
Распознавание текста (OCR) | Полнотекстовое распознавание
Smart Document Engine
— российская система полнотекстового распознавания (OCR) для десктопных, серверных и мобильных платформ.Smart Document Engine OCR использует современные методы искусственного интеллекта для распознавания текста в потоке изображений (фотографии или сканы). Автоматически находит и распознает печатные и рукописные текстовые данные на 102 языках, включая русский, английский и другие языки с кириллическим и латинским алфавитом, армянский, греческий и др.
Разработанная учеными и инженерами нашей компании в рамках инициативы Green AI (“зеленого” искусственного интеллекта) технология оптического распознавания текста GreenOCR® обеспечивает непревзойденные качество и скорость распознавания текста при минимальном потреблении энергии и воздействии на окружающую среду. Скорость достигает до 15 страниц в секунду на сервере без применения GPU и полностью обрабатывает фотографию листа А4 за 3-4 секунды на смартфоне, сохраняя при этом высочайшую точность распознавания текстовых данных.
Smart Document Engine распознает текст, даже если документ до этого был сложен или помят. Другими словами, программа превращает смартфон в мгновенный сканер, полностью заменяя традиционные планшетные сканеры.
Легкая интеграция без нарушения привычных процессов
Smart Document Engine является уникальным инструментом, позволяющими гибко интегрировать полнотекстовое распознавание в текущую деятельность компании. Программа легко и удобно встраивается в уже существующие бизнес-процессы, не нарушая привычного опыта использования. Решение доступно для интеграции с различными информационными системами, например, ECM, CRM, RPA, АБС и т.д.
Для чего нужно полнотекстовое распознавание Smart Document Engine?
Полнотекстовое распознавание является ключевым элементом ввода документов в системах электронного документооборота, управления бизнес-процессами, электронных архивах и RPA-системах.
Высокая скорость и точность извлечения данных системой Smart Document Engine позволяет вывести автоматизацию процессов обработки документов на принципиально новый уровень. .
.
Как работает полнотекстовое распознавание
Исходное изображения | Визуализация найденных текстовых объектов | Результаты распознавания (по строкам) |
| 1: ДОВЕРЕННОСТЬ 2: НА ПОЛУЧЕНИЕ ДОКУМЕНТОВ 3: ДВАДЦАТЬ СЕДЬМОЕ МАРТА ДВЕ ТЫСЯЧИ СЕМНАДЦАТОГО ГОДА 4: ГОРОД САНКТ-ПЕТЕРБУРГ 5: Я, ГРАЖДАНКА РОССИЙСКОЙ ФЕДЕРАЦИИ, ИМЯРЕК АННА СЕРГЕЕВНА, ДАТА РОЖДЕНИЯ 6: 01.01.1991 Г., ПРОЖИВАЮЩАЯ ПО АДРЕСУ: 7: ПАСПОРТ 00 00 000000, ВЫДАН 2 АПРЕЛЯ 2012 ГОДА УФМС РОССИИ ПО АЛТАЙСКОМУ … |
Функциональные особенности
Smart Document Engine OCR
1Система позволяет делать опциональный предварительный поиск и ректификацию изображения документа на исходном изображении (фотографии, скане и т.д.)
2Помимо строковых результатов распознавания, система предоставляет координаты текстовых объектов на исходном изображении и оценки уверенности распознавания на уровне символов, слов или строк
3Система может быть использована для распознавания присутствующего текста как на изображении документа целиком, так и на изображениях отдельных фрагментов документа
4Не требуется связь со внешними сервисами или ресурсами, все вычисления производятся непосредственно на вызывающем устройстве. Smart Document Engine OCR может быть развернута на on-premise сервере, персональном компьютере, в рамках автономного мобильного приложения, а также в веб-приложении
Smart Document Engine OCR может быть развернута на on-premise сервере, персональном компьютере, в рамках автономного мобильного приложения, а также в веб-приложении
5Поддерживается распознавание входных изображений в форматах JPG, PNG, TIFF. Распознавание документов в PDF и других форматах выполняется после конвертации в один из поддерживаемых форматов растровых данных
6Существует возможность упаковки изображения в формат PDF/A с текстовой информацией
Конфиденциальность и безопасность
Программное обеспечение Smart Document Engine:
- НЕ использует код Open Source и иностранные программные компоненты, обеспечивая технологический суверенитет
- НЕ передает личные данные ваших клиентов на обработку в сторонние сервисы и/или третьим лицам для ручного ввода
- НЕ сохраняет данные: вся обработка ведется в локальной оперативной памяти устройства – 100% on-premise
- НЕ требует сетевого соединения
- НЕ использует технологии: HITL(human in the loop), CrowdSourcing, Mechanical Turk и аналоги, удаленных, облачных или внешних верификаторов
Преимущества полнотекстового
распознавания Smart Document Engine
Smart Document Engine — это запатентованная система полнотекстового распознавания. Искусственный интеллект (ИИ) автоматически обрабатывает и вводит текстовые данные документов с высокой скоростью и точностью.
