
Распознавание текста (OCR). Онлайн и бесплатно. 5 бесплатных программ для сканирования и распознавания текста
Статьи
Содержание
- 1 Преобразование отсканированных документов и изображений в редактируемые форматы Word, Pdf, Excel и Txt (простой текст)
- 2 Веб-сервис Free Online OCR
- 3 OCR CuneiForm
- 4 Веб-сервис Free-OCR.com
- 5 Readiris
- 6 Microsoft OneNote
- 7 SimpleOCR
Преобразование отсканированных документов и изображений в редактируемые форматы Word, Pdf, Excel и Txt (простой текст)
Веб-сервис Free Online OCR
Free Online OCR — еще один бесплатный веб-сервис, очень похожий на предыдущий, но с расширенными функциями. Он:
- Он поддерживает 106 языков.
- Обрабатывайте многостраничные документы, в том числе на нескольких языках.
- Он распознает текст на отсканированных изображениях и фотодокументах многих типов. Помимо 10 форматов графических изображений, он управляет документами pdf, djvu, doxc, odt, zip-архивами и сжатыми файлами Unix.

- Сохраните выходные файлы в одном из 3-х форматов: txt, doc и pdf.
- Он поддерживает распознавание математических уравнений.
- Правильно распознает текст в нескольких столбцах на странице.
- Может распознать выбранный фрагмент.
- После обработки предлагает скопировать файл в буфер обмена, загрузить на компьютер, загрузить в сервис Google Docs или опубликовать в Интернете. Вы также можете мгновенно перевести текст на другой язык с помощью Google Translate или Bing Translator.

Мы должны отдать должное бесплатному онлайн-распознаванию текста за то, что оно хорошо читает изображения с низким разрешением и низкой контрастностью. Результат распознавания всех предоставленных ему русскоязычных текстов отказался быть стопроцентным или близким к нему.
Бесплатное онлайн-распознавание текста, на наш взгляд, является одной из лучших альтернатив FineReader, но оно обрабатывает бесплатно только 20 страниц (правда, на какой период не указано).
OCR CuneiForm
Бесплатная программа для чтения текстовой информации с изображений. Точность распознавания на порядок ниже, чем у предыдущей исследуемой программы. Но что касается бесплатной утилиты, то функциональность все равно отличная.
Интересный! CuneiForm распознает блоки текста, графики и даже различные таблицы. Также можно читать таблицы без строк.
Программа умеет читать и сохранять шрифт и размер распознанного текста. База шрифтов содержит большинство используемых гарнитур. Также поддерживается распознавание текста с пишущей машинки.
Для обеспечения точности к процессу распознавания прилагаются специальные словари, которые заполняют словарный запас отсканированных документов.
Преимущества:
- бесплатное распространение;
- использовать словари для проверки правильности текста;
- отсканированные тексты с фотокопий плохого качества.
Растрескивание:
- относительно невысокая точность;
- поддерживается небольшое количество языков.

Веб-сервис Free-OCR.com
Free-OCR.com (OCR — Optical Character Recognition, Optical Character Recognition) — это бесплатный интернет-сервис для распознавания отсканированного или сфотографированного текста, сохраненного в формате графического изображения (jpg, gif, tiff, bmp) или pdf. Он поддерживает 29 языков, в том числе русский и украинский, причем пользователь может выбрать не один, а несколько, если исходный текст их содержит.
Free-OCR не требует регистрации и не имеет ограничений по количеству загружаемых документов. Ограничен только размер файла — до 6 Мб. Сервис не обрабатывает многостраничные документы, точнее игнорирует все, кроме первого листа.
Скорость распознавания отсканированного текста довольно высока. Лист формата А4 с фрагментом книги на русском языке обрабатывался примерно за 5 секунд, но качество было невысоким. Крупные шрифты — как в детских книжках их распознает на 100%, а средние и мелкие — примерно на 80%. Немного лучше обстоит дело с англоязычными документами: мелкий, малоконтрастный шрифт распознается правильно примерно на 95%.
Readiris
Программа Readiris от бельгийского разработчика IRIS действительно является настоящим конкурентом российской ABBYY FineReader. Мощный, быстрый, кроссплатформенный, основанный на запатентованном движке OCR, который используют производители Adobe, HP и Canon, он отлично распознает даже самые трудные для чтения тексты. Он поддерживает 137 языков, в том числе русский и украинский.
Возможности и функции Readiris:
- Самая высокая скорость обработки файлов среди приложений этого класса, рассчитана на большие объемы.
- Сохранение исходного форматирования текста (шрифты, размер, стиль письма).
- Обработка одиночных и пакетных файлов, поддержка многостраничных документов.
- Распознавание математических уравнений, специальных символов и штрих-кодов.
- Очистите текст от «шума» — линий, подтеков и т.д.
- Интеграция с различными облачными сервисами: Google Docs, Evernote, Dropbox, SharePoint и некоторыми другими.
- Поддержка всех современных моделей сканеров.
- Форматы входных данных: pdf, djvu, jpg, png и другие, в которых графические изображения сохраняются, а также принимаются непосредственно со сканера.
- Форматы выходных данных: doc, docx, xls, xlsx, txt, rtf, html, csv, pdf. Поддерживается преобразование в djvu.

Интерфейс программы русский, использование интуитивно понятно. Он не дает пользователям возможности редактировать содержимое pdf файлов, как FineReader, но с основной задачей: распознавание текста, на наш взгляд, отлично ладит.
Readiris доступен в двух платных версиях. Стоимость лицензии Pro составляет 99 евро, корпоративной — 199 евро. Почти как ABBYY.
Microsoft OneNote
Программа для создания заметок Microsoft OneNote, за исключением очень старой и более новой версии 17, также содержит функцию распознавания текста. Он не такой продвинутый, как в специализированных приложениях, но его можно использовать, даже если нет других вариантов.
