
Распознавание текста онлайн
Главная › Уроки по компьютеру › Распознавание текста онлайн
Всем Привет. Сегодня я хочу рассказать Вам, про распознавание текста онлайн, как это можно сделать совершенно бесплатным способом. Возможно, Вы уже знаете, а если не знаете, я сейчас Вам об этом расскажу, что для распознавания текста в основном люди используют программу, которая называется FineReader. Она много весит и к тому же она платная, что естественно многих не устраивает. К счастью есть способ, который позволяет распознавать текст онлайн и не напрягаться с установкой дополнительного софта. Это сервис, который поможет нам в распознавание текста онлайн, также сделан разработчиками программы FineReader. https://finereaderonline.com/ru-ru/Tasks/Create
Чтобы начать распознавание текста онлайн на этом сервисе необходимо пройти быструю регистрацию. Для этого в центре сайта находим кнопку «Зарегистрироваться» и нажимаем ее. В следующем окне вводим свои правильные данные, придумываем логин и пароль, указываем свой рабочий почтовый ящик, после этого нажимаем «Зарегистрироваться». Нас поздравляют с регистрацией и говорят, что нужно подтвердить свой email адрес, перейдя по ссылке в письме, которое пришло. Вот такое пришло мне: Кликаем по ссылке и подтверждаем свою учетную запись. Теперь давайте я покажу, как распознать текст онлайн. Попадаем на сайт. В правом меню ищем ссылку «Распознать документ» нажимаем на нее.
В открывшемся окне с помощью кнопки «Загрузить» указываем на компьютере страницу с тестом для распознавания и выбираем некоторые настройки – языки, которые используются в документе, формат для сохранения результата. Когда все будет готово, нажимаем кнопку «Распознать». Нам говорят, что документ добавлен в очередь на распознавание и также указано примерное время, сколько это займет. Обычно не долго. Жмем «Посмотреть доступные задания». И там видим, что распознавание текста уже завершено. Можем скачать файл, кликнув по нему и сохранив себе на компьютер или можно выделить, поставив галочку и нажать «Скачать все отмеченные файлы». К сожалению, распознавание текста онлайн на этом сервисе возможно только для трех страниц. Если нужно еще распознать, то тут уже платно. Взглянуть на цены можно на странице «Купить страницы». За 20 страниц нам нужно будет заплатить 3 доллара. Но это лучше чем покупать дорогую программу и пользоваться ею раз в несколько месяцев для распознания пары страниц.
Этот сервис для распознавания текста онлайн пригодиться тем, кому это нужно очень редко. Если нам нужно рас в месяц распознать 2-3 страницы, то в таком случае можно просто пройти повторную регистрацию. Дополнительно программ устанавливать не нужно, переходим на сайт, регистрируется, указываем страницы и распознаем текс онлайн. Удобный сервис, в случае необходимости рекомендую им пользоваться! Ну, вот и все, думаю, ответ на вопрос, про распознавание текста онлайн решен! Всем Удачи и ПОКА! Интересные статьи по теме: Как конвертировать файл видео, аудио или фото в любой формат? Как создать образ диска в программе Daemon Tools? Создание и удаление виртуальных приводов в Деймон Тулс Как установить Daemon Tools? Как поменять тему в Google Chrome? |



Распознавание речи онлайн
Начать диктовку
Отдалить
Приблизить
Очистить содержимое
Сохранить в формате “.
