
ABBYY FineReader, CuneiForm — ABC IMPORT
Содержание статьи:
- Области применения OCR
- Процесс определения точности текста
- Оптическая технология для Брайля
- Выбор программ для распознавания текста
- Популярное ПО для мобильных устройств
- Документы Google
- Оптическое распознавание Abbyy
- Облачный сервис Adobe Acrobat
- Лучшее бесплатное программное обеспечение
- Распознавание символов в Linux
Технология OCR (Optical Character Recognition) может быть использована для преобразования печатной копии документа в электронную версию. Например, если сканируется многостраничный экземпляр в файл TIFF, то его загружают в OCR-программу, которая распознает текст, и далее переводят в редактируемый файл. Некоторые приложения позволяют сканировать страницы и преобразовывать содержимое в документ за один шаг.
Хотя технология изначально была разработана для оптического распознавания печатных символов, она также может использоваться для рукописных. Например, почтовые службы, такие как USPS, используют программное обеспечение OCR для автоматической обработки писем и посылок, считывая адрес.
Например, почтовые службы, такие как USPS, используют программное обеспечение OCR для автоматической обработки писем и посылок, считывая адрес.
Области применения OCR
Вам будет интересно:Замена Microsoft Office: альтернативные системы, рейтинг лучших, рекомендации и отзывы
OCR расшифровывается, как Оптическое Распознание Символов. Это широко распространенная технология распознавания текста внутри изображений в виде отсканированных документов и фотографий. Технология используется для преобразования практически любого типа изображений, содержащих письменный, рукописный или напечатанный текст в машиночитаемые текстовые данные.
OCR стала популярной в начале 1990-х годов при попытке оцифровки исторических материалов. С тех пор метод претерпел значительные улучшения, и в настоящее время обеспечивает практически идеальную точность оптического распознавания символов. Расширенные методики, такие как Zonal OCR, используются для автоматизации сложных рабочих процессов на основе преобразования машинописных текстов в цифровые документы.
Вам будет интересно:Lightshot: как пользоваться программой
До того как появилась эта технология, единственным вариантом оцифровки печатных документов был ручной набор текста. Это не только занимало много времени, но и приводило к неточностям и ошибкам при воспроизведении копии. OCR часто используется в качестве «скрытой» технологии во многих известных системах и службах, включающих автоматизацию ввода данных и индексацию для поисковых систем, автоматическое оптическое распознавание символов номерных знаков, а также помощь слепым и слабовидящим людям.
Процесс определения точности текста
Каждый шаг процесса OCR важен для определения точности окончательного текста. Он начинается с преобразования печатного документа. Если на нем есть следы, пятна и плохая контрастность, программное обеспечение при распознавании будет делать ошибки, а результат получится некорректным. Чтобы избежать этих проблем, можно сделать улучшенную ксерокопию печати.
Чтобы избежать этих проблем, можно сделать улучшенную ксерокопию печати.
Первый шаг работы – сканирование распечатанного текста. Программное обеспечение OCR работает с файлами изображений. Сканер или хорошая цифровая камера создают четкие фотокопии документов. Лучше преобразовать отсканированные файлы в черно-белом формате. Процесс является двоичным. С помощью черного цвета на картинке происходит распознавание текста OCR, а белый, в свою очередь, выступает фоном.
Вам будет интересно:Программы для учебы: обзор. Обучающие программы для школьников
Вторым этапом является определение символов. Скорость этого процесса зависит от используемой программы OCR. Большинство из них анализируют каждый элемент один за другим. Целью приложения является определение знаков, но хорошие программы распознают не только текст, но и таблицы, и другие элементы макета.
Процесс не идеален, так как есть много факторов, которые влияют на точность. Какие программы предназначены для оптического распознавания символов, рассмотрим ниже.
Последний этап – сохранение готового документа в нужном формате. Если приложение не выдает необходимый, то можно воспользоваться многочисленными бесплатными конвекторами онлайн.
Оптическая технология для Брайля
Технология Optical Character Recognition (OCR) предоставляет слепым или слабовидящим людям возможность определить текст и произносить его вслух. При этом используется речевой вывод, а также отображается информация на дисплее Брайля.
