
Как перевести картинку с китайского на русский
Китай – популярное направление для путешествий; обилие достопримечательностей и экскурсионных туров, древняя история страны и ее богатое культурное наследие делают Китай особенно привлекательным для туристов. Однако, как же посетить все красоты, и справиться с такими простыми действиями, как поиск дороги, регистрация в отеле и заказ еды в ресторане, если не знаешь языка. Китайский является одним из самых сложных языков в мире с уникальным алфавитом, и выучить его на простейшем уровне за несколько недель как европейские языки не так-то просто. Справиться с переводом через камеру с китайского на русский помогут специальные приложения-словари.
Как перевести китайские иероглифы
Технологии не стоят на месте, и теперь путешественникам нет нужды мучиться с карманными переводчиками, которые только запутывают своего владельца и его собеседников. Электронные словари тоже мало помогут делу, особенно непросто с ними приходится новичкам.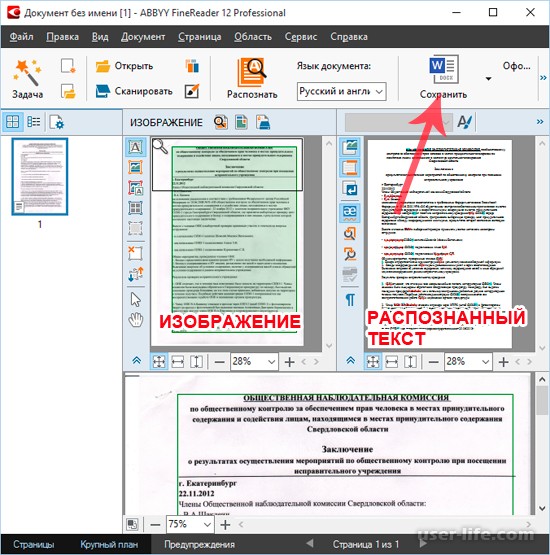
Функция эта новая, поэтому работает нестабильно и требует некоторой сноровки. Для того чтобы получить читаемый текст, необходимо сделать качественное изображение, на котором хорошо виден требуемые символы. Чем четче и ярче изображение, тем выше вероятность того, что текст будет переведен максимально близко к смыслу.
Обратите внимание! Большинство шрифтов приложения для переводов не воспринимают, особенно это касается иероглифов написанных нечетко.
Яндекс Переводчик с картинок в помощь
Несмотря на то, что традиционно большей популярностью пользуется GoogleTranslate, Яндекс Переводчик выполняет работу с китайским языком (и некоторыми европейскими) более корректно и грамотно, чем его более известный собрат.
Перевод с фото при помощи Яндекса можно выполнить только с телефона, для компьютеров такая функция пока отсутствует. Сначала требуется выбрать язык, с которого выполняется работа, в данном случае китайский. Для того чтобы получить результат, нужно просто сделать фотографию, либо выбрать нужное изображение в памяти смартфона, предварительно нажав на иконку «Картинка» в сервисе. Яндекс предложит выделить область, с которой необходимо поработать. Сделав это, нужно нажать Enter и дождаться завершения процесса.
Перевод в Free Online OCR
Free Online OCR известен как один из первых сайтов, предназначенных для выполнения переводов с фотографии. Сервис сравнительно новый, поэтому корректность результатов с некоторых языков у него заметно страдает. Также сайт пока не имеет полной версии на русском, но доступен на английском.
Важный момент: Качество и верность перевода очень сильно зависят от качества фото и количества текста. Чем меньше слов и чем выше качество фотографии, тем лучше программа сможет распознавать информацию.
Для того чтобы перевести текст с изображения с китайского языка на русский, нужно:
- Загрузить изображение с компьютера, нажав иконку «Выберите файл». Сервис позволяет загрузить сразу несколько картинок;
- На нижней строке сервиса необходимо выбрать язык, с которого выполняется перевод;
- Выполнив предыдущие шаги, нужно нажать на иконку «Upload + OCR»;
- По завершении процесса, сервис предлагает увидеть и оригинальный текст, и готовый перевод. Оригинальный текст позволяет пользователю посмотреть, как приложение «видит» шрифт, сравнить его с картинкой и разобраться, где работа выполнена некорректно (изображение и оригинальный текст в этих местах не будут совпадать). Распознавание шрифтов пока оставляет желать лучшего.
Как перевести китайский текст с картинки другими способами?
Помимо Яндекс Переводчика и Free Online OCR (которых может не оказаться под рукой) существует множество сервисов, выполняющих аналогичные задачи.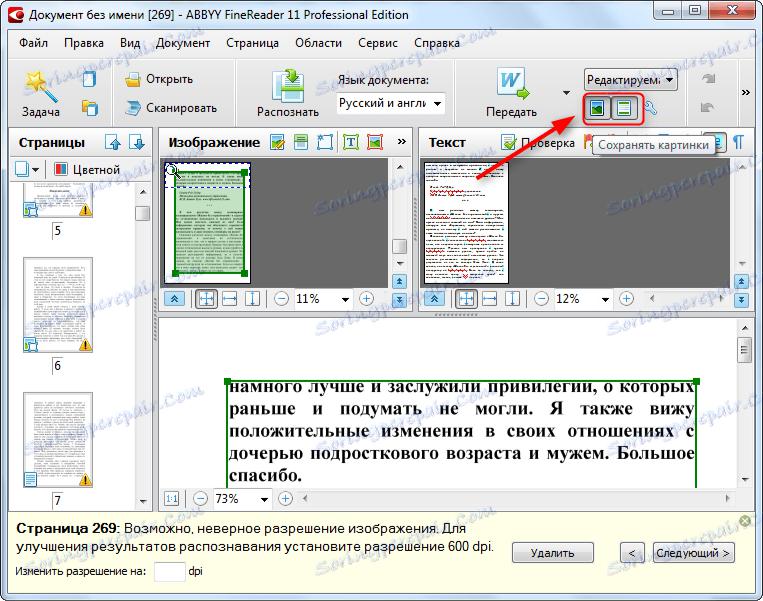 Некоторые из них доступны только со смартфона и компьютера, некоторые работают на всех устройствах.
Некоторые из них доступны только со смартфона и компьютера, некоторые работают на всех устройствах.
Для перевода с картинки на русский язык можно воспользоваться:
- Google Translate, который работает аналогично Яндекс Переводчику. Google переиздал свое приложение специально для китайских пользователей с одобрения государства. До некоторых пор в Китае невозможно было воспользоваться ни одной из платформ Google, который был запрещен китайским правительством;
- Программа для распознавания текста и последующий перевод. Более трудоёмкий способ, чем предыдущие, но возможно более надежный. Выполняется в два этапа. При помощи Optical Character Recognition (можно скачать в любом магазине бесплатно) из фото извлекается исходный текст, а затем вводится в любой популярный сервис, который переводит.
Заключение
Пока сервисы для переводов с картинки работают неуверенно: проблемы с качеством фотографий, высокие требования к изображениям и некорректный перевод дают о себе знать.
Если вы собрались путешествовать в Китай, то переводчик с китайского языка на русский по фото в режиме онлайн будет просто необходим. Чтобы перевести расписание самолётов в аэропорту в этой стране, вам нужно будет всего лишь запустить программу и навести камеру на малопонятный текст. Ознакомьтесь с лучшими приложениями в нашей статье.
Google Переводчик по фотографии с китайского языка на русский
Одной из лучших программ и приложений для перевода в интернете является Google Translate или Переводчик Гугл . Прежде всего из-за качества перевода, а также скорости работы. Сервис умеет работать со 103 языками мира и распознавать информацию по фото, голосовые сообщения, через камеру смартфона, текстовые сообщения. Ещё приложение сможет быстро перевести на ваш родной язык любой сайт в интернете. Для этого разработчик предлагает нам воспользоваться их браузером — Google Chrome .
Ещё приложение сможет быстро перевести на ваш родной язык любой сайт в интернете. Для этого разработчик предлагает нам воспользоваться их браузером — Google Chrome .
В 2017 году переводчик от компании Google значительно «поумнел». Так как его движок был полностью перенесён на нейросети. Также переводчик всегда готов рассмотреть другие варианты перевода того или иного слова. Вы можете указать правильный или даже неправильный вариант. Но со временем он будет изменён либо алгоритмом программы, либо другими пользователями обратно на правильный. Чтобы понять китайские иероглифы на изображении необходимо загрузить приложение для мобильных телефонов « Google Translate » для Android или iOS.
Дальнейший порядок действий:
- Откройте мобильный маркет на Андроид и iOS. Скачайте и установите его;
Результат перевода появится в приложении.
Сфотографируйте результат, чтобы прочесть его позже в более комфортных условиях. Язык всегда можно сменить на верхней панели приложения. В том случае, если он автоматически установлен неправильно.
В том случае, если он автоматически установлен неправильно.
Яндекс Переводчик — сервис для расшифровки китайских иероглифов онлайн
Две поисковые системы — Яндекс и Google уже давно соревнуются в интернете за звание лидера. И обе достойны быть лучшими. Переводчик, созданный российскими разработчиками всё же немного уступает сервису от Google по функциям. Он также способен переводить по фотографии и делает это хорошо. Потому что его движок также переведён на нейросеть. А тексты для преобразования основываются на миллионах уже переведённых в интернете статьях.
Особенности online переводчика:
| Функционал: | Пояснение: |
|---|---|
| Большая база языков | Переводчик позволяет трансформировать печатный текст на 95 языков мира. |
| Наличие подсказок | При вводе текста отображаются подсказки, которые помогают быстрее вводить слово, фразу или даже предложение. |
| Понятная транскрипция | Сервис Яндекс показывает транскрипцию китайского или любого другого языка. И помогает понять, как звучит то или иное слово при произношении. И помогает понять, как звучит то или иное слово при произношении. |
Алгоритм, при помощи которого распознаются тексты на картинках — собственная разработка компании Yandex.
Порядок работы с сервисом:
- Скачайте приложение Яндекс.Переводик из мобильного маркета и запустите на Айфоны и Андроид;
В момент использования переводчика на русский по фотоснимку, необходимо подключение к интернету. Так как приложение способно различать языки на изображении только online. Если вам не понятно обращение к вам китайца, вы можете попросить его говорить в микрофон смартфона , чтобы вы увидели текст на русском в приложении Яндекс. Для этого выберите соответствующий режим перевода.
Также, как и переводчик от Гугла способен переводить целые веб-сайты на разные доступные языки. Расшифровка по картинке доступна пока что только для 12 языков: Ещё в мобильном приложении реализована поддержка Android Wear .
Microsoft Переводчик — поможет преобразовать слово с китайского на русский по картинке
Вслед за популярными приложениями-переводчиками устремляется и разработка компании Майкрософт. Создатели самой популярной операционной системы для компьютеров также решили сказать своё слово в современном переводе. Этот переводчик умеет работать с китайским текстом и даже переводить его по изображению. Приложение доступно для мобильных платформ в Google Play и App Store. Как и его конкуренты, сервис умеет работать с фотографиями, скриншотами, распознавать голос, текстовые сообщения и работает с 60 языками.
Работает как онлайн, так и оффлайн. Способен переводить «на лету» беседу двух человек, разговаривающих на разных языках.
Пользователи сталкиваются с необходимостью перевода текста с фото онлайн. Ситуации могут быть разными: на фотографии есть текст, который необходимо извлечь из изображения и перевести на другой язык, есть изображение документа на иностранном языке, нужно перевести текст с картинки и т. п.
п.
Можно воспользоваться программами для распознавания текста, которые с помощью технологии OCR (Optical Character Recognition) извлекают текст из изображений. Затем, извлеченный их фото текст, можно перевести с помощью переводчика. Если исходное изображение хорошего качества, то в большинстве случаев подойдут бесплатные онлайн сервисы для распознавания текста.
В этом случае, вся операция проходит в два этапа: сначала происходит распознавание текста в программе или на онлайн сервисе, а затем осуществляется перевод текста, с помощью переводчика онлайн или приложения, установленного на компьютере. Можно, конечно, скопировать текст из фото вручную, но это не всегда оправданно.
Есть ли способ совместить две технологии в одном месте: сразу распознать и перевести тест с фотографии онлайн? В отличие от мобильных приложений, выбора для пользователей настольных компьютеров практически нет. Но, все же я нашел два варианта, как перевести текст с изображения онлайн в одном месте, без помощи программ и других сервисов.
Переводчик с фотографии онлайн распознает текст на изображении, а затем переведет его на нужный язык.
При переводе с изображений онлайн, обратите внимание на некоторые моменты:
- качество распознавания текста зависит от качества исходной картинки
- для того, чтобы сервис без проблем открыл картинку, изображение должно быть сохранено в распространенном формате (JPEG, PNG, GIF, BMP и т. п.)
- если есть возможность, проверьте извлеченный текст, для устранения ошибок распознавания
- текст переводится с помощью машинного перевода, поэтому перевод может быть не идеальным
Мы будем использовать Яндекс Переводчик и онлайн сервис Free Online OCR, на котором присутствует функциональная возможность для перевода для извлеченного из фотошрафии текста. Вы можете использовать эти сервисы для перевода с английского на русский язык, или использовать другие языковые пары поддерживаемых языков.
Яндекс Переводчик для перевода с картинок
В Яндекс. Переводчик интегрирована технология оптического распознавания символов OCR, с помощью которой из фотографий извлекается текст. Затем, используя технологии Яндекс Переводчика, происходит перевод извлеченного текста на выбранный язык.
Переводчик интегрирована технология оптического распознавания символов OCR, с помощью которой из фотографий извлекается текст. Затем, используя технологии Яндекс Переводчика, происходит перевод извлеченного текста на выбранный язык.
Последовательно пройдите следующие шаги:
- Войдите в Яндекс Переводчик во вкладку «Картинки».
- Выберите язык исходного текста. Для этого кликните по названию языка (по умолчанию отображается английский язык). Если вы не знаете, какой язык на изображении, переводчик запустит автоопределение языка.
- Выберите язык для перевода. По умолчанию, выбран русский язык. Для смены языка кликните по названию языка, выберите другой поддерживаемый язык.
- Выберите файл на компьютере или перетащите картинку в окно онлайн переводчика.
- После того, как Яндекс Переводчик распознает текст с фотографии, нажмите «Открыть в Переводчике».
В окне переводчика откроются два поля: одно с текстом на иностранном языке (в данном случае на английском), другое с переводом на русский язык (или другой поддерживаемый язык).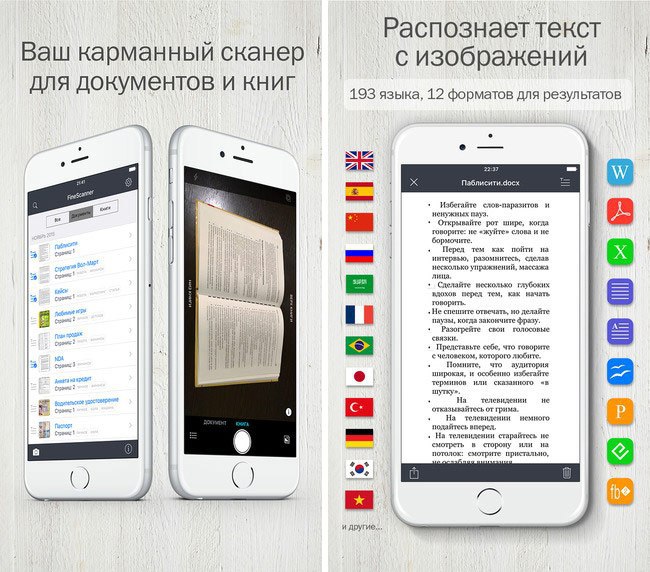
- Если у фото было плохое качество, имеет смысл проверить качество распознавания. Сравните переводимый текст с оригиналом на картинке, исправьте найденные ошибки.
