
Работа с текстом – Распознавание текста и речи
Главная > Каталог программ > Работа с текстом > Распознавание текста и речи
Сервис для автоматической загрузки первичной документации в 1С
Программа для распознавания текста, разработанная специально для Mac OS X, переводит изображения документов и любые типы PDF-файлов в электронные редактируемые форматы.
Универсальное решение для работы с бумажными и PDF-документами, которое сочетает в себе лидирующие технологии распознавания и нужные инструменты для работы с различными типами PDF.

Readiris Pro 17 – это программное обеспечение для оптического распознавания символов (OCR), которая преобразует изображение, файл PDF или отсканированный документ в полностью редактируемый текстовый файл. Благодаря мощности и точности распознающих технологий, Readiris Pro распознает текст из документов с высокой скоростью и точностью, сохраняя структуру исх…
Программа для распознавания текста, которая переводит изображения документов и любые типы PDF-файлов в электронные редактируемые форматы.
Программа для сканирования документов и распознавания текста. Позволяет получать электронные версии документов при помощи сканера, одновременно уменьшая размер без потери информационного качества.
Программа предназначена для обработки файлов растровых изображений, в первую очередь сканов документов. Обработка возможна как в пакетном режиме, когда обрабатывается набор изображений с одними настройками, так и индивидуально, когда обработка настраивается и применяется к отдельным изображениям.
Эффективный серверный OCR (оптическое распознавание символов) инструмент, предназначенный для автоматической конвертации большого количества сканированных, а также цифровых файлов в однотипные, стандартные документы с функцией поиска.
 Частота основного тона (ЧОТ) – наиболее информативная из них. Именинно она измеряется в нашей программе в режиме мягкого реального времени (с задержкой не более 1-2 сек.) для выявления фальши (false) в речевом сигнале от вашего собеседника.
Программа создана в двух версиях: психокоррекционного тренажера (версия 1.0), а также в версии 2.0 – для работы в двух разных режимах: бесконтактного (фонетического) детектора лжи и автоматического тестера качества речевого сигнала.
Частота основного тона (ЧОТ) – наиболее информативная из них. Именинно она измеряется в нашей программе в режиме мягкого реального времени (с задержкой не более 1-2 сек.) для выявления фальши (false) в речевом сигнале от вашего собеседника.
Программа создана в двух версиях: психокоррекционного тренажера (версия 1.0), а также в версии 2.0 – для работы в двух разных режимах: бесконтактного (фонетического) детектора лжи и автоматического тестера качества речевого сигнала.Легкое, быстрое и не перегруженное массой ненужных функций программное обеспечение для сканирования. Точная настройка параметров сканирования, копирование документов в один клик.
Бессрочная лицензия, идет как модуль расширения для BIQE. При установлении данного формата в качестве экспортного, программа на этапе экспорта распознает документ с использованием Tesseract.

Пакет позволяет управлять сканированием планетарных сканеров на базе Canon EOS DSLR.
Пакет поддержки сканирования устройств Image Access.
Вы работаете с людьми, и поэтому на вашем рабочем месте всегда существует опасность разного рода конфликтов: от претензий клиентов к качеству вашей работы до срыва партнерами ваших договоренностей. В этих условиях вам необходим свидетель, включаемый в действие в любой необходимый (по ситуации) момент времени. Программа VOICE CONTROLLER призвана решить данную проблему в жизни каждого из нас на основе управляемой пользователем скрытной аудиозаписи коротких (3-5 мин.) отрезков его переговоров.
Программа для распознавания текста из pdf формата в файл word, а так же с картинки
Часто требуется перевести изображение, фотографию или отсканированный файл в формат текста, в который можно вносить исправления.
Программы для распознавания текста необходимы пользователям
Abbyy Finereader
Abbyy Finereader – популярная программа для распознания текста и сохранения его в любом формате. Помимо своих главных функций она имеет массу дополнительных характеристик и преимуществ перед аналогичным софтом.
Преимущества и возможности программы
- возможность распознать текст из pdf формата в файл word,
- распознавание текста с фотографии, отсканированного файла или электронной книги,
- возможность сканировать документы и улучшать их качество перед распознаванием,
- перевод изображений, pdf фалов, снимков с камеры в другие форматы,
- поддержка многоязычного языкового пакета (более 42),
- сохранение форматирования в конечном вордовском документе,
- возможность машинного перевода с более, чем 30 мировых языков,
- экспорт по вашему желанию в любое из облачных хранилищ в интернете,
- направление копии документа в один из популярных редакторов, среди которых не только MSWord и MS Excel, но и Org Writer, PowerPoint, WordPerfekt, OpenOffice и Adobe Acrobat.

- высокая скорость работы и большие возможности редактирования файла непосредственно в рамках Abbyy Finereader.
Как пользоваться Abby Finereader
Abbyy Finereader прекрасный рапознаватель текста с картинки, даже если она плохого качества. Эта программ обладает интуитивно понятным интерфейсом, а многие её процессы проходят в автоматическом режиме. Давайте на несложном примере рассмотрим, как перевести картинку в текст:
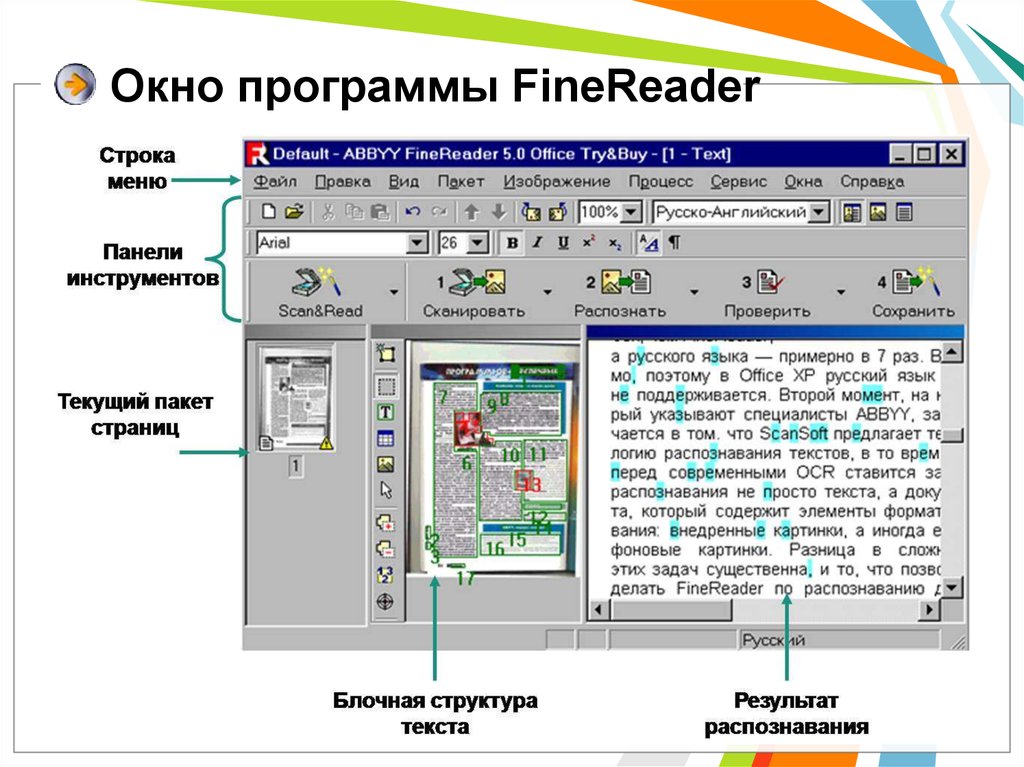
- Запускаем программу. Перед нами открывается такое окно.
- Затем нажимаем под меню кнопку Открыть. Она выводит на экран окошко, в котором мы и находим нужную картинку.
Выбираем файл и нажимаем кнопку Открыть в его нижнем правом углу. Перетащите в окно программы нужный объект, удерживая левую кнопку мыши. Вот так выглядит окно программы после открытия файла.
Нажимаем кнопку Закрыть и видим, что слева расположена зона эскизов загруженных страниц файла (у нас это одна картинка).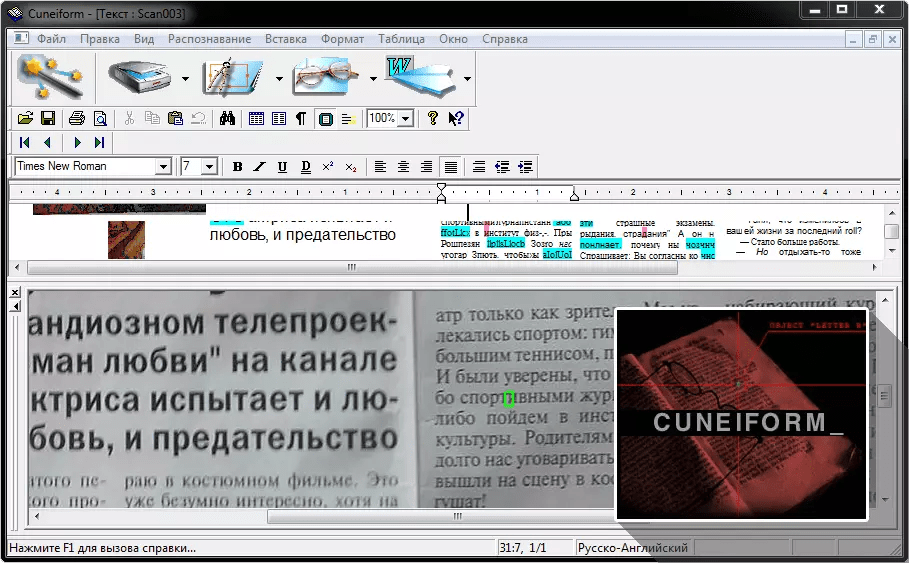 В центре — само изображение, в котором уже выделены зоны распознаваемого содержимого, а справа – сам текст.