Чтобы распознать текст на изображении с помощью OneNote, вставьте изображение в файл («Изображение» — «Вставить»), щелкните его правой кнопкой мыши и выберите «Копировать текст из изображения».
Затем вставьте скопированный текст в любое место заметки.
По умолчанию установлен английский язык распознавания. Если вам нужен русский или любой другой, пожалуйста, измените настройку вручную.
Качество распознавания русского текста в Microsoft OneNote оставляет желать лучшего, поэтому его нельзя назвать полноценной заменой FineReader. И обрабатывать в нем большие многостраничные документы очень неудобно.
SimpleOCR
Замечательная маленькая программа для распознавания текста по изображениям. Он также поддерживает чтение рукописей. Проблема в том, что русского нет ни в языковой пакет интерфейса, ни в список поддерживаемых языков для распознавания.
Однако, если вам нужно сканировать на английском, датском или французском языках, лучшего бесплатного варианта нет.
В своей области программа обеспечивает точное декодирование символов, удаление шума и извлечение графики. Кроме того, в интерфейс программы интегрирован текстовый редактор, практически идентичный WordPad, что значительно увеличивает удобство использования программы.
Преимущества:
- точное распознавание текста;
- удобный текстовый редактор;
- убрать шум с изображения.
Растрескивание:
- полное отсутствие русского языка.
Источники
- https://convertio.co/ru/ocr/
- https://CompConfig.ru/software/programmy-i-servisy-dlya-skanirovaniya.html
- https://pomogaemkompu.temaretik.com/930401132721474208/5-besplatnyh-programm-dlya-skanirovaniya-i-raspoznavaniya-teksta/
[свернуть]
Поделиться
Предыдущая Компьютер не видит сетевой принтер в Windows 7, 10: что делать, как устранить
Следующая Стандартные форматы и размеры листов бумаги: А3, А4, А0, А5, А6, А1, А2
OCR – Оптическое распознавание символов обзор, сравнение, лучшие продукты, внедрения, поставщики.
Оптическое распознавание символов (англ. optical character recognition, OCR) — механический или электронный перевод изображений рукописного, машинописного или печатного текста в текстовые данные, использующиеся для представления символов в компьютере (например, в текстовом редакторе). Распознавание широко применяется для преобразования книг и документов в электронный вид, для автоматизации систем учёта в бизнесе или для публикации текста на веб-странице. Оптическое распознавание символов позволяет редактировать текст, осуществлять поиск слов или фраз, хранить его в более компактной форме, демонстрировать или распечатывать материал, не теряя качества, анализировать информацию, а также применять к тексту электронный перевод, форматирование или преобразование в речь. Оптическое распознавание текста является исследуемой проблемой в областях распознавания образов, искусственного интеллекта и компьютерного зрения.
Распознавание широко применяется для преобразования книг и документов в электронный вид, для автоматизации систем учёта в бизнесе или для публикации текста на веб-странице. Оптическое распознавание символов позволяет редактировать текст, осуществлять поиск слов или фраз, хранить его в более компактной форме, демонстрировать или распечатывать материал, не теряя качества, анализировать информацию, а также применять к тексту электронный перевод, форматирование или преобразование в речь. Оптическое распознавание текста является исследуемой проблемой в областях распознавания образов, искусственного интеллекта и компьютерного зрения.
Системы оптического распознавания текста требуют калибровки для работы с конкретным шрифтом; в ранних версиях для программирования было необходимо изображение каждого символа, программа одновременно могла работать только с одним шрифтом. В настоящее время больше всего распространены так называемые «интеллектуальные» системы, с высокой степенью точности распознающие большинство шрифтов. Некоторые системы оптического распознавания текста способны восстанавливать исходное форматирование текста, включая изображения, колонки и другие нетекстовые компоненты.
Некоторые системы оптического распознавания текста способны восстанавливать исходное форматирование текста, включая изображения, колонки и другие нетекстовые компоненты.
Точное распознавание латинских символов в печатном тексте в настоящее время возможно, только если доступны чёткие изображения, такие, как сканированные печатные документы. Точность при такой постановке задачи превышает 99 %, абсолютная точность может быть достигнута только путём последующего редактирования человеком. Проблемы распознавания рукописного «печатного» и стандартного рукописного текста, а также печатных текстов других форматов (особенно с очень большим числом символов) в настоящее время являются предметом активных исследований.
Точность работы методов может быть измерена несколькими способами и поэтому может сильно варьироваться. К примеру, если встречается специализированное слово, не используемое для соответствующего программного обеспечения, при поиске несуществующих слов, ошибка может увеличиться.
Распознавание символов онлайн иногда путают с оптическим распознаванием символов. Последний — это офлайн-метод, работающий со статической формой представления текста, в то время как онлайн-распознавание символов учитывает движения во время письма. Например, в онлайн-распознавании, использующем PenPoint OS или планшетный ПК, можно определить, с какой стороны пишется строка: справа налево или слева направо.
Онлайн-системы для распознавания рукописного текста «на лету» в последнее время стали широко известны в качестве коммерческих продуктов. Алгоритмы таких устройств используют тот факт, что порядок, скорость и направление отдельных участков линий ввода известны. Кроме того, пользователь научится использовать только конкретные формы письма. Эти методы не могут быть использованы в программном обеспечении, которое использует сканированные бумажные документы, поэтому проблема распознавания рукописного «печатного» текста по-прежнему остаётся открытой. На изображениях с рукописным «печатным» текстом без артефактов может быть достигнута точность в 80 % — 90 %, но с такой точностью изображение будет преобразовано с десятками ошибок на странице. Такая технология может быть полезна лишь в очень ограниченном числе приложений.
Такая технология может быть полезна лишь в очень ограниченном числе приложений.
