
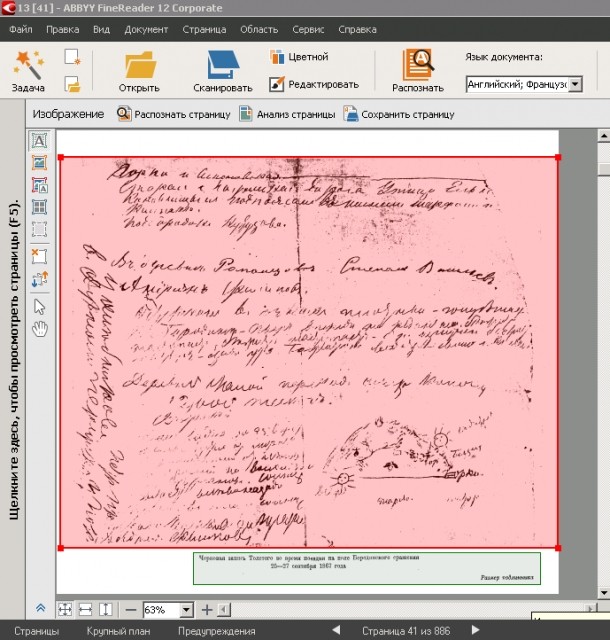
Как перевести рукописный текст в печатный онлайн бесплатно
Функции распознавания текста с фото часто бывают необходимы в офисной, образовательной или другой деятельности. И на сегодня IT-индустрия может предложить большое количество достаточно качественных способов сделать это. Это и онлайн приложения, которые работают через браузер, и мобильные приложения, которые используют облачные вычислительные мощности, а также автономные сложные программы для компьютера.
В данной статье мы рассмотрим самые удобные способы перевести рукописный текст в печатный онлайн и бесплатно, вы узнаете обо всех особенностях такой операции и поймёте, как можно улучшить качество распознавания.
Содержание
- Особенности распознавания рукописного текста
- Онлайн распознавание Convertio
- К функциям и достоинствам данного сервиса можно отнести следующее:
- Рассмотрим подробнее, как этим пользоваться для того, чтобы переделать рукописный текст в печатный:
- img2txt — простой сервис онлайн распознавания
- Работать с этим сервисом просто:
- Text Scanner — распознавание рукописного текста на Android
Особенности распознавания рукописного текста
Если с распознаванием напечатанного текста всё просто: программа просто видит типовые буквы и превращает документ в текстовый; то с рукописным есть свои особенности. Они связанны с тем, что буквы, написанные от руки, часто отличаются от образцовых, ведь у всех разный почерк. Да, есть определённые шаблоны и правила написания письменных букв, но их придерживаются разве что в начальной школе. Со временем почерк формируется и в некоторых деталях буквы уже не такие, какие должны быть.
Они связанны с тем, что буквы, написанные от руки, часто отличаются от образцовых, ведь у всех разный почерк. Да, есть определённые шаблоны и правила написания письменных букв, но их придерживаются разве что в начальной школе. Со временем почерк формируется и в некоторых деталях буквы уже не такие, какие должны быть.
- Таким образом, качество распознавания будет тем лучше, чем почерк на рукописи близок к идеальному. Особые трудности возникнут, если почерк в рукописи необычный, и непонятный даже человеческому глазу. Здесь придётся значительно корректировать после распознавания.
- Также качество распознавания можно улучшить, если убрать из фото с рукописью лишние элементы, например, рисунки, таблицы и прочее. Нужно оставить только текст, который следует распознать.
- И, конечно же, чем лучше качество фото с рукописью (цвет, контраст, чёткость, разрешение), тем лучше будет распознавание.
Но даже при соблюдении всех условий, в 95% случаев после распознавания рукописного текста, приходится дорабатывать результат и исправлять моменты, которые программа не смогла корректно обработать.
Вам это может быть интересно: Расшифровка почерка врачей онлайн по фото.
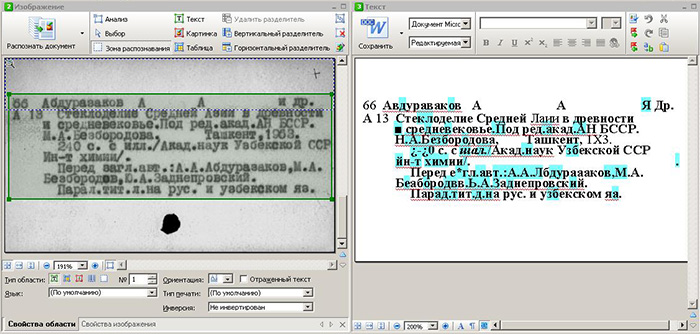
Онлайн распознавание Convertio
Convertio является одним из популярных сервисов онлайн распознавания. Это условно-бесплатный инструмент, в котором можно без регистрации распознавать до 10 файлов. Если зарегистрироваться, то на бесплатном тарифе можно уже поработать с 50 документами. Этого вполне хватает для пробы сервиса и рядовой работы. Если нужно больше, то придётся оплачивать. С тарифами можно познакомиться здесь https://convertio.co/ru/ocr/pricing/.
К функциям и достоинствам данного сервиса можно отнести следующее:
- Работает онлайн через браузер на любом устройстве. Поэтому не требуется установка никаких программ.
- Есть расширение для популярных браузеров. Удобно в том случае, если распознавать нужно много и часто.
- Работает как с печатными, так и с рукописными текстами.
- Загрузить файл можно как из компьютера в виде изображения, так и из облачных хранилищ DropBox и Google Диск, либо по URL на файл изображения с текстом.

- Сервис умеет работать не только с распознаванием текстов, но и с конвертацией файлов одного формата в другой, в том числе и с мультимедийными файлами.
- Поддерживает более 25 000 форматов файлов. С полным списком можно познакомиться здесь https://convertio.co/ru/formats/.
- Гарантируется безопасность и конфиденциальность обработанных файлов.
Рассмотрим подробнее, как этим пользоваться для того, чтобы переделать рукописный текст в печатный:
- Перейдите на страницу онлайн распознавателя https://convertio.co/ru/ocr/. Загрузите файл изображения с рукописным текстом удобным вам способом — с компьютера, через облако или по URL. Изображение может быть в форматах PDF, JPG, BMP, GIF, JP2, JPEG, PBM, PCX, PGM, PNG, PPM, TGA, TIFF или WBMP.
- Файл загрузится в сервис. Теперь прокрутите немного ниже и убедитесь, что сервис правильно определил язык документа, а также задайте нужный формат итогового файла, по умолчанию это .doc, который открывается через Word.
 Если в исходном файле несколько страниц, то можно выбрать нужные. Когда все опции заданы, нажмите кнопку «Распознать». В большинстве случаев обработка файлов происходит в течение двух минут.
Если в исходном файле несколько страниц, то можно выбрать нужные. Когда все опции заданы, нажмите кнопку «Распознать». В большинстве случаев обработка файлов происходит в течение двух минут. - Когда операция будет завершена, вам будет предложено скачать готовый файл в выбранном вами формате.
img2txt — простой сервис онлайн распознавания
От предыдущего сервиса, данный инструмент отличается простотой. В нём нет никаких дополнительных возможностей, кроме распознавания текста с изображения. Поддерживает, как рукописный, так и напечатанный шрифты. Он абсолютно бесплатный, но на страницах сервиса можно увидеть рекламу, которая совершенно не навязчивая.
Из функций и достоинств нужно отметить следующее:
- Также не требует установки на устройство никаких программ и работает онлайн через браузер.
- Поддерживает русский, украинский, английский, а также ещё более 35 языков Азии и Европы.
- Можно загрузить файл с компьютера либо по URL. Максимальный вес — 8 мб.

- В качестве источника поддерживаются форматы JPG, JPEG, PNG и PDF, а выходной файл может быть в TXT, PDF, DOCX или ODF.
- Обеспечивается безопасность распознанных файлов.
Работать с этим сервисом просто:
- Перейдите на страницу https://img2txt.com/ru и загрузите файл с компьютера либо по ссылке (в соседней вкладке загрузчика).
- Когда вы увидите сообщение об успешной загрузке, в списке ниже выберите язык документа, а потом нажмите кнопку «Загрузить».
- Дождитесь завершения обработки. В это время нельзя обновлять страницу и закрывать браузер.
- Вы получите результат, с которым сможете делать разнообразные операции: скопировать, перевести на другой язык, проверить орфографию, редактировать в Google Doc или скачать.
Text Scanner — распознавание рукописного текста на Android
Для использования такого метода вам понадобится мобильное устройство под управлением Android и интернет. Здесь потребуется установить приложение. На момент создания данного обзора это приложение является одним из самых оценённых в Google Play, и оценивается пользователями в 4,6 баллов. Имеется большое количеств положительных отзывов.
На момент создания данного обзора это приложение является одним из самых оценённых в Google Play, и оценивается пользователями в 4,6 баллов. Имеется большое количеств положительных отзывов.
Рассмотрим достоинства и функции этого сканера текстов:
- Приложение бесплатное, но в нём присутствует реклама. Однако она не мешает пользоваться программой. Есть платная версия с дополнительным функционалом и без рекламы.
- Фото с текстом можно загрузить как через файл в файловом менеджере устройства, так и с помощью фотокамеры.
- Есть возможность включить вспышку камеры, чтобы сделать более качественный снимок. Качество снимка с текстом значительно влияет на качество распознавания.
- Можно обрезать лишние элементы на фото прямо в этом приложении до сканирования. Лишние детали, кроме текста, могут негативно повлиять на качество распознавания.
Пользоваться мобильным приложения для распознавания рукописного текста так же легко, как и описанными выше браузерными способами:
- Скачайте Text Scanner из Google Play на своё устройство с Android по ссылке.
 После установки запустите приложение. Если появятся запросы на использование различных функций устройства (камеры или файлового менеджера), то согласитесь.
После установки запустите приложение. Если появятся запросы на использование различных функций устройства (камеры или файлового менеджера), то согласитесь. - Если вы хотите загрузить фото с текстом из галереи, то нажмите вверху справа на кнопку галереи. А если хотите сфотографировать рукопись, то нажмите на кнопку камеры внизу справа (при этом может появляться запрос на оплату приложения, которое можно закрыть крестиком и продолжать пользоваться бесплатно).
- После загрузки вы увидите фото в редакторе приложения. Если на фото есть лишние элементы. то нажмите кнопку «Crop», чтобы обрезать изображение и оставить только текст. Обрезать можно простым перетаскиванием границ.
- Когда изображение готово, нажмите «Scan», чтобы начать сканирование и распознавание текста.
- В результате вы получите распознанный текст, который можно скопировать и вставить в другом редакторе либо поделиться им через социальные сети или мессенджеры.
А ниже вы можете увидеть видео об ещё одном способе перевести рукописный текст в печатный. Он более качественный, но трудоёмкий и не использует функции распознавания.
Он более качественный, но трудоёмкий и не использует функции распознавания.
Главная » Программы
Автор Рамиль Опубликовано Обновлено
Искусственный интеллект, нейронные сети и распознавание рукописного текста
Технология
Искусственный интеллект полностью меняет наши представления о том, как люди записывают информацию, и открывает новые горизонты для развития технологии цифрового рукописного ввода.
Важность искусственного интеллекта
Вместо полного термина «искусственный интеллект» часто используется аббревиатура «ИИ». Это направление информатики, где изучаются принципы создания интеллектуальных машин, способных воспроизводить и дополнять определенные функции человеческого мозга, в частности навыки чтения, понимания или анализа.