Искусственный интеллект (ИИ) автоматически обрабатывает и вводит текстовые данные документов с высокой скоростью и точностью.
Только ИИ и ничего лишнего
ИИ работает автономно: без облачных решений (SaaS), операторов, Толоки и сторонних сервисов. Конфиденциально и безопасно. 100% on-device / on-premise
Точность распознавания данных
Никаких трат времени и средств на ошибки сотрудников с новейшим высокоточным GreenOCR®, разработанным учеными нашей российской компании
Скорость без аналогов в России
На 32-х ядерном HPC без применения GPU скорость полнотекстового распознавания достигает 15 страниц в секунду
Для множества платформ и ОС
Windows, Linux, Эльбрус, Альт Линукс, macOS, React Native, Flutter, 1C, Android, iOS, Salfish Mobile, Аврора, Комдив, Baikal и другие
100+ языков и считывание печатей
Распознает текстовые данные документов на 100+ языках, включая кириллицу, латиницу, армянский, арабский, персидский, урду, японский, китайский, корейский и другие
Не требует GPU и легко интегрируется
Программа (SDK) легковесна и не требует значительных вычислительных мощностей или больших объемов памяти. Легко интегрируется в уже существующие бизнес-процессы. Сотрудников не придется обучать навыкам работы с ПО.
Легко интегрируется в уже существующие бизнес-процессы. Сотрудников не придется обучать навыкам работы с ПО.
Комфортное использование
Устойчивость к перепаду освещения, ракурсу съемки и перекосам. Без прицеливания в рамку, подготовки качественного фото, картинки, изображения или другой предварительной подготовки документа к распознаванию
Как происходит интеграция полнотекстового распознавания Smart Document Engine
Программа Smart Document Engine поставляется для десктопных, серверных и мобильных приложений в виде автономного SDK (software development kit), содержащего все необходимые прекомпилированные библиотеки, документацию программного интерфейса и примеры интеграции для различных языков программирования.
Для разработчиков подготовлен простой, но многофункциональный API (application programming interface), который позволяет внедрить распознавание текста документов (OCR) в решения с использованием языков C++, C#, Java, Python и Objective-C для широкого круга операционных систем: iOS, Android, Linux, Windows, MacOS, в том числе Sailfish Mobile, МОС “Аврора”, ОС Эльбрус, РЕД ОС, Astra Linux, и другие. Обеспечивается поддержка следующих аппаратных платформ: x86_64, ARM v7, v8 (Aarch42, Aarch64), MIPS, Эльбрус. Имеется возможность настройки и подключения к популярным фреймворкам RPA и продуктам 1С по запросу.
Обеспечивается поддержка следующих аппаратных платформ: x86_64, ARM v7, v8 (Aarch42, Aarch64), MIPS, Эльбрус. Имеется возможность настройки и подключения к популярным фреймворкам RPA и продуктам 1С по запросу.
Больше возможностей в одной интеграции
При необходимости ввода документов, удостоверяющих личность, технология органично дополняется нашим продуктом Smart ID Engine, который с высочайшим качеством и скоростью распознает паспорта РФ и другие удостоверения личности.
Распознавание кодифицированных объектов, таких как банковские карты и баркоды, доступно за счет использования Smart Code Engine.
Важным аспектом Smart Document Engine является возможность создания специализированных решений для конкретных заказчиков, позволяющих производить автоматическую обработку, классификацию, распознавание и анализ бумажных документов, форм и отсканированных pdf (пдф) файлов любой сложности.
