
Потоковое сканирование документов в системе DocSpace
Модуль «Потоковое сканирование» оптимизирует технологию ввода большого объема бумажных документов в СЭД. Модуль решает следующие задачи:
- Массово сканирует документы с прикреплением к РКК (регистрационной контрольной карточки) в СЭД;
- Формирует и распечатывает штрих-коды для регистрируемых документов;
- Позволяет легко найти нужный документ по отсканированным штрих-кодам;
- Формирует сканированный образ документа;
- Формирует электронную учётную карточку, содержащую электронный образ отсканированного документа;
- Передает корректно отсканированный электронный образ документа в БД.
Модуль «Потоковое сканирование» облегчает работу ввода бумажных документов в СЭД.
Как это работает?
- В сканнер загружаются все необходимые документы одной пачкой.
Работа в одно нажатие. Все действия происходят автоматически, сотруднику необходимо только загрузить бумажные документы в сканнер и нажать кнопку, остальное система сделает самостоятельно.
Все действия происходят автоматически, сотруднику необходимо только загрузить бумажные документы в сканнер и нажать кнопку, остальное система сделает самостоятельно.
- Каждому сканированному документу присваивается уникальный штрихкод для дальнейшего распознавания документа
Присваивание штрихкода документу. Сгенерированный штрихкод может быть распечатан как на самом документе, так и на отдельной его странице. Если документ уже имеет штрихкод стандартного формата, система распознает его и может использовать для своей идентификации.
- Документ инфицируется по штрихкоду, и система связывает его с регистрационной карточкой соответствующего документа
Распределение документов
Распознавание электронных документов
Модуль «Потоковое сканирование» позволяет распознавать и переводить в другие форматы документы уже имеющиеся в СЭД.
- В СЭД формируется заявка с требованиями к новому формату и другим опциям документа;
- Документ отправляется в модуль «Потоковое сканирование» и проходит обработку по заявленным требованиям;
- После завершения документ экспортируется обратно в СЭД.
Данный процесс может быть расширен и скорректирован бизнес-логикой заказчика.
Технологическая обработка документа
Ввод графического или текстового формата
Сканирование возможно как графического образа документа, так и текстовый его формат. Что облегчает дальнейшую работу над документом. Распознавание и перевод текста документа реализован с помощью Websio Plugin и ABBYY FineReader.
Графический формат
Графический образ документа возможно конвертировать в следующие форматы: pdf, tiff, jpeg, png, bnp, gif. Реализована функция выбора размеров изображения при сканировании, а также его дополнительные настройки (глубина цвета, тип сжатия и т.
Текстовый формат
При применении опции распознавания текста документы могут быть сохранены в различных форматах: txt, rtf, xls, xlsx, docs, html, xml, pdf. Также реализована возможность менять размер страницы, кодировку и прочие свойства документа при его сканировании. PDF-формат возможно сохранять как в виде текста, так и изображения.
Распознавание языка документа
Модуль «Потоковое сканирование» распознает документы более чем на 50 языках, в том числе: русский, английский, китайский, немецкий, французский, итальянский, испанский, шведский, финский, украинский и другие.
Преимущества использования системы массового ввода документов «Потоковое сканирование»:
- Возможность замены бумажного документооборота и бумажных архивов электронной системой документооборота;
- Повышение эффективности управления документами;
- Сокращение времени на ввод документов и поиск документов;
- Исключение человеческого фактора при вводе данных;
- Общее увеличение скорости бизнес-процессов;
- Повышение производительности сотрудников;
- Оптимизация трудовых и временных затрат на работу с документами.


Варианты поставки
Для интеграции в существующую инфраструктуру:- Модуль формирования и печати штрих-кодов из РКК;
- Модуль интеграции в составе СЭД DocSpace – автоматически размещает отсканированные и распознанные документы в карточки документов в СЭД;
- Модуль поиска РКК в СЭД по сканированным штрих-кодам.
Дополнительно к основному блоку включает средство интеграции с программой для потокового сканирования документов ABBYY Scan Station.
Для организации распознавания сканированных образов в автоматическом режимеДополнительно к основному блоку включает средство интеграции с программой для распознавания текста, которая переводит изображения документов и любые типы PDF-файлов ABBYY FineReader Corporate.
