RiDoc – программа для распознавания текста
RiDoc – программа для распознавания текста|
карта сайта |
техподдержка | |||
RiDoc – программа для сканирования и распознавания текста Скачать программу распознавания текста бесплатно |
||
По сути, программа RiDoc является универсальным средством для сканирования документов и распознавания текста. Для распознавания текста в программе RiDoc используется OCR Tesseract – свободно распространяемый продукт от компании Google. В настоящее время OCR Tesseract поддерживает огромное количество языков для распознавания, в том числе и русский язык (он уже включен в установочную программу RiDoc). Для добавления нового языка распознавания нужно выполнить следующие шаги: – Скачиваем архив нового языка со страницы загрузки языков распознавания OCR Tesseract. – Выполняем распознавание текста.
перейти на страничку программы RiDoc Посмотреть, как программа RiDoc сканирует документи и распознает текст
|
||
 Такая утилита должна быть всегда под рукой – очень часто требуется распознать простой отсканированный документ в текстовый формат.
Такая утилита должна быть всегда под рукой – очень часто требуется распознать простой отсканированный документ в текстовый формат.
Copyright © 2005-2022. |
||||||
 Компания “Риман”. Все права защищены
Компания “Риман”. Все права защищеныКак происходит распознавание текстов – Статьи –
Online-заявка
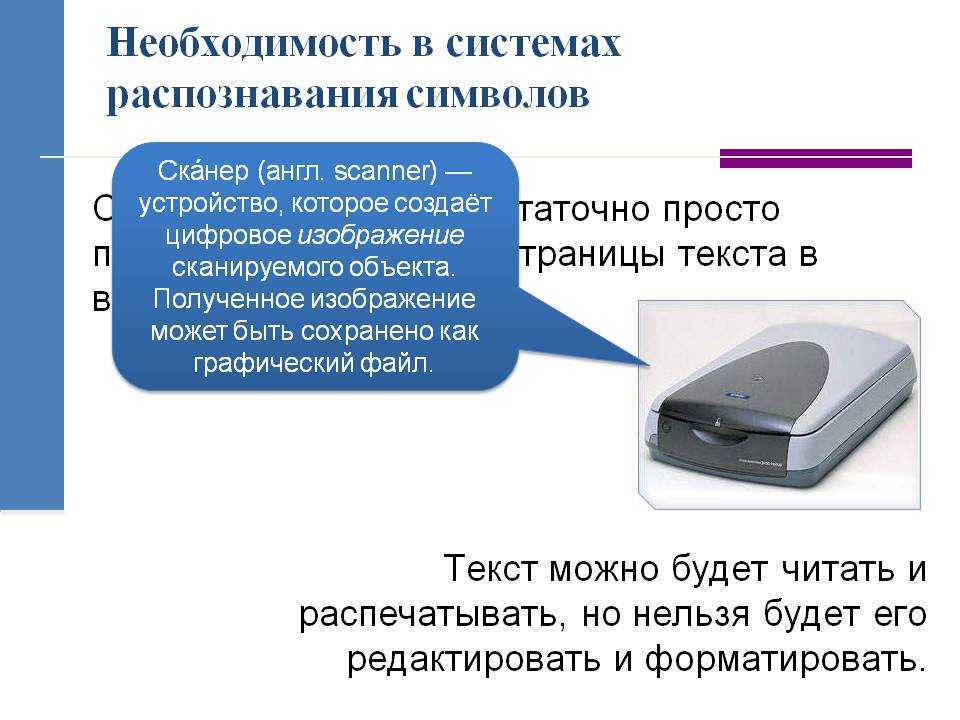
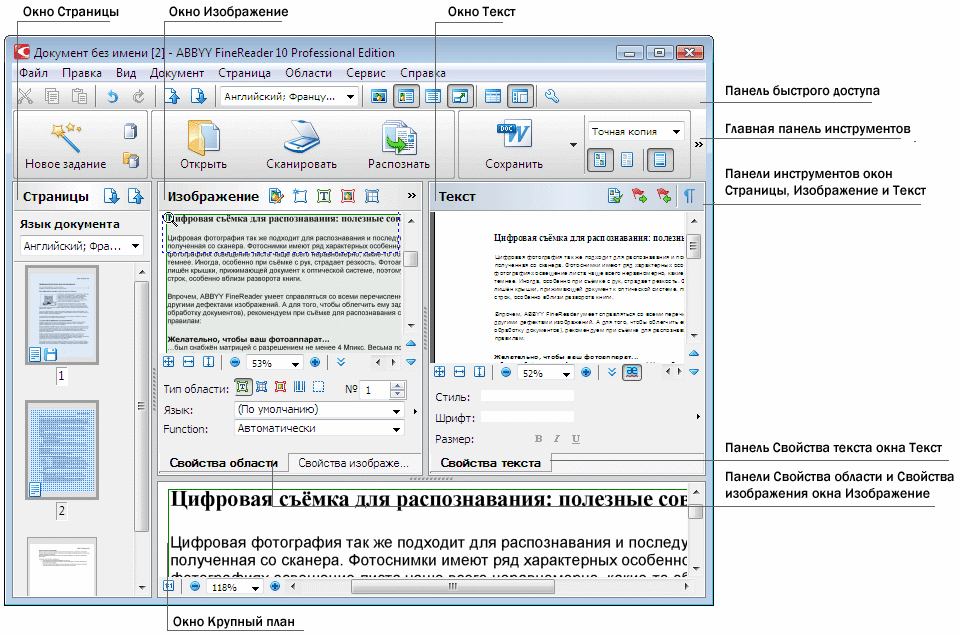
Сегодня нет необходимости заново набирать имеющийся текст, тратя на это драгоценное время. С этой работой помогают справиться многофункциональные устройства, которые выполняют ее в несколько этапов, освобождая человека от этой нудной процедуры.
Во-первых, нужно ввести отсканированный документ в компьютер. Страница в этом случае выглядит как изображение, еще не готовое для дальнейшей работы с ним.
Во-вторых, нужно произвести анализ макета, чтобы определить, где на странице находится текст, а где – таблицы и рисунки. Этот процесс выполняется при помощи OCR-приложения, которое позволяет разить текст на небольшие фрагменты, последовательно дробя их на предложения, слова и, наконец, самые мелкие – символы. Таким образом, конечным результатом данного этапа работы будет совокупность отдельных символов, каждый из которых находится в определенном месте страницы.
Этот процесс выполняется при помощи OCR-приложения, которое позволяет разить текст на небольшие фрагменты, последовательно дробя их на предложения, слова и, наконец, самые мелкие – символы. Таким образом, конечным результатом данного этапа работы будет совокупность отдельных символов, каждый из которых находится в определенном месте страницы.
