
Как Эффективно Преобразовать Отсканированный PDF в Текст
Audrey Goodwin
2021-05-20 14:37:28 • Опубликовано : Инструкции по статьям • Проверенные решения
Вам нужно преобразовать отсканированный PDF-файл в текст, чтобы вам не приходилось вручную набирать содержимое слово в слово? К счастью, вы легко можете конвертировать отсканированный PDF в текст как на Mac, так и на Windows с помощью подходящего инструмента PDF. Вам понадобится Оптическое Распознавание Символов (OCR), представляющее собой передовую технологию, которая точно распознает и обнаруживает текст в отсканированных или основанных на изображениях PDF-файлах. PDFelement – это инструмент, который включает функцию OCR, что упрощает эффективное преобразование PDF в текст.
БЕСПЛАТНО СКАЧАТЬ БЕСПЛАТНО СКАЧАТЬ КУПИТЬ СЕЙЧАС КУПИТЬ СЕЙЧАС
БЕСПЛАТНО СКАЧАТЬ
Шаг 1. Включить OCR для Преобразования отсканированного PDF в Текст
Загрузите и установите Конвертер PDF в Текст, PDFelement. Чтобы преобразовать отсканированный PDF-файл в текст, вам необходимо включить функцию распознавания текста. Нажмите кнопку “OCR” на вкладке “Редактировать” и следуйте инструкциям, чтобы выполнить OCR для вашего документа.
Чтобы преобразовать отсканированный PDF-файл в текст, вам необходимо включить функцию распознавания текста. Нажмите кнопку “OCR” на вкладке “Редактировать” и следуйте инструкциям, чтобы выполнить OCR для вашего документа.
Шаг 2. Выполните OCR в отсканированном PDF
После включения функции OCR откройте отсканированные файлы PDF, которые вы хотите преобразовать в текст. Когда появится окно напоминания OCR, выберите нужный язык для файлов PDF, затем нажмите “Выполнить OCR”. Завершение процесса занимает всего несколько секунд.
БЕСПЛАТНО СКАЧАТЬ БЕСПЛАТНО СКАЧАТЬ КУПИТЬ СЕЙЧАС КУПИТЬ СЕЙЧАС
БЕСПЛАТНО СКАЧАТЬ
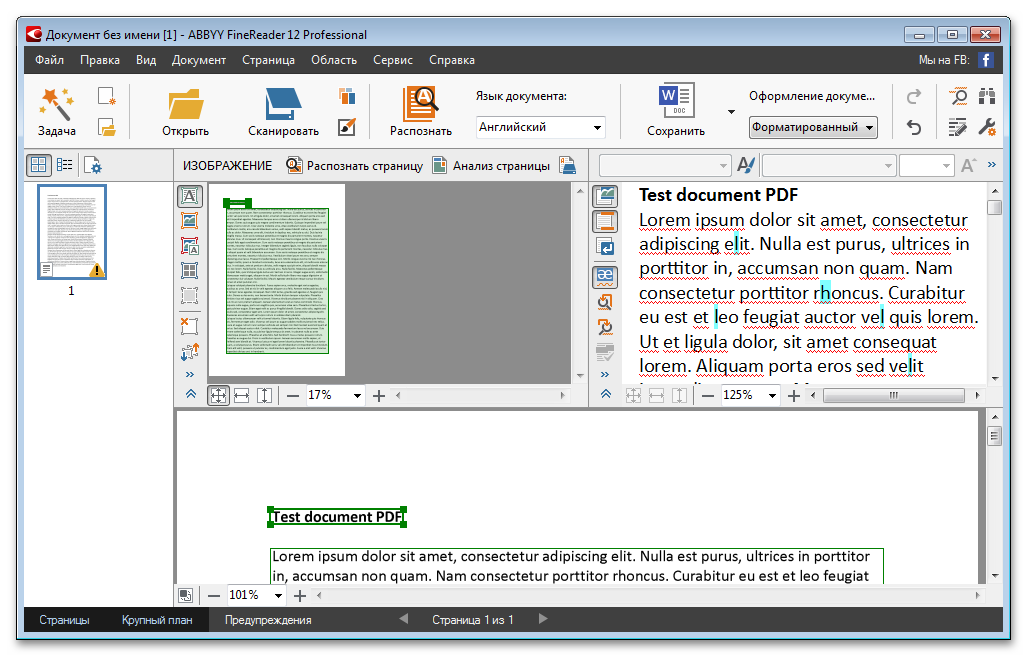
Шаг 3. Отредактируйте PDF-файлы в Текстовом Процессоре
На вкладке “Конвертировать” нажмите “В Текст”, и откроется новое окно. Выберите, куда вы хотите сохранить выходной текстовый файл. После этого нажмите “Сохранить”, и отсканированный PDF-файл будет немедленно преобразован в текст.