Существует три основных элемента систем оптического распознавания символов: получение изображения, распознавание и чтение текста. Сначала распечатанный документ захватывается камерой, затем программное обеспечение OCR преобразует его в распознанные символы и слова, а после этого синтезатор в системе произносит определенный материал вслух или отображает на дисплее Брайля. Информация может быть сохранена в электронном формате на устройстве, на котором запущено ПО OCR, или в памяти автономного устройства.
Информация может быть сохранена в электронном формате на устройстве, на котором запущено ПО OCR, или в памяти автономного устройства.
Процесс учитывает логическую структуру языка. Система сделает вывод, что, например, союз «этом» в начале предложения является ошибкой и должен читаться, как «это». Она использует лексикон и применяет методы проверки правописания, аналогичные тем, которые используются во многих текстовых редакторах.
Все системы OCR создают временные файлы, содержащие символы и макет страницы. В некоторых системах они могут быть преобразованы в форматы, которые можно найти с помощью широко используемых компьютерных приложений, таких как текстовый редактор, электронная таблица и базы данных.
Выбор программ для распознавания текста
Рекомендуется осознано подойти к выбору программного обеспечения для распознавания текста. Лучше провести собственное тестирование или учесть мнение продвинутых пользователей.
Тестирование проводят с учетом следующих факторов:
 Тем не менее нереально ожидать 100 % точности от приложения для распознавания рукописного текста. Такие факторы, как качество оригинальных документов и разрешение картинки существенно влияют на конечный результат. Хорошие OCR достигают 98 % при использовании современного сканера и исходников в удовлетворительном состоянии.
Тем не менее нереально ожидать 100 % точности от приложения для распознавания рукописного текста. Такие факторы, как качество оригинальных документов и разрешение картинки существенно влияют на конечный результат. Хорошие OCR достигают 98 % при использовании современного сканера и исходников в удовлетворительном состоянии. У людей очень разные почерки. Некоторые пишут аккуратно, в то время как большинство почерков недостаточно разборчивы. Качественные OCR могут распознавать любой почерк. Поэтому для архивации рукописного материала, потребуются программы для рукописного текста.
У людей очень разные почерки. Некоторые пишут аккуратно, в то время как большинство почерков недостаточно разборчивы. Качественные OCR могут распознавать любой почерк. Поэтому для архивации рукописного материала, потребуются программы для рукописного текста. Такие приложения сохраняют столбцы, таблицы и графические изображения, как в исходном варианте.
Такие приложения сохраняют столбцы, таблицы и графические изображения, как в исходном варианте.Популярное ПО для мобильных устройств
Вам будет интересно:Что такое в “Фотошопе” смарт-объект? Его назначение
OCR отлично подходит для переноса текста из физических источников непосредственно в цифровой документ. Существуют различные типы программ и приложений для настольных и мобильных устройств. Они различны по цене и имеют свои ключевые отличительные функции.
Наиболее популярные “Андроид”-сканеры:
 Отличительной чертой является то, что он поддерживает 46 языков, выходной документ весит не более 5 МБ, его легко преобразовать в Microsoft Word, Excel или обычный текстовый формат. После регистрации можно конвертировать многостраничные PDF, RTF, Excel и файлы размером до 100 МБ. Для больших объемов распознавания есть платная версия.
Отличительной чертой является то, что он поддерживает 46 языков, выходной документ весит не более 5 МБ, его легко преобразовать в Microsoft Word, Excel или обычный текстовый формат. После регистрации можно конвертировать многостраничные PDF, RTF, Excel и файлы размером до 100 МБ. Для больших объемов распознавания есть платная версия.Документы Google
Для тех, кто уже знаком с документами Google, можно использовать OCR, встроенный в Google Drive. Для достижения наилучших результатов шрифт должен быть установлен на Arial или Times New Roman. Можно улучшить результат, убедившись, что сканированное изображение имеет равномерное освещение и четкую контрастность. Фотоматериалы могут обрабатываться индивидуально в файлах: jpg, png, gif или в многостраничных документах PDF. Расширение поддерживает большинство языков.
