
Смартфоны научились моментальному чтению и переводу
Технологии
close
100%
Известный онлайн-переводчик Google Translate теперь может моментально перевести текст с листа, если навести на него камеру смартфона. Помимо Google над подобными онлайн-переводчиками и системами распознавания текста успешно работают и другие компании, в том числе российские.
Google Translate
Google добавила в свое приложение Google Translate для iOS и Android функции моментального перевода с элементами дополненной реальности. Пользователю достаточно навести камеру на фрагмент текста, и в окне приложения появляется моментальный перевод. Подобный функционал почти гарантированно станет очень популярным у туристов, путешественников и при международных командировках.
Новый функционал базируется на технологии Word Lens компании Quest Visual, которую Google купила в мае 2014 года.
В настоящее время новая опция Google Translate поддерживается при переводе с английского на один из шести языков (и обратно) — русский, французский, немецкий, испанский, португальский и итальянский. Для работы приложения требуется постоянное подключение к интернету.
ABBYY Lingvo
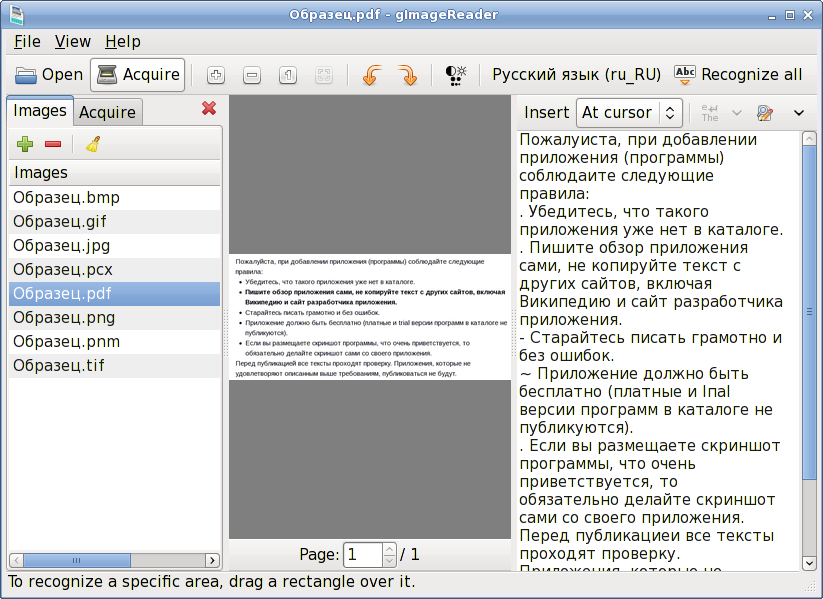
ABBYY, компания с российскими корнями, специализирующаяся на технологиях распознавания текста, разработала приложение, которое также распознает и переводит текст, используя камеру смартфона. Новая технология была представлена в 2014 году. В отличие от Google Translate, где текст переводится по умолчанию, для перевода с помощью ABBYY Lingvo требуется навести на текст камеру и нажать кнопку.
В настоящий момент ABBYY Lingvo поддерживает перевод с 28 языков.
ABBYY Lingvo является платным приложением. Существуют версии как для iOS, так и для Android. Существенным отличием от Google Translate является то, что ABBYY Lingvo может работать в офлайновом режиме.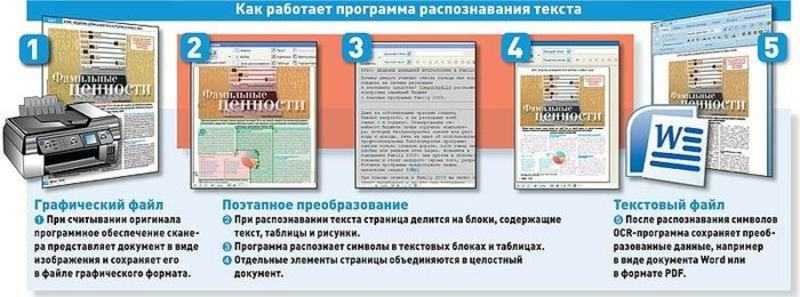
Skype Translator
В новом сервисе Skype Translator от Microsoft голосовой перевод обещает быть еще естественнее, чем в Google Translate: программа выступает в роли синхронного переводчика. Пользователь получает не просто текст с переводом слов его собеседника в окне чата, приложение еще и произносит реплики вслух.
На сегодняшний день Skype Translator знает только английский и испанский языки. В ближайшем будущем приложение должно получить поддержку немецкого языка: перевод с английского на немецкий и наоборот на презентации нового сервиса продемонстрировали вице-президент Skype Гурдип Пол и сотрудница Microsoft Диана Хайнрихс. Также в планы компании входит поддержка арабского, французского, итальянского, португальского, японского, корейского и двух диалектов китайского.