Заказные решения позволят вашей организации снизить издержки и нагрузку на персонал, внедрив высокоэффективное и высокоточное поточное сканирование и распознавание документации, оптимизированное под конкретный поток данных и под существующие бизнес-процессы, при этом исключив передачу каких-либо данных сторонним онлайн сервисам или третьим лицам.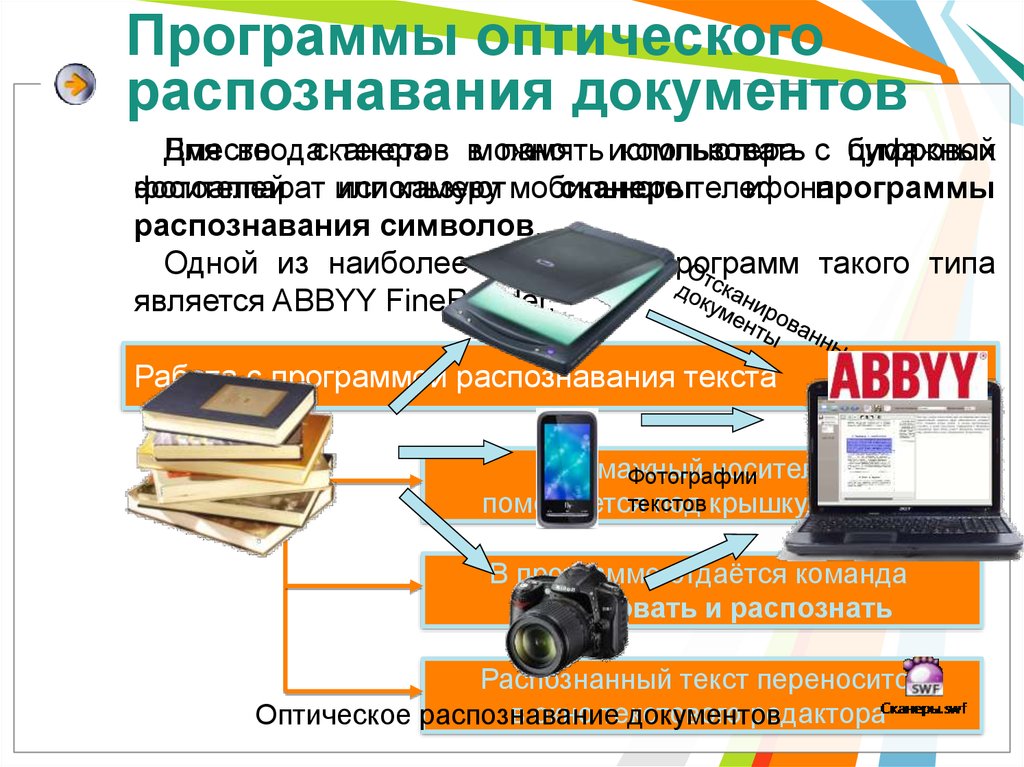
Наши клиенты
Тинькофф Банк
Smart Engines поставляет мобильные и серверные решения по распознаванию документов Тинькофф Банку
Альфа-Банк
Альфа-Банк распознает документы клиентов в мобильном приложении с помощью Smart ID Engine
Банк «Открытие»
Банк «Открытие» увеличит продажи кредитных продуктов за счет внедрения технологии распознавания документов Smart Engines на сайте
Газпромбанк
Газпромбанк внедрил решение Smart Engines на основе искусственного интеллекта для распознавания QR-кодов
Оптическое распознавание текста
Оптическое распознавание текстаВсе чаще встречаются ситуации, когда человек сталкивается с задачей перевода рукописей или напечатанных на бумаге текстов на цифровые носители.
Это делают и огромные корпорации, где архивы ценных бумаг нужно для надежности перевести в электронный вид, и маленькие, но стремительно развивающиеся компании, которые не желают отставать от современных тенденций.
И это логично, ведь в эпоху информационных технологий все процессы сводятся к обеспечению максимального комфорта и автоматизации, это касается и ведения документооборота. На замену монотонному многочасовому труду, когда приходилось вручную перепечатывать километры информации приходят технологии оптического распознавания текста (OCR).