У Google есть много обучающих программ и возможностей облачной обработки. Многие пользователи считают, что у сервиса нет достаточно продвинутых функций и опций.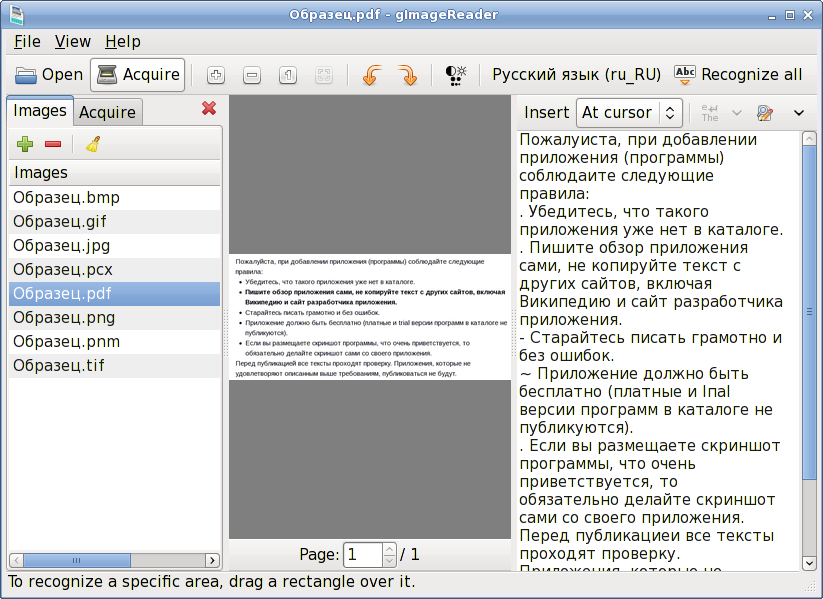 Тем не менее, если используется приложение Google Drive для Android, можно сканировать страницы прямо из приложения, используя камеру на смартфоне. В противном случае загружают документы с помощью сканера, подключенного к компьютеру, или любым другим способом, чтобы начать обработку распознавания в Google Диске. Для физических лиц на Google Диске предлагается бесплатный уровень хранения около 19 ГБ с возможностью расширения до 100 ГБ через Google One за 1,99 долл. США.
Тем не менее, если используется приложение Google Drive для Android, можно сканировать страницы прямо из приложения, используя камеру на смартфоне. В противном случае загружают документы с помощью сканера, подключенного к компьютеру, или любым другим способом, чтобы начать обработку распознавания в Google Диске. Для физических лиц на Google Диске предлагается бесплатный уровень хранения около 19 ГБ с возможностью расширения до 100 ГБ через Google One за 1,99 долл. США.
Оптическое распознавание Abbyy
Abbyy FineReader работает с документами уже давно. Это комплексное решение, как для бизнеса, так и для обычных пользователей. В нем можно получить все необходимые функции для извлечения содержания текстов из сканера с полной читаемостью, аккуратно организованные оцифрованные материалы. Помимо распознавания текстов и преобразования в PDF, Microsoft Office или другие форматы, программа также может сравнивать их, добавлять аннотации и комментарии.
Abbyy FineReader может конвертировать материал в пакетном режиме и обрабатывать множество выходных форматов на 192-х различных языках. Есть сопутствующие мобильные приложения, когда нужно выполнить быстрое сканирование с телефона.
Есть сопутствующие мобильные приложения, когда нужно выполнить быстрое сканирование с телефона.
Программное обеспечение не самое современное, но оно простое, функциональное и отлично справляется со своей работой. Утилита имеет прочную репутацию одного из лучших вариантов в области оптического распознавания символов. Можно воспользоваться бесплатной пробной версией. ПО стоит от 199,99 долл. США за стандартную разовую бессрочную лицензию.
Если кому-то покажется это дорогим вариантом, можно воспользоваться хорошей альтернативой ABBYY FineReader – онлайн версией. Она ограничена тем, что позволяет сканировать только 10 страниц в месяц. Но поставляется со всеми другими функциями премиум-версии. Потребуется регистрация, чтобы получить доступ. Она поддерживает очень много форматов входных файлов, и можно выбрать выходные, такие как PDF, Word, Excel, PowerPoint и e-Pub.
Облачный сервис Adobe Acrobat
Adobe Acrobat отвечает всем требованиям и предлагает впечатляющий список возможностей и опций, хотя цена немного круче, чем у конкурентов. Для всех функций оптического распознавания текста выбирают Pro версию Adobe Acrobat. DC означает «Облако документов», и довольно четко интегрируется с облачным решением Adobe, если нужно получить доступ к своим файлам с любого компьютера. Также есть простая и бесшовная интеграция со всем остальными сервисами Adobe, например, таким как Photoshop.