В центре — само изображение, в котором уже выделены зоны распознаваемого содержимого, а справа – сам текст.
Чтобы перевести картинку в формат Word нужно нажать кнопку Распознать, расположенную, как и кнопка Открыть, под главным меню. После этого вы увидеть диалоговое окно, отражающее ход распознания. Большие объёмы занимают много времени – от 10 минут до получаса. Единичная картинка не отнимет более 2-5 минут.
Чтобы сохранить информацию в формат Word, нажмите кнопку Сохранить с вордовским значком, которая находится справа от кнопки Распознать. Так выглядит новое окно, которое перед вами появится
- Выбирайте место сохранения и имя нового файла, после чего жмите кнопку Сохранить. Вордовский документ с распознанной информацией и картинками появится у вас на экране. Также происходит распознавание текста в PDF, с той лишь разницей, что полученный результат вы можете сохранить в один документ или каждую страницу в отдельный.
Совет.
Есть ещё один путь перевода файла из формата изображения или PDF –файла в вордовский документ. Для этого при запуске программы выберите в открывшемся окне команду Сканировать в MS Word или PDF или изображение в MS Word. При этом часть операций выполнится в автоматическом режиме, а вы получите готовый результат намного проще и быстрее.
Стоит отметить, что программа не бесплатна. Она требует регистрации. Но при необходимости используйте ABBYY Fine Reader Online без регистрации и бесплатно. Это сэкономит и деньги, если перевод информации из картинки в текст вы делаете редко, и время. Интерфейс в этом режиме очень похож на обычную программу и не вызовет у пользователя затруднений. Да и перевести информацию из картинки в текст online вы сможете на любом компьютере и в любое время.
CuneiForm
CuneiForm – удобная и простая в использовании программа для распознавания текста при сканировании. У неё очень простой интерфейс, большой набор функций. При этом она распространяется абсолютно бесплатно, что не может не радовать пользователей.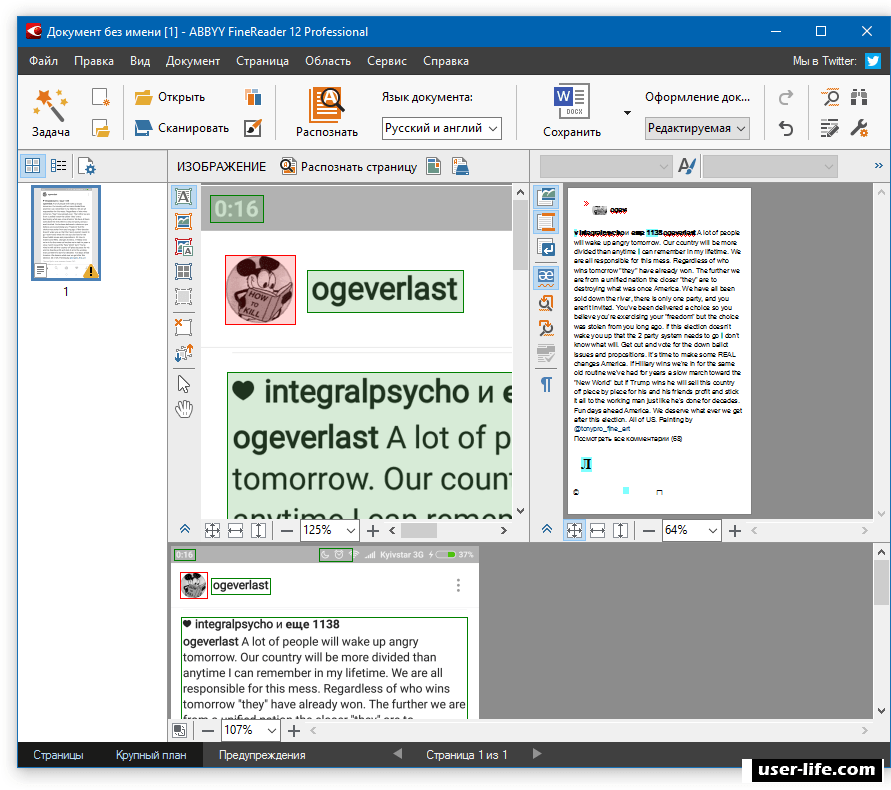
Функционал программы
- возможность распознавать текст более, чем на 20 языках мира,
- работа с различными печатными шрифтами и символами,
- восстановление текста с изображений плохого качества,
- качественное распознание таблиц и списков, сносок и индексов,
- встроенный электронный словарь слов,
- проверка орфографических ошибок,
- распознание текста с фотографии и сохранение его в формат *.txt или *.rtf,
- сохранение форматирования.
Хотя с CuneiForm можно работать с любым изображением, находящимся на компьютере или на съёмном носителе, это всё-таки программа для распознавания текста со сканера. Она открывает перед пользователем широкие перспективы и упрощает работу.
Как пользоваться CuneiForm
Пользоваться CuneiForm легко. Давайте попробуем распознать текст с картинки, которую мы уже использовали сегодня:
- Откройте программу. Перед вами покажется такое главное окно, которое выглядит так
- Выберите команду Файл, а затем Открыть и в появившемся окне найдите картинку или PDF-файл.
Под главным меню нажмите кнопку Распознание. Картинка трансформируется в текст
Теперь, после того, как у вас получилось распознать текст с картинки, его можно сохранить. Для этого нажмите кнопку Сохранить рядом с кнопкой Распознание под главным меню. Вы увидите окно
- Выбирайте нужное место и название файла и жмите кнопку Сохранить. Вот так будет выглядеть полученный файл.
Как видите, хотя программы выдала не такой красивый результат, как получилось у Abbyy Finereader, текст распознался полностью и не содержит непонятных символов или других включений. Его можно сохранить в файл, формат которого вы выберете на своё усмотрение.
Microsoft OneNote
Microsoft OneNote – ещё одна полезная программа для распознавания текста с картинки. Использовать её просто и удобно. Если вы её как следует изучите, то найдёте себе хорошего помощника, обладающего массой полезных функций.
Возможности программы
- автоматическое сохранение информации,
- возможность форматирования текста, добавление списков и оформления без обращения к другому редактору,
- улучшенный алгоритм снятия скриншотов открытого окна,
- добавление информации в файл непосредственно из интернета в режиме онлайн,
- удобство перехода между вложенными страницами,
- закрепление на рабочем столе и создание ссылок внутри файла,
Как вы уже поняли, Microsoft OneNote – это полноценный текстовый редактор с огромным количеством функций. Меню программы похоже на MS Word и MS Exel, поэтому подробно рассматривать как распознать текст в Microsoft OneNote и сохранить мы не будем. Качество при этом ничем не уступает двум предыдущим редакторам.
Меню программы похоже на MS Word и MS Exel, поэтому подробно рассматривать как распознать текст в Microsoft OneNote и сохранить мы не будем. Качество при этом ничем не уступает двум предыдущим редакторам.
OmniPage Ultimate, OmniPage 18
OmniPage – ещё одна популярная программа для считывания текста с картинки. Версия OmniPage Ultimate – наиболее полная и расширенная. Она, как и Abbyy Finereader, не коммерческий продукт и не распространяется бесплатно. Версия программы OmniPage 18 также платная и обладает похожим функционалом. Тем не менее, с поставленной задачей она также справляется.
Возможности программы
- точность распознавания текста,
- работа с разными языками,
- широкий выбор встроенных словарей, распознающий даже узкие специальные термины,
- возможность распознать текст с картинки в Word и MS Exel,
- расширенный функционал распознания текста и вывода страниц,
- работа с разными форматами, в том числе и PDF,
- распознание текста на изображениях разного качества,
- сохранение форматирования и фиксирование колонтитулов,
- создание аудиодокументов из других электронных форматов,
- расшифровка иероглифов и специфических символов.

По внешнему виду OmniPage 18 и Ultimate похожа на Abbyy Fine reader. Единственное, что отличается, кнопки под меню у неё не такие крупные. То же окно с эскизами открытых страниц слева и окна с картинкой и распознанным текстом. Поэтому, если вам знакома программа Finereader, то воспользоваться OmniPage не будет сложным.
Другие способы распознания текста
Есть ещё немалое количество программ, которые помогут вам распознать текст с любого изображения или файла PDF. Их можно скачать и установить бесплатно. Среди них популярны такие, как:
- Top OCR. Преимущество этого софта перед другими программами этого класса – возможность озвучивания распознанного текста и запись в файл mp3.
- RiDoc. Функционал утилиты уже в сравнении с Abbyy Finereader, но скорость её работы с подключенным сканером и принтером высокая, а качество текста на выходе также полностью удовлетворяет пользователей.
- Capture text. Она разрешает не распознавать весь документ, а выделить только нужный фрагмент текста.

- Readiris. Это бесплатный аналог Finereader, который справляется с поставленными ему задачами сканирования текста, распознавания и сохранение в файл нужного расширения.
ПОСМОТРЕТЬ ВИДЕО
Это далеко не полный перечень возможных способов распознания текста и его сохранения, в том числе и в MS Word. Каждый пользователь выбирает подходящую ему утилиту. Программа Abbyy Finereader – признанный фаворит среди подобных программ с большим набором функций для работы с текстом не бесплатна. Поэтому пользователи вместо неё, желая сэкономить, скачивают бесплатные аналоги с интернета, работающие не хуже, хоть и узки в наборе функций.
