Модель визитной карточки распознавателя форм – Azure Applied AI Services
- Чтение занимает 3 мин
В этой статье
Обзор
Модель “бизнес-карта” сочетает мощные возможности оптического распознавания символов (OCR) с моделями глубокого обучения для анализа и извлечения ключевых данных из образов визитных карточек. API анализирует печатные визитные карты; Извлекает ключевые сведения, такие как имя, фамилия, название компании, адрес электронной почты и номер телефона; и возвращает структурированное представление данных JSON.
Пример визитной карточки, обработанной с помощью примера средства создания меток для распознавателя форм:
Попробуйте форму распознавателя студии (Предварительная версия)
Разметка Forms Studio доступна в предварительной версии API (v 3.

Извлечение имени, должности, адреса, электронной почты, названия организации и других возможностей с помощью нашей функции “визитная карточка” для распознавания.
Чтобы увидеть, как извлекаются данные из визитной карточки, используйте наш пример средства создания меток. Вам потребуется следующее:
Подписка Azure — вы можете создать ее бесплатно .
Экземпляр распознавателя форм ) в портал Azure. Вы можете использовать ценовую категорию “Бесплатный” (
F0), чтобы поработать со службой. После развертывания ресурса щелкните
В пользовательском интерфейсе распознавателя форм:
- Выберите использовать готовую модель для получения данных.
- В раскрывающемся меню тип формы выберите Визитная карточка :
Требования к входным данным
- Для получения наилучших результатов предоставьте одну четкую фотографию или высокое качество сканирования на документ.

- Поддерживаемые форматы файлов: JPEG, PNG, BMP, TIFF и PDF (внедренный или отсканированный текст). PDF-файлы с внедренным текстом позволяют исключить возможность ошибки при извлечении и расположении символов.
- Для документов PDF и TIFF можно обработать до 2000 страниц (с подпиской уровня Free, обрабатываются только первые две страницы).
- Размер файла должен быть менее 50 МБ.
- Изображения должны иметь размеры в пределах от 50 x 50 до 10000 x 10000 пикселей.
- Размеры PDF-файла имеют размер до 17 x 17 дюймов, соответствующие юридическим или стандартному размеру бумаги или меньше.
- Общий размер обучающих данных составляет 500 страниц или меньше.
- Если PDF-файлы заблокированы паролем, необходимо снять блокировку перед отправкой.
- Для неконтролируемого обучения (без помеченных данных):
- данные должны содержать ключи и значения.
- ключи должны располагаться выше или левее значений; они не могут отображаться ниже или справа.

Поддерживаемые языки и языковые стандарты
Примечание
Указывать языковой стандарт не обязательно. Этот параметр является необязательным. Технология глубокого обучения Распознавателя документов будет автоматически определять язык текста в изображении.
| Моделирование | Язык — код локали | По умолчанию |
|---|---|---|
| Визитная карточка |
| Автоматически обнаруживаемый |
Извлечение пар “ключ-значение”
| Имя | Тип | Описание | Стандартизованные выходные данные |
|---|---|---|---|
| ContactNames | массив объектов | Имя контактного лица | |
| FirstName | строка | Имя контакта | |
| LastName | строка | Фамилия контакта | |
| CompanyNames | Массив строк | Названия организаций | |
| Departments | Массив строк | Отделы или организации контакта | |
| JobTitles | Массив строк | Названия названий заданий контакта | |
| Адреса электронной почты | Массив строк | Адрес электронной почты контакта | |
| веб-сайты; | Массив строк | Веб-сайты компании | |
| Адреса | Массив строк | Адреса, извлеченные из визитной карточки | |
| MobilePhones | Массив номеров телефонов | Номера мобильных телефонов от визитной карточки | + 1 XXX XXX XXXX |
| Faxes | Массив номеров телефонов | Номера телефонов с визитной карточки | + 1 XXX XXX XXXX |
| WorkPhones | Массив номеров телефонов | Номера рабочих телефонов с визитной карточки | + 1 XXX XXX XXXX |
| OtherPhones | Массив номеров телефонов | Другие номера телефонов с визитной карточки | + 1 XXX XXX XXXX |
Предварительная версия распознавателя форм 3.
 0
0В предварительной версии распознавателя форм представлены несколько новых функций и возможностей.
Дальнейшие действия
Предварительно созданная модель ИИ для распознавания текста — AI Builder
- Чтение занимает 2 мин
В этой статье
Предварительно созданная модель распознавания текста извлекает распознаваемые слова из документов и изображений в потоки машиночитаемых символов. Для обнаружения печатных и рукописных текстов на изображениях используется современный механизм оптического распознавания символов (OCR).
Эта модель обрабатывает изображения и файлы документов для извлечения строк печатного или рукописного текста.
Использование в Power Apps
Использование в Power Automate
Для получения информации о том, как использовать эту модель в Power Automate см. Использование предварительно созданной модели распознавания текстов в Power Automate.
Поддерживаемый язык, формат и размер
Файлы, которые можно проверить с помощью модели распознавания текста, должны обладать следующими характеристиками:
- Язык: африкаанс, албанский, арабский, астурийский, баскский, бислама, бретонский, каталонский, кебуанский, чаморро, китайский (упрощенный), китайский (традиционный), корнуоллский, корсиканский, крымскотатарский (латинский), чешский, датский, голландский, английский, эстонский, фиджийский, филиппинский, финский, французский, фриульский, галисийский, немецкий, гильбертский, греческий, гренландский, гаитянский креольский, хани, хмонг Дау (латиница), венгерский, индонезийский, интерлингва, инуктитут (латинский), ирландский, итальянский, японский, яванский, киче, кабувердиану, качин (латиница), каракалпакский, кашубский, хаси, корейский, курдский (латинский), люксембургский, малайский (латинский), мэнский, неаполитанский, норвежский, норвежский, окситанский, польский, португальский, румынский, ретороманский, русский, шотландский, шотландский гэльский, сербский (кириллица), сербский (латиница), словацкий, словенский, испанский, суахили (латинский), шведский, татарский (латинский), тетум, турецкий, верхнесорбский, узбекский (латинский), волапюк, вальзер, западно-фризский, юкатекский майя, чжуанг, зулусский
- Формат:
- Размер: не более 20 МБ
Выходные данные модели
При обнаружении документа модель распознавания текста выводит следующую информацию:
- Результаты: список строк, извлеченных из входного текста.