Сканирование документов и создание электронного архива
Многие сталкивались с задачей отсканировать документ с помощью офисного сканера, и на первый взгляд это кажется несложным процессом который можно выполнить своими силами.
Готовая инфраструктура
Современные центры обработки на территории России
Центры оборудованы всем необходимым оборудованием для сканирования, при соблюдении всех требований безопасности. Сотрудники центров обучены и имеют большой опыт сканирования в промышленных объемах. Эти знания позволяют производить сканирование не только быстро и эффективно, но и бережно, не повреждая документы.
Собственное программное обеспечение для сканирования и распознавания документов
Мы используем только специализированное программное обеспечение собственной разработки OnePoint™ и SmartScan™. Это позволяет нам с одной стороны делать процессы максимально эффективно, подстраивая под нюансы процесса, с другой стороны это позволяет значительно сократить затраты
Автоматическое распознавание и классификация документов
Набор программных средств собственной разработки позволяет минимизировать ручной труд. У нас есть стандартный набор шаблонов который позволяет быстро запустить данный процесс для наиболее распространенных видов документов.
Вы можете быть уверены, что документы не потеряются и не будут повреждены.
Специализированное программное обеспечение для сканирования и распознавания является самой существенной составляющей в затратах процесса. Мы исключаем эту долю используя собственное ПО.

При использовании остальных сервисов Инфолоджистикс: логистики, внеофисного хранения, хранение в нашей системе электронного архива, уничтожения, вы получаете уникальную синергию процессов, полностью избавляясь от каких-либо операций на своей стороне. Сервисы сертифицированы по стандарту качества ГОСТ Р ИСО 9001-2015 (ISO 9001:2015) Смотреть сертификаты
Лучшие практики
С помощью решения docuForce компании Инфолоджистикс мы перевели кассовую документацию сети магазинов Prisma в электронный вид. Теперь согласование, подписание и хранение приходных/расходных кассовых ордеров, а также кассовых книг происходит в электронном виде. Мы значительно сократили свои расходы на данный бизнес-процесс.
Наши взаимоотношения с заказчиками предполагают необходимость предоставления детальных агентских отчетов вместе с закрывающими документами.
Для составления таких отчетов для заказчиков необходимо переносить большой
объем информации со счетов-фактур от поставщиков, большая часть которых использует бумажный документооборот.Аутсорсинг оцифровки и ввода данных с документов от компании Инфолоджистикс позволил существенно сократить трудозатраты на процесс формирования агентских актов и масштабировать процесс без увеличения собственного штата компании.
Для увеличения операционной эффективность мы решили придерживаться концепции централизованной бухгалтерии, когда в магазинах нет бухгалтеров, а документы от локальных поставщиков подписывают управляющие магазинами. В связи с этим остро встал вопрос о скорости оплаты счетов, так как оригиналы из удаленных магазинов доставлялись в центральный офис долго, а также отсутствовал механизм контроля этих доставок.
Инфолоджистикс разработали для нас мобильное приложение, позволяющее сотрудникам магазина быстро сделать фото документов, отправить их в операционный центр Инфолоджистикс для распознавания и верификации, а оттуда - в системы согласования платежей. Это решение позволило существенно сократить сроки оплаты входящих счетов, а также обеспечить контроль за поступлением в архив закрывающих документов.
Мы сотрудничаем с Инфолоджистикс уже много лет и реализовали большое количество проектов по оптимизации бэк-офиса в части документооборота. Архивное хранение документов в физическом и электронном архиве, интеграционные решения для обработки входящих документов, единый архив электронных документов от разных операторов ЭДО и скан-копий – все эти решения показали высокую надежность и эффективность.
Особенно хочу отметить качество поддержки и клиентского сервиса, благодаря которым все вопросы решаются быстро и качественно.
 Для составления таких отчетов для заказчиков необходимо переносить большой
объем информации со счетов-фактур от поставщиков, большая часть которых использует бумажный документооборот.
Для составления таких отчетов для заказчиков необходимо переносить большой
объем информации со счетов-фактур от поставщиков, большая часть которых использует бумажный документооборот.
Наши решения
Электронный
документооборотЭлектронные архивы
первичных документовВнеофисное хранение
Электронный кадровый
документооборотInvoice Processing
Управление
архивами
Напишите нам
Спасибо, Наши специалисты в ближайшее время свяжутся с Вами!