Skype Translator понимает все произносимые слова в широком контексте — таким образом, чем более развернутые предложения используются при общении, тем более точным получается перевод.
Пока Skype Translator работает только на платформе Windows 8.1, и скачать его можно только по приглашению Microsoft (для этого необходимо оставить заявку на сайте Skype).
Waygo
Waygo – это офлайн-переводчик и словарь, который умеет переводить с китайского, японского и корейского языков на английский и наоборот. Разработчики приложения позиционируют его прежде всего как инструмент для путешественников — возможность пользоваться моментальным переводом даже без доступа к интернету в этом случае будет явным достоинством программы.
Waygo моментально переводит текст, который сфотографировал или на который навел камеру смартфона пользователь. После этого переводом можно поделиться, отправив его по электронной почте, в SMS или через социальные сети.
Пока приложение способно распознавать только печатный текст и не понимает «креативные» шрифты или рукописные иероглифы.
Бесплатная версия приложения позволяет переводить 10 надписей в день. Waygo доступен для iOS и Android.
Подписывайтесь на «Газету.Ru» в Новостях, Дзен и Telegram.
Чтобы сообщить об ошибке, выделите текст и нажмите Ctrl+Enter
Новости
Дзен
Telegram
Картина дня
Военная операция на Украине. День 374-й
Онлайн-трансляция специальной военной операции на Украине — 374-й день
«Плата за войну с Ираном может оказаться для США непомерно высокой»
Военный эксперт Ходаренок — о ядерной программе Ирана и возможном конфликте республики с США
Это все придумал Сорос: данные жителей Дальнего Востока попадают в «недружественные страны»
Специалист по доменам предупредил об опасности транзита данных россиян через Европу и США
В трех областях Украины объявлена воздушная тревога
Глава Минобороны РФ Шойгу проинспектировал группировку войск «Восток» в зоне спецоперации
РБК: Евросоюз разрешил Россельхозбанку использовать факс и e-mail вместо SWIFT
Объемы валютных депозитов россиян снизились в январе до минимальных с 2008 года $53,7 млрд
Новости и материалы
Боец UFC Волков признался, что из-за Дзюбы стал болеть за «Локомотив»
Мануальный терапевт Едзиев рассказал, что делать при болях в шее
В ФСБ сообщили о задержании жительницы Москвы по подозрению в финансировании ВСУ
Немецкий политик рассказал о недовольстве граждан ФРГ поставками оружия Украине
РИА Новости: фирма из Германии отказала РФ в участии в выставке в Таиланде
В Ханты-Мансийске открылся XXI Международный фестиваль дебютов «Дух огня»
Бородавко заявил, что слова норвежских лыжников проходят жесткую цензуру
В Пекине заявили, что раздувание китайской угрозы не служит интересам Китая и Евросоюза
Полянский высмеял оговорку пресс-секретаря Байдена о «Российской Народной Республике»
Звезда «Побега из Шоушенка» Клэнси Браун сыграет врага Бэтмена в сериале «Пингвин»
В Санкт-Петербурге психически больной мужчина устроил драку в рекламном агентстве и умер
Президента США Байдена попросили вмешаться в дело об отказе Джоковичу в визе
Arctic Monkeys и Guns N’ Roses стали хэдлайнерами фестиваля «Гластонбери»
В ЛНР заявили об отсутствии серых зон между российскими и украинскими силами под Кременной
В Москве произошло обрушение строительных конструкций, один человек погиб
Эксперт ответил на страхи айтишников остаться без работы из-за ИИ
Президент Польши заявил, что российские спортсмены не должны требовать участия в турнирах
В КНР рассказали о причинах наращивания военного бюджета
Все новости
Задушили ремнем, добили ножом. Что известно о гибели разработчика «Спутника V» в столице
Что известно о гибели разработчика «Спутника V» в столице
На северо-западе Москвы убили одного из создателей вакцины «Спутник V» Андрея Ботикова
Тест: как проводились медицинские операции в древние времена?
Знаете ли вы, как древние хирурги оперировали больных?