Это направление информатики, где изучаются принципы создания интеллектуальных машин, способных воспроизводить и дополнять определенные функции человеческого мозга, в частности навыки чтения, понимания или анализа.
Искусственный интеллект в MyScript
В основе наших главных программных продуктов лежит модуль ИИ собственной разработки. Искусственный интеллект помогает нам распознавать рукописное содержимое на более чем 70 языках, анализировать структуру рукописных заметок, понимать математические уравнения и даже определять и преобразовывать записанные от руки ноты.
Мы развиваем и совершенствуем эту технологию уже более 20 лет. Стремясь создать самый точный в мире модуль распознавания рукописного текста, мы провели (и продолжаем проводить) множество исследований, посвященных языковым нюансам: построение предложений от уровня слова и слов от уровня символа, правила размещения диакритических знаков над определенными гласными или под ними и т.
Несколько групп исследователей MyScript непрерывно работают над оптимизацией лучшей в своем классе системы, способной распознавать впечатляющий массив рукописного содержимого.
Исследования по рукописному вводу текста
Наши специалисты из отдела исследований по рукописному вводу текста занимаются решением проблем с преобразованием последовательностей (seq2seq) — например, преобразование рукописного текста в составляющие его символы — при помощи технологий машинного обучения.
Их необходимо адаптировать с учетом алфавитов мира и конвенций. Это обязательное условие для распознавания, например, языков с написанием справа налево, в частности арабского и иврита, диакритических гласных в индийских текстах, китайских иероглифов, корейского алфавита Хангыль либо вертикальных символов из японских азбук хирагана, катакана и кандзи.
Исследования по рукописному вводу двумерного текста
Этот отдел отвечает за построение математических моделей на основе синтаксических анализаторов двумерных массивов и/или грамматических правил. Они занимаются теми проблемами, которые невозможно решить методом преобразования последовательностей. Это распознавание математических выражений, нот или диаграмм и графиков. Эти специалисты применяют для распознавания методы на основе графиков. Основной сложностью является обработка данных в режиме реального времени.
Исследования по обработке текстов на естественном языке
Наши специалисты по обработке текстов на естественном языке создают алгоритмы, умеющие воспринимать языки так же естественно, как человек. Это подразделение работает с корпусом текстов, где содержатся сотни миллионов слов из общедоступных документов и статей.
Сбор данных
Немалая часть нашей работы строится на обработке анонимных образцов данных, которые добровольно присылают нам пользователи из разных стран мира. В отношении этих «обучающих примеров» (так их называют исследователи искусственного интеллекта) всегда применяются самые строгие стандарты конфиденциальности и защиты. Это очень ценная для компании информация, которая позволяет нам совершенствовать и расширять возможности технологии.
Распознавание рукописного текста: сложности
Распознавание рукописного текста неразрывно связано с серьезными техническими сложностями из-за огромной вариативности почерков. На результат могут повлиять возраст автора, ведущая рука, родная страна, даже поверхность, на которой он пишет, — и все это без учета влияния языка и алфавита.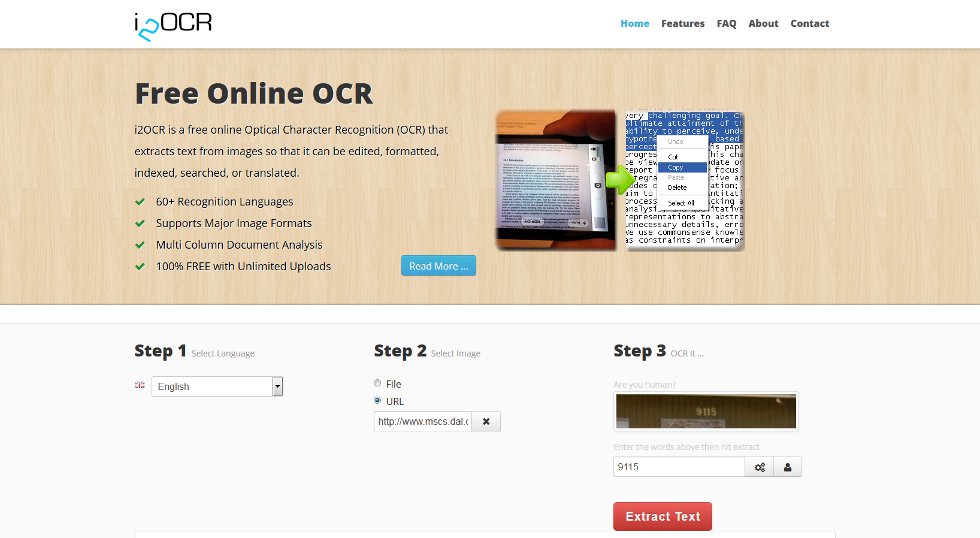
Чтобы проиллюстрировать это наглядно, приведем пример: эффективное ПО для распознавания рукописного текста должно уметь выделить нужный китайский иероглиф среди более 30 000 возможных вариаций. Ожидается также, что оно будет поддерживать функции распознавания и расшифровки двунаправленного письма, чтобы исключить сбои, когда в языке с написанием справа налево (например, арабский или иврит) встречаются иностранные слова с написанием слева направо.
Почерк со слитным написанием еще больше усложняет задачи по сегментации и распознаванию отдельных символов, а задержки при добавлении штрихов (в частности диакритических знаков) вносят дополнительную путаницу. Характерное для них отсутствие четкой структуры делает автоматический анализ содержимого еще более трудоемким. Не упрощает его и наличие объектов из других категорий: математических выражений, графиков и таблиц.
Важен также фактор времени: ПО для распознавания рукописного текста должно анализировать вводимые пользователем данные в режиме реального времени, по мере написания. Если пользователь вносит правки, например зачеркивает слово, чтобы удалить его, вставляет пробел или перемещает абзац, то модуль распознавания должен отреагировать своевременно.
Если пользователь вносит правки, например зачеркивает слово, чтобы удалить его, вставляет пробел или перемещает абзац, то модуль распознавания должен отреагировать своевременно.
Инвестиции в развитие нейронных сетей
Более 20 лет назад, когда международное сообщество по изучению принципов распознавания рукописного текста активно исследовало скрытые марковские модели и методы опорных векторов, компания MyScript выбрала другой путь.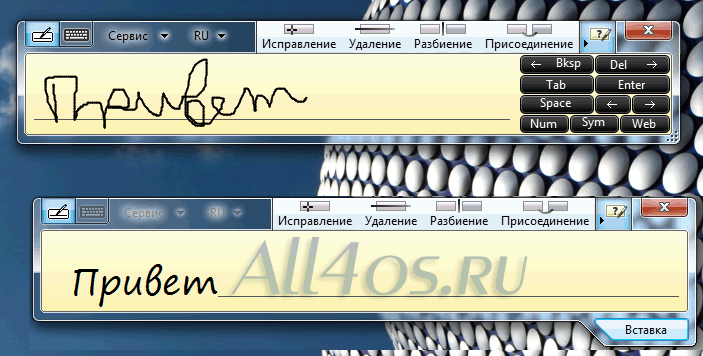
Мы решили сосредоточиться на нейронных сетях.
Нейронная сеть — это метод машинного обучения, копирующий процессы познания, которые протекают в мозге человека. Мощные алгоритмы в основе нейронной сети позволяют выявлять шаблоны в больших наборах данных, повышая точность обобщений в изучаемой области — в нашем случае это рукописный ввод текста.
Нейронные сети состоят из математических моделей, которые «учатся» находить шаблоны при помощи заранее заданных переменных («критерии»). Тщательно запрограммированные алгоритмы постоянно разделяют и сортируют данные на основании указанных критериев, снова и снова классифицируя их до обнаружения четких шаблонов.
Это значит, что нейронным сетям под силу задачи, с которыми не сможет справиться человек. Они с высокой скоростью «просеивают» огромные объемы информации, позволяя регистрировать шаблоны, во всех других случаях ускользнувшие бы от внимания.
Распознавание рукописного текста при помощи нейронных сетей
Изначально идея заключалась в предварительной обработке рукописного содержимого для подготовки к анализу: извлечение строк, выравнивание тона чернил и исправление наклоненных символов. Затем предполагалось выполнять сверхсегментацию и пропускать текст через модуль распознавания для обнаружения границ между символами и словами.
Это подразумевало построение графика сегментации путем моделирования всех существующих вариантов: в сущности, группировка смежных сегментов в предполагаемые комбинации символов, которые бы после этого классифицировались при помощи нейронных сетей прямого распространения. Мы выбрали инновационный подход, основанный на схеме глобального дифференцированного обучения.
Мы также совершили небольшую революцию, создав и внедрив статистическую языковую модель, объединявшую в себе лексические, грамматические и семантические данные. Она сделала возможным уточнение результатов и устранение части противоречий при наличии нескольких подходящих символов.
Обучение искусственного интеллекта для двумерных языков
Использование нейронных сетей принесло нам успех и позволило создать лучший в мире модуль распознавания, поддерживающий работу и с печатными, и с рукописными символами. Но некоторые языки оказались намного более сложными по структуре, в результате чего перед нами возникла новая сложность.
Распознавание китайских символов
За время своего существования компания MyScript создала целый ряд технических решений по анализу и распознаванию двумерных языков, особенно китайских иероглифов.
Когда большинство наших конкурентов пошло по пути анализа и распознавания китайских символов при помощи моделей в виде деревьев решений, мы сконцентрировали все усилия на совершенствовании нейронных сетей, обучая наш модуль так, чтобы он мог узнать любой из более чем 30 000 иероглифов.
Впервые в истории отрасли исследовательскому подразделению удалось успешно подготовить к работе настолько крупную сеть. Это стало возможным благодаря масштабной кампании по сбору данных, позволившей нам накопить крупнейший массив текстов с рукописными символами на китайском языке.
На основе этих данных была выстроена новая нейронная архитектура, где учитывались все особенности написания китайских иероглифов. Кроме того, мы добавили специальный механизм кластеризации, чтобы обработка происходила быстрее. Эти инновационные методики помогли нам выйти на новый уровень распознавания рукописных текстов в сегменте, где ввод данных с клавиатуры остается чрезмерно сложной и негибкой процедурой. Кроме того, за счет этого удалось обеспечить аналогичный уровень поддержки для других языков, в том числе японского, хинди и корейского.
Кроме того, за счет этого удалось обеспечить аналогичный уровень поддержки для других языков, в том числе японского, хинди и корейского.
Распознавание математических выражений
Когда нейронные сети научились успешно анализировать и распознавать тексты на самых разных языках мира, мы поставили перед собой новую цель: познакомить наш модуль с математическими выражениями.
Если в регулярных языках символы и слова объединяются в структурные последовательности, то в двумерных языках (с визуальным синтаксисом) преобладает структура дерева или графа с пространственными отношениями между узлами. Как и в случае с текстами, наша система распознавания математических выражений строится на том принципе, что для получения самых точных результатов процессы сегментации, распознавания и грамматико-синтаксического анализа должны протекать одновременно и на одном уровне.
