
Как распознать PDF-файл в Google Диск
Испытываете сложности при работе с отсканированными PDF-файлами? Ищете способ быстро преобразовывать отсканированные PDF в текст? Мы предлагаем два эффективных решения данной проблемы. Сначала мы поговорим о том, как распознавать текст в Google Drive, а затем я представлю вам лучшее решение этой задачи – PDFelement.
Скачать бесплатно
Как использовать альтернативы Google Диска для распознавания текста
PDFelement сочетает функции создания, редактирования, аннотирования и преобразования файлов в одной программе. Функция OCR в данной программе позволяет с легкостью распознавать ваши отсканированные или основанные на изображениях PDF-документы и превращать их в редактируемый текст. Функция распознавания текста поддерживает широкий спектр языков, таких как английский, корейский, немецкий, румынский, итальянский, португальский, испанский и другие.
Шаг 1. Открытие отсканированного PDF-файла
После установки PDFelement откройте отсканированный PDF-документ с помощью этой программы.
Шаг 2. Распознавание текста PDF без конвертирования
Программа напомнит вам выполнить распознавание текста после загрузки отсканированного PDF. Нажмите кнопку «Распознать текст» в верхней информационной панели и выберите нужный язык. Через некоторое время отсканированный PDF будет преобразован в редактируемый формат. Если вам нужно внести изменения в получившийся документ, нажмите «Редактировать» в левом верхнем углу экрана.
Скачать бесплатно
Шаг 3. Конвертирование PDF в текст с помощью функции распознавания текста
Если вам нужно экспортировать отсканированный PDF в текстовый формат, перейдите во вкладку «Главная», нажмите кнопку «В другие формату» и выберите опцию «Преобразовать в текст». Затем установите флажок «Настройки» > «Включить распознавание» во всплывающем окне. Нажмите «Сохранить», чтобы запустить процесс распознавания.
Чтобы установить язык распознавания, перейдите в меню «Файл > Настройки» и выберите нужный язык во вкладке «Распознавание (OCR)».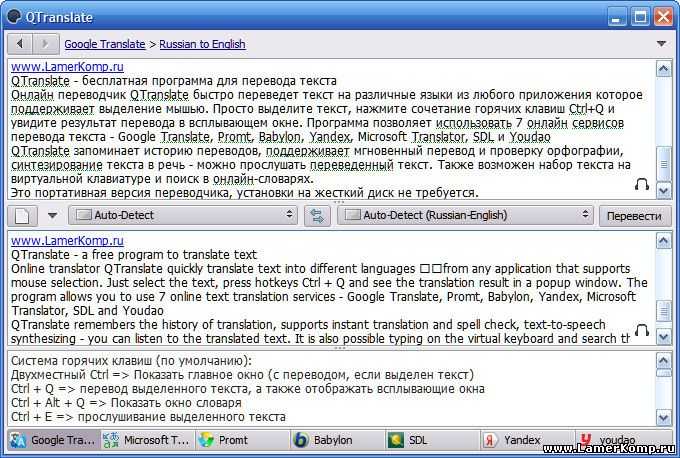
Благодаря мощному функционалу вы можете редактировать текст PDF, менять изображения и размечать контент с легкостью. Помимо редактирования вы можете аннотировать, шифровать PDF, конвертировать в другие форматы, создавать заполняемые формы и т.д.
Скачать бесплатно
Как использовать Google Диск для распознавания текста
Шаг 1. Импортирование PDF-файла, созданного на основе изображений
После входа в учетную запись Google Диск вы можете загрузить в нее свое изображение или отсканированный файл.
Шаг 2. Распознавание текста в Google Документах
Выберите загруженный файл и откройте его с помощью Google Документы. При открытии файла в Google Документах подключается опция распознавания символов Google Drive OCR. Текст в файле с изображениями теперь можно редактировать.
Шаг 3. Сохранение файла
Нажмите кнопку «Файл» > «Скачать», чтобы выбрать формат его сохранения на своем компьютере.
