
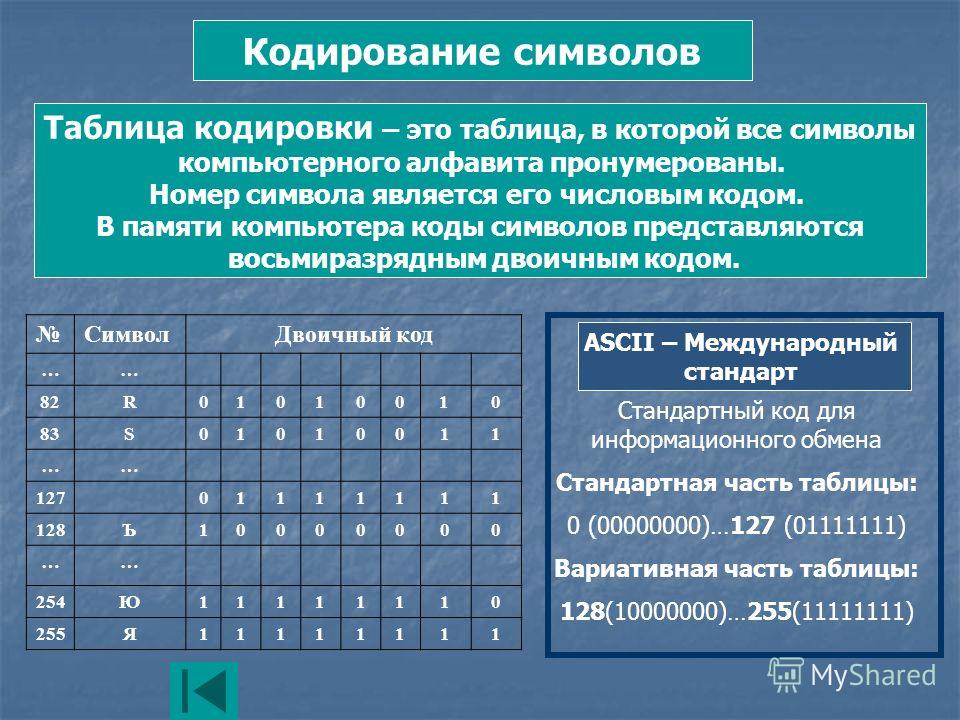
Universal online Cyrillic decoder – recover your texts
Universal online Cyrillic decoder – recover your texts Version: 20230216 By the same author: Virtour.fr – visites virtuelles Հայերեն –
Башҡорт – Беларуская – Български –
Иронау –
Қазақша –
Кыргызча – Македонски –
Монгол
Нохчийн – O’zbek – Русский – Slovensky – Српски – Татарча – Тоҷикӣ – Українська – Чaваш – Français – English
Output
The resulting text will be displayed here…
| Guestbook Please link to this site! | Custom Work For a small fee I can help you quickly recode/recover large pieces of data – texts, databases, websites… or write custom functions you can use (invoice available).  FAQ and contact information. |
About the program
Welcome! You may find this site useful, if you have recieved some texts that you believe are written in the Cyrillic alphabet, but instead are displayed in some strange combination of bizarre characters. This program will try to guess the encoding, and if it does not, it will show samples, examples of all encoding-combinations, so as you will be able to select the good one.
How to
- Paste the text to decode in the big text area. The first few words will be analyzed so they should be (scrambled) in supposed Cyrillic.
- The program will try to decode the text and will print the result below.
- If the translation is successful, you will see the text in Cyrillic characters and will be able to copy it and save it if it’s important.
- If the translation isn’t successful (still the text is not in Cyrillic but in the same or other unintelligible characters), you can choose from the newly created select-listbox the variant that is in Cyrillic (if there are more than one, select the longest).
 By pressing the button OK you will have the correct text converted.
By pressing the button OK you will have the correct text converted. - If the text is not totally converted, try all other variants in Cyrillic from the select-listbox.
Limits
- If your text contains question marks “???? ?? ??????”, the problem is with the sender and no recovery will be possible. Ask them to resend the text, eventually as an ordinary text file or in LibreOffice/OpenOffice/MSOffice format.
- There is no claim that every text is recoverable, even if you are certain that the text is in Cyrillic.