Наш модуль определяет пространственные отношения между частями математического уравнения по правилам, на которых основывается его особая грамматическая структура, а затем использует эти данные для разбивки выражения на сегменты.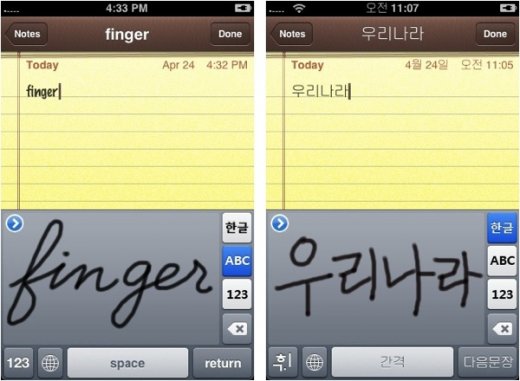 Грамматическая структура сама по себе представляет набор правил, описывающих принципы анализа уравнения. Каждому правилу соответствует конкретное пространственное отношение. Например, правило дроби определяет вертикальные взаимоотношения между числителем, дробной чертой и знаменателем.
Грамматическая структура сама по себе представляет набор правил, описывающих принципы анализа уравнения. Каждому правилу соответствует конкретное пространственное отношение. Например, правило дроби определяет вертикальные взаимоотношения между числителем, дробной чертой и знаменателем.
Понимание неупорядоченных заметок
Возможность быстро и точно распознавать математические выражения открыла совершенно новые возможности для работы со структурой и содержимым рукописных заметок.
Если модуль распознавания способен правильно определять пространственные отношения между частями математических уравнений, может ли он так же точно классифицировать нетекстовые объекты? Если да, то это позволило бы справиться с проблемами обработки неупорядоченных заметок, используя нашу технологию для точного определения элементов и даже улучшения вида некоторых из них, например нарисованных от руки диаграмм.
Мы посчитали, что для этих целей лучше всего подойдут графовые нейронные сети (GNN). В данном случае основной идеей является представление всего документа в виде графа, где штрихи представлены узлами и соединены с соседними штрихами при помощи ребер.
При анализе содержимого заметки таким способом графовая нейронная сеть должна классифицировать каждый штрих как текстовый или нетекстовый символ. Для этого проверяются собственные характеристики каждого штриха и (если необходимо) контекстные данные, полученные от его соседних ребер и узлов.
Один из уровней в графовой нейронной сети объединяет все характеристики узла с характеристиками соседних объектов и формирует вектор числовых значений, представляющих характеристики более высокого уровня. Как и в сверточных нейронных сетях, поддерживается объединение нескольких уровней в стек для получения большего числа глобальных характеристик и, соответственно, более точного отнесения штрихов к текстовым или нетекстовым. На схеме ниже, например, 2 вертикальные линии слева кажутся одинаковыми. И только после получения контекстных данных от соседних штрихов графовая нейронная сеть может на уровне вывода классифицировать их как часть прямоугольника (крайняя левая черта) и часть символа T.
На схеме ниже, например, 2 вертикальные линии слева кажутся одинаковыми. И только после получения контекстных данных от соседних штрихов графовая нейронная сеть может на уровне вывода классифицировать их как часть прямоугольника (крайняя левая черта) и часть символа T.
Глубокое обучение и модель кодирования/декодирования
Пары лучших в своем классе систем для распознавания текста и математических выражений тоже может оказаться недостаточно — особенно для пользователей, работающих или обучающихся для работы в определенной сфере науки. Им часто нужно записывать математические формулы прямо во время ввода текста (не в специально выделенном пространстве на странице), и они рассчитывают, что модуль распознавания сможет обработать их правильно.
Сложность заключалась в том, чтобы создать систему, которая могла бы распознавать символы и слова наряду с математическими выражениями, то есть анализировать сочетания символов из естественного одномерного языка (текст) и двумерного языка (математические формулы).
С появлением технологии глубокого обучения пришли новые архитектуры нейронных сетей. Одна из них, модель кодирования/декодирования, стала очень популярным средством решения проблем с преобразованием последовательностей. Она позволяет обрабатывать вводимые и выводимые строки переменной длины, поэтому быстро приобрела популярность в сферах, как-либо связанных с распознаванием рукописного текста (например, распознавание речи). Главным преимуществом технологии кодирования/декодирования является комплексное обучение, в отличие от систем, где каждый элемент необходимо обучать отдельно. Поддерживается внедрение нескольких архитектур, в том числе сверточных нейронных сетей, рекуррентных нейронных сетей, сетей с долгой краткосрочной памятью (LSTM) и сетей на основе механизма внимания, обычно используемых в модели Transformer (среди множества прочих).
В нашем случае модель кодирования/декодирования получает данные в виде последовательности координат, где отражена траектория рукописных штрихов. 2 вместо x² или (\frac{ }) вместо дроби).
2 вместо x² или (\frac{ }) вместо дроби).
Будущее рукописного ввода на основе искусственного интеллекта
Эволюция технологий распознавания рукописного текста еще даже не приблизилась к финальной стадии. Мы уже расширяем возможности ИИ для решения таких задач, как автоматическое определение языка и распознавание интерактивных рукописных таблиц.
Мы убеждены, что модели глубокого обучения имеют огромный потенциал развития. Возможно, они помогут нам унифицировать подход в тех сферах исследования, которые раньше не считались смежными (например, обработка текстов на естественном языке и анализ структуры). Принимая во внимание исключительную доступность цифровых устройств с поддержкой сенсорного ввода, мы уверены, что алгоритмы искусственного интеллекта помогут нам перейти от распознавания увиденного к распознаванию намерения. При анализе уже написанного содержимого разница может казаться минимальной, но в действительности это станет новой парадигмой. И мы готовы помочь взять этот барьер.
И мы готовы помочь взять этот барьер.
Нам хотелось бы, чтобы каждый в этом мире мог создавать любое содержимое на привычном ему устройстве будто бы на листе бумаги, но со всеми возможностями и максимальной гибкостью цифрового формата. Благодаря потенциалу искусственного интеллекта эта концепция с каждым днем все ближе к своему воплощению.
Технология
Пользовательский опыт в контексте цифрового рукописного ввода с поддержкой естественных жестов
Что такое оптическое распознавание символов? – Azure Cognitive Services
- Статья
- Чтение занимает 3 мин
Оптическое распознавание символов (OCR) позволяет извлекать печатный или рукописный текст из изображений, таких как фото вывесок и продуктов, а также из документов — счетов, ведомостей, финансовых отчетов, статей и т. д. Технологии OCR Майкрософт поддерживают извлечение печатного текста на нескольких языках.
д. Технологии OCR Майкрософт поддерживают извлечение печатного текста на нескольких языках.
Чтобы приступить к работе с REST API или клиентским пакетом SDK, следуйте инструкциям из краткого руководства. Вы также можете быстро и легко опробовать возможности OCR в браузере с помощью Vision Studio.
Опробовать Vision Studio
Эта документация включает статьи следующих видов:
- Краткие руководства — пошаговые инструкции, которые помогут вам вызвать службу и быстро получить результат.
- Практические руководства — содержат инструкции для более специфического или специализированного использования службы.
Чтобы узнать о более структурированном подходе, изучите модуль обучения OCR.
- Чтение текста на изображениях и в документах с помощью службы “Компьютерное зрение”
API чтения
API чтения Компьютерного зрения — это новейшая технология оптического распознавания символов (узнайте о новых возможностях), которая позволяет извлекать печатный текст (на нескольких языках), рукописный текст (только на английском языке), а также цифры и символы валют из изображений и многостраничных PDF-документов. Она оптимизирована для извлечения текста из изображений с большим объемом текста и многостраничных PDF-документов на различных языках. API может извлекать печатный и рукописный текст из одного и того же изображения или документа.
Она оптимизирована для извлечения текста из изображений с большим объемом текста и многостраничных PDF-документов на различных языках. API может извлекать печатный и рукописный текст из одного и того же изображения или документа.
Требования к входным данным
При вызове Read в качестве входных данных используются изображения и документы. Для них действуют следующие требования:
- Поддерживаемые форматы файлов: JPEG, PNG, BMP, PDF и TIFF
- Для файлов PDF и TIFF обрабатывается до 2000 страниц (только первые две страницы для бесплатного уровня доступа).
- Размер изображений должен быть менее 500 МБ (4 МБ для бесплатного уровня доступа), а их измерение — не менее 50 x 50 пикселей и не более 10000 x 10000 пикселей. PDF-файлы не имеют ограничения на размер.
- Минимальная высота извлекаемого текста составляет 12 пикселей для изображения 1024 x 768. Это примерно соответствует 8-му шрифту при разрешении 150 точек на дюйм.
Поддерживаемые языки
Последняя общедоступная модель API чтения поддерживает 164 языка для печатного и 9 языков для рукописного текста.
OCR для печатного текста включает поддержку английского, французского, немецкого, итальянского, португальского, испанского, китайского, японского, корейского, русского, арабского, хинди и других международных языков, использующих латиницу, кириллицу, арабское письмо и символы деванагари.
Распознавание рукописного текста включает поддержку английского, испанского, итальянского, китайского (упрощенное письмо), корейского, немецкого, португальского, французского и японского языков.
Узнайте, как указать версию модели для использования предварительных версий поддержки языков и функций. См. полный список языков, поддерживаемых OCR.
Основные возможности
Функция Read API включает следующие функции.
- Извлечение печатного текста на 164 языках
- Извлечение рукописного текста на 9 языках
- Текстовые строки и слова с указанием местоположения и оценки достоверности
- Необходимость в распознавании языка отсутствует
- Поддержка смешанных языков, смешанный режим (печать и рукописный ввод)
- Выбор страниц и диапазонов страниц из больших, многостраничных документов
- Естественный порядок чтения для выходных данных строки текста (только для языков на основе латиницы)
- Рукописная классификация текстовых строк (только для языков на основе латиницы)
- Функция доступна как контейнер Distroless Docker для локального развертывания
Узнайте, как использовать функции OCR.
Использование облачного API или развертывание в локальной среде
Для большинства клиентов рекомендуется использовать облачные версии API чтения версии 3.x: их легко интегрировать и начать с ними работу. Azure и служба Компьютерное зрение обеспечивают масштабирование, производительность, безопасность данных и соответствие требованиям, а вы можете сосредоточиться на обслуживании своих клиентов.
Контейнер Docker для чтения (предварительная версия) позволяет развертывать новые возможности OCR в собственной локальной среде. Контейнеры соответствуют конкретным требованиям к безопасности и управлению данными.
Предупреждение
Операции RecognizeText и ocr Компьютерного зрения более не поддерживаются и находятся в процессе вывода из эксплуатации. Вместо них следует использовать API чтения, рассмотренные в этой статье. Существующим клиентам следует перейти на использование API чтения.
Конфиденциальность и безопасность данных
Как и в случае со всеми другими Cognitive Services, разработчикам, использующим API компьютерного зрения, следует учитывать политику корпорации Майкрософт касательно клиентских данных.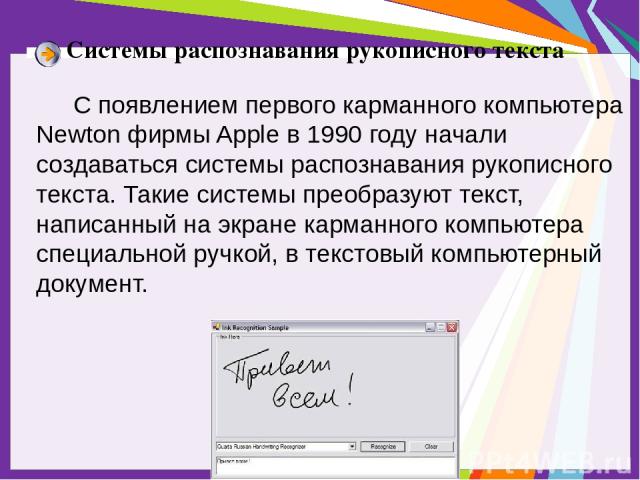 Дополнительные сведения см. на странице о Cognitive Services Центра управления безопасностью Майкрософт.