Дмитрий Воденников
Рукописи не едят
О голодном Гоголе и прожорливом огне
«Муж отказывает мне в сексе с тех пор, как я перестала удалять волосы на теле»
Менеджер из Казани – о ссоре из-за стандартов красоты
Грач, дрозд, скворец: сможете ли вы назвать птицу на фотографии
Викторина на знание птиц, которые нас окружают
«Давят, чтобы признать независимость Косово». В Белграде объяснили фейки о поставках оружия Киеву
В Белграде объяснили фейки о поставках оружия Киеву
Глава МИД Сербии Дачич заявил, что его страна не поставляет оружие ни России, ни Украине
Умер Том Сайзмор — он играл в «Схватке» и «Спасти рядового Райана»
В США сообщили о расколе в ОПЕК. Как это повлияло на цену нефти
Мировые цены на нефть упали из-за сообщений о возможном выходе ОАЭ из ОПЕК
«У нас много кто с ножами ходит». Подробности нападения в московской школе
В Москве школьница пырнула ножом 13-летнего мальчика
«Новый уровень российской пропаганды». Украина требует «отменить» игру Atomic Heart
Вице-премьер Украины Федоров призвал крупнейшие онлайн-магазины запретить продажи Atomic Heart
«Украина серьезно проигрывает войну»: экс-советник ЦРУ назвал единственный вариант ответа США
Экс-советник ЦРУ Рикардс: эскалация конфликта на Украине станет следующим шагом США
«Все с одобрения и при поддержке США». МИД РФ указал на роль НАТО в теракте в Брянской области
ФСБ опубликовало видео с расстрелянными украинскими диверсантами машинами в Брянской области
«Прерогатива президента». В Кремле сообщили, что военное положение пока не вводилось
Песков: решение ввести военное положение на границе с Украиной не принималось
Обнаружение машинного перевода текста на основе сходства текста с двусторонним переводом
Hoang-Quoc Nguyen-Son, Тран Тао, Сейра Хидано, Ишита Гупта, Shinsaku Kiyomoto
Abstract
Переведенные тексты использовались в злоумышленных целях, т. е. для плагиата или поддельных отзывов. Существующие детекторы были построены вокруг определенного переводчика (например, Google), но не могут обнаружить переведенный текст от незнакомого переводчика. Если мы используем один и тот же переводчик, переведенный текст будет похож на его двунаправленный перевод, когда текст переводится на другой язык и переводится обратно на исходный язык. Однако текст, переведенный туда и обратно, существенно отличается от исходного текста или текста, переведенного с помощью чужого переводчика. Следовательно, мы предлагаем детектор, использующий сходство текста с двусторонним переводом (TSRT). TSRT достигает 86,9% точность определения переведенного текста от чужого переводчика. Он превосходит существующие детекторы (77,9%) и человеческое распознавание (53,3%).
е. для плагиата или поддельных отзывов. Существующие детекторы были построены вокруг определенного переводчика (например, Google), но не могут обнаружить переведенный текст от незнакомого переводчика. Если мы используем один и тот же переводчик, переведенный текст будет похож на его двунаправленный перевод, когда текст переводится на другой язык и переводится обратно на исходный язык. Однако текст, переведенный туда и обратно, существенно отличается от исходного текста или текста, переведенного с помощью чужого переводчика. Следовательно, мы предлагаем детектор, использующий сходство текста с двусторонним переводом (TSRT). TSRT достигает 86,9% точность определения переведенного текста от чужого переводчика. Он превосходит существующие детекторы (77,9%) и человеческое распознавание (53,3%).- Anthology ID:
- 2021.naacl-main.462
- Volume:
- Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies 10 1 3 июнь Month1: Month1
- Год:
- 2021
- Адрес:
- Онлайн
- Venue:
- NAACL
- SIG:
- Publisher:
- Association for Computational Linguistics
- Note:
- Pages:
- 5792–5797
- Language:
- URL:
- https:/ /aclanthology.
 org/2021.naacl-main.462
org/2021.naacl-main.462 - . Тран Тао, Сейра Хидано, Исита Гупта и Синсаку Киёмото. 2021. Обнаружение машинного перевода текста на основе сходства текста с двусторонним переводом. В Материалы конференции 2021 года Североамериканского отделения Ассоциации вычислительной лингвистики: технологии человеческого языка , страницы 5792–5797, онлайн. Ассоциация компьютерной лингвистики.