- Текст: строки, содержащие обнаруженные строки текста.
- BoundingBox: четыре значения, представляющие ограничивающий прямоугольник, описываемый шириной и высотой, которые отсчитываются от верхнего левого угла.
Ограничения
| Действие | Ограничение | Период возобновления действия |
|---|---|---|
| Вызовы распознавания текста (на среду) | 480 | 60 секунд |
Голосовой блокнот – Speechpad.ru
Голосовой блокнот позволяет вводить текст, используя микрофон, а также переводить речь из аудио и видео в печатный текст. В настоящее время голосовой ввод возможен только
в браузере Chrome для OS Windows, Mac и Linux (для пользователей Андроид и iOS разработаны специальные Android, iOS приложения). Для работы сервиса рекомендуется использовать внешний микрофон неплохого качества.
Голосовой набор текста
Нажмите кнопку “включить запись”. При первом посещении сайта вверху браузера возникнет панелька с просьбой разрешить доступ к микрофону. Нажмите там кнопку “Разрешить”
Говорите в микрофон
Кнопка A/a меняет регистр первой буквы слова, рядом с которым находится курсор
Кнопка Отменить удаляет из результирующего поля последний введенный фрагмент
Кнопки пунктуации служат для ввода знаков с помощью мыши
Текст в результирующее поле добавляется после последней позиции курсора. Если был выделен фрагмент текста в результирующем поле, то введенный текст будет его заменять
Установка флажка Отключить управление заглавными буквами Google отменяет простановку заглавных букв анализатором Google.
Если отмечен флажок Заменять слова пунктуации, то слова в голосовом вводе, совпадающие со знаками препинания, будут заменяться на эти знаки. Соответствующие слова можно увидеть, если навести мышь на кнопку знака.
*В настоящее время Google самостоятельно заменяет слова: точка, запятая, вопросительный и восклицательный знаки, поэтому при отключении флажка замена все равно может проводиться.
Соответствующие слова можно увидеть, если навести мышь на кнопку знака.
*В настоящее время Google самостоятельно заменяет слова: точка, запятая, вопросительный и восклицательный знаки, поэтому при отключении флажка замена все равно может проводиться.
Смена языка для голосового ввода осуществляется выбором соответствующего языка в выпадающем списке. Если языка нет в списке, но он поддерживается для голосового ввода, то его можно добавить в кабинете пользователя (доступен после регистрации)
Если отмечен флажок Выполнять команды, то во время ввода текста можно давать команды голосом.
Если отмечен флажок Вывод в буфер обмена, то текст будет поступать не в результирующее поле, а в буфер обмена. Флажок работает только при установленном расширении блокнота.
Поле Уровень распознавания отображает качество распознавания речи или вид ошибки, если она возникла.
Ввод текста голосом любое поле ввода! Интеграция с Windows, Mac и Linux
Установив расширение для голосового блокнота,
вы получите возможность вводить текст голосом в любое поле ввода напрямую. Добавив модуль интеграции c Windows, Mac или Linux,
вы обеспечите прямой голосовой ввод во все приложения в этой OS.
Добавив модуль интеграции c Windows, Mac или Linux,
вы обеспечите прямой голосовой ввод во все приложения в этой OS.
Перевод аудио в текст
Кнопка Транскрибация включает панель воспроизведения звуковых и видео файлов.
В настоящее время в голосовом блокноте доступен перевод аудиотекстов из форматов html5 видео и аудио, а также из видеозаписей youtube.