Распознавание текста с помощью OCR / Хабр
Tesseract — это движок оптического распознавания символов (OCR) с открытым исходным кодом, является самой популярной и качественной OCR-библиотекой.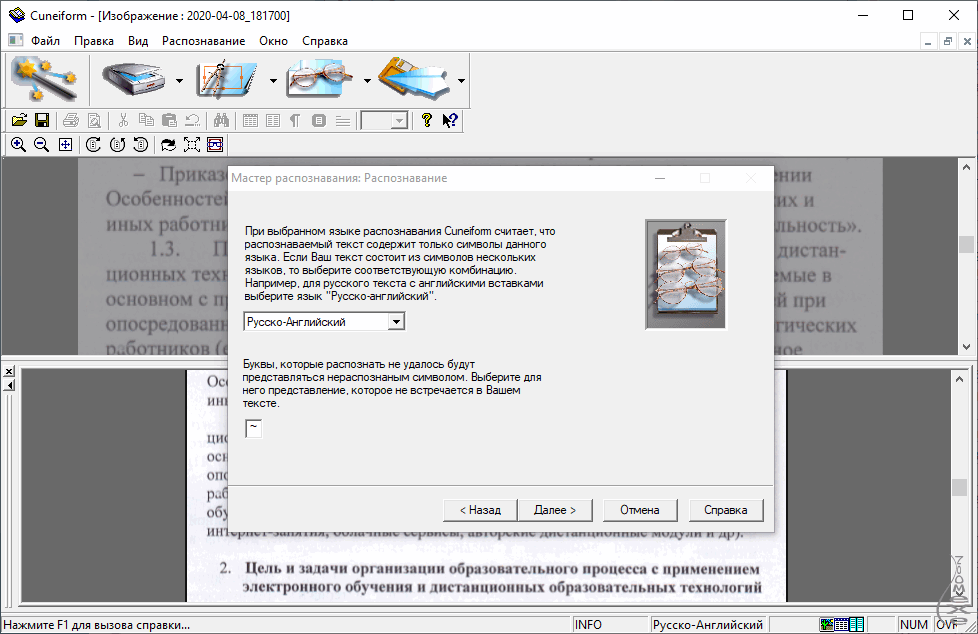
OCR использует нейронные сети для поиска и распознавания текста на изображениях.
Tesseract ищет шаблоны в пикселях, буквах, словах и предложениях, использует двухэтапный подход, называемый адаптивным распознаванием. Требуется один проход по данным для распознавания символов, затем второй проход, чтобы заполнить любые буквы, в которых он не был уверен, буквами, которые, скорее всего, соответствуют данному слову или контексту предложения.
На одном из проектов стояла задача распознать чеки с фотографий.
Инструментом для распознавания был использован Tesseract OCR. Плюсами данной библиотеки можно отметить обученные языковые модели (>192), разные виды распознавания (изображение как слово, блок текста, вертикальный текст), легкая настройка. Так как Tesseract OCR написан на языке C++, был использован сторонний wrapper c github.
Различиями между версиями являются разные обученные модели (версия 4 имеет большую точность, поэтому мы использовали её).
Нам потребуются файлы с данными для распознавания текста, для каждого языка свой файл. Скачать данные можно по ссылке.
Скачать данные можно по ссылке.
Чем лучше качество исходного изображения (имеют значение размер, контрастность, освещение), тем лучше получается результат распознавания.
Также был найден способ обработки изображения для его дальнейшего распознавания путем использования библиотеки OpenCV. Так как OpenCV написан на языке C++, и не существует оптимального для нашего решения написанного wrapper’а, было решено написать собственный wrapper для этой библиотеки с необходимыми для нас функциями обработки изображения. Основной сложностью является подбор значений для фильтра для корректной обработки изображения. Также есть возможность нахождения контуров чеков/текста, но не изучено до конца. Результат получился лучше (на 5-10%).
Параметры:
language — язык текста с картинки, можно выбрать несколько путем их перечисления через “+”;
pageSegmentationMode — тип расположения текста на картинке;
charBlacklist — символы, которые будут игнорироваться ignoring characters.
Использование только Tesseract дало точность ~70% при идеальном изображении, при плохом освещении/качестве картинки точность была ~30%.
Vision + Tesseract OCR
Так как результат был неудовлетворителен, было решено использовать библиотеку от Apple — Vision. Мы использовали Vision для нахождения блоков текста, дальнейшего разделения изображения на отдельные блоки и их распознавания. Результат был лучше на ~5%, но и появлялись ошибки из-за повторяющихся блоков.
Недостатками этого решения были:
- Скорость работы. Скорость работы уменьшилась >4 раза (возможно, существует вариант распоточивания)
- Некоторые блоки текста распознавались более 1 раза
- Текст распознается справа налево, из-за чего текст с правой части чека распознавался раньше, чем текст слева.
MLKit
Еще одним из методов определения текста является MLKit от Google, развернутый на Firebase. Данный метод показал наилучшие результаты (~90%), но главным недостатком этого метода является поддержка только латинских символов и сложная обработка разделенного текста в одной строке (наименование — слева, цена — справа).
В итоге можно сказать, что распознать текст на изображениях — задача выполнимая, но есть некоторые трудности. Основной проблемой является качество (размер, освещенность, контрастность) изображения, которую можно решить путем фильтрации изображения. При распознавании текста при помощи Vision или MLKit были проблемы с неверным порядком распознавания текста, обработкой разделенного текста.
Распознанный текст может быть в ручную откорректирован и пригоден к использованию; в большинстве случаев при распознавании текста с чеков итоговая сумма распознается хорошо и не нуждается в корректировках.
Лучшие инструменты OCR для распознавания текста
Допустим, у вас есть книга, и вы хотите отредактировать ее на своем компьютере. Что ты будешь делать? Вручную напишете? Очевидно нет. Вы его отсканируете. Но отсканированный документ по-прежнему является изображением, и вы не можете его редактировать.
Существует технология, которая поможет вам выполнить эту задачу, известную как оптическое распознавание символов (OCR). Его инструменты извлекают текст из изображения и преобразуют его в формат, доступный для редактирования на компьютере. По этой причине мы предоставляем вам лучшие инструменты OCR для распознавания текста.
Его инструменты извлекают текст из изображения и преобразуют его в формат, доступный для редактирования на компьютере. По этой причине мы предоставляем вам лучшие инструменты OCR для распознавания текста.
OCR работает как человеческий мозг. Мы распознаем распознаваемые буквы, символы, числа, знаки препинания и преобразуем их в предложения. Точно так же OCR распознает буквы, символы, числа, знаки препинания и преобразует их в текст, доступный для машинного редактирования. Изображение представляет собой пиксельный узор, но инструменты распознавания текста помогают преобразовать его в файлы doc или txt. Вы можете редактировать преобразованный текст с помощью других программ, таких как MS Office. Чтобы прояснить функцию OCR, мы можем сказать, что это пять основных причин, по которым вам необходимо программное обеспечение OCR:
- Избегать повторного набора
- Редактировать печатный текст
- Быстрый цифровой поиск
- Освободить место: файлы в шкафах не нужно
- Быстрый доступ к информации
Какой инструмент оптического распознавания текста лучше выбрать?
Бесплатное распознавание текста в Word Free OCR to Word входит в число лучших программ OCR для настольных ПК. Он поддерживает широкий спектр форматов изображений и преобразует их в редактируемый текст. Он имеет удобный интерфейс, который обеспечивает быстрый доступ ко всем его функциям. Лучшее в этом инструменте – то, что он предоставляет вам возможность конвертировать изображения и напрямую конвертировать их с помощью сканера.
Он поддерживает широкий спектр форматов изображений и преобразует их в редактируемый текст. Он имеет удобный интерфейс, который обеспечивает быстрый доступ ко всем его функциям. Лучшее в этом инструменте – то, что он предоставляет вам возможность конвертировать изображения и напрямую конвертировать их с помощью сканера.
Вам не нужно беспокоиться о том, какой сканер выбрать. Хорошо работает со всеми производителями. После преобразования он отобразит текст в правой части окна. После этого текст можно сохранить.Точность содержания зависит от состояния файла изображения. Если вас не устраивает результат, вы можете нажать кнопку «Очистить текст» и восстановить его. Выполните следующие действия, чтобы преобразовать файл:
Шаг 1: Загрузите «Бесплатное распознавание текста в Word» с официального сайта и установите его на свой компьютер.
Шаг 2: Выберите файл. Функция «Открыть» позволяет вам выбрать файл на вашем компьютере, который уже там сохранен. А опция «Сканировать» позволяет сканировать документ напрямую с помощью сканера.
А опция «Сканировать» позволяет сканировать документ напрямую с помощью сканера.
Шаг 3: Теперь нажмите кнопку преобразования.
Шаг 4: Бесплатное распознавание текста в Word займет всего несколько секунд, чтобы преобразовать ваш файл. После преобразования вы можете скопировать текст и вставить его в другие файлы с поддержкой Word.
