
Распознавание текста на картинке с помощью tesseract на Kotlin / Хабр
Ни для кого не секрет, что Python прочно занял первенство в ML и Data Science. А что если посмотреть на другие языки и платформы? Насколько в них удобно делать аналогичные решения?
К примеру, распознавание текста на картинке.
Среди текущих решений одним из наиболее распространённым инструментом является tesseract. В Python для него существует удобная библиотека, а для первоначальной обработки изображений, как правило, используется OpenCV. Для обоих этих инструментов есть исходные C++ библиотеки, поэтому их также возможно вызывать и из других экосистем. Попробуем это сделать в jvm и, в частности, на Kotlin.
Несколько слов о Kotlin. У него есть много удобных вещей для Data Science. В совокупности с экосистемой jvm получается «статически типизированный Python на jvm». А не так давно ещё появилась возможность использовать Kotlin вместе с Apache Spark.
Первым делом установим tesseract. Его нужно установить отдельно на систему, согласно описанию из wiki. После установки можно проверить, что tesseract работает следующим образом:
Его нужно установить отдельно на систему, согласно описанию из wiki. После установки можно проверить, что tesseract работает следующим образом:
tesseract input_file.jpg stdout -l eng --tessdata-dir /usr/local/share/tessdata/
Где –tessdata-dir — путь до файлов tesseract (/usr/local/share/tessdata/ в macos). В случае успешной установки в stdout будет выведен распознанные текст.
После этого можно подключить tesseract в jvm и сравнить результат работы с нативным вызовом. Для этого подключим библиотеку:
implementation("net.sourceforge.tess4j:tess4j:4.5.3")Для тех, кто не очень хорошо знаком с экосистемой jvm, есть лёгкий способ быстро себе всё настроить. Понадобится только установленная Java 13+. Её проще всего поставить через sdkman. Далее для удобства можно скачать Intellij IDEA, подойдёт и Community version. Основу проекта можно создать из IDE (new project -> Kotlin, gradle Kotlin) или можно клонировать репозиторий github, в котором перейти на ветку start.

После подключения библиотеки доступ к tesseract становится простым. Вызов той же команды из примера выше будет выглядеть следующим образом:
val api = Tesseract()
api.setDatapath("/usr/local/share/tessdata/")
api.setLanguage("eng")
val image = ImageIO.read(File("input_file.jpg"))
val result: String = api.doOCR(image)Как видно, практически все команды совпадают с используемыми в вызове из командной строки. Но, как минимум, на macos нужно ещё дополнительно настроить системную переменную
val libPath = "/usr/local/lib"
val libTess = File(libPath, "libtesseract.dylib")
if (libTess.exists()) {
val jnaLibPath = System.getProperty("jna.library.path")
if (jnaLibPath == null) {
System.setProperty("jna.library.path", libPath)
} else {
System.setProperty("jna.library.path", libPath + File.pathSeparator + jnaLibPath)
}
}После всех настроек можно попробовать запустить распознавание для того же файла и результат должен полностью соответствовать вызову из командной строки.
Перейдём теперь к обработке изображений с OpenCV. В Python для работы с ней не требуется ставить каких-либо дополнительных инструментов, кроме пакета в pip. В описании OpenCV под java указан порядок установки, когда всё ставится отдельно. Для самой jvm-экосистемы подход, когда требуются установки каких-либо нативных библиотек, не совсем привычен. Чаще всего если зависимости требуется какие-либо дополнительные библиотеки, то либо она сама их скачивает (как, например, djl-pytorch), либо при подключении через систему сборки внутри себя уже содержит библиотеки под различные операционные системы. К счастью, для OpenCV есть такая сборка, которой и воспользуемся:
implementation("org.openpnp:opencv:4.3.0-2")Перед началом работы с OpenCV потребуется подгрузить нативные библиотеки через:
nu.pattern.OpenCV.loadLocally()
После чего можно использовать все доступные инструменты. Как, например, конвертация изображения в чёрно-белый цвет:
Imgproc.cvtColor(mat, mat, Imgproc.COLOR_BGR2GRAY)
 COLOR_BGR2GRAY)
COLOR_BGR2GRAY)Как вы уже обратили внимание, аргументом для OpenCV выступает Mat, который представляет из себя основной класс-обёртку вокруг изображения в OpenCV в jvm, похожий на привычный BufferedImage.