Дополнительные сведения см. на странице о Cognitive Services Центра управления безопасностью Майкрософт.
Дальнейшие действия
- Начните работу с краткими руководствами по REST API OCR (для чтения) или клиентским библиотекам.
- Дополнительные сведения о REST API чтения версии 3.2.
Распознаватель рукописного ввода в App Store
Описание
Лучшее приложение для распознавания рукописного текста и оптического распознавания символов.
Это абсолютно бесплатно для вас.
Вы можете писать рукописные текстовые заметки, список или любую форму текста от бумаги до редактируемого текста на вашем устройстве всего одним щелчком мыши.
ХАРАКТЕРИСТИКИ:
– Поддержка голландского, английского, французского, немецкого, итальянского, португальского и испанского языков.
– Поддержка смешанных или нескольких языков в одном изображении.
Подпишитесь, чтобы получить неограниченный доступ к основным функциям приложения.
Стоимость подписки составляет 1,49 долларов США в месяц или 11,99 долларов США в год. Цены равны значению, которое «Матрица ценообразования Apple App Store» определяет как эквивалент стоимости подписки в долларах США.
– Все цены могут быть изменены без уведомления. Иногда мы используем рекламные цены в качестве поощрений или ограниченных по времени возможностей для соответствующих покупок, совершенных в течение рекламного периода. Из-за срочности и рекламного характера этих мероприятий мы не можем предложить защиту цен или ретроактивные скидки или возмещение за предыдущие покупки в случае снижения цены или рекламного предложения.
— оплата будет снята с учетной записи iTunes при подтверждении покупки
— подписка автоматически продлевается на ту же цену и срок действия, что и исходный пакет «1 месяц»/«1 год», если автоматическое продление не отключено по крайней мере 24 -часов до окончания текущего периода
– С аккаунта будет взиматься плата за продление в течение 24 часов до окончания текущего периода за счет выбранного пакета (недельного, месячного или годового пакета)
– Подписки может управляться пользователем, а автоматическое продление может быть отключено в настройках учетной записи пользователя iTunes после покупки
— Отмена текущей подписки не допускается в течение активного периода подписки.
— Вы можете отменить подписку в течение ее бесплатного пробного периода в настройках подписки в своей учетной записи iTunes. Это необходимо сделать за 24 часа до окончания периода подписки, чтобы избежать списания средств. Пожалуйста, посетите http://support.apple.com/kb/ht4098 для получения дополнительной информации
— Вы можете отключить автоматическое продление подписки в настройках своей учетной записи iTunes. Однако вы не можете отменить текущую подписку в течение ее активного периода
– Любая неиспользованная часть бесплатного пробного периода будет аннулирована, когда пользователь приобретет подписку на приложение для чтения рукописного ввода.
Условия использования, политика конфиденциальности, политика подписки:
https://cruxsolution-practice-project.firebaseapp.com/privacy.html
https://cruxsolution-practice-project.firebaseapp.com/tos.html
Версия 2.0
Незначительные исправления ошибок
Рейтинги и обзоры
2,1 тыс. оценок
только запись в текстовое приложение с правами
Мне нравится писать заметки от руки, но я предпочитаю хранить и использовать их в цифровом виде, но в прошлом у меня был минимальный успех с этим типом программного обеспечения, особенно потому, что мой почерк немного беспорядочный. поэтому я загрузил 6 лучших приложений с OTC, которые я смог найти, и попробовал их все на одной и той же короткой странице 4×6 заметок, которые я изо всех сил старался писать разборчиво. Я потерял надежду после того, как буквально все остальные напечатали беспорядок из искаженных букв, которых не хватило даже на половину отсканированной мной страницы.
видя, что у этого приложения было меньше отзывов и оно было явно не таким популярным, как другие, я подумал, что, конечно, оно не будет лучше, но все, что мне нужно было сделать, это открыть приложение и сделать снимок, и оно вернуло почти безупречное воссоздание моего примечания в текст. а затем то же самое произошло с несколькими другими страницами, которые я начал сканировать. здесь и там были небольшие однобуквенные ошибки, но все они легко исправимы и достаточно незначительны, чтобы они даже не мешали пониманию заметок, если я оставлю их как есть. ему даже удалось распознать мои крайне неаккуратные звездочки и сделать из них звездочки. Я обычно не заморачиваюсь с отзывами, но я просто счастлив с этим приложением! (в настоящее время я просто использую полностью бесплатную версию, но вполне могу обновить ее, если буду использовать ее так часто, как я подозреваю, что буду. но реклама довольно ненавязчива, поэтому я пока даже не возражаю против нее)
Ого Спасибо!!
У меня есть рукописные заметки на два месяца, которые мне нужно расшифровать для книги, которую я пытаюсь закончить к концу года.
Мой ноутбук в настоящее время возвращается к производителю для ремонта, что означало задержку около двух недель в моем будущем. Когда я услышал (и помолился), что существует такая технология, где можно это сделать, я проверил ее. Для меня, если приложение не является удобным для пользователя и не является всеобъемлющим, я готов. Это приложение взорвало мой мозг. Это было просто, быстро и, что удивительно, почти абсолютно точно на каждой странице, написанной от руки. Я думал: «Ни за что эта штука не сможет вычислить мою куриную царапину», но оказалось, что я ошибался. У меня было очень мало исправлений, но это больше из-за его неряшливого почерка, чем из-за чего-либо еще. Затем сохранение/перенос на Google Диск, где я храню остальные заметки, которые у меня уже есть для моей книги, было проще простого. Я не думаю, что вы могли бы попросить более совершенное приложение для этой конкретной потребности.
Я думаю, что наконец нашел приложение для меня!
Я ВЕЧНОСТЬ искал приложение, которое могло бы помочь мне с КУЧАМИ рукописных заметок, идей, исследований и т.
д., которые валяются у меня дома в коробках, картотеках, папках и приклеены к моей стене. И позвольте мне сказать вам… ЭТО ПРИЛОЖЕНИЕ, ЧТОБЫ ДЕЛАТЬ ДЕЛА!! У меня отличный почерк… нормальный. Но когда у меня появляется идея для моей книги или нового OC, у меня нет времени, чтобы быть аккуратным или даже разборчивым. Я просто пишу так быстро, как приходит момент мысли/идеи/озарения, и надеюсь, что моя рука не отстанет от моего нового откровения, чтобы положить конец всем откровениям. Так что можно только представить состояние этих нот. Честно говоря, я думал, что никакое приложение для распознавания рукописного ввода не сможет мне помочь… но потом я нашел это и могу честно сказать, что я НЕВЕРОЯТНО впечатлен. Это не идеально, но ЕМУ БОГУ МОЖЕТ ПОЛУЧИТЬСЯ КАК МИНИМУМ 85-9СКИДКА 5% НА СЛОВА. ПЕРВАЯ ПОПЫТКА! И ЭТО, мой друг, приложение, которое стоит держать под рукой!
Разработчик, М. Мохсин, указал, что политика конфиденциальности приложения может включать обработку данных, как описано ниже. Для получения дополнительной информации см. политику конфиденциальности разработчика.
Для получения дополнительной информации см. политику конфиденциальности разработчика.
Данные, не связанные с вами
Могут быть собраны следующие данные, но они не связаны с вашей личностью:
- Данные об использовании
- Диагностика
Методы обеспечения конфиденциальности могут различаться, например, в зависимости от используемых вами функций или вашего возраста. Узнать больше
Информация
- Продавец
- М. Мохсин
- Размер
- 30,1 МБ
- Категория
- Образование
- Возрастной рейтинг
- 4+
- Авторское право
- © М Мохсин
- Цена
- Бесплатно
- Сайт разработчика
- Тех.
 поддержка
поддержка - Политика конфиденциальности
Еще от этого разработчика
Вам также может понравиться
Распознавание рукописного ввода на основе RNN в Gboard
Точки касания, кривые Безье и рекуррентные нейронные сети
Отправной точкой любого онлайн-распознавателя рукописного ввода являются точки касания. Нарисованный ввод представлен как последовательность штрихов, и каждый из этих штрихов, в свою очередь, представляет собой последовательность точек, к каждой из которых прикреплена временная метка. Поскольку Gboard используется на самых разных устройствах и с разными разрешениями экрана, наш первый шаг — нормализовать координаты точки касания. Затем, чтобы точно зафиксировать форму данных, мы преобразуем последовательность точек в последовательность кубических Кривые Безье для использования в качестве входных данных для рекуррентной нейронной сети (RNN), которая обучена точно идентифицировать записываемый символ (подробнее об этом шаге ниже). Хотя кривые Безье имеют давнюю традицию использования в распознавании рукописного ввода, их использование в качестве входных данных является новым и позволяет нам обеспечить согласованное представление ввода на устройствах с различной частотой дискретизации и точностью. Этот подход существенно отличается от наших предыдущих моделей, в которых использовался так называемый подход «сегмент-и-декодирование», который заключался в создании нескольких гипотез о том, как разложить штрихи на символы (сегменты), а затем найти наиболее вероятную последовательность символов из этого разложения ( расшифровать).
Хотя кривые Безье имеют давнюю традицию использования в распознавании рукописного ввода, их использование в качестве входных данных является новым и позволяет нам обеспечить согласованное представление ввода на устройствах с различной частотой дискретизации и точностью. Этот подход существенно отличается от наших предыдущих моделей, в которых использовался так называемый подход «сегмент-и-декодирование», который заключался в создании нескольких гипотез о том, как разложить штрихи на символы (сегменты), а затем найти наиболее вероятную последовательность символов из этого разложения ( расшифровать).
Еще одним преимуществом этого метода является то, что последовательность кривых Безье более компактна, чем лежащая в основе последовательность входных точек, что облегчает модели получение временных зависимостей вдоль входных данных — Каждая кривая представлена полиномом, определяемым начальная и конечная точки, а также две дополнительные контрольные точки, определяющие форму кривой. Мы используем итеративную процедуру, которая минимизирует квадраты расстояний (в x , y и времени) между нормализованными входными координатами и кривой, чтобы найти последовательность кубических кривых Безье, которые точно представляют входные данные. На рисунке ниже показан пример процесса подгонки кривой. Рукописный пользовательский ввод можно увидеть черным цветом. Он состоит из 186 точек касания и явно предназначен для слова 9.0150 иди . Желтым, синим, розовым и зеленым мы видим его представление через последовательность четырех кубических кривых Безье для буквы g (с двумя контрольными точками каждая), а соответственно оранжевый, бирюзовый и белый представляют три кривые, интерполирующие букву . о .
Мы используем итеративную процедуру, которая минимизирует квадраты расстояний (в x , y и времени) между нормализованными входными координатами и кривой, чтобы найти последовательность кубических кривых Безье, которые точно представляют входные данные. На рисунке ниже показан пример процесса подгонки кривой. Рукописный пользовательский ввод можно увидеть черным цветом. Он состоит из 186 точек касания и явно предназначен для слова 9.0150 иди . Желтым, синим, розовым и зеленым мы видим его представление через последовательность четырех кубических кривых Безье для буквы g (с двумя контрольными точками каждая), а соответственно оранжевый, бирюзовый и белый представляют три кривые, интерполирующие букву . о .
