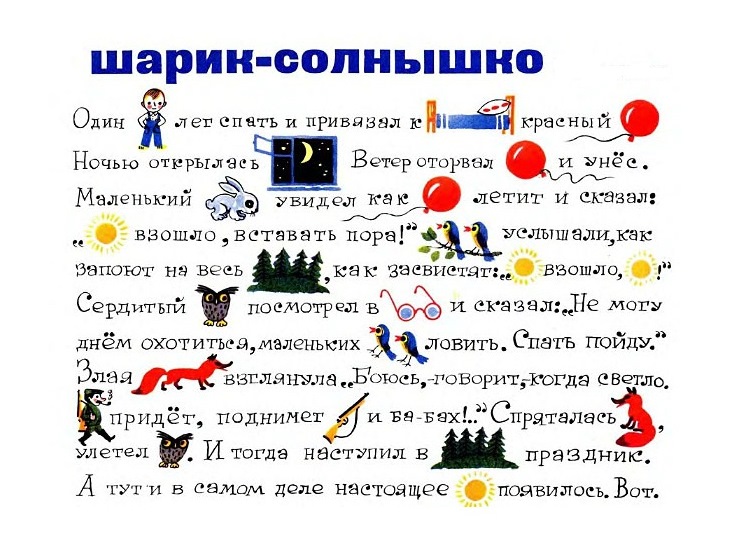
Получение данных с помощью OCR
Активити Считать текст OCR извлекает текст из элементов интерфейса при помощи OCR (оптического распознавания символов) и сохраняет его в контекстные переменные процесса.
При этом бот воспринимает область экрана как изображение, а затем использует инструменты для распознавания текста.
Рекомендуется использовать OCR в тех случаях, когда недоступны другие способы получения данных элемента интерфейса (например, при работе с RDP или с устаревшими программами). Этот метод более сложный, и распознавание требует больше времени. Результат зависит от качества распознаваемого изображения (от размера и типа шрифта, языка, контрастности и т. д.).
Настройки активити задаются автоматически во время записи процесса.
начало внимание
Работа с этой функцией доступна, только если в процессе создана хотя бы одна контекстная переменная.
конец внимание
- В режиме записи наведите курсор на область для распознавания и вызовите радиальное меню, нажав сочетание клавиш Ctrl+Alt+Q, заданное по умолчанию.
 Вы можете изменить это сочетание в настройках Дизайнера ELMA RPA. Подробнее о том, как это сделать, читайте в этой статье.
Вы можете изменить это сочетание в настройках Дизайнера ELMA RPA. Подробнее о том, как это сделать, читайте в этой статье.
 Вы можете изменить это сочетание в настройках Дизайнера ELMA RPA. Подробнее о том, как это сделать, читайте в этой статье.
Вы можете изменить это сочетание в настройках Дизайнера ELMA RPA. Подробнее о том, как это сделать, читайте в этой статье.- Выберите и выделите рамкой область экрана, содержащую текст, который требуется распознать. Можно выделить несколько областей для распознавания.
- Выберите контекстную переменную процесса, в которую будет сохранен распознанный текст. Вы можете добавить новую переменную, нажав Создать параметр. Чтобы отменить выделение, нажмите на .
- Теперь распознанный текст сохранен в указанной контекстной переменной и может быть отображен путем вставки значений переменных.
После сохранения процесса на графической модели добавится активити Считать текст OCR.
Вы можете изменить заданные настройки. Чтобы открыть окно настроек, нажмите на активити на графической модели процесса.
Вкладка «Параметры»
На вкладке Параметры отображаются основные параметры активити:
- Наименование — название активити на графической модели процесса. При добавлении активити его название задается по умолчанию. В этом поле название можно изменить.
Блок «Указатель»
- Редактировать области — здесь вы можете добавить новые области для распознавания текста. Для этого нажмите на скриншот. В открывшемся окне выделите рамочкой элемент интерфейса, из которого нужно извлечь текст, и укажите переменную, в которую текст будет сохранен. Вы можете выбрать ее из списка всех переменных процесса или добавить новую, нажав Создать параметр.