Для форматов html5 видео и аудио необходимо указать URL медиа файла, для воспроизведения записи youtube нужно ввести ID этой записи в Youtube.
После чего следует нажать на кнопку включить запись.
Снятие флажка Запускать синхронно с записью в модуле транскрибирования дает возможность самостоятельно проговаривать прослушиваемые фрагменты аудио или видео (при использовании наушников). Данная опция крайне полезна при плохом качестве роликов, когда автоматическое распознавание невозможно.
Видео инструкции по работе с системой
Обучающие видео по работе с голосовым блокнотом.
Приложения для голосового блокнота
Для удобства работы можно установить приложение CHROME или воспользоваться возможностями CHROME по созданию ярлыков приложений для запуска блокнота с предустановленными параметрами.
Распознаватели текста (Text Recognition) — MrTranslate.ru
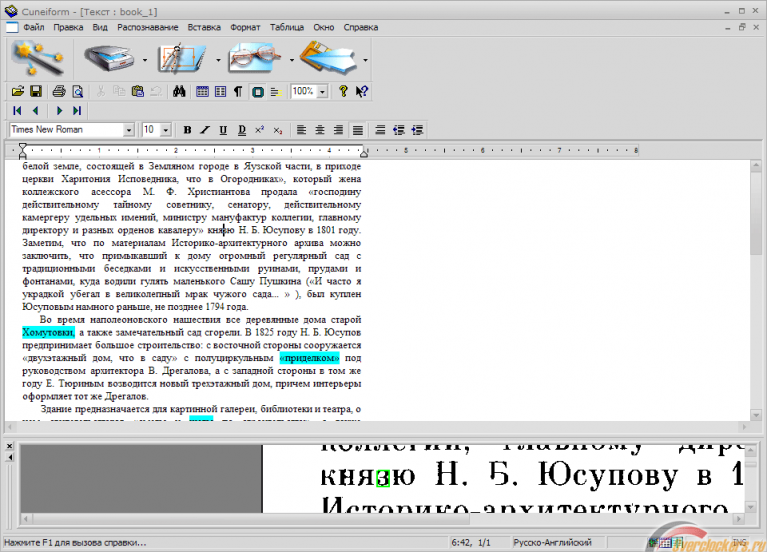
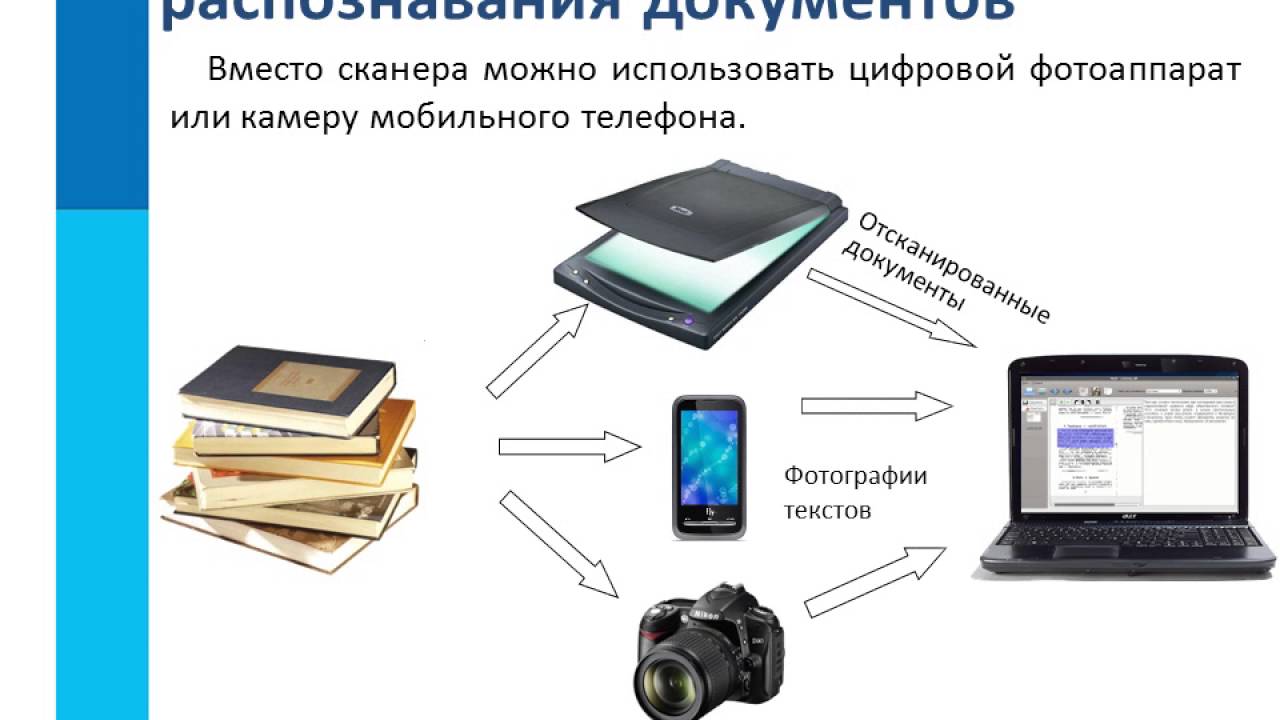
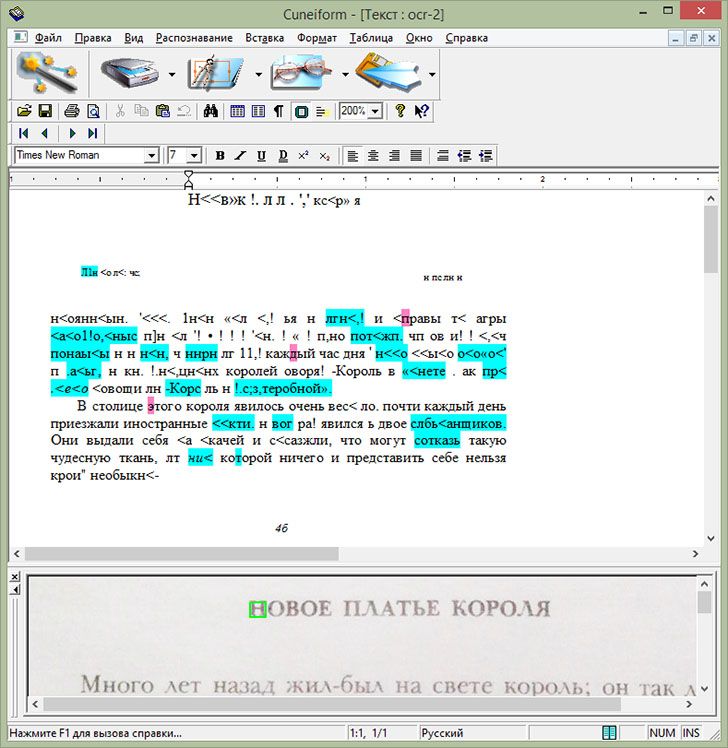
Если вам необходимо перевести ранее напечатанный текст в электронную форму, то сегодня вам не потребуется набирать его на клавиатуре. Современные технологии существенно упрощают этот процесс. Достаточно отсканировать его или сфотографировать, и обработать специальной программой — распознавателем текста.
Давно прошло то время, когда для получения электронной копии печатного текста, приходилось набирать его на клавиатуре, символ за символом, буква за буквой. Сегодня печатный текст достаточно положить на сканер, нажать одну кнопку, и уже через несколько секунд у вас будет его электронная копия, как будто кто-то уже набрал его для вас. Как же это стало возможным? Как работает распознавание текста?Системы распознавания текста или OCR-системы (Optical Character Recognition) предназначены для автоматического ввода документов в компьютер. Это может быть страница книги, журнала, словаря, какой-то документ — все, что угодно, что было уже напечатано, и должно быть преобразовано обратно в электронную форму.
Это может быть страница книги, журнала, словаря, какой-то документ — все, что угодно, что было уже напечатано, и должно быть преобразовано обратно в электронную форму.
OCR-системы распознают текст и различные его элементы (картинки, таблицы) с электронного изображения. Изображение получается обычно путем сканирования документа и реже — его фотографированием. Поступившее изображение обрабатывается алгоритмом OCR-программы, выделяются области текста, изображений, таблиц, отделяется мусор от нужных данных.
На следующем этапе каждый символ сравнивается со специальным словарем символов, и если находится соответствие, то этот символ считается распознанным. В итоге вы получаете набор распознанных символов, то есть искомый текст.
Современные OCR-системы представляют собой достаточно сложные программные решения. Ведь текст может быть замусорен, искажен,
загрязнен, и программа должна это учитывать и уметь правильно обрабатывать такие ситуации. Кроме того, современные OCR-системы позволяют также получить копию печатного документа в электронном виде с сохранением форматирования, стилей, размеров текста и видов шрифтов и т. д.
д.
ABBYY FineReader 9.0 Home Edition
| Разработчик: | ABBYY |
| Тип лицензии: | Trial, только для домашнего использования |
| Требования: | Windows 2000/XP/Vista, 250-512 Mb свободного места, сканер |
ABBYY FineReader 9.