- Процитируйте (неофициально):
- Обнаружение машинного перевода текста на основе сходства текста с двусторонним переводом (Nguyen-Son et al., NAACL 2021)
- Копия цитирования:
- PDF:
- https://aclanthology.org/2021.naacl-main.462.pdf
- Video:
- https://aclanthology.org/2021.naacl-main.462.mp4
- Code
- quocnsh/machine_translation_detection
 org/2021.naacl-main.462
org/2021.naacl-main.462- BibTeX
- MODS XML
- Endnote
- Preformatted
@inproceedings{nguyen-son-etal-2021-machine,
title = "Обнаружение машинно переведенного текста на основе схожести текста с двусторонним переводом",
автор = "Нгуен-Сон, Хоанг-Куок и
Тао, Тран и
Хидано, Сейра и
Гупта, Ишита и
Киёмото, Синсаку».
booktitle = "Материалы конференции 2021 года Североамериканского отделения Ассоциации компьютерной лингвистики: технологии человеческого языка",
месяц = июнь,
год = "2021",
адрес = "Онлайн",
издатель = "Ассоциация вычислительной лингвистики",
url = "https://aclanthology.org/2021.naacl-main.462",
doi = "10.18653/v1/2021.naacl-main.462",
страницы = "5792--5797",
abstract = "Переведенные тексты использовались в злонамеренных целях, т. е. для плагиата или поддельных обзоров. Существующие детекторы были построены вокруг определенного переводчика (например, Google), но не могут обнаружить переведенный текст от чужого переводчика. Если мы используем тот же переводчик, переведенный текст похож на его двунаправленный перевод, то есть когда текст переводится на другой язык и переводится обратно на исходный язык, однако двусторонне переведенный текст существенно отличается от исходного текста или переведенного текста. с использованием странного транслятора, поэтому мы предлагаем детектор, использующий текстовое сходство с переводом туда и обратно (TSRT). TSRT достигает 86,9{\%} точность определения переведенного текста от чужого переводчика. Он превосходит существующие детекторы (77,9%} и человеческое распознавание (53,3%}).",
}
 booktitle = "Материалы конференции 2021 года Североамериканского отделения Ассоциации компьютерной лингвистики: технологии человеческого языка",
месяц = июнь,
год = "2021",
адрес = "Онлайн",
издатель = "Ассоциация вычислительной лингвистики",
url = "https://aclanthology.org/2021.naacl-main.462",
doi = "10.18653/v1/2021.naacl-main.462",
страницы = "5792--5797",
abstract = "Переведенные тексты использовались в злонамеренных целях, т. е. для плагиата или поддельных обзоров. Существующие детекторы были построены вокруг определенного переводчика (например, Google), но не могут обнаружить переведенный текст от чужого переводчика. Если мы используем тот же переводчик, переведенный текст похож на его двунаправленный перевод, то есть когда текст переводится на другой язык и переводится обратно на исходный язык, однако двусторонне переведенный текст существенно отличается от исходного текста или переведенного текста. с использованием странного транслятора, поэтому мы предлагаем детектор, использующий текстовое сходство с переводом туда и обратно (TSRT).
booktitle = "Материалы конференции 2021 года Североамериканского отделения Ассоциации компьютерной лингвистики: технологии человеческого языка",
месяц = июнь,
год = "2021",
адрес = "Онлайн",
издатель = "Ассоциация вычислительной лингвистики",
url = "https://aclanthology.org/2021.naacl-main.462",
doi = "10.18653/v1/2021.naacl-main.462",
страницы = "5792--5797",
abstract = "Переведенные тексты использовались в злонамеренных целях, т. е. для плагиата или поддельных обзоров. Существующие детекторы были построены вокруг определенного переводчика (например, Google), но не могут обнаружить переведенный текст от чужого переводчика. Если мы используем тот же переводчик, переведенный текст похож на его двунаправленный перевод, то есть когда текст переводится на другой язык и переводится обратно на исходный язык, однако двусторонне переведенный текст существенно отличается от исходного текста или переведенного текста. с использованием странного транслятора, поэтому мы предлагаем детектор, использующий текстовое сходство с переводом туда и обратно (TSRT). TSRT достигает 86,9{\%} точность определения переведенного текста от чужого переводчика. Он превосходит существующие детекторы (77,9%} и человеческое распознавание (53,3%}).",
}
TSRT достигает 86,9{\%} точность определения переведенного текста от чужого переводчика. Он превосходит существующие детекторы (77,9%} и человеческое распознавание (53,3%}).",
}
<моды> <информация о заголовке> Обнаружение машинно переведенного текста на основе схожести текста с двусторонним переводом <название типа="личное">Хоанг-Куок Нгуен-Сон <роль>автор <название типа="личное">Транс Тао <роль>автор <название типа="личное">Сейра Хидано <роль>автор <название типа="личное">Исита Гупта <роль>автор <название типа="личное">Синсаку Киёмото <роль>автор <информация о происхождении>2021-06 текст <информация о заголовке> Материалы конференции 2021 года Североамериканского отделения Ассоциации компьютерной лингвистики: технологии человеческого языка <информация о происхождении>Ассоциация компьютерной лингвистики <место>Онлайн публикация конференции Переведенные тексты использовались в злонамеренных целях, т. nguyen-son-etal-2021-machine 10.18653/v1/2021.naacl-main.462 <местоположение> https://aclanthology. <часть> <дата>2021-06 <единица экстента="страница"> <начало>57925797
 е. для плагиата или поддельных обзоров. Существующие детекторы были построены вокруг определенного переводчика (например, Google), но не могут обнаружить переведенный текст от незнакомого переводчика. Если мы используем один и тот же переводчик, переведенный текст будет похож на его двунаправленный перевод, когда текст переводится на другой язык и переводится обратно на исходный язык. Однако текст, переведенный туда и обратно, существенно отличается от исходного текста или текста, переведенного с помощью чужого переводчика. Следовательно, мы предлагаем детектор, использующий сходство текста с двусторонним переводом (TSRT). TSRT достигает 86,9% точность определения переведенного текста от чужого переводчика. Он превосходит существующие детекторы (77,9%) и человеческое распознавание (53,3%).