Чтобы удалить переменную, нажмите на значок .
Вы можете изменить масштаб изображения при помощи ползунка в левом верхнем углу.
Чтобы применить изменения, нажмите на кнопку Ок.
- Координаты — указывается контекстная переменная, в которую сохраняется распознанный текст и координаты заданных областей.
 Они определяют две точки: верхний левый (x, y) и нижний правый угол (x, y). Можно указать несколько областей. Чтобы удалить область для распознавания, нажмите на кнопку Удалить область. Вы можете выбрать переменную из списка или создать новую, нажав . Подробнее о создании контекстных переменных читайте в статье «Контекст процесса».
Они определяют две точки: верхний левый (x, y) и нижний правый угол (x, y). Можно указать несколько областей. Чтобы удалить область для распознавания, нажмите на кнопку Удалить область. Вы можете выбрать переменную из списка или создать новую, нажав . Подробнее о создании контекстных переменных читайте в статье «Контекст процесса».
Область для распознавания текста отображается на скриншоте.
- Метод поиска — выбор метода поиска для элемента, относительно которого рассчитываются области для распознавания.
Остальные настройки активити совпадают с настройками указателя и элемента управления. Подробнее о них читайте в статье «Общие принципы настройки активити».
Вкладка «Обработчики»
О вкладке Обработчики можно прочитать в статье «Общие принципы настройки активити».
get-text. html
get-folder-files.html
html
get-folder-files.html
Была ли статья полезной?
ДаНет
Выберите вариантРекомендации не помоглиТекст трудно понятьНет ответа на мой вопросСодержание статьи не соответствует заголовкуДругая причинаНашли опечатку? Выделите текст, нажмите ctrl + enter и оповестите нас
Сканер текста документа : OCR
Описание
 Превращает ваш мобильный телефон в сканер текста
Превращает ваш мобильный телефон в сканер текстаОптическое распознавание символов (OCR) позволяет обнаруживать текст на изображениях и в документе с любым количеством страниц, а также автоматически определять язык. конвертер документов и изображений в текст поддерживает широкий набор языков для автоматического распознавания любого языка
В повседневной офисной и рабочей жизни мы часто чувствуем потребность в приложении для преобразования изображений в текст, и это потому, что AsyncByte предоставил вам свое приложение для преобразования документов и изображений в текст и приложение OCR Scanner для пользователей iOS. Это приложение может быть полезно всякий раз, когда вам нужно преобразовать изображение в текст, и оно может значительно сэкономить ваши усилия при вводе текста. Нет необходимости вводить вручную. он автоматически извлечет текст из всего вашего документа и сохранит его на вашем телефоне. Он автоматически идентифицирует номер телефона, адрес электронной почты и URL-адреса из извлеченного текста.
У вас есть задание, в котором у вас есть много книг и статей с текстом, который вам нужно написать? Не тратьте время на написание, вместо этого используйте этот документ и приложение-сканер OCR и конвертер изображений в текст для преобразования изображения в текст. Да, вы правильно прочитали! Вы можете преобразовать изображение в текст без ввода. Все, что вам нужно сделать, это загрузить это приложение Document & image to text OCR Scanner, а затем вы можете использовать это приложение в качестве средства чтения текста из изображений и изображений.
Уникальными функциями сканера и конвертера документов и фотографий в текст являются:
У них нет ограничений на количество страниц в документе
• Сканирование напрямую с помощью камеры
Выберите изображения из галереи
• Извлечь текст на изображении
• Позволяет выбрать определенную область изображения для сканирования текста.
• Прочтите отсканированный текст с изображения
• Скопируйте текст в буфер обмена, чтобы использовать где угодно
следите за тем, что вы сканируете
Распознанный текст, можно выполнить следующую операцию
– Доступ по URL
– Телефонный разговор
– Скопировать в буфер обмена
– Календарное событие
– Номер отслеживания отгрузки
– Номер рейса
•.

Используйте опцию Intelligent Select Area, которая позволяет вам выбрать область изображения, содержащую как текст, так и графику, и интеллектуально извлечь текст.
