какие есть и что выбрать?
У профессионального офисного работника нередко появляется необходимость сканирования текста и его дальнейшего редактирования. Поэтому важно понимать, какая лучшая программа для распознавания текста со сканера есть. Желательно ориентироваться не только среди платных, но и бесплатных решений.
ABBY FineReader
Это программа, ориентированная на профессионалов. В спектр ее возможностей входит распознавание печатных документов, фотографий, PDF-файлов с высокой точностью и сохранением первоначальной верстки. Это означает, что приложение сохраняет расположение картинок, таблиц, нумерации страниц, экспортируя весь распознанный материал в разные форматы Microsoft Office, позволяя пользователю в дальнейшем редактировать их.
Приложение платное, но цена оправдывает возможности. Так, данный софт может распознавать 179 языков. Стоит она относительно недорого, но если появляется необходимость разового сканирования документов, можно установить бесплатную демонстрационную версию, которая позволит на протяжении 15 дней распознать 50 документов. Дальше придется ее зарегистрировать. Если же цена не устраивает пользователя, он может воспользоваться бесплатными программами.
Дальше придется ее зарегистрировать. Если же цена не устраивает пользователя, он может воспользоваться бесплатными программами.
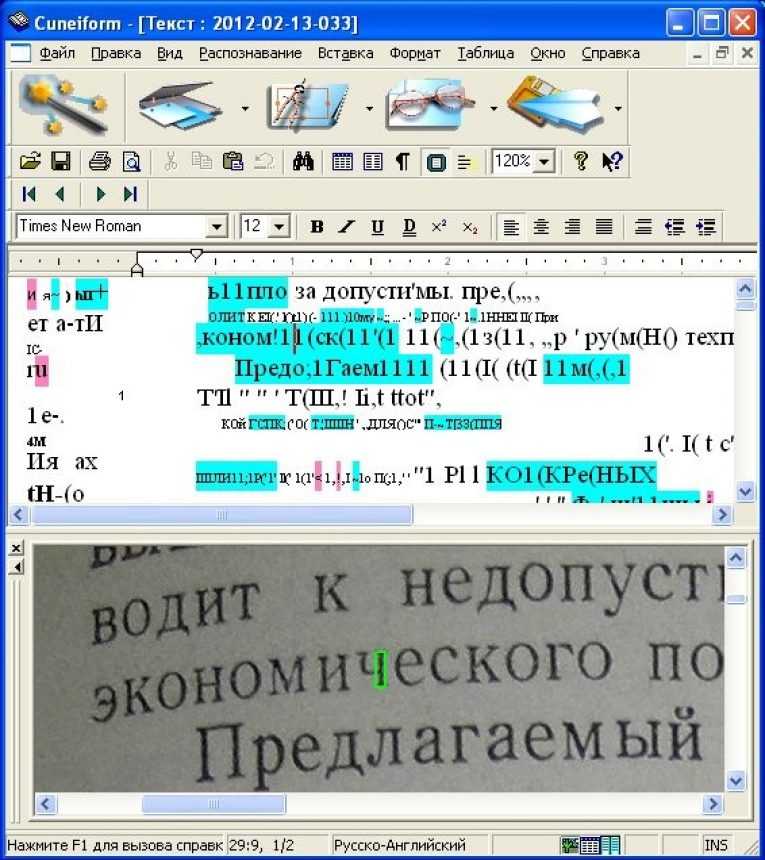
CuneiForm
Преимуществом данного приложения на фоне предыдущего является цена (вернее, ее отсутствие), но при этом приложение располагает рядом интересных функций, способных сделать ее лучшим бесплатным решением. Данная программа для распознавания текста со сканера позиционируется авторами (а она разработана отечественным производителем) как интеллектуальная система оптического распознавания документов.
Ее преимуществом является сохранение шрифтов оригинала, благодаря чему можно просто его отсканировать, отредактировать и распечатать практически в неизменном виде. Данная программа имеет возможность и пакетного сканирования документов. А что насчет качества распознавания? С этим параметром все в порядке. Благодаря специфическому алгоритму этого приложения, основанному на анализе определенных частей сканируемого текста и их сравнении с внутренним словарем, в любом случае пользователь остается в выигрыше.