Сохранить в формате “.doc”
Скопировать содержимое
Распечатать содержимое
Отправить содержимое
AfrikaansአማርኛAzərbaycancaবাংলা – বাংলাদেশবাংলা – ভারতBahasa IndonesiaBahasa MelayuCatalàČeštinaDanskDeutschEnglish – AustraliaEnglish – CanadaEnglish – IndiaEnglish – KenyaEnglish – TanzaniaEnglish – GhanaEnglish – New ZealandEnglish – NigeriaEnglish – South AfricaEnglish – PhilippinesEnglish – United KingdomEnglish – United StatesEspañol – ArgentinaEspañol – BoliviaEspañol – ChileEspañol – ColombiaEspañol – Costa RicaEspañol – EcuadorEspañol – El SalvadorEspañol – EspañaEspañol – Estados UnidosEspañol – GuatemalaEspañol – HondurasEspañol – MéxicoEspañol – NicaraguaEspañol – PanamáEspañol – ParaguayEspañol – PerúEspañol – Puerto RicoEspañol – República DominicanaEspañol – UruguayEspañol – VenezuelaEuskaraFilipinoFrançaisBasa JawaGalegoગુજરાતીHrvatskiIsiZuluÍslenskaItaliano – ItaliaItaliano – Svizzeraಕನ್ನಡភាសាខ្មែរLatviešuLietuviųമലയാളംमराठीMagyarລາວNederlandsनेपाली भाषाNorsk bokmålPolskiPortuguês – BrasilPortuguês – PortugalRomânăසිංහලSlovenščinaBasa SundaSlovenčinaSuomiSvenskaKiswahili – TanzaniaKiswahili – KenyaქართულიՀայերենதமிழ் – இந்தியாதமிழ் – சிங்கப்பூர்தமிழ் – இலங்கைதமிழ் – மலேசியாతెలుగు – Tiếng ViệtTürkçeاُردُو – پاکستاناُردُو – بھارتΕλληνικάбългарскиPусскийСрпскиУкраїнська한국어中文 – 普通话 (中国大陆)中文 – 普通话 (香港)中文 – 中文 (台灣)中文 – 粵語 (香港)日本語हिन्दीภาษาไทย
Скажите | Получите | |
|---|---|---|
| Точка | . | |
| Запятая | , | |
| Точка с запятой | ; | |
| Двоеточие | : | |
| Тире, Дефис | – | |
| Знак вопроса | ? | |
| Восклицательный знак | ! | |
| Открытая скобка | ( | |
| Закрытая скобка | ) | |
| Пробел | ||
| Новая строчка, Новая строка | ↵ | |
| Новый абзац | ↵↵ | |
Распознавание рукописного текста с помощью ИИ
Там, где ИИ встречается с историческими документами
Транскрибус — это комплексная платформа для оцифровки, распознавания текста с помощью ИИ, транскрипции и поиска исторических документов — из любого места, в любое время, и на любом языке.
Смотреть видео
Бесплатная регистрация
Транскрибус Лайт
Попробуй
Transkribus Lite — это версия браузера
Автоматически расшифровывать , комфортно редактировать и легко совместно работать над историческими документами. А с помощью Transkribus Lite вы можете обучать своих собственных моделей искусственного интеллекта . В вашем браузере.
Транскрибус Эксперт
Скачать
Expert Client — это автономная версия Transkribus со всеми возможностями платформы Transkribus: оцифровка, распознавание с помощью ИИ, транскрипция и поиск исторических документов .
0 +
Зарегистрированные пользователи
0 +
Модели HTR AI обучены
0 + Миллион
Обработано страниц
0 +
Бесплатные общедоступные модели ИИ
Распознавание, расшифровка и поиск исторических документов с помощью ИИ
Обучение собственных моделей распознавания текста ИИ
Обучение специальных моделей распознавания текста, способных распознавать миллионы рукописных, машинописных или печатных документов.
Распознавание макета, структуры и текста
Использование ИИ для распознавания рукописного текста, анализа макета и распознавания структуры.
Расшифруйте любой текст
Используйте редактор расшифровки для ручной расшифровки исторических документов или работайте с распознаванием на основе ИИ, используя общедоступные модели ИИ или модели, которые вы можете обучить самостоятельно.
Поиск документов с помощью расширенных параметров
Поиск документов с помощью расширенных параметров поиска, таких как инструмент определения ключевых слов.
Совместная работа над документами
.Работайте вместе над своими документами, объединяйте их в коллекции и извлекайте пользу из работы друг друга
Поделитесь своей работой и экспортируйте ее
Поделитесь своей работой с любым пользователем веб-сайта для чтения и поиска или экспортируйте свои документы в формате PDF или ALTO (XML).