Это приложение для преобразования изображения в текст также имеет дополнительную функцию, например, Speech Engine, а это означает, что вы можете не только извлекать текст из изображения, но и попросить приложение прочитать текст на изображении. Другими словами, это приложение-сканер OCR – это приложение для преобразования изображения в текст в речь. вы можете распознать человеческий почерк в дополнение к тексту, напечатанному машиной.
Вы можете преобразовать картинку в текст, который сохраняется в вашей медиа-библиотеке, или вы можете использовать эту программу для чтения текста непосредственно с помощью камеры. Откройте документ и изображение в приложение сканера OCR, откройте камеру и выберите текстовую область, а затем это приложение преобразует изображение в слово или текст.
Версия 1.11
*improvement in scanning text on images and pdf
Оценки и отзывы
Оценок: 36
Огонь!
Отличное приложение, которое помогло быстро конвертировать очень большое документ из пдф в текст!
Приложение пря супер 😍👍
Советую 💪🏽😍быстрее копирует
Классное приложение.
Приложение просто супер! За пару минут текст с фото переводится в формат редактируемого текста.
Ошибок не нашла. Прямо очень советуют.
Разработчик Muhammad Shahid указал, что в соответствии с политикой конфиденциальности приложения данные могут обрабатываться так, как описано ниже. Подробные сведения доступны в политике конфиденциальности разработчика.
Данные, используемые для отслеживания информации
Следующие данные могут использоваться для отслеживания информации о пользователе в приложениях и на сайтах, принадлежащих другим компаниям:
Не связанные с пользователем данные
Может вестись сбор следующих данных, которые не связаны с личностью пользователя:
- Идентификаторы
- Данные об использовании
- Диагностика
Конфиденциальные данные могут использоваться по-разному в зависимости от вашего возраста, задействованных функций или других факторов. Подробнее
Подробнее
Информация
- Провайдер
- Muhammad Shahid
- Размер
- 43,9 МБ
- Категория
- Производительность
- Возраст
- 4+
- Copyright
- © AsyncByte 2020
- Цена
- Бесплатно
- Сайт разработчика
- Поддержка приложения
- Политика конфиденциальности
Другие приложения этого разработчика
Вам может понравиться
Извлечение текста из изображений с помощью PyTesseract | Программа инженерного образования (EngEd)
Как разработчик, вы можете захотеть извлечь текстовую информацию из изображения. Используя Python, мы можем создать программу, которая извлекает такие текстовые данные из любого заданного изображения.
Используя Python, мы можем создать программу, которая извлекает такие текстовые данные из любого заданного изображения.
Python — один из самых популярных языков, с которым любят работать разработчики. Его удобочитаемый синтаксис облегчает изучение.
В этом руководстве мы напишем скрипт Python, который извлекает изображения, сканирует текст, расшифровывает его и сохраняет в текстовый файл. Мы будем использовать библиотеку Python tesseract для распознавания текстовых данных из изображений.
Содержание
- Содержание
- Предпосылки
- Настройка распознавания текста тессеракт
- Добавление зависимостей проекта
- Питессеракт
- ПиМуPDF
- Подушка
- OpenCV-питон
- Создайте сценарий тессеракта Python
- Извлечение изображений
- Извлечь текстовую информацию
- Протестируйте приложение
- Заключение
Предпосылки
Чтобы следовать этой статье, убедитесь, что на вашем компьютере установлен и запущен Python.
Также убедитесь, что у вас есть базовые знания Python.
Настройка OCR tesseract
Оптическое распознавание символов (OCR) — это технология, которая используется для распознавания текста на изображениях. Его можно использовать для преобразования компактных рукописных или печатных текстов в машиночитаемые тексты.
Чтобы использовать OCR, вам необходимо установить и настроить tesseract на вашем компьютере.
Сначала загрузите исполняемые файлы Tesseract OCR здесь. При установке этого исполняемого файла убедитесь, что вы скопировали путь установки tesseract и добавили его в переменные системной среды.