Новое обращение в службу поддержки
Обратный звонок
Что такое OCR? Основы оптического распознавания символов
Оптическое распознавание символов (OCR) — это технология, которая позволяет компьютерному программному обеспечению преобразовывать текст, найденный в отсканированном документе или изображении, в машиночитаемый текст.
Любой, кто когда-либо был в аэропорту, отправлял письмо по почте или вносил чек в банкомат, использовал технологию OCR.
Наиболее распространенным применением технологии OCR является извлечение печатного или рукописного текста из физических документов для использования и понимания компьютерным программным обеспечением.
Благодаря преобразованию данных изображения в текст, закодированный компьютером, отсканированные документы становятся значительно более функциональными, предоставляя пользователю цифровой версии возможность искать, просматривать и редактировать его содержимое, извлекать информацию и многое другое.
По этой причине популярность технологии OCR значительно возросла, и ее часто можно найти как в профессиональном, так и в потребительском программном обеспечении для сканирования.
OCR — это абсолютно необходимая технология для всех, кто хочет иметь возможность оцифровывать текстовые документы и немедленно использовать содержащуюся в них информацию.
Как работает распознавание текста?
Программное обеспечение для оптического распознавания символов извлекает текст из изображения, используя комбинацию компьютерного зрения, распознавания образов и искусственного интеллекта.
Для простоты мы рассмотрим OCR в сравнении с предоставляемыми нами услугами сканирования документов, но концепции в основном одинаковы в любом приложении OCR.
OCR позволяет нам преобразовывать бумажные документы в цифровые файлы, которые можно искать по любому тексту в файле, которые можно редактировать в текстовом редакторе и получать удаленный доступ из облака.
Мы следуем простой процедуре из 4 частей, чтобы завершить этот процесс.
1. Процесс сканирования
Первой и, пожалуй, самой важной частью процесса является начальное сканирование документа. Крайне важно, чтобы полученное изображение было точным представлением исходного документа, четким и свободным от каких-либо дефектов, которые могут помешать процессу оптического распознавания символов.
Документы следует сканировать с максимально допустимым разрешением, чтобы программа OCR имела наилучшие шансы точно идентифицировать текст.
В идеале сканер должен быть откалиброван по образцу документа, а в случае массового сканирования — повторно откалиброван несколько раз на протяжении всего процесса.
2. Обработка изображений
На следующем шаге программа OCR обработает отсканированное изображение, чтобы создать оптимальные условия для распознавания символов.
Во-первых, программа исправит любые проблемы с выравниванием, возникшие в процессе сканирования, повернув изображение, чтобы обеспечить правильную ориентацию документа.
Несовершенства, такие как пыль, случайные следы и цифровые артефакты, удаляются, а края сглаживаются.
Затем информация о цвете отбрасывается, а контраст полученного изображения в градациях серого увеличивается, в результате чего получается высококонтрастное черно-белое изображение (это называется бинаризацией). Это максимизирует разделение между передним планом (текстом) и фоном, уменьшая вероятность неправильной идентификации символов.
Это максимизирует разделение между передним планом (текстом) и фоном, уменьшая вероятность неправильной идентификации символов.
3. Распознавание символов.
Это происходит во время процесса распознавания символов, когда программное обеспечение OCR преобразует текст, найденный в документе, в его эквивалент на машинном языке.
Сначала документ анализируется на макет, определяя расположение текстовых блоков и абзацев. Затем каждое место разбивается по строкам, а затем по отдельным словам.
Наконец, каждый отдельный символ изолируется (так называемая «сегментация») для перевода.
В простых приложениях OCR необработанные пиксельные данные каждого символа сравниваются напрямую с базой данных известных буквенно-цифровых форм для определения наиболее близкого совпадения.
Однако большинство современных приложений OCR обычно используют один из двух методов идентификации символов:
- Распознавание образов: Распознавание образов работает путем анализа каждого символа в целом, сравнивая его с матрицей символов, хранящейся в программном обеспечении. Недостаток этого метода заключается в том, что он основан на том, что вводимые символы и сохраненные символы имеют одинаковую форму и масштаб.