Сам экземпляр Mat можно получить привычным для Python кода вызовом imread:
val mat = Imgcodecs.imread("input.jpg")В таком виде экземпляр можно дальше передавать в OpenCV и проделывать с ним различные манипуляции. Но для Java общепринятым является BufferedImage, вокруг которого, как правило, уже может быть выстроен pipeline загрузки и обработки изображения. В связи с чем возникает необходимость конвертации BufferedImage в Mat:
val image: BufferedImage = ...
val pixels = (image.raster.dataBuffer as DataBufferByte).data
val mat = Mat(image.height, image.width, CvType.CV_8UC3)
.apply { put(0, 0, pixels) }И обратной конвертации Mat в BufferedImage:
val mat = ... var type = BufferedImage.TYPE_BYTE_GRAY if (mat.
 channels() > 1) {
type = BufferedImage.TYPE_3BYTE_BGR
}
val bufferSize = mat.channels() * mat.cols() * mat.rows()
val b = ByteArray(bufferSize)
mat[0, 0, b] // get all the pixels
val image = BufferedImage(mat.cols(), mat.rows(), type)
val targetPixels = (image.raster.dataBuffer as DataBufferByte).data
System.arraycopy(b, 0, targetPixels, 0, b.size)
channels() > 1) {
type = BufferedImage.TYPE_3BYTE_BGR
}
val bufferSize = mat.channels() * mat.cols() * mat.rows()
val b = ByteArray(bufferSize)
mat[0, 0, b] // get all the pixels
val image = BufferedImage(mat.cols(), mat.rows(), type)
val targetPixels = (image.raster.dataBuffer as DataBufferByte).data
System.arraycopy(b, 0, targetPixels, 0, b.size)В частности, тот же tesseract в методе doOCR поддерживает как файл, так и BufferedImage. Используя вышеописанные преобразования, можно вначале обработать изображения с помощью OpenCV, преобразовать Mat в Bufferedimage и передать подготовленное изображение на вход tesseract.
Попробуем теперь на практике собрать рабочий вариант приложения, который сможет найти текст на следующей картинке:
Для начала проверим результат нахождения текста на изображении без обработки. И вместо метода doOCR будем использовать getWords, чтобы получить ещё confidence (score в Python-библиотеке) для каждого найденного слова:
val image = ImageIO.read(URL("http://img.ifcdn.com/images/b313c1f095336b6d681f75888f8932fc8a531eacd4bc436e4d4aeff7b599b600_1.jpg")) val result = api.getWords(preparedImage, ITessAPI.TessPageIteratorLevel.RIL_WORD)

В результате будет найден только разный «мусор»:
[ie, [Confidence: 2.014679 Bounding box: 100 0 13 14], bad [Confidence: 61.585358 Bounding box: 202 0 11 14], oy [Confidence: 24.619446 Bounding box: 21 68 18 22], ' [Confidence: 4.998787 Bounding box: 185 40 11 18], | [Confidence: 60.889648 Bounding box: 315 62 4 14], ae. [Confidence: 27.592728 Bounding box: 0 129 320 126], c [Confidence: 0.000000 Bounding box: 74 301 3 2], ai [Confidence: 24.988930 Bounding box: 133 283 41 11], ee [Confidence: 27.483231 Bounding box: 186 283 126 41]]
Если внимательней посмотреть на изображение, то можно увидеть, что шрифт для текста белый, а значит, можно попробовать использовать threshold вместе с последующей инверсией, чтобы оставить текст только на картинке:
Пробуем следующие преобразования:
// convert to gray Imgproc.