FreeOCR Многие люди думают, что «FreeOCR» и «Бесплатное распознавание текста в Word» – это одни и те же инструменты. Но это неправда. Оба они представляют собой разные настольные программы, используемые для преобразования изображения в текст. FreeOCR входит в число легких программ, представленных Tesseract Engine.Он известен тем, что его разработала всемирно известная компания HP Lab, и теперь он поддерживается Google. Этот инструмент может конвертировать одно изображение за раз, но после преобразования изображения в PDF вы можете конвертировать неограниченное количество изображений за раз.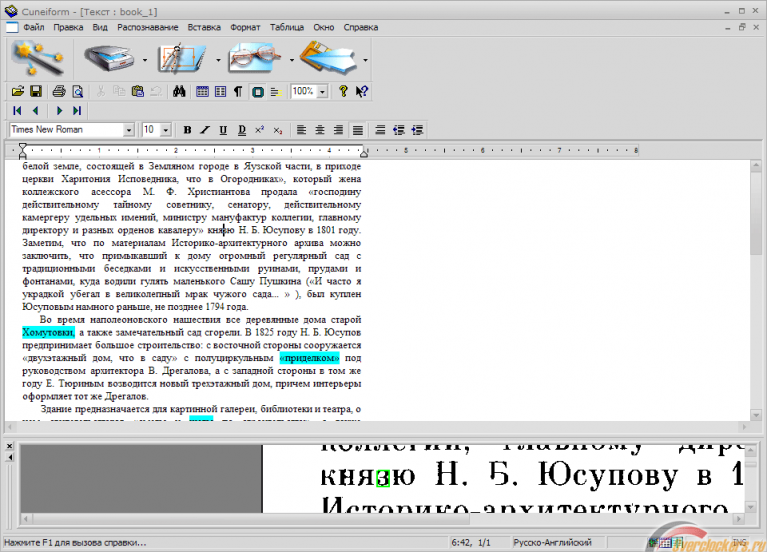
Кроме того, с помощью зашифрованного чата можно защитить все ваши файлы и уберечь их от хакеров.
FreeOCR предоставляет вам простой текст и не соответствует формату исходного файла. Как бесплатный инструмент, он может выполнять только простые функции, такие как поворот и масштабирование.Тем не менее, точность результата отличная. Для преобразования файла вам необходимо выполнить следующие действия:
Шаг 1: Загрузите и установите FreeOCR. Вы должны получить этот инструмент с официального сайта.
Шаг 2: Выберите файл, который хотите преобразовать. Если вы хотите избежать проблем с макетом, обрежьте изображение и выберите конкретную область.
Шаг 3: Он поддерживает 11 языков, поэтому выберите язык.
Шаг 4: Теперь нажмите кнопку «Конвертировать».
Шаг 5: Загрузите файл и отредактируйте его в MS Word или WordPad.
onlineconvertfree.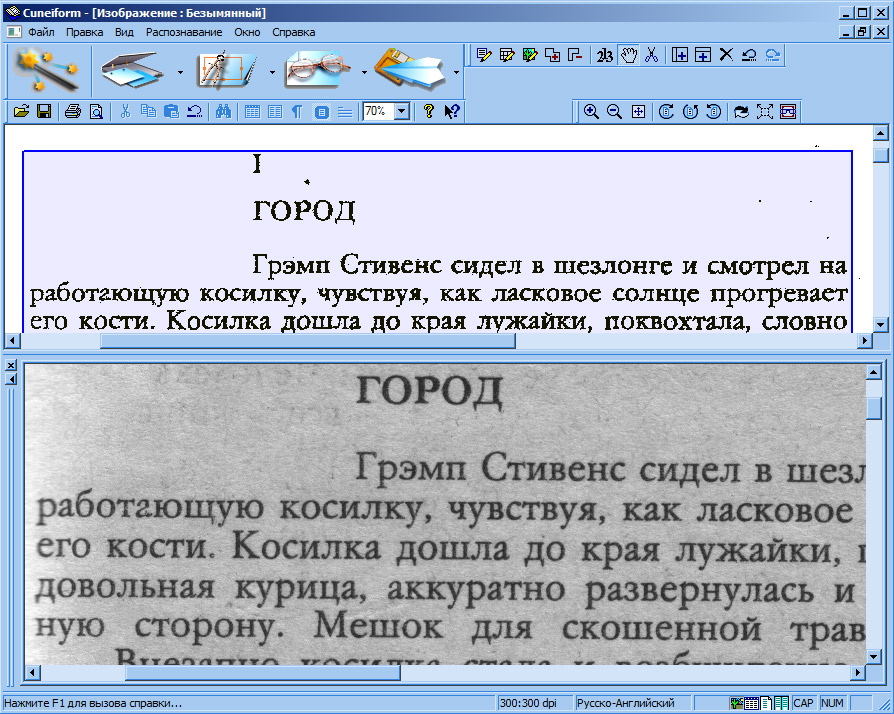 com
com Он входит в число лучших бесплатных онлайн-конвертеров, поддерживающих несколько форматов и языков. Его функции OCR работают сверхбыстро и обеспечивают точные результаты. Кроме того, это блестящие онлайн-инструменты распознавания текста, он известен преобразованием аудио, книг, видео, изображений и архивов. Самое лучшее в onlineconvertfree.com – это то, что он может конвертировать несколько файлов за раз.Он помогает конвертировать отсканированные изображения и документы в редактируемые форматы вывода Excel, PDF, Word и Txt. Для преобразования файла вы должны выполнить следующие действия:
Шаг 1: Перейдите на официальную веб-страницу, щелкнув эту ссылку: https://onlineconvertfree.com/ocr/
Шаг 2: Загрузите файлы для распознавания или перетащите их на эту страницу.
Шаг 3: После выбора одного изображения вы можете нажать кнопку «Добавить файлы» и выбрать несколько файлов одновременно.
Шаг 4: Выберите язык и формат вывода и нажмите кнопку «Распознать».
Шаг 5: После анализа изображения он преобразует ваш файл. Теперь прокрутите вниз и нажмите кнопку конвертировать.
Итог
Мы обсудили 3 лучших инструмента распознавания текста для распознавания текста. Используя эти конвертеры (два офлайн и один онлайн), вы можете конвертировать изображение в текст или текст в изображение. Выберите тот, который вам нужен, и сэкономьте свое время и деньги.
Создайте собственное OCR (оптическое распознавание символов) бесплатно | by Balaaji Parthasarathy
Оптическое распознавание символов , или OCR, – это технология, которая позволяет конвертировать различные типы документов, такие как отсканированные бумажные документы, файлы PDF или изображения, снятые цифровой камерой, в редактируемые и доступные для поиска данные. Он преобразует эти документы в машинно-кодированный текст.
Оптическое распознавание текста набирает популярность в последнее время, и возможность распознавания того, что присутствует на изображении, открывает новые горизонты возможностей.
За последние несколько лет фреймворки OCR сильно изменились, но не до такой степени, чтобы они могли быть на 100% для любого размера изображения или любого качества изображения.
Для того, чтобы приблизиться к 100%, требуется большая настройка и обучение. Прежде чем можно будет получить наиболее точную информацию, необходимо провести много предварительной обработки.
Существует множество доступных программ / API, которые могут неплохо справиться с обработкой изображения, и в зависимости от того, что они могут делать и насколько хорошо они справляются, цены различаются.
Давайте рассмотрим некоторые из них подробнее.
Оптическое распознавание текста набирает популярность в последнее время, и возможность распознавания того, что присутствует на изображении, открывает новые горизонты возможностей.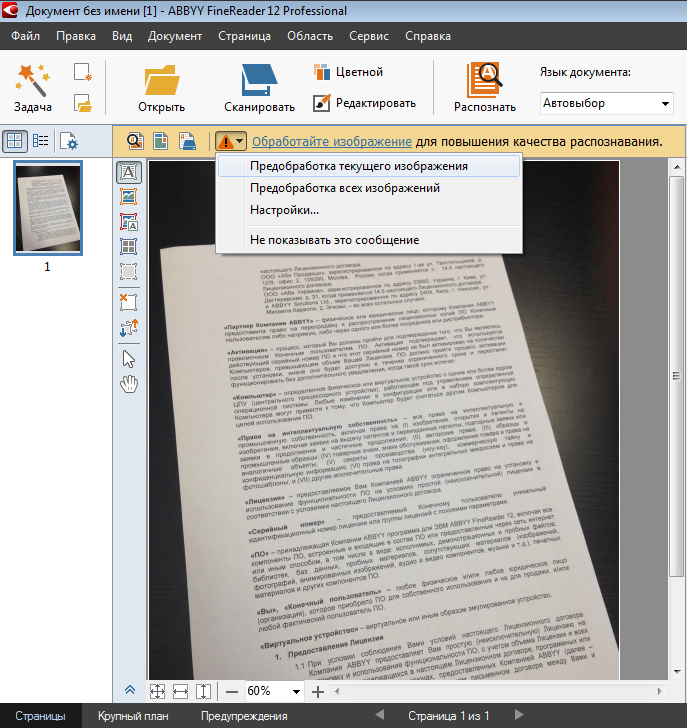
За последние несколько лет фреймворки OCR сильно изменились, но не до такой степени, чтобы они могли быть на 100% для любого размера изображения или любого качества изображения.
Для того, чтобы приблизиться к 100%, требуется большая настройка и обучение. Прежде чем можно будет получить наиболее точную информацию, необходимо провести много предварительной обработки.
Существует множество доступных программ / API, которые могут неплохо справиться с обработкой изображения, и в зависимости от того, что они могут делать и насколько хорошо они справляются, цены различаются.
Давайте рассмотрим некоторые из них подробнее.
API Google Vision ( https://cloud.google.com/vision/ ) – один из самых популярных доступных API-интерфейсов, предоставляющий наиболее точную информацию. Vision API – это скорее среда обработки изображений, чем просто среда оптического распознавания символов.Если цель состоит в том, чтобы просто определить, какие символы присутствуют на изображении, эта структура имеет гораздо больше возможностей. Этот фреймворк действительно дорог, если только ваш базовый набор изображений не несколько.