Далее программа начинает распознавать символы, т.е. идентифицировать их. От того, насколько правильно пройдет этот процесс, зависит весь результат распознавания. Главная проблема состоит в том, что существуют похожие по своему начертанию символы, которые несут различную смысловую нагрузку. Для идентификации символов используются такие методы, как сопоставление признаков и сопоставление с имеющимся образцом. Один из них (сопоставления признаков) основан на таком принципе, что программа ориентируется на то, что каждый символ имеет свои отличительные признаки, которые остаются неизменными независимо от начертания шрифтов.
В соответствии со вторым методом программа сравнивает распознаваемый символ с тем шаблоном, который хранится в базе данных ее памяти. Этот метод называется методом сопоставления, но не очень удобен, поскольку на распознавание текста уходит много времени. Причиной низкой эффективности является также и то, что при использовании этого метода должно быть стопроцентное соответствие между символом и шаблоном, чтобы программа смогла распознать текст.
После распознавания текста начинается реконструкция документа. Программа имеет встроенный словарь, с помощью которого происходит процесс объединения символов в значимые слова, далее – в предложения и абзацы. Одна из функций программы позволяет реконструировать текст с учетом грамматических особенностей отсканированного текста, чтобы предложения получились грамотно построенными с точки зрения стилистики, грамматики и пунктуации.
И, наконец, реконструированный текст нужно сохранить. Пользователь сам определяет, в каком формате нужен полученный документ. Это может быть текст в формате TXT или макет страницы в формате PDF либо Microsoft Word.
Это может быть текст в формате TXT или макет страницы в формате PDF либо Microsoft Word.
Одним из лидеров в области разработки программного обеспечения для распознавания текстов является компания ABBYY со своим программным продуктом ABBYY Fine Reader.
Все статьи
Оптическое распознавание символов Python (OCR): Учебное пособие
Оптическое распознавание символов (OCR) — это технология, которая распознает текст в изображениях, таких как отсканированные документы и фотографии. Возможно, вы сфотографировали текст только потому, что не хотели делать заметки, или потому, что сделать фото быстрее, чем напечатать его. К счастью, благодаря сегодняшним смартфонам мы можем применять OCR, чтобы копировать изображение текста, которое мы сделали раньше, без необходимости его повторного ввода.