 0 Professional Edition
0 Professional Edition| Разработчик: | ABBYY |
| Тип лицензии: | Trial |
| Требования: | Windows 2000/XP/Vista, 250-512 Mb свободного места, сканер |
 Подробнее о FineReader 9.0 Professional Edition →
Подробнее о FineReader 9.0 Professional Edition →ABBYY FineReader 9.0 Corporate Edition
| Разработчик: | ABBYY |
| Тип лицензии: | для корпоративного использования |
| Требования: | Windows 2000/XP/Vista, 250-512 Mb свободного места, сканер |
ABBYY Business Card Reader
| Разработчик: | ABBYY |
| Тип лицензии: | Trial 1 день |
| Требования: | Nokia (модели N73, N78, N79, N82, N85, N86 8MP, N93, N93i, N95, N95-3 NAM, N95 8GB, N96, N96-3, E90 Communicator, 6210 Navigator, E71, E66, E63, E75, 6220 classic, 6720 classic, 5730 XpressMusic, 6710 Navigator, 5800 XpressMusic) |
 ABBYY Business Card Reader будет удобна для деловых людей, бизнесменов, менеджеров, всех, кто часто сталкивается с визитными карточками. Программа поддерживает 16 языков.
Подробнее о ABBYY Business Card Reader →
ABBYY Business Card Reader будет удобна для деловых людей, бизнесменов, менеджеров, всех, кто часто сталкивается с визитными карточками. Программа поддерживает 16 языков.
Подробнее о ABBYY Business Card Reader →Readiris 12 Pro
| Разработчик: | I.R.I.S. s.a. |
| Тип лицензии: | Trial |
| Требования: | Windows 200/XP/Vista или Mac, 256 Mb RAM, 150-250 Mb свободного места, сканер |
 Подробнее о Readiris 12 Pro →
Подробнее о Readiris 12 Pro →Readiris 12 Corporate
| Разработчик: | I.R.I.S. s.a. |
| Тип лицензии: | Trial |
| Требования: | Windows 200/XP/Vista или Mac, 256 Mb RAM, 150-250 Mb свободного места, сканер |
SimpleOCR
| Разработчик: | SimpleSoftware |
| Тип лицензии: | Freeware |
| Требования: | Windows 95/98/NT4/2000/XP/Vista, 50 Mb свободного места, сканер, TWAIN driver |
 Программа обладает множеством возможностей, практически не уступая коммерческим версиям. В данный момент SimpleOCR умеет распознавать тексты на английском и французском языках.
Подробнее о SimpleOCR →
Программа обладает множеством возможностей, практически не уступая коммерческим версиям. В данный момент SimpleOCR умеет распознавать тексты на английском и французском языках.
Подробнее о SimpleOCR →Ввод китайских иероглифов при помощи мыши или планшета
| Разработчик: | NJStar Software Corp. |
| Тип лицензии: | trial на 30 дней |
Программа поддерживает как китайский традиционный, так и китайский упрощенный. Набранный текст можно озвучивать (произносить) при помощи встроенного speech-движка. Все параметры программы полностью настраиваются.
NJStar Chinese Pen поддерживает все версии операционной системы Windows. Для работы программы требуется примерно 50 Мб свободного места на жестком диске.
Для работы программы требуется примерно 50 Мб свободного места на жестком диске.
rite Pen
| Разработчик: | Evernote Corp. |
| Тип лицензии: | trial на 30 дней |
 Подробнее о rite Pen →
Подробнее о rite Pen →ArioForm
| Разработчик: | Ariolis |
| Тип лицензии: | trial на 30 дней |
MyScript Studio
| Разработчик: | Vision Objects |
| Тип лицензии: | trial на 30 дней |
 Программа будет полезна всем деловым людям, менеджерам, журналистам, и всем остальным, кто часто делает рукописные заметки.
При помощи этой программы вы сможете быстро перевести в электронную форму все ваши заметки, записи и рукописные документы, распознать текст и организовать электронный архив.
Подробнее о MyScript Studio →
Программа будет полезна всем деловым людям, менеджерам, журналистам, и всем остальным, кто часто делает рукописные заметки.
При помощи этой программы вы сможете быстро перевести в электронную форму все ваши заметки, записи и рукописные документы, распознать текст и организовать электронный архив.
Подробнее о MyScript Studio →Распознавание рукописного текста MyScript Stylus
| Разработчик: | Vision Objects |
| Тип лицензии: | trial на 30 дней |
| Требования: | Windows, Mac или Linux, 400 Мб свободного места |
 Вы можете закрепить MyScript Stylus за определенной программой, и весь распознаваемый текст будет передаваться ей, как-будто текст вводится стандартным способом. MyScript Stylus поддерживает 26 языков.
Подробнее о MyScript Stylus →
Вы можете закрепить MyScript Stylus за определенной программой, и весь распознаваемый текст будет передаваться ей, как-будто текст вводится стандартным способом. MyScript Stylus поддерживает 26 языков.
Подробнее о MyScript Stylus →PenOffice
| Разработчик: | PhatWare Corporation |
| Тип лицензии: | trial на 30 дней |
| Требования: | Windows XP/Vista, 50 Мб свободного места |
CalliGrapher
| Разработчик: | PhatWare Corporation |
| Тип лицензии: | trial на 30 дней |
| Требования: | Windows Mobile 4/5/6/6. 1, 3.8 Мб свободного места, ActiveSync 4.0 1, 3.8 Мб свободного места, ActiveSync 4.0 |
Распознавание текста | Комплект ML | Разработчики Google
API распознавания текста ML Kit может распознавать текст на любом языке, основанном на латинице. набор символов. Его также можно использовать для автоматизации задач ввода данных. например, обработка кредитных карт, квитанций и визитных карточек.
iOS Android
Ключевые возможности
- Распознавать текст на латинских языках Поддерживает распознавание текст латиницей
- Анализировать структуру текста Поддерживает определение слов / элементов, строк и пункты
- Определение языка текста Определение языка распознанного текста
- Небольшой размер приложения На Android API предлагается как разделенная библиотека через Google Play Services
- Распознавание в реальном времени Может распознавать текст в реальном времени на широком диапазоне устройства
 Он повышает точность распознавания текста и предлагает поддержку
Китайские, деванагари, японские и корейские шрифты.
