
Как распознать текст с картинки
Натали Азаренко
13 декабря, 2022
Как работает распознавание текста на картинках Google Lens Google Docs Яндекс.Картинки Дополнительные сервисы
Когда нужно извлечь текст с изображения, то самый простой способ очевиден — нужно просто его переписать. Но если надписей или картинок очень много, то выполнить задачу вручную становится сложнее. В этом случае помогут специальные программы и сервисы по автоматическому распознаванию. Рассказываю, как легко распознать текст на картинке и какие инструменты в этом помогут.
Как работает распознавание текста на картинках
Извлечение текста из изображения основано на технологии OCR — оптического распознавания символов. Она включает в себя такие этапы:
Она включает в себя такие этапы:
Получение и анализ изображения. Программа сканирует картинку и определяет светлые области как фон, а тёмные — как символы и буквы.
Подготовка к распознаванию. Изображение проходит очистку — сглаживается контраст, удаляются пятна, стираются рамки и линии, распознаются шрифты.
Распознавание текста. Программа сравнивает символы с шаблонами из базы или по отдельным элементам символа ищет наибольшие соответствия.
Итоговая обработка. Результат отображается в текстовом формате. Некоторые системы могут преобразовать извлечённые данные в текстовые файлы — PDF, TXT, DOC.
Для качественного распознавания нужно, чтобы надписи отличались от фона и иллюстраций. Все символы должны быть разборчивыми и чёткими, а строки на картинке — идти ровно, без перекосов и искажений.
Вот какие сервисы можно использовать для извлечения текста из изображений.
Google Lens
Приложение «Google Объектив» может не только извлечь текст с картинки, но и перевести его на другой язык. Распознанные символы можно скопировать с изображения как в обычном текстовом файле.
Распознанные символы можно скопировать с изображения как в обычном текстовом файле.
Кликните по изображению в браузере для вызова контекстного меню и выберите пункт «Найти через Google Объектив». После открытия картинки в Google Lens нажмите на «Текст» и скопируйте символы с картинки через меню или Ctrl + C.
Если кликнуть на «Переводчик», можно сразу перевести результат на любой язык с помощью Google Translate.
Аналогично функция работает и в браузере Google на мобильных устройствах. Нужно нажать на картинку для вызова меню, выбрать «Найти через Google Объектив» и скопировать результат.
Кстати, с помощью Google Lens можно распознавать текст на изображениях, сохранённых на мобильном устройстве. Для этого откройте нужный файл в «Галерее» и нажмите на «Поделиться». В разделе «Отправить файлы через…» выберите «Google Поиск по изображению». Картинка откроется в Google Lens, и вы сможете скопировать надписи.
Google Docs
Извлечь текст с картинки помогают и Google Документы.
- Загрузите фото, скан или изображение на Google Drive.
- Кликните по загруженному файлу для вызова меню.
- Выберите пункт «Открыть с помощью Google Документы».
- В открывшемся документе скопируйте текст, отображаемый под картинкой.
При необходимости результат преобразования можно сразу отредактировать и исправить в нём ошибки.
Длительность обработки картинки в Google Docs зависит от объёма загруженного файла. Но, по личному опыту, на обработку уходит не больше одной минуты.
Яндекс.Картинки
Функция распознавания текста есть и в Яндексе.