Получить консультацию
Что это означает
OCR или Optical Character Recognition – это система оптического распознавания символов, с помощью которой происходит преобразование изображений, к примеру фотографий печатного текста, файлов в PDF-формате, а также отсканированных документов, в текстовые форматы с возможностью их дальнейшего редактирования и наличием в них поиска.
Как результат – можно справиться с различными задачами. Например, если на почту пришел договор, а его необходимо отредактировать или есть бумажная версия документа, статьи, рукописного заявления и т.д., которое легко можно отсканировать.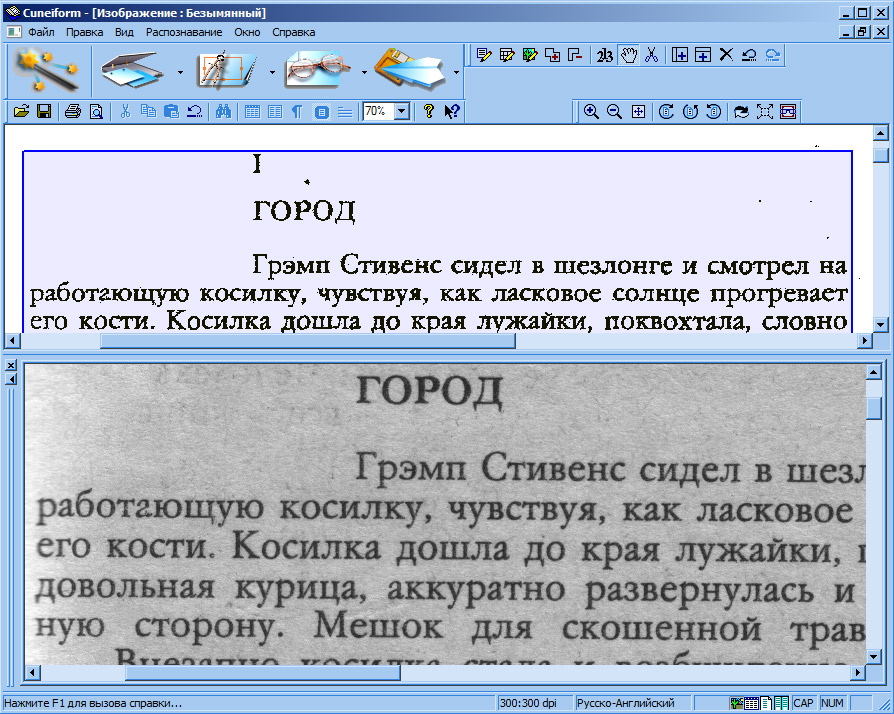 Но что делать дальше?
Но что делать дальше?
Используя различные программы по распознаванию текста, появляется возможность быстрого, а главное качественного их преобразования в редактируемые форматы, к примеру, doc или docx. Прибегая к такого рода услугам следует обращать внимание на многие факторы, которые могут сыграть ключевую роль при выборе компании, которая производит оптическое распознавание.
Что вы получите, обратившись в Биорг
Только высококачественную и квалифицированную помощь в оцифровке необходимых бумаг. Компания «Биорг» зарекомендовала себя как лидер в сфере сканирования и распознания документов. Работая с нами, клиенты получают весь спектр необходимых услуг, а также приятные бонусы:
- в работу принимаются бумаги с различной степенью тяжести распознавания текста, в том числе старые, ветхие или измятые;
- большой объем выполняемой работы – от 10 тысяч листов до 10 млн;
- возможность контролировать все этапы процесса, благодаря предоставлению отчетности;
- достоверность и сохранность данных – финансовая гарантия соответствия исходной и конечной информации;
- предварительная обработка и подготовка документов, а также сортировка цифрового варианта;
- работа с разными форматами: PDF, JPEG, RTF, TIFF, а также предоставление результата на различных электронных носителях;
Среди предоставляемых услуг стоит выделить:
- Сканирование, сортировка и обработка документовСистема дает возможность качественно и быстро обрабатывать заполненные от руки бумаги, такие как: бланки, анкеты, купоны маркетинговых акций и клубных программ, заявления, листы с опросами и бумаги с любыми личными данными.
 Результатом преобразования большого объема документов служит база данных с содержащимися документами и архив с полным объемом обработанных данных, в том числе с изображениями и базой.