После завершения процесса запустите команду tesseract -v , чтобы убедиться, что OCR установлен.
Чтобы проверить, работает ли эта среда, вы можете запустить OCR на любом изображении и посмотреть, извлекаются ли текстовые данные и сохраняются ли они в читаемом текстовом файле.
Для этого убедитесь, что у вас есть изображение с текстовой информацией. Используйте командную строку, чтобы перейти к расположению изображения, и выполните следующую команду
Используйте командную строку, чтобы перейти к расположению изображения, и выполните следующую команду tesseract :
tesseract
В этом случае вы должны указать имя изображения и имя файла. При выполнении команды будет создан и сохранен в той же папке файл .txt .
Это подтверждает, что библиотека tesseract успешно установлена. Теперь мы можем приступить к реализации того же самого с помощью скрипта Python.
Добавление зависимостей проекта
Нам нужно установить несколько зависимых библиотек, чтобы помочь нам начать работу со сценарием Python.
Pytesseract
Python-tesseract — это библиотека OCR, которая используется для сканирования и расшифровки любых текстовых данных в изображениях. Эта библиотека используется для распознавания текстовой информации, но не для ее сохранения в какой-либо текстовый документ.
Чтобы установить pytesseract , выполните следующую команду:
pip install pytesseract
PyMuPDF
PyMuPDF — это библиотека Python, которая используется для доступа к файловым документам и изображениям, таким как PDF-файлы.
В этом приложении PyMuPDF будет читать PDF-документы и проверять наличие сохраненных изображений. PyMuPDF преобразует файлы PDF в форматы PNG, сканирует любой текст и, наконец, извлекает текст из визуализированных изображений PNG.
Чтобы установить PyMuPDF , выполните следующую команду:
pip install PyMuPDF
Pillow
Библиотека Pillow действует как интерпретатор изображений со всеми возможностями обработки изображений.
Чтобы установить подушку, выполните следующую команду:
pip install Pillow
Opencv-python
Opencv-python используется для чтения изображений и видео, управления медиафайлами с помощью преобразований изображений, рисования фигур и помещения текста в эти файлы.
Мы будем использовать OpenCV для распознавания текстов из медиафайлов (изображений).
Чтобы установить opencv-python, выполните следующую команду:
pip install opencv-python
Создание сценария тессеракта Python
Создайте папку проекта и добавьте в нее новый файл main.. py
py
Во-первых, нам нужно импортировать эти библиотеки, которые мы установили. Добавьте следующий импорт в файл main.py :
import os # from native modules импортировать fitz # из PyMuPDF импортировать pytesseract # из pytesseract импортировать cv2 # из Opencv import io # из нативных модулей из PIL импортировать изображение, ImageFile # из Pillow from colorama import Fore # из нативных модулей импортировать платформу # из нативных модулей
Затем разрешите этому приложению обрабатывать файлы изображений:
ImageFile.LOAD_TRUNCATED_IMAGES = True
Как только приложение предоставит доступ к файлам PDF, его содержимое будет извлечено в виде изображений. Затем эти изображения будут обработаны для извлечения текста.
В этом случае нам нужно создать несколько глобальных переменных, которые помогут создавать и сохранять эти изображения в пути проекта. Мы также указываем путь для сохранения извлеченного текста в файл .. txt
txt
Добавьте эти глобальные переменные, как показано ниже:
# Глобальные переменные
strPDF, textScanned, textScanned, inputTeEx, dirName = "", "", "", "", [
"изображения", "output_txt"]
Это создаст каталог images , в котором будут сохранены изображения, извлеченные из PDF. Будет создан каталог output_txt для сохранения отсканированной текстовой информации в виде файла .txt .