Декодирование символов
Последовательность кривых представляет входные данные, но нам все еще нужно преобразовать последовательность входных кривых в фактические письменные символы. Для этого мы используем многослойную RNN для обработки последовательности кривых и создания выходной матрицы декодирования с распределением вероятностей по всем возможным буквам для каждой входной кривой, обозначая, какая буква записывается как часть этой кривой.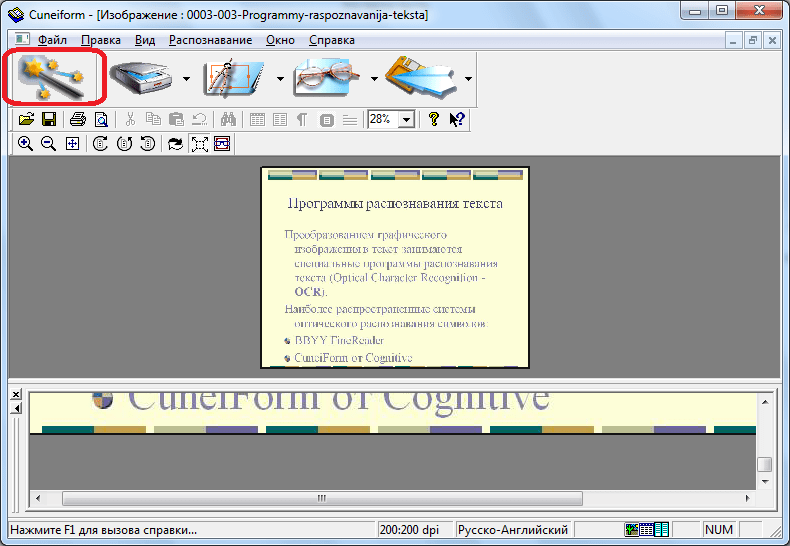
Мы экспериментировали с несколькими типами RNN и, наконец, остановились на использовании двунаправленной версии квази-рекуррентных нейронных сетей (QRNN). QRNN чередуются между сверточными и рекуррентными слоями, что дает теоретический потенциал для эффективного распараллеливания и обеспечивает хорошую прогностическую производительность при сохранении сравнительно небольшого количества весов. Количество весов напрямую связано с размером модели, которую необходимо загрузить, поэтому чем меньше, тем лучше.
Для «декодирования» кривых рекуррентная нейронная сеть создает матрицу, где каждый столбец соответствует одной входной кривой, а каждая строка соответствует букве в алфавите. Столбец для конкретной кривой можно рассматривать как распределение вероятностей по всем буквам алфавита. Однако каждая буква может состоять из нескольких кривых (например, g и o выше, состоят из четырех и трех кривых соответственно). Это несоответствие между длиной выходной последовательности из рекуррентной нейронной сети (которая всегда соответствует количеству кривых Безье) и фактическим количеством символов, которые должны представлять входные данные, устраняется добавлением специального символа 9.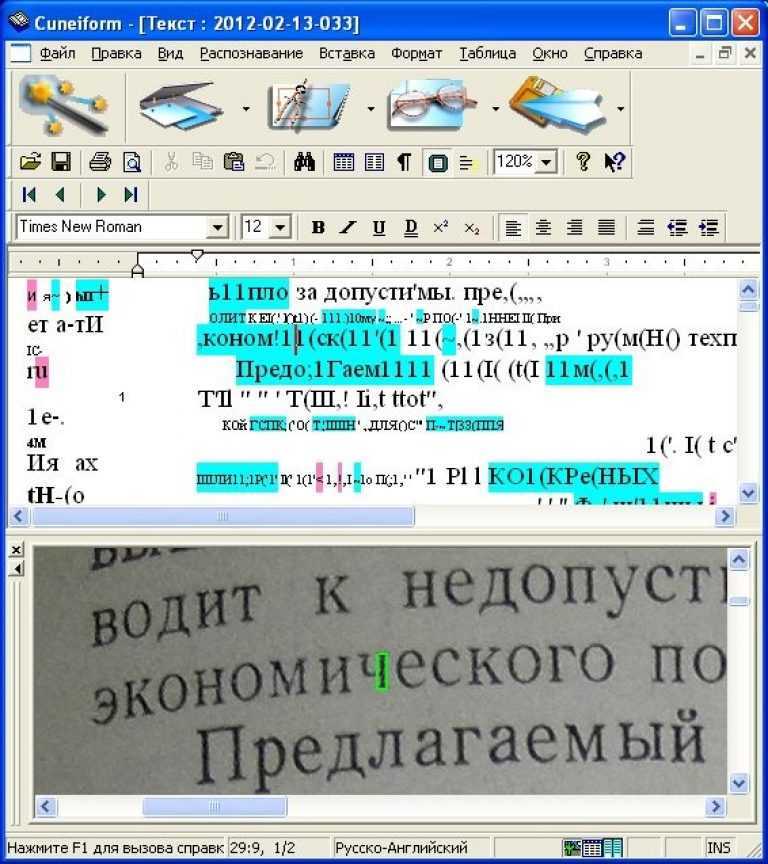 0150 пустой символ для обозначения отсутствия выходных данных для конкретной кривой, как в алгоритме временной классификации коннекционистов (CTC). Мы используем декодер конечного автомата, чтобы объединить выходные данные нейронной сети с моделью языка на основе символов, закодированной как взвешенный акцептор конечного состояния. Последовательности символов, которые распространены в языке (например, «sch» в немецком языке), получают бонусы и с большей вероятностью будут выводиться, тогда как необычные последовательности наказываются. Процесс визуализируется ниже.
0150 пустой символ для обозначения отсутствия выходных данных для конкретной кривой, как в алгоритме временной классификации коннекционистов (CTC). Мы используем декодер конечного автомата, чтобы объединить выходные данные нейронной сети с моделью языка на основе символов, закодированной как взвешенный акцептор конечного состояния. Последовательности символов, которые распространены в языке (например, «sch» в немецком языке), получают бонусы и с большей вероятностью будут выводиться, тогда как необычные последовательности наказываются. Процесс визуализируется ниже.
Последовательность точек касания (обозначенная цветом сегментов кривой, как на предыдущем рисунке) преобразуется в гораздо более короткую последовательность коэффициентов Безье (семь в нашем примере), каждый из которых соответствует одной кривой. Распознаватель на основе QRNN преобразует последовательность кривых в последовательность вероятностей символов той же длины, показанную в матрице декодера со строками, соответствующими буквам от «a» до «z» и пустому символу , где яркость входа соответствует его относительной вероятности. Проходя матрицу декодера слева направо, мы видим в основном пробелы и светлые точки для символов «g» и «o», в результате чего на выходе текста «go».
Проходя матрицу декодера слева направо, мы видим в основном пробелы и светлые точки для символов «g» и «o», в результате чего на выходе текста «go».
Несмотря на то, что наши новые модели распознавания символов значительно проще, они не только делают на 20-40% меньше ошибок, чем старые, но и намного быстрее. Однако все это еще нужно выполнять на устройстве!
Как заставить это работать, на устройстве
Чтобы обеспечить наилучшее взаимодействие с пользователем, недостаточно точных моделей распознавания — они также должны быть быстрыми. Чтобы добиться минимально возможной задержки в Gboard, мы конвертируем наши модели распознавания (обученные в TensorFlow) в модели TensorFlow Lite. Это включает в себя квантование всех наших весов во время обучения модели, так что вместо четырех байтов на вес мы используем только один, что приводит к меньшим моделям, а также к меньшему времени вывода. Кроме того, TensorFlow Lite позволяет нам уменьшить размер APK по сравнению с использованием полной реализации TensorFlow, поскольку он оптимизирован для небольшого двоичного размера, включая только те части, которые необходимы для логического вывода.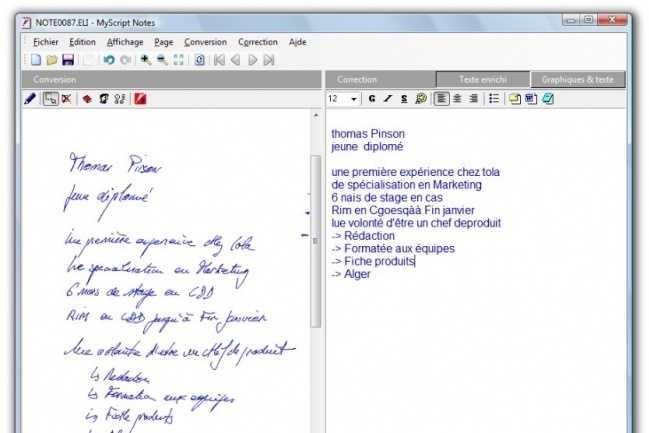
Еще не все
Мы продолжим расширять границы, помимо улучшения распознавателей латинского алфавита. Команда рукописного ввода уже усердно работает над запуском новых моделей для всех поддерживаемых нами языков рукописного ввода в Gboard.
Благодарности
Мы хотели бы поблагодарить всех, кто внес свой вклад в улучшение рукописного ввода в Gboard. В частности, Джатин Матани из команды Gboard, Дэвид Райбах из группы алгоритмов речи и языка, Прабху Калиамурти из группы Expander, Пит Уорден из команды TensorFlow Lite, а также Генри Роули, Ли-Лун Ван, Мирча. Трейчиою, Филипп Жерве и Томас Деселерс из группы почерков.
Авторы: Сандро Фойц и Педро Гоннет, старшие инженеры-программисты, команда рукописного ввода
В 2015 году мы запустили Google Рукописный ввод, который позволил пользователям вводить текст от руки на своем мобильном устройстве Android в качестве дополнительного метода ввода для любого приложения Android. При первом запуске нам удалось поддерживать 82 языка, от французского до гэльского, от китайского до малаялама. Чтобы обеспечить более удобный пользовательский интерфейс и устранить необходимость переключения методов ввода, в прошлом году мы добавили поддержку распознавания рукописного ввода на более чем 100 языках в Gboard для Android, клавиатуру Google для мобильных устройств.
При первом запуске нам удалось поддерживать 82 языка, от французского до гэльского, от китайского до малаялама. Чтобы обеспечить более удобный пользовательский интерфейс и устранить необходимость переключения методов ввода, в прошлом году мы добавили поддержку распознавания рукописного ввода на более чем 100 языках в Gboard для Android, клавиатуру Google для мобильных устройств.
С тех пор прогресс в области машинного обучения позволил создать новые архитектуры моделей и методологии обучения, что позволило нам пересмотреть наш первоначальный подход (который опирался на разработанную вручную эвристику для разделения рукописного ввода на отдельные символы) и вместо этого построить единую модель машинного обучения. который работает со всеми входными данными и существенно снижает количество ошибок по сравнению со старой версией. Мы запустили эти новые модели для всех языков на основе латиницы в Gboard в начале года и опубликовали документ «Быстрое многоязычное онлайн-распознавание рукописного ввода на основе LSTM», в котором более подробно объясняется исследование, лежащее в основе этого выпуска. В этом посте мы даем общий обзор этой работы.
В этом посте мы даем общий обзор этой работы.
Точки касания, кривые Безье и рекуррентные нейронные сети
Отправной точкой любого онлайн-распознавателя рукописного ввода являются точки касания. Нарисованный ввод представлен как последовательность штрихов, и каждый из этих штрихов, в свою очередь, представляет собой последовательность точек, к каждой из которых прикреплена временная метка. Поскольку Gboard используется на самых разных устройствах и с разными разрешениями экрана, наш первый шаг — нормализовать координаты точки касания. Затем, чтобы точно зафиксировать форму данных, мы преобразуем последовательность точек в последовательность кубических Кривые Безье для использования в качестве входных данных для рекуррентной нейронной сети (RNN), которая обучена точно идентифицировать записываемый символ (подробнее об этом шаге ниже). Хотя кривые Безье имеют давнюю традицию использования в распознавании рукописного ввода, их использование в качестве входных данных является новым и позволяет нам обеспечить согласованное представление ввода на устройствах с различной частотой дискретизации и точностью.