Результатом преобразования большого объема документов служит база данных с содержащимися документами и архив с полным объемом обработанных данных, в том числе с изображениями и базой. - Архивная обработка документовПроцедура, в которой нуждаются многие компании и предприятия, ведь большие архивы в бумажном виде рано или поздно придется привести к цифровому формату. Среди вышеупомянутых документов могут быть: картотеки, книги, чертежи и графики, бухгалтерская и кадровая документация, а также архивные фонды и т.п. Подробнее об услуге обработки архивов.
- ПО БисканЭто уникальное комплексное программное обеспечение, которое использует систему оптического распознавания текста любого уровня сложности – от анкет или брошюр до рукописей и изображений. Подробнее о Бискане.
Получить презентацию
Какие трудности возникают при оцифровке
Системы оптического распознавания документов несовершенны и имеют ряд проблем.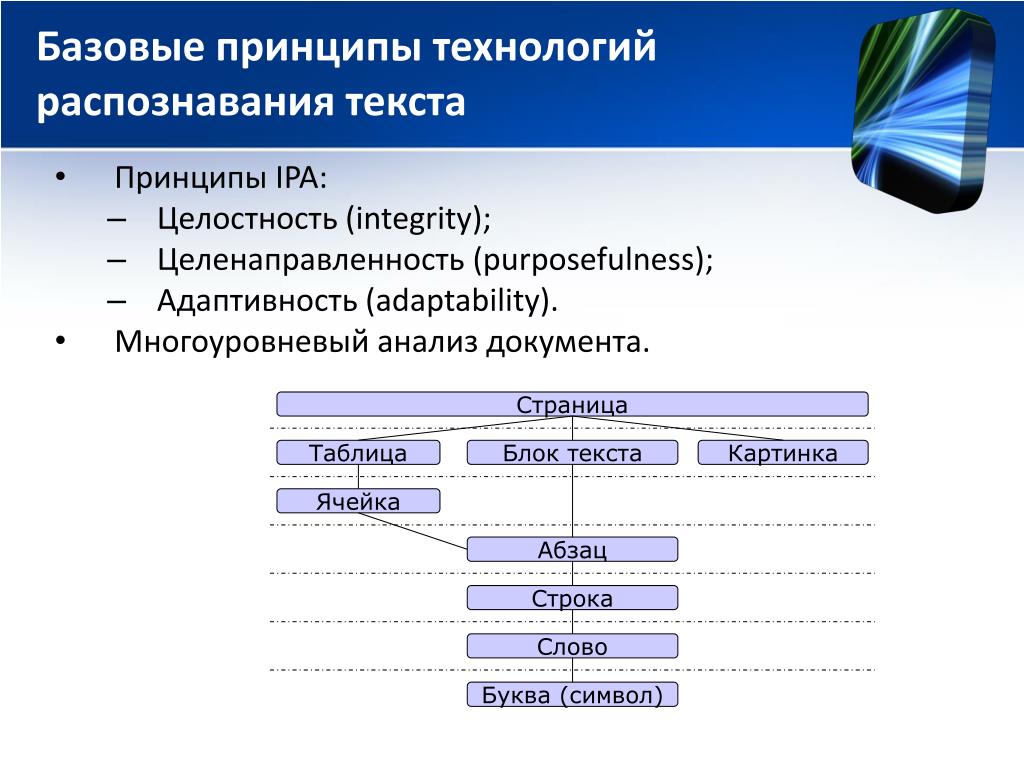 Самыми частыми становятся следующие:
Самыми частыми становятся следующие:
- Различные формы начертаний символов, это зависит от того, какой шрифт использовался в исходном документе.
- Искажение символа, которое может быть вызвано влиянием световых эффектов – теней, отражений, бликов. Часто при некачественной фотографии или плохо отсканированном документе происходит искажение наклона или мелких элементов символа.
- Проблема масштабирования символов связана с изменением размера исходного символа в результате сканирования или фотографии.
Для решения вышеупомянутых проблем OCR должна уметь выделять текстовые поля, в них – строки, а уже затем – конкретные символы, оставаясь при этом не чувствительной к их размеру, шрифту и прочим параметрам печати или почерка. Но компания «Биорг» использует в работе методы по улучшению распознавания, которые призваны свести к минимуму подобные погрешности.