Что такое оптическое распознавание символов Python (OCR)?
Python OCR — это технология, которая распознает и извлекает текст из изображений, таких как отсканированные документы и фотографии, с помощью Python. Его можно выполнить с помощью OCR-движка Tesseract с открытым исходным кодом.
Его можно выполнить с помощью OCR-движка Tesseract с открытым исходным кодом.
Мы можем сделать это на Python, используя несколько строк кода. Одним из наиболее распространенных инструментов OCR является Tesseract. Tesseract — это механизм оптического распознавания символов для различных операционных систем.
Установка Python OCR
Tesseract работает на платформах Windows, macOS и Linux. Он поддерживает Unicode (UTF-8) и более 100 языков. В этой статье мы начнем с процесса установки Tesseract OCR и протестируем извлечение текста из изображений.
Первый шаг — установить Tesseract. Чтобы использовать библиотеку Tesseract, нам нужно установить ее в нашей системе. Если вы используете Ubuntu, вы можете просто использовать apt-get для установки Tesseract OCR:
sudo apt-get install Tesseract-ocr
Для пользователей macOS мы будем использовать Homebrew для установки Tesseract.
brew install Tesseract
Для Windows см. документацию по Tesseract.
документацию по Tesseract.
Начнем с установки pyTesseract.
$ pip install pyTesseract
Еще о Python: 5 способов написать дополнительный код Pythonic
Реализация оптического распознавания символов Python
После завершения установки давайте приступим к применению Tesseract с Python. Сначала мы импортируем зависимости.
из изображения импорта PIL импортировать pyTesseract импортировать numpy как np
Я буду использовать простое изображение для проверки использования Tesseract.
Образец изображения для преобразования Tesseract в текст. | Изображение: Фахми НуфикриДавайте загрузим это изображение и преобразуем его в текст.
имя файла = 'image_01.png' img1 = np.array (Image.open (имя файла)) text = pyTesseract.image_to_string(img1)
Теперь посмотрим на результат.
print(text)
И вот результат.
Результат после запуска OCR в Python. | Скриншот: Fahmi Nufikri Результаты, полученные с Tesseract, достаточно хороши для простых изображений.
Мы проделаем тот же процесс, что и раньше.
имя файла = 'image_02.png' img2 = np.array (Image.open (имя файла)) текст = pyTesseract.image_to_string(img2) print(text)
Это результат.
Нет результата после попытки извлечь текст из изображения с шумом. | Скриншот: Fahmi NufikriРезультат – ничего. Это означает, что tesseract не может читать слова на изображениях с шумом.
Далее мы попробуем немного обработать изображение, чтобы устранить шум на изображении. Здесь я буду использовать библиотеку OpenCV. В этом эксперименте я использую нормализацию, пороговое значение и размытие изображения.
импортировать numpy как np импортировать cv2norm_img = np.zeros((img.shape[0], img.shape[1])) img = cv2.normalize (img, norm_img, 0, 255, cv2.NORM_MINMAX) img = cv2.threshold(img, 100, 255, cv2.THRESH_BINARY)[1] img = cv2.GaussianBlur(img, (1, 1), 0)
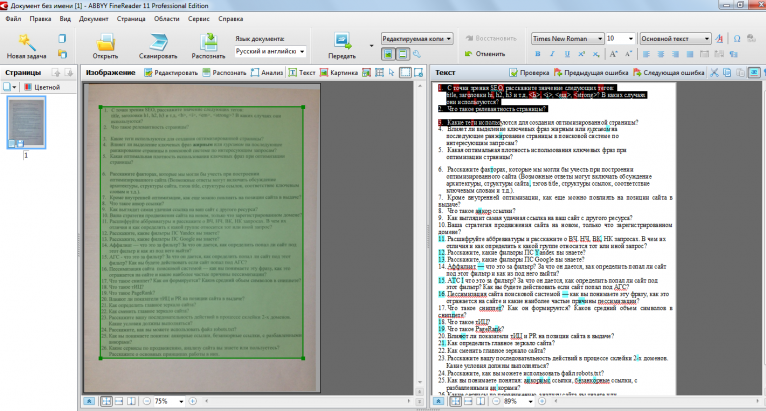 threshold(img, 100, 255, cv2.THRESH_BINARY)[1]
img = cv2.GaussianBlur(img, (1, 1), 0)
threshold(img, 100, 255, cv2.THRESH_BINARY)[1]
img = cv2.GaussianBlur(img, (1, 1), 0) Результат будет таким:
Теперь, когда изображение достаточно чистое, мы попробуем еще раз, используя тот же процесс, что и раньше. И это результат.