 Этот подход существенно отличается от наших предыдущих моделей, в которых использовался так называемый подход «сегмент-и-декодирование», который заключался в создании нескольких гипотез о том, как разложить штрихи на символы (сегменты), а затем найти наиболее вероятную последовательность символов из этого разложения ( расшифровать).
Этот подход существенно отличается от наших предыдущих моделей, в которых использовался так называемый подход «сегмент-и-декодирование», который заключался в создании нескольких гипотез о том, как разложить штрихи на символы (сегменты), а затем найти наиболее вероятную последовательность символов из этого разложения ( расшифровать). Еще одним преимуществом этого метода является то, что последовательность кривых Безье более компактна, чем базовая последовательность входных точек, что облегчает для модели получение временных зависимостей вдоль входных данных — Каждая кривая представлена полиномом, определяемым start и конечные точки, а также две дополнительные контрольные точки, определяющие форму кривой. Мы используем итеративную процедуру, которая минимизирует квадраты расстояний (в x , y и времени) между нормализованными входными координатами и кривой, чтобы найти последовательность кубических кривых Безье, которые точно представляют входные данные. На рисунке ниже показан пример процесса подгонки кривой. Рукописный пользовательский ввод можно увидеть черным цветом. Он состоит из 186 точек касания и явно предназначен для слова 9.0150 иди . Желтым, синим, розовым и зеленым мы видим его представление через последовательность четырех кубических кривых Безье для буквы g (с двумя контрольными точками каждая), а соответственно оранжевый, бирюзовый и белый представляют три кривые, интерполирующие букву . о .
Рукописный пользовательский ввод можно увидеть черным цветом. Он состоит из 186 точек касания и явно предназначен для слова 9.0150 иди . Желтым, синим, розовым и зеленым мы видим его представление через последовательность четырех кубических кривых Безье для буквы g (с двумя контрольными точками каждая), а соответственно оранжевый, бирюзовый и белый представляют три кривые, интерполирующие букву . о .
Декодирование символов
Последовательность кривых представляет входные данные, но нам все еще нужно преобразовать последовательность входных кривых в реальные письменные символы. Для этого мы используем многослойную RNN для обработки последовательности кривых и создания выходной матрицы декодирования с распределением вероятностей по всем возможным буквам для каждой входной кривой, обозначая, какая буква записывается как часть этой кривой.
Мы экспериментировали с несколькими типами RNN и, наконец, остановились на использовании двунаправленной версии квази-рекуррентных нейронных сетей (QRNN). QRNN чередуются между сверточными и рекуррентными слоями, что дает теоретический потенциал для эффективного распараллеливания и обеспечивает хорошую прогностическую производительность при сохранении сравнительно небольшого количества весов. Количество весов напрямую связано с размером модели, которую необходимо загрузить, поэтому чем меньше, тем лучше.
QRNN чередуются между сверточными и рекуррентными слоями, что дает теоретический потенциал для эффективного распараллеливания и обеспечивает хорошую прогностическую производительность при сохранении сравнительно небольшого количества весов. Количество весов напрямую связано с размером модели, которую необходимо загрузить, поэтому чем меньше, тем лучше.
Для «декодирования» кривых рекуррентная нейронная сеть создает матрицу, где каждый столбец соответствует одной входной кривой, а каждая строка соответствует букве в алфавите. Столбец для конкретной кривой можно рассматривать как распределение вероятностей по всем буквам алфавита. Однако каждая буква может состоять из нескольких кривых (например, g и o выше, состоят из четырех и трех кривых соответственно). Это несоответствие между длиной выходной последовательности из рекуррентной нейронной сети (которая всегда соответствует количеству кривых Безье) и фактическим количеством символов, которые должны представлять входные данные, устраняется добавлением специального символа 9.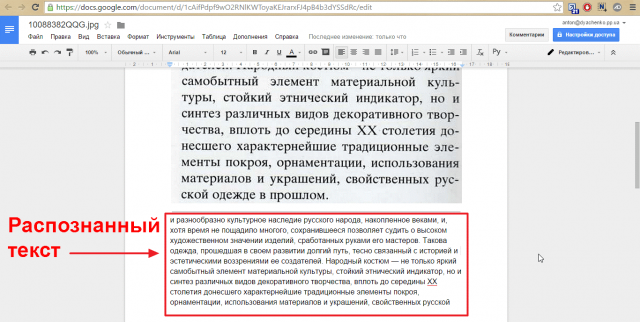 0150 пустой символ для обозначения отсутствия выходных данных для конкретной кривой, как в алгоритме временной классификации коннекционистов (CTC). Мы используем декодер конечного автомата, чтобы объединить выходные данные нейронной сети с моделью языка на основе символов, закодированной как взвешенный акцептор конечного состояния. Последовательности символов, которые распространены в языке (например, «sch» в немецком языке), получают бонусы и с большей вероятностью будут выводиться, тогда как необычные последовательности наказываются. Процесс визуализируется ниже.
0150 пустой символ для обозначения отсутствия выходных данных для конкретной кривой, как в алгоритме временной классификации коннекционистов (CTC). Мы используем декодер конечного автомата, чтобы объединить выходные данные нейронной сети с моделью языка на основе символов, закодированной как взвешенный акцептор конечного состояния. Последовательности символов, которые распространены в языке (например, «sch» в немецком языке), получают бонусы и с большей вероятностью будут выводиться, тогда как необычные последовательности наказываются. Процесс визуализируется ниже.
Последовательность точек касания (обозначенных цветом сегментов кривой, как на предыдущем рисунке) преобразуется в гораздо более короткую последовательность коэффициентов Безье (в нашем примере семь), каждая из которых соответствует одной кривой. Распознаватель на основе QRNN преобразует последовательность кривых в последовательность вероятностей символов той же длины, показанную в матрице декодера со строками, соответствующими буквам от «a» до «z» и пустому символу , где яркость входа соответствует его относительной вероятности.
 Проходя матрицу декодера слева направо, мы видим в основном пробелы и светлые точки для символов «g» и «o», в результате чего на выходе текста «go».
Проходя матрицу декодера слева направо, мы видим в основном пробелы и светлые точки для символов «g» и «o», в результате чего на выходе текста «go».Несмотря на то, что наши новые модели распознавания символов значительно проще, они не только делают на 20-40% меньше ошибок, чем старые, но и намного быстрее. Однако все это еще нужно выполнять на устройстве!
Как заставить это работать, на устройстве
Чтобы обеспечить наилучшее взаимодействие с пользователем, недостаточно точных моделей распознавания — они также должны быть быстрыми. Чтобы добиться минимально возможной задержки в Gboard, мы конвертируем наши модели распознавания (обученные в TensorFlow) в модели TensorFlow Lite. Это включает в себя квантование всех наших весов во время обучения модели, так что вместо четырех байтов на вес мы используем только один, что приводит к меньшим моделям, а также к меньшему времени вывода. Кроме того, TensorFlow Lite позволяет нам уменьшить размер APK по сравнению с использованием полной реализации TensorFlow, поскольку он оптимизирован для небольшого двоичного размера, включая только те части, которые необходимы для логического вывода.
Еще не все
Мы продолжим расширять границы, помимо улучшения распознавателей латинского алфавита. Команда рукописного ввода уже усердно работает над запуском новых моделей для всех поддерживаемых нами языков рукописного ввода в Gboard.
Благодарности
Мы хотели бы поблагодарить всех, кто внес свой вклад в улучшение рукописного ввода в Gboard. В частности, Джатин Матани из команды Gboard, Дэвид Райбах из группы алгоритмов речи и языка, Прабху Калиамурти из группы Expander, Пит Уорден из команды TensorFlow Lite, а также Генри Роули, Ли-Лун Ван, Мирча. Трейчиою, Филипп Жерве и Томас Деселерс из группы почерков.
Распознавание почерка
Авторы: A_K_NAIN, Sayak Paul
Дата Создана: 2021/08/16
Последний модифицированный: 2021/08/16
767.
Описание: Обучение модели распознавания рукописного ввода с последовательностями переменной длины.
Введение
В этом примере показано, как распознавать капчу пример можно распространить на набор данных IAM, который имеет наземные мишени переменной длины. Каждый образец в наборе данных представляет собой изображение некоторого рукописный текст, и его соответствующей целью является строка, присутствующая на изображении. Набор данных IAM широко используется во многих тестах OCR, поэтому мы надеемся, что этот пример может послужить хорошая отправная точка для создания систем OCR.
Сбор данных
!wget -q https://git.io/J0fjL -O IAM_Words.zip !unzip -qq IAM_Words.zip ! !mkdir данные !mkdir данные/слова !tar -xf IAM_Words/words.tgz -C данные/слова !mv Данные IAM_Words/words.txt
Предварительный просмотр организации набора данных. Строки, начинающиеся с «#», представляют собой просто информацию метаданных.
!head -20 data/words.txt
#--- Words.txt ----------------------------------------- ----------------------# # # информация о слове базы данных iam # # формат: a01-000u-00-00 ok 154 1 408 768 27 51 AT A # # a01-000u-00-00 -> идентификатор слова для строки 00 в форме a01-000u # ok -> результат сегментации слов # ok: слово было правильно # er: сегментация слова может быть плохой # # 154 -> уровень серого для бинаризации строки, содержащей это слово # 1 -> количество компонентов для этого слова # 408 768 27 51 -> ограничивающая рамка вокруг этого слова в формате x,y,w,h # AT -> грамматический тег для этого слова, см.# файл tagset.txt для объяснения # A -> транскрипция для этого слова # а01-000у-00-00 ок 154 408 768 27 51 В А a01-000u-00-01 ок 154 507 766 213 48 NN ПЕРЕМЕЩЕНИЕ
Импорт
из tensorflow.keras.layers.experimental.preprocessing import StringLookup из тензорного потока импортировать керас импортировать matplotlib.pyplot как plt импортировать тензорный поток как tf импортировать numpy как np импорт ОС np.random.seed (42) tf.random.set_seed(42)
Разделение набора данных
base_path = "данные"
список_слов = []
слова = открыть (f"{base_path}/words.txt", "r").readlines()
для строки словами:
если строка[0] == "#":
Продолжать
if line.split(" ")[1] != "err": # Нам не нужно иметь дело с ошибочными записями.
words_list.append(строка)
лен(список_слов)
np.random.shuffle (слова_список)
Мы разделим набор данных на три подмножества с соотношением 90:5:5 (обучение:проверка:тест).
split_idx = int(0,9 * len(words_list))
train_samples = список_слов[:split_idx]
test_samples = список_слов[split_idx:]
val_split_idx = int (0,5 * длина (test_samples))
validation_samples = test_samples[:val_split_idx]
test_samples = test_samples[val_split_idx:]
утверждать len(words_list) == len(train_samples) + len(validation_samples) + len(
test_samples
)
print(f"Всего обучающих выборок: {len(train_samples)}")
print(f"Всего проверочных образцов: {len(validation_samples)}")
print(f"Всего тестовых образцов: {len(test_samples)}")
Всего обучающих выборок: 86810 Всего проверочных образцов: 4823 Всего тестовых образцов: 4823
Конвейер ввода данных
Мы начинаем построение нашего конвейера ввода данных с подготовки путей к изображениям.
base_image_path = os.path.join(base_path, "слова")
def get_image_paths_and_labels (образцы):
пути = []
исправленные_образцы = []
для (i, file_line) в перечислении (образцы):
line_split = file_line.strip()
line_split = line_split.split(" ")
# Каждое разделение строки будет иметь этот формат для соответствующего изображения:
# часть1/часть1-часть2/часть1-часть2-часть3.png
image_name = line_split[0]
частьI = имя_изображения.split("-")[0]
частьII = имя_изображения.split("-")[1]
img_path = os.path.join(
base_image_path, часть I, часть I + "-" + часть II, имя_изображения + ".png"
)
если os.path.getsize(img_path):
пути.append(img_path)
corrected_samples.append(file_line.split("\n")[0])
пути возврата, corrected_samples
train_img_paths, train_labels = get_image_paths_and_labels(train_samples)
validation_img_paths, validation_labels = get_image_paths_and_labels(validation_samples)
test_img_paths, test_labels = get_image_paths_and_labels(test_samples)
Затем мы готовим этикетки для подтверждения правды.
