
Hаспознать текст с фотографии документа на смартфоне HUAWEI
от SabitovAdmin
Бумага как основной носитель информации, постепенно утрачивает своё значение. Во многих государственных и иных организациях осуществляется переход на «безбумажные» технологии. Теперь вместо бумажных документов чаще используют их электронный вариант.
Очень большим подспорьем для перехода к «электронным документам» помогло появление специальных программ для распознавания текста. Эти программные продукты используют технологию OCR (Optical character recognition) или ICR (Intelligence character recognition). На русский язык эти аббревиатуры переводятся как «оптическое распознавание символов» или «интеллектуальное распознавание символов».
Смысл работы этих OCR-программ заключается в выделении на фотографии участков, где расположен какой-то текст, распознавание нарисованных символов, и из этих распознанных символов воссоздание текста для работы в текстовом редакторе на компьютере.
Такие программы достаточно компактны и в них для обработки символов используются искусственные нейронные сети. Главное преимущество этих программ – непрерывное обучение. Это позволяет в дальнейшем эффективно распознавать слова, написанные человеком и рукописными буквами.
А как распознать текст с фотографии документа для его редактирования или перевода на русский язык на смартфоне HUAWEI (honor)?
В стандартном наборе приложений на смартфонах HUAWEI (honor) есть приложение Google Lens, которое может распознать на фотографиях всевозможные текстовые символы, информацию зашифрованную QR или штриховой кодировкой.
Порядок распознавания текста с фотографий документов на смартфоне HUAWEI (honor) с помощью приложения Google Lens.

Чтобы распознавание текста на фотографии было качественным, очень важно, чтобы фотографии документов были сделаны с соблюдением особых требований. Порядок съёмки документов на смартфоне HUAWEI (honor) под ОС Android 8 Oreo и под ОС Android 9 Pie описан в двух статьях: статья 1 и статья 2.
Чтобы распознать текст на фото и перенести его в текстовый редактор, нужно:
1. Открыть папку Google на Главном экране смартфона.
Экран №1 смартфона — открываем папку Google.2. Запустить приложение Google Фото.
Экран №2 смартфона – запускаем приложение Google Фото.3. В приложении Google Фото найти интересующую вас фотографию документа. Нажать на значок фотографии.
Экран №3 смартфона – находим фотографию и открываем её для просмотра.4. Далее, при просмотре выбранной фотографии нужно нажать на значок приложения Google Lens.
5. После запуска приложения Google Lens программа в автоматическом режиме проанализирует фотографию и через 1-2 секунды предложит выбрать текст на экране смартфона.
Экран №5 смартфона – вид экрана приложения Google Lens. Экран №6 смартфона – для открытия меню нажать на значок в виде «Увеличительного стекла».Для распознавания всего текста документа нам нужно перейти в режим работы с документом. Для этого вначале нужно нажать на значок в виде «Увеличительного стекла» и после открытия меню выбрать значок «Текст документа».
Экран №7 смартфона – в меню выбрать значок «Текст документа» .6. Теперь мы находимся в режиме работы со всем текстом документа. Чтобы распознать весь текст документа нужно нажать на значок «Выбрать всё».
Экран №8 смартфона – нажать на значок «Выбрать всё».7. После этого текст распознан и выделен в синий цвет. Для дальнейшей работы с текстом в текстовом редакторе нужно копировать выделенный текст в буфер обмена, а для этого нужно нажать на значок «Копировать текст».
8. Теперь внизу экрана появляется табличка «Скопировано в буфер обмена».
Далее для работы с текстом в редакторе нужно открыть соответствующее приложение редактора и поместить текст из буфера обмена в этот редактор.
Либо, если мы распознали текст на иностранном языке, то мы можем запустить приложение переводчика для перевода текста, помещенного в буфер обмена. Для запуска программы переводчика нужно нажать на значок Google Переводчик.
Экран №10 смартфона – для перевода текста нужно нажать на значок Google Переводчик.9. Таким образом, мы распознали текст с фотографии документа, снятого на камеру смартфона, и поместили его в буфер обмена для работы в текстовом редакторе или для его перевода.
Всё это заняло буквально пару секунд.
Как распознавать печатный или рукописный текст прямо в Telegram. Это очень удобно, попробуйте
Telegram Мессенджеры iOS Инструкции
Как распознавать печатный или рукописный текст прямо в Telegram.
 Это очень удобно, попробуйте
Это очень удобно, попробуйтеАлександр Кузнецов —
Telegram научился распознавать распечатанный или рукописный текст и преобразовывать его в текст, который можно отправить сообщением. Распознавание производится непосредственно с фотографий в приложении.