Безопасность ваших документов является нашим главным приоритетом
Весь контент Transkribus, то есть ваши загруженные изображения, распознанный текст, обученные модели распознавания и введенные метаданные, размещены в ЕС, и мы соблюдаем GDPR.
Попробуйте силу Транскрибуса!
Члены READ-COOP SCE
Где используется Транскрибус
Исследования
Используйте Transkribus для расшифровки исторических документов. Транскрипции могут быть выполнены очень стандартизированным, гибким и надежным способом.
Архивы и библиотеки
Благодаря передовой технологии распознавания рукописного текста большие коллекции архивных материалов могут быть легко доступны.
Подробнее >>
Генеалогия и гражданская наука
Расшифруйте и найдите старый почерк (например, Kurrent или Sütterlin) в исторических письмах, рукописях или старых документах.
Подробнее >>
Бизнес
Используйте искусственный интеллект для анализа макета и понимания документов, а также для работы с большими объемами документов (как исторических, так и печатных).
Образование
Поддержка будущих ученых — одна из наших основных ценностей. Поэтому мы предлагаем студенческую программу «Транскрибус».
Наука
Transkribus отлично подходит для вашего конвейера, если вы ученый в области компьютерного зрения, анализа документов, распознавания образов, обработки естественного языка или смежных областей.
Исключительные проекты, реализованные с Transkribus
Цены
Обучение, анализ макета, использование Transkribus для ручной расшифровки и т. д. – т. е. все, кроме распознавания текста собственно бесплатно . Тем не менее, вы также можете использовать функцию распознавания текста Transkribus бесплатно, поскольку при регистрации вы получаете 500 бесплатных кредитов (т. е. около 500 страниц).
Ваши покупки позволят нам поддерживать Transkribus в будущем и поддерживать существование этого замечательного сообщества. Все, что вам нужно знать о покупке кредитов, вы можете найти здесь.
Все, что вам нужно знать о покупке кредитов, вы можете найти здесь.
БЕСПЛАТНО
Регистрация абсолютно бесплатна
500 бесплатных кредитов при регистрации
Обучение модели
Анализ макета
Ручная транскрипция
Зарегистрироваться
Создать бесплатную учетную запись READ-COOP
ПЛАТНЫЕ УСЛУГИ
Распознавание рукописного текста
Обработка больших сумм
По запросу или по подписке
Кредиты могут быть разделены
Вы поддерживаете платформу
См. цены
Купить кредиты по запросу или в виде подписки
Полезные ресурсы
Предстоящие события Транскрибуса
16 ноября
7 декабря
Хотите провести семинар Transkribus?
Мы предлагаем мастер-классы Transkribus, которые точно соответствуют вашим потребностям
Корни Transkribus
Transkribus был разработан Университетом Инсбрука в сотрудничестве с ведущими исследовательскими группами со всей Европы в рамках исследовательского проекта ЕС Horizon 2020 READ. Благодаря высокому международному признанию работа над экосистемой Transkribus в настоящее время продолжается в рамках Европейского кооперативного общества (SCE). Подробнее читайте на нашей странице о нас .
Благодаря высокому международному признанию работа над экосистемой Transkribus в настоящее время продолжается в рамках Европейского кооперативного общества (SCE). Подробнее читайте на нашей странице о нас .
Святой Иероним работы Альбрехта Дюрера
Начните работу с Transkribus
Сделайте свои исторические документы доступными
Эта страница была переведена с помощью искусственного интеллекта.
Если вы обнаружите какие-либо ошибки перевода, сообщите нам об этом или переключитесь на английский язык:
ЕН
RU DE ИТ
COOP
Товары и услуги
Полезная информация
Полезные ресурсы
Сообщество
Твиттер Линкедин YouTube Фейсбук
Copyright © 2021 READ-COOP SCE
Лучшее бесплатное программное обеспечение для распознавания текста с открытым исходным кодом | HelloSign
Оцифровка документов дает множество преимуществ для вашего бизнеса, но после того, как текстовый документ был преобразован в PDF, как вы выполняете поиск или редактирование текста? Существуют программы для решения этой проблемы, и многие из них бесплатны и имеют открытый исходный код.