- В Яндекс Переводчике можно изменить перевод. Для этого включите переключатель «Новая технология перевода». Перевод осуществляют одновременно нейронная сеть и статистическая модель. Алгоритм автоматически выбирает лучший вариант перевода.
- Скопируйте переведенный текст в текстовый редактор. При необходимости, отредактируйте машинный перевод, исправьте ошибки.
Перевод с фотографии онлайн в Free Online OCR
Бесплатный онлайн сервис Free Online OCR предназначен для распознавания символов из файлов поддерживаемых форматов. Сервис подойдет для перевода, так как на нем опционально имеется возможности для перевода распознанного текста.
В отличие от Яндекс Переводчика, на Free Online OCR приемлемое качество распознавания получается только на достаточно простых изображениях, без присутствия на картинке посторонних элементов.
Выполните следующие действия:
- Войдите на Free Online OCR.
- В опции «Select your file» нажмите на кнопку «Обзор», выберите файл на компьютере.
- В опции «Recognition language(s) (you can select multiple)» выберите необходимый язык, с которого нужно перевести (можно выбрать несколько языков). Кликните мышью по полю, добавьте из списка нужный язык.
- Нажмите на кнопку «Upload + OCR».
После распознавания, в специальном поле отобразится текст с изображения. Проверьте распознанный текст на наличие ошибок.
Для перевода текста нажмите на ссылку «Google Translator» или «Bing Translator» для того, чтобы использовать одну из служб перевода онлайн. Оба перевода можно сравнить и выбрать лучший вариант.
Скопируйте текст в текстовый редактор. Если нужно, отредактируйте, исправьте ошибки.
Заключение
С помощью Яндекс Переводчика и онлайн сервиса Free Online OCR можно перевести текст на нужный язык из фотографий или картинок в режиме онлайн. Текст из изображения будет извлечен и переведен на русский или другой поддерживаемый язык.
Текст из изображения будет извлечен и переведен на русский или другой поддерживаемый язык.
App Store: Сканер Перевoдчик+ перевод OCR
Загрузите приложение Scan and Translate сейчас и мгновенно переводите: деловые документы, контракты, домашние задания, меню, уличные знаки и другие изображения. Получите более 90 различных языков доступных для перевода!
Хотите понимать, что написано на иностранных вывесках и знаках, которые встречаются при путешествиях за границу? Возникали ли у вас трудности с пониманием важного документа, написанного на иностранном языке? Нужен перевод во время совершения покупок, поиска или чтения любых текстов? Тогда это приложение для вас. Scan & Translate – это ваш персональный переводчик 90 различных языков. Все, что требуется – это просто сделать снимок текста.
С помощью Сканер-Переводчик, вы можете оцифровать любой печатный текст и получить прямой перевод с голосовой озвучкой слов и фраз на любом языке на ваш выбор.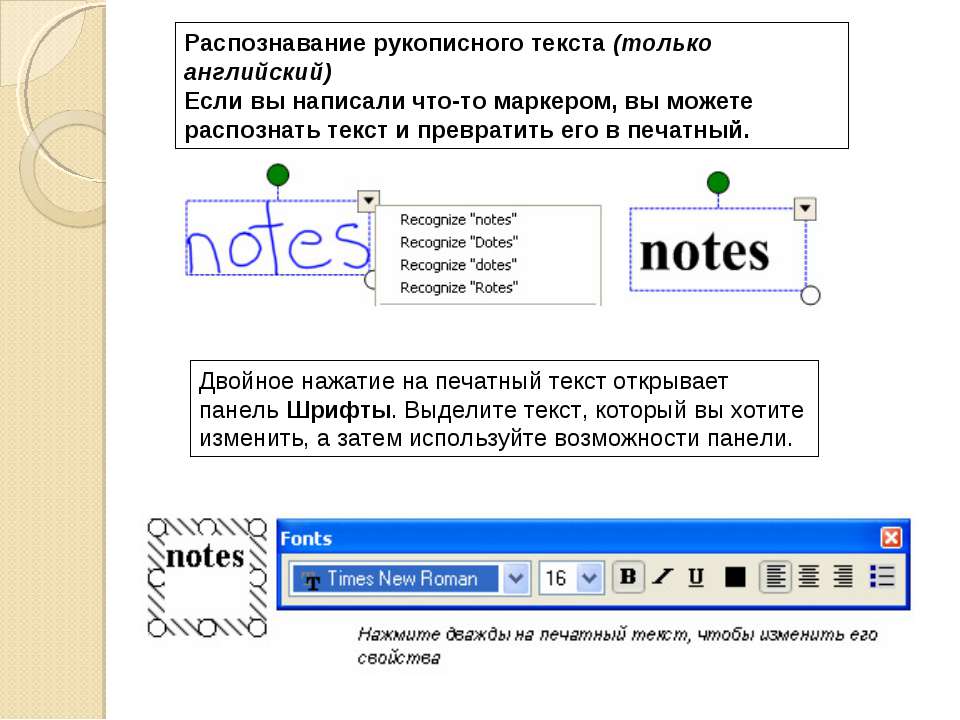 Этот универсальный онлайн переводчик значительно упрощает жизнь. Приложение Сканер-Переводчик всегда под рукой, чтобы вы могли получить точный и быстрый перевод.
Этот универсальный онлайн переводчик значительно упрощает жизнь. Приложение Сканер-Переводчик всегда под рукой, чтобы вы могли получить точный и быстрый перевод.
ФУНКЦИИ: сканер текста и переводчик по фотографии
Приложение включает следующие функции:
– Автоматизированная голосовая система произношения
– Усовершенствованная технология оптического распознавания символов
– Перевод с помощью камеры:
• любых бумажных документов
• рецептов из кулинарных книг
• записок и писем
• меню в ресторанах, барах и кафе
• инструкции и руководства по эксплуатации
• состава продуктов на упаковке
• дорожных знаков и указателей в аэропортах и на вокзалах
• и многого другого
Как пользоваться приложением:
– Выберите язык оригинального текста в качестве языка для распознавания
– Сфотографируйте документ с помощью встроенной камеры для перевода языка
– Нажмите на кнопку “Сканировать”, чтобы активировать фотосканер
– Распознанный текст появится на экране вместе с опцией выбора исходного языка текста и языка, на который осуществляется перевод
– После выбора языка нажмите “Перевод”, и полный перевод текста появится на следующей странице
– Для прослушивания переведенного текста, нажмите кнопку “Голос”, чтобы воспользоваться всеми функциями переводчика по фото
Переводчик фото + Сканер текста
Приложение Scan & Translate – это переводчик сделанных вами фото. Если вам нужен китайский переводчик, англо-русский переводчик, немецкий переводчик или переводчик любого другого из более чем 90 языков, мы предоставим вам необходимую информацию.
Если вам нужен китайский переводчик, англо-русский переводчик, немецкий переводчик или переводчик любого другого из более чем 90 языков, мы предоставим вам необходимую информацию.
Скачайте Сканер-Переводчик сейчас и получите доступ к максимальному за все время количеству языков!
Для того, чтобы получить полный доступ ко всем функциям приложения Сканер-Переводчик, необходимо разрешить доступ к:
*Камере – чтобы использовать камеру-переводчик. Сделайте фото и получите перевод текста и/или названия объектов
*Фото – чтобы перевести текст и названия объектов на фотографиях, сделанных ранее
Примечание: Бесплатная версия имеет ограничения (например, количество распознаваний текстов и переводов в день), которые могут меняться.
Выберите один из вариантов подписки. Стандартные варианты подписки включают:
подписку на 1 месяц
подписку на 1 год
После подписки вам будут доступны:
– Безлимитные переводы
– Безлимитные распознавания текстов
– Распознавание текстов оффлайн
– Перевод оффлайн
– Отключение рекламы
– Режим моментального снимка
Вы можете отменить бесплатный пробный период или подписку в любое время через настройки вашего аккаунта iTunes. Во избежание списания средств, выполните отмену не позднее чем за 24 часа до окончания бесплатного пробного периода или подписки. Изменения вступят в силу на следующий день после окончания текущего периода подписки, а вы сможете продолжить пользоваться бесплатной версией.
Во избежание списания средств, выполните отмену не позднее чем за 24 часа до окончания бесплатного пробного периода или подписки. Изменения вступят в силу на следующий день после окончания текущего периода подписки, а вы сможете продолжить пользоваться бесплатной версией.
Обратите внимание: неиспользованные дни бесплатного пробного периода (если доступны) будут утрачены, если вы приобрете премиум подписку в период действия бесплатного пробного периода.
Политика конфиденциальности: https://datacomprojects.com/api/PrivacyPolicy?bid=com.translatoria.scanandtranslatefree
EULA: https://datacomprojects.com/api/Eula?bid=com.translatoria.scanandtranslatefree
Переводчик с китайского на русский по фото
Китай – популярное направление для путешествий; обилие достопримечательностей и экскурсионных туров, древняя история страны и ее богатое культурное наследие делают Китай особенно привлекательным для туристов. Однако, как же посетить все красоты, и справиться с такими простыми действиями, как поиск дороги, регистрация в отеле и заказ еды в ресторане, если не знаешь языка.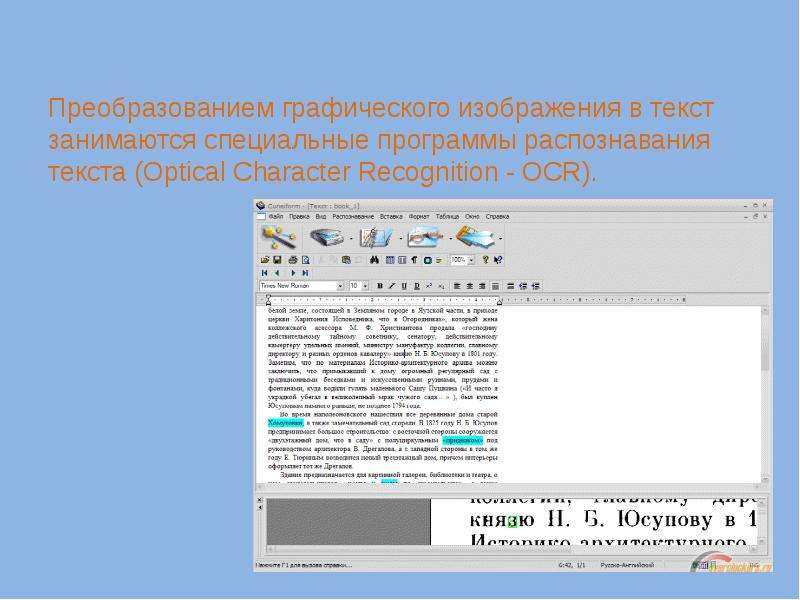 Китайский является одним из самых сложных языков в мире с уникальным алфавитом, и выучить его на простейшем уровне за несколько недель как европейские языки не так-то просто. Справиться с переводом через камеру с китайского на русский помогут специальные приложения-словари.
Китайский является одним из самых сложных языков в мире с уникальным алфавитом, и выучить его на простейшем уровне за несколько недель как европейские языки не так-то просто. Справиться с переводом через камеру с китайского на русский помогут специальные приложения-словари.
Как перевести китайские иероглифы
Технологии не стоят на месте, и теперь путешественникам нет нужды мучиться с карманными переводчиками, которые только запутывают своего владельца и его собеседников. Электронные словари тоже мало помогут делу, особенно непросто с ними приходится новичкам. Но возможность с ходу понять незнакомый язык теперь возможна любому, кто владеет смартфоном. Современные программы для перевода текста с фотографии требуют лишь наличия камеры – владельцу достаточно загрузить картинку в приложение и немного подождать, пока сервис сможет его распознать.
Функция эта новая, поэтому работает нестабильно и требует некоторой сноровки.
 Для того чтобы получить читаемый текст, необходимо сделать качественное изображение, на котором хорошо виден требуемые символы. Чем четче и ярче изображение, тем выше вероятность того, что текст будет переведен максимально близко к смыслу.
Для того чтобы получить читаемый текст, необходимо сделать качественное изображение, на котором хорошо виден требуемые символы. Чем четче и ярче изображение, тем выше вероятность того, что текст будет переведен максимально близко к смыслу.Обратите внимание! Большинство шрифтов приложения для переводов не воспринимают, особенно это касается иероглифов написанных нечетко.
Яндекс Переводчик с картинок в помощь
Несмотря на то, что традиционно большей популярностью пользуется GoogleTranslate, Яндекс Переводчик выполняет работу с китайским языком (и некоторыми европейскими) более корректно и грамотно, чем его более известный собрат.
Перевод с фото при помощи Яндекса можно выполнить только с телефона, для компьютеров такая функция пока отсутствует. Сначала требуется выбрать язык, с которого выполняется работа, в данном случае китайский. Для того чтобы получить результат, нужно просто сделать фотографию, либо выбрать нужное изображение в памяти смартфона, предварительно нажав на иконку «Картинка» в сервисе. Яндекс предложит выделить область, с которой необходимо поработать. Сделав это, нужно нажать Enter и дождаться завершения процесса.
Яндекс предложит выделить область, с которой необходимо поработать. Сделав это, нужно нажать Enter и дождаться завершения процесса.
Перевод в Free Online OCR
Free Online OCR известен как один из первых сайтов, предназначенных для выполнения переводов с фотографии. Сервис сравнительно новый, поэтому корректность результатов с некоторых языков у него заметно страдает. Также сайт пока не имеет полной версии на русском, но доступен на английском.
Важный момент: Качество и верность перевода очень сильно зависят от качества фото и количества текста. Чем меньше слов и чем выше качество фотографии, тем лучше программа сможет распознавать информацию.
Для того чтобы перевести текст с изображения с китайского языка на русский, нужно:
- Загрузить изображение с компьютера, нажав иконку «Выберите файл». Сервис позволяет загрузить сразу несколько картинок;
- На нижней строке сервиса необходимо выбрать язык, с которого выполняется перевод;
- Выполнив предыдущие шаги, нужно нажать на иконку «Upload + OCR»;
- По завершении процесса, сервис предлагает увидеть и оригинальный текст, и готовый перевод.
 Оригинальный текст позволяет пользователю посмотреть, как приложение «видит» шрифт, сравнить его с картинкой и разобраться, где работа выполнена некорректно (изображение и оригинальный текст в этих местах не будут совпадать). Распознавание шрифтов пока оставляет желать лучшего.
Оригинальный текст позволяет пользователю посмотреть, как приложение «видит» шрифт, сравнить его с картинкой и разобраться, где работа выполнена некорректно (изображение и оригинальный текст в этих местах не будут совпадать). Распознавание шрифтов пока оставляет желать лучшего.
Как перевести китайский текст с картинки другими способами?
Помимо Яндекс Переводчика и Free Online OCR (которых может не оказаться под рукой) существует множество сервисов, выполняющих аналогичные задачи. Некоторые из них доступны только со смартфона и компьютера, некоторые работают на всех устройствах.
Для перевода с картинки на русский язык можно воспользоваться:
- Google Translate, который работает аналогично Яндекс Переводчику. Google переиздал свое приложение специально для китайских пользователей с одобрения государства. До некоторых пор в Китае невозможно было воспользоваться ни одной из платформ Google, который был запрещен китайским правительством;
- Программа для распознавания текста и последующий перевод.
 Более трудоёмкий способ, чем предыдущие, но возможно более надежный. Выполняется в два этапа. При помощи Optical Character Recognition (можно скачать в любом магазине бесплатно) из фото извлекается исходный текст, а затем вводится в любой популярный сервис, который переводит.