- Извлечение признаков: Извлечение признаков — это более сложный и универсальный метод распознавания символов, который более точно имитирует способ обработки текста человеческим разумом. Алгоритм разбивает каждый символ на отдельные черты, определяя прямые линии, кривые, углы и пересечения. Затем он сопоставляет наличие этих физических особенностей с соответствующей буквой. Преимущество этого метода заключается в том, что он не полагается на определенный шрифт или набор шрифтов для идентификации.
 Недостаток этого метода заключается в том, что он основан на том, что вводимые символы и сохраненные символы имеют одинаковую форму и масштаб.
Недостаток этого метода заключается в том, что он основан на том, что вводимые символы и сохраненные символы имеют одинаковую форму и масштаб.4. Проверка
После идентификации каждого символа результирующий текст сверяется с внутренними словарями и известными словарями для повышения общей точности окончательного вывода.
Используя анализ ближайших соседей, программа OCR ищет буквы и слова, которые обычно встречаются вместе, и использует эти «правила» для выявления ошибок и внесения исправлений.
Например, распространенные диграфы (пара букв, представляющие один звук речи), включая «qu», «ea» и «ch», могут быть надежно исправлены при неправильной идентификации на основе этих рекомендаций.
Какие существуют типы OCR?
В настоящее время существует несколько различных типов технологии OCR. Вот несколько примеров OCR, с которыми вы можете столкнуться:
- Простая технология оптического распознавания символов преобразует печатный текст в машиночитаемые символы путем анализа базы данных шрифтов и текстовых изображений, которые могут использоваться алгоритмами сопоставления с образцом для идентификации отдельных символов в документе.
- Зональное распознавание — это тип OCR, который обычно используется для извлечения информации из документа путем сканирования определенных областей документа, что часто полезно при оцифровке форм
- Оптическое распознавание меток можно использовать для обработки информации, отмеченной на полях, в опросах или тестах. Его также можно использовать для идентификации логотипов, водяных знаков и других символов, которые могут появляться в документе.
- Считыватели штрих-кода используют лазеры для извлечения информации, хранящейся в штрих-коде, тогда как OCR штрих-кода извлекает эту информацию из цифрового изображения штрих-кода. Это автоматизирует процесс извлечения штрих-кода из документов в процессе оцифровки.
- Интеллектуальное распознавание слов можно использовать отдельно или в сочетании с другими типами OCR для распознавания целых слов в документе. Это может повысить точность процесса OCR, поскольку символы можно идентифицировать и проверять в зависимости от контекста, в котором они появляются.
 Его также можно использовать для идентификации логотипов, водяных знаков и других символов, которые могут появляться в документе.
Его также можно использовать для идентификации логотипов, водяных знаков и других символов, которые могут появляться в документе.Насколько точен OCR?
Во всех смыслах и целях OCR — чрезвычайно точный и эффективный способ оцифровки текста.
Большинство профессиональных приложений способны распознавать символы с точностью 98-99%. Например, документ из 2000 символов, проанализированный OCR, может содержать от 20 до 40 неверно идентифицированных символов.
Например, документ из 2000 символов, проанализированный OCR, может содержать от 20 до 40 неверно идентифицированных символов.
По этой причине важно проверять и исправлять выходные данные OCR, особенно в тех случаях, когда требуется очень точная транскрипция.
Как измеряется точность OCR?
Чтобы измерить точность конкретного решения OCR, необходимо провести сравнение исходного документа и оцифрованного вывода. Каждая ошибка должна быть задокументирована и подсчитана одним из двух способов:
.- Точность на уровне символов: (Всего правильно идентифицированных символов / Всего отсканированных символов) * 100
- Точность на уровне слов (Всего правильно идентифицированных слов / Всего слов) * 100
Каковы преимущества OCR?
Оптическое распознавание символов — это самый быстрый, дешевый и эффективный метод оцифровки содержимого бумажного документа. Технология оптического распознавания текста обеспечивает множество преимуществ, в том числе:
- Повышение эффективности ручного ввода данных
- Снижение операционных и трудовых затрат
- Экономия места
- Обеспечение автоматизации трудоемких бизнес-процессов
- Снижение вероятности ошибок при подаче документов
- Простота управления заполненными вручную формами
- Автоматический перевод документов на другие языки
- Работа с документами только для чтения
- Улучшение обслуживания клиентов и коммуникации
- Повышение безопасности данных
Повышение эффективности ручного ввода данных
OCR можно использовать для дополнения и поддержки существующей группы ввода данных, устраняя первоначальные усилия по ручному вводу информации в системы.