Это работает так: вы открываете фотографию документа, нажимаете кнопку распознавания, выделяете распознанный текст, копируете его. Далее этот текст можно вставить в поле для набора текста для последующей отправки. Благодаря этому, нет необходимости перепечатывать текст вручную.
Эта функция работает на iOS версии 13 и выше, её реализация стала возможна благодаря появлению в iOS встроенной возможности распознавания текста. Трансформация напечатанного илу рукописного текста происходит почти моментально, причём распознавание производится непосредственно на устройстве, поэтому данные не передаются на сторону (например, к Telegram, ни Apple), а только вашему собеседнику.
В настоящее время распознаётся только текст на английском языке. Добавление поддержки других языков зависит не от Telegram, а от Apple. Стоит отметить, что на Android-смартфонах тоже можно распознавать напечатанный или написанный от руки текст, в том числе на русском языке, но не в Telegram, а в приложении «Google Переводчик» или «Google Ассистент».
iGuides в Яндекс.Дзен — zen.yandex.ru/iguides.ru
iGuides в Telegram — t.me/igmedia
Рекомендации
- Как вынудить собеседника перестать делать скриншоты переписки в Telegram
- Как платить бесконтактно смартфоном, если у вас карта Visa или Mastercard
- Как ускорить компьютер на 25%, изменив всего одну настройку
 Как находить и качать торренты через Telegram”> RuTracker не работает несколько дней. Как находить и качать торренты через Telegram
Как находить и качать торренты через Telegram”> RuTracker не работает несколько дней. Как находить и качать торренты через TelegramРекомендации
Как вынудить собеседника перестать делать скриншоты переписки в Telegram
Как ускорить компьютер на 25%, изменив всего одну настройку
RuTracker не работает несколько дней. Как находить и качать торренты через Telegram
Читайте также
Apple iphone
Обзор смартфона HONOR X9a: а что, так можно было?!
Honor
Как установить любое iOS-приложение или игру на Mac с чипом Silicon M1/M2
Гайды M1 M2 Apple Silicon Mac MacBook macOS
Распознавание текста из изображения в Swift | by Тони Уилсон jesuraj | IVYMobility TechBytes
Как работает OCR и как распознавание изображений выполняется в swift
Привет, сначала я объяснил процесс OCR. Если вам нужна только часть кода , идите вниз, приятель (спасибо).
Если вам нужна только часть кода , идите вниз, приятель (спасибо).
Оптическое распознавание символов
- OCR, известное как оптическое распознавание символов или оптическое считывание символов
- OCR Сканирует документ или файл изображения с последующим преобразованием текста в машиночитаемый
примечания: я украл изображение из Google
позвольте мне разбить процесс один за другим и объяснить вам и замените каждый пиксель изображения черным или белым пикселем
Пример изображения
Примечание. Это мое собственное изображение
Таким образом, наше изображение будет преобразовано. Следующие
Предварительная обработка- Области за пределами текста будут удалены
Пример изображения
После предварительной обработки этого черно-белого изображения мы получим изображение, показанное выше.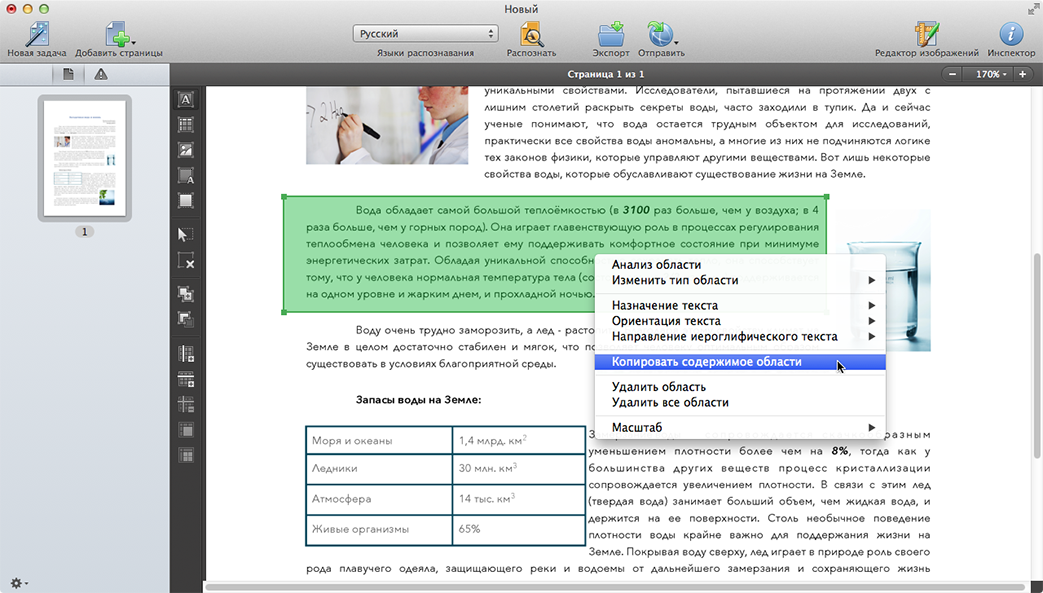
Просто посмотрите на 22 , он был как бы объединен с одним и другим, поэтому в этом процессе OCR будет сегментировать эти типы
Извлечение признаков
- Каждый символ будет в этом процессе. Распознавание и преобразование в машиночитаемый текст
- OCR имеет много шрифтов
- Есть много Подход, покажет два
Подход #1