Он повышает точность распознавания текста и предлагает поддержку
Китайские, деванагари, японские и корейские шрифты.Структура текста
Распознаватель текста сегментирует текст на блоки, строки и элементы. Грубо говорящий:
a Блок представляет собой непрерывный набор текстовых строк, таких как абзац или колонна,
a Строка представляет собой непрерывный набор слов на одной оси, а
элемент представляет собой непрерывный набор буквенно-цифровых символов («слово») на та же ось в большинстве латинских языков или символ в других
На изображении ниже показаны примеры каждого из них в порядке убывания.В Первый выделенный блок голубым цветом – это блок текста. Второй набор выделенные блоки синим цветом – это строки текста. Наконец, третий набор выделенные блоки темно-синим цветом – это слова.
Для всех обнаруженных блоков, линий и элементов API возвращает ограничивающие рамки,
угловые точки, распознанные языки и распознанный текст.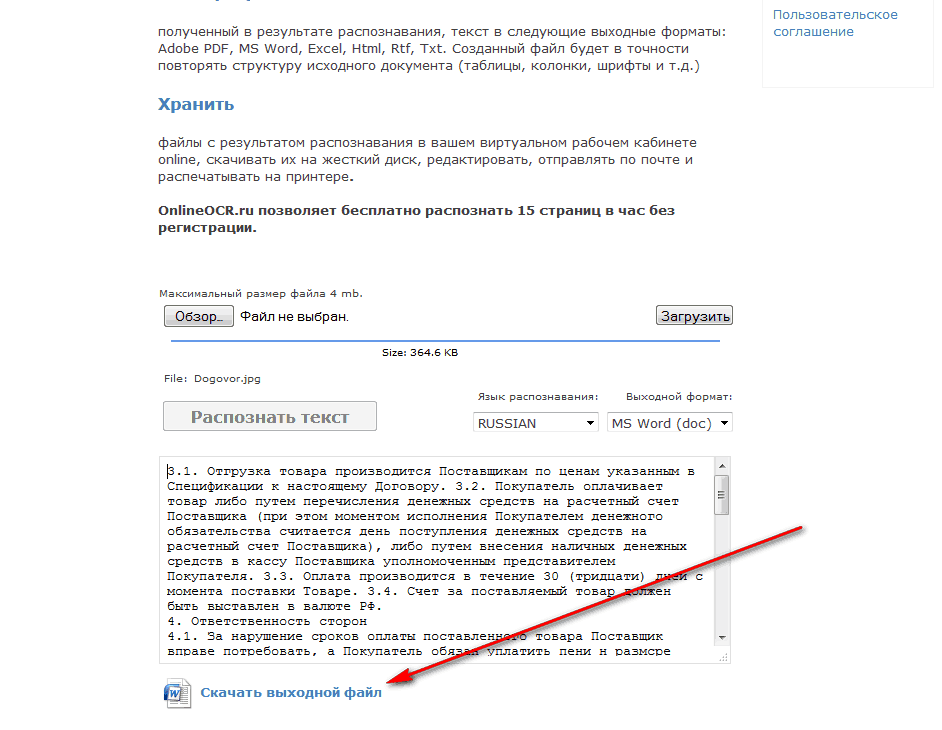
Пример результатов
Фото: Дитмар Рабич, Wikimedia Commons, “Дюссельдорф, Wege der parlamentarischen Demokratie – 2015 – 8123 “, CC BY-SA 4.0
| Распознанный текст | |
|---|---|
| Текст | Wege der parlamentarischen Demokratie |
| Блоки | (1 блок) |
| Блок 0 | |
|---|---|
| Текст | Wege der parlamentarischen Demokratie |
| Рама | (117,0, 258,0, 190,0, 83,0) |
| Угловые точки | (117, 270), (301,64, 258,49), (306.05, 329,36), (121,41, 340,86) |
| Распознанный код языка | из |
| Строки | (3 линии) |
| Строка 0 | |
|---|---|
| Текст | Wege der |
| Рама | (167,0, 261,0, 91,0, 28,0) |
| Угловые точки | (167, 267), (255,82, 261,46), (257,19, 283,42), (168,36, 288,95) |
| Распознанный код языка | из |
| Элементы | (2 элемента) |
| Элемент 0 | |
|---|---|
| Текст | Wege |
| Рама | (167. 0, 263,0, 59,0, 26,0) 0, 263,0, 59,0, 26,0) |
| Угловые точки | (167, 267), (223,88, 263,45), (225,25, 285,41), (168,36, 288,95) |
Готовая модель AI для распознавания текста – AI Builder
- 2 минуты на чтение
В этой статье
Предварительно созданная модель распознавания текста извлекает слова из документов и изображений в машиночитаемые потоки символов.Он использует современное оптическое распознавание символов (OCR) для обнаружения печатного и рукописного текста на изображениях.
Эта модель обрабатывает изображения и файлы документов для извлечения строк напечатанного или рукописного текста.
Использование в Power Apps
Предварительно созданная модель распознавания текста доступна в Power Apps с помощью компонента распознавания текста. Дополнительные сведения: Используйте компонент распознавания текста в Power Apps
Дополнительные сведения: Используйте компонент распознавания текста в Power Apps
Использование в Power Automate
Для получения информации о том, как использовать эту модель в Power Automate, см. Использование предварительно созданной модели распознавания текста в Power Automate.
Поддерживаемый язык, формат и размер
Файлы, которые можно сканировать с помощью модели распознавания текста, должны иметь следующие характеристики:
- Язык : африкаанс, албанский, арабский, астурийский, баскский, бислама, бретонский, каталонский, кебуанский, чаморро, китайский (упрощенный), китайский (традиционный), корнуоллский, корсиканский, крымскотатарский (латиница), чешский, датский, Голландский, английский, эстонский, фиджийский, филиппинский, финский, французский, фриульский, галисийский, немецкий, гильбертский, греческий, гренландский, гаитянский креольский, хани, хмонг Дау (латинский), венгерский, индонезийский, интерлингва, инуктитут (латинский), ирландский, Итальянский, японский, яванский, киче, кабувердиану, качин (латиница), каракалпакский, кашубский, хаси, корейский, курдский (латинский), люксембургский, малайский (латинский), мэнский, неаполитанский, норвежский, норвежский, окситанский, Польский, португальский, румынский, ретороманский, русский, шотландский, шотландский гэльский, сербский (кириллица), сербский (латиница), словацкий, словенский, испанский, суахили (латинский), шведский, татарский (латинский), тетум, турецкий, верхнесербский, Узбекский (латиница), волапюк, вальсер, западно-фризский, юкатекский майя, чжуанг, зулу
- Формат :
- Размер : не более 20 МБ
Выпуск модели
Если документ обнаружен, модель распознавания текста выводит следующую информацию:
- Результаты : список строк, извлеченных из входного текста.