Более трудоёмкий способ, чем предыдущие, но возможно более надежный. Выполняется в два этапа. При помощи Optical Character Recognition (можно скачать в любом магазине бесплатно) из фото извлекается исходный текст, а затем вводится в любой популярный сервис, который переводит.
Заключение
Пока сервисы для переводов с картинки работают неуверенно: проблемы с качеством фотографий, высокие требования к изображениям и некорректный перевод дают о себе знать. Но уже сейчас на такие сервис есть устойчивый спрос, и они приходят на помощь многим путешественникам. Программы (чтобы перевести с китайского с фото) пока только набирают обороты. Но уже сейчас с уверенностью можно сказать, что через несколько лет они будут пользоваться устойчивой популярностью.
Онлайн-сервисы для распознавания текста / Программное обеспечение
Как только человек изобрел компьютер, он стал переносить в него свои знания. Поскольку главным носителем знаний до появления компьютерной техники были книги, возникла задача – каким образом накопленную информацию можно быстро перевести в “цифру”? Глупо было бы использовать для этого самый простой и очевидный способ перевода книг в цифровой формат – набор вручную. Человечество тысячелетиями накапливало различные тексты, поэтому процесс их повторного “написания” занял бы невероятно много времени. Для решения этой задачи необходимо было найти какой-то простой и эффективный способ автоматизации процесса повторного набора текста. Так возникли различные технологии оптического распознавания текста или сокращенно OCR (optical character recognition). В наши дни с процедурой перевода машинописного листа в текстовый документ знаком каждый студент и школьник. Печатный текст сканируется (или фотографируется), затем с помощью специального программного обеспечения компьютер анализирует снимок текста, выделяет на изображении отдельные элементы и создает новый документ, в который заносит все распознанные буквы и символы.
Поскольку главным носителем знаний до появления компьютерной техники были книги, возникла задача – каким образом накопленную информацию можно быстро перевести в “цифру”? Глупо было бы использовать для этого самый простой и очевидный способ перевода книг в цифровой формат – набор вручную. Человечество тысячелетиями накапливало различные тексты, поэтому процесс их повторного “написания” занял бы невероятно много времени. Для решения этой задачи необходимо было найти какой-то простой и эффективный способ автоматизации процесса повторного набора текста. Так возникли различные технологии оптического распознавания текста или сокращенно OCR (optical character recognition). В наши дни с процедурой перевода машинописного листа в текстовый документ знаком каждый студент и школьник. Печатный текст сканируется (или фотографируется), затем с помощью специального программного обеспечения компьютер анализирует снимок текста, выделяет на изображении отдельные элементы и создает новый документ, в который заносит все распознанные буквы и символы.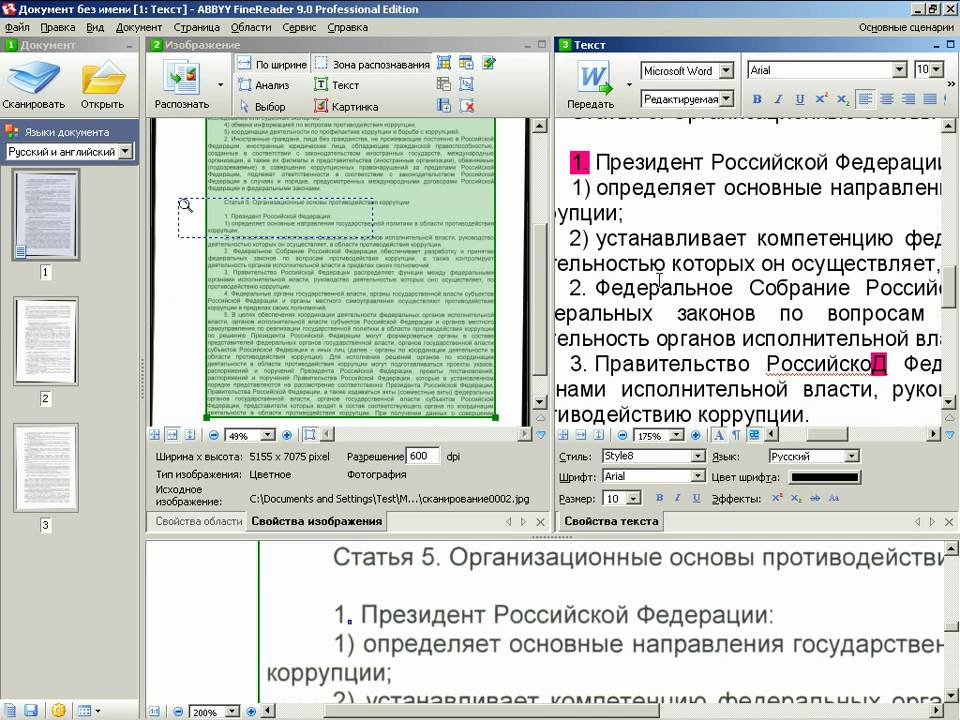 Такой документ, как правило, является редактируемым, благодаря чему можно исправлять ошибки машинного распознавания и работать с ним как с набранным текстом. В зависимости от сложности исходного текста и качества отсканированного изображения, процесс обработки документа OCR-приложением занимает больше или меньше времени. К счастью, сегодня процедура перевода набранного текста в формат электронного документа занимает намного меньше времени, чем несколько лет назад – аппаратные возможности компьютеров за последние десять лет заметно увеличились, а благодаря постоянным усовершенствованиям алгоритмов анализа изображения процент ошибок стал намного меньше. Более того, теперь распознавание текста можно доверить даже онлайновым сервисам, преимущества которых перед обычными настольными приложениями очевидны – не нужно раскошеливаться на дорогостоящее ПО и тратить время на установку приложения. Наконец, используя для распознавания онлайновые средства, можно получить редактируемый текст из снимка даже на таких компьютерах, где просто нет возможности устанавливать программы, например, на публичном ПК в библиотеке.
Такой документ, как правило, является редактируемым, благодаря чему можно исправлять ошибки машинного распознавания и работать с ним как с набранным текстом. В зависимости от сложности исходного текста и качества отсканированного изображения, процесс обработки документа OCR-приложением занимает больше или меньше времени. К счастью, сегодня процедура перевода набранного текста в формат электронного документа занимает намного меньше времени, чем несколько лет назад – аппаратные возможности компьютеров за последние десять лет заметно увеличились, а благодаря постоянным усовершенствованиям алгоритмов анализа изображения процент ошибок стал намного меньше. Более того, теперь распознавание текста можно доверить даже онлайновым сервисам, преимущества которых перед обычными настольными приложениями очевидны – не нужно раскошеливаться на дорогостоящее ПО и тратить время на установку приложения. Наконец, используя для распознавания онлайновые средства, можно получить редактируемый текст из снимка даже на таких компьютерах, где просто нет возможности устанавливать программы, например, на публичном ПК в библиотеке. Начнем с онлайнового сервиса компании ABBYY. Нет ничего удивительного в том, что она использует в качестве системы для распознавания текста популярную программу FineReader. В рекламе этот продукт не нуждается – сегодня это приложение можно считать одним из лучших вариантов OCR. Причин успешного продвижения этой программы очень много. Прежде всего, это отшлифованный алгоритм идентификации печатных символов. Движок самой популярной системы оптического распознавания текста, FineReader, совершенствовался годами, механизм анализа изображения улучшался от версии к версии. В программу вносились различные изменения и улучшения, которые уменьшали количество нераспознанных или некорректно определенных символов при обработке сканированного изображения. FineReader включает в себя множество средств и вспомогательных инструментов, которые дают возможность выполнить тонкую настройку программы, улучшить качество исходного изображения, определить тип распознаваемых символов, установить области для обработки и т.
Начнем с онлайнового сервиса компании ABBYY. Нет ничего удивительного в том, что она использует в качестве системы для распознавания текста популярную программу FineReader. В рекламе этот продукт не нуждается – сегодня это приложение можно считать одним из лучших вариантов OCR. Причин успешного продвижения этой программы очень много. Прежде всего, это отшлифованный алгоритм идентификации печатных символов. Движок самой популярной системы оптического распознавания текста, FineReader, совершенствовался годами, механизм анализа изображения улучшался от версии к версии. В программу вносились различные изменения и улучшения, которые уменьшали количество нераспознанных или некорректно определенных символов при обработке сканированного изображения. FineReader включает в себя множество средств и вспомогательных инструментов, которые дают возможность выполнить тонкую настройку программы, улучшить качество исходного изображения, определить тип распознаваемых символов, установить области для обработки и т. д. Онлайновый сервис является бесплатным проектом, который дает возможность пользователям оценить точность работы FineReader. Одно из его главных достоинств – поддержка большого количества определяемых языков (всего доступно 37 языков). Для того чтобы воспользоваться сервисом, необходимо пройти регистрацию. Поскольку этот проект носит отчасти рекламный характер, возможности распознавания текста в нем существенно ограничены. Во-первых, анализ изображения происходит в полностью автоматическом режиме. Пользователь может лишь указать язык распознавания и включить опцию, которая позволит получить ссылку на результат распознавания на введенный адрес электронной почты. Во-вторых, объем файла, загружаемого на сервер, не должен превышать 10 мегабайт. Но самое неприятное ограничение – небольшое количество документов, которое можно распознать. Зайдя под одной учетной записью, можно обработать не более десяти файлов. Однако и это, согласитесь, неплохо. FineReader Online может также обрабатывать тексты, содержащие любые комбинации поддерживаемых языков.
д. Онлайновый сервис является бесплатным проектом, который дает возможность пользователям оценить точность работы FineReader. Одно из его главных достоинств – поддержка большого количества определяемых языков (всего доступно 37 языков). Для того чтобы воспользоваться сервисом, необходимо пройти регистрацию. Поскольку этот проект носит отчасти рекламный характер, возможности распознавания текста в нем существенно ограничены. Во-первых, анализ изображения происходит в полностью автоматическом режиме. Пользователь может лишь указать язык распознавания и включить опцию, которая позволит получить ссылку на результат распознавания на введенный адрес электронной почты. Во-вторых, объем файла, загружаемого на сервер, не должен превышать 10 мегабайт. Но самое неприятное ограничение – небольшое количество документов, которое можно распознать. Зайдя под одной учетной записью, можно обработать не более десяти файлов. Однако и это, согласитесь, неплохо. FineReader Online может также обрабатывать тексты, содержащие любые комбинации поддерживаемых языков. При этом сервис не позволяет выбирать более трех языков распознавания для одного документа. Разработчики мотивируют это тем, что подобная функция существенно замедлила бы процесс распознавания текста. Готовый результат распознавания текста может быть сохранен в один из форматов – MS Word (.doc), MS Excel (.xls), PDF, PDF/A, RTF и TXT. В принципе, сервис справляется с поставленной задачей и определяет текст. Однако, справедливости ради, следует сказать, что даже очень хорошее качество исходного изображения не дает стопроцентной гарантии распознавания. Даже такое “идеальное” изображение, как скриншот всплывающей подсказки на странице сервиса, FineReader Online распознал с ошибками. ocrNow! – британский сервис, который также использует в качестве системы для распознавания текста FineReader. Уже на этапе регистрации можно выбрать формат, в котором по умолчанию будут сохранены данные – RTF, PDF, XLS, XLM, TXT или Web Archive. Изменить формат можно при загрузке каждого нового файла.
При этом сервис не позволяет выбирать более трех языков распознавания для одного документа. Разработчики мотивируют это тем, что подобная функция существенно замедлила бы процесс распознавания текста. Готовый результат распознавания текста может быть сохранен в один из форматов – MS Word (.doc), MS Excel (.xls), PDF, PDF/A, RTF и TXT. В принципе, сервис справляется с поставленной задачей и определяет текст. Однако, справедливости ради, следует сказать, что даже очень хорошее качество исходного изображения не дает стопроцентной гарантии распознавания. Даже такое “идеальное” изображение, как скриншот всплывающей подсказки на странице сервиса, FineReader Online распознал с ошибками. ocrNow! – британский сервис, который также использует в качестве системы для распознавания текста FineReader. Уже на этапе регистрации можно выбрать формат, в котором по умолчанию будут сохранены данные – RTF, PDF, XLS, XLM, TXT или Web Archive. Изменить формат можно при загрузке каждого нового файла. Кроме этого, есть возможность получить текст по почте. Стоит отметить, что результаты могут быть запакованы в ZIP-архив, благодаря чему время на загрузку полученного файла сократится. Сервис поддерживает загрузку изображений в форматах TIF, PNG и JPG (JPEG), а также PDF. Кроме этого, можно загрузить ZIP-архивы, содержащие файлы поддерживаемых типов, и они будут распакованы и обработаны автоматически. ZIP-архив удобен не только тем, что позволяет уменьшить размер файлов, которые необходимо загрузить на сервер, но и тем, что благодаря ему можно загрузить несколько файлов за один раз. ocrNow! работает с шестнадцатью языками, в том числе с документами на русском английском, французском, чешском, испанском, итальянском. Выбор языка осуществляется при загрузке файла. Даже если не указать язык, сервис попытается определить его автоматически, правда, не исключено, что он ошибется, поэтому лучше все же выбрать язык вручную. Стоит заметить, что выбрать можно лишь один язык. Каждому зарегистрированному пользователю предоставляется два бесплатных кредита, которые можно использовать для распознавания двух страниц формата A4.
Кроме этого, есть возможность получить текст по почте. Стоит отметить, что результаты могут быть запакованы в ZIP-архив, благодаря чему время на загрузку полученного файла сократится. Сервис поддерживает загрузку изображений в форматах TIF, PNG и JPG (JPEG), а также PDF. Кроме этого, можно загрузить ZIP-архивы, содержащие файлы поддерживаемых типов, и они будут распакованы и обработаны автоматически. ZIP-архив удобен не только тем, что позволяет уменьшить размер файлов, которые необходимо загрузить на сервер, но и тем, что благодаря ему можно загрузить несколько файлов за один раз. ocrNow! работает с шестнадцатью языками, в том числе с документами на русском английском, французском, чешском, испанском, итальянском. Выбор языка осуществляется при загрузке файла. Даже если не указать язык, сервис попытается определить его автоматически, правда, не исключено, что он ошибется, поэтому лучше все же выбрать язык вручную. Стоит заметить, что выбрать можно лишь один язык. Каждому зарегистрированному пользователю предоставляется два бесплатных кредита, которые можно использовать для распознавания двух страниц формата A4.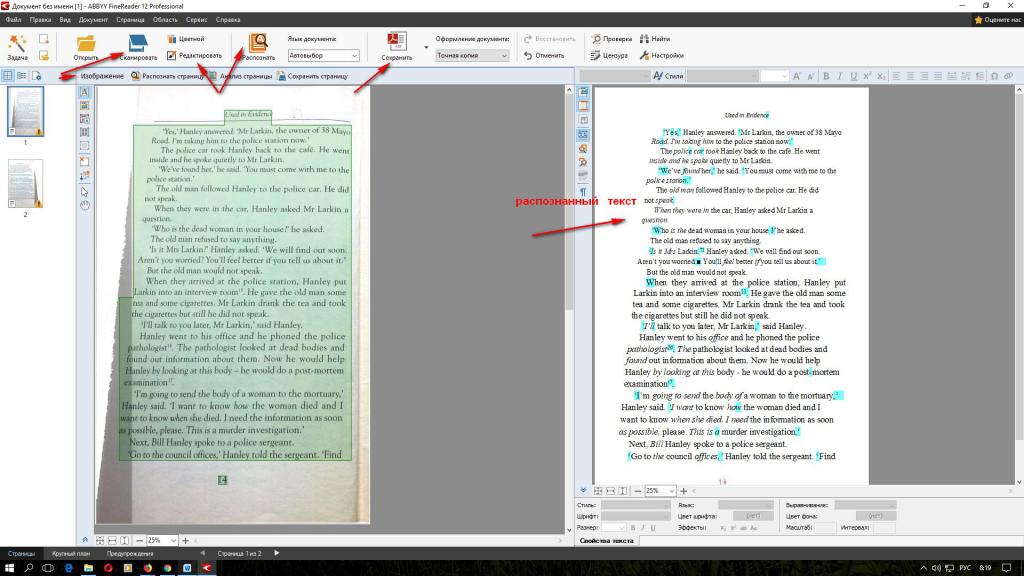 Если необходимо работать с большим количеством данных, необходимо купить кредиты. Их стоимость зависит от того, сколько кредитов вы решите приобрести за один раз. Например, если купить 20 кредитов, то распознавание одного листа A4 обойдется в 0,1 фунта стерлингов (около 4,6 рубля), а если приобрести сразу 500, то стоимость распознавания одного листа снизится примерно до 2,96 рубля. Создатели сервиса предлагают специальную утилиту, позволяющую использовать его совместно с Apple iPhone. При помощи этой программы можно фотографировать документы, а затем отсылать их на сервис и получать результаты. Бесплатная версия этой программы дает возможность обработать десять фотографий, а коммерческий вариант, снимающий это ограничение, обойдется в 14 долл. Пользователям, которые часто обращаются к услугам сервиса со своего настольного компьютера, предлагается скачать утилиту Unimessage Solo, предназначенную для сканирования файлов. Особенность этой программы в том, что в ней реализована интеграция с сервисом ocrNow! Кроме этого, созданные с ее помощью файлы можно загрузить на Facebook.