- The analyzed and converted text is limited to 100 KiB.
- A 100% precision is not always achieved – in a conversion from a codepage to another code page, some characters may be lost, like the Bulgarian quotes or rarely some single letters. Some of this depends on your Windows Clipboard character handling.
- The program will try a maximum of 8280 variants in two or three levels: if there had been a multiple encoding like koi8(utf(cp1251(utf))), it will not be detected or tested.
 Usually the possible and displayed correct variants are between 32 and 255.
Usually the possible and displayed correct variants are between 32 and 255. - If a part of the text is encoded with one code page, and another part – with another code page, the program could recognize only one of the parts at a time.
Terms of use
Please notice that this freeware program is created with the hope that it would be useful, but has no warranty, not even an implied warranty for fitness for any particular use
If you have very long texts to translate, please make sure you have a backup copy.
What’s new
- March 2021 : After a server upgrade, the program stopped working and some parts of it had to be rewritten.
- May 2020 : Added Тоҷикӣ/Tajik translation, thanks to Анвар/Anvar.
- October 2017 : Added “Select all / Copy” button.
- July 2016 : SSL Certificate installed, you can now access the Decoder on a secure connection.
- October 2013 : I am trying different optimizations for the system which should make the decoder run faster and handle more text.

- March 2013 : My hosting provider sent me a warning that the Decoder is using too much server CPU power and its processes were killed more than 100 times. I am making some changes so that the program will use less CPU, especially when reposting a previously sampled text, however, the decoded form may load somewhat slower. Please contact me if you have some difficulties using the program.
- 2012-08-09 : Added French translation, thanks to Arnaud D.
- 2011-03-06 : Added Belorussian translation, thanks to Зыль and Aliaksandr Hliakau.
- 31.07.10
- 07.05.09 : Raised limit of MAX text size to 50 kiB.
- may 2009 : Added Ukrainian interface thanks to Barmalini.
- 2008-2009 : A number of small fixes and tweaks of the detection algorithm. Changed interface to default to automatic decoding.

- 12.08.07 : Fixed Russian language translation, thanks to Petr Vasilyev. This page will be significantly restructured in the near future.
- 10.11.06 : Three new postfilters added: “base64”, “unix-to-unix” и “bin-to-hex”, theoretically the tested combinations are 4725. Changes to the frequency analysis function (testing).
- 11.10.06 : The main site is on a new hardware server, should run faster.
- 11.09.06 : The program now uses PHP5 and should run times faster.
- 19.08.06 : Because of a broken DNS entry, this site was inaccessible from 06:00 on 15 august up to 15:00 on 18 august. That was the reason for me to set two “mirror” sites (5ko.free.fr/decode and www.accent.bg/decode) with the same program. If the original has a problem, you can find the copies in Google and recover your texts.
- 17.06.06 : Added two more antique Cyrillic encodings, MIK и KOI-7, but you better not need them.
- 03.03.
 06 : Added Slovak translation, thanks to Martin from KPR Slovakia.
06 : Added Slovak translation, thanks to Martin from KPR Slovakia. - 15.02.06 : More encodings added and tested.
- 20.10.05 : Small improvement to the frequency-analysis function: for texts, written in all-capital letters.
- 14.10.05 : Two more gmail-Cyrillic encodings were added. Theoretically the tested combinations are 2112.
- 15.06.05 : Russian language interface was added. Big thanks to chAlx!
- 16.02.05 : One more postfilter decoding is added, for strings like this: “%u043A%u0438%u0440%u0438%u043B%u0438%u0446%u0430”.
- 05.02.05 : More encodings tests added, the number of tested encodings is doubled, but thus the program may work slightly slower.
- 03.02.05 : The frequency analysis function that detects the original encoding works much better now. Currently the program recognises most of the encodings if the first few words are not too weird. It although still needs some improvement.

- 15.01.05 : The input text limit is raised from 10 to 20 kB.
- 01.12.04 : First public release.
Back to the Latin to Cyrillic convertor.
Раскодировать текст онлайн: сервисы для раскодировки
Весь текстовый контент, с которым мы работаем, хранится изначально в числовом виде. Для его преобразования используется кодирование. В различных системах одним и тем же значениям соответствуют различные буквенные, цифровые или просто символьные последовательности. Так иногда можно открыть документ или страничку и увидеть непонятные символы. Получается, что здесь данные были сохранены в другой кодировке. В таком случае можно раскодировать текст онлайн, с помощью специализированных сервисов. Все перечисленные ниже инструменты являются довольно популярными и функциональными.