Для всех функций оптического распознавания текста выбирают Pro версию Adobe Acrobat. DC означает «Облако документов», и довольно четко интегрируется с облачным решением Adobe, если нужно получить доступ к своим файлам с любого компьютера. Также есть простая и бесшовная интеграция со всем остальными сервисами Adobe, например, таким как Photoshop.
Если пользователь решит оплатить Pro версию Adobe Acrobat DC, он получит все инструменты распознавания текста, возможность добавлять комментарии и отзывы к содержанию, специализированный сервис для сканирования таблиц, возможность быстрого сравнения двух документов вместе. Материалы можно редактировать прямо на экране через несколько секунд после их сканирования.
Знак Adobe гарантирует определенный уровень качества, и пользователи впечатлены интуитивностью и возможностями Adobe Acrobat DC. Подписка на сервис начинается с 12,99 долл. США.
Лучшее бесплатное программное обеспечение
Free OCR to Word – это лучшее бесплатное программное обеспечение для оптического распознавания символов, использующее новейшие механизмы.
Вам будет интересно:VMware – что это? Описание, установка, применение
Двигатель Tesseract был первоначально разработан Hewlett Packard Labs в 1985-1994 годах. Некоторые изменения были внесены в него в 1996 году. В 1995 году он был включен в тройку лучших механизмов распознавания. Он работает с Windows, Linux и Mac OS X. FreeOCR может обрабатывать изображения, имеющие многоколонный и многоязычный текст. Он обрабатывает форматы PDF и поддерживает устройства TWAIN такие, как сканеры, имеет широко распространенный интерфейс с двойным окном, настройки которого легко понять.
Free OCR to Word может сэкономить много времени без необходимости повторного ввода уже написанного произведения. Программа берет документ, отсканированный объект или изображение и преобразует его в читаемый, редактируемый и точный материал. ПО можно бесплатно загрузить в Word. OCR to Word оптимизирован для работы со всеми типами сканеров и имеет рейтинг точности 98 %, современный интерфейс, который позволяет легко получить доступ ко всем задачам, имеются функции поворота на случай, если фото не помещается на экране правильно. ПО извлекает текст из захваченных снимков с помощью смартфонов или цифровых камер с высокой точностью и качеством.
Программа берет документ, отсканированный объект или изображение и преобразует его в читаемый, редактируемый и точный материал. ПО можно бесплатно загрузить в Word. OCR to Word оптимизирован для работы со всеми типами сканеров и имеет рейтинг точности 98 %, современный интерфейс, который позволяет легко получить доступ ко всем задачам, имеются функции поворота на случай, если фото не помещается на экране правильно. ПО извлекает текст из захваченных снимков с помощью смартфонов или цифровых камер с высокой точностью и качеством.
Распознавание символов в Linux
Набор OCRFeeder предоставляет удобный графический интерфейс Linux, который в основном является внешним интерфейсом для некоторых изображений, OCR и текстовых инструментов таких, как распечатка или проверка орфографии. Он не считывает символы сам по себе, но вместо этого использует другие приложения OCR через так называемые настройки «механизмов распознавания». Он имеет предопределенные параметры для Tesseract, CuneiForm, GOCR и Ocrad.
Пользователю нужно только установить в Ubuntu выбранные им движки – один или несколько и затем обнаружить их в настройках Feeder. Можно добавить другие движки и изменить эти параметры вручную. В одном приложении может быть несколько разных движков. Главное окно Feeder позволяет на лету выбрать, какой их них использовать для конкретной области, также есть настройка для выбора одного по умолчанию. Для выбора языка прочитанного текста, в случае с Tesseract и CuneiForm, необходимо добавить переключатель «-l» с соответствующим кодом языка / скрипта, например, «-l pol» для польского или «-l dan-frak» для датского к настройкам данного движка
Технология оптического распознавания печатных символов “Тессеракт” в начале могла распознавать текст только на английском языке, версия 2.x сделала ее многоязычной. При необходимости можно установить более одного словаря. Новые версии оцифровывают текст на основе ISO 963-2.
После успешной установки используют команду “tesseract>путь к изображению>базовое имя выходного файла”. Tesseract автоматически придаст выходному документу расширение “.txt”, можно указать опцию “-l”, за которой следует код языка. Для версий Tesseract более ранних, чем третья, очень важно, чтобы изображение было в формате файла тегового значения и имело расширение “.tif”, а не “.tiff”. Командная строка должна выглядеть следующим образом:”$ tesseract ~ / input.tif output”.