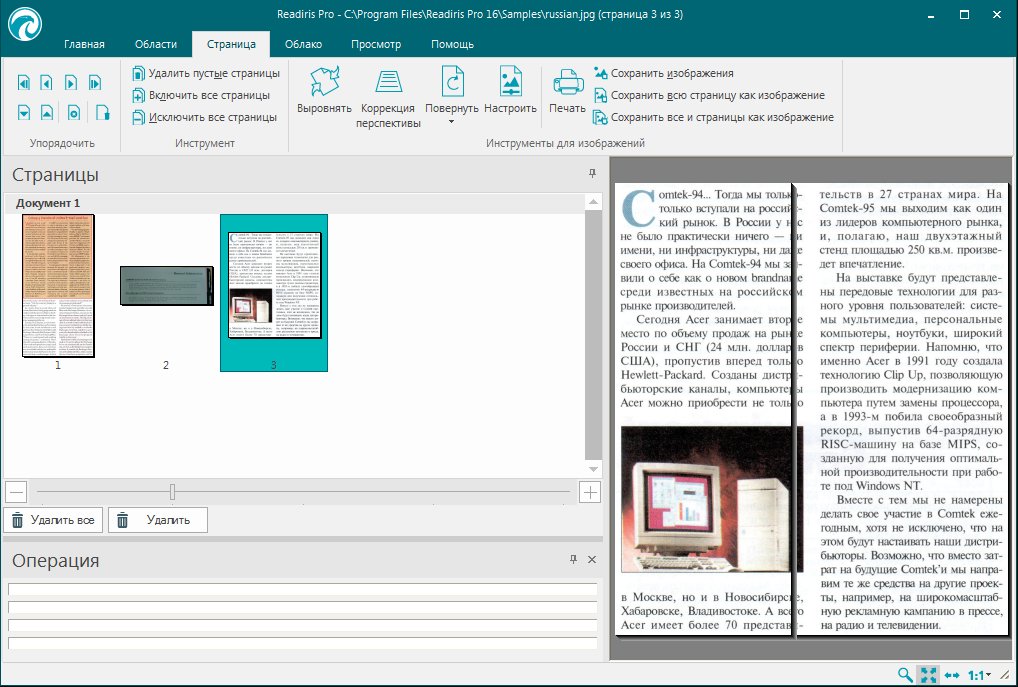
Если необходимо работать с большим количеством данных, необходимо купить кредиты. Их стоимость зависит от того, сколько кредитов вы решите приобрести за один раз. Например, если купить 20 кредитов, то распознавание одного листа A4 обойдется в 0,1 фунта стерлингов (около 4,6 рубля), а если приобрести сразу 500, то стоимость распознавания одного листа снизится примерно до 2,96 рубля. Создатели сервиса предлагают специальную утилиту, позволяющую использовать его совместно с Apple iPhone. При помощи этой программы можно фотографировать документы, а затем отсылать их на сервис и получать результаты. Бесплатная версия этой программы дает возможность обработать десять фотографий, а коммерческий вариант, снимающий это ограничение, обойдется в 14 долл. Пользователям, которые часто обращаются к услугам сервиса со своего настольного компьютера, предлагается скачать утилиту Unimessage Solo, предназначенную для сканирования файлов. Особенность этой программы в том, что в ней реализована интеграция с сервисом ocrNow! Кроме этого, созданные с ее помощью файлы можно загрузить на Facebook. Данный сервис является коммерческим. Для работы с ним необходимо приобретать кредиты, каждый кредит – возможность распознавания одной страницы документа. Однако даже в демонстрационном режиме с его помощью можно переводить небольшие фрагменты текста. Сервис предлагает очень удобную загрузку файлов – на сервер можно загружать одновременно несколько изображений, упаковав их в ZIP-архив. Максимальный размер файла – 20 мегабайт, но можно использовать и файлы большего размера, однако для получения такой возможности необходимо связаться с администрацией сервиса. В качестве исходного формата графического файла можно использовать TIFF (поддерживаются в том числе и многостраничные документы), JPEG/JPG, BMP, PCX, PNG, GIF, PDF. Если с помощью данного сервиса распознается многостраничный документ, например, PDF, можно указать только отдельные страницы для распознавания. Для этого в настройках распознавания необходимо установить флажок напротив “Многостраничный документ” и в поле для диапазона страниц указать необходимые страницы через запятую (или диапазон страниц через дефис).
Данный сервис является коммерческим. Для работы с ним необходимо приобретать кредиты, каждый кредит – возможность распознавания одной страницы документа. Однако даже в демонстрационном режиме с его помощью можно переводить небольшие фрагменты текста. Сервис предлагает очень удобную загрузку файлов – на сервер можно загружать одновременно несколько изображений, упаковав их в ZIP-архив. Максимальный размер файла – 20 мегабайт, но можно использовать и файлы большего размера, однако для получения такой возможности необходимо связаться с администрацией сервиса. В качестве исходного формата графического файла можно использовать TIFF (поддерживаются в том числе и многостраничные документы), JPEG/JPG, BMP, PCX, PNG, GIF, PDF. Если с помощью данного сервиса распознается многостраничный документ, например, PDF, можно указать только отдельные страницы для распознавания. Для этого в настройках распознавания необходимо установить флажок напротив “Многостраничный документ” и в поле для диапазона страниц указать необходимые страницы через запятую (или диапазон страниц через дефис). Если указать, скажем “4,13”, сервис распознает только четвертую и тринадцатую страницы. В демонстрационном режиме сервис OnlineOCR.ru распознаёт не весь текст, а только его часть. Всего сервис поддерживает 28 языков, включая русский, английский, белорусский, венгерский, голландский, греческий, датский, испанский, латвийский, латинский, немецкий, польский, шведский, финский, французский, украинский и др. Сервис позволяет хранить файлы с результатом распознавания в виртуальном рабочем кабинете online, редактировать, отправлять их по почте и выводить на печать. Проект NewOCR.com не требует ни регистрации, ни дополнительных денежных трат со стороны пользователя. Сервис имеет минималистический интерфейс, и его настройки сводятся к выбору языка. Если загруженное изображение имеет неправильную ориентацию, например, повернуто в процессе сканирования на 90 градусов, в выпадающем меню сервиса можно установить угол поворота картинки. Качество обработки графического файла оставляет желать лучшего – конечный документ содержит многочисленные ошибки распознавания, поэтому вряд ли стоит использовать этот сервис для обработки большого числа страниц.
Если указать, скажем “4,13”, сервис распознает только четвертую и тринадцатую страницы. В демонстрационном режиме сервис OnlineOCR.ru распознаёт не весь текст, а только его часть. Всего сервис поддерживает 28 языков, включая русский, английский, белорусский, венгерский, голландский, греческий, датский, испанский, латвийский, латинский, немецкий, польский, шведский, финский, французский, украинский и др. Сервис позволяет хранить файлы с результатом распознавания в виртуальном рабочем кабинете online, редактировать, отправлять их по почте и выводить на печать. Проект NewOCR.com не требует ни регистрации, ни дополнительных денежных трат со стороны пользователя. Сервис имеет минималистический интерфейс, и его настройки сводятся к выбору языка. Если загруженное изображение имеет неправильную ориентацию, например, повернуто в процессе сканирования на 90 градусов, в выпадающем меню сервиса можно установить угол поворота картинки. Качество обработки графического файла оставляет желать лучшего – конечный документ содержит многочисленные ошибки распознавания, поэтому вряд ли стоит использовать этот сервис для обработки большого числа страниц. Этот недостаток несколько смягчает то обстоятельство, что проект поддерживает работу с 29 языками (включая русский). Распознавать можно изображения в форматах JPEG, PNG, GIF, BMP, а также многостраничные файлы TIFF. Размер файлов не должен превышать пять мегабайт, а для многостраничных PDF-документов лимит составляет 20 мегабайт. После обработки отсканированного изображения сервис продемонстрирует результат в отдельном поле, рядом с копией загруженного изображения. Распознанный текст можно экспортировать в формат .doc или .txt. Этот сервис можно использовать бесплатно, причем регистрация не требуется. Для защиты от спама используется контрольное изображение (Captcha). Однако, выбрав этот сервис для обработки своих файлов, следует учитывать ограничения, которые касаются обрабатываемых изображений. Так, размер загружаемых на сервер файлов ограничен двумя мегабайтами. Еще одно ограничение сервиса, которое касается загружаемых файлов, – разрешение каждого из графических изображений не должно превышать 5000 точек по ширине.
Этот недостаток несколько смягчает то обстоятельство, что проект поддерживает работу с 29 языками (включая русский). Распознавать можно изображения в форматах JPEG, PNG, GIF, BMP, а также многостраничные файлы TIFF. Размер файлов не должен превышать пять мегабайт, а для многостраничных PDF-документов лимит составляет 20 мегабайт. После обработки отсканированного изображения сервис продемонстрирует результат в отдельном поле, рядом с копией загруженного изображения. Распознанный текст можно экспортировать в формат .doc или .txt. Этот сервис можно использовать бесплатно, причем регистрация не требуется. Для защиты от спама используется контрольное изображение (Captcha). Однако, выбрав этот сервис для обработки своих файлов, следует учитывать ограничения, которые касаются обрабатываемых изображений. Так, размер загружаемых на сервер файлов ограничен двумя мегабайтами. Еще одно ограничение сервиса, которое касается загружаемых файлов, – разрешение каждого из графических изображений не должно превышать 5000 точек по ширине. Кроме этого, Free-OCR.com устанавливает лимит на количество обработанных документов. В час можно загрузить не более десяти изображений. На данный момент сервис не умеет распознавать многостраничные документы PDF или TIFF, поэтому при обработке таких файлов распознается только первая страница. Сервис позволяет обрабатывать страницы с многочисленными столбцами текста. В настройках Free-OCR.com нельзя выбрать более одного языка, поэтому, если попробовать распознать, например, русский текст с английскими терминами, ошибок будет предостаточно. Общее количество поддерживаемых языков, которые можно выбирать для распознавания, довольно много – двадцать девять, в том числе и русский. Качество распознавания документов удовлетворительное.
Кроме этого, Free-OCR.com устанавливает лимит на количество обработанных документов. В час можно загрузить не более десяти изображений. На данный момент сервис не умеет распознавать многостраничные документы PDF или TIFF, поэтому при обработке таких файлов распознается только первая страница. Сервис позволяет обрабатывать страницы с многочисленными столбцами текста. В настройках Free-OCR.com нельзя выбрать более одного языка, поэтому, если попробовать распознать, например, русский текст с английскими терминами, ошибок будет предостаточно. Общее количество поддерживаемых языков, которые можно выбирать для распознавания, довольно много – двадцать девять, в том числе и русский. Качество распознавания документов удовлетворительное.⇡#Заключение
Далеко не все услуги онлайновых сервисов для распознавания текста предоставляются бесплатно. Однако цена, которую просят их создатели, заметно ниже стоимости специализированного ПО. Естественно, если вам необходимо распознавать десятки документов ежедневно, то платить создателям онлайнового сервиса для вас вряд ли будет выгодно – гораздо дешевле будет один раз заплатить за лицензию программы. Но если вы пользуетесь подобными средствами лишь время от времени, то проще заплатить за распознавание необходимого числа страниц или попытаться обойтись полностью бесплатными сервисами.
Но если вы пользуетесь подобными средствами лишь время от времени, то проще заплатить за распознавание необходимого числа страниц или попытаться обойтись полностью бесплатными сервисами.Если Вы заметили ошибку — выделите ее мышью и нажмите CTRL+ENTER.
Преобразование Изображений В Текст – Онлайн-Распознавание Текста
Нередко мы сталкиваемся с ситуацией, когда требуется извлечь и повторно использовать текст, содержащийся в сканированном документе или изображении. Такие изображения могут иметь различные форматы, включая форматы PNG, JPG, GIF, BMP, что иногда может стать проблемой, поскольку обычно мы не можем просто выделить и скопировать текст из необработанного изображения. Здесь на помощь приходит технология оптического распознавания символов.
Извлечение текста из JPG и других форматов изображений с помощью бесплатного OCR онлайн-распознавания текста
Aspose OCR Reader предоставляет собой решение для обработки изображений и распознавания текста. Программа интерпретирует изображения и превращает изображения в текстовые данные, готовые для поиска, копирования-вставки и редактирования.
Программа интерпретирует изображения и превращает изображения в текстовые данные, готовые для поиска, копирования-вставки и редактирования.
Если вам нужно подготовить документы к дальнейшей текстовой обработке, воспользуйтесь нашим бесплатным сервисом для распознавания текста. Он обладает мощными возможностями и поддерживает более 100 языков, включая японский, китайский и хинди. Служба распознавания текста от компании Aspose преобразует ваши изображения в текст быстро, эффективно и точно.
Надежный OCR Reader. Конвертер изображений в текст
Наш сервис выполняет функцию сканера документов, позволяет читать текст из картинок и сохранять результаты в различных форматах. Перевести картинку в текст очень просто. Преобразуйте PNG, BMP, GIF, TIFF, JPG в текст, доступный для поиска и редактирования.
Преобразовать изображение в текст
Наш конвертер изображений в текст – бесплатный инструмент распознавания текста, который может захватывать и читать любой текст на фотографиях. Используйте его как онлайн-конвертер изображений в Word, для извлечения нужных текстов и сохранения результатов в редактируемых Word или PDF-файлах с возможностью поиска.
Используйте его как онлайн-конвертер изображений в Word, для извлечения нужных текстов и сохранения результатов в редактируемых Word или PDF-файлах с возможностью поиска.
Платформа Aspose.Words
Это бесплатное онлайн-приложение OCR предоставляется Aspose.Words. Мы предоставляем нашим клиентам высокопроизводительные технологии обработки документов и надежные программные решения для автоматизации делопроизводства, доступные в операционных системах Windows, iOS, Linux и Android: C#, Java, C++.