Процедура работы системы оптического распознавания
Изначально необходимо получить изображение исходного документа в цифровом формате. Это может быть фотография или отсканированный документ.
Это может быть фотография или отсканированный документ.
OCR должна определить, какая структура характерна тексту: наличие абзацев, таблиц, колонок, изображений и т.д. Затем происходит разделение части текстовой области на отдельные символы.
В зависимости от качества исходного текста используются растровые или векторные методы распознания текста, при которых исходное изображение символа сравнивается с хранящимся в памяти растровым или векторным символом соответственно.
Результатом будет считаться символ, который в наибольшей степени совпадает с изображением из памяти устройства. Для каждого конкретного документа система распознания подбирает отдельный набор изображений для сравнивания. В случае анализа фотографии, перед основной процедурой необходимо также обработать фото на предмет устранения бликов от вспышки, плохой яркости, недостаточного контраста и прочих дефектов изображения.
При применении ПО Бискан используются технологии, точно распознающие даже устаревшие или нечеткие изображения и документы. Точность гарантирована и достигает 99.9% — не более 1 ошибки на 10 000 символов. А как приятное дополнение – это простота использования и удобный интерфейс, пользоваться которым можно без каких-либо дополнительных умений.
Точность гарантирована и достигает 99.9% — не более 1 ошибки на 10 000 символов. А как приятное дополнение – это простота использования и удобный интерфейс, пользоваться которым можно без каких-либо дополнительных умений.
Получить консультацию
- 30.10.2022 Оптическое распознавание текста
- 12.02.2021 Как автоматизировать рутину и обрабатывать паспорта с помощью ИИ
- 17.05.2019 Анализ цен конкурентов
- 30.01.2019 Программа лояльности от А до Я
- 23.01.2019 Обработка социологических анкет
- 09.01.2019 Хранение электронных документов
- 27.11.2018 Как проводить retail-аудит (аудит розничной торговли)
- 08.08.2018 Методы обработки результатов анкетирования
- 07.

- 09.01.2018 Оцифровка книг и документов в библиотеке
Получить консультацию
Работаем только с юридическими лицами
Соглашаюсь на обработку персональных данных
Получить презентацию
Работаем только с юридическими лицами
На указанный вами email мы автоматически пришлем презентацию.
Соглашаюсь на обработку персональных данных
Отправить пример файла
[contact-form-7 404 “Не найдено”]
Получить презентацию
[contact-form-7 404 “Не найдено”]
Отклик на вакансию
Соглашаюсь на обработку персональных данных
Обзор ИИ для документов | Google Cloud
Этот документ представляет собой руководство по основным концепциям использования Document AI.
Вам следует прочитать эту страницу, прежде чем переходить к любой другой документации или кратким руководствам.
Автоматизация рабочих процессов обработки документов
Компании во всем мире в значительной степени полагаются на документы для хранения и передачи информации. Эту информацию часто необходимо оцифровать, чтобы она стала полезной; однако, это обычно достигается с помощью трудоемких ручных процессов.
Например:
- Оцифровка книг для электронных книг
- Заполнение медицинских бланков в кабинетах врачей
- Представление отчетов о расходах на основании квитанций и счетов-фактур
- Аутентификация личности на основе удостоверений личности
- Утверждение кредитов на основании информации о доходах из налоговых форм
- Понимание контрактов по ключевым деловым соглашениям
Каждый из этих рабочих процессов включает в себя получение текста из документов, а затем понимание
как этот текст соответствует необходимым данным. Однако каждый тип документа имеет
различная структура и расположение, а самая важная информация может отличаться
в зависимости от конкретного варианта использования.
Компоненты ИИ документа
ИИ документа — это понимание документа платформа, которая берет неструктурированные данные из документов и преобразует их в структурированные данные, облегчающие понимание, анализ и использование.
Document AI использует машинное обучение и Google Cloud, чтобы помочь вам создавать масштабируемые комплексные облачные приложения для обработки документов.
