяти), либо через API, который в некоторой степени дает нам свободу ограничения памяти.
Глубокое обучение — это основанный на данных метод искусственной нейронной сети, который требует большого количества качественных данных для обучения, чтобы быть эффективным. Table Bank, ICDAR и Marmot — это три важных исследовательских проекта, которые собирают данные для изучения и интерпретации таблиц в изображениях, PDF-файлах и других переносимых форматах и ускоряют исследования и исследования в области понимания таблиц за счет открытия своих наборов данных.
В этом исследовании мы будем использовать набор данных Marmot для разработки нашей модели. Набор данных содержит аннотации для ограничивающих рамок таблиц в заданном изображении набора данных в формате xml.
Щелкните здесь, чтобы загрузить набор данных.
Обратите внимание, что мы будем использовать другую версию того же набора данных, аннотированную командой TableNet . Этот набор данных состоит из аннотаций ограничительной рамки на уровне столбца исходных данных Marmot. Для удобства мы будем ссылаться на исходный набор данных как 9.0068 marmot_v1 , а затем marmot_extended в этом блоге.
Мы извлекли набор данных ( marmot_v1 ) после его загрузки с указанного URL-адреса. Теперь мы посмотрим на извлеченный каталог, чтобы увидеть, как организован набор данных.
4.1. Экспериментальные наблюдения
- Основная папка содержит папку data, которая фактически содержит данные вместе с некоторыми файлами, описывающими набор данных.

- Набор данных Marmot состоит из страниц на китайском и английском языках, которые хранятся в отдельных папках.
- Обе эти папки (китайская и английская) имеют одинаковую структуру каталогов, состоящую из папок с именами положительных и отрицательных.
- Для простоты будем рассматривать только английскую папку. Есть две папки, а именно Labeled и Raw, как в положительных, так и в отрицательных каталогах.
- Теперь давайте посмотрим на образец точки данных из набора
- Ниже приведен соответствующий файл аннотации
- Ограничивающая рамка таблицы и сама таблица определяются тег (выделен) Composites . Но следует отметить, что атрибуту BBox присваивается длинная шестнадцатеричная последовательность, поэтому нам нужно каким-то образом преобразовать эту последовательность в осмысленные обозначения.
 Мы займемся этим в следующей части (4.2) этого раздела.
Мы займемся этим в следующей части (4.2) этого раздела.
Теперь давайте посмотрим на набор данных marmot_extended
Содержимое расширенного каталога marmotКоличество точек данных и аннотаций- Эти аннотации содержат ограничивающую рамку для каждого столбца таблиц на изображении
- Этот набор данных содержит только изображения из подпапки English/Positive исходного набора данных.
- Количество файлов аннотаций составляет 495, а растровых изображений – 509. Следовательно 14 xml файлов соответствующих изображений нет.
Ранее мы видели типичные данные изображения из набора данных ( marmot_v1 ), давайте проверим только макет файла аннотации из marmot_extended
XML-аннотацию для marmot_extended, аннотированную командой TableNet- Эти новые аннотации состоят только из ограничивающих аннотаций поля для каждого столбца, представленного на изображении. Каждый тег объекта в XML-файле обозначает столбец, а тег bndbox под каждым объектом содержит прямоугольные координаты ограничивающей рамки этого конкретного столбца
- Мы уже видели, что аннотации в marmot_v1 содержат только аннотации таблиц
- Мы будем использовать эти два типа аннотаций (таблица из marmot_v1 и столбец из marmot_extended ) и создадим изображения масок из этих аннотаций w.
 r.t. каждое изображение, присутствующее в наборе данных.
r.t. каждое изображение, присутствующее в наборе данных. - Поскольку для 14 точек данных отсутствуют аннотации на уровне столбца, мы также проигнорируем 14 аннотаций на уровне таблицы.
Прежде чем перейти к этапу предварительной обработки, мы рассмотрим распределение ширины и высоты каждого изображения в нашем наборе данных.
Распределение ширины и высоты изображения- Из приведенного выше графика видно, что все изображения в наборе данных имеют ширину и высоту, то есть (816, 1056)
На этом этапе мы должны проанализировать предоставленные аннотации и создать маску изображения (как для таблицы, так и для столбца) из них. Операции предварительной обработки, которые были выполнены для выполнения задачи, кратко перечислены ниже:
- Преобразование шестнадцатеричной записи и возврат соответствующего значения с плавающей запятой для сурок_v1 . Для этого мы определили функцию, которую можно вызывать при чтении аннотаций на ходу
- Чтение данных ограничивающей рамки для таблицы из marmot_v1 .