Как онлайн распознать текст с картинки и сохранить его
Что делать, если надо распознать текст с картинки или сканированный текст, а подходящей программы на компьютере нет? Устанавливать специальный софт? Но это долго, и большинство их них платны.
i2OCR (Optical Character Recognition) – 100% бесплатный онлайн сервис, который быстро распознает текст с любого изображения и позволит скачать его в виде файла. В качестве источника можно использовать страницы книг, факсы, рецепты, фотографии, скриншоты и пр.

Основные возможности i2OCR
- Для распознавания можно загружать как сами документы с компьютера, так и указывать ссылки на них в интернет
- Форматы исходников: JPG, PNG, BMP, TIF, PBM, PGM, PPM
- Поддержка более 60 языков, среди которых есть английский, русский, украинский, японский, китайский и пр.
- Распознанный текст можно сохранить и скачать в форматах: Text (txt), Microsoft Word (doc), Adobe PDF (pdf), HTML
- Поддержка многоколоночной верстки
- Редактирование распознанного текста в Google Docs или его онлайн перевод при помощи переводчиков Google или Bing
Как видим, возможности для бесплатного сервиса более чем впечатляющие и вполне достаточны для обычных нужд. Теперь рассмотрим как именно распознать текст с картинки при помощи i2OCR.
Как работать с сервисом
Всё делается очень быстро в три простых этапа:
- Загрузка файла или указание ссылки на него в интернет
- Указание языка текста на картинке
- Нажатие кнопки «Extract Text»
Для проверки качества работы сервиса я выбрал следующие изображение со сканированным текстом (качество шрифта не самое лучшее):
Вот такой результат я получил в итоге:
Всё распознано идеально, без ошибок кроме символа «№».
После того как текст будет распознан, появятся кнопки дополнительных опций:
- «Download» — скачать документ в одном из форматов
- «Translate» — перевести на другой язык
- «Edit Google Docs» — внести правки в онлайн редакторе
Ограничения сервиса
Все ограничения сервиса носят лишь системный характер и состоят в следующем:
- размер загружаемого изображения не должен превышать 10 MB
- сервис не распознает рукописный текст
i2OCR не имеет ограничений на количество загружаемых файлов и на число скачиваний! Все возможности сервиса абсолютно бесплатны и доступны без регистрации!
Итог
При помощи сервиса i2OCR можно бесплатно распознать онлайн текст с картинки (скана, фото и пр.), сделать его перевод на другой язык, отредактировать, сохранить и скачать в одном из форматов (txt, doc, pdf, html). Всё делается быстро, четко и без установки на ПК дополнительных программ. Сервис однозначно должен быть в закладках у каждого!
P. S. Рекомендую также прочитать обзор двух лучших сервисов онлайн конвертирования речи в текст.
S. Рекомендую также прочитать обзор двух лучших сервисов онлайн конвертирования речи в текст.
Автор статьи: Сергей Сандаков, 40 лет.
Программист, веб-мастер, опытный пользователь ПК и Интернет.
Tesseract-OCR-03-Распознавание текста в картинках – Русские Блоги
В этой статье рассказывается об использовании Tesseract-OCR для распознавания текста изображения. При распознавании рукописного текста степень точности может достигать 90%. После обучения уровень точности чрезвычайно высок. Представленное здесь распознавание текста изображения может распознавать английский, числа, китайский и т. Д.
Распознавание текста изображений Tesseract-OCR
- Tesseract:Механизм OCR с открытым исходным кодом (оптическое распознавание символов, оптическое распознавание символов), разработанный HP Labs и поддерживаемый Google. Мы можем постоянно обучать библиотеку, чтобы постоянно улучшать способность изображений преобразовывать текст; если команде это очень нужно, ее также можно использовать В качестве шаблона разработайте движок OCR, который соответствует вашим потребностям.
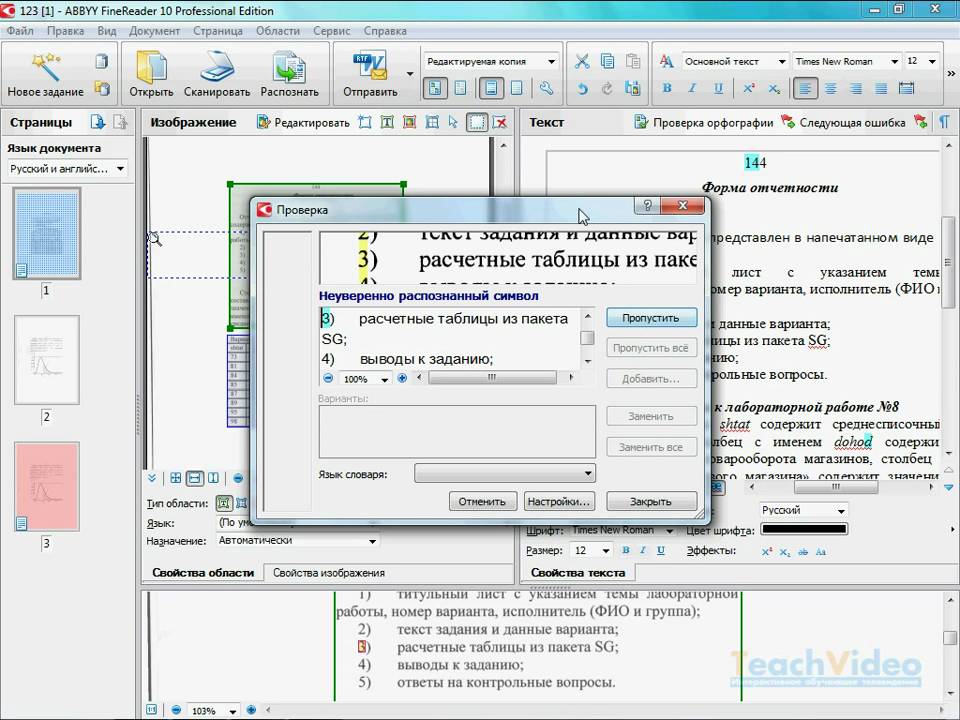
- Если вы не установили Tesseract-OCR, обратитесь к:
- Конечно, конфигурационная среда также была загружена из указанной выше статьи. Шаги очень подробны.
Основная тема Распознавание текста изображения
- Я собрал несколько материалов, мне лень их найти и могу скачать напрямую:
- https://pan.baidu.com/s/10XxYJa19KIa8-ENdQkhhHg
- Здесь я выложил картинку: D: \ p
- Нам нужно войти в этот каталог в cmd
- Используйте имя каталога cd для входа в каталог
- Используйте cd .., чтобы вернуться в предыдущий каталог.
Используйте команду Tesseract:
имя файла tesseract имя сохраненного txt файла -l eng пример:tesseract num1.jpg num1
Здесь -l eng для установки языка, если не написано, по умолчанию используется eng, то есть английский
- Результат:
- Заметка:
- 1. Если здесь сообщается об ошибке, Tesseract не является внутренней или внешней командой, то есть переменная среды не настроена для справки:
https://blog.csdn.net/qq_40147863/article/details/82285920
- 2. Если распознанный текст изображения на китайском языке, будет предложено 0 текст
- 1. Если здесь сообщается об ошибке, Tesseract не является внутренней или внешней командой, то есть переменная среды не настроена для справки:
Распознавать рукописный английский
- Узнай картинку eng2.jpg
- Команда ввода: сохранить как eng2.txt
- Сравним результаты:
- Вот неправильное распознавание букв, неправильное распознавание ig как S, включая указанное выше число, тоже неверное
- Это направление, в котором мы должны работать
Узнай китайский
- Чтобы распознать китайский язык, достаточно изменить параметр -l на chi_sim Например:
Для изображения chi1.jpg с текстом на китайском языке введите путь к изображению и используйте следующую команду:
tesseract chi1.jpg chi1 -l chi_sim
Стиль изображения:
- Выполнение заказа:
- результат операции:
Распознавать английские и смешанные цифровые коды подтверждения
- Например:
Для изображения timg.
 jpg введите путь к изображению и используйте следующую команду:
jpg введите путь к изображению и используйте следующую команду:tesseract timg.jpg timg
Стиль изображения:
- Выполнение заказа:
- результат операции:
Обучение тессеракту:
- Мы можем добиться более высокой точности распознавания за счет многократного обучения и большего количества данных для обучения.
- Используем обучение jTessBoxEditor
- В связи с установкой и обучением jTessBoxEditor контента стало больше, поэтому я организую другую статью
Ссылки на другие статьи:Эссе Тессеракта
-Это примечание не разрешает никому или организациям перепечатывать
Китайский упрощенный и традиционный OCR (онлайн и бесплатно) – Convertio
Преобразование отсканированных документов и изображений на упрощенном китайском традиционном языке в редактируемые форматы вывода Word, Pdf, Excel и Txt (текст)
Доступных страниц: 10 (Вы уже использовали 0 страниц)
Если вам нужно узнать больше страниц, зарегистрируйтесь
Загрузите файлы для распознавания или перетащите их на эту страницу
Поддерживаемые форматы файлов:
pdf, jpg, bmp, gif, jp2, jpeg, pbm, pcx, pgm, png, ppm, tga, tiff, wbmp
Распознавать
Как распознать текст на китайском языке?
Шаг 1
Загрузить изображения или PDF-файлы
Выберите файлы с компьютера, Google Диска, Dropbox, URL-адреса или перетащив его на страницу
Шаг 2
Выбрать выходной формат
Выбрать. doc или любой другой формат, который вам нужен в результате (поддерживается более 10 текстовых форматов)
doc или любой другой формат, который вам нужен в результате (поддерживается более 10 текстовых форматов)
Шаг 3
Преобразовать и скачать
Нажмите кнопку «Распознать», и вы сразу сможете загрузить распознанный текстовый файл на китайском языке.
Что это за персонаж? 5 приложений для распознавания китайских иероглифов
Приходилось ли вам когда-нибудь заказывать из меню китайское без изображений?
В Китае вы обнаружите, что во многих местных заведениях есть свои списки продуктов питания на стене, без перевода на английский язык и без изображений для их сопровождения.
Несмотря на то, что я изучал мандарин большую часть своего детства и знаю множество ресторанных фраз, у меня все еще возникают проблемы с определением некоторых продуктов питания здесь и там.
И это не похоже на то, что у меня есть все время в мире, чтобы выяснить специфику каждого овощного блюда, поскольку очередь передо мной начинает двигаться все быстрее и быстрее! Чувствуя давление толпы в таких ситуациях, я всегда заказываю свою традиционную китайскую еду 牛肉 牛肉 面 ( là niú ròu miàn ), которая представляет собой острую говяжью лапшу.
К счастью, я загрузил приложения для распознавания китайских иероглифов, , которые изменили правила игры. Они помогли мне отклониться от моего обычного. В конце концов, я могу съесть не так много острой говяжьей лапши.
Загрузить: Это сообщение в блоге доступно в виде удобного и портативного PDF-файла, который вы можете можно взять куда угодно. Щелкните здесь, чтобы получить копию. (Скачать)
Изучив различные приложения для перевода, удивительно, что не все из них имеют оптическое распознавание символов, , которое позволяет делать фотографии персонажей или загружать снимки экрана.
Оптическое распознавание символов, или OCR, – это то, чем могут воспользоваться все изучающие китайский язык, независимо от того, делаем ли мы заказ в местном ресторане, путешествуем по улице или просто задаемся вопросом, о чем весь окружающий нас китайский текст.
Существует несколько типов приложений, которые поддерживают распознавание текста. У некоторых есть полные словарные функции, в то время как другие – только приложения для перевода OCR. Некоторые из них оснащены дополнительными принадлежностями, такими как карточки, которые позволяют использовать приложение в качестве учебного пособия или перевода аудио в текст.
Ищете приложение, в котором есть множество интересных способов выучить китайские иероглифы? Оцените FluentU!
FluentU берет реальные видео – например, музыкальные видеоклипы, трейлеры к фильмам, новости и вдохновляющие выступления – и превращает их в индивидуальные уроки изучения языка.
Вы найдете широкий спектр современных видео, охватывающих все разные интересы и уровни, как вы можете видеть здесь:
FluentU делает эти видеоролики на китайском языке доступными с помощью интерактивных субтитров. Вы можете нажать на любое слово, чтобы мгновенно его найти.
Все слова имеют тщательно написанные определения и примеры, которые помогут вам понять, как используется слово. Нажмите, чтобы добавить слова, которые вы хотите просмотреть, в список слов.
На странице описания вы можете получить доступ к интерактивным стенограммам на вкладке Dialogue или просмотреть слова и фразы в Vocab .
Тесты FluentU превращают каждое видео в урок изучения языка.Вы всегда можете провести пальцем влево или вправо, чтобы увидеть больше примеров изучаемого слова.
Самое приятное то, что FluentU всегда следит за вашим обучением. Он настраивает тесты, чтобы сосредоточить внимание на областях, требующих внимания, и напоминает вам, когда пришло время повторить то, что вы узнали. Другими словами, вы получите 100% персонализированный опыт.
Попробуйте FluentU в своем браузере или, что еще лучше, загрузите приложение FluentU для iOS или Android прямо сейчас!
Пока вы изучаете китайские иероглифы, эти пять приложений для распознавания китайских иероглифов позаботятся о том, чтобы вы ничего не пропустили.
Китайский словарь Pleco
iOS | Android
Цена: Бесплатно с покупками из приложения
Перевод: OCR, рукописный ввод, текст
Одно из самых популярных приложений для перевода, Pleco Chinese Dictionary – лучшее приложение для языкового перевода. Лидер среди приложений языковых словарей, возможности включают в себя устройство чтения документов , инструмент для изучения карточек и диаграммы порядка штрихов.
Еще одна вещь, которая ставит его выше остальных? Нет объявлений. Да, вы правильно прочитали. Без рекламы!
Хотя на самом деле это не является недостатком, можно быть ошеломленным объемом информации, предоставляемой при поиске определенного слова или сканировании текста с помощью камеры. Некоторым людям просто нужно приложение, которое предоставляет перевод, не более того. С другой стороны, некоторым студентам понравится вся контекстная информация, которая приходит с их поисковыми запросами.
Сканер-переводчик
iOS
Цена: Бесплатно с покупками из приложения
Переводы: OCR
Ищете хорошо принятое приложение, которое обеспечивает быстрые и надежные переводы? Сканер и переводчик – сильный соперник.
Приложение отличается на более быстрым временем отклика, чем аналогичные продукты , и предлагает более дешевые тарифы на услуги премиум-класса. У вас также будет возможность сохранять предыдущие переводы и делиться ими через социальные сети, SMS и электронную почту.
Что касается недостатков, вам разрешается переводить только пять изображений в день, если вы подписаны на бесплатную услугу, и, как и в случае с другими приложениями, требуется подключение к Интернету. Не говоря уже о том, что оно буквально делает то, что написано в названии приложения, и не более того.Опять же, , если вы не особо разбираетесь в технологиях, , возможно, это приложение как раз для вас!
Переводчик – Translate Box
iOS | Android
Цена: Бесплатно с покупками из приложения
Переводы: OCR, текст, голос
Вам может быть интересно, почему большие приложения-переводчики, такие как Google Translate, не включены в этот список. Причина: существует приложение под названием Translator – Translate Box, которое представляет собой нечто вроде агрегатора переводов , если хотите.
Благодаря параллельным переводам из таких авторитетных программ, как Google Translate, Microsoft Translator, Yandex Translator и Baidu Translator (культовый фаворит за точность), вы можете легко сравнить переводы, чтобы определить, какой из них наиболее целесообразен.
А теперь о минусах. По сравнению с некоторыми другими в этом списке, интерфейс выглядит немного запутанным: все переводы перечислены один за другим. Для планшетов или телефонов с большими экранами это может быть не так плохо, но на экране телефона среднего размера он выглядит довольно загроможденным.