Скачать бесплатно
Вот как можно использовать функцию распознавания символов Google Docs для преобразования отсканированного PDF в текст. Это достаточно удобно, но в Google Документах нельзя сохранить форматирование и конфигурацию PDF-файла. После работы с Google Drive OCR вы можете обнаружить, что текст исходного файла было изменен. Если вы хотите сохранить исходное форматирование и конфигурацию PDF, попробуйте Wondershare PDFelement.
Это достаточно удобно, но в Google Документах нельзя сохранить форматирование и конфигурацию PDF-файла. После работы с Google Drive OCR вы можете обнаружить, что текст исходного файла было изменен. Если вы хотите сохранить исходное форматирование и конфигурацию PDF, попробуйте Wondershare PDFelement.
App Store: Google Переводчик
Описание
Приложение позволяет выполнять переводы (доступно до 133 языков). Список поддерживаемых функций зависит от языка:
• Текст. Перевод введенного текста.
• Офлайн-режим. Перевод без подключения к интернету.
• Быстрый перевод камерой. Мгновенный перевод текста на изображениях, на которые наведена камера.
• Фото. Перевод текста на собственных, скачанных и полученных изображениях.
• Режим разговора. Автоматический перевод речи на двух языках.
• Рукописный ввод. Перевод текста, написанного от руки.
• Разговорник. Возможность помечать и сохранять переводы слов и выражений, чтобы использовать их в дальнейшем.
Необходимые разрешения:
• Микрофон для перевода речи
• Камера для перевода текста с изображений
• Фотогалерея для импорта фотографий
Поддерживаются следующие языки:
азербайджанский, аймара, албанский, амхарский, английский, арабский, армянский, ассамский, африкаанс, бамбара, баскский, белорусский, бенгальский, бирманский, болгарский, боснийский, бходжпури, валлийский, венгерский, вьетнамский, гавайский, галисийский, греческий, грузинский, гуарани, гуджарати, датский, догри, зулу, иврит, игбо, идиш, илоканский, индонезийский, ирландский, исландский, испанский, итальянский, йоруба, казахский, каннада, каталанский, кечуа, киргизский, китайский (традиционный), китайский (упрощенный), конкани, корейский, корсиканский, коса, креольский (гаити), крио, курдский (курманджи), курдский (сорани), кхмерский, лаосский, латинский, латышский, лингала, литовский, луганда, люксембургский, майтхили, македонский, малагасийский, малайский, малаялам, мальдивский, мальтийский, маори, маратхи, мейтейлон (манипури), мизо, монгольский, немецкий, непальский, нидерландский, норвежский, ория, оромо, панджаби, персидский, польский, португальский, пушту, руанда, румынский, русский, самоанский, санскрит, себуанский, сепеди, сербский, сесото, сингальский, синдхи, словацкий, словенский, сомалийский, суахили, сунданский, таджикский, тайский, тамильский, татарский, телугу, тигринья, тсонга, турецкий, туркменский, узбекский, уйгурский, украинский, урду, филиппинский, финский, французский, фризский, хауса, хинди, хмонг, хорватский, чви, чева, чешский, шведский, шона, шотландский (гэльский), эве, эсперанто, эстонский, яванский, японский
Версия 7.2.0
• Мы обновили и упростили интерфейс Google Переводчика, сохранив все ваши привычные функции.
Оценки и отзывы
Оценок: 27,2 тыс.
Один нюанс лишь – 3D Touch
Лучший переводчик, вопросов нет. Но ведь давно уже можно было сделать поддержку 3D Touch для по вставки текста с буфера 🙂
Огромное спасибо разработчикам
Очень удобная и полезная программа!!! Особенно полезная для переписки, удобная функция копирование текста.
Отлично
Отличное приложения для перевода.

Особенно обрадовали такие функции, как перевод по фотографии и озвучивание переведенного текста.
Так же одним из плюсов приложения является то, что присутствует автоподбор языка текста, который нужно перевести.
Приложение работает быстро, без лагов и зависаний.
Разработчик Google LLC указал, что в соответствии с политикой конфиденциальности приложения данные могут обрабатываться так, как описано ниже. Подробные сведения доступны в политике конфиденциальности разработчика.