- Будет сканировать по одному символу и сравнивать с функциями
- В этом подходе построчная обработка (например, чтение глазами человека) и преобразование
Подобных подходов существует много, они основаны на том, какие технологии нам нужны
ПостобработкаКомпьютер тоже делает какую-то ошибку (OCR делает орфографическую ошибку при распознавании), так что здесь постараемся исправить.
Часть кодирования приветствует вас
Итак, процесс оптического распознавания текста для разработчиков iOS будет похож на
Мы можем сделать это просто с помощью зрения.
Step -1
import Vision
Step -2
// преобразование изображения в CGImage guard let cgImage = imageWithText.image?.cgImage else else0008 { return } Step -3
// создание запроса с cgImage
let handler = VNImageRequestHandler(cgImage: cgImage, options: [:])
Step -4
// Vision предоставляет свой текст -возможности распознавания через VNRecognizeTextRequest , тип запроса на основе изображения, который находит и извлекает текст в изображениях. пусть запрос = VNRecognizeTextRequest { запрос, ошибка вохрана пусть наблюдения = запрос.результаты как [VNRecognizedTextObservation],
error == nil else { return } let text =Observations.
 compactMap({$0.topCandidates(1).first?.string}).joined(separator: “, “)
compactMap({$0.topCandidates(1).first?.string}).joined(separator: “, “) print(text) // текст, который мы получаем из изображения}
VNRecognizeTextRequest- тип запроса на основе изображения, который находит и извлекает текст в изображениях (так просто)
step -5
запрос. признаниеLevel = VNRequestTextRecognitionLevel try handler.perform([request])
Здесь у нас есть два пути для распознавания. Уровень Fast Path и Accurate Path
Fast Path- аналогично традиционному оптическому распознаванию символов 90 метод обнаружения символов
// Просто добавьте . быстро в концеТочный путь
request.recognitionLevel = VNRequestTextRecognitionLevel.fast
- Использует нейронную сеть для поиска текста
- построчный метод (аналогично человеческому чтению)
// Просто добавьте .fast в конце
request.recognitionLevel = VNRequestTextRecognitionLevel.accurate
 fast в конце
fast в конце Для нескольких языков в
VNRecognizeTextRequest// просто добавьте код языка
code.recognitionLanguages request ="
request.recognitionLanguages] признаниеLevel = VNRequestTextRecognitionLevel.accurate
try handler.perform([request])
Получите -> вывод -> Наслаждайтесь
Вот и все. Надеюсь, вы узнали кое-что об OCR.
Если какая-то ошибка или вам нужно крикнуть мне, сессия комментариев всегда открыта
நன்றி வணக்கம்
Как работает OCR? | Советы пользователям
Обновлено 14 февраля 2023 г.
Виктория
Опубликовано 18 мая 2016 г. в Советы и рекомендации для пользователей
«Оптическое распознавание символов» – или OCR – это процесс, который позволяет нам преобразовывать текст, содержащийся в изображениях, в редактируемые документы.
Эта технология используется для различных приложений, таких как ввод данных документов, автоматическое распознавание номерных знаков, оцифровка печатных документов в Google Книгах и даже преодоление систем защиты от ботов CAPTCHA!
В мире САПР оптическое распознавание символов играет решающую роль в преобразовании растровых эскизов в редактируемые чертежи САПР. В этой статье мы заглянем за кулисы, чтобы понять, как работает OCR!
Существует два разных метода (или алгоритма) оптического распознавания символов: распознавание образов и извлечение признаков, и каждый из них заслуживает более подробного рассмотрения.