 cvtColor(mat, mat, Imgproc.COLOR_BGR2GRAY)
// text -> white, other -> black
Imgproc.threshold(mat, mat, 244.0, 255.0, Imgproc.THRESH_BINARY)
// inverse
Core.bitwise_not(mat, mat)
cvtColor(mat, mat, Imgproc.COLOR_BGR2GRAY)
// text -> white, other -> black
Imgproc.threshold(mat, mat, 244.0, 255.0, Imgproc.THRESH_BINARY)
// inverse
Core.bitwise_not(mat, mat)После них посмотрим на картинку в результате (которую можно сохранить в файл через
Теперь если посмотреть на результаты вызова getWords, то получим следующее:
[WHEN [Confidence: 94.933418 Bounding box: 48 251 52 14], SHE [Confidence: 95.249252 Bounding box: 109 251 34 15], CATCHES [Confidence: 95.973259 Bounding box: 151 251 80 15], YOU [Confidence: 96.446579 Bounding box: 238 251 33 15], CHEATING [Confidence: 96.458656 Bounding box: 117 278 86 15]]
Как видно, весь текст успешно распознался.
Итоговый код по обработке изображения будет выглядеть следующим образом:
import net.sourceforge.tess4j.ITessAPI import net.sourceforge.tess4j.Tesseract import nu.pattern.OpenCV import org.opencv.core.Core import org.opencv.core.CvType import org.opencv.core.Mat import org.opencv.imgproc.Imgproc import java.awt.image.BufferedImage import java.awt.image.DataBufferByte import java.io.File import java.net.URL import javax.imageio.ImageIO fun main() { setupOpenCV() setupTesseract() val image = ImageIO.read(URL("http://img.ifcdn.com/images/b313c1f095336b6d681f75888f8932fc8a531eacd4bc436e4d4aeff7b599b600_1.jpg")) val mat = image.toMat() Imgproc.cvtColor(mat, mat, Imgproc.COLOR_BGR2GRAY) Imgproc.threshold(mat, mat, 244.0, 255.0, Imgproc.THRESH_BINARY) Core.bitwise_not(mat, mat) val preparedImage = mat.toBufferedImage() val api = Tesseract() api.setDatapath("/usr/local/share/tessdata/") api.setLanguage("eng") val result = api.getWords(preparedImage, ITessAPI.TessPageIteratorLevel.RIL_WORD) println(result) } private fun setupTesseract() { val libPath = "/usr/local/lib" val libTess = File(libPath, "libtesseract.dylib") if (libTess.exists()) { val jnaLibPath = System. getProperty("jna.library.path") if (jnaLibPath == null) { System.setProperty("jna.library.path", libPath) } else { System.setProperty("jna.library.path", libPath + File.pathSeparator + jnaLibPath) } } } private fun setupOpenCV() { OpenCV.loadLocally() } private fun BufferedImage.toMat(): Mat { val pixels = (raster.dataBuffer as DataBufferByte).data return Mat(height, width, CvType.CV_8UC3) .apply { put(0, 0, pixels) } } private fun Mat.toBufferedImage(): BufferedImage { var type = BufferedImage.TYPE_BYTE_GRAY if (channels() > 1) { type = BufferedImage.TYPE_3BYTE_BGR } val bufferSize = channels() * cols() * rows() val b = ByteArray(bufferSize) this[0, 0, b] // get all the pixels val image = BufferedImage(cols(), rows(), type) val targetPixels = (image.raster.dataBuffer as DataBufferByte).data System.arraycopy(b, 0, targetPixels, 0, b.size) return image }


Если сравнить полученный код с Python-версией, то разница будет минимальная. Производительность тоже должна быть практически сравнимой (за исключением, быть может, чуть больших преобразований изображения между Mat и BufferedImage).
Производительность тоже должна быть практически сравнимой (за исключением, быть может, чуть больших преобразований изображения между Mat и BufferedImage).
Преимущество Python в рамках текущего примера будет только в бесшовной передаче изображений между OpenCV и tesseract. Экосистема Python сама по себе удобна тем, что все библиотеки общаются одними и теми же типами.
В jvm-экосистеме тоже есть свои преимущества. Это и статическая типизация, и многопоточность, и общая скорость работы вместе с наличием огромного количества инструментов под любые требования. Может, текущий пример не сильно раскрывает все преимущества, но, как минимум, он демонстрирует, что для данной задачи решение на jvm и Kotlin получается ничуть не сложнее.