Кликните на изображение с надписями и в меню выберите «Найти это изображение в Яндексе». Картинка откроется в новом окне. Нажмите на «Распознать текст» в правой части страницы, если автоматического преобразования не произошло.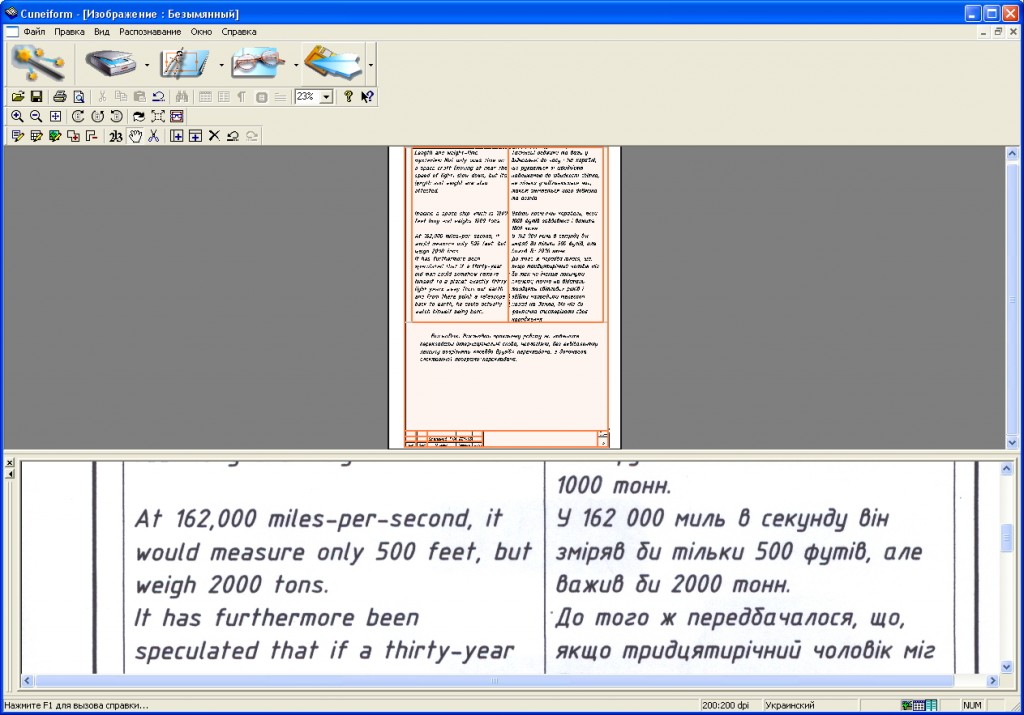
Результат можно скопировать или отправить в «Яндекс.Переводчик».
Если нужно извлечь только определённую часть текста, то используйте функцию «Выбрать фрагмент». Выделите нужную часть изображения и активируйте распознавание.
Извлечение текста с картинок поддерживается и в мобильной версии Яндекса. При этом для обработки можно загружать изображения из «Галереи» смартфона.
Дополнительные сервисы
Помимо встроенных инструментов Яндекса и Google, можно применять для распознавания текста и другие сервисы.
Convertio
Сайт
Онлайн-сервис Convertio преобразует отсканированные документы и изображения в редактируемые форматы DOC, PDF, XLS и TXT. Бесплатно и без регистрации можно обработать до 10 страниц. После загрузки файла можно выбрать язык документа, формат сохранения результата, номера страниц в файле. Готовый текст доступен для скачивания или отправки в Google Drive либо Dropbox.
На платной версии сервиса потребуется регистрация. Стоимость зависит от объёма предоплаченного пакета — от $4.99 за 50 страниц.
Стоимость зависит от объёма предоплаченного пакета — от $4.99 за 50 страниц.
Aspose
Сайт
В Aspose можно бесплатно конвертировать в текст отсканированные документы, изображения, фотографии. Можно загрузить файл, сделать снимок на камеру или указать URL картинки. В списке поддерживаемых языков — 45 вариантов. Есть возможность настроить формат загруженного документа, включить коррекцию контраста и переноса, отрегулировать уровень разрешения.
Тестирование сервиса показало, что он хорошо обрабатывает картинки с небольшим количеством текста. А вот более объёмные документы содержат много ошибок. Хотя, возможно, сервис не устроило качество файлов или что-то ещё.
Цифра Р
Сайт
В сервисе от типографии «Цифра Р» можно бесплатно преобразовать изображения в текст. Поддерживаются только форматы JPG и JPEG. Результат выводится в отдельном окне и доступен для копирования.
В этом сервисе нет никакого дополнительного функционала и настроек. Но именно своей простотой он и привлекает: загрузить файл, нажать кнопку и скопировать результат. Обработка файлов происходит достаточно быстро.
Но именно своей простотой он и привлекает: загрузить файл, нажать кнопку и скопировать результат. Обработка файлов происходит достаточно быстро.
Online-convert
Сайт
Ещё один инструмент для извлечения текста из изображений, фотографий и других рисунков. В Online-convert поддерживается обработка файлов формата JPG, PNG, TIFF, SVG, BMP, WEBP. Результат сохраняется в текстовый файл TXT. В дополнительных настройках сервиса можно указать все языки, которые используются в файле.
В бесплатной версии сервиса доступны только самые простые функции. Также есть ограничения по размеру файла, количеству задач в сутки, времени обработки. Платный тариф позволяет обрабатывать файлы от 4–8 ГБ и более, без ограничений по количеству документов и с высоким приоритетом. Стоимость платной версии по подписке — от $6.42 в сутки.