- Текст : Обнаружены строки, содержащие строку текста.
- BoundingBox : четыре значения, представляющие ограничивающую рамку, описываемую с помощью верхнего и левого положения вместе с его шириной и высотой.
Пределы
| Действие | Предел | Срок продления |
|---|---|---|
| Вызовы распознавания текста (для каждой среды) | 480 | 60 секунд |
Пять лучших инструментов для распознавания текста
Работа с текстом на вашем компьютере предлагает ряд возможностей для поиска и редактирования, которые просто недоступны для бумажных копий текста.Воспользуйтесь этими пятью инструментами распознавания текста, чтобы перенести печатный текст на свой компьютер.
Автор фото: mmechinita .
Оптическое распознавание символов (OCR) существует уже несколько десятилетий, но только недавно стало экономичным и достаточно простым в использовании, что стало доступным для среднего потребителя. Сегодня мы рассмотрим пять любимых читателей Lifehacker приложений для преобразования физического текста в машиночитаемый виртуальный текст.
Сегодня мы рассмотрим пять любимых читателей Lifehacker приложений для преобразования физического текста в машиночитаемый виртуальный текст.
Adobe Acrobat (Windows / Mac, от 130 долларов)
G / O Media может получить комиссию
Надежная система распознавания текста – одна из самых недооцененных функций Adobe Acrobat.Включенная во все версии от Adobe Acrobat Standard до Pro Extended и заправленная в подменю, функция распознавания текста в Adobe надежна и работает как с отсканированными, так и с уже сохраненными документами. Многие люди уже имеют копию Acrobat дома или на работе и обнаруживают, что качество распознавания достаточно высокое, поэтому у них нет особых причин вкладывать деньги в специальный инструмент распознавания текста.
Evernote (Windows / Mac, бесплатно) / OneNote (Windows, 65 долларов США)
Мы сгруппировали Evernote и OneNote вместе, потому что у них есть общее ограничение.Ни одно из приложений не было разработано для использования в качестве автономного инструмента распознавания текста, поэтому возможности распознавания текста обоих предназначены просто для дополнения основной цели инструмента – создания отличных заметок. С этой целью, однако, если ваших потребностей в оптическом распознавании текста немного и они в основном сосредоточены на добавлении бумажного текста в рабочий процесс создания заметок / исследования, то Evernote и OneNote – отличные решения. Однако, если вам нужно распознавание текста с большим объемом документов с большим количеством страниц, вы, вероятно, захотите найти другое решение OCR, поскольку эти два приложения не особенно хорошо подходят для работы с чем-то большим, чем индексирование текста визитки и мелкие документы.
С этой целью, однако, если ваших потребностей в оптическом распознавании текста немного и они в основном сосредоточены на добавлении бумажного текста в рабочий процесс создания заметок / исследования, то Evernote и OneNote – отличные решения. Однако, если вам нужно распознавание текста с большим объемом документов с большим количеством страниц, вы, вероятно, захотите найти другое решение OCR, поскольку эти два приложения не особенно хорошо подходят для работы с чем-то большим, чем индексирование текста визитки и мелкие документы.
OmniPage (Windows, от 149 долл. США)
На этом этапе мы уходим от продуктов, которые удовлетворяют потребности нечастых пользователей OCR, и переходим к продуктам, которые содержат множество функций и ориентированы исключительно на OCR. OmniPage имеет мощный механизм распознавания текста, отличное распознавание и сохранение формата и макета, а также интеграцию с популярными приложениями, включая поддержку распознавания текста одним щелчком в Microsoft Office и функцию отправки на Kindle. OmniPage поддерживает несколько языков, пакетную обработку и экспорт в несколько распространенных форматов документов.
OmniPage поддерживает несколько языков, пакетную обработку и экспорт в несколько распространенных форматов документов.
ABBYY FineReader (Windows / Mac, 399,99 долл. США)
ABBYY FineReader предлагает поразительное количество функций и приемов распознавания текста – как и должно быть, за внушительную цену в 399 долл. США. FineReader превосходно распознает текст и форматирует широкий спектр входных данных – отсканированный текст, существующие документы, снимки с камеры и многое другое – с поддержкой более 180 языков. Он может распознавать текст на изображениях, штрих-кодах и других элементах, которые не хватает большинству основных инструментов распознавания текста. FineReader интегрируется с популярными офисными приложениями и поставляется с запрограммированными «быстрыми задачами», позволяющими упростить стандартные рабочие процессы сканирования одним щелчком мыши.ABBYY FineReader доступен как для Windows, так и для Mac OS X, хотя пользователи Mac ограничены пакетом FineReader Express (99 долларов США), облегченной версией полного пакета FineReader.
Readiris (Windows / Mac, 129 долл. США)
Технология Readiris – это механизм оптического распознавания текста, лежащий в основе функций оптического распознавания текста в популярных приложениях, таких как Adobe Acrobat, но эта же технология используется в их автономном программном обеспечении оптического распознавания текста. Readiris поддерживает более 120 языков – для азиатских и ближневосточных языков доступны дополнительные пакеты.Приложение сканирует и отправляет документы прямо в ваше любимое приложение, создает и конвертирует файлы PDF, а также генерирует документы меньшего размера, используя собственные методы сжатия, чтобы радикально сжимать документы для облегчения передачи и архивирования. Readiris также поддерживает распознавание текста в изображениях и рукописных заметках.
Теперь, когда у вас была возможность ознакомиться с наборами функций пяти самых популярных инструментов распознавания текста, пришло время проголосовать за своего фаворита:
Придумайте совет, уловку или инструмент, который вы хотите поделиться, чтобы помочь другим читателям улучшить сканирование OCR? Узнаем об этом в комментариях.
Как использовать средство распознавания текста в приложении Canvas
Введение:Microsoft AI builder обладает множеством удивительных функций и может быть интегрирован с Power Platforms. В предыдущем блоге мы видели, как использовать управление сканером штрих-кода в Power Apps. В сегодняшнем блоге мы рассмотрим, как интегрировать Microsoft AI Builder Text Recognizer в приложение Canvas. Здесь у нас должна быть включена лицензия AI Builder, чтобы использовать Text Recognizer в приложении Canvas.