Python на текущий момент, беcспорно, лидер в ML. И в первую очередь все инструменты и библиотеки появляются на нём. Тем не менее, в других экосистемах можно использовать те же инструменты. Особенно учитывая, что если что-то есть под Python, то должна быть и нативная библиотека, которую можно легко подключить.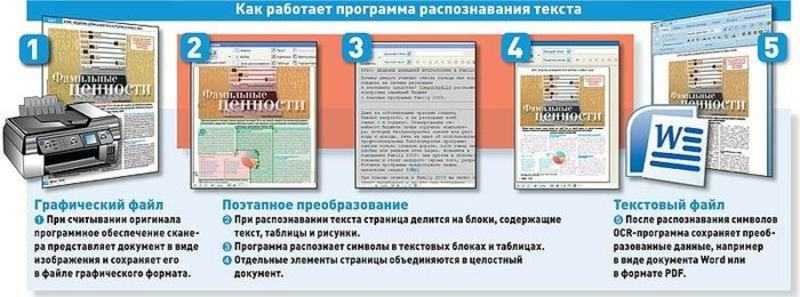
Надеюсь, что в этой статье вы нашли для себя что-нибудь полезное и новое. Спасибо за внимание, и напоследок несколько полезных ссылок:
djl.ai — Deep Learning на jvm, где можно подключать модели из pytorch и tensorflow
deeplearning4j.org — аналогичное решение с возможностью обучать модели и импортировать существующие на tensorflow и keras
kotlinlang.org/docs/reference/data-science-overview — разные полезные вещи по Data Science на Kotlin (и Java)
Весь код доступен в репозитории.
App Store: Сканер текста и изображения в текст
Описание
Сканер текста — лучший инструмент для извлечения текста из изображений. Вам больше не нужно печатать, сэкономьте время и используйте Text Scanner для удобного сканирования текста. Поддерживается более 90 языков.
Если вы хотите извлечь текст из фотографий и изображений, не ищите дальше. Text Scanner OCR помогает вам захватывать текст с изображений, поэтому вам не нужно снова печатать. Вы можете легко копировать текст с изображений. Алгоритм использует нейронную сеть поверх традиционной технологии OCR для достижения максимальной точности.
Вы можете легко копировать текст с изображений. Алгоритм использует нейронную сеть поверх традиционной технологии OCR для достижения максимальной точности.
Функции:
● Извлечение текста/слов из изображений
● Импорт изображений из фотобиблиотеки или камеры
● Распределение отсканированных изображений по папкам
● Копирование текста в буфер обмена
● Оптическое распознавание символов с помощью алгоритмов ИИ
● Делитесь отсканированным текстом и изображением с любой
● Перевод текста на другие языки
● Чтение текста вслух
● Редактирование текста в приложении
● Назовите свои сканы, чтобы вы знали, о чем они
● Синхронизация iCloud между вашими устройствами
—— —————————–
Если вы решите приобрести Text Scanner Pro, вы можете оформить подписку или заплатить единовременно. Оплата будет снята с вашей учетной записи Apple ID при подтверждении покупки. Подписка продлевается автоматически, если она не будет отменена как минимум за 24 часа до окончания текущего периода. С вашего аккаунта будет взиматься плата за продление в течение 24 часов до окончания текущего периода. Вы можете управлять своими подписками и отменять их, перейдя в настройки своей учетной записи в App Store после покупки. Текущая цена подписки на Text Scanner Pro начинается с $3,9.Доступны 9 долларов США в месяц, а также пакеты на один и 12 месяцев. Цены указаны в долларах США, могут отличаться в других странах, кроме США, и могут быть изменены без предварительного уведомления. Отмена текущей подписки не допускается в течение активного периода подписки. Если вы не решите приобрести Text Scanner Pro, вы можете просто продолжать использовать Text Scanner бесплатно.
С вашего аккаунта будет взиматься плата за продление в течение 24 часов до окончания текущего периода. Вы можете управлять своими подписками и отменять их, перейдя в настройки своей учетной записи в App Store после покупки. Текущая цена подписки на Text Scanner Pro начинается с $3,9.Доступны 9 долларов США в месяц, а также пакеты на один и 12 месяцев. Цены указаны в долларах США, могут отличаться в других странах, кроме США, и могут быть изменены без предварительного уведомления. Отмена текущей подписки не допускается в течение активного периода подписки. Если вы не решите приобрести Text Scanner Pro, вы можете просто продолжать использовать Text Scanner бесплатно.