Распознавание образов
Компьютер сопоставляет текст со своим словарем символов.
Используя эту технику, компьютер пытается распознать весь символ, и сопоставляет его с матрицей символов, хранящейся в программном обеспечении. В результате этот метод также известен как сопоставление с образцом или сопоставление с матрицей. Недостатком этого метода является то, что он полагается на то, что вводимые символы и сохраненные символы имеют один и тот же шрифт и один и тот же масштаб. Посмотрите на фотографию слева — это первый шрифт, созданный в 1960-х годах для OCR — OCR-A, — где все буквы имели одинаковую ширину. Все чеки были напечатаны с использованием этого шрифта, чтобы банковские компьютеры могли их обрабатывать!
В результате этот метод также известен как сопоставление с образцом или сопоставление с матрицей. Недостатком этого метода является то, что он полагается на то, что вводимые символы и сохраненные символы имеют один и тот же шрифт и один и тот же масштаб. Посмотрите на фотографию слева — это первый шрифт, созданный в 1960-х годах для OCR — OCR-A, — где все буквы имели одинаковую ширину. Все чеки были напечатаны с использованием этого шрифта, чтобы банковские компьютеры могли их обрабатывать!
Scan2CAD применяет нейронные сети к задаче сопоставления с образцом. Нейронные сети работают аналогично человеческому мозгу. Они учатся распознавать формы и узоры на различных примерах. Scan2CAD включает в себя функцию, позволяющую пользователю обучать свои собственные нейронные сети распознавать стили шрифтов, уникальные для их чертежей.
Извлечение признаков
Буква A = две наклонные линии + одна горизонтальная линия
Это гораздо более сложный способ обнаружения персонажей. Он разбивает символы на «функции», такие как линии, замкнутые петли, направления линий и пересечения.
Он разбивает символы на «функции», такие как линии, замкнутые петли, направления линий и пересечения.
Возьмем в качестве примера букву А. Если компьютер видит две наклонные линии, которые встречаются вверху, и обе линии соединены горизонтальной линией посередине, это буква A.
Используя такие правила, программа может определить большинство заглавных букв «А», независимо от шрифта, которым они написаны.
Предварительная обработка для улучшения распознавания текста
Для эффективного распознавания текста программное обеспечение должно предварительно обработать изображение с использованием таких методов, как:
- Устранение перекоса — наклон изображения на несколько градусов, чтобы строки текста были идеально горизонтальными или вертикальными
- Удаление пятен – Удаление пятен и сглаживание краев символов
- Изоляция персонажей — Разделение соприкасающихся персонажей, которые могли сливаться друг с другом
- Анализ компоновки — Идентификация текстовых позиций, столбцов и абзацев
- Удаление линий – Удаление наложенных друг на друга линий или блоков
Более сложное программное обеспечение также выполняет этапы постобработки.
Технология распознавания текста в Scan2CAD
Scan2CAD — это механизм преобразования растровых изображений в векторные. Он преобразует изображения в векторные рисунки, чтобы их можно было редактировать с помощью других программ CAD/CAM и ЧПУ. Поскольку многие изображения содержат текст, распознавание текста является жизненно важной частью процесса преобразования растра в вектор. В отличие от многих конвертеров изображений САПР, Scan2CAD преобразует текст в растровых изображениях в правильные редактируемые векторные текстовые строки вместо того, чтобы создавать его из отдельных векторных объектов (таких как линии и дуги).
Вы можете убедиться, что текст на растровом изображении готов к векторизации, следуя Контрольному списку качества растрового текста Scan2CAD.
Слева – текст САПР, преобразованный с помощью Scan2CAD. Справа текст, преобразованный с помощью другого программного обеспечения, который не очень точно пересобирается в логические предложения.
С OCR нет необходимости вручную перепечатывать метки, и эти текстовые векторы также легко редактируются. Во многих случаях все, что вам нужно сделать, это щелкнуть «OCR» на ленте в верхней части рабочего пространства, и вуаля! Попробуйте распознавание текста самостоятельно, используя нашу 14-дневную БЕСПЛАТНУЮ пробную версию Scan2CAD.
Дальнейшее чтение:
- Рекомендации по повышению точности оптического распознавания символов
- Преобразование рукописных заметок в документы Word
- Создайте собственное приложение OCR с помощью kNN
О Виктории
Я напишу об основных навыках САПР, которые необходимо знать каждому — просмотр и редактирование файлов, выбор формата файла и тому подобное.