Ещё одной широко исследуемой задачей является распознавание рукописного текста. В данное время достигнутая точность даже ниже, чем для рукописного «печатного» текста. Более высокие показатели могут быть достигнуты только с использованием контекстной и грамматической информации. Например, в ходе распознания искать целые слова в словаре легче, чем пытаться выявить отдельные знаки из текста. Знание грамматики языка может также помочь определить, является ли слово глаголом или существительным. Формы отдельных рукописных символов иногда могут не содержать достаточно информации, чтобы точно (более 98 %) распознать весь рукописный текст.
Для решения более сложных задач в области распознавания используются, как правило, интеллектуальные системы распознавания, такие, как искусственные нейронные сети.
Для калибровки систем распознавания текста создана стандартная база данных MNIST, состоящая из изображений рукописных цифр.
8 Лучшие онлайн-сайты OCR для извлечения текста из изображений — h3S Media
OCR или оптическое распознавание символов — одна из самых важных задач, которые регулярно выполняются в офисах и других местах для извлечения текстов из отсканированного документа, изображения или чего-либо еще. такого рода. После извлечения текста его можно манипулировать, копировать и выполнять другие соответствующие действия с текстами, что может значительно упростить вашу жизнь. В 2018 году смартфоны довольно эффективно извлекают тексты, и Google Lens вполне справляется с этим. С другой стороны, есть куча автономных программ, которые могут делать то же самое в Windows. Вам просто нужно найти фотографию или PDF-документ, а программа OCR сделает все остальное.
Adobe Acrobat Reader DC — одна из лучших программ для извлечения текстов из PDF-файлов, и она предлагает довольно приличную производительность. Но, если вы один из тех, кому не нужно регулярно извлекать тексты из фотографий, лучше использовать веб-решения или онлайн-сайты OCR.
Итак, давайте выясним лучшие и 8 лучших бесплатных веб-сайтов OCR для распознавания текста на изображении?
Первым в списке является newocr.com, одно из самых простых и легких программ для оптического распознавания символов, которое вы можете использовать. На newocr.com вы можете загружать фотографии во множестве форматов, таких как JPEG, GIF, PNG, TIFF, BMP и многих других. После того, как вы закончите загрузку, вам нужно будет выбрать язык текста, присутствующего на изображении. По умолчанию язык будет английский. Но вы можете добавить несколько других языков, а также некоторые из самых популярных индийских языков, такие как хинди, бенгали, маратхи, тамильский, малаялам и т. д. Таким образом, если вы ищете онлайн-конвертер изображений в текст, поддерживающий индийские языки, newocr .com — это тот, на который вы должны пойти.
Free-online-ocr.com — еще один отличный бесплатный инструмент без рекламы для извлечения текстов из фотографий и PDF-файлов. Просто загрузите файл и выберите выходной формат, чтобы начать извлечение текстов из входного файла и получить результат в нужном формате. После того, как вы закончите загрузку входного файла, вы можете получить выходной текст в виде документа Word, документа PDF, форматированного текста или даже в простом текстовом формате. Просто выберите тот, который вам по душе. Как и на предыдущем веб-сайте, бесплатное онлайн-распознавание текста также поддерживает несколько форматов изображений, помимо поддержки документов PDF. Free Online OCR не хранит ваши фотографии и даже не сохраняет извлеченные тексты на своем сервере, что делает программное обеспечение полностью безопасным в использовании, и в то же время ценится ваша конфиденциальность.
OCR.space — один из лучших онлайн-сайтов OCR, который предлагает вам больше, чем просто извлечение текста. Да, это, очевидно, поддерживается, но есть множество дополнительных функций, которые делают его одним из лучших в своем классе. Помимо генерации вывода в текстовом формате, пространство OCR также имеет функцию отображения извлеченного текста в виде наложения на изображение, что может быть полезно для выявления любых ошибок при извлечении. Эта функция действительно удобна. Есть также варианты для создания PDF-файла с извлеченным текстом, чтобы вы могли искать в нем что-то. Пространство OCR также может генерировать выходные данные в формате JSON, что может быть полезно для дальнейшего анализа или для различных задач. В настоящее время пространство OCR поддерживает несколько языков, хотя поддержки каких-либо индийских языков пока нет. OCR space — это еще один онлайн-сайт OCR, на котором нет рекламы. Из-за расширенных функций, предлагаемых пространством OCR, он немного медленнее по сравнению с другими веб-сайтами, но это не мешает.
Из-за расширенных функций, предлагаемых пространством OCR, он немного медленнее по сравнению с другими веб-сайтами, но это не мешает.