Бывает и такое, что необходимого слова нет в словаре. В этом случае можно просто пополнить его. А учитывая, что данная программа для распознавания текста со сканера понимает тексты на 20 языках, она становится незаменимым помощником при редактировании печатных документов на компьютере для представителей разных профессий.
WinScan 2 PDF
Данная программа для распознавания текста со сканера является невероятно простым решением для людей, которым надоело копаться в огромном количестве настроек, способных только запутать непрофессионала. Взаимодействие с этой утилитой (ее размер составляет всего несколько десятков килобайт) заключается всего лишь в одном нажатии кнопки сканирования. И при этом есть возможность превращения огромного количества печатных документов в текст только одним нажатием пальца. Преимуществом этой программы является отсутствие необходимости устанавливать это приложение.
Программа для распознавания рукописного текста со сканера: возможна ли?
К сожалению, на данный момент нет разработок, гарантирующих хотя бы нормальную точность при распознавании печатных документов, имеющих рукописный текст. Если еще приложения для ввода с помощью руки на смартфонах существуют более-менее работающие, то определять содержание уже написанных рукописей – задача временами сложная даже для человека.
Если еще приложения для ввода с помощью руки на смартфонах существуют более-менее работающие, то определять содержание уже написанных рукописей – задача временами сложная даже для человека.
Казалось бы, почему нельзя использовать наработки приложений для рукописного ввода в софте для распознавания текста, написанного от руки? Ведь там же используются простые картинки. А вот нет. Приложения для рукописного ввода анализируют движения пальца или стилуса по экрану мобильного телефона. А вот распознавать уже написанную букву они не способны.
Программы для распознавания текста
Зачем нужны программы распознавания текста.
Программы распознавания текста позволяют работать с отсканированными изображениями. С их помощью выполняется редактирование информации, исправление ошибок, сохранение данных в нужном формате и т.д.
Как работает сканер.
Чтобы лучше понять ценность упомянутых программ разберемся с тем, как работает сканер. Механизм устройства помещен в корпус, верхняя часть которого представлена стеклом. Внутри находится яркая лампа и зеркала. Именно они отвечают за «фотографирование» источника для сканирования. При этом шрифт и изображения считываются в виде цветных, серых или черно-белых точек (в зависимости от модели устройства). А за распознавание текста и картинок отвечает драйвер сканера.
Механизм устройства помещен в корпус, верхняя часть которого представлена стеклом. Внутри находится яркая лампа и зеркала. Именно они отвечают за «фотографирование» источника для сканирования. При этом шрифт и изображения считываются в виде цветных, серых или черно-белых точек (в зависимости от модели устройства). А за распознавание текста и картинок отвечает драйвер сканера.
Полученное изображение является своеобразной фотографией исходного источника, будь то разворот книги, лист формата A4 или справка. Программы для распознавания текста позволяют расширить возможности пользователя, редактировать текст, исправлять ошибки.
Для наглядности рассмотрим пример. Допустим, вам нужно вставить большой кусок текста из книги в дипломную работу. Чтобы не тратить время на перепечатывание с листа, страницы можно отсканировать. Однако этого недостаточно, поскольку вы получите файлы-картинки, которые не подойдут для использования в Microsoft Word. С помощью программ для распознавания текста пользователь отредактирует полученное изображение и сможет вставить информацию в текстовый редактор.
С помощью программ для распознавания текста пользователь отредактирует полученное изображение и сможет вставить информацию в текстовый редактор.
Возможности современных программ для распознавания текста.
Если предстоит сканирование листов с четко прописанными буквами, читабельным, ярким шрифтом, то с такой задачей справится любой сканер. Куда хуже обстоит дело, если речь идет о таких носителях информации, как старые, потрепанные листы бумаги или пожелтевшие газеты. Не каждый драйвер сможет идентифицировать подобный текст, а потому возможности специальной программы придутся как нельзя кстати. С их помощью утраченные области шрифта легко восстановить, дописав на клавиатуре в рамках редактора.