«Фото в текст»
Сайт
Бесплатный сервис «Фото в текст» умеет преобразовывать в текстовый формат изображения JPG, JPEG, BMP, PNG, GIF И TIFF. Результат можно скопировать или скачать в виде файла TXT. Сервис поддерживает множество языков, при этом автоматически распознаёт язык документа. Также можно самостоятельно выбрать нужный язык. Картинки загружаются с компьютера, из Dropbox или по URL.
Результат можно скопировать или скачать в виде файла TXT. Сервис поддерживает множество языков, при этом автоматически распознаёт язык документа. Также можно самостоятельно выбрать нужный язык. Картинки загружаются с компьютера, из Dropbox или по URL.
Текст получается довольно качественным. Потестировав сервис, я обнаружила только одну ошибку в тексте объёмом на половину страницы. Конечно, результат во многом зависит от качества исходного оригинала.
Есть и другие инструменты на основе OCR. Например, десктопные программы, которые позволяют локально обрабатывать документы большого объёма. Но для периодического применения и обработки относительно небольших файлов онлайн-сервисы вполне подходят.
Поделиться
СВЕЖИЕ СТАТЬИ
Другие материалы из этой рубрики
Не пропускайте новые статьи
Подписывайтесь на соцсети
Делимся новостями и свежими статьями, рассказываем о новинках сервиса
Статьи почтой
Раз в неделю присылаем подборку свежих статей и новостей из блога. Пытаемся
шутить, но получается не всегда
Пытаемся
шутить, но получается не всегда
Наш юрист будет ругаться, если вы не примете 🙁
Как запустить email-маркетинг с нуля?
В бесплатном курсе «Rock-email» мы за 15 писем расскажем, как настроить email-маркетинг в компании. В конце каждого письма даем отбитые татуировки об email ⚡️
*Вместе с курсом вы будете получать рассылку блога Unisender
Оставляя свой email, я принимаю Политику конфиденциальностиНаш юрист будет ругаться, если вы не примете 🙁
C# Разработка: Быстрый способ распознавания текста
Теперь, зная фрагменты, можно посчитать их количество, в результате получится характеристический набор [F0, F1, F2, F3. ..F15], который будет уникален для любого изображения. Ниже приведен пример алгоритма подсчета фрагментов:
..F15], который будет уникален для любого изображения. Ниже приведен пример алгоритма подсчета фрагментов:
На каждом изображение
ЗАМЕЧАНИЕ: на практике значение F0 (для изображения Original это значение 8) не используется, поскольку является фоном изображения. Поэтому будут использоваться 15 значений, начиная с F1 до F15.
Свойства эйлеровой характеристики изображения.
- Значение характеристического набора [F1, F2…F15] является уникальным, иными словами не существует два изображения с одинаковой эйлеровой характеристикой.
- Нет алгоритма преобразования из характеристического набора в исходное изображение, единственный способ – это перебор.

Каков алгоритм распознания текста?
Идея распознания букв заключается в том, что мы заранее вычисляем эйлеровую характеристику для всех символов алфавита языка и сохраняем это в базу знаний. Затем для частей распозноваемого изображения будем вычислять эйлеровую характеристику и искать её в базе знаний.
Этапы распознавания:
- Изображение может быть как черно-белым так и цветным, поэтому первым этапом происходит аппроксимация изображения, то есть получение из него черно белого.
- Производим попиксельный проход по всему изображению с целью нахождения черных пикселей. При обнаружении закрашенного пикселя запускается рекурсивная операция по поиску всех закрашенных пикселей прилегающий к найденному и последующим. В результате мы получим фрагмент изображения, который может быть как симвом целиком так и часть его, либо “мусором”, которые следует отбросить.
- После нахождения всех не связанных частей изображения, для каждого вычисляется эйлеровая характеристика.

- Далее в работу вступает анализатор, который проходя по каждому фрагменту определяет, есть ли значение его эйлеровой характеристики в базе знаний. Если значение находим, то считаем, что это распознанный фрагмент изображения, иначе оставляем его для дальнейшего изучения.
- Нераспознанные части изображения подвергаются эвристическому анализу, то есть я пытаюсь по значению эйлеровой характеристики найти наиболее подходящее значение в базе знаний. Если же найти не удалось, то происходит попытка “склеить” находящиеся неподалеку фрагменты, и уже для них провести поиск результата в базе знаний. Для чего делается “склеивание”? Дело в том, что не все буквы состоят из одного непрерывного изображения, допустим “!” знак восклицания содержит 2 сегмента (палочка и точка), поэтому перед тем как его искать в базе знаний, требуется вычислить суммарное значение эйлеровой характеристики из обоих частей. Если же и после склейки с соседними сегментами приемлемый результат найти не удалось, то фрагмент считам мусором и пропускаем.