Если вы ищете онлайн-инструмент распознавания текста с минимумом рекламы, вам подойдет i2ocr.com. I2ocr.com поддерживает несколько языков, и вы можете выбрать файл изображения либо со своего компьютера, либо ввести URL-адрес, если изображение присутствует на том же URL-адресе. Когда вы закончите, вы можете получить извлеченный текст, который можно отредактировать, открыв его в Документах Google. Таким образом, вам не придется копировать его отдельно и вставлять, чтобы начать с ним работать и что-то редактировать в том же. На всякий случай, если вы не хотите его редактировать, вы можете загрузить вывод или извлеченный текст в различных форматах, таких как текст, документ, PDF или HTML, в зависимости от того, какой из них наиболее эффективен для вас. Поддержка нескольких языков является большим преимуществом для i2ocr.com, но я бы хотел, чтобы поддержка различных индийских языков была добавлена в ближайшее время.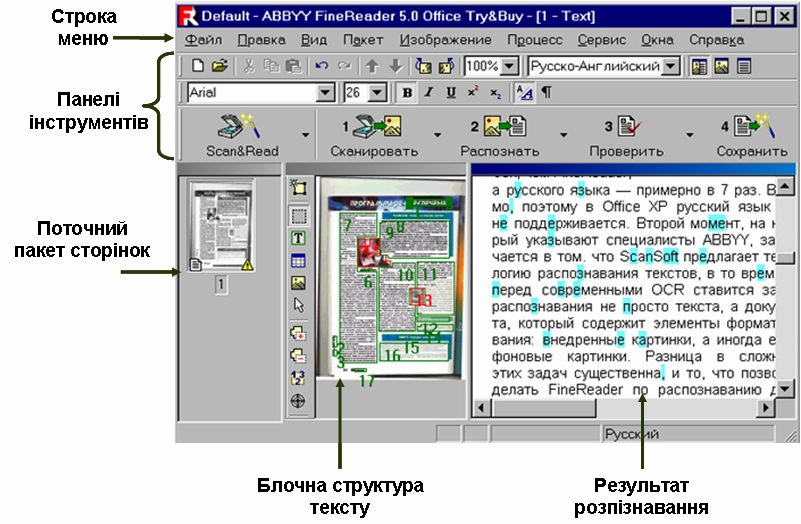
Если у вас есть PDF-файлы, в которых тексты не редактируются или вы просто не можете их скопировать, SodaPDF облегчит вам работу. В отличие от других онлайн-решений OCR, SodaPDF OCR только сканирует и извлекает тексты из PDF-файлов, что может показаться недостатком, но это не так. Вы можете либо загрузить файл со своего компьютера, либо даже добавить PDF-файлы для извлечения из Dropbox или Google Drive. Когда вы закончите, вы можете либо загрузить извлеченный текст, либо просмотреть его в своем веб-браузере. SodaPDF online также имеет веб-приложение Chrome, которое может помочь вам извлекать тексты из файлов PDF, не посещая веб-сайт вообще. Хотя статья не посвящена автономным программам или программному обеспечению OCR, SodaPDF также имеет настольное приложение, которое может быть удобно, если у вас нет доступа к Интернету каждый раз, когда вы хотите извлечь тексты из PDF-файлов.
Convertio OCR — еще один качественный инструмент OCR, доступный онлайн. Convertio OCR поддерживает загрузку файлов изображений и PDF с компьютера, Dropbox, Google Диска или любого другого URL-адреса. После того, как файл загружен, извлеченный на выходе текст можно загрузить в нескольких различных форматах, больше, чем могут предложить другие веб-сайты. Помимо поддержки обычных текстовых форматов и формата документа Word, Convertio OCR также предлагает загружать выходные извлеченные тексты в формате PDF, расширенном текстовом формате, CSV и многих других, что в конечном итоге открывает многочисленные возможности для работы с извлеченными текстами. Convertio OCR имеет возможность распознавать максимум 4 языка в одном входном файле. Будучи гостем, вы можете извлекать тексты только на 10 страницах, но вы сможете извлекать больше текстов из файлов, зарегистрировавшись на сайте. Хотя Convertio OCR не полностью свободен от рекламы, они не настолько разочаровывают, что ваш опыт будет испорчен только из-за них.
Convertio OCR поддерживает загрузку файлов изображений и PDF с компьютера, Dropbox, Google Диска или любого другого URL-адреса. После того, как файл загружен, извлеченный на выходе текст можно загрузить в нескольких различных форматах, больше, чем могут предложить другие веб-сайты. Помимо поддержки обычных текстовых форматов и формата документа Word, Convertio OCR также предлагает загружать выходные извлеченные тексты в формате PDF, расширенном текстовом формате, CSV и многих других, что в конечном итоге открывает многочисленные возможности для работы с извлеченными текстами. Convertio OCR имеет возможность распознавать максимум 4 языка в одном входном файле. Будучи гостем, вы можете извлекать тексты только на 10 страницах, но вы сможете извлекать больше текстов из файлов, зарегистрировавшись на сайте. Хотя Convertio OCR не полностью свободен от рекламы, они не настолько разочаровывают, что ваш опыт будет испорчен только из-за них.