Программное обеспечение для оптического распознавания символов (OCR) позволяет преобразовывать нередактируемые файлы, такие как PDF-файлы или изображения, в редактируемый текст. На рынке существует множество инструментов OCR. В этом обзоре будут сравниваться некоторые из лучших бесплатных инструментов OCR с открытым исходным кодом, чтобы вы могли выбрать один из них для своих проектов.
Как работает программа OCR?
Программное обеспечение OCR идентифицирует текст из отсканированных документов или изображений и преобразует текст в доступный для поиска или редактирования формат, такой как Microsoft Word или обычный текст. Эти инструменты могут работать с поставщиками облачных хранилищ, так что счетами-фактурами или другими документами вашей организации будет проще управлять и легко извлекать.
Каковы проблемы OCR-инструментов?
Существуют определенные проблемы, связанные с использованием программного обеспечения OCR, для решения которых предназначены перечисленные инструменты. К этим проблемам относятся:
К этим проблемам относятся:
Точность — Инструменты OCR не всегда точны на 100% и могут не распознавать каждую букву или цифру в документе. Вы можете повысить точность с помощью предварительной обработки, исправляя изображение, повышая его резкость и сглаживая, или постобработкой, обнаруживая и исправляя ошибки. Tesseract, например, предлагает предварительную обработку, такую как удаление шума и эрозия. EasyOCR предлагает автоматическую предварительную обработку, а PaddleOCR — постобработку. Инструменты, использующие алгоритмы глубокого обучения, имеют особое преимущество с точки зрения повышения точности.
Языковая поддержка — Инструменты OCR должны работать на нескольких языках, поскольку нет гарантии, что все документы вашей организации будут на английском языке. Tesseract, EasyOCR и PaddleOCR поддерживают более пятидесяти языков. Однако на момент написания CognitiveOCR поддерживает не более тридцати языков.
Зачем вам нужно программное обеспечение OCR?
Инструменты оптического распознавания текста помогают исключить ручную работу по редактированию документов или доступу к ним, экономя время и деньги.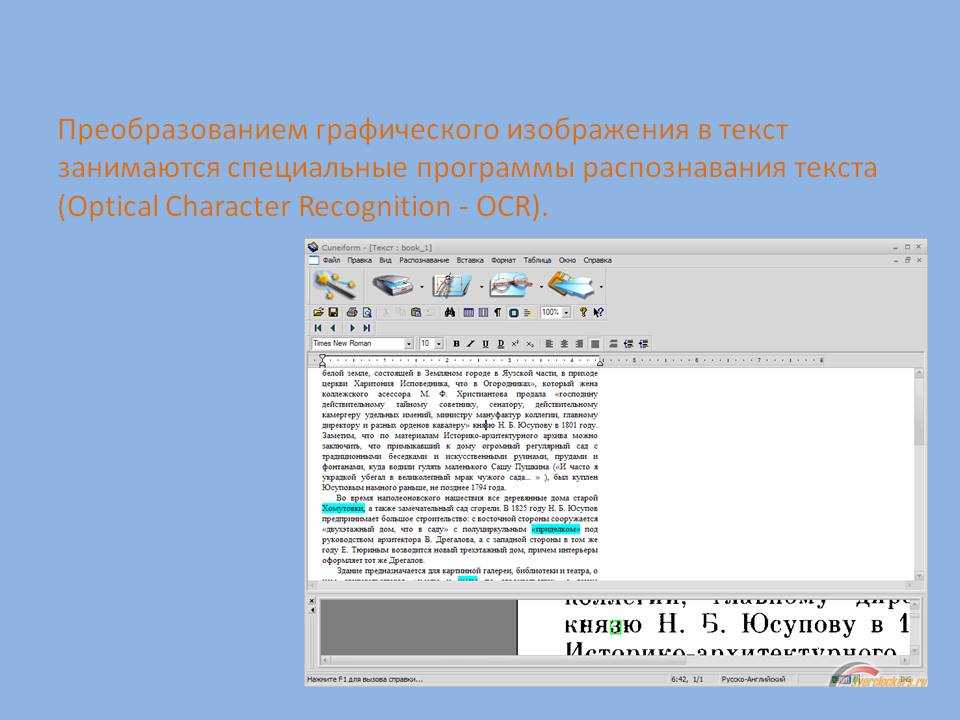 Вы можете более эффективно получать доступ и редактировать важную информацию. Поскольку вы можете легко оцифровывать документы своей организации и делиться ими, вы можете полностью перейти на безбумажный офис.