Этот фреймворк действительно дорог, если только ваш базовый набор изображений не несколько.
Ниже приводится информация о ценах.
https://cloud.google.com/vision/pricing
Amazon Rekognition (https://aws.amazon.com/rekognition/) снова представляет собой среду обработки изображений, аналогичную Google Vision API. использует технологию глубокого обучения для идентификации объектов, изображений и лиц.Это немного дешевле, чем Vision API.
Ниже приводится информация о ценах.
https://aws.amazon.com/rekognition/pricing/
OCR Space (https://ocr.space/) является более экономичным вариантом по сравнению с первыми двумя вариантами. Этот SDK отлично справляется с получением необходимой информации, но не до уровня Rekognition и Vision API. Если ваше требование составляет менее 25 000 запросов в месяц, вы даже можете уйти бесплатно.
Ниже приводится информация о ценах.
https://ocr.space/ocrapi
Есть несколько фреймворков с открытым исходным кодом, которые можно использовать для создания фреймворка OCR самостоятельно. Они тоже эффективны, если вы знаете, как обучить их вашим требованиям. Ниже перечислены несколько таких фреймворков.
Они тоже эффективны, если вы знаете, как обучить их вашим требованиям. Ниже перечислены несколько таких фреймворков.
Python pyocr
PyOCR (https://github.com/jflesch/pyocr) – это оболочка инструмента оптического распознавания символов (OCR) для Python. То есть помогает использовать инструменты OCR из программы Python. Он был протестирован только в системах GNU / Linux.Он также должен работать в аналогичных системах (* BSD и т. Д.). Он может работать или не работать в Windows, MacOSX и т. Д.
PyOCR можно использовать в качестве оболочки для Google Tesseract-OCR или Cuneiform. Он может читать все типы изображений, поддерживаемые Pillow, включая jpeg, png, gif, bmp, tiff и другие. Он также поддерживает данные ограничивающей рамки.
Tesseract-OCR
Tesseract – это средство оптического распознавания символов для различных операционных систем. Это бесплатное программное обеспечение, выпущенное под лицензией Apache License, Version 2. 0, и изначально был разработан в Hewlett-Packard Laboratories Bristol и Hewlett-Packard Co, Грили Колорадо в период с 1985 по 1994 год, с некоторыми дополнительными изменениями, внесенными в 1996 году для переноса на Windows, и некоторыми изменениями на C ++ в 1998 году. В 2005 году Tesseract был открыт HP. Позже он был разработан и спонсирован Google с 2006 года. Tesseract считается одним из наиболее точных движков OCR с открытым исходным кодом, доступных в настоящее время.
0, и изначально был разработан в Hewlett-Packard Laboratories Bristol и Hewlett-Packard Co, Грили Колорадо в период с 1985 по 1994 год, с некоторыми дополнительными изменениями, внесенными в 1996 году для переноса на Windows, и некоторыми изменениями на C ++ в 1998 году. В 2005 году Tesseract был открыт HP. Позже он был разработан и спонсирован Google с 2006 года. Tesseract считается одним из наиболее точных движков OCR с открытым исходным кодом, доступных в настоящее время.
Было не так много вариантов с открытым исходным кодом для самостоятельной сборки.В этом документе мы подробно рассмотрим структуру Tesseract и то, как ее настроить, и насколько хорошими или плохими будут результаты.
Большинство фреймворков OCR, вероятно, построено на основе Tesseract, и это самый популярный среди множества фреймворков, дающий довольно хорошие результаты.
Tesseract поддерживает множество языков, как никакой другой фреймворк. Он поддерживает английский, испанский, тайский и тамильский, узбекский и идиш. Будет сложно найти то, что не поддерживается.
Будет сложно найти то, что не поддерживается.
Обзор
Процесс OCR
Архитектура машинного уровня
В этом упражнении я использую Dockerized Java Spring – загрузочное приложение со сборкой Gradle.
Необходимо добавить зависимость Gradle для Tesseract, Leptonica, JMagick и Im4Java. Давайте немного обсудим, что это за зависимости
{
группа компиляции: 'org.bytedeco.javacpp-presets', имя: 'tesseract', версия: '3.03-rc1-1.0 '
группа компиляции:' org.bytedeco.javacpp-presets ', имя:' tesseract ', версия:' 3.03-rc1-1.0 ', классификатор: opencvBinaryClassifer
группа компиляции:' org.bytedeco.javacpp-presets ', имя:' leptonica ', версия:' 1.72-1.0 ', классификатор: opencvBinaryClassifer
группа компиляции:' jmagick ', имя:' jmagick ', версия:' 6.6.9 '
группа компиляции: 'org.im4java', имя: 'im4java', версия: '1.4.0'
}
- Tesseract -CPP Preset – это оболочка Java для Tesseract, которая является построен на основе CPP.
- Leptonica – это зависимость от Tesseract, благодаря которой мы получаем поддержку нескольких форматов изображений. Он также получает информацию о положении и макете страницы.
- JMagick – JMagick – это Java-интерфейс для ImageMagick C-API.
- Im4Java – это оболочка Java для ImageMagick. Это запускает команды ImageMagic из командной строки с помощью Java Process Builder.
Нам также необходимо убедиться, что на нашем компьютере установлена программа ImageMagick. Это легко сделать с помощью варева.
- brew install imagemagick
- brew info imagemagick – мы можем запустить эту команду, чтобы убедиться, что установка прошла успешно.
На этом вы закончили настройку и теперь можете начинать кодирование.
Как повысить эффективность вывода с помощью тессеракта?
- Чтобы Tesseract работал наилучшим образом, вы должны убедиться, что изображение максимально четкое.

- Это может означать, что нам придется выполнять модификации изображения, такие как изменение размера, цветовое пространство, контраст, морфология, фильтр (по Гауссу, треугольнику, сплайну и т. Д.), Обнаружение краев.
- По этой причине мы будем использовать JMagick, который имеет множество функций, которые используют ImageMagick под кожей для выполнения модификации изображений.
- Вот несколько полезных ссылок для выполнения модификации изображения
http://www.fmwconcepts.com/imagemagick/downsize/index.php
http://www.imagemagick.org/script/index.php
- Ниже приведены примеры изображений того, что это было и каким должно быть Tesseract, чтобы понимать и выполнять распознавание текста.
Вы можете столкнуться с обстоятельствами, когда Tesseract не распознает ответ со всем текстом, отображаемым на изображении. Это может быть связано с тем, что Tesseract не был запрограммирован на понимание шрифта на изображении. По этой причине становится обязательным идентифицировать шрифт, устанавливать и создавать файлы обученных данных для необходимых шрифтов.
По этой причине становится обязательным идентифицировать шрифт, устанавливать и создавать файлы обученных данных для необходимых шрифтов.
Ниже приведены шаги для достижения того же
- Установите Tesseract на машину
brew install – with-training-tools tesseract
- Загрузите и установите JTessBox Editor
https: / / sourceforge.net / projects / vietocr /? source = typ_redirect
- Определите шрифт в изображении и установите его в системе.
- Откройте редактор JTessBox, выберите нужный шрифт и введите предложение со всеми необходимыми символами.
- Если щелкнуть «Создать», будут созданы файлы .box и .tif.
- Теперь обновите имя шрифта в приведенном ниже коде и запустите скрипт python, используя следующую команду
- python tesseract-trainer.py
Python Tesseract Script Expand source
- После успешного запуска скрипта python он сгенерирует множество файлов и добавит то же самое в устанавливаемый тессеракт.
 Хотя вам нужно будет скопировать их и добавить в папку tessdata в вашем проекте.
Хотя вам нужно будет скопировать их и добавить в папку tessdata в вашем проекте.
Полезные ссылки:
http://scholarworks.sjsu.edu/cgi/viewcontent.cgi?article=1416&context=etd_projects
https://en.wikipedia.org/wiki/Tesseract
http : //im4java.sourceforge.net/
https://www.smashingmagazine.com/2015/06/efficient-image-resizing-with-imagemagick/
https://github.com/tesseract-ocr/tesseract / wiki / APIExample
http: // www.programcreek.com/java-api-examples/index.php?api=org.im4java.core.ConvertCmd
http://im4java.sourceforge.net/docs/dev-guide.html
https: // medium. com/@sathishvj/training-tesseract-ocr-for-a-new-font-and-input-set-on-mac-7622478cd3a1#.ju5p3mv47
Лучшее программное обеспечение для оптического распознавания символов – Распознавание текста и рукописного ввода
Оптический символ Распознавание (OCR)
OCR – это процесс извлечения слов (и, возможно, информации о макете и форматировании) из файлов изображений, таких как факсы и PDF-файлы, прикрепленных к электронным письмам, и преобразования их в текст.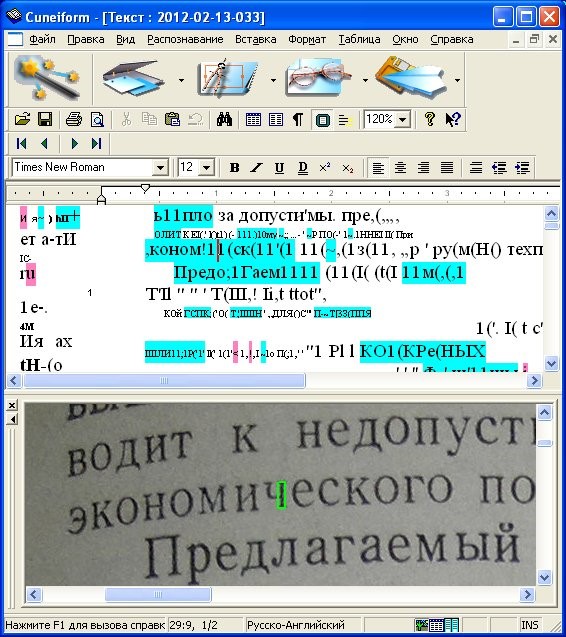 После того, как изображение было отсканировано на компьютер, программа OCR переводит текстовые изображения в реальный текст, который компьютер может прочитать. OCR лучше всего работает с печатным текстом либо в случаях, когда исходная распечатка отсутствует, либо при сканировании распечатанных или машинописных листов.