Состав системы:
- База знаний – файл или файлы изначально созданные мной, либо кем то ещё, содержащие характеристические наборы символов и требуемые для распознования.
- Core – содержит основные функции, выполняющие распознавание
- Generator – модуль для создания базы знаний.
ClearType и сглаживание.
Итак, на вход мы имеем распозноваемое изображение, и цель из него сделать черно-белое, подходящее для начала процесса распознавания. Казалось бы, чего может быть проще, все белые пиксели считаем за 0, а все остальные остальные 1, но не все так просто. Текст на изображении может быть сглаженным и не сглаженным. Сглаженные символы смотрятся плавными и без углов, а не сглаженные будут выглядеть на современным мониторах с заметными глазу пикселями по контуру. С появлением LCD (жидкокристаллических) экранов были созданы ClearType (для Windows) и другие виды сглаживания, которые пользуясь особенностями матрицы монитора.
В чем же дело? Почему на маленьком масштабе мы видим обычный символ? Неужели глаза нас обманываю? Дело в том, что пиксель LCD монитора состоит не из единого пикселя, который может принимать нужный цвет, а из 3 субпикселей 3 цветов, которых хватает для получения нужного цвета. Поэтому цель работы ClearType получить наиболее приятный глазу текст используя особенность матрицы LCD монитора, а это достигается с помощью субпиксельного рендеринга. У кого есть “Лупа” можете, с целью эксперимента, увеличить любое место включенного экрана и увидеть матрицу как на картинке ниже.
На рисунке показан квадрат из 3х3 пикселей LCD матрицы.
Внимание! Данная особенность усложняет получение черно белого изображения и очень сильно влияет на результат, поскольку не всегда даёт возможность получить такое же изображение, эйлеровая характеристика которого сохранена в базу знаний.Тем самым различие изображений заставляет выполнять эвристический анализ, которые не всегда может быть удачным.
Получение черно-белого изображения.
Найденные в интернете алгоритмы преобразования цветного в черно-белое меня не устроили качеством. После их применения, образы символов подвергнутых сублепиксельному рендеренгу, становились разными по ширине, появлялись разрывы линий букв и непонятный мусор. В итоге решил получать черно-белого изображения путем анализа яркости пикселя. Черным считал все пиксели ярче (больше величины) 130 единиц, остальные белые. Данный способ не идеален, и все равно приводит к получению неудовлетворительного результата если меняется яркость текста, но он хотя бы получал схожие со значениями в базе знаний изображения. Реализацию можно посмотреть в классе LuminosityApproximator.
База знаний.
Изначальная задумка наполнения базы знаний была такая, что я для каждой буквы языка подсчитаю эйлеровую характеристику получаемого изображения символа для 140 шрифтов, которые установлены у меня на компьтере (C:\Windows\Fonts), добавлю ещё все варианты типы шрифтов (Обычный, Жирный, Курсив) и размеры с 8 до 32, тем самым покрою все, или почти все, вариации букв и база станет универсальной, но к сожалению это оказалось не так хорошо как кажется. С такими условиями у меня получилось вот что:
С такими условиями у меня получилось вот что:
- Файл базы знаний получился достаточно большим (около 3 мегабайт) для русского и английского языка. Не смотря на то, что эйлеровая характеристика хранится в виде простой строки из 15 цифр, а сам файл представляет из себя сжатый архив (DeflateStream), который потом распаковывается в памяти.
- Около 10 секунд у меня занимает десериализация базы знаний. При этом страдало время сравнения характеристических наборов. Функцию для вычисления GetHashCode() подобрать не получилось, поэтому пришлось сравнивать поразрядно. И по сравнению с базой знаний из 3-5 шрифтов, время анализа текста с базой в 140 шрифтов увеличиволось в 30-50 раз. При этом в базу знаний не сохраняются одинаковые характеристические наборы, не смотря на то, что некоторые символы в разных шрифтах могут выглядеть одинаково и быть схожими даже есть это к примеру 20 и 21 шрифт.