Связанные с пользователем данные
Может вестись сбор следующих данных, которые связаны с личностью пользователя:
- Геопозиция
- Контактные данные
- Контакты
- Пользовательский контент
- История поиска
- Идентификаторы
- Данные об использовании
- Диагностика
- Другие данные
Не связанные с пользователем данные
Может вестись сбор следующих данных, которые не связаны с личностью пользователя:
- История просмотров
- Данные об использовании
- Диагностика
Конфиденциальные данные могут использоваться по-разному в зависимости от вашего возраста, задействованных функций или других факторов. Подробнее
Подробнее
Информация
- Провайдер
- Google LLC
- Размер
- 160,4 МБ
- Категория
- Справочники
- Возраст
- 4+
- Copyright
- © 2023 Google LLC
- Цена
- Бесплатно
- Сайт разработчика
- Поддержка приложения
- Политика конфиденциальности
Другие приложения этого разработчика
Вам может понравиться
Обзор ИИ для документов | Google Cloud
Этот документ представляет собой руководство по основным концепциям использования Document AI. Вам следует прочитать эту страницу, прежде чем переходить к любой другой документации или кратким руководствам.
Вам следует прочитать эту страницу, прежде чем переходить к любой другой документации или кратким руководствам.
Автоматизация рабочих процессов обработки документов
Компании во всем мире в значительной степени полагаются на документы для хранения и передачи информации. Эту информацию часто необходимо оцифровать, чтобы она стала полезной; однако, это обычно достигается с помощью трудоемких ручных процессов.
Например:
- Оцифровка книг для электронных книг
- Заполнение медицинских бланков в кабинетах врачей
- Представление отчетов о расходах на основании квитанций и счетов-фактур
- Аутентификация личности на основе удостоверений личности
- Утверждение кредитов на основании информации о доходах из налоговых форм
- Понимание контрактов по ключевым деловым соглашениям
Каждый из этих рабочих процессов включает в себя получение текста из документов, а затем понимание
как этот текст соответствует необходимым данным. Однако каждый тип документа имеет
различная структура и расположение, а самая важная информация может отличаться
в зависимости от конкретного варианта использования.
Однако каждый тип документа имеет
различная структура и расположение, а самая важная информация может отличаться
в зависимости от конкретного варианта использования.
Компоненты ИИ документа
ИИ документа — это понимание документа платформа, которая берет неструктурированные данные из документов и преобразует их в структурированные данные, облегчающие понимание, анализ и использование.
Document AI использует машинное обучение и Google Cloud, чтобы помочь вам создавать масштабируемые комплексные облачные приложения для обработки документов.
Используя Document AI, вы можете:
- Предварительно обрабатывать документы с определением качества изображения и устранением искажений
- Извлечение текста и информации о макете из файлов документов
- Определение пар ключ-значение в структурированных формах
- Разделить и классифицировать документы по типу
- Извлечение и нормализация объектов
- Маркировка и просмотр документов
- Хранение, поиск, систематизация, управление и анализ документов и метаданных
На этой диаграмме показаны все основные этапы обработки документов, которые
поддерживаемые Document AI, и как они могут соединяться друг с другом.
Процессор
Процессор ИИ для документов — это интерфейс между файлом документа и моделью машинного обучения, который выполняет действия по обработке документа. Их можно использовать для классификации, разделения, разбора или анализа документа.
Каждый проект Google Cloud должен создавать собственные экземпляры процессора.
Процессоры относятся к одной из следующих категорий:
- Общие — Готовые процессоры для совместимости с большинством документов
- Специализированный — встроенные процессоры для определенных типов документов
- Закупки. Документы, используемые для покупок и платежей, такие как счета и квитанции
- Идентификация — документы, используемые для проверки личности
- Кредитование – Документы, используемые для ипотечных кредитов
- Контракт — Извлечение и понимание объектов из деловых контрактов
- Пользовательский — Пользовательские процессоры для пользовательских документов и вариантов использования
В каждой категории есть несколько типов процессоров. Каждый тип предназначен для определенной задачи, такой как
Оптическое распознавание символов (OCR),
разбор формы, разделение,
классификация
или извлечение объекта для определенных типов документов.