Через несколько секунд вы увидите выходной текстовый файл.
PDFelement – это профессиональный конвертер PDF, который позволяет пользователям конвертировать PDF в текст, PDF в MS Word, PDF в Excel, PDF в Powerpoint, PDF в файлы изображений (jpg, jpeg, png, gif, bmp, tiff), PDF в Epub, PDF в HTML или PDF в RTF.
БЕСПЛАТНО СКАЧАТЬ БЕСПЛАТНО СКАЧАТЬ КУПИТЬ СЕЙЧАС КУПИТЬ СЕЙЧАС
БЕСПЛАТНО СКАЧАТЬ
Его функция OCR является выдающейся по сравнению с другими программами, которые также включают OCR. Он может преобразовывать отсканированные PDF-файлы в форматы с возможностью поиска и редактирования. Функция OCR также может преобразовывать изображения для редактирования. PDFelement – это комплексный редактор PDF, который позволяет легко редактировать, конвертировать, создавать, выделять и аннотировать PDF-файлы.
Скачать Бесплатно или Купить PDFelement прямо сейчас!
Скачать Бесплатно или Купить PDFelement прямо сейчас!
Купить PDFelement прямо сейчас!
Купить PDFelement прямо сейчас!
Оптическое распознавание текста
Оптическое распознавание текста позволяет преобразовывать изображения текста PDF документа в редактируемый текстовый формат, который поддерживает возможность поиска текста в документе, его копирование и редактирование.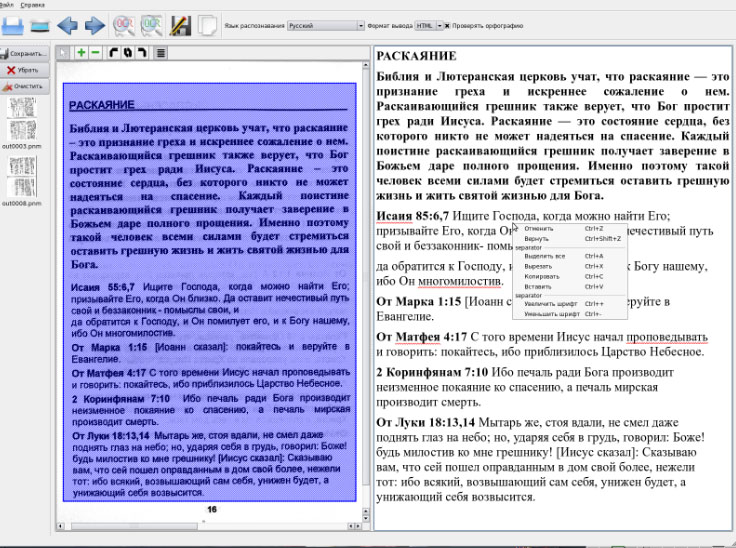 Распознавание текста будет осуществляться только в том случае, если в PDF документе не установлен запрет на редактирование.
Распознавание текста будет осуществляться только в том случае, если в PDF документе не установлен запрет на редактирование.
Для включения оптического распознавания текста выберите в главном меню Документ > Распознавание текста. В диалоговом окне укажите следующие параметры:
- Диапазон страниц Укажите диапазон страниц, на которых необходимо произвести распознавание текста.
- Языки Укажите язык/языки распознаваемого текста. Желательно выбирать минимальное количество вариантов. Это улучшит качество распознавания текста.
Если распознавание текста используется первый раз, данный список будет пустым. Для добавления языков нажмите кнопку
- Установить языки Установите маркеры, чтобы выбрать необходимые варианты. В диалоговом окне перечислены языки, для которых поддерживается распознавание текста в Master PDF Editor.
- Шрифт Выберите вариант шрифта, который будет использоваться в документе после распознавания текста.
 При выборе Автоматически программа сама подберет шрифт наиболее подходящий для данного документа.
При выборе Автоматически программа сама подберет шрифт наиболее подходящий для данного документа. - Текст с возможностью поиска
- Редактируемый текст При выборе данной опции после завершения процедуры распознавания текст будет доступен для редактирования. Распознанный текст вставится поверх изображения с данным текстом. Само изображение при этом затирается фоном.
- Вручную редактировать весь распознанный текст При выборе данной опции во время процедуры распознавания текста открывается диалоговое окно, в котором будет отображаться:
- Оригинал Фрагмент изображения с текстом
В диалоговом окне поочередно будет отображаться каждый фрагмент изображения PDF документа с соответствующим ему распознанным текстом. Здесь можно редактировать распознанный текст перед вставкой в документ.