Теперь давайте создадим метод, который поможет нам получить доступ к установленной библиотеке tesseract и необходимым файлам. Мы сделаем это под gInUs() функция как показано:
def gInUs():
# Глобальная переменная
глобальный стрPDF
глобальный вводTeEx
если (платформа.система() == "Windows"):
# Распечатать ввод
печать (Fore.ЖЕЛТЫЙ +
"[.] Добавить локальный путь tesseract.exe" + Fore.RESET)
вводTeEx = ввод()
# Распечатать ввод
print(Fore. GREEN + "[!] Добавить локальный путь к файлу PDF:" + Fore.RESET)
вводПользователь = ввод()
# Распечатать предупреждение, если ввод недействителен, если нет, вызвать fun reDoc
если (inputUser == "" или len (inputUser.split ("\\")) == 1):
print(Fore.RED + "[X] Пожалуйста, введите действительный ПУТЬ к файлу" + Fore.RESET)
еще:
extIm (входной пользователь)
GREEN + "[!] Добавить локальный путь к файлу PDF:" + Fore.RESET)
вводПользователь = ввод()
# Распечатать предупреждение, если ввод недействителен, если нет, вызвать fun reDoc
если (inputUser == "" или len (inputUser.split ("\\")) == 1):
print(Fore.RED + "[X] Пожалуйста, введите действительный ПУТЬ к файлу" + Fore.RESET)
еще:
extIm (входной пользователь)
Из приведенного выше кода:
-
«[.] Добавить локальный путь к tesseract.exe»— это помогает нам получить доступ к библиотеке tesseract. -
"[!] Добавьте локальный путь к файлу PDF:"– это поможет нам получить доступ к локальному файлу PDF, который мы хотим использовать.
После того, как мы введем этот путь, нам нужно сначала проверить правильность пути к файлу. Если путь неверный, приложение отобразит сообщение об ошибке Пожалуйста, введите действительный ПУТЬ к файлу . Если путь правильный, приложение извлечет текст из изображений, выполнив метод extIm() .
Как только мы получим правильный путь к файлу PDF, нам нужно запустить файл и извлечь текст в файл .txt .
Сначала нам нужно открыть текстовый файл и прочитать его содержимое. Для этого мы будем использовать модуль fitz , как показано ниже:
# Извлечение изображений
определение extIm (fileStr):
# открыть файл
pdf_file = fitz.open(fileStr)
Мы создаем путь для сохранения изображений, которые мы извлекаем из файла:
global dirName
# Создать выходную папку, если она не существует
для я в dirName:
пытаться:
ос.македирс(я)
print(Fore.GREEN + "[!] Directory", i, "Created" + Fore.RESET)
кроме FileExistsError:
print(Fore.RED + "Каталог [X] ", i,
"уже существует" + Fore.RESET)
контент = os.listdir("изображения")
Нам нужно проверить, есть ли в папке изображения. Если да, перечислите их и распечатайте содержимое каждого изображения, как показано:
# Перечислите изображения, если они существуют, и распечатайте каждое из них.если не извлечь все изображения если (длина (содержание) >= 1): # Распечатать каждое изображение в содержании для я по содержанию: print(Fore.YELLOW + f"Это изображение: {i}" + Fore.RESET) еще: # Итерация по страницам PDF для page_index в диапазоне (len (pdf_file)): # получить саму страницу страница = pdf_файл[страница_индекс] image_list = page.getImageList()
Если в папке нет доступных изображений, мы перебираем файлы PDF и извлекаем их содержимое.
Давайте напечатаем количество изображений, которые мы извлекли, и отобразим сообщение об ошибке, если изображение не найдено в папке:
# печать количества изображений, найденных на этой странице
если image_list:
Распечатать(
Fore.GREEN + f"[+] Всего найдено {len(image_list)} изображений на странице {page_index}" + Fore.RESET)
еще:
print(Fore.RED + "[!] На странице не найдено изображений",
page_index, Fore.RESET)
В цикле мы присваиваем имя каждому изображению, сгенерированному из PDF. Здесь мы добавим количество изображений к строке
Здесь мы добавим количество изображений к строке image . Например, image2_1 :
для (image_index, img) в enumerate(page.getImageList(), start=1):
# получить XREF изображения
внешняя ссылка = изображение [0]
# извлечь байты изображения
base_image = pdf_file.extractImage(xref)
image_bytes = базовое_изображение["изображение"]
# получить расширение изображения
image_ext = базовое_изображение["расширение"]
# загрузить его в PIL
изображение = Image.open(io.BytesIO(image_bytes))
# сохраняем на локальный диск
изображение.сохранить(
open(f"images/image{page_index+1}_{image_index}.{image_ext}", "wb"))
reImg()
Здесь мы выполняем функцию reImg() для рендеринга этих изображений и извлечения их содержимого. Давайте сделаем это на следующем шаге.