е. для плагиата или поддельных обзоров. Существующие детекторы были построены вокруг определенного переводчика (например, Google), но не могут обнаружить переведенный текст от незнакомого переводчика. Если мы используем один и тот же переводчик, переведенный текст будет похож на его двунаправленный перевод, когда текст переводится на другой язык и переводится обратно на исходный язык. Однако текст, переведенный туда и обратно, существенно отличается от исходного текста или текста, переведенного с помощью чужого переводчика. Следовательно, мы предлагаем детектор, использующий сходство текста с двусторонним переводом (TSRT). TSRT достигает 86,9% точность определения переведенного текста от чужого переводчика. Он превосходит существующие детекторы (77,9%) и человеческое распознавание (53,3%). org/2021.naacl-main.462
org/2021.naacl-main.462%0 Материалы конференции %T Обнаружение машинного перевода текста по сходству текста с двусторонним переводом %А Нгуен-Сон, Хоанг-Куок %A Тао, Тран %A Хидано, Сейра %А Гупта, Ишита %A Киёмото, Шинсаку %S Материалы конференции 2021 года Североамериканского отделения Ассоциации компьютерной лингвистики: технологии человеческого языка %D 2021 %8 июня %I Ассоциация компьютерной лингвистики %С онлайн %F nguyen-son-etal-2021-machine %X Переведенные тексты использовались в злонамеренных целях, т. е. для плагиата или поддельных обзоров. Существующие детекторы были построены вокруг определенного переводчика (например, Google), но не могут обнаружить переведенный текст от незнакомого переводчика. Если мы используем один и тот же переводчик, переведенный текст будет похож на его двунаправленный перевод, когда текст переводится на другой язык и переводится обратно на исходный язык.
 Однако текст, переведенный туда и обратно, существенно отличается от исходного текста или текста, переведенного с помощью чужого переводчика. Следовательно, мы предлагаем детектор, использующий сходство текста с двусторонним переводом (TSRT). TSRT достигает 86,9% точность определения переведенного текста от чужого переводчика. Он превосходит существующие детекторы (77,9%) и человеческое распознавание (53,3%).
%R 10.18653/v1/2021.naacl-main.462
%U https://aclanthology.org/2021.naacl-main.462
%U https://doi.org/10.18653/v1/2021.naacl-main.462
%Р 5792-5797
Однако текст, переведенный туда и обратно, существенно отличается от исходного текста или текста, переведенного с помощью чужого переводчика. Следовательно, мы предлагаем детектор, использующий сходство текста с двусторонним переводом (TSRT). TSRT достигает 86,9% точность определения переведенного текста от чужого переводчика. Он превосходит существующие детекторы (77,9%) и человеческое распознавание (53,3%).
%R 10.18653/v1/2021.naacl-main.462
%U https://aclanthology.org/2021.naacl-main.462
%U https://doi.org/10.18653/v1/2021.naacl-main.462
%Р 5792-5797
Уценка (неофициальная)
[Обнаружение машинно переведенного текста на основе сходства текста с двусторонним переводом] (https://aclanthology.org/2021.naacl-main.462) (Nguyen-Son et al., NAACL 2021)
- Обнаружение машинного перевода текста на основе схожести текста с двусторонним переводом (Нгуен-Сон и др., NAACL 2021) Синсаку Киёмото. 2021. Обнаружение машинного перевода текста на основе сходства текста с двусторонним переводом. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , страницы 5792–5797, онлайн. Ассоциация компьютерной лингвистики.
 In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , страницы 5792–5797, онлайн. Ассоциация компьютерной лингвистики.