Отдельные программы предоставляют даже такие эксклюзивные возможности, как правка рукописного текста. Правда, для этого нужно, чтобы разрешение картинки было не меньше 300 точек на дюйм. Кроме того, буквы в строке должны быть примерно одной высоты, одного наклона и написаны как можно аккуратнее.
Функцию распознавания рукописного текста поддерживают такие программы, как ABBYY FineReader, CuneiForm (бесплатная утилита), MyScript Stylus, SimpleOCR и другие. Помимо русских символов они идентифицируют буквы, написанные на иностранном языке. Кроме того, программы распознают таблицы и рисунки, перенося их в компьютер для последующего редактирования.
Таким образом, ни один современный пользователь ПК, имеющий сканер, не обойдется без программы распознавания текста. Выбор платных и бесплатных утилит позволит выбрать то, что отвечает именно вашим запросам с точки зрения функциональности.
www.38i.ru
OCR и сканеры — цифровая проверка : Digital Check
Оптическое распознавание символов, часто сокращенно OCR, — одна из наиболее важных технологий, используемых в современном сканировании и захвате изображений: это то, что позволяет машинам «читать» что напечатано или написано на листе бумаги. Тем не менее, несмотря на его присутствие в сотнях наших повседневных дел, мы редко даже замечаем его.
Как производитель сканеров, мы на самом деле считаем, что это хорошо, поскольку тихое выполнение вашей работы в фоновом режиме без каких-либо ошибок — это именно то, что вы хотите от машины. Но каждый раз, когда вы сканируете квитанцию на домашнем принтере 3-в-1, вкладываете чек в банкомат, используете функцию камеры в Google Translate или даже кладете долларовую купюру в автомат с газировкой, велика вероятность того, что Технология OCR работала.
Как работает распознавание символов? Основы:
При оптическом распознавании символов, или OCR, машина сравнивает пиксели изображения с библиотекой известных шрифтов. В этом примере символы, скорее всего, будут плохо соответствовать конкретному тестируемому шрифту, и движок перейдет к следующему.
Так как же машина превращает кучу данных с камеры в читаемый текст? Проще говоря, это умная часть реверс-инжиниринга. Отсканированное или сфотографированное изображение пропускается через Модуль OCR , который идентифицирует группы пикселей на основе их контраста с фоном, а затем сравнивает их с библиотекой известных шрифтов, чтобы определить, совпадают ли какие-либо из них. Если набор пикселей достаточно близко совпадает, ему присваивается показатель достоверности , , и если он проходит с достаточно высокой степенью достоверности, он записывается как текстовый символ.
Если набор пикселей достаточно близко совпадает, ему присваивается показатель достоверности , , и если он проходит с достаточно высокой степенью достоверности, он записывается как текстовый символ.
Довольно просто, правда? Ну, так и было бы, если бы все всегда было так просто. Однако в реальных условиях обычно нецелесообразно запускать комплексный тест OCR для каждой части каждого документа.
Это означает следующее: если вы сканируете чек в банке, вы не будете искать те же вещи, что и при сканировании водительских прав или квитанции. Итак, в зависимости от того, что вы пытаетесь прочитать и что вы собираетесь делать с данными OCR, вы, вероятно, получите множество «мини-движков» OCR, созданных для очень конкретных целей.
Один размер не подходит всем
Наши собственные сканеры чеков на самом деле являются прекрасным примером того, как OCR становится специализированным для выполнения конкретной работы. Когда вы вносите чек в банк, он проходит через два совершенно разных механизма OCR в процессе преобразования в изображение.
Когда проверка выполняется через сканер в перевернутом виде, модуль OCR в API сканера распознает символы шрифта E13B вверху, а не внизу, вызывая переориентацию изображения в правильном направлении. Благодаря урезанной функциональности этого ограниченного механизма OCR этот процесс можно выполнять в режиме реального времени.