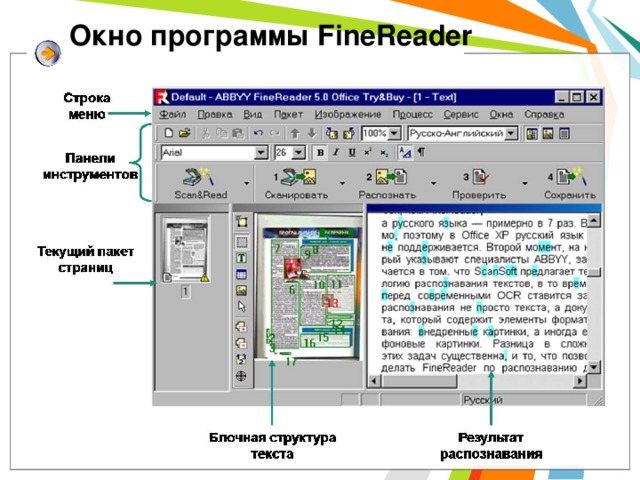 Это достигается путем синтаксического анализа каждого аннотированного XML-файла и обнаружения всех тегов Composites с атрибутом label , для которого задано значение «Таблица». Функция python, определенная для выполнения этой задачи, представлена ниже:
Это достигается путем синтаксического анализа каждого аннотированного XML-файла и обнаружения всех тегов Composites с атрибутом label , для которого задано значение «Таблица». Функция python, определенная для выполнения этой задачи, представлена ниже:
- штука с marmot_extended аннотаций для получения аннотаций на уровне столбца.
- Объединение двух вышеуказанных задач для получения аннотаций на уровне таблиц и столбцов для всех изображений (используя функцию, указанную ниже).
Давайте визуализируем одно такое изображение вместе с его таблицей и маской столбца.
Пример изображения из набора данных вдоль его обработанных масокТеперь давайте кратко рассмотрим различные решения этой проблемы. Этот раздел не является частью процесса разработки, но обеспечивает более широкую перспективу, исследуя аналогичные реализации идей, принятых в этом направлении; некоторые из них кратко рассмотрены ниже:
5.
 1. Преимущества тонкой настройки для обнаружения таблиц в изображениях документов
1. Преимущества тонкой настройки для обнаружения таблиц в изображениях документов [Angela Casado-Garcia et al. 2019]
Их исследование было в основном сосредоточено на том, как улучшается производительность трансферного обучения в моделях компьютерного зрения, если изученные параметры используются более похожими задачами, чем разнородными. Задача, выполненная в исследовании, была разделена на два этапа:
i) Эксперименты проводились с моделями обнаружения объектов SOTA, такими как: yolo, mask-rnn, retina-net, для обучения обнаружению объектов на наборе данных Pascal POV (набор данных естественных изображений ), а затем обученные параметры были доработаны с использованием данных ICDAR, Marmot (табличные данные обнаружения и распознавания).
ii) Другая серия экспериментов была проведена с теми же моделями обнаружения объектов, но на этот раз они были сначала обучены с использованием набора данных TableNet (набор данных обнаружения и распознавания таблиц), а затем была выполнена точная настройка параметров с помощью ICDAR и Наборы данных сурков.
Для обоих наборов экспериментов применялось трансферное обучение, сначала из удаленной области (естественные изображения), а затем из близкой области (обнаружение таблицы). Результаты их экспериментов показали значительное улучшение, когда для обнаружения таблиц в изображениях документов применялось обучение с переносом данных в узкой области.
5 .2. GFTE: извлечение финансовых таблиц на основе графиков
[Yiren Li et al. 2020]
Основные результаты работы, проделанной этой командой, можно кратко резюмировать следующим образом:
i) Составление китайского набора финансовых данных FinTab из нескольких типов финансовых документов. Набор данных состоит из более чем 1600 изображений различных типов таблиц вместе с их структурными аннотациями.
ii) Представление графовой модели сверточной нейронной сети под названием GFTE. Работа модели обсуждается ниже.
В этом подходе таблица представлена в виде графа, где каждая ячейка считается узлом.
 Эти узлы связаны между собой отношениями: вертикальными, горизонтальными или несвязанными. Следовательно, их задачу можно интерпретировать так: предсказать отношения между парой узлов, учитывая набор узлов и их характеристики.