Tesseract автоматически придаст выходному документу расширение “.txt”, можно указать опцию “-l”, за которой следует код языка. Для версий Tesseract более ранних, чем третья, очень важно, чтобы изображение было в формате файла тегового значения и имело расширение “.tif”, а не “.tiff”. Командная строка должна выглядеть следующим образом:”$ tesseract ~ / input.tif output”.
Где “input.tif” – это документ для преобразования, расположенный в домашней папке, а “output” – материал, который Tesseract создаст, как “output.txt”. Часто отсканированные тексты хранятся в виде растрового рисунка в большом документе PDF. Используя ImageMagick, отдельные страницы могут быть извлечены в виде файлов TIFF для обработки с Tesseract. Следующий скрипт может помочь автоматизировать этот процесс.
Программа CuneiForm – это еще одна система оптического распознавания текста, которая была первоначально разработана и основана на открытых источниках Cognitive Technologies. Версия Windows, которая имеет собственный графический интерфейс, может быть запущена с некоторыми результатами в Wine. Его порт Linux разрабатывается на Launchpad и хотя в настоящее время у него нет собственного графического интерфейса, CuneiForm может быть успешно запущен из графического интерфейса OCRFeeder.
Его порт Linux разрабатывается на Launchpad и хотя в настоящее время у него нет собственного графического интерфейса, CuneiForm может быть успешно запущен из графического интерфейса OCRFeeder.
Ниже приведен пример, как успешно преобразовать некоторые скриншоты изображений .jpeg доски объявлений в Интернете в полезные текстовые файлы.
Pdfocr – это скрипт, который выполняет OCR для многостраничных файлов PDF, а также внедряет его обратно в виде текстового слоя с возможностью поиска. Он может использовать “Тессеракт” или клинопись в качестве механизма распознавания. Сам скрипт может быть получен из Github или из PPA. Чтобы запустить команду, прописывают в терминале: “pdfocr -i input.pdf -o output.pdf”.
Технология OCR не стоит на месте, в перспективе признание интеллектуальной системы оптического распознавания символов – ICR. Этот стандарт является передовым. Большая часть ICR имеет самообучающуюся систему, называемую нейронной сетью, которая автоматически обновляет базу данных для новых образцов почерка. Она расширяет полезность сканирующих устройств для целей обработки документов от распознавания печатного текста (функция OCR) до рукописных материалов и могут достигать более 97 % степени точности при чтении рукописного материала в структурированных формах.
Она расширяет полезность сканирующих устройств для целей обработки документов от распознавания печатного текста (функция OCR) до рукописных материалов и могут достигать более 97 % степени точности при чтении рукописного материала в структурированных формах.
Источник
Software Reviews — Топ-5 лучших бесплатных программ для распознавания текста — Бесплатное распознавание текста в Word
Допустим, вы хотите отредактировать и проанализировать информацию в книге на своем компьютере. Как бы вы это сделали? Кажется очевидным, что нужно просто отсканировать книгу. Но отсканированный документ — это просто изображение, и мало что можно сделать для редактирования текста на изображении. Поэтому большинство людей в результате вручную перепечатывают текст. Чего эти люди не знают, так это того, что существует технология оптического распознавания символов ( OCR ). Эта технология анализирует печатный текст на изображениях и преобразует его в данные, которые можно редактировать на компьютере. Вот почему мы предоставляем информацию и источники загрузки Лучшее бесплатное программное обеспечение для распознавания текста в этом посте.
Вот почему мы предоставляем информацию и источники загрузки Лучшее бесплатное программное обеспечение для распознавания текста в этом посте.
СОДЕРЖАНИЕ
| Заявленная точность | СКОРОСТЬ | Простусть | Усовершенствованные функции | В целом | Простусть | . | ||
|---|---|---|---|---|---|---|---|---|
| БЕСПЛАТНО OCR к слову | 98% | (5/5) | (5/5) | (4,5 / 5) | (5/5) | (4,5 / 5)(5/5) | (4,5 / 5) | (5/5) |
| Клинопись Open OCR | 100% | (5 / 5) | (3 / 5) | (5 / 5) | (4) | |||
| FreeOCR | 98-99% | (4 / 5) | (5 / 5) | (3 / 5) | (3 / 5) | 9,0|||
| ABBYY FineReader Online | 99,8% | (2 / 5) | (4 / 5) | (3 / 5) | (3 / 5) | |||
| Документы Google | 90%+ | (2 / 5) | (3 / 5) | (9,5 / 5) 3,0039 9,0039 9,0039 |
Когда вам показывают страницу с письменным текстом, подобную этой, она имеет для вас ценность только в том случае, если вы можете распознать язык и прочитать его. Мозг распознает шаблоны символов (буквы, цифры и знаки препинания) и преобразует символы в слова, а слова в предложения.