Поэтому пришлось создать небольшую базу знаний, которая идет внутри Core модуля, и даёт возможность проверить функционал. Есть очень серьезная проблема при наполнении базы. Не все шрифты отображают символы небольшого размера корректно. Допустим символ “e” при отрисовке 8 размером шрифта по имени “Franklin Gothic Medium” получается как:
Есть очень серьезная проблема при наполнении базы. Не все шрифты отображают символы небольшого размера корректно. Допустим символ “e” при отрисовке 8 размером шрифта по имени “Franklin Gothic Medium” получается как:
шрифтов — библиотека C++ для распознавания изображений: изображения, содержащие слова, в строку
спросил
Изменено 5 лет, 11 месяцев назад
Просмотрено 6к раз
Кто-нибудь знает о библиотеке С++ для получения изображения и выполнения распознавания изображения на нем, чтобы он мог находить буквы на основе заданного шрифта и/или высоты шрифта? Подойдет даже тот, который не позволяет выбрать шрифт (например: readLetters(Image image).
- c++
- шрифты
- ocr
- распознавание изображений
0
В последнее время я много этим занимаюсь. Ваше лучшее – это просто Тессеракт. Если вам нужен анализ макета поверх OCR, используйте Ocropus (который, в свою очередь, использует Tesseract для OCR). Анализ макета означает способность определять положение текста на изображении и выполнять такие действия, как сегментация строк, сегментация блоков и т. д.
Ваше лучшее – это просто Тессеракт. Если вам нужен анализ макета поверх OCR, используйте Ocropus (который, в свою очередь, использует Tesseract для OCR). Анализ макета означает способность определять положение текста на изображении и выполнять такие действия, как сегментация строк, сегментация блоков и т. д.
Экспериментируя с Tesseract, я нашел несколько действительно хороших советов, которыми стоит поделиться. По сути, мне пришлось сделать много предварительной обработки изображения.
- Увеличение/уменьшение входного изображения до 300 dpi.
- Удалить цвет с изображения. Серая шкала хорошая. На самом деле я использовал порог дизеринга и сделал ввод черно-белым.
- Вырежьте ненужный мусор из изображения. Для всех трех описанных выше я использовал netbpm (набор инструментов для работы с изображениями для Unix), чтобы добиться почти 100-процентной точности того, что мне было нужно.
Если у вас есть сильно настроенный шрифт и вы работаете только с tesseract, вам нужно «обучить» систему – в основном вам нужно передать кучу обучающих данных. Это хорошо задокументировано на сайте tesseract-ocr. По сути, вы создаете новый «язык» для своего шрифта и передаете его с параметром -l.
Это хорошо задокументировано на сайте tesseract-ocr. По сути, вы создаете новый «язык» для своего шрифта и передаете его с параметром -l.
Другой механизм обучения, который я нашел, был с Ocropus, использующим обучение nueral net (bpnet). Для построения хорошей статистической модели требуется много входных данных.
С точки зрения вызова Tesseract/Ocropus оба являются C++. Это будет не так просто, как ReadLines(Image), но есть API, который вы можете проверить. Вы также можете вызвать через командную строку.
1
Хотя я не могу рекомендовать какой-либо конкретный термин, вы ищете термин OCR (оптическое распознавание символов).
1
Для этого есть tesseract-ocr, профессиональная библиотека.
Оттуда веб-сайт
Двигатель Tesseract OCR был одним из трех лучших двигателей в тесте на точность UNLV 1995 года.
В период с 1995 по 2006 год над ним было мало работы, но это, вероятно, один из самых точных доступных OCR-движков с открытым исходным кодом 9.0005
Думаю, вам нужна гипотеза. Раньше это был проект libgocr. Я не использовал его несколько лет, но раньше он был очень надежным, если вы установили ключ.
Библиотека Tesseract OCR дает довольно точные результаты, это библиотека C и C++. Мои первоначальные результаты были точными примерно на 80%, но при предварительной обработке изображений перед отправкой в OCR результаты были точными примерно на 95%. Что такое предварительная обработка:
1) Бинаризация растрового изображения (у меня лучше работал черно-белый). Как это можно сделать
2) Изменение разрешения изображения до 300 dpi
3) Сохраните изображение в формате без потерь, таком как LZW TIFF или CCITT Group 4 TIFF.