Давайте создадим функцию с именем reImg() для хранения этих глобальных переменных:
def reImg():
# Глобальная переменная
глобальный текст отсканирован
глобальное имя_каталога
глобальный вводTeEx
На этом этапе нам потребуется доступ к файлу tesseract.. Для этого мы используем глобальную переменную  exe
exe inputTeEx , где мы принимаем путь к файлу от пользователя:
pytesseract.pytesseract.tesseract_cmd = f"{inputTeEx}"
Python будет использовать модуль pytesseract для доступа к tesseract через cmd .
Нам нужно перебрать все извлеченные изображения и прочитать их содержимое, чтобы извлечь текстовую информацию, как показано:
# Список изображений
контент = os.listdir('изображения')
для i в диапазоне (len (содержание)):
# Чтение каждого изображения в изображениях
изображение = cv2.imread(f'images/{content[i]}')
# Сканировать текст с изображения
print(Fore.YELLOW + f"[.] Сканировать текст из {content[i]}" + Fore.RESET)
текст = pytesseract.image_to_string (изображение, язык = 'спа')
# Объединить отсканированный текст в строку
textScanned += текст
# Распечатать
print(Fore.GREEN + "[!] Законченный отсканированный текст" + Fore. RESET)
# Отображение ввода img
cv2.imshow('Изображение', изображение)
# 0,5 миллисекунды
cv2.waitKey(1000)
RESET)
# Отображение ввода img
cv2.imshow('Изображение', изображение)
# 0,5 миллисекунды
cv2.waitKey(1000)
# Создать и записать файл txtResult.txt
print(Fore.CYAN + "[.] Запись txtResult.txt" + Fore.RESET)
fileTxt = открыть (f"{dirName[1]}/txtResult.txt", "w")
fileTxt.write(textScanned)
print(Fore.GREEN + "[!] File Writted" + Fore.RESET)
Наконец, вызовите функцию gInUs() для выполнения программы:
# Вызов основной функции гИнУс()
Тестирование приложения
Чтобы протестировать приложение, запустите python main.py .
Сначала укажите путь тессеракта и нажмите Enter:
> [!] Добавить локальный путь tesseract.exe
После того, как вы нажмете Enter, вам будет предложено добавить путь к файлу PDF:
> [!] Добавить локальный путь к файлу PDF
При выполнении программа создает папку output_txt для сохранения извлеченной текстовой информации в файлах .. txt
txt
Заключение
В этом руководстве мы создали сценарий Python, который извлекает текстовую информацию из изображений путем сканирования, расшифровки и сохранения в текстовый файл. Вы можете получить код, используемый в этом руководстве, на GitHub.
Надеюсь, этот урок был вам полезен.
Хлоп 👏 Если вам поможет эта статья.
Рецензирование Вклад: Сришилеш П.С.
Как написать замещающий текст и описания изображений для слабовидящих
Если кто-то зайдет на ваш сайт или в профиль с закрытыми глазами, сможет ли он найти дорогу? По мере того как все больше и больше людей страдают нарушениями зрения, они обращаются к вспомогательным технологиям, чтобы получить доступ к контенту. Подробнее об этом читайте в моем посте, посвященном Всемирному дню зрения 2017 года, здесь. Добавление замещающего текста и описаний изображений снимает барьеры, и больше людей могут получить доступ к вашему контенту. Читайте дальше, чтобы узнать больше о том, как создавать замещающий текст и описания изображений.
Что такое альтернативный текст?
Альтернативный текст сообщает людям, что находится на изображении, например, текст или основные важные детали. Если изображение не загружается, на его месте будет отображаться замещающий текст. Поисковые системы также индексируют замещающий текст и учитывают его при определении рейтинга в поисковых системах.