После того, как вы пропустите чек через сканер, первое, что происходит, это то, что изображение подвергается очень простому анализу OCR либо на самом сканере, либо на ПК, к которому он напрямую подключен. Это ограниченные функциональные тесты, которые являются частью собственного внутреннего механизма OCR Digital Check. Вот некоторые из вещей, которые он может сделать:0003 Чтение OCR магнитной строки MICR , чтобы эти символы можно было сравнить с магнитным чтением; распознавание перевернутых чеков, если печать на дне не на месте; или идентификация некоторых других документов (в основном используемых на международном уровне), которые имеют немагнитные контрольные линии.
Поскольку тесты OCR, выполняемые нашим собственным движком, строго необходимы для работы сканера, естественно, он будет сильно упрощен по сравнению с «полным» движком, который обрабатывает более продвинутые функции. Например, он использует только несколько шрифтов в своей библиотеке: шрифты E13B и CMC7 MICR; ОКР-А и ОКР-В; несколько разных шрифтов; и некоторая ограниченная поддержка штрих-кода.
Еще одна важная характеристика модуля OCR в сканере чеков заключается в том, что он запрограммирован только на поиск определенных символов в определенных частях чека, а не на анализ всего документа. Это означает, что он будет читать пару полдюймовых полос на лицевой стороне документа, игнорируя при этом остальную часть чека, где будут напечатаны такие вещи, как сумма в долларах и подпись. Это сокращает анализируемую область на добрых 80 процентов и более, а поскольку мы ищем только несколько шрифтов, это устраняет 99 процентов работы.
Такая упрощенная возможность необходима для поддержания управляемого размера ядра, чтобы оно соответствовало API сканера, а также для того, чтобы его можно было быстро запускать на сотнях документов в режиме реального времени.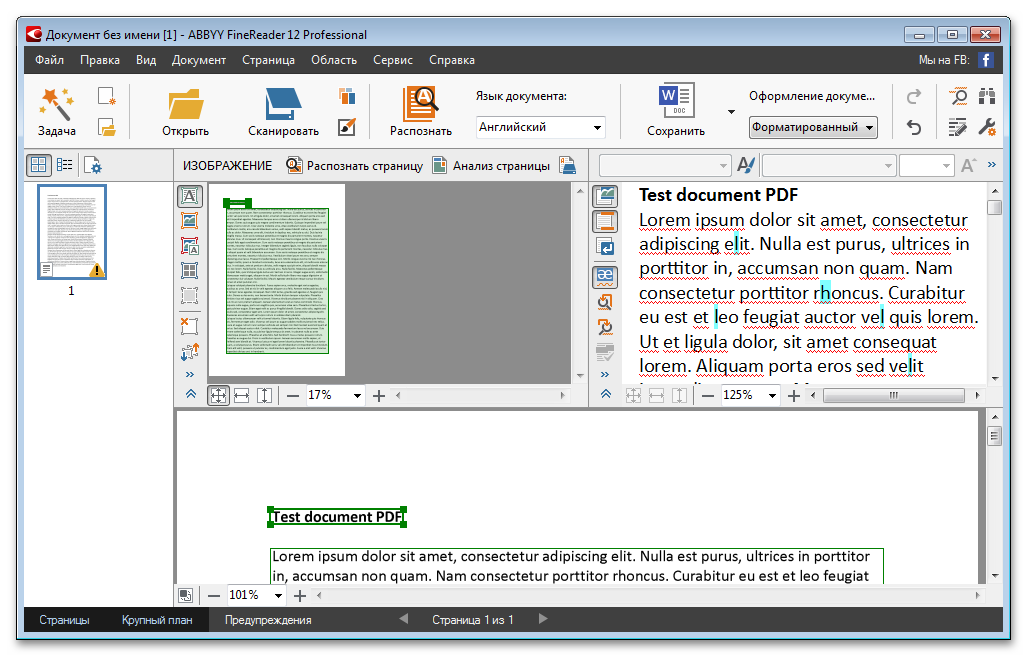 API сканера выполняет базовое функциональное распознавание текста на чеке за 20–30 миллисекунд — достаточно быстро, чтобы не отставать от машины с непрерывной подачей, тогда как полный анализ всего документа будет медленнее, чем скорость сканирования. Вы можете найти другие подобные «внешние» механизмы OCR, которые справляются с основными задачами для своих конкретных типов устройств. 9″ Двигатель CAR/LAR» на чеках) — дальше все становится намного сложнее. Для этого требуется серьезный механизм OCR, написанный компанией-разработчиком программного обеспечения, которая специализируется на этом. Orbograph и Mitek A2iA — два примера таких компаний.