Снижение затрат
OCR экономит предприятиям значительное количество времени и денег, которые в противном случае были бы потрачены на ручной ввод данных. То, что специалисту по вводу данных может расшифровать за час, OCR может сделать почти мгновенно.
OCR также снижает эксплуатационные расходы. Преобразовывая бумажные документы в цифровые файлы с возможностью текстового поиска, сотрудники могут легко находить нужную им информацию, создавая более эффективные рабочие процессы и сокращая время обработки.
Сохранить место
OCR избавляет от необходимости хранить большие объемы бумажных документов. Цифровое хранилище дешевле и эффективнее, помогая предприятиям высвободить ценное офисное пространство для более важных целей.
Автоматизировать бизнес-процессы
Предприятия, постоянно обрабатывающие большие объемы бумажных документов, могут значительно сэкономить время и ресурсы с помощью услуг сканирования документов с поддержкой OCR. OCR позволяет извлекать важные данные из документов во время процессов сканирования, которые можно легко перенести в соответствующие системы, что позволяет предприятиям внедрять сверхэффективные автоматизированные рабочие процессы.
OCR позволяет извлекать важные данные из документов во время процессов сканирования, которые можно легко перенести в соответствующие системы, что позволяет предприятиям внедрять сверхэффективные автоматизированные рабочие процессы.
Уменьшить количество ошибок при подаче
OCR можно использовать для автоматической маркировки и классификации документов, что снижает вероятность потери или неправильного размещения документов.
Управление заполняемыми вручную формами
Компании , которые используют рукописные формы и анкеты, могут использовать OCR, чтобы мгновенно преобразовывать ответы клиентов в доступные для поиска и действия данные.
Перевод документов
Документы, обработанныеOCR, можно легко перевести на другой язык либо с помощью самого программного обеспечения OCR, либо с помощью автоматических инструментов перевода текста, таких как Google Translate.
Преобразование документов только для чтения
OCR можно использовать для преобразования любого нередактируемого цифрового документа в редактируемый цифровой текст, а не только отсканированные документы.
Улучшение обслуживания клиентов
OCR может помочь улучшить общение с клиентами, эффективный поиск данных и лучшую организацию, позволяя предприятиям быстро реагировать на запросы клиентов.
Повышение безопасности данных
Бумага — невероятно небезопасный способ хранения важных данных. Это связано с тем, что бумажные документы подвержены краже, потере и повреждению. Извлечение данных из бумажных документов с помощью оптического распознавания текста позволяет хранить важные данные в цифровом виде, обеспечивая улучшенный контроль доступа, шифрование данных, а также автоматическое резервное копирование и восстановление.
Каковы ограничения OCR?
Хотя оптическое распознавание текста обеспечивает многочисленные преимущества по сравнению с вводом данных вручную, оно также имеет несколько важных недостатков, которые следует отметить, в том числе:
- Структурирование данных включает в себя больше, чем просто OCR.
- OCR хорошо работает только с отсканированными изображениями высокого качества
- Для рукописного содержимого требуется специальное программное обеспечение
- Почти всегда требуется корректура
- OCR может иметь трудности со сложными изображениями
OCR не помогает структурировать важные данные
Несмотря на то, что OCR отлично справляется с оцифровкой письменного текста, оно не способно понять его на макроуровне. Документы, обработанные с помощью OCR, по-прежнему должны быть помечены, классифицированы и организованы каким-либо другим ручным процессом, чтобы стать полностью полезными для профессиональных целей.
Документы, обработанные с помощью OCR, по-прежнему должны быть помечены, классифицированы и организованы каким-либо другим ручным процессом, чтобы стать полностью полезными для профессиональных целей.
OCR хорошо работает только при сканировании высокого качества.
Чтобы OCR правильно распознавал текст в документе, исходное изображение, созданное в процессе сканирования, должно быть максимально четким.