Что такое описание изображения?
Описание изображения дает больше деталей, чем замещающий текст, и позволяет узнать больше о том, что находится на изображении, помимо замещающего текста. Замещающий текст предоставляет пользователю наиболее важную информацию, а описания изображений содержат дополнительные сведения. Например, альтернативный текст говорит кому-то, что на полу лужа, а описание изображения говорит кому-то, что лужа на полу находится посреди пола и это апельсиновый сок.
Как это помогает людям с нарушениями зрения
Люди с нарушениями зрения, такими как слабовидящие и слепые, могут использовать программы чтения с экрана для доступа к Интернету или просто иметь проблемы с различением изображений. Программа чтения с экрана будет читать замещающий текст вслух, а также описания изображений, в зависимости от того, какие настройки включены пользователем. Замещающий текст и описания изображений могут содержать важную информацию, такую как текст, ссылки и сведения об изображениях.
Программа чтения с экрана будет читать замещающий текст вслух, а также описания изображений, в зависимости от того, какие настройки включены пользователем. Замещающий текст и описания изображений могут содержать важную информацию, такую как текст, ссылки и сведения об изображениях.
Длина текста
Изображение может стоить тысячи слов, но нет причин записывать их все и заставлять пользователя ждать окончания описания. Настоятельно рекомендуется, чтобы длина замещающего текста не превышала 125 символов, чтобы обеспечить совместимость с популярными программами чтения с экрана. Описания изображений могут быть длиннее, но я рекомендую придерживаться длины твита или около 280 символов. Говоря о Твиттере, прочитайте мою публикацию в аккаунтах Твиттера для слабовидящих, чтобы подписаться здесь, и подпишитесь на меня в Твиттере @veron4ica здесь.
Напишите текст на изображении
Если изображение содержит текст, обязательно запишите текст изображения дословно в качестве замещающего текста. Используйте правильную орфографию, использование заглавных букв, интервалы и грамматику — если кто-то прикрепляет изображение к Pinterest, альтернативный текст — это то, что будет отображаться в качестве описания изображения. Альтернативный текст также полезен для изображений с декоративным текстом, который может быть трудно увидеть, например подпись или логотип.
Используйте правильную орфографию, использование заглавных букв, интервалы и грамматику — если кто-то прикрепляет изображение к Pinterest, альтернативный текст — это то, что будет отображаться в качестве описания изображения. Альтернативный текст также полезен для изображений с декоративным текстом, который может быть трудно увидеть, например подпись или логотип.
Особенности изображения для описания
При составлении описания изображения может показаться сложным решить, что включить. Вот функции, которые могут быть включены в описания изображений — напишите о них, если применимо:
- Размещение объектов на изображении
- Стиль изображения (живопись, графика)
- Цвета
- Имена людей
- Одежда (если она является важной деталью)
- Животные
- Размещение текста
- Эмоции, такие как улыбка
- Окрестности
Что не описывать
Кроме того, есть некоторые вещи, которые следует исключить из описания изображений. К ним относятся:
К ним относятся:
- Описание цветов – не нужно описывать, как выглядит красный
- Очевидные детали, такие как наличие у кого-то двух глаз, носа и рта
- Детали, которые не в центре внимания картины
- Чрезмерно поэтические или подробные описания
- Смайлик
- Несколько знаков препинания
Я рассказываю о некоторых из этих деталей в своем посте об этикете текстовых сообщений и плохом зрении здесь.
Примечание об автоматическом альтернативном тексте
Автоматический замещающий текст интегрируется в различные веб-сайты. Хотя это замечательная функция, она не всегда самая точная. Например, автоматический альтернативный текст однажды интерпретировал изображение моего брата, стоящего снаружи, как изображение автомобиля. Никогда не помешает перепроверить замещающий текст и убедиться, что и компьютер, и люди согласны с тем, что изображено на картинке.
Использование замещающего текста null
Бывают случаи, когда использование замещающего текста или описаний изображений бессмысленно.