После того, как изображение было отсканировано на компьютер, программа OCR переводит текстовые изображения в реальный текст, который компьютер может прочитать. OCR лучше всего работает с печатным текстом либо в случаях, когда исходная распечатка отсутствует, либо при сканировании распечатанных или машинописных листов.
Оптическое распознавание меток (OMR)
В процессе OMR оптический считыватель меток обнаруживает метки на отсканированном бланке. Программное обеспечение OMR – это компьютерное приложение, которое использует сканер изображений для обработки опросов, ведомостей посещаемости, тестов, контрольных списков и других печатных форм.Программное обеспечение OMR – это высоконадежный и специализированный метод точного чтения и сканирования данных.
Распознавание штрих-кода
Штрих-код представляет символы в виде наборов параллельных полос различной толщины и разделения, которые считываются оптически при поперечном сканировании. Программное обеспечение для распознавания штрих-кодов автоматически обнаруживает и декодирует популярные типы штрих-кодов в любом направлении на отсканированных документах. Программное обеспечение собирает данные о продуктах и клиентах, сохраняя их на вашем компьютере.
Программное обеспечение для распознавания штрих-кодов автоматически обнаруживает и декодирует популярные типы штрих-кодов в любом направлении на отсканированных документах. Программное обеспечение собирает данные о продуктах и клиентах, сохраняя их на вашем компьютере.
Интеллектуальное распознавание символов (ICR)
Вам нужно преобразовать рукописный ввод в текст? ICR – это компьютерный перевод рукописных и рукописных символов. Программное обеспечение ICR иногда используется вместе с программным обеспечением OCR во время обработки форм. Однако, в то время как программное обеспечение OCR может считывать неструктурированный машинно-напечатанный текст хорошего качества, программное обеспечение ICR предъявляет строгие требования к дизайну. Программное обеспечение ICR выполняет анализ изображения, чтобы точно выровнять изображение, сопоставить зоны ICR с предсказуемыми полями данных и начать категоризацию данных как набранные символы, отпечатки от руки или другие типы данных. Программное обеспечение ICR позволяет добиться автоматического документооборота, что значительно повышает вашу эффективность.
Программное обеспечение ICR позволяет добиться автоматического документооборота, что значительно повышает вашу эффективность.
Двойное голосование
Технология двойного голосования позволяет параллельно использовать механизм OCR и систему голосования. В качестве альтернативы, любой из механизмов OCR может применяться индивидуально на уровне поля для повышения точности распознавания.
Многопоточность для многопроцессорной архитектуры
Эта технология предусматривает несколько потоков на операцию для оптимальной пропускной способности многоядерных процессоров для приложений, которые имеют дело с большим количеством изображений.
Лучшие приложения OCR для Linux
Эта статья будет охватывать список полезного программного обеспечения для оптического распознавания символов, доступного для Linux. Программное обеспечение оптического распознавания символов (OCR) пытается обнаружить текстовое содержимое нетекстовых файлов, содержимое которых нельзя выбрать или скопировать, но можно просмотреть или прочитать. Например, программное обеспечение OCR может идентифицировать текст из изображений, PDF или других отсканированных документов в цифровых форматах файлов, используя различные алгоритмы и решения на основе ИИ.
Например, программное обеспечение OCR может идентифицировать текст из изображений, PDF или других отсканированных документов в цифровых форматах файлов, используя различные алгоритмы и решения на основе ИИ. Это программное обеспечение OCR особенно полезно для преобразования и сохранения старых документов, поскольку их можно использовать для идентификации текста и создания цифровых копий.Иногда идентифицированный текст может быть неточным на 100%, но программное обеспечение OCR устраняет необходимость в ручном редактировании в значительной степени, извлекая как можно больше текста. Позже можно будет внести правки вручную, чтобы повысить точность и создать точные копии. Большинство программ OCR могут извлекать текст в отдельные файлы, хотя некоторые также поддерживают наложение скрытого текстового слоя на исходные файлы. Наложенный текст позволяет вам читать содержимое в исходном формате и печати, но также позволяет выбирать и копировать текст.Этот метод специально используется для оцифровки старых документов в формат PDF.
Тессеракт OCR
Tesseract OCR – это бесплатное программное обеспечение для распознавания текста с открытым исходным кодом, доступное для Linux. Спонсируемый Google и поддерживаемый многими добровольцами, это, вероятно, самый полный пакет OCR, который может даже превзойти некоторые платные проприетарные решения. Он предоставляет инструменты командной строки, а также API, который вы можете интегрировать в свои собственные программы. Он может с хорошей точностью определять текст на многих языках.Он поставляется с набором предварительно обученных данных, которые можно использовать для идентификации и извлечения текста. Вы также можете использовать свои собственные обученные данные, если вам нужно индивидуальное решение или вы можете получить больше моделей от третьих лиц. Tesseract OCR поставляется с несколькими механизмами обнаружения, и вы можете использовать их в соответствии с вашими потребностями в зависимости от метода установки.
Чтобы установить Tesseract OCR в Ubuntu, используйте команду, указанную ниже:
$ sudo apt установить tesseract-ocr
Вы можете установить его в других дистрибутивах Linux из репозиториев по умолчанию через диспетчер пакетов. Универсальный файл AppImage и дополнительные инструкции по установке доступны здесь.
Универсальный файл AppImage и дополнительные инструкции по установке доступны здесь.
Tesseract OCR по умолчанию поддерживает определение содержимого на английском языке. Если вы хотите включить дополнительные языки, вам, возможно, придется загрузить дополнительные языковые пакеты. По приведенной выше ссылке есть инструкции по установке дополнительных языковых пакетов. В Ubuntu вы можете напрямую найти языковые пакеты, выполнив команду ниже:
$ apt-cache search tesseract-ocr-
Приведенная выше команда выведет имена пакетов для разных языковых пакетов.Просто установите их, выполнив команду в следующем формате:
$ sudo apt install <языковой-пакет>
Вы можете получить список всех установленных языковых пакетов, выполнив следующую команду:
После установки основного пакета Tesseract OCR и дополнительных языковых пакетов вы можете начать обнаружение текста в изображениях и файлах PDF. Для извлечения текста используйте команды в следующих форматах:
$ tesseract image. png output -l eng
png output -l eng$ tesseract image.png output -l eng + spa
$ tesseract image.png вывод -l eng pdf
Первая команда извлечет текст из файла «image.png» на языке «eng» и сохранит его в файле с именем «output». Вторая команда проанализирует изображение с использованием нескольких языковых пакетов. Третья команда может использоваться для создания файла PDF с текстовым слоем, наложенным на файл изображения.
Для получения дополнительной информации об использовании Tesseract OCR в командной строке используйте следующие две команды:
$ tesseract –help$ man tesseract
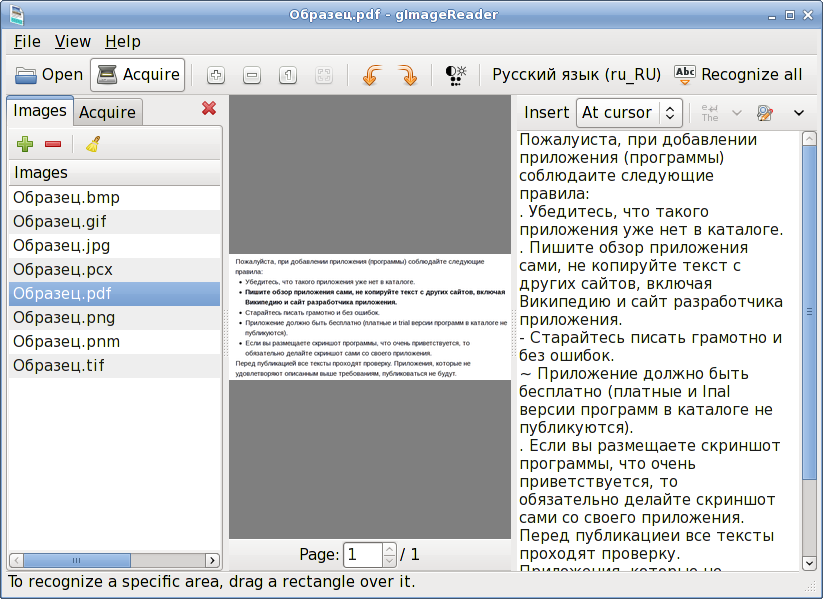
gImageReader
gImageReader – это графический клиент для упомянутого выше механизма Tesseract OCR.Вы можете использовать его для запуска большинства параметров и действий командной строки, поддерживаемых Tesseract OCR, включая извлечение текста из нескольких файлов, проверку орфографии извлеченного текста и выполнение пост-обработки идентифицированного текста.
Чтобы установить gImageReader в Ubuntu, используйте команду, указанную ниже:
$ sudo apt установить gimagereader
Вы можете установить его в других дистрибутивах Linux из репозиториев по умолчанию через диспетчер пакетов. Дополнительные пакеты для конкретных дистрибутивов доступны здесь.