Результат показывает, что OCR распознал текст. | Скриншот: Фахми НуфикриКак видите, результаты соответствуют нашим ожиданиям.
Видео, знакомящее с основами использования PyTesseract для извлечения текста из изображений. | Видео: ProgrammingKnowledgeПодробнее о Python: 11 лучших доступных IDE и редакторов кода для Python
Локализация и обнаружение текста в Python OCR
С помощью Tesseract мы также можем выполнять локализацию и обнаружение текста на изображениях. Сначала мы введем зависимости, которые нам нужны.
Сначала мы введем зависимости, которые нам нужны.
из вывода импорта pyTesseract импортировать pyTesseract импорт cv2
Я буду использовать простое изображение, как в приведенном выше примере, чтобы проверить использование Tesseract.
Образец изображения для запуска в OCR. | Изображение: Fahmi NufikriТеперь давайте загрузим это изображение и извлечем данные.
имя файла = 'image_01.png' image = cv2.imread(filename)
Это отличается от того, что мы делали в предыдущем примере. В предыдущем примере мы сразу превратили изображение в строку. В этом примере мы преобразуем изображение в словарь.
результатов = pyTesseract.image_to_data(изображение, output_type=Вывод.DICT)
Следующие результаты являются содержанием словаря.
{
'уровень': [1, 2, 3, 4, 5, 5, 5],
'номер_страницы': [1, 1, 1, 1, 1, 1, 1],
'номер_блока': [0, 1, 1, 1, 1, 1, 1],
'par_num': [0, 0, 1, 1, 1, 1, 1],
'line_num': [0, 0, 0, 1, 1, 1, 1],
'номер_слова': [0, 0, 0, 0, 1, 2, 3],
«слева»: [0, 26, 26, 26, 26, 110, 216],
«верх»: [0, 63, 63, 63, 63, 63, 63],
«ширина»: [300, 249, 249, 249, 77, 100, 59],
«высота»: [150, 25, 25, 25, 25, 19, 19],
'conf': ['-1', '-1', '-1', '-1', 97, 96, 96],
'текст': ['', '', '', '', 'Тестирование', 'Tesseract', 'OCR']
} Я не буду объяснять назначение каждого значения в словаре. Вместо этого мы будем использовать левый, верхний, ширину и высоту, чтобы нарисовать ограничивающую рамку вокруг текста вместе с самим текстом. Кроме того, нам понадобится ключ
Вместо этого мы будем использовать левый, верхний, ширину и высоту, чтобы нарисовать ограничивающую рамку вокруг текста вместе с самим текстом. Кроме того, нам понадобится ключ conf для определения границы обнаруженного текста.
Теперь мы извлечем координаты ограничивающей рамки текстовой области из текущего результата и укажем желаемое значение достоверности. Здесь я буду использовать значение conf = 70. Код будет выглядеть так:
для i в диапазоне (0, len (результаты ["текст"])): х = результаты ["слева"] [i] y = результаты["верхний"][i] w = результаты["ширина"][i] h = результаты["высота"][i] текст = результаты["текст"][i] conf = int(результаты["conf"][i]) если конф > 70: text = "".join([c, если ord(c) < 128, иначе "" для c в тексте]).strip() cv2.rectangle (изображение, (x, y), (x + w, y + h), (0, 255, 0), 2) cv2.putText (изображение, текст, (х, у - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 0, 200), 2)
Теперь, когда все настроено, мы можем отобразить результаты, используя этот код.
cv2.imshow(image)
И это результат.
Результаты с координатами прямоугольника вокруг текста. | Изображение: Fahmi NufikriВ конечном счете, Tesseract лучше всего подходит для создания конвейера обработки документов, в котором изображения сканируются и обрабатываются. Это лучше всего подходит для ситуаций с вводом с высоким разрешением, когда текст переднего плана аккуратно отделен от фона.
Для локализации и обнаружения текста существует несколько параметров, которые можно изменить, например пределы достоверных значений. Или, если вы находите это непривлекательным, вы можете изменить толщину или цвет ограничивающей рамки или текста.