API сканера выполняет базовое функциональное распознавание текста на чеке за 20–30 миллисекунд — достаточно быстро, чтобы не отставать от машины с непрерывной подачей, тогда как полный анализ всего документа будет медленнее, чем скорость сканирования. Вы можете найти другие подобные «внешние» механизмы OCR, которые справляются с основными задачами для своих конкретных типов устройств. 9″ Двигатель CAR/LAR» на чеках) — дальше все становится намного сложнее. Для этого требуется серьезный механизм OCR, написанный компанией-разработчиком программного обеспечения, которая специализируется на этом. Orbograph и Mitek A2iA — два примера таких компаний.
Такого рода полные механизмы OCR, по крайней мере, в банковском мире, либо встроены в основной программный пакет банка, либо работают вместе с ним. Они будут использовать сложные алгоритмы, которые могут идентифицировать тысячи различных шрифтов, а также рукописные печатные и курсивные буквы, и учитывать всевозможные ситуации при чтении ключевой информации, напечатанной на чеке. Это совершенно другое животное, чем то, что может работать на сканере, но, надеюсь, вы видите, насколько хороши оба варианта для работы, для которой они предназначены!
Это совершенно другое животное, чем то, что может работать на сканере, но, надеюсь, вы видите, насколько хороши оба варианта для работы, для которой они предназначены!
Мы надеемся, что вам понравился этот взгляд на интересный, но в значительной степени неизвестный мир сканеров и OCR, и что мы помогли вам немного больше понять о фоновых процессах, которые помогают машинам научиться читать.
OCR-сканеры, программное обеспечение и приложения: полное руководство
Люсион Технологии Опубликовано Опубликовано в Сканирование и OCR С тегами Как работает сканирование OCR, Приложение OCR, Приложение OCR, Сканирование OCR, Программное обеспечение для сканирования OCR, Программное обеспечение OCR, Технология OCR, оптическое распознавание символов, Редактор PDF, Что такое сканер OCR, Что такое извлечение функций OCR, Что такое сообщение OCR -Обработка
Многие сценарии требуют наличия физического документа в современном бизнесе. Однако с развитием цифровых технологий большинство документов должны быть доступны для электронной передачи, доступны и читабельны. Сканер OCR использует оптическое распознавание символов для преобразования бумажных документов в машиночитаемые текстовые копии.
Однако с развитием цифровых технологий большинство документов должны быть доступны для электронной передачи, доступны и читабельны. Сканер OCR использует оптическое распознавание символов для преобразования бумажных документов в машиночитаемые текстовые копии.
Технология OCR не нова, но сегодняшние возможности значительно превосходят предыдущие решения. Программное обеспечение для оптического распознавания текста обладает передовыми функциями, которые могут помочь организациям ускорить переход к цифровой трансформации. В течение следующего десятилетия аналитики прогнозируют среднегодовой рост более чем на 15 %, поскольку новые решения находят применение в офисах и операциях всех типов.