Каждый тип предназначен для определенной задачи, такой как
Оптическое распознавание символов (OCR),
разбор формы, разделение,
классификация
или извлечение объекта для определенных типов документов.
Обратитесь к полному процессору и подробному списку для получения информации обо всех доступные типы процессоров для Document AI.
Какой процессор следует использовать?
Чтобы решить, какой тип процессора использовать для конкретного приложения, воспользуйтесь некоторыми общими рекомендациями:
Примечание: Все процессоры могут извлекать текст и информацию о макете.| Пример использования | Тип процессора |
|---|---|
| Извлечение текста и информации о макете из документов | Документ OCR |
| Извлечение таблиц или пар ключ-значение из структурированной формы в документе | Анализатор форм |
| Анализ качества отсканированного изображения документа | Document OCR или Intelligent Document Quality |
| Разделение или классификация документов, которые имеют специализированный процессор разделения/классификатора | Специализированный процессор разделителя/классификатора, соответствующий типу документа |
| Извлечение объектов из документа, имеющего соответствующий специализированный процессор | Специализированный процессор, соответствующий типу документа. Используйте Uptraining для повышения точности или извлечения дополнительных сущностей Используйте Uptraining для повышения точности или извлечения дополнительных сущностей |
| Разделение документов без специального процессора разделения | Создание пользовательского разделителя документов |
| Классифицировать документы, не имеющие специализированного процессора-классификатора | Создание пользовательского классификатора документов |
| Извлечение объектов из пользовательского документа, который соответствует критериям пользовательского процессора | Создание пользовательского экстрактора документов |
| Извлечение объектов из пользовательского документа, который не соответствует критериям пользовательского процессора | Используйте распознавание документов для извлечения текста и создания модели AutoML для извлечения сущностей |
Эта диаграмма помогает определить, какой процессор лучше всего подходит для каждого варианта использования.
Использование процессоров Document AI
Ниже приведены основные шаги по использованию Document AI для начала обработки документов:
Выберите процессор , подходящий для вашего варианта использования.
Для получения полной информации о каждом процессоре см. Полный процессор и подробный список.
Создайте процессор с помощью облачной консоли или Document AI API.
Document AI создает конечную точку прогнозирования , куда вы можете отправлять свои документы.
Подробные инструкции см. в разделе Создание процессора
Отправьте документ(ы) на обработку.
Document AI обрабатывает документ(ы) и возвращает один или несколько объектов
Document, содержащих извлеченную структурированную информацию.Подробные инструкции см.
 в разделах Отправка запроса на обработку и Обработка ответа на обработку.
в разделах Отправка запроса на обработку и Обработка ответа на обработку.
- Human-in-the-Loop (HITL) — проверка и корректировка человеком для обеспечения точности данных, извлекаемых процессорами Document AI для использования в критически важных бизнес-приложениях.
- Enterprise Knowledge Graph — обогащение данных реальными сущностями и связями.
- Document AI Warehouse — хранение, поиск, систематизация, управление и анализ документов и их структурированных метаданных.
- Сопутствующие товары
Как использовать Google Drive OCR и его альтернативу
PDFelement — мощный и простой редактор PDF
Начните с самого простого способа управления PDF-файлами с помощью PDFelement!
Попробуйте бесплатно Попробуйте бесплатно Попробуйте бесплатно
Иногда вам может понадобиться преобразовать изображение с подписью в текст и скопировать текст для других целей. В этом случае используйте Google Drive OCR . Как вы, возможно, уже знаете, вы можете сканировать и конвертировать изображения в текст в сервисах Google , таких как Google Drive. Итак, вы хотите узнать, как работает эта функция? Тогда продолжайте читать до конца. Я также познакомлю вас с лучшей альтернативой Google OCR.
В этом случае используйте Google Drive OCR . Как вы, возможно, уже знаете, вы можете сканировать и конвертировать изображения в текст в сервисах Google , таких как Google Drive. Итак, вы хотите узнать, как работает эта функция? Тогда продолжайте читать до конца. Я также познакомлю вас с лучшей альтернативой Google OCR.