Вы также можете быть раздражены тем, сколько раз приложение спрашивает, предпочитаете ли вы «продолжить показ рекламы» или «перейти на премиум-версию». При той скорости, с которой реклама продолжает появляться, на самом деле, возможно, стоит перейти на премиум-сервис! Но если у вас ограниченный бюджет, вы, вероятно, подумаете, что самый точный перевод стоит того, чтобы пожертвовать просмотром рекламы.
iOS | Android
Цена: Бесплатно с переводом из приложения
Переводы: OCR
WeChat кажется странным из всех, учитывая, что он в основном используется в качестве средства коммуникации.Однако Wechat – это гораздо больше, чем просто приложение для обмена сообщениями, с такими функциями, как кошелек WeChat и мини-программы, которые позволяют бронировать билеты на поезд, заказывать такси, брать напрокат велосипеды, заказывать еду… вы называете это!
Одно из недавних дополнений к этому уже всеобъемлющему приложению – это приложение под названием «Сканировать для перевода». На главном экране приложения в правом верхнем углу есть знак плюса, который представляет собой меню ярлыков, которое включает сканирование QR-кодов.
Но теперь вы можете сканировать не только QR-коды.WeChat обновил функцию камеры, включив в нее опцию перевода OCR, что является значительным шагом вперед, поскольку единственные возможности перевода, которые он имел раньше, – это тексты в чатах и страница «Моменты». «Сканировать для перевода» избавляет от необходимости открывать или загружать другое приложение для сканирования китайских дорожных знаков или меню ресторанов.
Обновление переводаWeChat довольно удобно для тех, кто использует приложение ежедневно, и я обнаружил, что оно надежнее, чем Microsoft Translator.Я не могу вспомнить, сколько раз я загружал снимки экрана или делал фотографии китайских иероглифов, только для того, чтобы переводчик Microsoft показал мне сообщение: «Хм. Кажется, я не могу это перевести ».
Опять же, для сканирования вам потребуется подключение к Интернету, а это предлагает только переводы OCR (если вы не переводите текст в приложении). Но это все равно лучше, чем выходить из WeChat каждый раз, когда вам нужно что-то перевести!
Waygo
iOS | Android
Цена: Бесплатная загрузка 10 переводов в день, затем 6 долларов США.99 за неограниченные китайские переводы
Переводы: OCR
На первый взгляд кажется, что Waygo не предлагает ничего, что дает ему преимущество перед другими. Но есть одно огромное отличие: – это приложение для автономного перевода.
Получив отзывы в таких СМИ, как The New York Times, TechCrunch и многих других, это приложение определенно заслуживает внимания. Кроме того, перевод китайских блюд сопровождается изображениями, , поэтому вы также знаете, как они выглядят.
Конечно, поскольку это автономное приложение, Waygo может быть ограничен в отношении переводов, хранящихся в базе данных. Некоторым недостатком также может быть то, что он предлагает только переводы OCR, а не типичные текстовые переводы.
Несмотря на то, что вам придется платить за неограниченное количество переводов, офлайн-приложение OCR – это то, что вам нужно, когда вы находитесь вне зоны покрытия сети и у вас нет доступа к Wi-Fi.
Какое из этих приложений для распознавания китайских иероглифов идеально подходит вам? Новичку будет намного удобнее работать с таким приложением, как Pleco, которое делает больше, чем просто обычные переводы.Свободно говорящий может просто время от времени нуждаться в небольшой помощи, используя функцию WeChat «сканировать для перевода».
Одно можно сказать наверняка: с этими приложениями вы сможете заказать в следующем китайском ресторане гораздо больше, чем просто острую говяжью лапшу.
Загрузить: Это сообщение в блоге доступно в виде удобного и портативного PDF-файла, который вы можете можно взять куда угодно. Щелкните здесь, чтобы получить копию. (Скачать)
Если вам понравился этот пост, что-то мне подсказывает, что вам понравится FluentU, лучший способ выучить китайский язык с помощью реальных видео.
Испытайте погружение в китайский язык онлайн!
Перевести фото + сканировать камеру в App Store
Загрузить сейчас!
Translate Photo и мгновенно распознает и переводит тексты из меню ресторанов, журналов, веб-сайтов, дорожных знаков, книг и т. Д. На более чем 100 языков. Изучая иностранный язык или путешествуя за границу, Translate Photo делает вашу жизнь проще, чем когда-либо прежде!
Просто сделайте снимок текста на свой мобильный телефон, коснитесь экрана и получите переведенный текст за секунду!
Да, это не просто звучит так просто, это действительно так! ПОПРОБУЙ!
Translate Photo использует новейшую углубленную нейронную сеть в сочетании с технологией распознавания облачных изображений, чтобы распознавать текст с изображений с высокой точностью и переводить его на несколько языков.
Ключевые особенности Translate Photo:
– Smart Document Edge Detection: автоматически определяет края документа и позволяет мгновенно сканировать и переводить документы;
– Расширенное оптическое распознавание символов (OCR): мгновенно преобразует отсканированные документы в текст;
– Редактировать отсканированные изображения: применять фильтры, обрезать, настраивать контрастность, вращать отсканированные документы;
– Многоязычный: распознавание текста и переводы на несколько языков;
– Text-to-Speech: слушать перевод при изучении или попытке произнести фразу на иностранном языке;
– Множественный обмен: делитесь отсканированными документами или переведенными текстами с друзьями и семьей, распечатывайте и отправляйте переводы по электронной почте или текстовым сообщениям.
*** Примечание. Бесплатная версия может иметь ограничения (например, количество переводов в день), которые могут изменяться ***
Воспользуйтесь преимуществами премиум-функций:
– Неограниченные переводы
– Без рекламы опыт перевода
Выбирайте из разных вариантов подписки. Наши стандартные варианты подписки:
* Подписка на 1 месяц
* Подписка на 1 год
* Подписка с бесплатным пробным периодом автоматически обновляется до платной подписки.Вы можете отменить подписку в настройках iTunes как минимум за 24 часа до окончания бесплатного пробного периода. Плата за подписку будет снята с вашей учетной записи iTunes при подтверждении вашей покупки и в начале каждого срока продления.
* Обратите внимание: любая неиспользованная часть бесплатного пробного периода (если предлагается) будет аннулирована при покупке премиальной подписки в течение бесплатного пробного периода.
* Вы можете отменить бесплатную пробную версию или подписку в любое время, отменив подписку в настройках своей учетной записи iTunes.Это необходимо сделать за 24 часа до окончания бесплатного пробного периода или периода подписки, чтобы избежать списания средств. Отмена вступит в силу на следующий день после последнего дня текущего периода подписки, и вы будете переведены на бесплатную услугу.
Для полного доступа ко всем функциям «Перевести фото» вам необходимо разрешить доступ к следующему:
* Камера – чтобы вы могли переводить текст и имена объектов после съемки;
* Фотографии – чтобы вы могли переводить текст и названия объектов в ваших существующих фотографиях.
Забудьте о языковых барьерах! Наслаждайтесь совершенно новым способом перевода мира вокруг вас! Просто переведите фото!
EULA: https://datacomprojects.com/api/Eula?bid=com.smartloftapps.phototranslatefree
Политика конфиденциальности: https://datacomprojects.com/api/PrivacyPolicy?bid=com.smartloftapps.phototranslatefree
Обнаружение текста – Amazon Rekognition
Amazon Rekognition может обнаруживать текст в изображениях и видео.Затем он может преобразовать обнаруженные текст в машиночитаемый текст. Вы можете использовать обнаружение машиночитаемого текста на изображениях, чтобы реализовать такие решения как:
Визуальный поиск.Например, получение и отображение изображений, содержащих одинаковые текст.
Информация о содержании. Например, предоставление информации о темах, встречающихся в тексте. это распознается в извлеченных видеокадрах.Ваше приложение может искать признанные текст для релевантного содержания, такого как новости, спортивные результаты, номера спортсменов и подписи.
Навигация.Например, разработка мобильного приложения с поддержкой речи для визуального инвалиды, которые узнают названия ресторанов, магазинов или уличные знаки.
Общественная безопасность и транспортная поддержка.Например, обнаружение номерного знака автомобиля числа из изображений с камеры трафика
Фильтрация. Например, фильтрация информации, позволяющей установить личность (PII) из изображений.
Для обнаружения текста в видео вы можете реализовать такие решения, как:
Поиск видеоклипов с определенными текстовыми ключевыми словами, такими как имя гостя на изображение в новостном шоу.
Модерирование контента на соответствие стандартам организации путем обнаружения случайный текст, ненормативная лексика или спам.
Поиск всех текстовых наложений на временной шкале видео для дальнейшей обработки, например замена текста текстом на другом языке для содержания интернационализация.
Поиск расположения текста, чтобы можно было соответствующим образом выровнять другую графику.
Для обнаружения текста в изображениях в формате JPEG или PNG используйте операцию DetectText.Чтобы асинхронно обнаруживать текст в видео, используйте StartTextDetection и GetTextDetection операции. Операции по обнаружению текста и изображений, и видео поддерживают большинство шрифтов, в том числе сильно стилизованные. После обнаружения текста Amazon Rekognition создает представление обнаруженных слова и строки текста, показывает взаимосвязь между ними и сообщает вам, где текст находится на изображении или видеокадре.
Операции DetectText и GetTextDetection обнаруживают слова и
линий. Слово – это один или несколько символов латинского алфавита стандарта ISO из
стандартный английский алфавит и символы ASCII, не разделенные пробелами. DetectText может обнаруживать до 100 слов в изображении. GetTextDetection может обнаруживать до 50 слов в кадре видео. В
В следующей таблице перечислены символы, которые может обнаруживать Amazon Rekognition.
Категория | Поддерживаемые символы |
|---|---|
| Прописные буквы | ABCDEFGHIJKLMNOPQRSTUVWXYZ |
Строчные буквы | abcdefghijklmnopqrstuvwxyz |
Номера | 0123456789 |
| Символы | ! “# $% & \ ‘() * +, -._ `{| } ~ |
Amazon Rekognition предназначен для обнаружения слов на английском языке. Он также может обнаруживать слова в другом языки, использующие эти символы, но не распознающие диакритические знаки и другие символы.Например, он может обнаруживать «un» во французском языке, но не может обнаруживать «garçon» или может нет определить его правильно.
Строка – это строка слов с равным интервалом. Линия не обязательно полное предложение (точка не указывает конец строки). Например, Amazon Rekognition определяет номер водительского удостоверения в виде строки.Линия заканчивается, когда нет выровненной текст после это или когда есть большой разрыв между словами относительно длины слов. В зависимости от о разрыве слов, Amazon Rekognition мощь обнаруживать несколько строк в тексте, выровненных в одном направлении. Если предложение занимает несколько строк, операция возвращает несколько строк.
Рассмотрим следующее изображение.
Синие поля представляют информацию об обнаруженном тексте и местонахождении
текст
который возвращается операцией DetectText . В этом примере Amazon Rekognition обнаруживает
«ЭТО», «ПОНЕДЕЛЬНИК», «но», «держать» и «Улыбаться» как слова.Amazon Rekognition обнаруживает
“ЭТО ПОНЕДЕЛЬНИК”,
«но держись» и «улыбайся» в виде линий. Чтобы быть обнаруженным, текст должен быть
в
+/- 90 градусов ориентации горизонтальной оси.
Для пример см. в разделе «Обнаружение текста на изображении».
Распознавание и поиск почерка – Notability
Преобразование рукописного ввода в текст и поиск в Notability.
Рукописный поиск
Инструмент поискаNotability теперь находит почерк. Вы можете искать почерк во всех своих заметках или в отдельной заметке.
Notability может обрабатывать рукописный текст в ваших заметках, только когда приложение открыто.
Преобразование рукописного ввода
- Открыть заметку.
- Коснитесь / щелкните инструмент «Лазо».
- Обведите рукописный ввод, который хотите преобразовать.
- Коснитесь / щелкните «Преобразовать в текст».
- Коснитесь / щелкните в любом месте преобразованного текста, чтобы отредактировать его.
- Коснитесь / щелкните «Преобразовать выделение», чтобы превратить рукописный текст в текстовое поле с преобразованным текстом.
- Нажмите / щелкните «Копировать текст в буфер обмена», чтобы скопировать текст в буфер обмена вашего устройства.
Какой язык ищет Notability?
Notability использует язык вашего устройства. Например, если ваш iPad настроен на английский язык, Notability будет искать английский в ваших заметках.
Изменение языка распознавания для всех нот
- Открытая библиотека Notability.
- Коснитесь / щелкните значок шестеренки в нижнем левом углу.
- Коснитесь / щелкните «Рукописный ввод».
- Коснитесь / щелкните «Язык».
- Коснитесь / щелкните нужный язык.
Это изменяет язык распознавания для новых заметок. Это не влияет на существующие заметки.
Изменение языка распознавания отдельной банкноты
- Открыть заметку.
- Коснитесь / щелкните значок с тремя точками в правом верхнем углу.
- Коснитесь / щелкните.
- Коснитесь / щелкните язык рядом с «Язык рукописного ввода».
Изменение языка распознавания для преобразования рукописного ввода
- Преобразуйте рукописный ввод в текст, как описано выше.
- Коснитесь / щелкните язык в нижнем левом углу окна преобразования.
- Выберите желаемый язык.
Математическое преобразование
Преобразуйте рукописные уравнения в масштабируемые изображения высокого разрешения. Уравнения с цветовой кодировкой сохранят свой исходный цвет.
Math Conversion поддерживает общие математические выражения, элементы и правила, включая:
- Латинский алфавит
- цифр
- Математические символы и операции
- Греческие символы
- Математические термины: sin, cos, tan, mean, median, mod, norm, ceil, cons, sort, sad, var и т. Д.
- Химические элементы
- Международные условные единицы (вес, длина, частота, светимость, дозировка, давление и т. Д.)
- Правила: горизонтальная пара, забор, квадратный корень, дробь, нижний индекс, вертикальная пара, матрица, частичные дроби и т. Д.
Мы поддерживаем LaTeX! После преобразования рукописного ввода в текст вы можете редактировать математические уравнения, изменив лежащий в основе LaTeX.
- Щелкните правой кнопкой мыши или коснитесь в любом месте преобразованных уравнений, чтобы получить доступ к параметрам редактора LaTeX.
- При редактировании уравнения вы можете добавить любой LaTeX, какой захотите!
Поддерживаемые языки
Функция распознавания рукописного ввода и поиск доступны на английском, датском, голландском, филиппинском (тагальском), французском, немецком, индонезийском, итальянском, японском, корейском, малайском, норвежском букмоле, польском, португальском, русском, упрощенном китайском, испанском, шведском, тайском языках. , Традиционный китайский, Турецкий, Украинский, Вьетнамский
OCR на основе глубокого обучения для текста в дикой природе
Мы живем во времена, когда любая организация или компания, стремящаяся к масштабированию и сохранению актуальности, должна изменить свой взгляд на технологии и быстро адаптироваться к меняющимся условиям.Мы уже знаем, как Google оцифровал книги. Или как Google Earth использует NLP (или NER) для идентификации адресов. Или как можно читать текст в цифровых документах, таких как счета-фактуры, юридические документы и т. Д.
Но как именно это работает?
Этот пост посвящен оптическому распознаванию символов (OCR) для распознавания текста в естественных изображениях сцены. Мы узнаем о том, почему это сложная проблема, о подходах к ее решению и о соответствующем коде.
Имеете в виду проблему распознавания текста? Хотите извлечь данные из документов? Зайдите в Nanonets и создавайте модели OCR бесплатно!
Но почему на самом деле?
В нашу эпоху оцифровки хранить, редактировать, индексировать и находить информацию в цифровом документе намного проще, чем тратить часы на просмотр распечатанных / рукописных / печатных документов.