Если вы много работаете с PDF-файлами и хотите извлечь из них текст, Docs.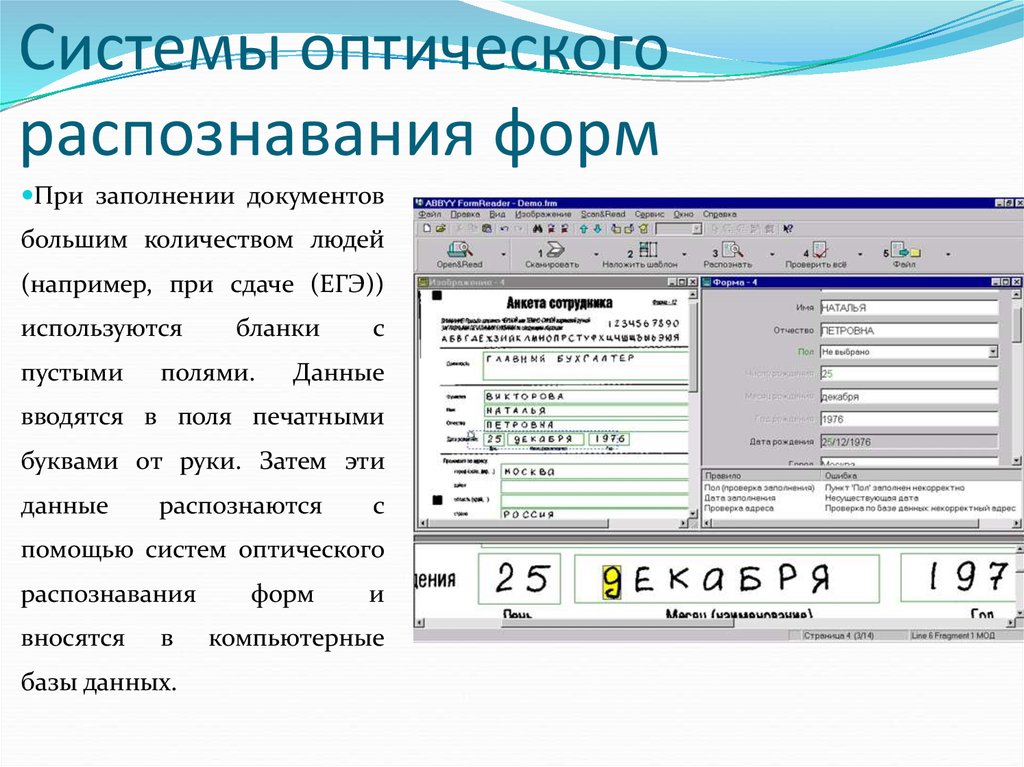 zone — еще один веб-сайт, который вы можете попробовать. Просто выберите файл, в котором присутствуют ваши тексты, выберите язык текста, и выходной файл будет готов в формате документа для загрузки. Помимо поддержки файлов PDF, Docs.zone также поддерживает различные форматы изображений. Docs.zone имеет очень простой и удобный интерфейс и не содержит рекламы. Если вы спешите, Docs.zone — это обязательная онлайн-платформа OCR, которую вы должны использовать, поскольку она способна обрабатывать или извлекать тексты со скоростью от 20 до 30 страниц в секунду. Единственное, что мне не нравится на этом сайте, это невозможность выбрать формат вывода для извлеченного текста. Docs.zone поддерживает загрузку извлеченного текста только в формате .docx. Хотелось бы поддержки форматов .doc или .txt
zone — еще один веб-сайт, который вы можете попробовать. Просто выберите файл, в котором присутствуют ваши тексты, выберите язык текста, и выходной файл будет готов в формате документа для загрузки. Помимо поддержки файлов PDF, Docs.zone также поддерживает различные форматы изображений. Docs.zone имеет очень простой и удобный интерфейс и не содержит рекламы. Если вы спешите, Docs.zone — это обязательная онлайн-платформа OCR, которую вы должны использовать, поскольку она способна обрабатывать или извлекать тексты со скоростью от 20 до 30 страниц в секунду. Единственное, что мне не нравится на этом сайте, это невозможность выбрать формат вывода для извлеченного текста. Docs.zone поддерживает загрузку извлеченного текста только в формате .docx. Хотелось бы поддержки форматов .doc или .txt
Convertimagetotext.net — это простой веб-сайт OCR, где вы можете получить поддержку нескольких индийских языков, таких как бенгальский, хинди, телугу, помимо поддержки ряда других иностранных языков. Convertimagetotext.net свободен от любой рекламы, что делает сайт действительно выдающимся и лучше, чем другие сайты того же класса. Convertimagetotext.net поддерживает ряд различных форматов изображений, помимо поддержки файлов PDF, как и другие веб-сайты этого класса. Convertimagetotext.net гарантирует, что все файлы будут удалены после завершения вашего сеанса, а это означает, что ваша конфиденциальность ценится, и вы можете работать со своими личными файлами на веб-сайте без каких-либо проблем или опасений утечки данных. Convertimagetotext.net довольно прост, и кажется, что он работает быстрее, чем другие доступные онлайн-сайты OCR.
Convertimagetotext.net свободен от любой рекламы, что делает сайт действительно выдающимся и лучше, чем другие сайты того же класса. Convertimagetotext.net поддерживает ряд различных форматов изображений, помимо поддержки файлов PDF, как и другие веб-сайты этого класса. Convertimagetotext.net гарантирует, что все файлы будут удалены после завершения вашего сеанса, а это означает, что ваша конфиденциальность ценится, и вы можете работать со своими личными файлами на веб-сайте без каких-либо проблем или опасений утечки данных. Convertimagetotext.net довольно прост, и кажется, что он работает быстрее, чем другие доступные онлайн-сайты OCR.
Таков был список. Я рекомендую вам попробовать все вышеперечисленные сайты для извлечения текстов и выбрать наиболее подходящий для вас. Просто добавьте в закладки то, что вам больше всего нравится, чтобы вам не пришлось полагаться на Google в следующий раз, когда вы захотите извлечь текст из документов с помощью OCR.