Мозг распознает шаблоны символов (буквы, цифры и знаки препинания) и преобразует символы в слова, а слова в предложения.
Компьютеры тоже могут распознавать символы и преобразовывать их в текст. Сначала вы должны предъявить компьютеру изображение текста, отсканированный файл или изображение с цифровой камеры. Изображение — это не что иное, как набор пикселей. Другими словами, изображение текста ничем не отличается от изображения Эйфелевой башни. Таким образом, программное обеспечение OCR помогает компьютеру преобразовывать изображение текста в сам текст. Это программное обеспечение преобразует изображения текста в файл DOC или файл TXT. Затем эти форматы можно редактировать и управлять ими с помощью таких программ, как Microsoft Word.
Процесс OCR
OCR включает в себя процесс. Каждый шаг процесса важен для определения точности окончательного текста.
Улучшение печати. Процесс OCR начинается с преобразования печатного документа. Если на нем есть метки, пятна от кофе и плохой контраст, программное обеспечение склонно к ошибкам при распознавании символов.

Отсканируйте документ для печати. Программное обеспечение OCR работает с файлами изображений. Отсканируйте документ, чтобы преобразовать его в изображение. Хорошая цифровая камера является хорошим вариантом, так как она будет производить четкие изображения документов.
Черно-белый (двухцветный). Вы должны преобразовать отсканированные файлы в черно-белые. Процесс OCR бинарный (есть символ или нет). Черный цвет изображения является частью распознаваемого узора, а белый — фоном.
Распознавание символов. Следующий этап — оптическое распознавание символов. Скорость этого процесса зависит от используемой программы OCR. Большинство из этих программ анализируют каждый символ на изображении один за другим. Цель программ OCR — распознавание символов, но хорошие программы распознают изображения, таблицы и другие элементы макета в отсканированных документах.

Исправление ошибок. Процесс не идеален, так как существует множество факторов, которые могут повлиять на точность. Программы OCR имеют встроенные средства проверки орфографии и выделяют любое слово с потенциально ошибочным написанием. Некоторые из этих программ настолько сложны, что выделяют несоответствие слов и грамматические ошибки.
Обычно так работает процесс OCR. Всегда корректируйте окончательную работу, особенно если исходный документ был плохого качества.
9Программное обеспечение 0002 OCR имеет много преимуществ для бизнеса, студентов, юристов, медицинских работников и многих других людей. Вот 5 основных причин, по которым вам нужно программное обеспечение для распознавания текста.
Избегайте повторного ввода
Альтернативой технологии OCR является ручной набор текста. Перепечатывать уже существующую работу утомительно и тратить драгоценное время. С OCR вам больше не нужно перепечатывать что-либо, что уже существует.

Редактировать печатный текст
После того, как программа OCR отсканирует и преобразует файлы изображений в текст, вы можете легко редактировать текст. Вы можете добавлять новую информацию и даже добавлять изображения к исходному тексту.
Выполнение быстрого цифрового поиска
Отсканированные документы теперь можно сохранять как текстовые документы. В этом формате вы можете легко выполнить быстрый поиск по ключевой фразе. Секретарям больше не нужно просматривать горы файлов, чтобы найти счет.
Освободить место
Работа с документами, особенно в деловой обстановке, может занимать физическое пространство. После того, как вы отсканируете все документы и сохраните их в doc. или PDF, вам больше не нужны файлы и картотеки. Таким образом, вы сэкономите много места в офисе.
Быстрый доступ к информации
Сохранение документов в цифровом виде не только экономит место в офисе, но и обеспечивает быстрый доступ к документам.
 Кроме того, к этим файлам можно получить доступ удаленно.
Кроме того, к этим файлам можно получить доступ удаленно.