Дополнительные пакеты для конкретных дистрибутивов доступны здесь.
Оформление документов
Paperwork – это бесплатный менеджер документов с открытым исходным кодом. Вы можете использовать его для эффективного управления вашей библиотекой документов, особенно если у вас большая коллекция. Он также имеет встроенный режим распознавания текста, который использует «Pyocr», модуль Python, основанный на механизмах распознавания текста Tesseract и Cuneiform. Другие основные функции Paperwork включают возможность редактирования отсканированных документов, панель поиска для поиска в библиотеке документов, возможность сортировки документов, поддержку сканера и так далее.
Чтобы установить Paperwork в Ubuntu, используйте команду, указанную ниже:
$ sudo apt install paperwork-gtk
Вы можете установить его в других дистрибутивах Linux из репозиториев по умолчанию через диспетчер пакетов.Здесь также доступна универсальная упаковка Flatpak.
OCRFeeder
OCRFeeder – это бесплатное программное обеспечение для оптического распознавания текста с открытым исходным кодом, поддерживаемое командой GNOME. Он поддерживает распознавание текста на многих языках и может экспортировать контент в различные форматы файлов. Он поддерживает множество механизмов OCR, включая Tesseract OCR, GOCR, Ocrad и Cuneiform. Он также позволяет выполнять некоторую пост-обработку для улучшения форматирования и компоновки извлеченного текстового содержимого.
Он поддерживает распознавание текста на многих языках и может экспортировать контент в различные форматы файлов. Он поддерживает множество механизмов OCR, включая Tesseract OCR, GOCR, Ocrad и Cuneiform. Он также позволяет выполнять некоторую пост-обработку для улучшения форматирования и компоновки извлеченного текстового содержимого.
Чтобы установить OCRFeeder в Ubuntu, используйте команду, указанную ниже:
$ sudo apt установить ocrfeeder
Вы можете установить его в других дистрибутивах Linux из репозиториев по умолчанию через диспетчер пакетов.Здесь также доступна универсальная упаковка Flatpak.
Обратите внимание, что в моем тестировании OCRFeeder, установленный из репозиториев Ubuntu, поставлялся только с одним движком OCR. Однако сборка flatpak поставляется со всеми четырьмя поддерживаемыми механизмами распознавания текста, хотя загружает около 2 ГБ данных. Пакет, включенный в репозиторий Ubuntu, был намного меньше по размеру.
gscan2pdf
gscan2pdf – это бесплатная графическая утилита с открытым исходным кодом, которая может идентифицировать и извлекать текст из различных форматов файлов.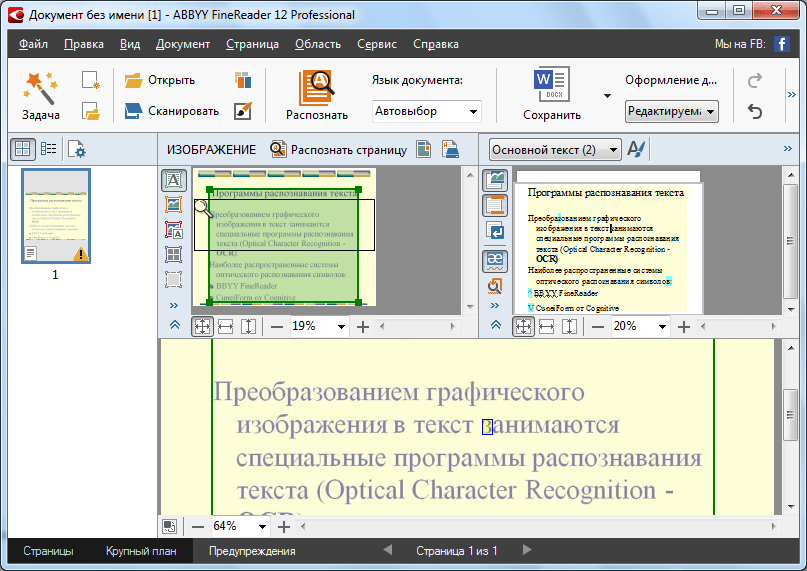 Он может напрямую работать со сканерами для сканирования документов, а затем экспортировать текстовое содержимое, обнаруженное с помощью оптического распознавания символов, в файлы PDF. Он также поддерживает несколько механизмов OCR, включая Tesseract OCR, GOCR, Ocropus и Cuneiform, если в вашей системе установлены пакеты для этих механизмов. Помимо прямого сканирования документов, вы также можете импортировать файлы изображений и извлекать из них текст.
Он может напрямую работать со сканерами для сканирования документов, а затем экспортировать текстовое содержимое, обнаруженное с помощью оптического распознавания символов, в файлы PDF. Он также поддерживает несколько механизмов OCR, включая Tesseract OCR, GOCR, Ocropus и Cuneiform, если в вашей системе установлены пакеты для этих механизмов. Помимо прямого сканирования документов, вы также можете импортировать файлы изображений и извлекать из них текст.
Чтобы установить gscan2pdf в Ubuntu, используйте команду, указанную ниже:
$ sudo apt install gscan2pdf gocr клинопись tesseract-ocr
Вы можете установить его в других дистрибутивах Linux из репозиториев по умолчанию через диспетчер пакетов.Исходный код и исполняемые двоичные файлы также доступны здесь.
Заключение
Это одни из наиболее полезных механизмов и программного обеспечения для оптического распознавания текста с использованием командной строки и графики, доступных для Linux. Tesseract OCR – это наиболее активно разрабатываемый и наиболее полный инструмент для обнаружения текста, и его должно хватить для большинства ваших нужд. Хотя вы также можете попробовать другие приложения, упомянутые в этой статье, если вас не устраивают результаты Tesseract OCR.
Tesseract OCR – это наиболее активно разрабатываемый и наиболее полный инструмент для обнаружения текста, и его должно хватить для большинства ваших нужд. Хотя вы также можете попробовать другие приложения, упомянутые в этой статье, если вас не устраивают результаты Tesseract OCR.
Использование оптического распознавания символов Google для извлечения текста из изображений
Программное обеспечение Google Optical Character Recognition (OCR) теперь работает более чем на 248 языках мира (включая все основные языки Южной Азии).Он довольно прост и удобен в использовании и может определять большинство языков с точностью более 90%.
Технология извлекает текст из изображений, сканирований печатного текста и даже рукописного ввода, что означает, что текст может быть извлечен практически из любых старых книг, рукописей или изображений.
Google OCR, вероятно, использует зависимости Tesseract, движка OCR, выпущенного как бесплатное программное обеспечение, или OCRopus, бесплатной системы анализа документов и оптического распознавания символов (OCR), которая в основном используется в Google Книгах. Разработанный как общественный проект в 1995–2006 годах, а затем переданный Google, Tesseract считается одним из самых точных движков OCR и работает более чем на 60 языках. Исходный код доступен на GitHub.
Разработанный как общественный проект в 1995–2006 годах, а затем переданный Google, Tesseract считается одним из самых точных движков OCR и работает более чем на 60 языках. Исходный код доступен на GitHub.
На странице поддержки проекта OCR предлагаются дополнительные сведения о сохранении форматирования символов для таких вещей, как жирный шрифт и курсив после OCR в выходном тексте:
При обработке вашего документа мы стараемся сохранить базовое форматирование текста, такое как полужирный и курсивный текст, размер и тип шрифта, а также разрывы строк.Однако обнаружить эти элементы сложно, и не всегда это удается. Другие элементы форматирования и структурирования текста, такие как маркированные и нумерованные списки, таблицы, текстовые столбцы, а также сноски или концевые сноски, могут быть потеряны.
Директор программ Викимедиа и Викимедиа на тамильском языке в Индии Равишанкар Айякканну сказал в Facebook следующее после тестирования: «Для некоторых языков, таких как малаялам и тамильский, OCR работает с почти 100% точностью, а также поддерживает форматирование, такое как автоматическая обрезка и разделение текста. отбрасывая изображения и игнорируя цветной фон.”Носители следующих индийских языков – бангла, малаялам, каннада, одия, тамильский и телугу – также прокомментировали сообщение в Facebook с отзывами после тестирования OCR.
отбрасывая изображения и игнорируя цветной фон.”Носители следующих индийских языков – бангла, малаялам, каннада, одия, тамильский и телугу – также прокомментировали сообщение в Facebook с отзывами после тестирования OCR.
Однако для некоторых скриптов, таких как Gurmukhi (используется для написания панджаби), вывод после OCR довольно плохой и приводит к тарабарщине текста в разных скриптах.
Учебное пособие по преобразованию текста на языке Odia (индийский язык) из отсканированного изображения с помощью Google OCR. Дизайн – Субхашиш Паниграхи. CC BY-SA 4.0В целом, это довольно большой скачок для языков, в которых есть старые тексты, которые еще не были оцифрованы. Старый и ценный текст на многих языках теперь можно оцифровать и поделиться через Интернет с помощью таких платформ, как Wikisource.
Примечание редактора: статья была обновлена с учетом отзывов сообщества. Мы изменили «OCR Google частично использует Tesseract, механизм OCR, выпущенный как бесплатное программное обеспечение» на «OCR Google, вероятно, использует зависимости Tesseract, движка OCR, выпущенного как бесплатное программное обеспечение, или OCRopus, бесплатный анализ документов и оптическое распознавание символов (OCR). система, которая в основном используется в Google Книгах.«Если у вас есть дополнительные отзывы о статье или технологии, сообщите нам об этом в комментариях. – Рикки Эндсли
система, которая в основном используется в Google Книгах.«Если у вас есть дополнительные отзывы о статье или технологии, сообщите нам об этом в комментариях. – Рикки Эндсли
Что такое OCR (оптическое распознавание символов)?