# Найдите максимальную длину и размер словаря в обучающих данных.
train_labels_cleaned = []
символы = установить ()
макс_длин = 0
для метки в train_labels:
метка = метка.split(" ")[-1].strip()
для char в метке:
символы.добавить(символ)
max_len = max (max_len, len (метка))
train_labels_cleaned.append(метка)
символы = отсортированные (список (символы))
print("Максимальная длина: ", max_len)
print("Размер словаря: ", len(символов))
# Проверьте некоторые образцы этикеток.
train_labels_cleaned[:10]
Максимальная длина: 21 Объем словарного запаса: 78 ['Конечно', 'он', 'в течение', 'из', 'добыча', 'гастрономия', 'мальчик', ', 'а также', 'в']
Теперь очищаем валидационные и тестовые этикетки.
по определению clean_labels(метки):
очищенные_метки = []
для метки в этикетках:
метка = метка.split(" ")[-1].strip()
clean_labels.append(метка)
вернуть очищенные_метки
validation_labels_cleaned = clean_labels(validation_labels)
test_labels_cleaned = clean_labels(test_labels)
Создание словаря символов
Keras предоставляет различные уровни предварительной обработки для обработки различных модальностей данных. Это руководство представляет собой всеобъемлющее введение.
Наш пример включает предварительную обработку меток на символе
уровень. Это означает, что если есть две метки, например. “кошка” и “собака”, то наш персонаж
словарный запас должен быть {a, c, d, g, o, t} (без каких-либо специальных токенов). Мы используем
Это руководство представляет собой всеобъемлющее введение.
Наш пример включает предварительную обработку меток на символе
уровень. Это означает, что если есть две метки, например. “кошка” и “собака”, то наш персонаж
словарный запас должен быть {a, c, d, g, o, t} (без каких-либо специальных токенов). Мы используем StringLookup слой для этой цели.
АВТОНАСТРОЙКА = tf.data.АВТОНАСТРОЙКА
# Преобразование символов в целые числа.
char_to_num = StringLookup (словарь = список (символы), mask_token = нет)
# Преобразование целых чисел обратно в исходные символы.
num_to_char = StringLookup(
словарь=char_to_num.get_vocabulary(), mask_token=Нет, инвертировать=Истина
)
Изменение размера изображений без искажений
Вместо квадратных изображений многие модели OCR работают с прямоугольными изображениями. Это станет
станет понятнее, когда мы визуализируем несколько образцов из набора данных. Пока
изменение размера квадратных изображений без учета аспекта не приводит к значительному увеличению
искажения это не относится к прямоугольным изображениям. Но изменение размера изображений до униформы
размер является требованием для мини-партирования. Поэтому нам нужно выполнить изменение размера таким образом, чтобы
выполнены следующие критерии:
Но изменение размера изображений до униформы
размер является требованием для мини-партирования. Поэтому нам нужно выполнить изменение размера таким образом, чтобы
выполнены следующие критерии:
- Соотношение сторон сохраняется.
- Содержимое изображений не изменяется.
определение искажения_free_resize (изображение, img_size):
ш, ч = img_size
изображение = tf.image.resize (изображение, размер = (h, w), save_aspect_ratio = True)
# Проверьте необходимое количество отступов.
pad_height = h - tf.shape (изображение) [0]
pad_width = w - tf.shape (изображение) [1]
# Необходимо только в том случае, если вы хотите сделать одинаковое количество отступов с обеих сторон.
если pad_height % 2 != 0:
высота = pad_height // 2
pad_height_top = высота + 1
pad_height_bottom = высота
еще:
pad_height_top = pad_height_bottom = pad_height // 2
если pad_width % 2 != 0:
ширина = pad_width // 2
pad_width_left = ширина + 1
pad_width_right = ширина
еще:
pad_width_left = pad_width_right = pad_width // 2
изображение = tf. pad(
изображение,
отступы=[
[pad_height_top, pad_height_bottom],
[pad_width_left, pad_width_right],
[0, 0],
],
)
изображение = tf.transpose (изображение, разрешение = [1, 0, 2])
изображение = tf.image.flip_left_right (изображение)
вернуть изображение
pad(
изображение,
отступы=[
[pad_height_top, pad_height_bottom],
[pad_width_left, pad_width_right],
[0, 0],
],
)
изображение = tf.transpose (изображение, разрешение = [1, 0, 2])
изображение = tf.image.flip_left_right (изображение)
вернуть изображение
Если мы просто изменим размер, то изображения будут выглядеть так:
Обратите внимание, что это изменение размера привело бы к ненужному растяжению.
Сбор утилит
batch_size = 64
padding_token = 99
ширина_изображения = 128
высота_изображения = 32
def preprocess_image (image_path, img_size = (image_width, image_height)):
изображение = tf.io.read_file(image_path)
изображение = tf.image.decode_png (изображение, 1)
изображение = искажение_free_resize (изображение, img_size)
изображение = tf.cast (изображение, tf.float32) / 255,0
вернуть изображение
def vectorize_label (метка):
метка = char_to_num(tf. strings.unicode_split(метка, input_encoding="UTF-8"))
длина = tf.shape (метка) [0]
pad_amount = max_len - длина
label = tf.pad(label, paddings=[[0, padding_amount]], константные_значения=padding_token)
ярлык возврата
def process_images_labels (путь к изображению, метка):
изображение = preprocess_image (image_path)
метка = vectorize_label (метка)
вернуть {"изображение": изображение, "метка": метка}
def prepare_dataset (image_paths, метки):
набор данных = tf.data.Dataset.from_tensor_slice((image_paths, labels)).map(
process_images_labels, num_parallel_calls = АВТОНАСТРОЙКА
)
вернуть dataset.batch(batch_size).cache().prefetch(AUTOTUNE)
strings.unicode_split(метка, input_encoding="UTF-8"))
длина = tf.shape (метка) [0]
pad_amount = max_len - длина
label = tf.pad(label, paddings=[[0, padding_amount]], константные_значения=padding_token)
ярлык возврата
def process_images_labels (путь к изображению, метка):
изображение = preprocess_image (image_path)
метка = vectorize_label (метка)
вернуть {"изображение": изображение, "метка": метка}
def prepare_dataset (image_paths, метки):
набор данных = tf.data.Dataset.from_tensor_slice((image_paths, labels)).map(
process_images_labels, num_parallel_calls = АВТОНАСТРОЙКА
)
вернуть dataset.batch(batch_size).cache().prefetch(AUTOTUNE)
train_ds = prepare_dataset (train_img_paths, train_labels_cleaned) validation_ds = prepare_dataset (validation_img_paths, validation_labels_cleaned) test_ds = prepare_dataset (test_img_paths, test_labels_cleaned)
Визуализируйте несколько выборок
для данных в train_ds.take(1): изображения, метки = данные["изображение"], данные["метка"] _, топор = plt.subplots(4, 4, figsize=(15, 8)) для я в диапазоне (16): изображение = изображения [я] img = tf.image.flip_left_right (img) img = tf.transpose (img, perm = [1, 0, 2]) img = (img * 255.0).numpy().clip(0, 255).astype(np.uint8) изображение = изображение [:, :, 0] # Собираем индексы, где label!= padding_token. метка = метки[i] индексы = tf.gather (метка, tf.where (tf.math.not_equal (метка, padding_token))) # Преобразование в строку. метка = tf.strings.reduce_join (num_to_char (индексы)) метка = метка.numpy().decode("utf-8") ax[i // 4, i % 4].imshow(img, cmap="gray") ax[i // 4, i % 4].set_title(метка) ax[i // 4, i % 4].axis("выкл") plt.show()
Вы заметите, что содержание исходного изображения сохранено максимально точно и был дополнен соответственно.
Модель
Наша модель будет использовать потери CTC в качестве уровня конечной точки. Для детального понимания
Потеря CTC, см. этот пост.
Для детального понимания
Потеря CTC, см. этот пост.
класс CTCLayer(keras.layers.Layer):
def __init__(я, имя=Нет):
супер().__init__(имя=имя)
self.loss_fn = keras.backend.ctc_batch_cost
вызов защиты (я, y_true, y_pred):
batch_len = tf.cast(tf.shape(y_true)[0], dtype="int64")
input_length = tf.cast(tf.shape(y_pred)[1], dtype="int64")
label_length = tf.cast(tf.shape(y_true)[1], dtype="int64")
input_length = input_length * tf.ones (shape = (batch_len, 1), dtype = "int64")
длина_метки = длина_метки * tf.ones(форма=(длина_пакета, 1), dtype="int64")
потеря = self.loss_fn (y_true, y_pred, input_length, label_length)
self.add_loss (потеря)
# Во время тестирования просто вернуть рассчитанные прогнозы.
вернуть y_pred
защита build_model():
# Входные данные для модели
input_img = keras.Input(shape=(image_width, image_height, 1), name="image")
метки = keras.layers.Input(name="label", shape=(None,))
# Первый конв блок. х = keras.layers.Conv2D(
32,
(3, 3),
активация = "релу",
kernel_initializer="he_normal",
отступ = «такой же»,
имя = "Конв1",
)(input_img)
x = keras.layers.MaxPooling2D((2, 2), name="pool1")(x)
# Второй конв блок.
х = keras.layers.Conv2D(
64,
(3, 3),
активация = "релу",
kernel_initializer="he_normal",
отступ = «такой же»,
имя="Конв2",
)(Икс)
x = keras.layers.MaxPooling2D((2, 2), name="pool2")(x)
# Мы использовали два максимальных пула с размером пула и шагом 2.
# Следовательно, карты объектов с пониженной дискретизацией в 4 раза меньше. Количество
# фильтров в последнем слое равно 64. Измените форму перед
# передача вывода в часть модели RNN.
new_shape = ((image_width // 4), (image_height // 4) * 64)
x = keras.layers.Reshape(target_shape=new_shape, name="reshape")(x)
x = keras.layers.Dense(64, активация = "relu", name = "dense1") (x)
х = keras.