Условия использования: https://sites.google.com/view/idlobapps-text-scanner/terms
Политика конфиденциальности: https://sites.google.com/view/idlobapps-text-scanner/privacy-policy
Версия 1.1.2
Улучшения производительности и исправления ошибок
Рейтинги и обзоры
129 оценок
Точный
Сканирование точное и быстрое. Это полезный инструмент. Очень рекомендую.
Хороший
Это хорошее приложение, которое делает то, что должно. Рекомендовал бы это.
Звучит как полезное приложение, я возлагал большие надежды
Идея отличная. Но приложение не работает. Я сделал около 5 попыток отсканировать документ. Я могу сделать снимок, показать изображение, оно выглядит хорошо, я выбираю использовать изображение, и оно сканирует первые 2 или 3 символа в каждой строке.
 Каретка возвращается на следующую строку.
Каретка возвращается на следующую строку.Подписки
Text Scanner Pro Yearly
Неограниченное количество сканирований, обмен текстом, без рекламы.
Бесплатная пробная версия
Разработчик, Болдизар Томпе, указал, что политика конфиденциальности приложения может включать обработку данных, как описано ниже. Для получения дополнительной информации см. политику конфиденциальности разработчика.
Данные не собираются
Разработчик не собирает никаких данных из этого приложения.
Методы обеспечения конфиденциальности могут различаться, например, в зависимости от используемых вами функций или вашего возраста. Узнать больше
Информация
- Продавец
- Болдизар Томпе
- Размер
- 37,1 МБ
- Категория
- Производительность
- Возрастной рейтинг
- 4+
- Авторское право
- © Болдизар Томпе
- Цена
- Бесплатно
- Тех. поддержка
- Политика конфиденциальности
 поддержка
поддержкаЕще от этого разработчика
Вам также может понравиться
Сканер текста Easy OCR— Zalmay
Как извлечь текст из изображений? Нужен бесплатный и надежный сканер изображений в текст? Фото в текст стало возможным с помощью этого простого в использовании приложения. Копируйте текст с изображений с точностью 99%, а также находите текст на изображениях.
Также возможно сделать изображение в речь и фото в речь, используя это приложение для чтения текста. Произносите текст с изображений с помощью этого бесплатного приложения для распознавания текста. Сохраняйте свои заметки в память телефона после преобразования фото в текст.
С помощью этого бесплатного сканера OCR вы можете конвертировать изображения и изображения в текст. Использование интеллектуальных моделей машинного обучения делает возможным очень простое преобразование фотографий в текст и изображений в текст.
Использование интеллектуальных моделей машинного обучения делает возможным очень простое преобразование фотографий в текст и изображений в текст.
Это приложение также хорошо работает со скриншотами. Сделайте снимок экрана и с помощью этого приложения преобразуйте снимок экрана в текст также с большой точностью.
Преобразование фотографий в текст упрощается с помощью простого приложения для распознавания текста. Все, что вам нужно сделать, это отсканировать изображение с помощью камеры или открыть из галереи, и пусть этот бесплатный сканер OCR творит чудеса. Используя машинное обучение, он может легко извлекать текст из изображений и позволяет сохранять извлеченные слова в виде файла на вашем телефоне.
Особенности:
☆ Сохраняйте изображения и картинки в виде текстовых файлов для дальнейшего использования с помощью этого мощного текстового сканера.
☆ Поиск текста на изображениях и картинках с помощью встроенной функции интеллектуального поиска.
☆ Прослушайте распознанный снимок экрана, используя возможности преобразования изображения в голос.
☆ Делитесь текстом с изображений и скриншотов с другими приложениями.
☆ Копировать извлеченный текст из изображений в буфер обмена.
☆ Обрезайте изображения и выполняйте преобразование изображения в текст на обрезанной части изображения.
Процесс преобразования фото в текст выполняется на вашем телефоне. Никакие данные не передаются в Интернете и не хранятся ни на одном сервере.
Обратите внимание, что сканер Easy OCR не может гарантировать точность 99% рукописного текста.