Мы не просто случайным образом выбрали лучшее бесплатное программное обеспечение для распознавания текста. Мы протестировали и пересмотрели каждое программное обеспечение с учетом следующих факторов:
Точность
Точность отличает хорошую программу OCR от плохой. Тем не менее, нереально ожидать 100% точности от любого программного обеспечения OCR. Такие факторы, как качество исходных отсканированных документов и качество самого сканера, сильно влияют на конечный результат. Хорошие программы OCR всегда достигают 98% при использовании с хорошим сканером и с оригинальными документами в отличном состоянии. Пока вы не протестируете программу, всегда относитесь к заявлениям производителя о точности с недоверием.
Многоязычная поддержка
Некоторые программы OCR распознают более одного языка. Такие программы должны быть вашим выбором, если вы будете сканировать документы на другом языке. Программное обеспечение OCR сканирует отдельный символ, чтобы определить, какая это буква. Программное обеспечение, запрограммированное на распознавание только английских символов, не будет точно интерпретировать специальные символы, такие как β, или буквы с диакритическими знаками, такие как é. Такое программное обеспечение будет представлять эти символы с ближайшим эквивалентом на английском языке.
Программное обеспечение OCR сканирует отдельный символ, чтобы определить, какая это буква. Программное обеспечение, запрограммированное на распознавание только английских символов, не будет точно интерпретировать специальные символы, такие как β, или буквы с диакритическими знаками, такие как é. Такое программное обеспечение будет представлять эти символы с ближайшим эквивалентом на английском языке.
При использовании программного обеспечения, поддерживающего несколько языков, необходимо указать язык документа, чтобы он мог точно выполнять распознавание символов.
Поддержка рукописного ввода
Печатный текст (распечатанный на принтере) легко распознается любой программой OCR. Однако рукописный текст — совсем другое испытание. У людей очень разный почерк. Некоторые пишут аккуратно, в то время как большинство почерков недостаточно разборчивы для людей, не говоря уже о компьютерах. Однако приличные программы OCR могут распознавать аккуратно написанный от руки текст. Итак, если вы собираетесь архивировать рукописные документы, ищите программы OCR, которые распознают рукописный текст.
Итак, если вы собираетесь архивировать рукописные документы, ищите программы OCR, которые распознают рукописный текст.
Уровень автоматизации
Программное обеспечение OCR может работать автоматически или в интерактивном режиме. Если вам нужно сканировать много документов одновременно, вам следует рассмотреть программы OCR, которые запускаются автоматически. С такой программой в несколько кликов вы начинаете сканировать документы, переходите к другим задачам и возвращаетесь, чтобы найти редактируемый файл PDF, txt или doc. Большинство бесплатных программ OCR имеют ограниченную автоматизацию. Однако вы обнаружите, что интерактивный ввод дает наиболее точные результаты.
Сохранение макета
Основной целью этих программ является преобразование текста изображения в текст. Некоторые не сохранят макет исходного документа. Поэтому вам придется много редактировать в окончательной копии. Хорошая программа должна сохранять исходную компоновку, чтобы в окончательной копии не требовалось незначительного редактирования. Некоторые из рассмотренных ниже программ сохранят столбцы, таблицы и графические изображения исходного документа.
Некоторые из рассмотренных ниже программ сохранят столбцы, таблицы и графические изображения исходного документа.
После опробования и тестирования различных программ, основанных на факторах, изложенных выше, вот обзоры лучших бесплатных программ для оптического распознавания текста.