Чтобы повысить шансы на успех, важно убедиться, что в документах нет пятен, размытого текста или пометок, которые могут привести к ошибкам в процессе сканирования.
Сканер должен быть правильно откалиброван по образцу, взятому из исходного материала, и должен периодически проверяться на протяжении всего процесса сканирования для обеспечения оптимального цифрового вывода.
Полученное изображение должно быть сохранено с высоким разрешением, в идеале 150 точек на дюйм (точек на дюйм) или выше, с высоким коэффициентом контрастности текста и фона.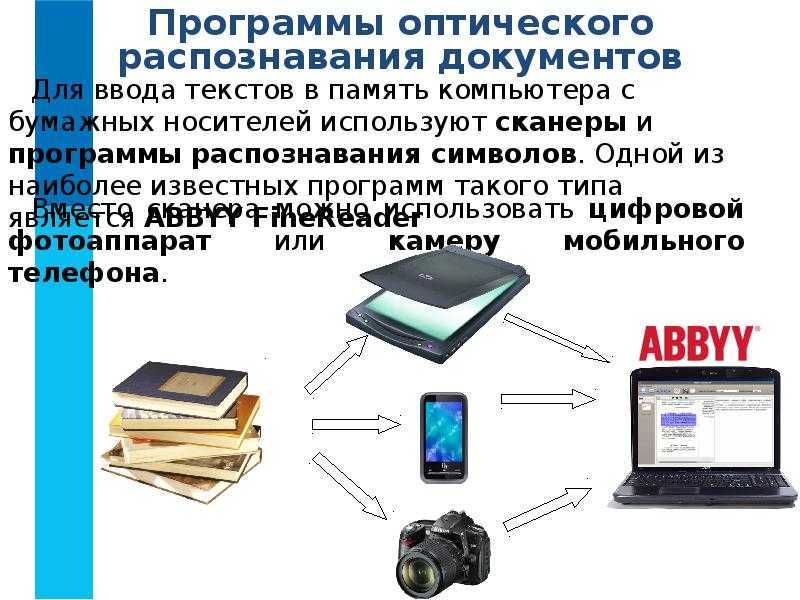
Для рукописного контента требуется специализированное программное обеспечение
Традиционное распознавание символов основано на принципе «изучения» предопределенных шрифтов и символов в количестве, достаточном для идентификации отдельных букв в тексте аналогичной формы.
В то время как ранние системы OCR, как правило, были способны распознавать только один шрифт, большинство современных систем могут применять базовый набор правил, который позволяет программному обеспечению сопоставлять символы практически из любого стандартного набора символов с засечками или без засечек.
Однако это не относится к рукописному тексту.
Рукописный ввод создает ряд проблем для программного обеспечения для оптического распознавания символов, поскольку рукописный ввод значительно отличается от печатного текста. Хотя существует программное обеспечение, способное оцифровывать рукописный текст, любой, кому требуется чрезвычайно точная транскрипция, обнаружит, что потребуется ручная проверка.
Вычитка почти всегда требуется
Несмотря на то, что программное обеспечение для оптического распознавания текста обычно дает довольно точные результаты, важно не полагаться на него в отношении важных данных. Каждый документ, обработанный с помощью программного обеспечения OCR, должен быть тщательно проверен на наличие ошибок и исправлен вручную, прежде чем данным можно будет полностью доверять.
Например, в ситуации, когда OCR обрабатывает отсканированный счет, использование суммы счета, содержащей необнаруженную ошибку, может привести к неточным записям или списанию средств.
OCR может иметь проблемы со сложными изображениями
Текст, расположенный на сложном фоне, может затруднить программному распознаванию символов правильное выделение отдельных символов, что приведет к неточным результатам.
Каковы распространенные варианты использования технологии OCR?
OCR имеет множество практических применений как для бизнеса, так и для потребителей. С практической точки зрения OCR можно использовать в качестве замены везде, где выполняется ручной ввод данных, автоматизируя процесс извлечения важных данных из набора печатных документов в электронную систему, где информация будет храниться.
С практической точки зрения OCR можно использовать в качестве замены везде, где выполняется ручной ввод данных, автоматизируя процесс извлечения важных данных из набора печатных документов в электронную систему, где информация будет храниться.
Наиболее распространенными вариантами использования OCR являются путешествия, банковское дело, здравоохранение и правительство.