Здесь можно редактировать распознанный текст перед вставкой в документ.
- Да Автоматически распознанный/редактированный текст запишется в документ. В диалоговом окне отобразится следующее изображение и текст к нему.
- Да для всех Все изображения будут распознаны автоматически и записаны в документ. Данное диалоговое окно больше не появится
- Не текст Текущий распознанный текст не является текстовым фрагментом. Отменяет вставку текста в текущем фрагменте.
- Отмена Отмена распознавания текста
3 метода, которые помогут вам распознавать текст в файлах PDF
В этой статье основное внимание будет уделено некоторым распространенным способам распознавания текста из файла PDF с помощью PDFelement.
Попробовать бесплатно Попробовать бесплатно
Формат PDF не обеспечивает гибкости шрифтов, макетов страниц и других функций, что является палкой о двух концах. В некоторых случаях PDF-документы могут содержать ошибки, поэтому инструменты распознавания текста могут быть необходимым инструментом для обеспечения точности. С PDFelement вы можете найти способы сделать Распознавание текста PDF задач проще, тогда вам будет разрешено изменить шрифт, цвет в тексте PDF.
В некоторых случаях PDF-документы могут содержать ошибки, поэтому инструменты распознавания текста могут быть необходимым инструментом для обеспечения точности. С PDFelement вы можете найти способы сделать Распознавание текста PDF задач проще, тогда вам будет разрешено изменить шрифт, цвет в тексте PDF.
PDFelement позволяет быстро и эффективно создавать, изменять и управлять документами PDF. Он имеет интуитивно понятный интерфейс и множество ценных инструментов, таких как редактирование, аннотирование, печать, распознавание текста, создание и преобразование. Это похоже на то, как если бы ваши собственные сверхспособности по созданию PDF-файлов были у вас под рукой.
Попробуйте бесплатно
Для Win 7 или более поздней версии (64-разрядная, 32-разрядная)
Попробуйте бесплатно
Для macOS 10.14 или более поздней версии
Как распознать текст в PDF
Метод 1 Распознавание текста OCR позволяет редактировать
Метод 2 Распознавание текста OCR позволяет выполнять поиск : Распознавание текста OCR позволяет редактировать
Благодаря распознаванию текста OCR вы можете редактировать текст, присутствующий в ваших документах.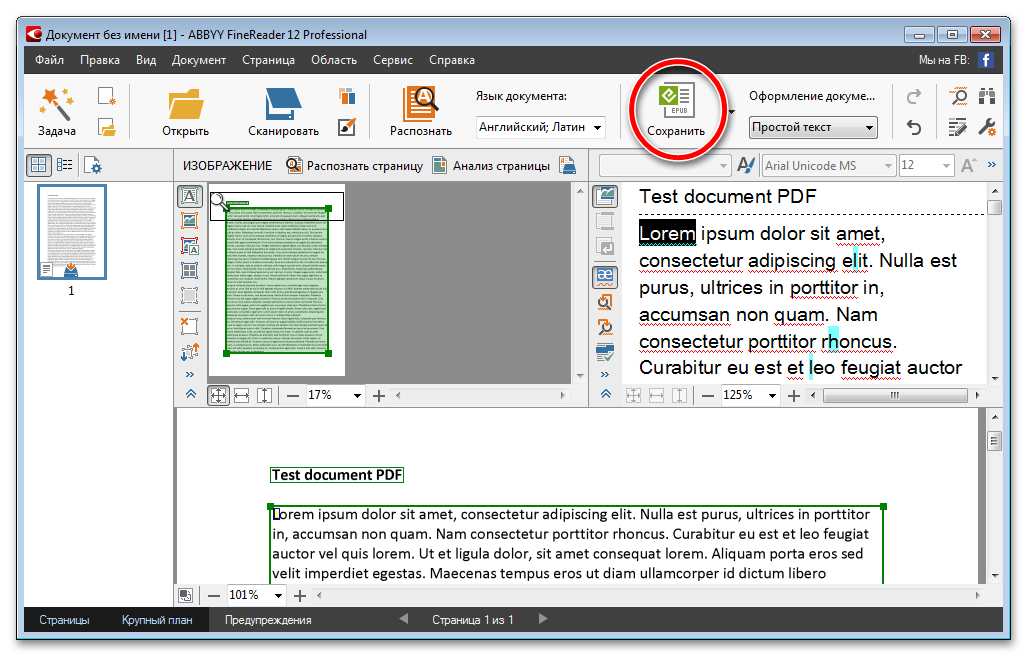 Ниже приведено пошаговое руководство по включению функции редактирования.