СОДЕРЖАНИЕ СТАТЬИ:
Универсальный декодер
Сервис отлично справляется с кириллицей. Очень популярен среди юзеров рунета. Если вы выбрали его для работы, то необходимо сделать копию текста, нуждающегося в декодировании и вставить в специальное поле. Следует размещать отрывок так, чтобы уже на первой строчке были непонятные знаки.
Следует размещать отрывок так, чтобы уже на первой строчке были непонятные знаки.
Если вы хотите, чтобы ресурс автоматически смог раскодировать, придется отметить это в списке выбора. Но можно выполнять и ручную настройку, указав выбранный тип. Итоги можете найти в разделе «Результат». Вот только тут есть определенные ограничения. К примеру, если в поле вставить отрывок более 100 Кб, софт не обработает его, так что нужно будет выбирать кусочки.
Как раскодировать текст онлайн с помощью Fox Tools
Здесь вы можете выбирать итоговый результат. Программа способна функционировать и в режиме «по умолчанию», который используется для неизвестных кодировок, но в таком случае необходимо отмечать самостоятельно вариант текстового объекта, подходящего больше всего. Инструмент простой и доступный, поэтому идеально подойдет даже новичкам.
Декодер Артемия Лебедева
Данный дешифратор способен взаимодействовать со всеми популярными кодировками. Приложение может предложить пользователю сложный и простой рабочий режим. В первом показывается не только исходник, но и преобразование. Еще можно указать кодировку, куда понадобилось перевести текст, из открывающегося списка. В правом блоке вы найдете результат для прочтения.
В первом показывается не только исходник, но и преобразование. Еще можно указать кодировку, куда понадобилось перевести текст, из открывающегося списка. В правом блоке вы найдете результат для прочтения.
Translit.net
Этот инструмент имеет сложный внешний вид, но по принципу работы он не отличается от остальных. Необходимо ввести текстовый отрывок и в ручном режиме установить настройки.
Программа Штирлиц
Приложение, которым легко раскодировать онлайн, было создано для работы с русскоязычными объектами. Сюда можно текст копировать из буфера обмена, а также из самого текстового файла. Программа, позволяющая раскодировать текст онлайн, проверяет разные схемы. Если схема корректно не отображает все русские слова, используется следующая. Еще здесь можно создавать авторскую кодовую схему и пользоваться ей для работы. Для одновременной обработки нескольких файлов, нужно индивидуально открывать каждый из них.
Пользуемся стандартным Word
Этот редактор очень популярен, именно с ним работает большая часть пользователей. Так что они регулярно сталкиваются с некорректным отображением букв или невозможностью открыть участок с неподходящей кодировкой. Если документ Ворд открылся в режиме ограниченной функциональности, следует ее убрать. Если все еще отображаются непонятные знаки, укажите верную кодировку в программных настройках. Для этого идете по такому пути:
Так что они регулярно сталкиваются с некорректным отображением букв или невозможностью открыть участок с неподходящей кодировкой. Если документ Ворд открылся в режиме ограниченной функциональности, следует ее убрать. Если все еще отображаются непонятные знаки, укажите верную кодировку в программных настройках. Для этого идете по такому пути:
Файл (Office)/Параметры/Дополнительно.
В разделе «Общие» установите галочку в спецнастройке «Подтверждать преобразование формата». Соглашаетесь с изменениями, закрываете прогу, а потом опять открываете файл. В окошке «Преобразование» выбираете «Кодированный текст». Ищите свой вариант.
Определение кодировки
Есть несколько способов определения:
- В Ворде во время открытия документа: если есть отличия от СР1251, редактор предлагает выбирать одну из самых подходящих кодировок. Оценить, насколько они аналогичны, можно по превью текстового образца;
- В утилите KWrite. Сюда загружаете объект с расширением .txt и используете настройки в меню «Кодирование»;
- Открываете объект в обозревателе Mozilla Firefox.