Пропустил ли я какой-нибудь замечательный веб-сайт OCR из списка 8 лучших бесплатных веб-сайтов OCR? Какой из них был вашим любимым? Не стесняйтесь комментировать это ниже.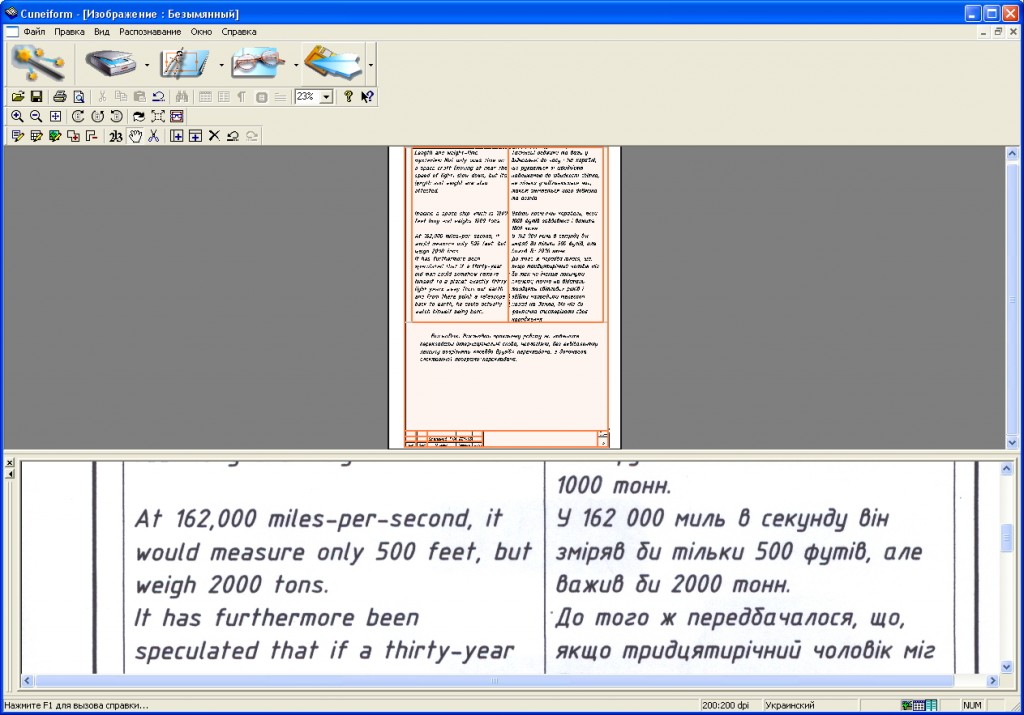
Вам также может быть интересно:
- Как распознавать PDF-документы
- 6 лучших редакторов PDF с открытым исходным кодом для Windows, Linux или Mac
- Как извлечь текст из изображения с помощью бесплатной программы Easy Screen OCR
- Топ-8 лучших программ для чтения PDF для ПК с Windows
- Как запретить Gboard подвергать цензуре текст с помощью функции блокировки оскорбительных слов
4 бесплатных онлайн-инструмента OCR, подвергнутых окончательному тестированию
Если вы хотите преобразовать любой печатный текст в цифровой текст, который можно копировать, вставлять, редактировать и выполнять поиск, вам необходимо использовать сканеры оптического распознавания символов (OCR).
Когда вы решите отсканировать или сфотографировать документ, он будет сохранен в таком формате, как JPEG или PDF. Затем программное обеспечение OCR может распознавать буквы и цифры в этих документах и преобразовывать их в PDF-файл с возможностью поиска или в файл, который вы можете редактировать в таких программах, как Microsoft Word.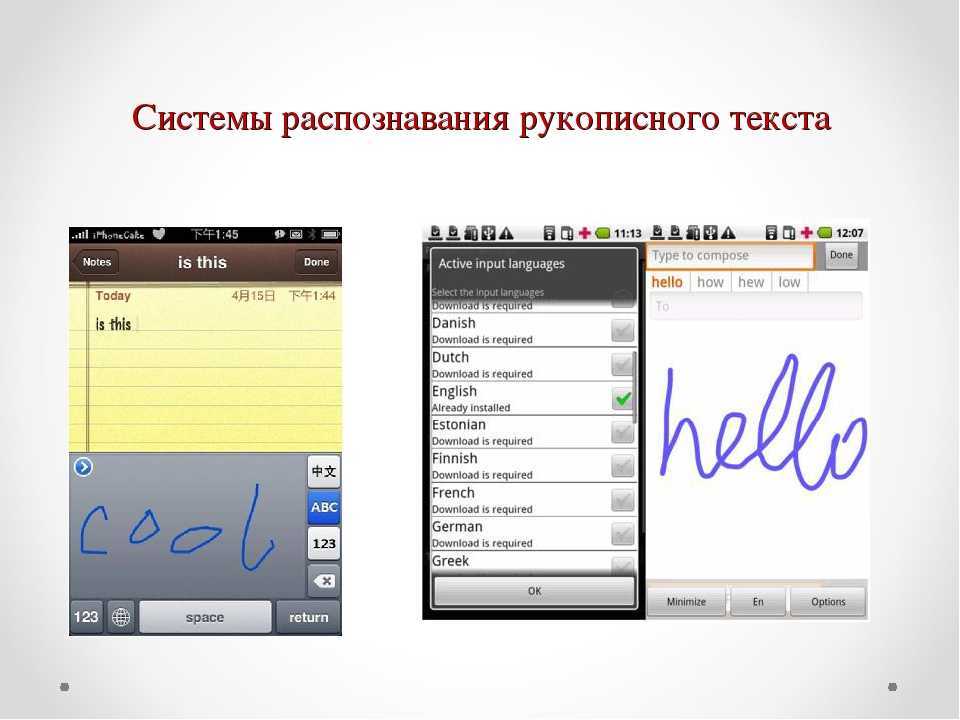
Проблема в том, что некоторые OCR-сканеры работают намного лучше, чем другие, причем самые лучшие из них довольно тяжелы для кошелька.
Например,Omnipage18 стоит 150 долларов, но особенно хорошо распознает разные языки. Adobe Acrobat Pro DC стоит невероятных 400 долларов, но обладает невероятной точностью. ABBYY FineReader стоит 150 долларов, но прекрасно справляется с преобразованием таких документов, как журналы и брошюры, в текст с возможностью поиска. Позже в этой статье мы будем тестировать онлайн-предложение ABBYY.
Однако, если вам нужны бесплатные альтернативы, которые вы можете загрузить и использовать в Windows или OS X, вам следует попробовать эти OCR-инструменты. Но если вы предпочитаете использовать бесплатный онлайн-инструмент OCR , продолжайте читать, так как мы опробовали несколько лучших, и результаты приведены ниже.
Тест
Похоже, что большинство людей теперь используют свои смартфоны для сканирования за них, я решил использовать приложение Evernote Scannable (бесплатно для iOS и Android). Я просмотрел первую страницу книги Ричарда Докина «9».0073 Восхождение на гору Невероятность , чтобы увидеть, какие результаты мы могли бы получить с помощью самого простого форматирования. Я также отсканировал страницу Тима Ферриса «4-часовой повар », чтобы опробовать сканеры с немного более сложным форматированием. Я сохранил каждый из этих файлов в формате PDF.