Вы можете более эффективно получать доступ и редактировать важную информацию. Поскольку вы можете легко оцифровывать документы своей организации и делиться ими, вы можете полностью перейти на безбумажный офис.
Почему были выбраны именно эти инструменты OCR?
Существует несколько вариантов программного обеспечения для оптического распознавания символов, многие из которых предлагают различные функции и возможности. В приведенном ниже разделе содержится обзор пяти бесплатных программ OCR с открытым исходным кодом, основанный на нескольких факторах: насколько хорошо они интегрируются с другими инструментами, насколько активно они поддерживаются, поддержка сообщества, точность, какие языки они поддерживают, оптимизация графического процессора и они предлагают оболочки или библиотеки для нескольких языков программирования.
Tesseract
Tesseract был разработан Hewlett-Packard, а затем выпущен как программа с открытым исходным кодом HP и Университетом Невады в Лас-Вегасе.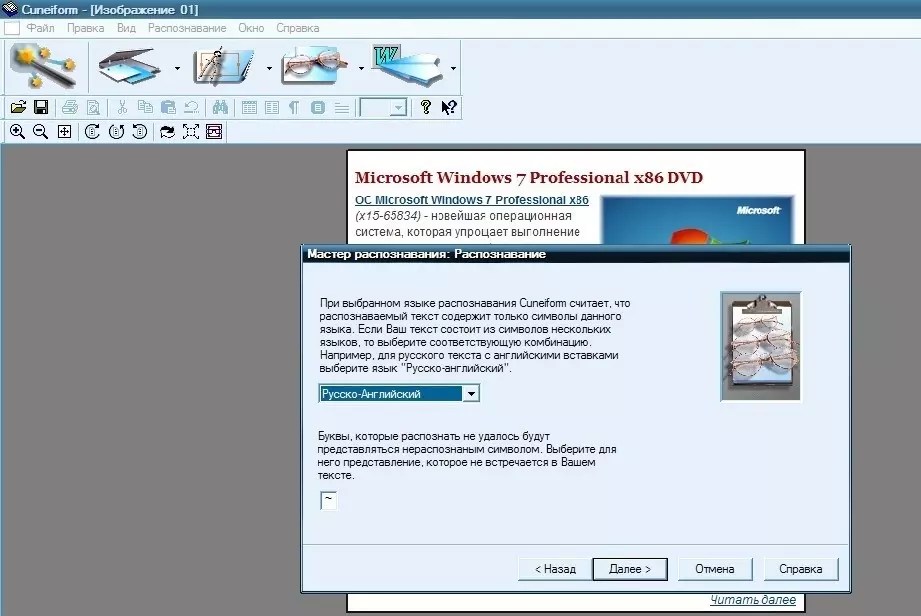 Tesseract 4 использует механизм OCR нейронной сети (LSTM) для распознавания строк, а Tesseract 3 использует устаревший механизм OCR для распознавания образов символов.
Tesseract 4 использует механизм OCR нейронной сети (LSTM) для распознавания строк, а Tesseract 3 использует устаревший механизм OCR для распознавания образов символов.