Используя Document AI, вы можете:
- Предварительно обрабатывать документы с определением качества изображения и устранением искажений
- Извлечение текста и информации о макете из файлов документов
- Определение пар ключ-значение в структурированных формах
- Разделить и классифицировать документы по типу
- Извлечение и нормализация объектов
- Маркировка и просмотр документов
- Хранение, поиск, систематизация, управление и анализ документов и метаданных
На этой диаграмме показаны все основные этапы обработки документов, которые
поддерживаемые Document AI, и как они могут соединяться друг с другом.
Процессор
Процессор ИИ для документов — это интерфейс между файлом документа и моделью машинного обучения, который выполняет действия по обработке документа. Их можно использовать для классификации, разделения, разбора или анализа документа.
Каждый проект Google Cloud должен создавать собственные экземпляры процессора.
Процессоры относятся к одной из следующих категорий:
- Общие — Готовые процессоры для совместимости с большинством документов
- Специализированный — встроенные процессоры для определенных типов документов
- Закупки. Документы, используемые для покупок и платежей, такие как счета и квитанции
- Идентификация — документы, используемые для проверки личности
- Кредитование – Документы, используемые для ипотечных кредитов
- Контракт — Извлечение и понимание объектов из деловых контрактов
- Пользовательский — Пользовательские процессоры для пользовательских документов и вариантов использования
В каждой категории есть несколько типов процессоров. Каждый тип предназначен для определенной задачи, такой как
Оптическое распознавание символов (OCR),
разбор формы, разделение,
классификация
или извлечение объекта для определенных типов документов.
Каждый тип предназначен для определенной задачи, такой как
Оптическое распознавание символов (OCR),
разбор формы, разделение,
классификация
или извлечение объекта для определенных типов документов.
Обратитесь к полному процессору и подробному списку для получения информации обо всех доступные типы процессоров для Document AI.
Какой процессор следует использовать?
Чтобы решить, какой тип процессора использовать для конкретного приложения, воспользуйтесь некоторыми общими рекомендациями:
Примечание: Все процессоры могут извлекать текст и информацию о макете.| Пример использования | Тип процессора |
|---|---|
| Извлечение текста и информации о макете из документов | Документ OCR |
| Извлечение таблиц или пар ключ-значение из структурированной формы в документе | Анализатор форм |
| Анализ качества отсканированного изображения документа | Document OCR или Intelligent Document Quality |
| Разделение или классификация документов, которые имеют специализированный процессор разделения/классификатора | Специализированный процессор разделителя/классификатора, соответствующий типу документа |
| Извлечение объектов из документа, имеющего соответствующий специализированный процессор | Специализированный процессор, соответствующий типу документа. Используйте Uptraining для повышения точности или извлечения дополнительных сущностей Используйте Uptraining для повышения точности или извлечения дополнительных сущностей |
| Разделение документов без специального процессора разделения | Создание пользовательского разделителя документов |
| Классифицировать документы, не имеющие специализированного процессора-классификатора | Создание пользовательского классификатора документов |
| Извлечение объектов из пользовательского документа, который соответствует критериям пользовательского процессора | Создание пользовательского экстрактора документов |
| Извлечение объектов из пользовательского документа, который не соответствует критериям пользовательского процессора | Используйте распознавание документов для извлечения текста и создания модели AutoML для извлечения сущностей |
Эта диаграмма помогает определить, какой процессор лучше всего подходит для каждого варианта использования.
Использование процессоров Document AI
Ниже приведены основные шаги по использованию Document AI для начала обработки документов:
Выберите процессор , подходящий для вашего варианта использования.
Для получения полной информации о каждом процессоре см. Полный процессор и подробный список.
Создайте процессор с помощью облачной консоли или Document AI API.
Document AI создает конечную точку прогнозирования , куда вы можете отправлять свои документы.
Подробные инструкции см. в разделе Создание процессора
Отправьте документ(ы) на обработку.
Document AI обрабатывает документ(ы) и возвращает один или несколько объектов
Document, содержащих извлеченную структурированную информацию.Подробные инструкции см.
 в разделах Отправка запроса на обработку и Обработка ответа на обработку.
в разделах Отправка запроса на обработку и Обработка ответа на обработку.
- Human-in-the-Loop (HITL) — проверка и корректировка человеком для обеспечения точности данных, извлекаемых процессорами Document AI для использования в критически важных бизнес-приложениях.
- Enterprise Knowledge Graph — обогащение данных реальными сущностями и связями.