Я просмотрел первую страницу книги Ричарда Докина «9».0073 Восхождение на гору Невероятность , чтобы увидеть, какие результаты мы могли бы получить с помощью самого простого форматирования. Я также отсканировал страницу Тима Ферриса «4-часовой повар », чтобы опробовать сканеры с немного более сложным форматированием. Я сохранил каждый из этих файлов в формате PDF.
Затем эти документы были пропущены через некоторые из якобы лучших онлайн-инструментов OCR, чтобы увидеть, насколько хорошо они справились.
Бесплатное онлайн-распознавание текста [Больше не доступно]
К счастью, для использования бесплатного онлайн-оптического распознавания символов регистрация не требуется. И я был вдвойне впечатлен, когда увидел их заявление о сохранении форматирования и макета моего документа.
Сайт утверждает, что поддерживает форматы PDF, GIF, BMP, JPEG, TIFF и PNG в качестве входных данных. Выходные данные могут быть в формате DOC, текстовый документ PDF, RTF и TXT. К сожалению, я не смог узнать, есть ли у них ограничение на размер файла.
К сожалению, я не смог узнать, есть ли у них ограничение на размер файла.
Основной документ в PDF
Конвертируется абсолютно идеально. Больше нечего сказать! Мы готовы к очень хорошему началу.
Основной документ к DOC
Настоящие слова, кажется, были преобразованы безукоризненно, за исключением слова «граф» из «Горы Рашмор», которое каким-то образом ушло в самоволку. Однако форматирование — это отдельная история. Многие запятые были заменены символами подчеркивания, а по всему документу в точках были вставлены случайные пробелы. Однако, когда вы позже увидите, как премиальное программное обеспечение показало себя в этом тесте, это неплохая попытка вообще .
Сложный документ в PDF
Преобразование документа заняло целых 120 секунд! После завершения весь текст был преобразован с точностью около 95%, хотя текст в отдельном поле в правом верхнем углу страницы был недоступен для поиска. Несколько других символов в PDF-файле также были неверными.
Несколько других символов в PDF-файле также были неверными.
Комплексный документ к DOC
На этот раз преобразование заняло всего 10 секунд, а текст снова был преобразован примерно за 9 секунд.точность 5%. Были некоторые странные проблемы с пробелами, и у программного обеспечения были проблемы с преобразованием шрифта в правом верхнем углу документа, и здесь и там пропущено несколько символов.
Вердикт
Если вы хотите преобразовать документы простого формата в PDF, это фантастический инструмент. С точки зрения преобразования в DOC результаты не были чем-то особенным.
i2OCR делает впечатляющие заявления. Инструмент распознает более 60 языков, может работать с многоколоночными макетами (путем удаления форматирования), не имеет ограничений по размеру файла, может преобразовывать загруженные файлы и из URL-адресов. И вам не нужно регистрироваться, чтобы использовать этот инструмент.
Служба работает, просто извлекая текст из изображения, а затем выводя неформатированный текст. Вы можете быстро исправить любые ошибки в параллельном представлении, прежде чем копировать текст в другие программы или загружать в формате DOC, PDF или HTML.
Вы можете быстро исправить любые ошибки в параллельном представлении, прежде чем копировать текст в другие программы или загружать в формате DOC, PDF или HTML.
Примечание: когда я пытался загрузить свои PDF-документы, они были отклонены i2OCR, поэтому мне нужно было преобразовать их в JPEG (сделав их снимок экрана, а затем загрузив файлы).
Основной документ в обычный текст
Из-за того, как работает этот инструмент, все форматирование теряется, хотя преобразование из изображения в текст было почти идеальным. Были некоторые небольшие ошибки, такие как расстояние между абзацами, а некоторые запятые были заменены точками, но это небольшие придирки.
Сложный документ в обычный текст
Большая часть текста была преобразована без особых ошибок, за исключением заголовка и рецепта в правом верхнем углу, которые не читались этим инструментом. Способ преобразования столбцов в обычный текст был далек от идеала. Если вы хотите, чтобы это преобразование работало, потребуется много времени, чтобы преобразовать строки в связные предложения.
Если вы хотите, чтобы это преобразование работало, потребуется много времени, чтобы преобразовать строки в связные предложения.
Вердикт
Для основных документов отлично работает i2OCR. Возможность редактировать текст перед загрузкой тоже очень приятно. Однако для более сложных документов преобразование все еще довольно точное, но способ вывода текста не сильно облегчит вашу жизнь.
В настоящее времяOnline OCR поддерживает 46 различных языков и может преобразовывать PDF, JPG, BMP, TIFF и GIF в формат Word, Excel или обычный текст. На сайте утверждается, что «преобразованные документы выглядят точно так же, как оригинал — таблицы, столбцы и графика».