Загрузить для Android: https://play.google.com/store/apps/details?id=com.lewanayustaz.easy_ocr
Леванай Устаз создал приложение Easy OCR Text Scanner как приложение с поддержкой рекламы. Данная УСЛУГА предоставляется компанией Lewanay Ustaz бесплатно и предназначена для использования в исходном виде.
Эта страница используется для информирования посетителей о моих правилах сбора, использования и раскрытия Личной информации, если кто-то решил воспользоваться моей Службой.
Если вы решите использовать мой Сервис, вы соглашаетесь на сбор и использование информации в связи с этой политикой. Личная информация, которую я собираю, используется для предоставления и улучшения Сервиса. Я не буду использовать или делиться вашей информацией с кем-либо, кроме случаев, описанных в настоящей Политике конфиденциальности.
Термины, используемые в настоящей Политике конфиденциальности, имеют те же значения, что и в наших Условиях и положениях, которые доступны на Easy OCR Text Scanner, если иное не определено в настоящей Политике конфиденциальности.
Сбор и использование информации
Для удобства использования нашего Сервиса я могу потребовать от вас предоставить нам определенную личную информацию. Информация, которую я запрашиваю, будет сохранена на вашем устройстве и никоим образом не будет собираться мной.
Приложение использует сторонние службы, которые могут собирать информацию, используемую для вашей идентификации.
Ссылка на политику конфиденциальности сторонних поставщиков услуг, используемых приложением
- Службы Google Play
- AdMob
- Google Analytics для Firebase
- Firebase Crashlytics
Данные журнала
Я хочу сообщить вам, что всякий раз, когда вы используете мой Сервис, в случае ошибки в приложении я собираю данные и информацию (через сторонние продукты) на вашем телефоне под названием «Данные журнала». Эти данные журнала могут включать в себя такую информацию, как адрес интернет-протокола («IP») вашего устройства, имя устройства, версия операционной системы, конфигурация приложения при использовании моего Сервиса, время и дата использования вами Сервиса и другие статистические данные. .
Файлы cookie
Файлы cookie — это файлы с небольшим объемом данных, которые обычно используются в качестве анонимных уникальных идентификаторов. Они отправляются в ваш браузер с веб-сайтов, которые вы посещаете, и сохраняются во внутренней памяти вашего устройства.
Эта Служба не использует эти файлы cookie в явном виде. Однако приложение может использовать сторонний код и библиотеки, которые используют файлы cookie для сбора информации и улучшения своих услуг. У вас есть возможность либо принять, либо отказаться от этих файлов cookie и узнать, когда файл cookie отправляется на ваше устройство. Если вы решите отказаться от наших файлов cookie, вы не сможете использовать некоторые части этой Услуги.
Поставщики услуг
Я могу нанимать сторонние компании и частных лиц по следующим причинам:
- Для облегчения нашего Сервиса;
- Для предоставления Сервиса от нашего имени;
- Для оказания услуг, связанных с обслуживанием; или
- Чтобы помочь нам проанализировать, как используется наш Сервис.
Я хочу сообщить пользователям этого Сервиса, что эти третьи лица имеют доступ к вашей Личной информации. Причина в том, чтобы выполнять возложенные на них задачи от нашего имени. Однако они обязаны не разглашать и не использовать информацию для каких-либо других целей.
Однако они обязаны не разглашать и не использовать информацию для каких-либо других целей.
Безопасность
Я ценю ваше доверие в предоставлении нам вашей личной информации, поэтому мы стремимся использовать коммерчески приемлемые средства ее защиты. Но помните, что ни один метод передачи через Интернет или метод электронного хранения не является на 100% безопасным и надежным, и я не могу гарантировать его абсолютную безопасность.
Ссылки на другие сайты
Эта служба может содержать ссылки на другие сайты. Если вы нажмете на стороннюю ссылку, вы будете перенаправлены на этот сайт. Обратите внимание, что эти внешние сайты не управляются мной. Поэтому я настоятельно рекомендую вам ознакомиться с Политикой конфиденциальности этих веб-сайтов. Я не контролирую и не несу ответственности за содержание, политику конфиденциальности или действия любых сторонних сайтов или служб.
Конфиденциальность детей
Эти Услуги не предназначены для лиц моложе 13 лет.