Полный список 10 лучших приложений OCR для мобильных телефонов (Android и iOS)
Опубликовано - Келси Тейлор
Вы видели изображение, из которого хотели извлечь текст или числа? А потом подумал про себя, это сложно напечатать все это! Ну, это уже не так.
На помощь приходит оптическое распознавание символов (OCR). Все эти часы, потраченные впустую на цифровое воспроизведение текста, теперь остались в прошлом.
Все эти часы, потраченные впустую на цифровое воспроизведение текста, теперь остались в прошлом.
- Зачем нужны приложения OCR?
- OCR для мобильных устройств
- Google Keep
- Текстовая фея
- CamScanner — iOS
- Офисный объектив — iOS
- Adobe Scan — iOS
- Смарт-линза
- Сканер текста
- Быстрое распознавание текста — сканер текста
- Evernote Scannable — iOS
- Ручка для печати
Зачем нужны приложения OCR?
Мир, как мы знаем, в один миг стал цифровым. Это означает, что мы больше не то поколение, которое зависит от старых добрых компьютеров и настольных компьютеров для получения информации.
Мы хотим, чтобы все было под рукой и быстро. Это привело к изобретению и разработке смартфонов.
Это привело к изобретению и разработке смартфонов.
Как и все, что касается смартфонов, функциональность обеспечивается приложениями, что приводит к необходимости в них.
Это относится и к OCR: чтобы ваш смартфон был совместим с OCR, вам нужно приложение, чтобы получить функциональные возможности и использовать их.
OCR для мобильных устройств
OCR для мобильных устройств прошло долгий путь — от элементарных приложений до полноценных корпоративных решений, доступных по цене. Сегодня более 95% рынка смартфонов составляют две операционные системы — Android и iOS.
Таким образом, мы будем проверять приложения, совместимые с этими двумя операционными системами.
Обратите внимание, что некоторые приложения работают как на iOS, так и на Android. Их версии для других операционных систем также будут иметь некоторые функции.
Итак, давайте рассмотрим 10 лучших приложений OCR для Android и iOS:
Google Keep
Мы все знаем Google Keep как облачное приложение для хранения заметок, близкого конкурента Evernote и OneNote.
Google время от времени обновляет приложение. Интересной функцией, которую он предоставляет, наряду с ведением заметок, является возможность захвата текста с изображений.
Google Keep использует камеру и извлекает текст из изображений. Но он может сделать это только в том случае, если изображение захвачено из приложения.
После получения изображения текст быстро захватывается и сохраняется в цифровом формате в заметке.
Текст доступен пользователям без необходимости вводить что-либо вручную. Затем пользователи могут удалить изображение из заметки.
После извлечения текста он автоматически синхронизируется с облаком на каждом устройстве, связанном с учетной записью.
Google Keep доступен как для iOS, так и для Android. Это бесплатное приложение без рекламы, как и OneNote.
Text Fairy
Приложение OCR, доступное для Android, является одним из лучших приложений OCR, доступных на сегодняшний день. Это надежное и быстрое приложение, которое пригодится, если вам нужно часто использовать приложение OCR.
Текстовая фея не только преобразует изображение в текст, но и корректирует точку обзора, с которой сделана фотография.
Например, если на странице есть складка, приложение улучшает изображение, чтобы повысить четкость. Затем приложение позволяет редактировать захваченный текст для устранения незначительных несоответствий.
Text Fairy позволяет копировать текст и вставлять его в любое другое приложение. Вам также предоставляется возможность экспортировать текст в файл PDF. Text Fairy — бесплатное приложение, в котором нет рекламы.
CamScanner — iOS
Как и Google Keep, CamScanner — еще одно приложение OCR, доступное как для Android, так и для iOS. CamScanner позволяет оцифровывать любые документы на ходу.
Функции сканирования документов в приложении доступны в бесплатной версии. Вы должны получить премиум-версию приложения для его функций OCR.
Премиум-версия приложения предоставляет несколько функций наряду с бесплатной версией. Он предлагает вам возможность извлечь текст из отсканированного изображения.
Он предлагает вам возможность извлечь текст из отсканированного изображения.
Предоставляет различные варианты преобразования, например, текст в изображение, изображение в WORD или изображение в EXCEL.
Распознавание CamScanner является, но не таким точным, как у Text Fairy и Google Keep. Подписка на премиум-версию приложения доступна за 4,99 доллара в месяц или 49,99 доллара в год.
Офисный объектив — iOS
Корпорация Майкрософт не идет на компромисс с качеством, когда речь идет о приложениях для повышения производительности.