Более того, поиск чего-либо в большом нецифровом документе занимает не только много времени, но и может упустить информацию при прокрутке документа вручную. К счастью для нас, компьютеры с каждым днем становятся все лучше и лучше, выполняя те задачи, которые люди думали только о них, и часто работают лучше, чем мы.
Извлечение текста из изображений нашло множество применений.
Некоторые из приложений: распознавание паспортов, автоматическое распознавание номерных знаков, преобразование рукописных текстов в цифровой, преобразование печатного текста в цифровой и т. Д.
Проблемы Источник изображения: https://pixabay.com
Прежде чем мы расскажем, как нам нужно понять проблемы, с которыми мы сталкиваемся при распознавании текста.
Многие реализации OCR были доступны еще до бума глубокого обучения в 2012 году. Хотя обычно считалось, что OCR – это решенная проблема, OCR по-прежнему остается сложной проблемой, особенно когда текстовые изображения снимаются в неограниченной среде.
Я говорю о сложном фоне, шуме, молниях, различном шрифте и геометрических искажениях изображения.
Именно в таких ситуациях блестят инструменты машинного обучения OCR.
Проблемы с распознаванием текста возникают в основном из-за свойств выполняемых задач распознавания текста. Обычно мы можем разделить эти задачи на две категории:
Структурированный текст – Текст в печатном документе. Стандартный фон, правильный ряд, стандартный шрифт и в основном плотный.
Неструктурированный текст – Текст в произвольных местах естественной сцены.Редкий текст, отсутствие правильной структуры строк, сложный фон, случайное место на изображении и отсутствие стандартного шрифта.
Неструктурированные тексты: рукописные, несколько шрифтов и разреженные; Источник изображения: https://pixabay.comМногие более ранние методы решали проблему распознавания текста для структурированного текста.
Но эти методы не работали должным образом для естественной сцены, которая является разреженной и имеет другие атрибуты, чем структурированные данные.
В этом блоге мы сосредоточимся больше на неструктурированном тексте, который представляет собой более сложную проблему для решения .
Как мы знаем в мире глубокого обучения, не существует единого решения, подходящего для всех. Мы увидим несколько подходов к решению поставленной задачи и проработаем один из них.
Nanonets OCR API имеет много интересных вариантов использования. Чтобы узнать больше, поговорите со специалистом по искусственному интеллекту Nanonets.
Запланировать звонок
Наборы данных для неструктурированных задач OCR
Существует множество наборов данных на английском языке, но найти наборы данных для других языков сложнее.Различные наборы данных представляют разные задачи, которые необходимо решить. Вот несколько примеров наборов данных, обычно используемых для задач распознавания текста машинным обучением.
Набор данных SVHN
Набор данных Street View House Numbers содержит 73257 цифр для обучения, 26032 цифры для тестирования и 531131 дополнительных в качестве дополнительных обучающих данных. Набор данных включает 10 меток, которые представляют собой цифры от 0 до 9. Набор данных отличается от MNIST, поскольку SVHN имеет изображения номеров домов с номерами домов на разном фоне.В наборе данных есть ограничивающие прямоугольники вокруг каждой цифры вместо нескольких изображений цифр, как в MNIST.
Набор данных текста сцены
Этот набор данных состоит из 3000 изображений в различных настройках (в помещении и на улице) и условиях освещения (тень, свет и ночь) с текстом на корейском и английском языках. Некоторые изображения также содержат цифры.
Набор данных Devanagri Character
Этот набор данных предоставляет нам 1800 образцов из 36 классов символов, полученных 25 различными авторами в сценарии devanagri.
И есть много других, таких как этот для китайских иероглифов, этот для CAPTCHA или этот для рукописных слов.
Любой Типичный конвейер OCR с машинным обучением включает следующие шаги:
Поток OCRПредварительная обработка
- Удаление шума из изображения
- Удаление сложного фона из изображения
- Обработка различных условий освещения в изображении
Это стандартные способы предварительной обработки изображения в задаче компьютерного зрения.В этом блоге мы не будем заострять внимание на этапе предварительной обработки.
Обнаружение текста
источникМетоды обнаружения текста, необходимые для обнаружения текста в изображении и создания ограничивающей рамки вокруг части изображения, содержащей текст. Здесь также будут работать стандартные методы обнаружения возражений.
Техника скользящего окна
Ограничивающая рамка может быть создана вокруг текста с помощью техники скользящего окна. Однако это вычислительно дорогостоящая задача.В этом методе скользящее окно проходит через изображение для обнаружения текста в этом окне, как сверточная нейронная сеть. Мы стараемся с другим размером окна, чтобы не пропустить текстовую часть другого размера. Существует сверточная реализация скользящего окна, которая может сократить время вычислений.
Детекторы одиночного снимка и детектора области
Существуют методы однократного обнаружения, такие как YOLO (вы смотрите только один раз) и методы обнаружения текста на основе области для обнаружения текста на изображении.
Архитектура YOLO: исходный кодYOLO – это однократная техника, когда вы передаете изображение только один раз, чтобы обнаружить текст в этой области, в отличие от скользящего окна.
Региональный подход работает в два этапа.
Сначала сеть предлагает регион, который, возможно, будет иметь тест, а затем классифицирует регион, есть ли в нем текст или нет. Вы можете обратиться к одной из моих предыдущих статей, чтобы понять методы обнаружения объектов, в нашем случае обнаружения текста.
EAST (Эффективный точный детектор текста сцены)
Это очень надежный метод глубокого обучения для обнаружения текста, основанный на этой статье.Стоит упомянуть, что это всего лишь метод обнаружения текста. Он может находить горизонтальные и повернутые ограничивающие рамки. Его можно использовать в сочетании с любым методом распознавания текста.
Конвейер обнаружения текста в этой статье исключил повторяющиеся и промежуточные этапы и состоит только из двух этапов.
One использует полностью сверточную сеть для непосредственного прогнозирования на уровне слов или текстовых строк. Полученные прогнозы, которые могут быть повернутыми прямоугольниками или четырехугольниками, дополнительно обрабатываются на этапе подавления без максимального значения, чтобы получить окончательный результат.
Изображение взято с https://arxiv.org/pdf/1704.03155v2.pdfEAST может обнаруживать текст как на изображениях, так и на видео. Как упоминалось в документе, он работает почти в реальном времени со скоростью 13 кадров в секунду на изображениях 720p с высокой точностью обнаружения текста. Еще одним преимуществом этого метода является то, что его реализация доступна в OpenCV 3.4.2 и OpenCV 4. Мы увидим эту модель EAST в действии вместе с распознаванием текста.
Распознавание текста
После того, как мы обнаружили ограничивающие прямоугольники с текстом, следующим шагом будет распознавание текста.Есть несколько техник распознавания текста. В следующем разделе мы обсудим некоторые из лучших техник.
Сверточная рекуррентная нейронная сеть (CRNN) представляет собой комбинацию потерь CNN, RNN и CTC (временная классификация соединений) для задач распознавания последовательности на основе изображений, таких как распознавание текста сцены и OCR. Сетевая архитектура была взята из этой статьи, опубликованной в 2015 году.
Изображение взято с https: // arxiv.org / pdf / 1507.05717.pdf
Эта архитектура нейронной сети объединяет извлечение признаков, моделирование последовательностей и транскрипцию в единую структуру. Эта модель не требует сегментации символов. Сверточная нейронная сеть извлекает признаки из входного изображения (область обнаружения текста). Глубокая двунаправленная рекуррентная нейронная сеть предсказывает последовательность меток с некоторой связью между символами. Слой транскрипции преобразует кадр, созданный RNN, в последовательность меток.Существует два режима транскрипции, а именно транскрипция без лексикона и транскрипция на основе лексики. В подходе, основанном на лексике, будет предсказана наиболее вероятная последовательность меток.
Машинное обучение OCR с Tesseract
Tesseract был первоначально разработан в Hewlett-Packard Laboratories в период с 1985 по 1994 год. В 2005 году он был открыт в HP. Согласно wikipedia –
В 2006 году Tesseract считался одним из наиболее точных на тот момент движков OCR с открытым исходным кодом.
Возможности Tesseract в основном ограничивались структурированными текстовыми данными. Он будет плохо работать с неструктурированным текстом со значительным шумом. Дальнейшая разработка tesseract спонсируется Google с 2006 года.
Метод, основанный на глубоком обучении, лучше работает с неструктурированными данными. В Tesseract 4 добавлены возможности на основе глубокого обучения с механизмом OCR на основе сети LSTM (своего рода рекуррентной нейронной сети), который ориентирован на распознавание строк, но также поддерживает устаревший механизм Tesseract OCR Tesseract 3, который работает путем распознавания шаблонов символов.Последняя стабильная версия 4.1.0 выпущена 7 июля 2019 года. Эта версия также значительно более точна в отношении неструктурированного текста.
Мы будем использовать некоторые изображения, чтобы показать как обнаружение текста с помощью метода EAST, так и распознавание текста с помощью Tesseract 4. Давайте посмотрим на обнаружение и распознавание текста в действии в следующем коде. Данная статья оказалась полезным ресурсом при написании кода для этого проекта.
## Загрузка необходимых пакетов
импортировать numpy как np
импорт cv2
от imutils.object_detection импорт non_max_suppression
импорт pytesseract
from matplotlib import pyplot as plt Загрузка пакетов # Создание словаря аргументов для аргументов по умолчанию, необходимых в коде.
args = {"image": "../ input / text-detection / example-images / Example-images / ex24.jpg", "east": "../ input / text-detection / east_text_detection.pb", " min_confidence ": 0,5," ширина ": 320," высота ": 320}
Создание словаря аргументов с некоторыми значениями по умолчаниюЗдесь я работаю с основными пакетами.Пакет OpenCV использует модель EAST для обнаружения текста. Пакет tesseract предназначен для распознавания текста в ограничивающей рамке, обнаруженной для текста. Убедитесь, что у вас версия tesseract> = 4. В Интернете доступно несколько источников для руководства по установке tesseract.
Создан словарь для аргументов по умолчанию, необходимых в коде. Посмотрим, что означают эти аргументы.
- изображение: расположение входного изображения для обнаружения и распознавания текста.
- восток: расположение файла с предварительно обученной моделью детектора EAST.
- минимальная достоверность: минимальная оценка вероятности достоверности геометрической формы, спрогнозированной в местоположении.
- width: Для правильной работы модели EAST ширина изображения должна быть кратна 32.
- высота: для правильной работы модели EAST высота изображения должна быть кратна 32.
# Укажите местоположение изображения для чтения.
# Здесь загружается изображение "Example-images / ex24.jpg".
args ['image'] = "../ input / text-detection / example-images / Example-images / ex24.jpg "
image = cv2.imread (args ['изображение'])
# Сохранение исходного изображения и формы
orig = image.copy ()
(origH, origW) = image.shape [: 2]
# установить новую высоту и ширину по умолчанию 320 с помощью args #dictionary.
(newW, newH) = (args ["ширина"], args ["высота"])
# Рассчитайте соотношение между исходным и новым изображением как для роста, так и для веса.
# Это соотношение будет использоваться для перевода положения ограничивающей рамки на исходном изображении.
rW = origW / float (newW)
rH = origH / float (newH)
# изменить размер исходного изображения до новых размеров
изображение = cv2.resize (изображение; (newW, newH))
(H, W) = image.shape [: 2]
# создаем blob из изображения, чтобы передать его модели EAST
blob = cv2.dnn.blobFromImage (изображение, 1.0, (Ш, В),
(123.68, 116.78, 103.94), swapRB = True, crop = False) Обработка изображений # загрузка предварительно обученной модели EAST для обнаружения текста
net = cv2.dnn.readNet (args ["восток"])
# Мы хотели бы получить два вывода от модели EAST.
№1. Оценки вероятности для региона, содержит он текст или нет.
№2. Геометрия текста - Координаты ограничивающей рамки, определяющей текст
# Следующие два слоя необходимо извлечь из модели EAST для этого.layerNames = [
"feature_fusion / Conv_7 / Sigmoid",
"feature_fusion / concat_3"] Загрузка предварительно обученной модели EAST и определение выходных слоев # Вперед передать blob из изображения, чтобы получить желаемые выходные слои
net.setInput (большой двоичный объект)
(scores, geometry) = net.forward (layerNames) Прямое прохождение изображения через модель EAST ## Возвращает ограничивающую рамку и оценку вероятности, если она превышает минимальную достоверность
прогнозы def (prob_score, geo):
(numR, numC) = prob_score.форма [2: 4]
коробки = []
доверие_val = []
# перебирать ряды
для y в диапазоне (0, numR):
scoresData = prob_score [0, 0, y]
x0 = geo [0, 0, y]
x1 = geo [0, 1, y]
x2 = geo [0, 2, y]
x3 = geo [0, 3, y]
anglesData = geo [0, 4, y]
# перебрать количество столбцов
для i в диапазоне (0, numC):
если scoresData [i] Функция декодирования ограничивающего прямоугольника из прогноза модели EASTВ этом упражнении мы декодируем только горизонтальные ограничивающие прямоугольники.Расшифровка вращающихся ограничивающих рамок из партитур и геометрии более сложна.
# Найдите прогнозы и примените подавление не максимальных значений
(коробки, доверительное_значение) = прогнозы (баллы, геометрия)
box = non_max_suppression (np.array (box), probs = доверительный_val) Получение окончательных ограничивающих рамок после подавления без максимумаТеперь, когда мы вывели ограничивающие прямоугольники после применения подавления без максимума. Мы хотели бы видеть ограничивающие рамки на изображении и то, как мы можем извлечь текст из обнаруженных ограничивающих рамок.Мы делаем это с помощью тессеракта.
## Обнаружение и распознавание текста
# инициализировать список результатов
результаты = []
# перебираем ограничивающие прямоугольники, чтобы найти координаты ограничивающих прямоугольников
для (startX, startY, endX, endY) в полях:
# масштабируйте координаты на основе соответствующих соотношений, чтобы отразить ограничивающую рамку на исходном изображении
startX = int (startX * rW)
startY = int (startY * rH)
конецX = число (конецX * rW)
конецY = int (конецY * rH)
# извлечь интересующую область
r = orig [начало: конецY, началоX: конецX]
#configuration параметр для преобразования изображения в строку.конфигурация = ("-l eng --oem 1 --psm 8")
## Это распознает текст на изображении ограничивающей рамки
text = pytesseract.image_to_string (r, config = конфигурация)
# добавить координату bbox и связанный текст в список результатов
results.append (((startX, startY, endX, endY), text)) Создание списка с координатами ограничивающего прямоугольника и распознанным текстом в поляхВ приведенной выше части кода сохранены координаты ограничивающего прямоугольника и связанный текст в списке. Посмотрим, как это будет выглядеть на изображении.
В нашем случае мы использовали определенную конфигурацию тессеракта. Для настройки тессеракта доступно несколько опций.
l: язык , выбран английский в приведенном выше коде.
OEM (режимы OCR Engine):
0 Только старый двигатель.
1 Только движок нейронных сетей LSTM.
2 двигателя Legacy + LSTM.
3 По умолчанию, в зависимости от того, что доступно.
psm (режимы сегментации страниц):
0 Только ориентация и обнаружение скриптов (OSD).
1 Автоматическая сегментация страниц с помощью экранного меню.
2 Автоматическая сегментация страниц, но без OSD или OCR. (не реализовано)
3 Полностью автоматическая сегментация страниц, без экранного меню. (По умолчанию)
4 Предположим, что один столбец текста переменного размера.
5 Предположим, что это единый однородный блок вертикально выровненного текста.
6 Предположим, что это один однородный блок текста.
7 Рассматривайте изображение как одну текстовую строку.