Эти узлы связаны между собой отношениями: вертикальными, горизонтальными или несвязанными. Следовательно, их задачу можно интерпретировать так: предсказать отношения между парой узлов, учитывая набор узлов и их характеристики.Они использовали три типа информации вместе с каждым узлом в качестве входных данных: i) текстовое содержание, ii) абсолютное местоположение и iii) изображение таблицы. Эти функции абсолютного положения преобразуются в функции относительного положения, а текстовые функции встраиваются и отправляются через слой LSTM для получения семантической информации, затем эти полученные функции объединяются и передаются в двухуровневую сверточную сеть графов. Позже, используя функции относительного положения и выходные данные GCN, рассчитываются функции узлов. Тем временем изображение предварительно обрабатывается, и с помощью трехслойной CNN из него рисуются функции. Эти функции узла и функции изображения затем передаются в MLP для моделирования вертикальных и горизонтальных отношений между ячейками.

5.3. TableNet: Модель глубокого обучения для сквозного обнаружения таблиц и извлечения табличных данных из отсканированных изображений документов
[Paliwal et al. 2020]
В этой работе они предложили сквозную модель глубокого обучения TableNet для распознавания таблиц и предоставили дополнительные аннотации для данных Marmot. Этот метод включает в себя трансферное обучение, поскольку предварительно обученный VGG-19 с весами ImageNet используется в качестве кодировщика для предлагаемой модели. Полностью связанные слои в конце VGG-19сети заменяются сверточными слоями 1×1 с активацией и выпадением ReLU. За кодировщиком следуют две разные ветви сверточного декодера, поскольку модель требуется для одновременного обнаружения таблицы и распознавания ее структурной семантики. В этих ветвях декодера использовались дополнительные слои для фильтрации полезных функций, а затем каждая из этих карт функций подвергалась повышающей дискретизации для создания изображений.
 Одно входное изображение создает два разных помеченных выходных изображения для таблиц и столбцов отдельно. После получения семантически размеченных изображений к позициям слов применяется алгоритм OCR, и строки извлекаются как набор слов с использованием метода извлечения строк на основе правил.
Одно входное изображение создает два разных помеченных выходных изображения для таблиц и столбцов отдельно. После получения семантически размеченных изображений к позициям слов применяется алгоритм OCR, и строки извлекаются как набор слов с использованием метода извлечения строк на основе правил.Сейчас мы находимся в точке, где мы будем создавать и обучать модели глубокого обучения, используя данные, которые мы собрали и обработали на предыдущих этапах. Давайте начнем с нашей первой стратегии сокращения.
6.1. Реализация TableNet в TensorFlow
Чтобы решить эту проблему, мы будем использовать трансферное обучение и архитектуру проектирования, вдохновленную работой команды TableNet.
Архитектура TableNet, предложенная Paliwal et al. 2020. Карты объектов из объединяющих слоев block_3, block_4 и block_5 VGG19.кодировщик используется для агрегации контекста на этапе декодирования.Технические характеристики модели
- В отличие от исходной архитектуры TableNet (показанной на рисунке выше), в которой в качестве базового кодировщика используется предварительно обученный VGG19, наша модель может работать с предварительно обученными моделями машинного зрения различных типов, такими как VGG, ResNet. , DenseNet, EfficientNet, Xception в качестве базовых кодировщиков.
- В модели используется опция, которая позволяет весам энкодера оставаться постоянными на протяжении всего обучения. Другими словами, с помощью этой опции можно разрешать или ограничивать тонкую настройку модели.
- Модель также имеет параметр регуляризации, который будет использовать tf.keras.regularizers для сверточных слоев в конце сети кодировщика и сверточных слоев декодера столбца
- Поскольку упомянутая архитектура предварительно обученных моделей выше отличаются друг от друга. Слои, из которых рисуются карты объектов для агрегирования контекста во время декодирования, отличаются от одного базового кодировщика к другому
- Архитектура декодера таблиц и столбцов остается неизменной.
Примечание: Чтобы проверить, какие уровни используются для агрегации контекста (из другой архитектуры кодировщика), обратитесь к приведенному ниже коду.
Определение модели
Ниже приведен код Python для TensorFlow, необходимый для определения модели.
6.2. Эксперименты с различными кодировщиками и настройками
В предыдущем разделе мы заявили, что наша модель совместима со многими типами предварительно обученных кодировщиков и содержит параметры, которые могут обеспечивать регуляризацию и точную настройку во время обучения. В этой части мы будем проводить эксперименты с различными комбинациями энкодеров и настроек, записывая поезд и тестируя потери для оценки производительности каждой модели.
Резюме:
Обсуждения:
- Мы экспериментировали с архитектурой TableNet, настраивая различные параметры, такие как предварительно обученный кодировщик, частота отсева и регуляризация на последних слоях.
- В одном из наших тестов мы также попытались заморозить слои первых нескольких блоков DenseNet, но это не помогло нам избежать переобучения.