Версия, которую можно использовать без регистрации, позволяет конвертировать до 15 изображений в час (ограничение 5 МБ). Если вы зарегистрируете учетную запись, вы сможете приобрести больше страниц сверх этого лимита, а также сможете конвертировать многостраничные документы и ZIP-архивы.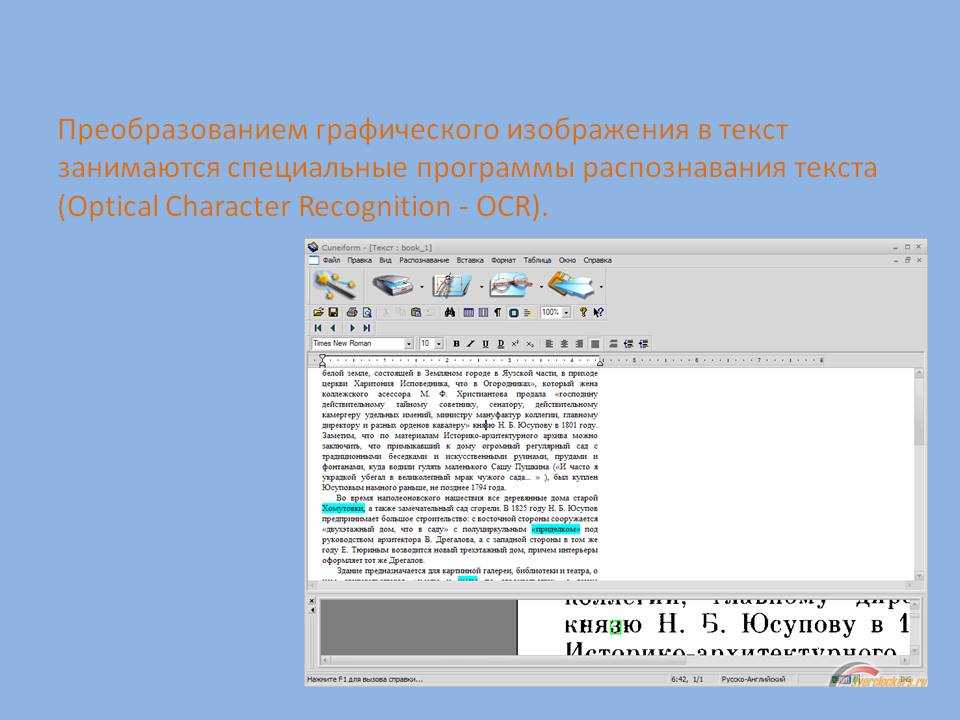
Основной документ к DOC
Базовый документ преобразован безупречно, за исключением того, что римская цифра I не была поднята. Как и обещал сайт, форматирование было именно таким, как в книге. Слава этому инструменту.
Комплексный документ к DOC
Разочаровавшись в предыдущих инструментах OCR при преобразовании сложного документа, я был очень впечатлен Online OCR. Планировка была почти идеальной, как вы можете видеть выше. Опять же, рецепт был подобран не слишком хорошо, но любые другие мелкие ошибки были незначительными.
Вердикт
Абсолютно фантастические результаты Online OCR. Единственный недостаток, который я вижу, заключается в том, что нет возможности загрузить преобразованные документы в формате PDF, поскольку упомянутые выходные форматы включают только DOCX, XLSX и TXT.
Как упоминалось ранее, ABBYY является одним из лидеров рынка программного обеспечения для оптического распознавания символов, стоимость полной загружаемой программы которого составляет около 150 долларов. Тем не менее, они предлагают 10-страничную бесплатную пробную версию для своего онлайн-инструмента (требуется регистрация). За подписку на 5 долларов их онлайн-инструмент позволит вам конвертировать 200 страниц каждый месяц.
Тем не менее, они предлагают 10-страничную бесплатную пробную версию для своего онлайн-инструмента (требуется регистрация). За подписку на 5 долларов их онлайн-инструмент позволит вам конвертировать 200 страниц каждый месяц.
Принимаются файлы размером до 100 МБ в любом из следующих форматов: PDF, JPG, JPEG, TIF, TIFF, PCX, DCX, BMP и PNG. ABBYY также распознает почти 200 языков. Выходные данные особенно впечатляют благодаря возможности выбора между DOCX, XLSX, RTF, TXT, PPTX, ODT, PDF, FB2 и EPUB.
Вы даже можете опробовать несколько БЕТА-функций во время пробного периода. Во-первых, это возможность перевести документ на другой язык. Другой — экспортировать преобразованный документ в учетную запись облачного хранилища, будь то Dropbox, Google Drive, Evernote, Microsoft OneDrive или Box.
Базовый документ в формате DOCX
Общие результаты были хорошими, но не ошеломляющими, учитывая, что это продукт премиум-класса. Несколько запятых и точек были переставлены местами, несколько кавычек заменены звездочкой, пропущена пара заглавных букв, а одно слово (буквальный) было написано неправильно.
Несколько запятых и точек были переставлены местами, несколько кавычек заменены звездочкой, пропущена пара заглавных букв, а одно слово (буквальный) было написано неправильно.
Сложный документ в DOCX
После конвертации в тексте документа было очень мало ошибок (кроме того, что OCR снова столкнулся со шрифтом этого рецепта!), но форматирование оставляло желать лучшего.
Три столбца каким-то образом заняли две страницы, а центральный столбец только появился на второй странице. Если бы вы действительно хотели сделать что-нибудь с этим преобразованным документом, вам пришлось бы рвать на себе волосы.
Основной документ в PDF
При просмотре конвертированного PDF-файла я вообще не нашел ошибок. Возможно, мы нашли то, в чем превосходит ABBYY. Фантастические результаты.
Сложный документ в PDF
Опять же, я не смог найти никаких ошибок в этом конвертированном файле. Очевидно, что ABBYY отлично умеет конвертировать в PDF.
Очевидно, что ABBYY отлично умеет конвертировать в PDF.
Вердикт
Если вы согласны заплатить несколько долларов, преобразование в PDF, кажется, работает феноменально хорошо с этой службой, а возможность синхронизировать преобразованные файлы с облачным хранилищем особенно полезна, если вы сканируете большой объем документов. Однако, как и в случае с другими вариантами, ABBYY до сих пор не придумала, как безупречно конвертировать документы в DOC для удобного редактирования.
Окончательный результат
Если, как и большинство людей, вы просто хотите отсканировать несколько журнальных статей и несколько счетов за дом, вам не нужно редактировать эти документы. Поэтому вам подойдет прямое преобразование в PDF, потому что вы все равно сможете искать эти документы. Для этого Free Online OCR определенно был лучшим бесплатным инструментом, который мы тестировали. При этом, если вы готовы платить 5 долларов США в месяц за почти совершенство, FineReader Online от ABBYY оказался немного более точным.