В этой статье
01 Что такое Google OCR
02 Как использовать Google Drive OCR
03 Лучшая альтернатива Google Drive OCR
04 Часто задаваемые вопросы о Google Drive/Docs OCR
Часть 1. Что такое Google OCR?
В двух словах, Google OCR — это сервис машинного обучения, встроенный в его облачные сервисы, в частности в Google Диск. Эта служба может сканировать и преобразовывать изображения с подписями в доступный для поиска и редактирования текст. Вы можете извлекать тексты из файлов JPEG, JPG, GIF, PNG и TIFF. И хорошая новость заключается в том, что Google OCR на 100% бесплатен.
Помимо изображений с подписями, вы можете использовать Google OCR на Google Диске для извлечения данных из счетов, квитанций и других документов. Кроме того, этот сервис OCR поддерживает извлечение машинописного и рукописного текста. Но убедитесь, что ваши файлы изображений четкие для достижения наилучших результатов. Вы также заметите, что разрывы строк далеки от совершенства. Поэтому вам может потребоваться отредактировать текст с помощью редактора Word перед его использованием.
Кроме того, этот сервис OCR поддерживает извлечение машинописного и рукописного текста. Но убедитесь, что ваши файлы изображений четкие для достижения наилучших результатов. Вы также заметите, что разрывы строк далеки от совершенства. Поэтому вам может потребоваться отредактировать текст с помощью редактора Word перед его использованием.
Часть 2. Как использовать Google Drive OCR
Google Диск — это облачный файловый менеджер, который может помочь вам хранить, совместно использовать и совместно работать с любыми файлами и папками с любых устройств, таких как мобильное устройство, планшет или компьютер. С помощью Google Диска OCR вы можете конвертировать файлы изображений в текст, и он определит язык документа. Давайте узнаем, как использовать OCR Google Диска для преобразования отсканированного файла или изображения в текст.
Шаг 1 Загрузить PDF-файл на основе изображения
После входа в свою учетную запись Google Диска вы можете загрузить в нее свое изображение или отсканированный файл.
Шаг 2 Google Docs OCR
Найдите загруженный файл и откройте его с помощью Google Docs. После того, как он открыт в Документах Google, OCR Google Диска уже используется. Текст в файле изображения теперь доступен для редактирования.
Шаг 3 Сохранить файл
Нажмите кнопку «Файл» > «Загрузить», чтобы выбрать формат для сохранения на компьютере.
Вот как использовать функцию OCR Google Docs для преобразования отсканированного PDF в текст. Это очень просто, но Google Docs не может сохранить форматирование и макет PDF-файла. После использования OCR Google Диска вы можете обнаружить, что текстовое содержимое исходного файла было изменено. Если вы хотите сохранить исходное форматирование и макет PDF в выходных документах, попробуйте Wondershare PDFelement.
Преимущества использования Google Docs OCR
Бесплатный и простой в использовании.
Сверхбыстрый перевод OCR.
Поддерживает большинство языков.
Отредактируйте текст перед выделением и копированием.
Недостатки использования Google Docs OCR
Перевод на некоторых языках не является на 100% точным.
Ограничения на размер файла, что делает его непригодным для крупных организаций.
Не пакетное распознавание текста.
Часть 3. Лучшая альтернатива Google Drive OCR
Wondershare PDFelement — лучшая альтернатива Google OCR для малого, среднего и крупного бизнеса. Этот мощный инструмент OCR может сканировать и извлекать текст из PDF-файлов в пакетном режиме. Он может конвертировать PDF в доступный для поиска и редактирования текст на нескольких языках. PDFelement поддерживает испанский, английский, голландский, немецкий, французский и другие языки OCR.
Но это только основная часть. PDFelement позволяет улучшать извлеченный текст с помощью наложений изображений, шрифтов, водяных знаков, ссылок и аннотаций. Кроме того, вы можете выделить текст и добавить отзыв или комментарий. В отличие от Google OCR, PDFelement позволяет преобразовывать извлеченные тексты в несколько форматов, включая PDF, PPT, Word, Excel, EPUB, изображения и т. д. Кроме того, вы можете добавить электронную подпись для проверки документа.