Сканеры и приложения OCR могут помочь:
- Оценка активов при слияниях и поглощениях путем превращения инженерных чертежей десятилетней давности в современные 3D-модели
- Сбор финансовых отчетов и квитанций с изображений с помощью мобильных приложений OCR
- Модернизация архивов в правительственных подвалах и в офисах для снижения затрат на физическое хранение бумаги
- Оптимизация процесса приема документов в современных компаниях за счет автоматического сбора и регистрации накладных, квитанций, утверждений или сведений об отгрузке
Новые приложения OCR помогают малым и средним предприятиям оптимизировать свои рабочие процессы с документами с помощью оцифрованных процессов, которые улучшают повседневные задачи, такие как ввод, хранение и редактирование документов.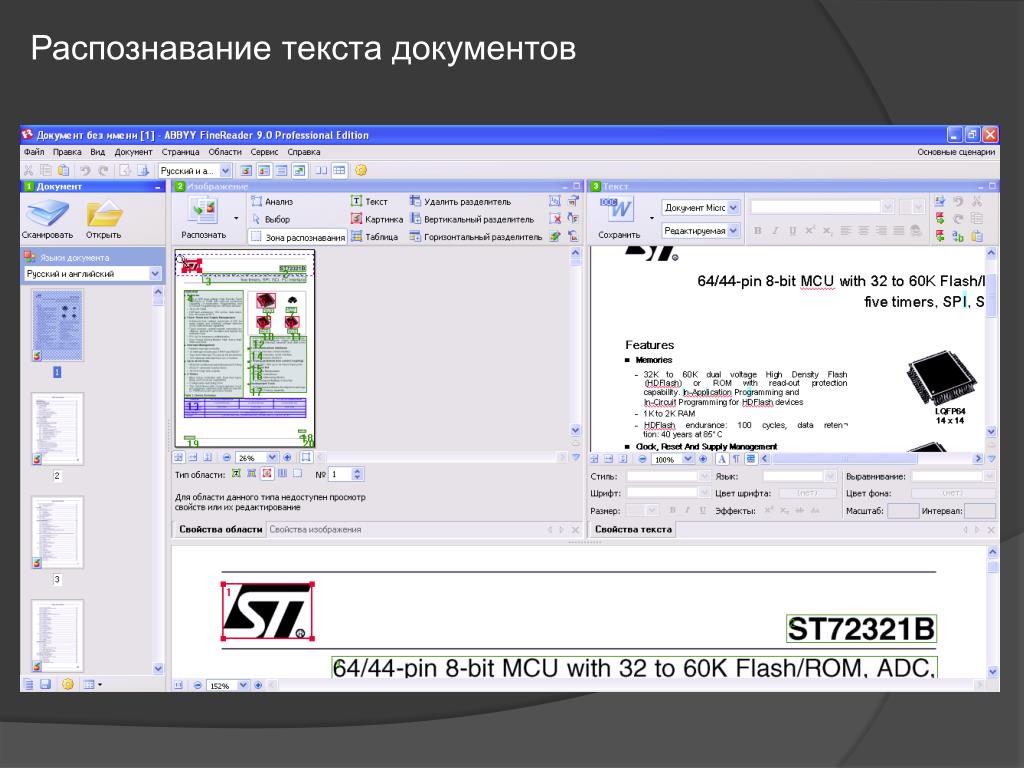
Ключевые выводы:
- Программное обеспечение OCR-сканера продолжает развиваться, и сегодняшняя точность может помочь улучшить рабочий процесс управления документами типы и изображения
- Преобразование бумажных документов в редактируемые в цифровом виде файлы позволяет вашей команде легко искать, редактировать, хранить и переводить файлы
Что такое OCR-сканер?
Сканеры OCRиспользуют программное обеспечение, предназначенное для извлечения текста из цифровых изображений. Программное обеспечение OCR имеет алгоритм, который распознает текстовые символы с разными шрифтами и создает машиночитаемую копию либо цифрового файла, либо отсканированного физического документа. Это позволяет организациям оцифровывать файлы или извлекать текст из файлов PDF, BMP, TIFF, JPG и многих других типов файлов в зависимости от дизайна приложения OCR.
Источник изображения: https://www.filecenter.com/blog/the-complete-guide-to-document-scanning-software/Как работает сканирование OCR?
Поскольку документы бывают самых разных форм и размеров, решения OCR используют разные алгоритмы для сопоставления определенных букв или цифр с вероятным символом. Предварительная обработка изображения приводит его в состояние готовности к чтению, прежде чем вы сможете начать извлечение признаков.
Предварительная обработка изображения приводит его в состояние готовности к чтению, прежде чем вы сможете начать извлечение признаков.