Его модуль OCR, вероятно, самый лучший среди конкурентов. Но единственная проблема в том, что он без проблем работает с пакетом Office 365 Suite, но не так хорошо с другими сторонними приложениями.
Так что, если вы являетесь активным пользователем 365, вам не нужно искать дальше Office Lens. В противном случае выберите другое приложение OCR.
Office Lens хорошо работает со всеми приложениями Word, Excel, Powerpoint, Note и т. д., и его можно использовать бесплатно как на iOS, так и на Android.
д., и его можно использовать бесплатно как на iOS, так и на Android.
Adobe Scan — iOS
Adobe Scan, доступный как для iOS, так и для Android, является одним из лучших на рынке OCR. Когда дело доходит до управления документами, Adobe — одно из первых имен, которое приходит на ум, и почему бы и нет.
У Adobe один из лучших механизмов оптического распознавания символов для мобильных устройств, и это очевидно в Adobe Scan.
Позволяет не только сканировать, но и редактировать, комментировать и комментировать на ходу. Он бесплатен для использования и даже предоставляет 5 ГБ облачного хранилища для ваших отсканированных документов.
Единственным недостатком является то, что он не совместим ни с какими другими решениями для хранения данных. Таким образом, пользователь зависит от 5 ГБ хранилища или должен будет купить больше у Adobe, если это необходимо.
Читайте также: OCR и ICR: чем они отличаются?
Smart Lens
Это приложение может делать то, что не могут другие, и оно не может делать то, что могут другие. Таким образом, это несколько смешанная сумка.
Таким образом, это несколько смешанная сумка.
Smart Lens позволяет своим пользователям сканировать любой документ и может преобразовывать изображение в текст, но, кроме того, он также может преобразовывать отсканированный текст в любой другой язык.
Его встроенный переводчик пригодится, если вы, скажем, путешествуете и вам нужна помощь в понимании текста с другого языка.
Тем не менее, основные функции, которые есть в других приложениях, такие как преобразование рукописного изображения в текст, не поддерживаются.
Даже в этом случае Smart Lens можно рассматривать как хороший вариант для пользователей Android, если они ищут приложение OCR для языкового переводчика.
Сканер текста
Сканер текста будет вашим лучшим выбором, если вы хотите приложение, поддерживающее распознавание рукописного ввода. Он быстрый, плавный и легко выполняет свою работу. Text Scanner доступен для Android и поставляется с моделью Freemium.
Свободный режим засыпает вас рекламой. Но вы можете получить покупки в приложении и избавиться от рекламы. Но на работу приложения это никак не влияет.
Но вы можете получить покупки в приложении и избавиться от рекламы. Но на работу приложения это никак не влияет.
OCR Quickly — Text Scanner
Поставляется с моделью OOTB, которая не требует регистрации или входа в систему; просто установите и используйте.
Он также поставляется с автономным режимом и, следовательно, работает в любых условиях. Его задняя часть гладкая и хорошо сложенная.
Он не только щелкает и обнаруживает текст, но и немного повышает резкость изображения, прежде чем продолжить. Это позволяет более точно распознавать текст.
Вы также можете использовать изображения в своей галерее, чтобы обнаружить текст вне нее. Он построен на движке Tesseract OCR, который представляет собой движок с открытым исходным кодом, разработанный Google и поставляется с версией только для Android.
Evernote Scannable — iOS
Evernote — идеальный конкурент всем крупным офисным пакетам, таким как Microsoft и Google. Его приложение Evernote Scannable доступно для iOS и значительно упрощает жизнь.
Можно просто отсканировать любой документ или визитку, и приложение автоматически захватит с них информацию.
Изображения можно сохранять в формате JPG или PDF. Данные можно быстро использовать для создания контактов из визитных карточек или копировать и вставлять в другие приложения.
Pen to Print
Это приложение, доступное для Android, считается лучшим приложением для распознавания рукописного текста в цифровой текст. Конечно, он может преобразовывать печатный текст в цифровой текст из изображений.
Но его рукописный движок, безусловно, лучший из всех. Это очень полезно для студентов и профессионалов, чья жизнь связана с ведением заметок. Он доступен бесплатно на Android.
Заключение
Мобильные приложения OCR претерпели значительные изменения за последние пару лет. У каждого приложения есть свои преимущества, и, самое главное, они добавляют реальную ценность жизни пользователей.
Для тех, кто ищет простое приложение, которое будет использоваться время от времени, хорошим вариантом будут бесплатные.