 При правильном отображении в разделе «Вид» ищите кодировку. Нужный вариант – тот, возле которого установлен флажок. Если все отображается с ошибками, проверяете различные варианты в меню «Дополнительно»;
При правильном отображении в разделе «Вид» ищите кодировку. Нужный вариант – тот, возле которого установлен флажок. Если все отображается с ошибками, проверяете различные варианты в меню «Дополнительно»; - Пользователи Unix могут воспользоваться приложением Enca.
С помощью предложенных инструментов вы можете быстро и легко раскодировать текст онлайн. Если у вас мало знаний, воспользуйтесь утилитами с простым меню и функционалом.
String Encoder / Decoder Converter Online
Расшифровано
| Bin String | |
|---|---|
| Hex String | |
| HTML Escape | |
| URL Encoding | |
| Punycode IDN | |
| Base32 | |
| Base45 | |
| Base45/Zlib/COSE/CBOR | |
| Base64 | |
| Ascii85 | |
| Quoted-printable | |
| Unicode Escape | |
| Program String | |
| Morse Code | Вариант Международный (Латинский)ЯпонскийРусский |
| Unicode NFD | |
| Unicode NFKD |
 punycode”>
punycode”> unicode-normalization”>
unicode-normalization”>Закодировано
| Строка ячеек | Сепаратор нетКаждые 4 битаКаждые 8 битов (1 байт)Каждые 16 битов (2 байта)Каждые 24 бита (3 байта)Каждые 32 бита (4 байта)Каждые 64 бита (8 байтов)Каждые 128 битов (16 байтов) |
|---|---|
| Шестигранная струна | Сепаратор noneКаждый 1 байтКаждый 2 байтКаждый 3 байтКаждый 4 байтКаждый 8 байтКаждый 16 байт А-Ф Нижний (a-f)Верхний (A-F) |
| Экранирование HTML (базовый) | |
| Экранирование HTML (полный) | |
| Кодировка URL | Космос %20 (процентное кодирование)+ (application/x-www-form-urlencoded) |
| Punycode IDN | |
| Base32 | |
| Base45 | |
| Base64 | Разрыв строки noneКаждые 64 символа (PEM – RFC 1421)Каждые 76 символов (MIME – RFC 2045) |
| Ascii85 | Вариант Z85 (ZeroMQ)Adobebtoa |
| Печать в кавычках | |
| Unicode Escape | Формат \uXXXX\uXXXX или \u{X}\uXXXX или \U00XXXXXX\u{X}\x{X}\X&#xX;%uXXXXU+XXXX0xX\N{имя} А-Ф Верхний (A-F) Нижний (a-f) |
| Строка программы | Цитаты Двойной (“) Одинарный (‘) Нет |
| Азбука Морзе | Вариант Международный (Латинский)ЯпонскийРусский |
| Верхний корпус CamelCase | |
| Нижний корпус CamelCase | |
| UPPER_SNAKE_CASE | |
| lower_snake_case | |
| UPPER-KEBAB-CASE | |
| lower-kebab-case | |
| Half Width | |
| Full Width | |
| Верхний регистр | |
| Нижний регистр | |
| Замена регистра | |
Заглавные буквы99 | |
| Инициалы | |
| Реверс | |
| UNICODE NFC | |
| UNICODE NFKC | 9999999999999999999999999999999999999989998999998999999999ампи. |
| Line Unique |
 punycode”>
punycode”> camel-case”>
camel-case”> text-initials”>
text-initials”>Другие конвертеры здесь
Анализ доступа
Этот сайт использует службу анализа доступа (Google Analytics).
Эти службы анализа доступа используют файлы cookie для сбора данных о трафике.
Для получения дополнительной информации, пожалуйста, проверьте ЗДЕСЬ.
Реклама
Этот сайт использует рекламную службу (Google AdSense) для размещения объявлений, распространяемых третьими лицами на сайте.
Эти рекламные службы используют файлы cookie для показа рекламы продуктов и услуг, которые вас интересуют.
Для получения дополнительной информации, пожалуйста, проверьте ЗДЕСЬ.
Инструмент для кодирования/декодирования. Анализировать проблемы и ошибки кодировки символов.
Это инструмент кодирования/декодирования, который позволяет имитировать проблемы с кодировкой символов. и ошибки.
Здесь вы можете смоделировать, что произойдет, если вы закодируете текстовый файл с помощью одной кодировки.