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google
Зарегистрироваться через Facebook
Зарегистрируйтесь, используя электронную почту и пароль
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
opencv – Трудности распознавания изображений с OCR – чтение цифр с картинки
Я пытаюсь разработать скрипт на Python, который может считывать числа с изображений, точнее, я пытаюсь получить расход газа. Расположение чисел всегда одинаково. Есть два «типа» фотографий, яркие и темные. (я фотографирую каждые 10 минут, поэтому у меня есть много примеров, если нужно)
Расположение чисел всегда одинаково. Есть два «типа» фотографий, яркие и темные. (я фотографирую каждые 10 минут, поэтому у меня есть много примеров, если нужно)
Я хотел бы получить в результате 8 цифр. например 10974748 (из темного изображения)
В основном я использую Pytesseract и OpenCV2.
Пока лучшим решением кажется то, что сначала я обрезаю нужную часть картинки, чем использую pytesseract.image_to_string() с config = --psm 7 . Но, к сожалению, это действительно ненадежное решение, оно не может распознавать одинаковые комбинации цифр, когда не было потребления, но были сделаны фотографии.
импорт cv2
импортировать numpy как np
импорт ОС
импортировать питессеракт
pytesseract.pytesseract.tesseract_cmd = r"C:\Program Files\Tesseract-OCR\tesseract"
directory = r"C:\Users\user\Desktop\test_pcs\test"
для изображения в os.listdir(каталог):
OriginalImagePath = os.path.join (каталог, изображение)
Исходное изображение = cv2.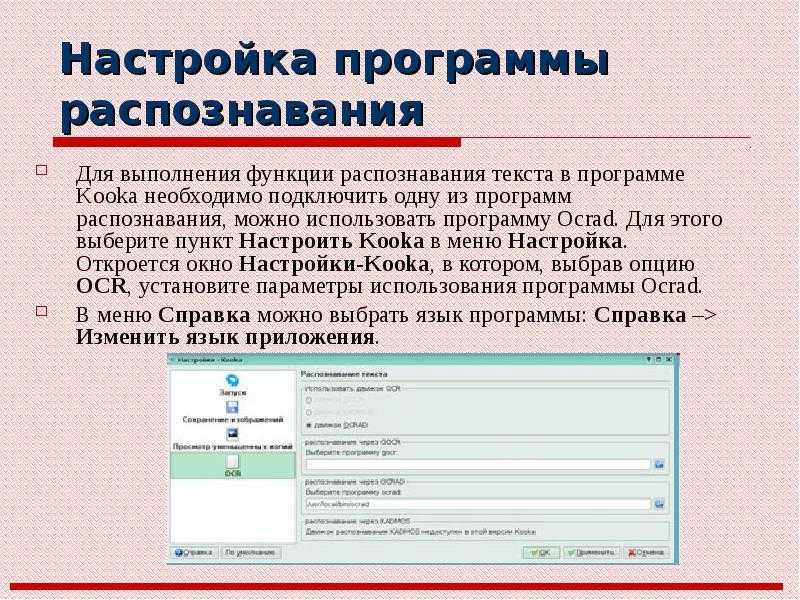 imread (исходный путь изображения)
x_start, y_start = интервал (1110), интервал (445)
x_end, y_end = интервал (1690), интервал(520)
Cropped_image = OriginalImage[y_start:y_end, x_start:x_end]
text = (pytesseract.image_to_string(cropped_image, config="--psm 7 выходных базовых цифр"))
cv2.imshow("Обрезано",croped_image)
cv2.waitKey(0)
печать (текст + " " + OriginalImagePath)
cv2.destroyAllWindows()
imread (исходный путь изображения)
x_start, y_start = интервал (1110), интервал (445)
x_end, y_end = интервал (1690), интервал(520)
Cropped_image = OriginalImage[y_start:y_end, x_start:x_end]
text = (pytesseract.image_to_string(cropped_image, config="--psm 7 выходных базовых цифр"))
cv2.imshow("Обрезано",croped_image)
cv2.waitKey(0)
печать (текст + " " + OriginalImagePath)
cv2.destroyAllWindows()
После этого я попытался использовать пороговое значение, но, к сожалению, получил худшие результаты, чем с простым image_to_string. Адаптивная пороговая обработка дает выходное изображение, которое кажется не таким уж плохим, но tesseract не может его прочитать.
импорт cv2 как cv импортировать numpy как np из matplotlib импортировать pyplot как plt импортировать питессеракт pytesseract.pytesseract.tesseract_cmd = r"C:\Program Files\Tesseract-OCR\tesseract" img = cv.imread(r"C:\Users\user\Desktop\test_pcs\new2\2022-10-30_14-49-30.jpg",0) изображение = cv.