OCR (оптическое распознавание символов) – это использование технологии для распознавания печатных или рукописных текстовых символов внутри цифровых изображений физических документов, таких как отсканированный бумажный документ. Базовый процесс OCR включает в себя изучение текста документа и перевод символов в код, который можно использовать для обработки данных.OCR иногда также называют распознаванием текста.
Системы оптического распознавания текста состоят из комбинации аппаратного и программного обеспечения, которое используется для преобразования физических документов в машиночитаемый текст. Оборудование, такое как оптический сканер или специализированная печатная плата, используется для копирования или чтения
текст
в то время как программное обеспечение обычно выполняет расширенную обработку. Программное обеспечение
может также воспользоваться преимуществами искусственного интеллекта (AI) для реализации более продвинутых методов интеллектуального распознавания символов (ICR), таких как определение языков или стилей почерка.
Программное обеспечение
может также воспользоваться преимуществами искусственного интеллекта (AI) для реализации более продвинутых методов интеллектуального распознавания символов (ICR), таких как определение языков или стилей почерка.
Процесс OCR чаще всего используется для включения печатная копия юридические или исторические документы в PDF. После помещения в эту электронную копию пользователи могут редактировать, форматировать и выполнять поиск в документе, как если бы он был создан с помощью текстового процессора.
Как работает оптическое распознавание символов
Первым шагом OCR является использование сканера для обработки физической формы документа. После копирования всех страниц программа OCR преобразует документ в двухцветную или черно-белую версию.Отсканированное изображение или растровое изображение анализируется на наличие светлых и темных областей, где темные области идентифицируются как символы, которые необходимо распознать, а светлые области идентифицируются как фон.
Затем темные области обрабатываются для поиска буквенных или цифровых цифр. Программы оптического распознавания символов могут различаться по своим методикам, но обычно подразумевают нацеливание на один символ, слово или блок текста за раз. Затем персонажи идентифицируются с использованием одного из двух алгоритмов:
- Распознавание образов. В программы OCR загружаются образцы текста с различными шрифтами и форматами, которые затем используются для сравнения и распознавания символов в отсканированном документе.
- Обнаружение функций – программы оптического распознавания текста применяют правила, касающиеся особенностей конкретной буквы или цифры, для распознавания символов в отсканированном документе. Функции могут включать в себя количество наклонных линий, пересеченных линий или кривых в символе для сравнения. Например, заглавная буква «А» может быть сохранена в виде двух диагональных линий, которые пересекаются с горизонтальной линией посередине.
Когда символ идентифицируется, он преобразуется в код ASCII, который может использоваться компьютерными системами для обработки дальнейших манипуляций.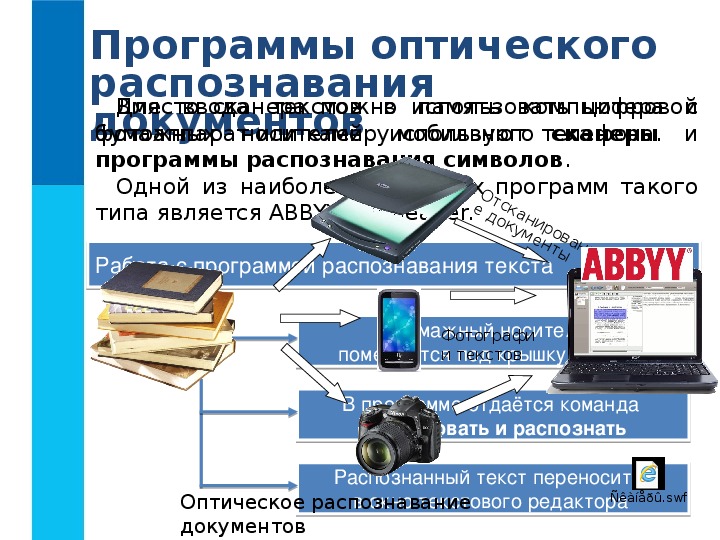 Пользователи должны исправить основные ошибки, вычитать и убедиться, что сложные макеты были правильно обработаны, прежде чем сохранять документ для будущего использования.
Пользователи должны исправить основные ошибки, вычитать и убедиться, что сложные макеты были правильно обработаны, прежде чем сохранять документ для будущего использования.
Варианты использования оптического распознавания символов
OCR может использоваться для множества приложений, в том числе:
- Сканирование печатных документов в версии, которые можно редактировать с помощью текстовых редакторов, таких как Microsoft Word или Google Docs.
- Индексирование печатных материалов для поисковых систем.
- Автоматизация ввода, извлечения данных а также обработка.
- Расшифровка документов в текст, который может быть прочитан вслух слабовидящим или слепым пользователям.

- Архивирование исторической информации, такой как газеты, журналы или телефонные книги, в форматы с возможностью поиска.
- Электронное депонирование чеков без использования кассира.
- Размещение важных подписанных юридических документов в электронной базе данных.
- Распознавание текста, например номерных знаков, с помощью камеры или программного обеспечения.
- Сортировка писем для доставки почты.
- Перевод слов в изображении на указанный язык.
Преимущества оптического распознавания символов
Основные преимущества технологии OCR – это экономия времени, уменьшение количества ошибок и минимизация усилий. Он также позволяет выполнять действия, недоступные для физических копий, такие как сжатие в файлы ZIP, выделение ключевых слов, включение в веб-сайт и прикрепление к электронному письму.
Хотя создание изображений документов позволяет архивировать их в цифровом виде, OCR предоставляет дополнительные функции, позволяющие редактировать эти документы и выполнять поиск в них.
Оптическое распознавание символов (OCR) | TensorFlow Lite
Оптическое распознавание символов (OCR) – это процесс распознавания символов. из изображений с использованием методов компьютерного зрения и машинного обучения. Этот справочное приложение демонстрирует, как использовать TensorFlow Lite для распознавания текста. Он использует комбинацию из модель обнаружения текста и модель распознавания текста как конвейер OCR для распознавания текстовых символов.
Начать
Если вы новичок в TensorFlow Lite и работаете с Android, мы рекомендуем изучение следующего примера приложения, которое может помочь вам начать работу.
Android пример
Если вы используете платформу, отличную от Android, или вы уже знакомы с API-интерфейсы TensorFlow Lite, вы можете скачать модели с TF Hub.
Как это работает
задач OCR часто разбиваются на 2 этапа. Сначала мы используем обнаружение текста
модель для обнаружения ограничивающих рамок вокруг возможных текстов. Во-вторых, мы кормим
обработали ограничивающие рамки в модели распознавания текста для определения конкретных
символы внутри ограничивающих рамок (нам также нужно сделать Non-Maximal Supression,
перспективное преобразование и др.перед распознаванием текста). В нашем случае
обе модели взяты из TensorFlow Hub и являются квантованными моделями FP16.
Во-вторых, мы кормим
обработали ограничивающие рамки в модели распознавания текста для определения конкретных
символы внутри ограничивающих рамок (нам также нужно сделать Non-Maximal Supression,
перспективное преобразование и др.перед распознаванием текста). В нашем случае
обе модели взяты из TensorFlow Hub и являются квантованными моделями FP16.
Тесты производительности
Показатели производительности генерируются с помощью описанного инструмента. здесь.
| Название модели | Размер модели | Устройство | процессор | графический процессор |
|---|---|---|---|---|
| Обнаружение текста | 45.9 Мб | Pixel 4 (Android 10) | 181.93 мс * | 89,77 мс * |
| Распознавание текста | 16.8 Мб | Pixel 4 (Android 10) | 338,33 мс * | НЕТ ** |
* Используется 4 резьбы.
** эта модель не может использовать делегат графического процессора, так как нам нужны операторы TensorFlow для его запуска
Входы
Модель обнаружения текста принимает 4-D float32 Tensor of (1, 320, 320, 3) как
Вход.
Модель распознавания текста принимает 4-D float32 Tensor of (1, 31, 200, 1) как
Вход.
Выходы
Модель обнаружения текста возвращает 4-D float32 Тензор формы (1, 80, 80, 5)
как ограничивающий прямоугольник и 4-D float32 Тензор формы (1,80, 80, 5) как обнаружение
счет.
Модель распознавания текста возвращает двумерный тензор формы float32 (1, 48) как
отображение индексов в алфавитный список ‘0123456789abcdefghijklmnopqrstuvwxyz’
Ограничения
Текущий модель распознавания текста обучается на синтетических данных с английскими буквами и цифрами, поэтому только Поддерживается английский язык.

Модели недостаточно общие для распознавания текста в естественных условиях (например, случайные изображения снято камерой смартфона при слабом освещении).
Итак, мы выбрали 3 логотипа продуктов Google только для того, чтобы продемонстрировать, как выполнять распознавание текста с помощью TensorFlow Lite. Если вы ищете готовое к использованию OCR промышленного уровня продукт, вы должны рассмотреть Комплект Google ML. ML Kit, который использует TFLite внизу, должен быть достаточным для большинства случаев использования OCR. случаев, но в некоторых случаях вы можете захотеть создать собственное OCR решение с TFLite.Вот несколько примеров:
- У вас есть собственные модели TFLite для обнаружения / распознавания текста, которые вы бы нравится использовать
- У вас есть особые бизнес-требования (т. Е. Распознавание текстов, которые вверх ногами) и необходимо настроить конвейер OCR
- Вы хотите поддерживать языки, не входящие в состав ML Kit
- У ваших целевых пользовательских устройств не обязательно есть сервисы Google Play установлено
Список литературы
.