Механизм OCR Tesseract использует библиотеку Leptonica для открытия изображений в форматах TIFF, PNG и JPG и обеспечивает вывод в формате PDF, hOCR (HTML), TSV или обычного текста. Он доступен для Windows, Linux и macOS X. Его можно использовать напрямую через командную строку или с помощью API.
Tesseract интегрируется с несколькими инструментами, доступными для мобильных устройств, iOS и других систем. Его также можно интегрировать со сторонними инструментами для работы с графическими пользовательскими интерфейсами (GUI). Организация GitHub активно поддерживается как tesseract-ocr с более чем четырнадцатью репозиториями. На момент написания основной репозиторий Tesseract насчитывал более 43,8 тыс. звезд и более 7,8 тыс. форков.
Tesseract также предлагает отличную поддержку сообщества с различными проектами, такими как Tesseract Polish, модели Tesseract для индийских языков и древнегреческий OCR. Вы можете найти больше проектов сообщества в документации.
Вы можете найти больше проектов сообщества в документации.
Точность вывода зависит от различных факторов, таких как язык, качество изображения, подготовленные данные, сегментация страницы и механизм. Для большей точности вы можете предварительно обработать изображения с помощью таких инструментов, как OpenCV или ImageMagick, для удаления шума, масштабирования, бинаризации, поворота, инвертирования изображения, расширения и эрозии.
Половина кода изначально была написана на C, а половина — на C++, а затем скомпилирована как C++. Tesseract совместим с различными языками программирования и имеет оболочки, доступные, в частности, для Java, Python, Ruby и Swift.
На момент написания Tesseract поддерживал Unicode (UTF-8) и теперь распознает более ста языков, включая испанский, латынь и хинди. Его также можно обучить работе на других языках. По умолчанию для обработки используется английский язык, но вы можете использовать `-l` для добавления другого языка или `+` для комбинации языков.
EasyOCR
EasyOCR был разработан Jaded AI. Построенный на основе библиотеки PyTorch и моделей обнаружения и распознавания текста, EasyOCR интегрирует алгоритмы OCR, такие как:
- Модель обнаружения текста: распознавание областей символов для обнаружения текста (CRAFT)
- Модель распознавания текста: ResNet для извлечения признаков, долговременная кратковременная память (LSTM) для маркировки последовательностей и декодирование временной классификации соединений (CTC) (CRNN для сквозная обучаемая модель).
- Он быстро растет и активно поддерживается на GitHub с 13,7 тыс. звезд и 1,8 тыс. ответвлений.
EasyOCR имеет хорошую поддержку сообщества и служит зависимостью для нескольких других репозиториев GitHub. Поскольку он построен на библиотеке PyTorch, он более точен. Вам не нужно выполнять предварительную обработку изображения, которая может выполняться автоматически.
По умолчанию EasyOCR использует GPU для вычислений, что увеличивает скорость распознавания. Если вы хотите использовать режим CPU, который медленнее, чем Tesseract, вам нужно установить `gpu=false`. Вам нужна среда с GPU-ускорением, если вы хотите использовать GPU.
Если вы хотите использовать режим CPU, который медленнее, чем Tesseract, вам нужно установить `gpu=false`. Вам нужна среда с GPU-ускорением, если вы хотите использовать GPU.
На момент написания EasyOCR в настоящее время поддерживает восемьдесят три языка, включая польский, тамильский, шведский и тайский. Он может читать несколько языков одновременно, но они должны быть совместимы друг с другом. Это пакет Python, который поддерживает только язык программирования Python.
PaddleOCR
PaddleOCR, разработанный Baidu, основан на платформе глубокого обучения PaddlePaddle ( PA rallel D распределен D eep 8 LE 900). Он поддерживает Linux, Windows, macOS и другие системы.