Различные типы подходов к предварительной обработке включают:
- Устранение перекоса — При сканировании документа может потребоваться устранение перекоса изображения для исправления выравнивания на несколько градусов, чтобы текст выровнялся по вертикали и горизонтали
- Удаление пятен — для сглаживания краев и удаления положительных и отрицательных точек из документа программа OCR использует алгоритм удаления пятен и фон
- Удаление строк — Удаляет поля без глифов и очищает все строки в документе
- Зонирование — Помогает идентифицировать заголовки, столбцы и абзацы как блоки текста в многоколоночных и табличных документах
- Распознавание сценариев — Используется в документах на нескольких языках для преобразования параметров распознавания на уровне слов
- Сегментация — Разделяет и связывает различные артефакты изображения (или отдельные символы) в части текста
- Нормализация — Исправления соотношение сторон и масштаб документа в стандартные размеры
Предварительная обработка необходима для извлечения осмысленного текста из документов, особенно при OCR-сканировании старых бумажных файлов с низким качеством изображения.
Что такое извлечение признаков OCR?
После предварительной обработки программа OCR начинает фазу извлечения признаков. Сопоставляя пиксели с распознаванием образов или оценкой линий/штрихов, сканеры OCR могут распознавать вероятные символы. Программное обеспечение OCR преобразует каждый пиксель в двоичное значение и выполняет различные вычисления для определения наиболее вероятного символа.
Что такое постобработка OCR?
Доступны различные методы постобработки для повышения точности вывода сканера OCR. Системы OCR используют библиотеку допустимых слов (называемую словарем), чтобы ограничить результаты сканирования определенным символом. Лексиконы могут включать все слова определенного языка или сокращенный список разрешенных слов, основанный на определенном типе документа.
Вы также можете повысить точность результатов сканирования OCR:
- Исправление ошибок — Использование анализа ближайших соседей повышает точность путем настройки правил для часто используемого языка
- Грамматика — Определение языка и вероятных слов возможно путем определения глаголов или существительных, которые часто встречаются вместе (часто применяется алгоритм расстояния Левенштейна)
 researchgate.net/figure/Levenshtein-Distance-Algorithm_fig5_359465619
researchgate.net/figure/Levenshtein-Distance-Algorithm_fig5_359465619Каковы распространенные приложения для сканирования OCR?
Современные решения OCR решают целый ряд задач в различных отраслях. Управление инженерной документацией часто полагается на OCR для оцифровки старых чертежей перед созданием доступного для поиска архива, который упрощает поиск информации об объекте.
Аналогичным образом, с рабочими процессами бухгалтерского учета система OCR может собирать и хранить квитанции, чтобы исключить необходимость ручного ввода данных. То же самое относится к финансовым фирмам, юридическим конторам и организациям здравоохранения.
Некоторые преимущества использования OCR-сканирования в вашем бизнесе включают:
- Создание доступных для поиска копий архивных документов, которые ускоряют ваши рабочие процессы управления документами
- Повторное создание форм и создание цифровых шаблонов, которые вы можете редактировать по мере необходимости для ведения физических архивов старых документов, что приводит к экономии средств компании
- Создание резервных копий всех записей и документов в доступной системе хранения для повышения производительности сотрудников
- Перевод документов на разные языки без необходимости перепечатывать все содержимое перед использованием службы перевода или программного решения
Зачем использовать OCR в вашем бизнесе?
Современные предприятия конкурируют за минимальную маржу. Технология OCR в сочетании с системой управления документами повысит эффективность любого офиса, если вы используете правильное решение. FileCenter предоставляет многофункциональную систему OCR с редактором PDF и системой управления документами.
Технология OCR в сочетании с системой управления документами повысит эффективность любого офиса, если вы используете правильное решение. FileCenter предоставляет многофункциональную систему OCR с редактором PDF и системой управления документами.
Повышение эффективности работы офиса с помощью программного обеспечения OCR Scanner от FileCenter
Каждому офису необходимо серьезно отнестись к цифровому преобразованию. Масштабирование вашего бизнеса с помощью решения FileCenter открывает путь к оцифровке всех ваших операций и поддержанию необходимого контроля над всеми важными документами вашей компании. С FileCenter вы можете быстро приступить к работе и получить экономичный, простой в освоении и оптимизированный рабочий процесс управления документами.