В отличие от Google OCR, PDFelement позволяет преобразовывать извлеченные тексты в несколько форматов, включая PDF, PPT, Word, Excel, EPUB, изображения и т. д. Кроме того, вы можете добавить электронную подпись для проверки документа.
Выполните следующие действия для сканирования, извлечения и редактирования текста PDF с помощью PDFelement:
Шаг 1 Загрузите файл(ы) PDF.
Запустите Wondershare PDFelement на компьютере Mac или Windows и нажмите «Открыть файлы», чтобы загрузить файлы PDF. Помните, что вы можете добавлять и распознавать несколько файлов в PDFelement.
Шаг 2 Распознавание PDF-документа.
После успешного добавления файла PDF коснитесь вкладки «Инструменты» и выберите OCR. Вы также можете нажать кнопку «Область OCR», чтобы выбрать и распознать определенные тексты, которые вы хотите извлечь. В любом случае выберите язык вывода OCR и нажмите «Применить к распознаванию документа».
Шаг 3 Отредактируйте и экспортируйте файл OCR (необязательно).
Вы хотите улучшить файл OCR перед его преобразованием и экспортом? Нажмите «Изменить», чтобы применить вложения, комментарии, тексты, изображения, водяные знаки и т. д. Если все устраивает, нажмите «Преобразовать» и выберите выходной формат. Помимо локального сохранения документов, PDFelement также поддерживает облачный экспорт в Google Drive, OneDrive и Dropbox. И да, вы можете напрямую печатать PDF на подключенном принтере.
Профи
OCR PDF с рукописным, распечатанным и отсканированным текстом изображения.
Поддерживается несколько языков OCR.
Поддерживает пакетное распознавание символов.
Преобразование документа в PDF, Doc, Excel, PPT и т. д.
Редактирование PDF с аннотациями, комментариями, электронной подписью, водяными знаками и т. д.
Можно использовать больше языков OCR.
Попробуйте бесплатно Попробуйте бесплатно КУПИТЬ СЕЙЧАС КУПИТЬ СЕЙЧАС
Часть 4.
 Часто задаваемые вопросы о Google Drive/Docs OCR
Часто задаваемые вопросы о Google Drive/Docs OCR1. Является ли Google Drive OCR бесплатным?
Да. Google Диск предоставляет вам быстрый и простой способ преобразования изображений в текст. Встроенное программное обеспечение OCR позволяет сканировать неограниченное количество документов в Документах Google. Итак, продолжайте и извлекайте эти подписи к изображениям бесплатно.
2. Какой формат поддерживает распознавание символов Google Диска?
OCR Google Диска в настоящее время совместимо с большинством форматов изображений. Вы можете сканировать JPEG, JPG, PNG, GIF и TIFF. И, конечно же, он поддерживает сканирование PDF-файлов.
3. Сколько языков может распознавать Google Drive OCR?
Теперь это одна из областей, где Google OCR превосходит большинство программ OCR. Этот сервис машинного обучения обеспечивает не менее 90% перевода на более чем 200 языков. Он поддерживает арабский, эстонский, хинди, суахили, сомалийский и другие языки.
4. Как использовать Google Docs для распознавания арабского текста?
Преобразование подписей к изображениям в редактируемый арабский язык выполняется быстро и просто с помощью Документов Google. Загрузите свое изображение в Документы Google и нажмите «Инструменты». Затем выберите «Перевести документ» и выберите арабский язык в качестве языка перевода. Наконец, нажмите «Перевести», чтобы преобразовать текст изображения в арабский.
5. Как включить распознавание текста на Google Диске?
Чтобы включить OCR Google Диска, вам нужна только учетная запись Google Диска. Затем загрузите свою фотографию в Документы Google и распознайте ее соответствующим образом.
Заключение
Видите ли, вы можете бесплатно переводить PDF-файлы и фотографии в редактируемые тексты с помощью встроенной службы распознавания текста Google. Загрузите свою фотографию на Google Диск и извлеките текст, выполнив шаги, перечисленные выше. Но если вам нужен более полный сервис OCR, используйте Wondershare PDFelement.