PaddleOCR состоит из сверхлегкой и общей модели OCR, объединяющей такие алгоритмы OCR, как:
- Модели распознавания текста: EAST, DB, SAST
- Модели распознавания текста: CRNN, Rosetta, STAR-Net, RARE, SRN
Вы можете обучить и развернуть PaddleOCR на серверах, мобильных (как iOS, так и Android), встроенных устройствах и устройствах IoT.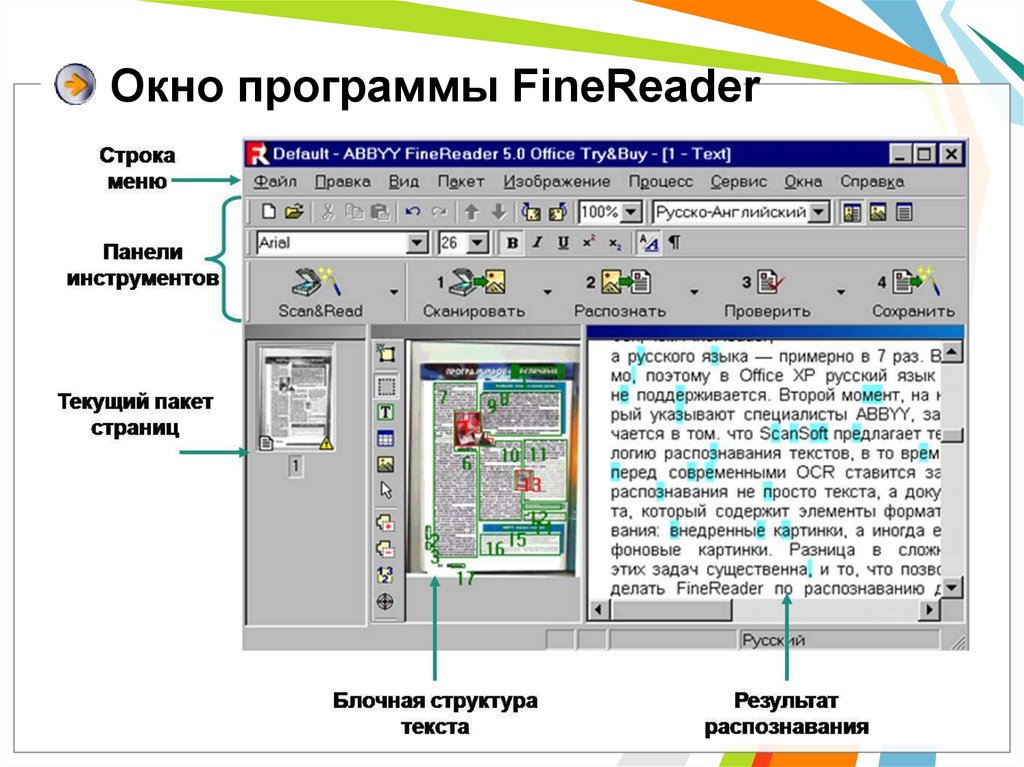 Он имеет библиотеку Paddle Lite, которая помогает интегрироваться с кроссплатформенным оборудованием для упрощения развертывания. Он поддерживает как CPU, так и GPU. Для более быстрых вычислений предпочтительнее использовать GPU.
Он имеет библиотеку Paddle Lite, которая помогает интегрироваться с кроссплатформенным оборудованием для упрощения развертывания. Он поддерживает как CPU, так и GPU. Для более быстрых вычислений предпочтительнее использовать GPU.
PaddleOCR поддерживает язык программирования Python, но для логического вывода и развертывания можно использовать C++ и Python. Доступны различные варианты обслуживания и контрольных показателей. Вы можете легко установить любой пакет с помощью менеджера пакетов pip. Вы также можете использовать этот репозиторий GitHub для преобразования Paddle в PyTorch.
На момент написания PaddleOCR активно поддерживается и быстро растет, насчитывая 18,8 тыс. звезд и 3,9 тыс. форков. Он предлагает хорошую поддержку сообщества и служит зависимостью для различных проектов GitHub.