Ниже приведено пошаговое руководство по включению функции редактирования.
Шаг 1 Загрузите отсканированный PDF-файл
Запустите PDFelement на ПК и нажмите «Открыть файлы». Выберите отсканированный документ, чтобы открыть его.
Шаг 2 Распознавание текста в PDF для редактирования
Нажмите ссылку «Выполнить распознавание» в синем уведомлении в верхней части страницы. Программа покажет окно «OCR». Нажмите кнопку «Редактируемый текст», чтобы сделать текст узнаваемым. Вы можете нажать «Изменить языки» и выбрать язык, если вас не устраивает язык по умолчанию. Нажмите «ОК», чтобы начать процедуру OCR. После завершения OCR программа распознает тексты в формате PDF.
Шаг 3 Редактирование текста PDF
Во втором меню нажмите «Редактировать». Теперь вы можете изменить фон, добавить изображения, текст, ссылки и водяной знак.
Попробуйте бесплатно
Для Win 7 или более поздней версии (64-разрядная, 32-разрядная)
Попробуйте бесплатно
Для macOS 10. 14 или более поздней версии
14 или более поздней версии
Метод 2: Поиск с OCR 903 Распознавание текста 9030s распознавания текста, вы можете искать текст, присутствующий в ваших документах.
Шаг 1 Загрузите PDF
Откройте отсканированный документ в PDFelement.
Шаг 2 Распознавание текста в PDF для поиска
Нажмите «Выполнить распознавание» на синей панели уведомлений. Нажмите «Сканировать, чтобы найти текст на изображении».
Шаг 3 Поиск текста PDF
Теперь откройте строку поиска и найдите текст, который вы ищете. Вы также можете заменить слова.
Попробуйте бесплатно
Для Win 7 или новее (64- и 32-разрядная версии)
Попробуйте бесплатно
Для macOS 10.14 или новее
Способ 3. Распознавание выделенной области в PDF
С помощью OCR вы можете распознавать текст в выбранной области ваших документов.
Шаг 1 Область OCR
Теперь, когда файл открыт в интерфейсе PDFelement, щелкните вкладку «Преобразовать». На этот раз вместо этого выберите опцию «Область OCR».
Шаг 2 Выберите распознает область
Теперь щелкните, чтобы выбрать область, в которой вы хотите выполнить распознавание текста в документе PDF. Откроется боковая панель, выберите язык и нажмите «Распознать». Когда процесс OCR завершится, выбранная часть станет распознаваемой.
Шаг 3 Редактирование распознанной области
Перейдите на вкладку «Редактировать». Вы можете добавлять текст, изображения, ссылки и водяные знаки. Существует также возможность изменить фон и добавить верхний или нижний колонтитул.
Попробуйте бесплатно
Для Win 7 или более поздней версии (64-разрядная, 32-разрядная)
Попробуйте бесплатно
Для macOS 10.14 или более поздней версии PDFill БЕСПЛАТНЫЕ инструменты для редактирования PDF: БЕСПЛАТНОЕ оптическое распознавание символов PDF для преобразования изображения в PDF с возможностью поиска онлайн/на компьютере
PDF Управление документами 20: БЕСПЛАТНОЕ распознавание PDF онлайн Инструменты
Выберите изображение Файл для OCR:
(bmp, png, gif, jpg/jpeg, tif/tiff)
Выходной формат: Доступный для поиска PDF Текст Доступно только для поиска PDF Текст ТСВ ОСКР
Вернуться к FreePDF.
net
PDF Управление документами 20: БЕСПЛАТНОЕ распознавание PDF Рабочий стол Инструменты
Эта БЕСПЛАТНАЯ функция OCR преобразует Изображение в PDF с возможностью поиска с помощью Тессеракт. Тессеракт – это механизм оптического распознавания символов для различных операционных системы. Его разработка была спонсирована Google с 2006 года. В 2006 году Tesseract считался одним из самые точные из доступных на тот момент механизмов OCR с открытым исходным кодом.
Пакетная (DOS) поддержка команд: Вы можете запустить пакетное задание в Windows, выполнив команду выполнение команды непосредственно из окна командной строки MS-DOS без открытие графического интерфейса PDFill.
Вот шаги о том, как использовать БЕСПЛАТНОЕ распознавание PDF:
1. Выберите Меню документа > Выберите файл, чтобы узнать больше Операции (Bates, Optimizer, Extract, OCR…) > БЕСПЛАТНЫЙ PDF-файл OCR (Выберите файл)
или нажмите БЕСПЛАТНАЯ выписка OCR Кнопка в Панель инструментов документа.