- Document AI Warehouse — хранение, поиск, систематизация, управление и анализ документов и их структурированных метаданных.
- Сопутствующие товары
Готовая модель ИИ для распознавания текста — AI Builder
Редактировать
Твиттер LinkedIn Фейсбук Электронная почта
- Статья
- 2 минуты на чтение
Готовая модель распознавания текста извлекает слова из документов и изображений в машиночитаемые потоки символов. Он использует современное оптическое распознавание символов (OCR) для обнаружения печатного и рукописного текста на изображениях.
Эта модель обрабатывает изображения и файлы документов для извлечения строк печатного или рукописного текста.
Использование в Power Apps
Готовая модель распознавания текста доступна в Power Apps с помощью компонента распознавания текста. Дополнительные сведения: Использование компонента распознавания текста в Power Apps
Использование в Power Automate
Сведения об использовании этой модели в Power Automate см. в статье Использование предварительно созданной модели распознавания текста в Power Automate.
Поддерживаемый язык, формат и размер
Файлы, которые можно сканировать с помощью модели распознавания текста, должны иметь следующие характеристики:
- Язык печатного текста : африкаанс, албанский, ангика (деванагири), арабский, астурийский, авадхи- Хинди (деванагири), азербайджанский (латиница), багели, баскский, белорусский (кириллица), белорусский (латиница), бходжпури-хинди (деванагири), бислама, бодо (деванагири), боснийский (латиница), браджбха, бретонский, болгарский, бундели , бурятский (кириллица), каталанский, кебуано, чамлинг, чаморро, чхаттисгархи (деванагири), китайский (упрощенный), китайский (традиционный), корнский, корсиканский, крымскотатарский (латиница), хорватский, чешский, датский, дари, дхимал (деванагири) ), догри (деванагири), голландский, английский, эрзянский (кириллица), эстонский, фарерский, фиджийский, филиппинский, финский, французский, фриульский, гагаузский (латиница), галисийский, немецкий, гильбертский, гонди (деванагири), гренландский, гурунг ( деванагири), гаитянский креольский, халби (деванагири), хани, харьянви, гавайский, хинди, хмонг дау (латиница), хо (деванагири), венгерский, исландский, инари-саамский, индонезийский, интерлингва, инуктитут (латиница), ирландский, итальянский, Японский, джаунсари (деванагири), яванский, кабувердиану, качинский (латиница), кангри (деванагири), карачаево-балкарский, каракалпакский (кириллица), каракалпакский (латиница), кашубский, казахский (кириллица), казахский (латиница) , халинг, хаси, киче’, корейский, корку, корякский, косраанский, кумыкский (кириллица), курдский (арабский), курдский (латиница), курух (деванагири), киргизский (кириллица), лакота, латинский, литовский, нижний сербский, луле-саамский, люксембургский, махасу-пахари (деванагири), малайский (латиница), мальтийский, мальто (деванагири), мэнский, маори, маратхи, монгольский (кириллица), черногорский (кириллица), черногорский (латиница), неаполитанский, непальский, ниуэйский, ногайский, северносаамский (латиница), норвежский, окситанский, осетинский, пушту, персидский, польский, португальский, пенджабский (арабский), прибрежный, румынский, ретороманский, русский, садри (деванагири), самоанский (латиница), санскрит (деванагари) ), сантали (деванагири), шотландский, шотландский гэльский, сербский (латиница), шерпа (деванагири), сирмаури (деванагири), скольт-саамский, словацкий, словенский, сомалийский (арабский), южносаамский, испанский, суахили (латиница), шведский , таджикский (кириллица), татарский (латиница), тетум, тхангми, тонганский, турецкий, туркменский (латиница), тувинский, верхнесербский, урду, уйгурский (арабский), узбекский (арабский), узбекский (кириллица), узбекский (латиница) , Volapük, Walser, Welsh, Western Frisian, Yucatec Maya, Zhuang, Zulu
- Язык для рукописного текста : английский, китайский (упрощенный), французский, немецкий, итальянский, японский, корейский, португальский, испанский
- Формат :
- JPG
- PNG
- БМП
- ПДФ
- Размер : не более 20 МБ
- Для документов PDF обрабатываются только первые 2000 страниц.