OCR в Travel
OCR широко используется в индустрии туризма, чтобы обеспечить более плавное и удобное взаимодействие с клиентами. Аэропорты, вокзалы и метро используют технологию OCR как для целей безопасности, так и для хранения данных.
OCR сокращает трудоемкие процессы, связанные с ручным вводом сведений о клиенте, поиском длинных билетов или идентификационных номеров заказов, а также сортировкой багажа.
OCR в банковском деле
Банковская отрасль является одним из крупнейших потребителей технологии OCR. OCR не только помогает банкам повысить качество обслуживания клиентов, но и сокращает объем ручного ввода данных.
Технология оптического распознавания символов используется банкоматами для проверки депонированных чеков, сканирования и извлечения рукописной информации о сумме и подтверждения наличия действительной подписи. OCR также часто внедряется в приложения для мобильного банкинга, позволяя клиентам вносить чеки, просто загружая изображение.
OCR в здравоохранении
Технология оптического распознавания символовоказалась чрезвычайно полезной для отрасли здравоохранения, позволив поставщикам медицинских услуг и медицинским работникам упростить обработку и хранение данных.
Медицинским учреждениям нередко приходится иметь дело с тоннами бумажных документов, таких как формы приема клиентов, рукописные записи врачей, счета-фактуры, квитанции и многое другое. OCR помогает сократить ручной труд по перемещению этих данных в соответствующие системы, улучшая как обслуживание клиентов, так и качество обслуживания.
OCR в правительстве
Государственные учреждения являются одним из крупнейших источников бумажных данных. Технология OCR позволяет этим агентствам модернизировать свои системы записи, сочетая удобство бумаги с безопасностью и эффективностью хранения цифровых данных.
Технология OCR позволяет этим агентствам модернизировать свои системы записи, сочетая удобство бумаги с безопасностью и эффективностью хранения цифровых данных.
OCR имеет множество практических применений для государственных учреждений. Критическая информация, хранящаяся в больших исторических бумажных архивах, может быть извлечена и сохранена в цифровом виде, что снижает ненужные расходы на хранение бумаги. OCR также позволяет правительству предоставлять своим клиентам удобные варианты обслуживания.
Что такое интеллектуальное распознавание документов и как оно работает?
Интеллектуальное распознавание документов (IDR) — это технология на основе искусственного интеллекта, которая может классифицировать и обрабатывать различные типы неструктурированной/полуструктурированной информации из документов. Часто IDR сочетает в себе искусственный интеллект и оптическое распознавание символов (OCR) для максимально быстрой и точной обработки данных.
Каждый бизнес-процесс содержит документы, и примерно 80 % данных в этих документах заблокированы или скрыты. IDR необходим для любого бизнеса, который хочет добиться успеха, поскольку он позволяет им лучше понимать свои данные и помогает им принимать взвешенные бизнес-решения.
Содержание:
- Что такое IDR?
- Как работает IDR?
- Преимущества IDR
- Чем IDR отличается от OCR?
- Как быстро вы сможете внедрить IDR?
- Часто задаваемые вопросы
В среднем офисный работник просматривает более 10 000 страниц документов в год, причем 45 % из этого количества становятся бесполезными в течение одного дня. Кроме того, типичный сотрудник тратит 30-40% своего времени на поиск фрагментов данных или конкретного документа.
Хотя для некоторых компаний эти болевые точки очевидны, большинству предприятий трудно должным образом оцифровать свои данные, чтобы сделать их легкодоступными и машиночитаемыми. И нет… сканирование документа и преобразование его в PDF — не лучший вариант.
Но правда в том, что большинство предприятий используют методы сканирования, копирования/вставки, преобразования в PDF, но большинство из них в конечном итоге прибегают к поиску Google способов быстрого извлечения данных из PDF-файлов. К сожалению, эти способы являются дорогостоящими, трудоемкими и подвержены ошибкам, поскольку люди не являются идеально отлаженными механизмами. Но благодаря интеллектуальному распознаванию документов (IDR) эти процессы могут быть полностью оптимизированы для любого бизнеса, стремящегося улучшить свою игру: повысить точность, скорость и значительно уменьшить количество ошибок.