х = keras.layers.Conv2D(
32,
(3, 3),
активация = "релу",
kernel_initializer="he_normal",
отступ = «такой же»,
имя = "Конв1",
)(input_img)
x = keras.layers.MaxPooling2D((2, 2), name="pool1")(x)
# Второй конв блок.
х = keras.layers.Conv2D(
64,
(3, 3),
активация = "релу",
kernel_initializer="he_normal",
отступ = «такой же»,
имя="Конв2",
)(Икс)
x = keras.layers.MaxPooling2D((2, 2), name="pool2")(x)
# Мы использовали два максимальных пула с размером пула и шагом 2.
# Следовательно, карты объектов с пониженной дискретизацией в 4 раза меньше. Количество
# фильтров в последнем слое равно 64. Измените форму перед
# передача вывода в часть модели RNN.
new_shape = ((image_width // 4), (image_height // 4) * 64)
x = keras.layers.Reshape(target_shape=new_shape, name="reshape")(x)
x = keras.layers.Dense(64, активация = "relu", name = "dense1") (x)
х = keras. layers.Dropout(0.2)(x)
# РНС.
x = keras.layers.Bidirectional(
keras.layers.LSTM(128, return_sequences=True, отсев=0,25)
)(Икс)
x = keras.layers.Bidirectional(
keras.layers.LSTM(64, return_sequences=True, отсев=0,25)
)(Икс)
# +2 для учета двух специальных токенов, введенных потерей CTC.
# Рекомендация находится здесь: https://git.io/J0eXP.
x = keras.layers.Dense(
len(char_to_num.get_vocabulary()) + 2, активация = "softmax", name = "dense2"
)(Икс)
# Добавить слой CTC для расчета потерь CTC на каждом шаге.
вывод = CTCLayer(name="ctc_loss")(метки, x)
# Определить модель.
модель = keras.models.Model(
inputs=[input_img, labels], outputs=output, name="handwriting_recognizer"
)
# Оптимизатор.
opt = keras.optimizers.Adam()
# Скомпилируйте модель и вернитесь.
model.compile (оптимизатор = опция)
модель возврата
# Получить модель.
модель = build_model()
модель.резюме()
layers.Dropout(0.2)(x)
# РНС.
x = keras.layers.Bidirectional(
keras.layers.LSTM(128, return_sequences=True, отсев=0,25)
)(Икс)
x = keras.layers.Bidirectional(
keras.layers.LSTM(64, return_sequences=True, отсев=0,25)
)(Икс)
# +2 для учета двух специальных токенов, введенных потерей CTC.
# Рекомендация находится здесь: https://git.io/J0eXP.
x = keras.layers.Dense(
len(char_to_num.get_vocabulary()) + 2, активация = "softmax", name = "dense2"
)(Икс)
# Добавить слой CTC для расчета потерь CTC на каждом шаге.
вывод = CTCLayer(name="ctc_loss")(метки, x)
# Определить модель.
модель = keras.models.Model(
inputs=[input_img, labels], outputs=output, name="handwriting_recognizer"
)
# Оптимизатор.
opt = keras.optimizers.Adam()
# Скомпилируйте модель и вернитесь.
model.compile (оптимизатор = опция)
модель возврата
# Получить модель.
модель = build_model()
модель.резюме()
Модель: "почерк_распознаватель"
______________________________________________________________________________________________________________
Слой (тип) Выходная форма Параметр # Подключен к
================================================== ================================================
изображение (InputLayer) [(Нет, 128, 32, 1)] 0
______________________________________________________________________________________________________________
Conv1 (Conv2D) (Нет, 128, 32, 32) 320 изображений[0][0]
______________________________________________________________________________________________________________
pool1 (MaxPooling2D) (Нет, 64, 16, 32) 0 Conv1[0][0]
______________________________________________________________________________________________________________
Conv2 (Conv2D) (Нет, 64, 16, 64) 1 8496 пул1[0][0]
______________________________________________________________________________________________________________
pool2 (MaxPooling2D) (Нет, 32, 8, 64) 0 Conv2[0][0]
______________________________________________________________________________________________________________
reshape (Изменить форму) (Нет, 32, 512) 0 pool2[0][0]
______________________________________________________________________________________________________________
плотности1 (Плотные) (Нет, 32, 64) 32832 изменить форму[0][0]
______________________________________________________________________________________________________________
отсев (отсев) (нет, 32, 64) 0 плотно1[0][0]
______________________________________________________________________________________________________________
двунаправленный (Двунаправленный) (Нет, 32, 256) 197632 отсев[0][0]
______________________________________________________________________________________________________________
bidirectional_1 (Двунаправленный) (Нет, 32, 128) 164352 двунаправленный[0][0]
______________________________________________________________________________________________________________
метка (InputLayer) [(Нет, Нет)] 0
______________________________________________________________________________________________________________
плотности2 (Плотные) (Нет, 32, 81) 10449двунаправленный_1[0][0]
______________________________________________________________________________________________________________
ctc_loss (CTCLayer) (Нет, 32, 81) 0 метка[0][0]
плотный2[0][0]
================================================== ================================================
Всего параметров: 424 081
Обучаемые параметры: 424 081
Необучаемые параметры: 0
______________________________________________________________________________________________________________
Метрика оценки
Редактировать расстояние
является наиболее широко используемой метрикой для оценки моделей OCR. В этом разделе мы будем
реализовать его и использовать в качестве обратного вызова для мониторинга нашей модели.
В этом разделе мы будем
реализовать его и использовать в качестве обратного вызова для мониторинга нашей модели.
Сначала мы разделяем проверочные изображения и их метки для удобства.
validation_images = []
валидация_метки = []
для партии в validation_ds:
validation_images.append (пакет ["изображение"])
validation_labels.append (пакет ["метка"])
Теперь мы создаем обратный вызов для отслеживания расстояний редактирования.
def calculate_edit_distance (метки, предсказания):
# Получить один пакет и преобразовать его метки в разреженные тензоры.
saprse_labels = tf.cast (tf.sparse.from_dense (метки), dtype = tf.int64)
# Делайте прогнозы и конвертируйте их в разреженные тензоры.
input_len = np.ones (предсказания.форма[0]) * предсказания.форма[1]
предсказания_декодированные = keras.backend.ctc_decode(
прогнозы, input_length = input_len, жадный = True
)[0][0][:, :max_len]
sparse_predictions = tf.cast(
tf. sparse.from_dense(predictions_decoded), dtype=tf.int64
)
# Вычислить отдельные расстояния редактирования и усреднить их.
edit_distances = tf.edit_distance(
sparse_predictions, saprse_labels, normalize=False
)
вернуть tf.reduce_mean (edit_distances)
класс EditDistanceCallback (keras.callbacks.Callback):
def __init__(я, пред_модель):
супер().__инит__()
self.prediction_model = пред_модель
def on_epoch_end (я, эпоха, журналы = нет):
edit_distances = []
для i в диапазоне (len (validation_images)):
метки = validation_labels[i]
прогнозы = self.prediction_model.predict (validation_images [i])
edit_distances.append(calculate_edit_distance(метки, прогнозы).numpy())
Распечатать(
f"Среднее расстояние редактирования для эпохи {эпоха + 1}: {np.mean(edit_distances):.4f}"
)
sparse.from_dense(predictions_decoded), dtype=tf.int64
)
# Вычислить отдельные расстояния редактирования и усреднить их.
edit_distances = tf.edit_distance(
sparse_predictions, saprse_labels, normalize=False
)
вернуть tf.reduce_mean (edit_distances)
класс EditDistanceCallback (keras.callbacks.Callback):
def __init__(я, пред_модель):
супер().__инит__()
self.prediction_model = пред_модель
def on_epoch_end (я, эпоха, журналы = нет):
edit_distances = []
для i в диапазоне (len (validation_images)):
метки = validation_labels[i]
прогнозы = self.prediction_model.predict (validation_images [i])
edit_distances.append(calculate_edit_distance(метки, прогнозы).numpy())
Распечатать(
f"Среднее расстояние редактирования для эпохи {эпоха + 1}: {np.mean(edit_distances):.4f}"
)
Обучение
Теперь мы готовы начать обучение моделей.
эпох = 10 # Для получения хороших результатов это должно быть не менее 50.модель = build_model() предсказание_модель = keras.models.Model ( model.get_layer(name="image").input, model.get_layer(name="dense2").output ) edit_distance_callback = EditDistanceCallback(прогноз_модель) # Обучить модель. история = model.fit( поезд_дс, validation_data=validation_ds, эпохи = эпохи, callbacks=[edit_distance_callback], )
Эпоха 1/10 1357/1357 [=============================] - 89 с 51 мс/шаг - потери: 13,6670 - val_loss: 11,8041 Среднее расстояние редактирования для эпохи 1: 20,5117 Эпоха 2/10 1357/1357 [=============================] - 48 с 36 мс/шаг - потери: 10,6864 - val_loss: 9,6994 Среднее расстояние редактирования для эпохи 2: 20,1167 Эпоха 3/10 1357/1357 [=============================] - 48 с 35 мс/шаг - потери: 9,0437 - val_loss: 8,0355 Среднее расстояние редактирования для эпохи 3: 19,7270 Эпоха 4/10 1357/1357 [=============================] - 48 с 35 мс/шаг - потери: 7,6098 - val_loss: 6,4239 Среднее расстояние редактирования для эпохи 4: 19,1106 Эпоха 5/10 1357/1357 [=============================] - 48 с 35 мс/шаг - потери: 6,3194 - val_loss: 4,9814 Среднее расстояние редактирования для эпохи 5: 18,4894 Эпоха 6/10 1357/1357 [=============================] - 48 с 35 мс/шаг - потери: 5,3417 - val_loss: 4,1307 Среднее расстояние редактирования для эпохи 6: 18.1909 Эпоха 7/10 1357/1357 [=============================] - 48 с 35 мс/шаг - потери: 4,6396 - val_loss: 3,7706 Среднее расстояние редактирования для эпохи 7: 18,1224 Эпоха 8/10 1357/1357 [=============================] - 48 с 35 мс/шаг - потери: 4,1926 - val_loss: 3,3682 Среднее расстояние редактирования для эпохи 8: 17,9387 Эпоха 9/10 1357/1357 [=============================] - 48 с 36 мс/шаг - потери: 3,8532 - val_loss: 3,1829 Среднее расстояние редактирования для эпохи 9: 17,9074 Эпоха 10/10 1357/1357 [=============================] - 49 с 36 мс/шаг - потери: 3,5769 - val_loss: 2,9221 Среднее расстояние редактирования для эпохи 10: 17,7960
Вывод
# Вспомогательная функция для декодирования вывода сети. def decode_batch_predictions (пред): input_len = np.ones (пред.форма[0]) * пред.форма[1] # Используйте жадный поиск. Для сложных задач можно использовать лучевой поиск. results = keras.backend.ctc_decode(pred, input_length=input_len, greedy=True)[0][0][ :, :max_len ] # Перебираем результаты и возвращаем текст.вывод_текст = [] для res в результатах: res = tf.gather(res, tf.where(tf.math.not_equal(res, -1))) res = tf.strings.reduce_join(num_to_char(res)).numpy().decode("utf-8") output_text.append(разрешение) вернуть вывод_текст # Давайте проверим результаты на некоторых тестовых образцах. для партии в test_ds.take(1): batch_images = пакет["изображение"] _, топор = plt.subplots(4, 4, figsize=(15, 8)) предс = предсказание_модель.предсказание(пакетные_изображения) pred_texts = decode_batch_predictions (предварительные) для я в диапазоне (16): img = пакетные_изображения[i] img = tf.image.flip_left_right (img) img = tf.transpose (img, perm = [1, 0, 2]) img = (img * 255.0).numpy().clip(0, 255).astype(np.uint8) изображение = изображение [:, :, 0] title = f"Предсказание: {pred_texts[i]}" ax[i // 4, i % 4].imshow(img, cmap="gray") топор[я // 4, я % 4].set_title(название) ax[i // 4, i % 4].