In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , страницы 5792–5797, онлайн. Ассоциация компьютерной лингвистики.Языковой перевод и распознавание символов с помощью Tesseract и Python
Нажмите здесь, чтобы загрузить исходный код к этому сообщению
Учитывая, что мы можем определить систему письма текста, возникает вопрос:
Возможно ли перевести текст с одного языка на другой с помощью OCR и Tesseract?
Чтобы научиться переводить языки с помощью Tesseract и Python, просто продолжайте читать.
Ищете исходный код этого поста?
Перейти прямо к разделу загрузок Языковой перевод и распознавание текста с помощью Tesseract и Python Краткий ответ: да , это возможно, но нам понадобится небольшая помощь из популярной библиотеки textblob Пакет Python для обработки текста (TextBlob: упрощенная обработка текста). К концу этого руководства вы автоматически переведете текст с OCR с одного языка на другой.
К концу этого руководства вы автоматически переведете текст с OCR с одного языка на другой.
Чтобы следовать этому руководству, в вашей системе должна быть установлена библиотека OpenCV.
К счастью, OpenCV можно установить в pip:
$ pip install opencv-contrib-python
Если вам нужна помощь в настройке среды разработки для OpenCV, я настоятельно рекомендую прочитать мой pip1 install3V руководство — оно поможет вам начать работу за считанные минуты.
Проблемы с настройкой среды разработки? Рис. 1: Возникли проблемы с настройкой среды разработки? Хотите получить доступ к предварительно настроенным ноутбукам Jupyter, работающим в Google Colab? Не забудьте присоединиться к PyImageSearch University — вы освоите этот учебник за считанные минуты.
Все, что сказал, вы:
- Мало времени?
- Изучение административно заблокированной системы вашего работодателя?
- Хотите избавиться от хлопот, связанных с командной строкой, менеджерами пакетов и виртуальными средами?
- Готовы запустить код прямо сейчас в вашей системе Windows, macOS или Linux?
Тогда присоединяйтесь к Университету PyImageSearch уже сегодня!
Получите доступ к Jupyter Notebooks для этого руководства и других руководств PyImageSearch, которые предварительно настроены для работы в экосистеме Google Colab прямо в вашем веб-браузере! Установка не требуется.
И самое главное, эти ноутбуки Jupyter будут работать на Windows, macOS и Linux!
Цели обученияВ этом учебном пособии вы:
- Научитесь переводить текст с помощью
TextBlobПакет Python перевод текста
В первой части этого руководства мы кратко обсудим пакет textblob и то, как его можно использовать для перевода текста. Оттуда мы рассмотрим структуру каталогов нашего проекта и реализуем наш сценарий OCR и перевода текста Python. Мы завершим урок обсуждением результатов OCR и перевода текста.
Оттуда мы рассмотрим структуру каталогов нашего проекта и реализуем наш сценарий OCR и перевода текста Python. Мы завершим урок обсуждением результатов OCR и перевода текста.
Для перевода текста с одного языка на другой мы будем использовать пакет Python textblob (https://textblob.readthedocs.io/en/dev/). Если вы следовали инструкциям по настройке среды разработки из предыдущего руководства, то в вашей системе уже должен быть установлен textblob . Если нет, вы можете установить его с помощью pip :
$ pip install textblob
После установки textblob вы должны выполнить следующую команду для загрузки корпусов Natural Language Toolkit (NLTK), которые textblob использует для автоматического анализа текста:
$ python -m textblob.
 download_corpora
download_corpora ознакомьтесь с библиотекой, открыв оболочку Python:
$ python >>> из textblob импортировать TextBlob >>>
Обратите внимание, как мы импортируем класс TextBlob — этот класс позволяет нам автоматически анализировать фрагмент текста на наличие тегов, именных словосочетаний и, да, даже языкового перевода. После создания экземпляра мы можем вызвать translate() класса TextBlob и выполнить автоматический перевод текста. Давайте используем TextBlob , чтобы сделать это сейчас: UTF8ipxm
>>> text = u"おはようございます。" >>> tb = TextBlob(текст) >>> переведено = tb.
 translate(to="en")
>>> печатать(переведено)
Доброе утро.
>>>
translate(to="en")
>>> печатать(переведено)
Доброе утро.
>>> Обратите внимание, как я успешно перевел японскую фразу для «Доброе утро» на английский язык.
Структура проектаНачнем с рассмотрения структуры каталогов проекта для этого руководства:
|-- comic.png |-- ocr_translate.py
Наш проект состоит из забавного мультяшного изображения, которое я создал с помощью инструмента для создания комиксов Explosm. Наш OCR-транслятор textblob размещен в сценарии ocr_translate.py .