Давайте рассмотрим сценарий, в котором человек хочет ежедневно отправлять заметки всем ученикам в соответствии с классом. Теперь человек откроет приложение Canvas, загрузит изображения в элемент управления распознаванием текста, выберет класс в раскрывающемся списке и нажмет кнопку «Отправить электронное письмо», чтобы отправить заметки всем ученикам класса, выбранного в раскрывающемся списке. Для этого сначала необходимо создать настраиваемую сущность «Студент» в Dynamics 365 CRM, которая содержит имя, адрес электронной почты и класс студента, как показано на снимке экрана ниже:
Для этого сначала необходимо создать настраиваемую сущность «Студент» в Dynamics 365 CRM, которая содержит имя, адрес электронной почты и класс студента, как показано на снимке экрана ниже:
Теперь, чтобы отправлять ежедневные заметки всем ученикам, следуйте инструкциям ниже:
1.Создайте приложение Canvas и щелкните AI Builder , чтобы добавить Text Recognizer Control, как показано на снимке экрана ниже:
2. Теперь добавьте Drop Down Input и добавьте приведенную ниже формулу в свойство Item раскрывающегося списка, чтобы в раскрывающемся списке отображался список классов:
3. Теперь добавьте HTML Text , чтобы отобразить текст, полученный из Text Recognizer, чтобы пользователь мог проверить текст и отправить электронное письмо .
Чтобы увидеть текст , установите свойство HTMLText , как показано на снимке экрана ниже:
Формула в свойстве HTMLText : Concat (TextRecognizer. Results, Text & «
Results, Text & «
»)
В приведенной выше формуле функция Concat объединяет строки, полученные из результата распознавания текста, и печатает каждый текст в следующей строке, используя тег
HTML.
4. Вы можете добавить коннектор « Office365Outlook » для отправки сообщения электронной почты, которое будет содержать текст, извлеченный из элемента управления Text Recognizer , как показано на снимке экрана ниже:
5.Добавьте источник данных Student из Common Data Service в приложение Canvas, чтобы отправить электронное письмо из данных Student, как показано на снимке экрана ниже:
6. Добавьте кнопку « Отправить электронное письмо » и для свойства onSelect кнопки добавьте приведенную ниже формулу для фильтрации записей учащихся в зависимости от класса и отправки им сообщений электронной почты.
ForAll (
)Фильтр (
Студенты,
ClassDropdown. Выбранный текст в классе
Выбранный текст в классе
),
Office365Outlook.SendEmail (
Электронная почта,
«Заметки -» и «Сегодня» (),
TextHtmlText.HtmlText
)
)
Приведенная выше формула отфильтрует записи Student в зависимости от Class , выбранного в раскрывающемся списке, и для каждой записи студента отправляется электронное письмо, содержащее текст, полученный из Text Recognizer.
7. Теперь давайте запустим приложение, загрузим изображение в элемент управления Text Recognizer и отправим студенту электронное письмо, как показано на снимке экрана ниже:
Заключение: Таким образом, мы можем добавить Text Recognizer в приложение Canvas, чтобы получать текст из изображений с помощью элемента управления Text Recognizer .
Указание языка распознавания текста для каждого типа документа
- Отобразите главное окно ScanSnap Home.
Щелкните значок [ScanSnap Home] в списке приложений, который отображается при нажатии кнопки Launchpad в Dock.
- Выберите [ScanSnap Home] в строке меню → [Предпочтения], чтобы отобразить окно предпочтений.
- Укажите язык распознавания текста для каждого типа документа на вкладке [Язык].
Язык, место / регион получения (язык)
Укажите язык распознаваемого текста.
СОВЕТ
Когда выбрано [Не распознавать текст], запись данных содержимого, созданная из отсканированного документа, импортируется в ScanSnap Home при следующих условиях:
Когда тип документа – [Визитные карточки], информация о визитной карточке не извлекается
Когда тип документа – [Квитанции], информация о квитанции не извлекается
После того, как записи данных содержимого будут импортированы в ScanSnap Home, распознавание текста может быть выполнено снова, если необходимо.

Подробнее см. Преобразование записей данных содержимого в доступные для поиска.
Валюта по умолчанию
Этот элемент настройки предназначен только для [Квитанции].
Укажите валюту, которая будет использоваться, если валюта не распознается как текст.
По умолчанию используется валюта, автоматически полученная из локали (информация о стране и регионе) вашего компьютера.
Чтобы указать валюту по вашему выбору, нажмите кнопку [Настроить] и введите трехбуквенный буквенный код валюты в появившемся окне. Рекомендуется использовать коды валют, определенные в ISO 4217.
Для настроенной валюты можно указать только одну валюту.
- Щелкните в верхнем левом углу окна, чтобы закрыть окно настроек.
Если тип документа – [Документы], [Визитные карточки] или [Квитанции], устанавливается язык для распознавания текста.
Распознаватель текстас AI Builder
В этом коротком блоге я собираюсь показать, как потрясающе работает распознаватель текста в Power Apps и AI Builder.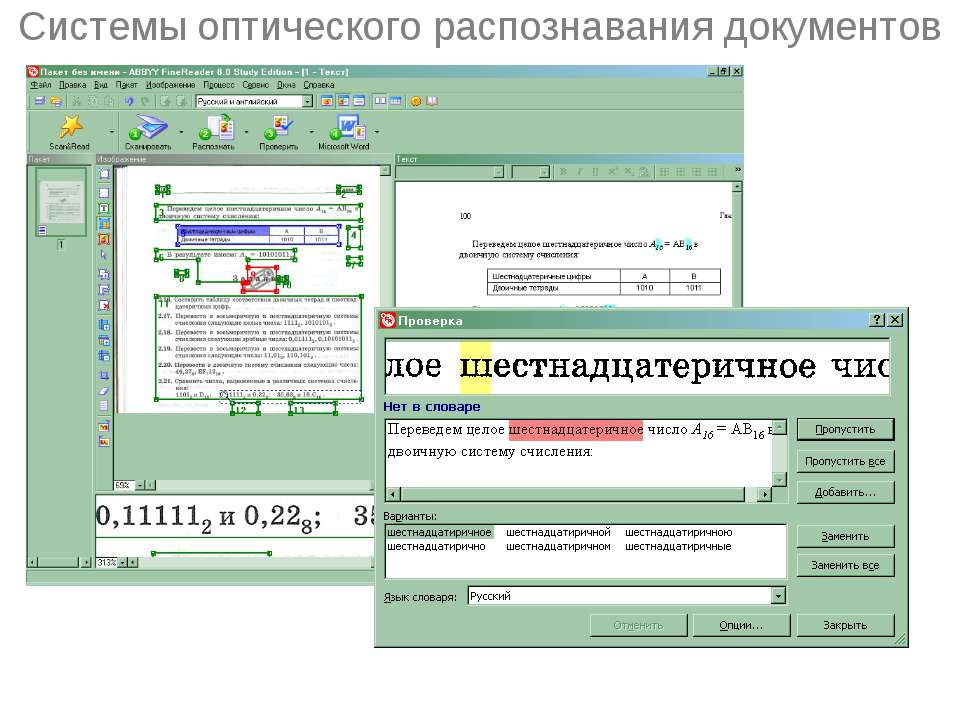
Это одна из новых функций, которые у нас есть.