а затем декодировать текст с другой кодировкой. Попробуйте, например. кодировать шведский
символы ääö с помощью utf-8, а затем декодировать их с помощью iso-8859-1 или попробуйте закодировать
明伯 (упрощенное китайское значение «понимать») с помощью utf-8 и декодировать с помощью
GB 18030.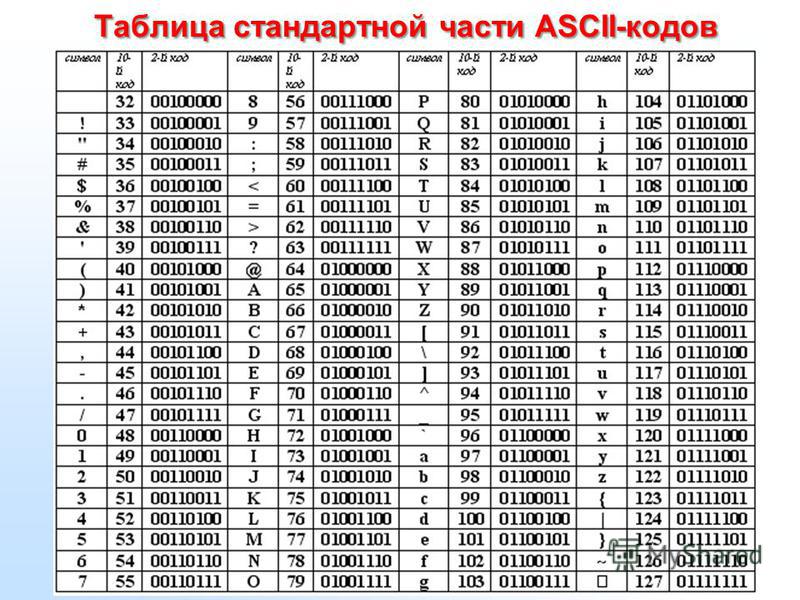 Это даст символы: 鏄庝集, которые я действительно не понимаю.
Это даст символы: 鏄庝集, которые я действительно не понимаю.
Введите строку для кодирования/декодирования
| Кодировать с помощью: | ASMO-708big5cp1025cp866cp875csISO2022JPDOS-720DOS-862EUC-CNEUC-JPeuc-jpeuc-krGB18030gb2312hz-gb-2312IBM00858IBM00924IBM01047IBM01140IBM01141IBM01142IBM01143IBM01144IBM01145IBM01146IBM01147IBM01148IBM01149IBM037IBM1026IBM273IBM277IBM278IBM280IBM284IBM285IBM290IBM297IBM420IBM423IBM424IBM437IBM500ibm737ibm775ibm850ibm852IBM855ibm857IBM860ibm861IBM863IBM864IBM865ibm869IBM870IBM871IBM880IBM905IBM-Thaiiso-2022-jpiso-2022-jpiso-2022-kriso-8859-1iso-8859-13iso-8859-15iso-8859-2iso-8859-3iso-8859-4iso-8859-5iso-8859-6iso-8859-7iso-8859-8iso-8859-8-iiso-8859-9Johabkoi8-rkoi8-uks_c_5601-1987macintoshshift_jisus-asciiutf-16utf-16BEutf-32utf -32BEutf-7utf-8windows-1250windows-1251Windows-1252windows-1253windows-1254windows-1255windows-1256windows-1257windows-1258windows-874x-Chinese-CNSx-Chinese-Etenx-cp20001x-cp20003x-cp20004x-cp20005x-cp20261x-cp20269x-cp20936x-cp20949x -cp50227x-EBCDIC-KoreanExtendedx-Europax-IA5x-IA5-немецкийx-IA5-норвежскийx-IA5-шведскийx-iscii-asx-iscii-bex-iscii-dex-iscii-gux-iscii-kax-iscii-max-iscii-orx -iscii-pax-iscii-tax-iscii-tex-mac-arabicx-mac-cex-mac-chinesesimpx-mac-chinesetradx-mac-croatianx-mac-cyrillicx-mac-greekx-mac-hebrewx-mac-icelandicx-mac -japanesex-mac-koreanx-mac-romanianx-mac-thaix-mac-turkishx-mac-ukrainian |
| Расшифровать с помощью: | ASMO-708big5cp1025cp866cp875csISO2022JPDOS-720DOS-862EUC-CNEUC-JPeuc-jpeuc-krGB18030gb2312hz-gb-2312IBM00858IBM00924IBM01047IBM01140IBM01141IBM01142IBM01143IBM01144IBM01145IBM01146IBM01147IBM01148IBM01149IBM037IBM1026IBM273IBM277IBM278IBM280IBM284IBM285IBM290IBM297IBM420IBM423IBM424IBM437IBM500ibm737ibm775ibm850ibm852IBM855ibm857IBM860ibm861IBM863IBM864IBM865ibm869IBM870IBM871IBM880IBM905IBM-Thaiiso-2022-jpiso-2022-jpiso-2022-kriso-8859-1iso-8859-13iso-8859-15iso-8859-2iso-8859-3iso-8859-4iso-8859-5iso-8859-6iso-8859- 7iso-8859-8iso-8859-8-iiso-8859-9Johabkoi8-rkoi8-uks_c_5601-1987macintoshshift_jisus-asciiutf-16utf-16BEutf-32utf-32BEutf-7utf-8windows-1250windows-1251Windows-1252windows-1253windows-1254windows-1255windows-1256windows- 1257windows-1258windows-874x-китайский-CNSx-китайский-Etenx-cp20001x-cp20003x-cp20004x-cp20005x-cp20261x-cp20269x-cp20936x-cp20949x-cp50227x-EBCDIC-KoreanExtendedx-Europax-IA5x-IA5-немецкийx-IA5-норвежскийx-IA5-шведскийx-iscii-asx-iscii-bex-iscii-dex-iscii-gux-iscii-kax-iscii-max-iscii- orx-iscii-pax-iscii-tax-iscii-tex-mac-arabicx-mac-cex-mac-chinesesimpx-mac-chinesetradx-mac-croatianx-mac-cyrillicx-mac-greekx-mac-hebrewx-mac-icelandicx- mac-japanesex-mac-koreanx-mac-romanianx-mac-thaix-mac-turkishx-mac-ukrainian |