Теперь мы готовы реализовать наш скрипт Python, который будет автоматически распознавать текст и переводить его на выбранный нами язык. Откройте
Откройте ocr_translate.py в структуру каталогов нашего проекта и вставьте следующий код:
# импортировать необходимые пакеты
из textblob импортировать TextBlob
импортировать питессеракт
импортировать аргументы
импорт cv2
# создаем анализатор аргументов и анализируем аргументы
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="путь к входному изображению для распознавания")
ap.add_argument("-l", "--lang", type=str, default="es",
help="язык для перевода текста OCR (по умолчанию испанский)")
аргументы = вары (ap.parse_args()) Начнем с нашего импорта, где TextBlob является наиболее заметным для этого скрипта. Оттуда мы погружаемся в нашу процедуру разбора аргументов командной строки. У нас есть два аргумента командной строки:
Оттуда мы погружаемся в нашу процедуру разбора аргументов командной строки. У нас есть два аргумента командной строки:
-
--image: Путь к нашему входному изображению для OCR и переведенный -
--lang: Язык для перевода текста OCR на – по умолчанию это испанский (es)
Используя pytesseract , мы распознаем наше входное изображение:
# загрузить исходное изображение и преобразовать его из канала BGR в канал RGB # заказ изображение = cv2.imread (аргументы ["изображение"]) rgb = cv2.cvtColor (изображение, cv2.
 COLOR_BGR2RGB)
# использовать Tesseract для распознавания изображения, затем заменить символы новой строки
# с одним пробелом
текст = pytesseract.image_to_string(rgb)
текст = текст.заменить("\n", "")
# показать исходный текст OCR
распечатать("ОРИГИНАЛ")
распечатать("========")
печать (текст)
print("")
COLOR_BGR2RGB)
# использовать Tesseract для распознавания изображения, затем заменить символы новой строки
# с одним пробелом
текст = pytesseract.image_to_string(rgb)
текст = текст.заменить("\n", "")
# показать исходный текст OCR
распечатать("ОРИГИНАЛ")
распечатать("========")
печать (текст)
print("") После загрузки и преобразования нашего --image в формат RGB ( Строки 17 и 18 ), мы отправляем его через движок Tesseract через pytesseract ( Line 22 ). Наш пакет textblob не будет знать, что делать с символами новой строки, присутствующими в text , поэтому мы заменим их пробелами ( Line 23 ).
После распечатки исходного текста с OCR мы продолжим и переведем строку на желаемый язык:
# переведем текст на другой язык tb = TextBlob(текст) переведено = tb.
 translate(to=args["язык"])
# показать переведенный текст
распечатать("ПЕРЕВОД")
распечатать("===========")
печать(перевод)
translate(to=args["язык"])
# показать переведенный текст
распечатать("ПЕРЕВОД")
распечатать("===========")
печать(перевод) Строка 32 создает объект TextBlob , передавая исходный текст конструктору. Оттуда Строка 33 переводит tb в желаемый --lang . И, наконец, мы распечатываем переведенный результат в наш терминал ( Lines 36-38 ).
Вот и все. Просто имейте в виду сложности механизмов перевода. Движок TextBlob под капотом похож на такие сервисы, как Google Translate, хотя, возможно, менее мощный. Когда в середине 2000-х появился Google Translate, он не был таким совершенным и точным, как сегодня. Кто-то может возразить, что Google Translate — это золотой стандарт. В зависимости от ваших потребностей в переводе OCR вы можете заменить вызов API на REST API Google Translate, если обнаружите, что
В зависимости от ваших потребностей в переводе OCR вы можете заменить вызов API на REST API Google Translate, если обнаружите, что textblob вам не подходит.
Теперь мы готовы к распознаванию входного изображения с помощью Tesseract, а затем к переводу текста с помощью textblob . Чтобы протестировать наш автоматический скрипт распознавания и перевода, откройте терминал и выполните команды, показанные на рис. 2 ( справа ). Здесь наше входное изображение на слева содержит английское восклицание «Вы сказали мне, что научиться распознаванию текста будет легко!» Это изображение было создано с помощью генератора комиксов Explosm. Как показывает вывод нашего терминала, мы успешно перевели текст на испанский, немецкий и арабский языки (язык с написанием справа налево ).
 Результаты Tesseract для OCR и
Результаты Tesseract для OCR и textblob для перевода восклицательного знака «Вы говорили мне, что научиться распознаванию символов будет легко!» на испанский, немецкий и арабский эквиваленты. Распознавание и перевод текста очень просты, если вы используете textblob пакет!
Что дальше? Я рекомендую университет PyImageSearch.