Кроме того, с помощью IDR извлеченные данные можно легко интегрировать в другие бизнес-системы, такие как RPA, ERP или CRM практически любого поставщика.
Интеллектуальное распознавание документов (IDR) — это программное обеспечение для обработки данных, основанное на искусственном интеллекте и (часто) OCR. Программное обеспечение может интеллектуально автоматизировать обработку любых неструктурированных/полуструктурированных данных из документов.
Как работает IDR?
Классификация документов:
IDR может распознавать данные и шаблоны в документе и классифицировать их по различным типам документов. Например, если в документе, проанализированном системой, слово «страховка» повторяется несколько раз, программа может определить, что, скорее всего, речь идет о страховом полисе. Классификация документов — утомительный процесс, когда им занимаются люди, поэтому IDR может быть отличным долгосрочным решением.
Извлечение данных:
После классификации документов IDR автоматически извлекает из них соответствующие точки данных. Точки данных каждой компании различаются в зависимости от того, что они хотят получить из своих наборов документов. Чтобы сделать это точно, человеку обычно нужно предоставить системе большую базу выборок, чтобы программное обеспечение могло научиться извлекать из них данные.
Проверка данных:
Наконец, система проверит все извлеченные данные, обеспечив точность и согласованность. Человек в цикле часто может сопровождать этот процесс, и человек может в конечном итоге определить и переопределить то, что система должна проверять.
Человек в цикле часто может сопровождать этот процесс, и человек может в конечном итоге определить и переопределить то, что система должна проверять.
Запланируйте собственную бесплатную демонстрацию с одним из наших экспертов по решениям для документов и посмотрите, как IDR работает с вашими документами.
Преимущества IDR
IDR — эффективное решение для компаний, которые борются с тяжелыми бэк-офисными процессами и в конечном итоге хотят оптимизировать свои задачи. Вот некоторые из преимуществ IDR:
Скорость:
Люди прекрасны, но мы быстро устаем, особенно когда выполняем однообразные задачи. IDR не устает, как мы, и может работать круглосуточно, автоматизируя процесс ввода и извлечения данных, обеспечивая при этом высокую точность.
Точность:
IDR использует интеллектуальные методы проверки и значительно снижает вероятность ошибки данных, которая в противном случае была бы обычным явлением, если бы человек вручную взял на себя управление.
Экономическая эффективность:
Программное обеспечение снижает высокие затраты, которые обычно связаны с исправлением ошибок и штрафами, вызванными несоблюдением требований. Кроме того, обработка данных занимает намного меньше времени, чем у члена команды, а это означает, что сотрудники могут сосредоточить свое внимание на других обязанностях.
Легче получить данные документа:
Средний сотрудник тратит 30-40% своего времени на поиск данных или определенных документов. Программное обеспечение IDR позволяет членам команды из любого отдела или офиса легко и быстро находить данные.
Члены команды могут потратить больше времени:
Благодаря автоматизации от IDR члены команды могут перенаправить свое внимание на более важные задачи и принятие решений, которые могут создать положительный эффект снежного кома для компании.
Чем IDR отличается от OCR?
OCR просто расшифровывает документ, оставляя вам текстовое представление отсканированного изображения, но не предоставляет дополнительной информации о том, о чем документ, или фактических точках данных. Это все, что им нужно для некоторых компаний, отлично, но для большинства этого недостаточно для достижения их целей по извлечению данных.
Это все, что им нужно для некоторых компаний, отлично, но для большинства этого недостаточно для достижения их целей по извлечению данных.
С другой стороны, IDR сочетает в себе AI и OCR для расшифровки документов таким образом, который может быть автоматизирован и предназначен для идентификации соответствующих бизнес-данных из документа.
Как быстро вы сможете внедрить IDR?
Большинство людей ожидают сложной и длительной интеграции программного обеспечения, включающей форму искусственного интеллекта, но все как раз наоборот. IDR можно внедрить в любую систему очень быстро, часто без помощи ИТ-специалистов.
Часто задаваемые вопросы
Какие технологии могут быть применены к IDR?
Оптическое распознавание символов (OCR): Механизм OCR может распознавать и преобразовывать (простые) рукописные и печатные символы в цифровой формат.
Машинное обучение (ML): технология, которая со временем продолжает учиться тому, как извлекать данные из набора данных.