- Модель TableNet Кодировщик DenseNet (с отсевом 0,6, без регуляризации и без замораживания слоев) показал наибольшую производительность с набором проверки, как показано в таблице выше, и модель показала меньше признаков переобучения, чем другие модели. .
6.3. Сжатие полученной модели с помощью TensorFlow Lite
Теперь мы импортируем лучшую модель и постараемся минимизировать требования к пространству, используя метод, называемый квантованием после обучения. В этом подходе модель сжимается за счет оптимизации представления типа данных для весов модели. Это означает, что тип данных весов изменяется на менее точное представление по сравнению с исходным (скажем, с числа с плавающей запятой 32 на число с плавающей запятой 16), сохраняя как можно больше информации.
Однако для этого нам не нужно создавать алгоритм; TensorFlow Lite с легкостью справится со всеми сложностями от нашего имени. Просто следуйте приведенным ниже инструкциям, чтобы выполнить квантование с помощью TF Lite.
- Загрузить модель
- Определить объект конвертера TF Lite
- Установить тип необходимой оптимизации
- Преобразовать модель
- Размер модели 3 после квантования 0002 Отлично! Теперь модель сжата примерно на 75 % по сравнению с версией .h5. Он завершен и готов к использованию для получения сегментированной маски. Теперь мы могли извлечь необходимую текстовую информацию, используя метод оптического распознавания символов, такой как тессеракт, в сегментированную область таблицы. В следующей части мы рассмотрим весь процесс и определим конечный конвейер.
6.4. Определение окончательного конвейера
Теперь мы будем использовать сжатую модель TF Lite, которую мы получили в предыдущей части, для создания нашего окончательного конвейера, то есть от принятия изображения (которое присутствует в виде файла на диске) для получения csv с извлеченными табличными данными (которые также будут сохранены в виде файла на диске).
Алгоритм и реализация окончательного конвейера на Python представлены ниже.- Алгоритм для окончательного трубопровода
- Код Python для окончательного Pipeline
- . документа, содержащего таблицу
ii) Сегментированная таблица, предсказанная моделью, приведена ниже
Сегментированное изображение таблицыiii) Извлеченная таблица как текст
Полученный текст из модуля OCR6.5. Веб-интерфейс с использованием Streamlit
В этой части мы возьмем наш окончательный конвейер и создадим оболочку с использованием пакета python Streamlit, чтобы можно было удобно протестировать модель.
Примечание. В этом разделе не показан код Python для развертывания приложения Streamlit; однако, если вам это нужно, вы можете проверить мой репозиторий. Посетите мой блог Predicting Volcanic Eruptions from Seismic Behavior, чтобы узнать больше о том, как использовать Streamlit для создания веб-приложений.
Разработанная система содержит некоторые ограничения, которые будут рассмотрены в следующем разделе, и именно из-за этих ограничений модель не может быть развернута (для использования другими пользователями). Поэтому рабочая демонстрация веб-приложения Streamlit (развернутого локально) представлена в следующем видео: реальные проблемы, с которыми может столкнуться система (если и когда она будет развернута).
- Для начала мы получили изображения, предоставленные данными сурков, и преобразовали два типа аннотаций ( marmot_v1 для таблицы и marmot_extended для столбца) в реальные изображения-маски, которые можно использовать в качестве меток для контролируемого обучения.
- Затем мы реализовали архитектуру TableNet с помощью фреймворка TensorFlow Python.
- Мы изменили первоначальный дизайн, чтобы он мог работать с различными предварительно обученными моделями зрения, и предоставили опции для включения/отключения точной настройки и регуляризации.
- После этого мы выбрали лучшую модель из наших экспериментов и сжали ее с помощью конвертера TF Lite.
- Наконец, мы использовали Streamlit, чтобы инкапсулировать нашу модель в пользовательский интерфейс, который можно было использовать в интерактивном режиме.
Ограничения:
Хотя модель способна извлекать табличные данные в достаточной степени, наша реализация имеет некоторые серьезные ограничения/проблемы.
- Качество извлечения снижается, когда изображение содержит несколько таблиц, поскольку оно пытается сегментировать только одну прямоугольную область, содержащую все таблицы.
- Слабое обнаружение текста при использовании OCR в сегментированной области таблицы. Было бы выгодно, если бы он мог изучать сегментацию на уровне ячеек и применять OCR к каждой ячейке.
- Не удается отличить ячейки, содержащие заголовки строк/столбцов, от ячеек, содержащих фактические данные.
Мы подошли к концу нашего блога, и цель этого раздела — указать направление для будущих улучшений.
- Основная папка содержит папку data, которая фактически содержит данные вместе с некоторыми файлами, описывающими набор данных.