Информация о курсе:
Всего 69 занятий • 73 часа обучающих видеороликов по запросу • Последнее обновление: февраль 2023 г. если бы у вас был правильный учитель, вы могли бы освоить компьютерное зрение и глубокое обучение.
Считаете ли вы, что изучение компьютерного зрения и глубокого обучения должно занимать много времени, быть непосильным и сложным? Или должен включать сложную математику и уравнения? Или требуется степень в области компьютерных наук?
Дело , а не .
Все, что вам нужно, чтобы освоить компьютерное зрение и глубокое обучение, — это чтобы кто-то объяснил вам простые, интуитивно понятные термины.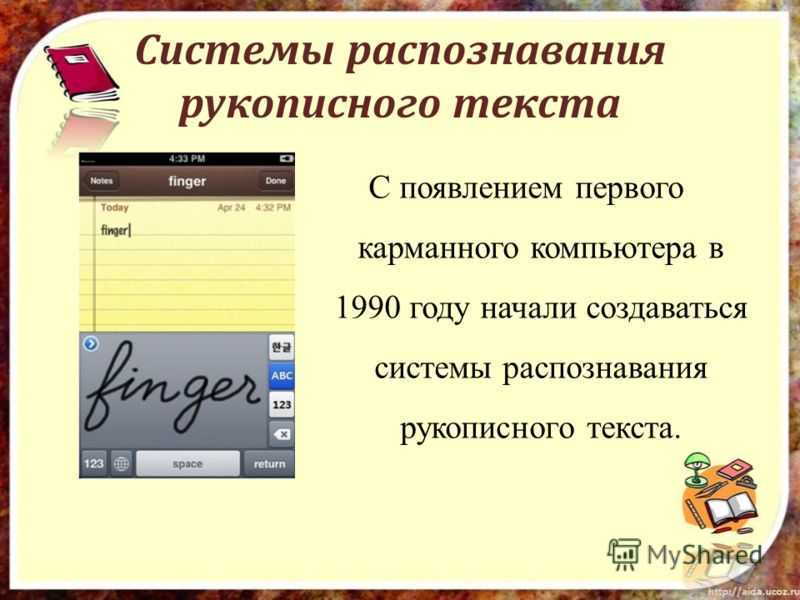 Именно это я и делаю . Моя миссия — изменить образование и то, как преподаются сложные темы искусственного интеллекта.
Именно это я и делаю . Моя миссия — изменить образование и то, как преподаются сложные темы искусственного интеллекта.
Если вы серьезно относитесь к изучению компьютерного зрения, вашей следующей остановкой должен быть PyImageSearch University, самый полный онлайн-курс по компьютерному зрению, глубокому обучению и OpenCV на сегодняшний день. Здесь вы узнаете, как успешно и уверенно применяйте компьютерное зрение в своей работе, исследованиях и проектах. Присоединяйтесь ко мне в мастерстве компьютерного зрения.
Внутри PyImageSearch University вы найдете:
- ✓ 69 курсов по основным темам компьютерного зрения, глубокого обучения и OpenCV
- &проверить; 69 Сертификатов об окончании
- &проверить; 73 часа видео по запросу
- &проверить; Выпуск новых курсов регулярно , чтобы вы могли идти в ногу с самыми современными методами
- &проверить; Предварительно настроенные ноутбуки Jupyter в Google Colab
- &проверить; Запускайте все примеры кода в веб-браузере — работает в Windows, macOS и Linux (конфигурация среды разработки не требуется!)
- &проверить; Доступ к централизованным репозиториям кода для всех 500+ руководств на PyImageSearch
- &проверить; Простая загрузка одним щелчком кода, наборов данных, предварительно обученных моделей и т. д.
- &проверить; Доступ к номеру на мобильном телефоне, ноутбуке, настольном компьютере и т. д.
 д.
д.Нажмите здесь, чтобы присоединиться к Университету PyImageSearch
Сводка Из этого руководства вы узнали, как автоматически выполнять распознавание символов и переводить текст с помощью Tesseract, Python и библиотеки textblob . С помощью textblob перевод текста был таким же простым, как вызов одной функции.
В нашем следующем уроке вы узнаете, как использовать Tesseract для автоматического распознавания языков, отличных от английского, включая нелатинские системы письма (например, арабский, китайский и т. д.).
Чтобы загрузить исходный код к этому сообщению (и получать уведомления, когда будущие руководства будут опубликованы здесь, на PyImageSearch), просто введите свой адрес электронной почты в форму ниже!
Загрузите исходный код и БЕСПЛАТНОЕ 17-страничное руководство по ресурсам
Введите свой адрес электронной почты ниже, чтобы получить .