Сначала войдите в Power Apps с функциями AI Builder. Затем нажмите на Ai Builder на левой панели и выберите Build, затем выберите Text Recognizer внизу страницы.
Затем выберите вариант использования в приложении.
в приложении может спросить вас об аутентификации, затем принять ее, и вы увидите новую страницу с компонентом распознавания текста.
Затем, чтобы увидеть метки, нажмите Вставить в верхнем левом углу и затем выберите Метку на панели
Затем для формулы выберите TextRecognizer1.SelectedText
Затем просто запустите приложение, я запускаю его для своей визитной карточки. Я нажимаю на всю текстовую строку, и, как вы можете видеть, вы можете увидеть результат в текстовом поле! это потрясающе.
Алос пробовал для L&P!
Посмотрите видео отсюда
Тренер, консультант, наставник
Лейла – первый Microsoft AI MVP в Новой Зеландии и Австралии, имеет докторскую степень. в информационной системе Оклендского университета. Она является содиректором и специалистом по анализу данных в компании RADACAD, имеющей более 100 клиентов по всему миру. Она является соорганизатором группы (встречи) Microsoft Business Intelligence и Power BI Use в Окленде с более чем 1200 участников. Она является соорганизатором трех основных конференций в Окленде: SQL Saturday Auckland (с 2015 г. по настоящее время) с более чем 400 регистраций, Difinity (с 2017 г. по настоящее время) с более чем 200 регистрациями и Global AI Bootcamp 2018.Она специалист по анализу данных, консультант по бизнес-аналитике, тренер и спикер. Она является известным международным докладчиком на многих конференциях, таких как Microsoft ignite, SQL pass, Data Platform Summit, SQL Saturday, Power BI world Tour и т. Д. В Европе, США, Азии, Австралии и Новой Зеландии. У нее более десяти лет опыта работы с базами данных и программными системами. Принимала участие во многих масштабных проектах для крупных компаний. Она также ИИ и платформа данных Microsoft MVP. Лейла – активный технический блоггер Microsoft AI для RADACAD.
Д. В Европе, США, Азии, Австралии и Новой Зеландии. У нее более десяти лет опыта работы с базами данных и программными системами. Принимала участие во многих масштабных проектах для крупных компаний. Она также ИИ и платформа данных Microsoft MVP. Лейла – активный технический блоггер Microsoft AI для RADACAD.
Распознаватель рукописного ввода в текст М. Мохсина
Лучшее приложение для распознавания рукописного текста и оптического распознавания символов.
Это абсолютно бесплатно для вас.
Вы можете писать от руки текстовые заметки, список или любую форму текста с бумаги до редактируемого текста на вашем устройстве всего одним щелчком мыши.
ОСОБЕННОСТИ:
– Поддерживает голландский, английский, французский, немецкий, итальянский, португальский и испанский языки.
– Поддержка смешанных или нескольких языков в одном образе.
Подпишитесь, чтобы получить неограниченный доступ к основным функциям приложения.
Стоимость подписки составляет 0,99 доллара США в месяц или 7,99 доллара США в год. Цены равны значению, которое «Матрица ценообразования Apple App Store» определяет как эквивалент цены подписки в долларах США.
Цены равны значению, которое «Матрица ценообразования Apple App Store» определяет как эквивалент цены подписки в долларах США.
– Все цены могут быть изменены без уведомления. Время от времени мы запускаем рекламные цены в качестве стимулов или ограниченных по времени возможностей для соответствующих покупок, сделанных в период действия рекламной акции. Из-за срочного и рекламного характера этих мероприятий мы не можем предложить защиту цен или ретроактивные скидки или возмещение за предыдущие покупки в случае снижения цены или рекламного предложения.
– Оплата будет снята с учетной записи iTunes при подтверждении покупки.
– Подписка автоматически продлевается с той же ценой и периодом действия, что и исходный пакет «1 месяц» / «1 год», если автоматическое продление не отключено по крайней мере через 24 часа. -часов до окончания текущего периода
– С аккаунта будет взиматься плата за продление в течение 24 часов до окончания текущего периода по стоимости выбранного пакета (еженедельный, ежемесячный или годовой пакет)
– Подписки может управляться пользователем, и автоматическое продление может быть отключено, перейдя в настройки учетной записи iTunes пользователя после покупки
– Отмена текущей подписки не допускается в течение активного периода подписки
– Вы можете отменить подписку во время ее бесплатный пробный период через настройку подписки через вашу учетную запись iTunes. Это необходимо сделать за 24 часа до окончания периода подписки, чтобы избежать списания средств. Посетите http://support.apple.com/kb/ht4098 для получения дополнительной информации.
Это необходимо сделать за 24 часа до окончания периода подписки, чтобы избежать списания средств. Посетите http://support.apple.com/kb/ht4098 для получения дополнительной информации.
– Вы можете отключить автоматическое продление подписки в настройках своей учетной записи iTunes. Однако вы не можете отменить текущую подписку в течение ее активного периода.
– Любая неиспользованная часть бесплатного пробного периода будет аннулирована, когда пользователь приобретет подписку на Handwriting Reader.
Условия использования, Политика конфиденциальности, Политика подписки:
https: // cruxsolution-Practice-project.firebaseapp.com/privacy.html
https://cruxsolution-practice-project.firebaseapp.com/tos.html
.