Закодированная/декодированная строка:
Что такое кодовая страница?
Кодовая страница — это другое название кодировки символов. Он состоит из таблицы значений
который описывает набор символов для определенного языка.
Он состоит из таблицы значений
который описывает набор символов для определенного языка.
Что такое кодировка символов?
Кодирование символов — это процесс кодирования набора символов в соответствии с системой кодирования. Этот процесс обычно объединяет числа с символами для кодирования информации, которую может использовать компьютер.
Зачем нам нужно кодировать символы?
Поскольку компьютеры могут интерпретировать только необработанные нули и единицы (например, 01100110), слова и предложения необходимо кодировать при вводе информации в компьютер. Символы в этих словах и предложениях сгруппированы в набор символов, который может распознать компьютер.
Что такое кодировки символов?
Кодировки символов позволяют нам понять кодировку, используемую компьютерами. Из-за наличия множества кодировок символов могут возникать ошибки при кодировании с помощью одной кодировки символов и декодировании с помощью другой. Вышеупомянутый инструмент можно использовать для имитации возникновения каких-либо ошибок при кодировании с любой кодировкой символов и декодировании с другой.
Типы кодировок символов
Существует множество кодировок, которые можно использовать для кодирования или декодирования строки символов, включая UTF-8, ASCII и ISO 9959-1.
Примеры популярных кодировок символов:
- ASCII: Американский стандартный код для обмена информацией
- ANSI: Американский национальный институт стандартов
- Unicode (внутренние текстовые коды, используемые операционными системами)
- UTF-8 (формат преобразования Unicode, в котором для представления символов используется 1 байт)
- UTF-16 (формат преобразования Unicode, который использует 2 байта для представления символов)
- UTF-32 (формат преобразования Unicode, который использует 4 байта для представления символов)
Хотя это, безусловно, популярные кодировки, бывают случаи, когда строки кода кодируются менее широко используемыми кодировками, такими как x-IA5-Norgwegian или DOS-720. Это может привести к путанице и возможным ошибкам, поэтому важно понять, как уменьшить количество этих ошибок путем предварительного моделирования с помощью инструмента кодирования/декодирования символов String Functions.