8 Обращайтесь с изображением как с одним словом.
9 Рассматривайте изображение как отдельное слово в круге.
10 Считайте изображение одним символом.
11 Разрозненный текст. Найдите как можно больше текста в произвольном порядке.
12 Разреженный текст в экранном меню.
13 Необработанная линия. Относитесь к изображению как к одной текстовой строке, минуя хаки, специфичные для Tesseract.
Мы можем выбрать конкретную конфигурацию Tesseract на основе наших данных изображения.
# Показать изображение с ограничивающей рамкой и распознанным текстом
orig_image = orig.copy ()
# Перемещение результатов и отображение на изображении
for ((start_X, start_Y, end_X, end_Y), text) в результатах:
# отображаем текст, обнаруженный Tesseract
print ("{} \ n".формат (текст))
# Отображение текста
text = "" .join ([x if ord (x) <128 else "" для x в тексте]). strip ()
cv2.rectangle (orig_image, (start_X, start_Y), (end_X, end_Y),
(0, 0, 255), 2)
cv2.putText (orig_image, текст, (start_X, start_Y - 30),
cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0,0, 255), 2)
plt.imshow (orig_image)
plt.title ('Вывод')
plt.show () Показать изображение с ограничивающей рамкой и распознанным текстомРезультаты
В приведенном выше коде используется модель OpenCV EAST для обнаружения текста и tesseract для распознавания текста.PSM для Tesseract настроен в соответствии с изображением. Важно отметить, что для нормальной работы Tesseract обычно требуется четкое изображение.
В нашей текущей реализации мы не рассматривали вращающиеся ограничивающие прямоугольники из-за сложности реализации. Но в реальном сценарии, когда текст повернут, приведенный выше код не будет работать. Кроме того, если изображение не очень четкое, tesseract будет трудно правильно распознать текст.
Некоторые из результатов, сгенерированных с помощью приведенного выше кода:
Источник необработанного изображения: https: // madison.citymomsblog.com Источник сырого изображения: http://lrv.fri.uni-lj.si/andreji/CVLOCRDB/ Источник сырого изображения: https://www.tripadvisor.in/Код может обеспечить отличные результаты для всех трех вышеперечисленных изображений. Текст на этих изображениях четкий, а фон за текстом также одинаков.
Источник необработанного изображения: https://www.magic.co.nzМодель показала здесь хорошие результаты. Но некоторые алфавиты распознаются неправильно. Вы можете видеть, что ограничивающие рамки в основном правильные, какими они должны быть.Возможно, поможет небольшое вращение. Но наша текущая реализация не предоставляет вращающихся ограничивающих рамок. Похоже, из-за четкости изображения tesseract не смог его точно распознать.
Источник необработанного изображения: https://www.ktoo.orgМодель здесь показала неплохие результаты. Но некоторые тексты в ограничивающих рамках распознаются неправильно. Цифра 1 вообще не может быть обнаружена. Здесь неоднородный фон, возможно, создание однородного фона помогло бы в этом случае. Кроме того, 24 неправильно ограничены в рамке.В таком случае может помочь заполнение ограничивающей рамки.
Источник необработанного изображения: https://www.mirror.co.uk/Кажется, что стилизованный шрифт с тенью на заднем фоне повлиял на результат в приведенном выше случае.
Нельзя ожидать, что модель OCR будет точной на 100%. Тем не менее, мы добились хороших результатов с моделью EAST и Tesseract. Добавление дополнительных фильтров для обработки изображения поможет улучшить производительность модели.
Вы также можете найти этот код для этого проекта в ядре Kaggle, чтобы попробовать его самостоятельно.
Nanonets OCR API имеет много интересных вариантов использования. Чтобы узнать больше, поговорите со специалистом по искусственному интеллекту Nanonets.
Запланировать звонок
OCR с Nanonets
API Nanonets OCR позволяет с легкостью создавать модели OCR. Вы можете загрузить свои данные, аннотировать их, настроить модель для обучения и ждать получения прогнозов через пользовательский интерфейс на основе браузера.
1. Использование графического интерфейса: https://app.nanonets.com/
Вы также можете использовать Nanonets-OCR- API, выполнив следующие действия:
2.Использование NanoNets API: https://github.com/NanoNets/nanonets-ocr-sample-python
Ниже мы дадим вам пошаговое руководство по обучению вашей собственной модели с использованием Nanonets API за 9 простых шагов. .
Шаг 1. Клонируйте репо
git clone https://github.com/NanoNets/nanonets-ocr-sample-python
CD наносети-ОКР-образец-Питон
запросы на установку sudo pip
sudo pip install tqdm Шаг 2. Получите бесплатный ключ API
Получите бесплатный ключ API с https: // app.nanonets.com/#/keys
Шаг 3. Установите ключ API в качестве переменной среды
экспорт NANONETS_API_KEY = YOUR_API_KEY_GOES_HERE
Шаг 4. Создание новой модели
python ./code/create-model.py
Примечание. При этом генерируется MODEL_ID, необходимый для следующего шага.
Шаг 5. Добавление идентификатора модели в качестве переменной среды
экспорт NANONETS_MODEL_ID = YOUR_MODEL_ID
Шаг 6: Загрузите обучающие данные
Соберите изображения объекта, который вы хотите обнаружить.Когда у вас есть готовый набор данных в папке изображений (файлы изображений), начните загрузку набора данных.
питон ./code/upload-training.py
Шаг 7. Обучение модели
После загрузки изображений начните обучение модели
python ./code/train-model.py
Шаг 8: Получение состояния модели
Обучение модели занимает около 30 минут. Вы получите электронное письмо после обучения модели. А пока вы проверяете состояние модели
watch -n 100 python./code/model-state.py
Шаг 9: Сделайте прогноз
После обучения модели. Вы можете делать прогнозы, используя модель
python ./code/prediction.py PATH_TO_YOUR_IMAGE.jpg
Зайдите в Nanonets и создавайте модели компьютерного зрения бесплатно!
Дополнительная литература
Обновление # 1 :
https://nanonets.com/ocr-api теперь доступно, где вы можете использовать графический интерфейс Nanonets для обучения пользовательской модели OCR, включая рабочий процесс автоматической обработки счетов .
Обновление # 2 :
Добавлены дополнительные материалы для чтения о различных подходах с использованием распознавания текста на основе глубокого обучения для извлечения текста.
6 лучших приложений Android OCR для извлечения текста из изображений
Вам нужно оцифровать печатный текст, чтобы сохранить его электронную копию? В конце концов, отказ от бумажной документации дает множество преимуществ. Если это так, все, что вам нужно, это инструмент оптического распознавания символов (OCR).
В прошлом мы рассмотрели несколько онлайн-инструментов оптического распознавания текста, но ничто не сравнится с удобством возможности оцифровывать документы прямо с вашего телефона Android. Прежде чем погрузиться в лучшие инструменты распознавания текста для Android, давайте посмотрим, как мы их тестировали.
Наша методика тестирования
Мы просмотрели различные отрывки из биографии Стива Джобса Уолтера Айзексона. Сначала мы отсканировали отрывки с простым форматированием.
Затем мы отсканировали отрывки со страниц с более сложным форматированием. Только несколько приложений поддерживают извлечение текста из рукописного текста, поэтому мы протестировали рукописные заметки с курсивом. Сканирование проводилось при хорошем освещении. Наконец, эти документы были запущены с помощью одних из лучших инструментов распознавания текста для Android. Вот как они выступили.
1. Google Keep
Отличное приложение для создания заметок от Google содержит в себе несколько хитрых приемов и имеет множество творческих применений.Он также имеет встроенную поддержку OCR. В ходе тестирования мы обнаружили, что извлечение текста в Google Keep довольно стабильно работает как при простом, так и при сложном форматировании текста. Он также в значительной степени сохраняет исходное форматирование текста.
Инструкции по извлечению текста:
- Добавьте новую заметку и нажмите значок + .
- Выберите Сделать фото , чтобы отсканировать документ с камеры, или выберите Выберите изображение , чтобы импортировать изображение из вашей галереи.
- Откройте изображение, нажмите на трехточечное меню переполнения и выберите Захватить текст изображения .
Текст должен быть извлечен за несколько секунд. Возможно, лучше всего то, что текстовая заметка будет автоматически синхронизироваться на всех ваших устройствах, поэтому вы можете сканировать документ на своем телефоне Android и редактировать его позже на своем компьютере.
Скачать: Google Keep (бесплатно)
2.Сканер текста [OCR]
Сканер текста [OCR] оказался на втором месте после Google Keep в нашем тестировании. Приложение утверждает, что поддерживает более 50 языков, включая китайский, японский, французский и другие. Он даже поддерживает извлечение текста из рукописного текста. Интерфейс приложения включает в себя основные функции сканирования, такие как увеличение и ползунок яркости, для наиболее четкого захвата текста.
В нашем тестировании у него не было проблем с извлечением текста, хотя извлечение текста из рукописных заметок казалось его ахиллесовой пятой.Но это не удивительно, поскольку почерк может сильно отличаться от человека к человеку. Тем не менее, это все еще одно из немногих приложений, которое действительно поддерживает извлечение текста из рукописных заметок, поэтому попробовать стоит.
Инструкции по извлечению текста:
- Нажмите на синюю кнопку спуска затвора , чтобы сделать снимок и отсканировать документ. Кроме того, вы также можете импортировать существующее изображение, щелкнув значок галереи .
Теперь должен отображаться извлеченный текст. Отсюда вы можете редактировать текст, копировать его или делиться им со сторонними приложениями.
Загрузить: Сканер текста [OCR] (бесплатно с рекламой)
3. СМС Фея
.Text Fairy - еще один достойный инструмент для извлечения изображений для Android, способный распознавать текст более чем на 50 языках, включая китайский, японский, голландский, французский и другие.Он поддерживает множество индийских языков, таких как хинди, бенгали, маратхи, телугу и т. Д. Вам будет предложено загрузить необходимые языки при первом запуске приложения.
Он отсканировал наш тестовый документ без каких-либо ошибок, но имел проблемы с распознаванием текста со страницы, содержащей пару изображений. Он прямо упоминает, что у него есть некоторые проблемы с распознаванием разноцветных букв. Также стоит упомянуть, что перед сканированием документа необходимо выполнить множество действий вручную, что делает его непригодным для пакетного сканирования.Лучше ограничить его использование сканированием книг и журналов с простым макетом.
Инструкции по извлечению текста:
- Нажмите на значок камеры , чтобы сделать снимок. Или нажмите на значок галереи , чтобы импортировать изображение из галереи.
- Выберите раздел изображения, который вы хотите отсканировать. Нажмите на стрелку вперед , чтобы продолжить.
- Выберите, является ли макет документа одним или двумя столбцами.
- Выберите язык текста.
- Наконец, нажмите Start .
Если все пойдет хорошо, текст следует извлечь, и теперь вы можете редактировать или копировать его в любом месте.
Скачать: Text Fairy (бесплатно)
4. Офисная линза
Office Lens - это попытка Microsoft представить портативное приложение для сканирования на устройствах Android. Его заголовок - это возможность сканировать и оцифровывать документы, но он также имеет удобную опцию OCR. Он включен в качестве расширенного варианта, но вы можете получить его бесплатно, зарегистрировав бесплатную учетную запись Microsoft.Регистрация также открывает доступ к другим функциям, таким как 5 ГБ бесплатного хранилища OneDrive и возможность сохранения в нескольких форматах.
В нашем тестировании Office Lens оказался одним из лучших приложений для распознавания текста на изображении. Кажется, у него нет никаких проблем с распознаванием даже цветных шрифтов. Кроме того, это лучшее приложение для Android OCR для распознавания текста из рукописных заметок. Он тесно интегрируется с другими продуктами Microsoft, такими как OneNote и Office 365.Если вы доверяете экосистеме Microsoft, использовать Office Lens не составит труда.
Инструкции по извлечению текста:
- Откройте Office Lens и наведите камеру на документ, который хотите отсканировать. Он автоматически определяет участок изображения с текстом, но вы можете настроить его вручную. Нажмите кнопку спуска затвора камеры .
- Нажмите Сохранить .
- В разделе «Сохранить в» проверьте документ Word и коснитесь значка Проверить .
После открытия вы можете внести любые необходимые изменения.
Загрузка: Office Lens (бесплатно)
5. Сканер текста OCR
Сканер текста OCR имеет упрощенный интерфейс и поддерживает более 55 языков, включая английский, французский, итальянский, шведский и другие.В нашем тестировании казалось, что с документами он работает в основном нормально, хотя в разных местах пропустил пару слов. Он не может извлекать текст изображения из рукописных заметок. Он также пронизан рекламой, поэтому вам придется подождать около пяти секунд между каждым сканированием.
Инструкции по извлечению текста:
- Нажмите значок камеры , чтобы отсканировать документ. Чтобы импортировать документ из галереи, нажмите на кнопку с тремя точками o Verflow , а затем нажмите Импорт .
- Выберите язык документа и коснитесь Захватить текст изображения .
Он должен отображать извлеченный текст. Вы можете легко скопировать или поделиться текстом отсюда.
Скачать: Сканер текста OCR (бесплатно с рекламой)
6. CamScanner
CamScanner какое-то время был одним из наших любимых приложений для сканирования документов на вашем телефоне.Но, как ни странно, его функция распознавания текста довольно проста. В нашем тестировании он часто пропускал определенные слова или писал их с ошибками. Это не так уж плохо, но упомянутые выше приложения в целом показали лучшие результаты. Одна замечательная вещь в нем - то, что он может обрабатывать документы в пакетном режиме. В отличие от некоторых других приложений, оно не требует ручной настройки перед сканированием документа.
Бесплатная версия CamScanner позволяет просматривать текст только для чтения, поэтому, конечно, вам придется перейти на премиум-версию, чтобы редактировать извлеченный текст.
Инструкции по извлечению текста:
- Коснитесь значка Камера , чтобы отсканировать документ с помощью камеры вашего устройства. Чтобы импортировать изображение из вашей галереи, нажмите на дополнительное меню и выберите «Импортировать из галереи».
- Откройте изображение и нажмите Распознать .
- Вы можете коснуться Распознать всю страницу , чтобы извлечь текст из всего изображения, или коснуться Выбрать область , чтобы извлечь текст из определенного раздела.
Загрузка: CamScanner (бесплатно, полная)
Помните, что ни один инструмент распознавания текста не является надежным на 100 процентов, когда дело касается извлечения текста. Всегда рекомендуется редактировать и корректировать документы перед их сохранением. Google Keep довольно последовательно работает для оцифровки моих документов, а Office Lens отлично справляется с оцифровкой моих рукописных заметок.
Однако ваш опыт может варьироваться в зависимости от стиля текста документа или его языка, поэтому лучше проверить все приложения и посмотреть, что лучше всего подходит для вас.
Какое приложение вы предпочитаете для извлечения текста из документов? Если ваше любимое приложение отсутствует в списке, сообщите нам об этом в комментариях ниже.
Кредит изображения: guteksk7 / Depositphotos
Windows 11 - бесплатное обновление для всех пользователей Windows 10Но это может зависеть от оборудования вашей системы.
Читать далее
Об авторе Abhishek Kurve (Опубликовано 23 статей)Абхишек Курве - бакалавр компьютерных наук. Он компьютерный фанат, который с нечеловеческим энтузиазмом принимает любую новую потребительскую технологию.
Более От Абхишека КурвеПодпишитесь на нашу рассылку новостей
Подпишитесь на нашу рассылку, чтобы получать технические советы, обзоры, бесплатные электронные книги и эксклюзивные предложения!
Еще один шаг…!
Подтвердите свой адрес электронной почты в только что отправленном вам электронном письме.