PaddleOCR не обязательно является самым точным, но после некоторой постобработки PaddleOCR составляет серьезную конкуренцию Tesseract, особенно в китайском языке. На момент написания он поддерживает более восьмидесяти языков, включая корейский, немецкий и французский.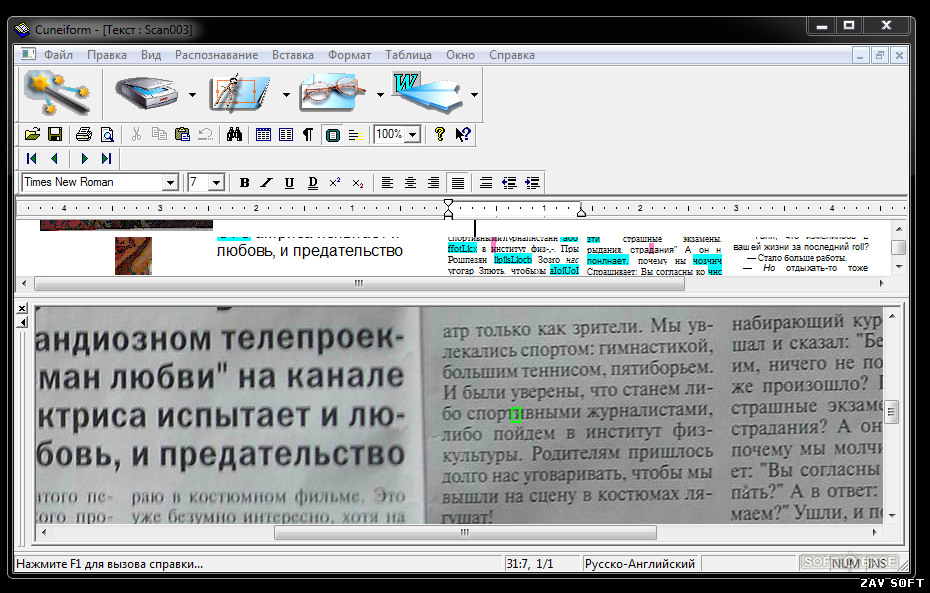
GOCR
GOCR (или JOCR) был разработан по общественной лицензии GNU Йоргом Шуленбургом. (Первоначально он был известен как GNU OCR, но позже был изменен на OCR Йорга). Он поддерживает входные форматы, такие как TIFF, GIF, PNG, PNM, PBM и BMP, для вывода текстового файла. Он поддерживает Windows, Linux и OS/2.
Вы можете интегрировать GOCR с различными внешними интерфейсами, что упрощает перенос на различные операционные системы и архитектуры. Вам не нужно обучать программу или хранить большие шрифты. Вы можете просто вызвать из командной строки, чтобы получить результаты.
Он не всегда точен, поскольку с трудом читает рукописный текст, зашумленные изображения и перекрывающиеся символы. Он доступен на английском языке и может также переводить штрих-коды. На момент написания GOCR активно не поддерживался, новых выпусков не было с 2018 года. Похоже, что у него нет большой поддержки сообщества,
Он работает на ЦП, но не на графическом процессоре. Он был написан на языке программирования Си. Доступны некоторые оболочки, такие как gocr-php, реализация Golang и GOCR.js.
Он был написан на языке программирования Си. Доступны некоторые оболочки, такие как gocr-php, реализация Golang и GOCR.js.
Cognitive OpenOCR
Cognitive OpenOCR (Cuneiform) от Cognitive Technologies был разработан путем объединения баз данных из других программ OCR с открытым ПО, а также пользовательского ввода и обратной связи. Он поддерживает от двадцати до тридцати языков, включая русский, английский, турецкий и итальянский.
Поскольку база данных встроена, для ее использования не требуется подключение к Интернету; однако он не поддерживается активно с 2019 года и не предлагает поддержку сообщества.
В большинстве случаев требуется редактирование выходных данных, и инструмент дает плохие результаты с менее контрастными изображениями, что делает его менее точным. Он работает на процессоре, но не поддерживает GPU. Он был написан на C и C++ и имеет оболочку, доступную в .NET.
Заключение
Программы оптического распознавания текста могут быть огромным преимуществом для предприятий, поскольку они завершают оцифровку документов и переходят на безбумажные офисы.