1. Бесплатное распознавание текста в Word
Бесплатное распознавание текста в Word — это лучшее бесплатное программное обеспечение для распознавания текста, которое открывает широкий спектр форматов файлов изображений и преобразует текст на изображениях в редактируемый текст. Он имеет интуитивно понятный пользовательский интерфейс, который обеспечивает быстрый доступ ко всем функциям. Функция «Открыть» позволяет открывать изображения, уже сохраненные на вашем компьютере. Функция «сканирования» позволяет программному обеспечению напрямую сканировать файлы в подключенном сканере. Программное обеспечение хорошо работает со сканерами всех основных производителей. Отсканированный файл или изображение отображается в левом окне.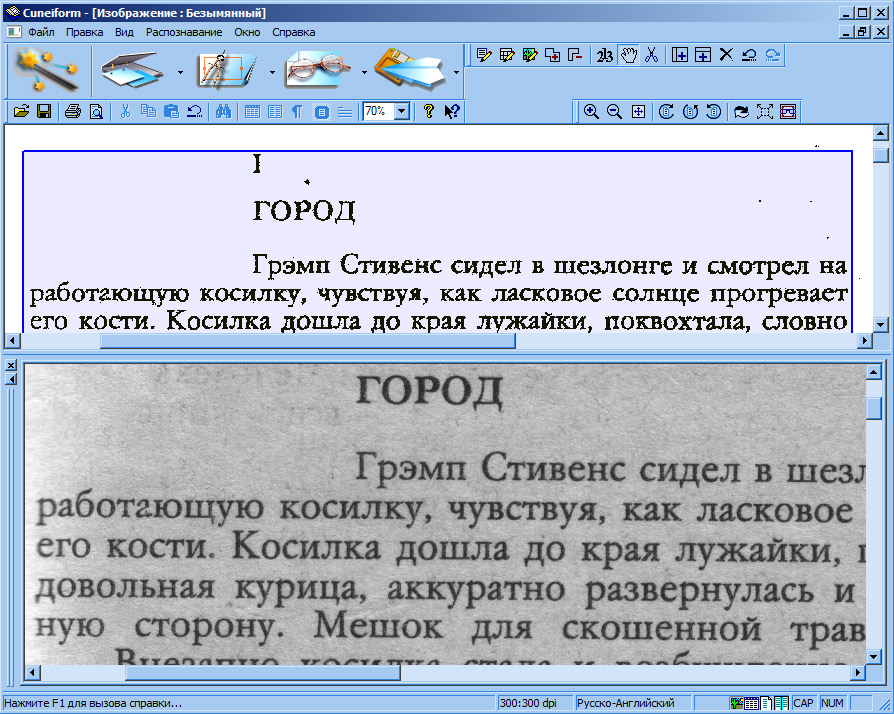
Функция «OCR» быстро отобразит любой распознанный текст в правом окне. Затем вы можете сохранить распознанный текст в виде файла TXT или файла .doc. Если вас не устраивают результаты, вы можете использовать ярлык «очистить текст в правом окне» и снова сгенерировать текст.
Точность конечного текста зависит от состояния исходного документа. Вам придется вычитывать окончательный текст и исправлять все опечатки.
Плюсы
Быстрое распознавание текста
Получить редактируемый текст всего за 3 шага
Неограниченное распознавание символов
Минусы
Скачать бесплатно OCR в Word
2. Клинопись OpenOCR
Клинопись OpenOCR изначально был коммерческим продуктом, но теперь доступен бесплатно. Он имеет идеальный механизм распознавания текста, хотя может показаться, что это не так из-за устаревшего пользовательского интерфейса. Вы можете открывать файлы изображений, сохраненные на компьютере, или напрямую сканировать изображения со сканера. Перед процессом распознавания исходное изображение можно поворачивать, увеличивать и уменьшать, а также конкретную область на изображении, выбранную для распознавания.
Поскольку он распознает 20 языков, используйте мастер распознавания, чтобы указать язык ввода. После процесса OCR вы можете использовать функцию проверки орфографии, чтобы исправить орфографические ошибки из доступных предложений. Это программное обеспечение распознает таблицы и изображения и сохраняет их в отдельный файл. Кроме того, он сохраняет исходный макет, текст и стили форматирования, такие как выделение полужирным шрифтом и курсивом. Вы можете отредактировать сгенерированный текст или сохранить его для последующего редактирования или экспортировать в другую программу, например Microsoft Word.
Плюсы
Сохранение макета
Распознает изображения и таблицы
Многоязычная поддержка
Проверка орфографии
Высокая точность результатов
Минусы
https://cognitive-openocr-cuneiform. forumer.it/
3. FreeOCR
Первая FreeOCR — это мощная программа, разработанная на основе Tesseract Engine. HP Labs, но в настоящее время поддерживается Google. Это программное обеспечение сканирует изображения по одному, но может выполнять пакетное сканирование файлов PDF. На выходе обычный текст. Он не сохраняет форматирование или макет исходного документа. Он может сканировать прямо со сканера и позволяет использовать простые функции предварительного просмотра изображения, такие как вращение и масштабирование.
Имеет интуитивно понятный пользовательский интерфейс. Функции Scan, Open и OCR легко найти. Точность результатов впечатляет. Чтобы избежать проблем с макетом, выберите блок текста, который программа должна распознавать, и выберите «обрезать изображение по выделенной области». Одним из основных плюсов этого программного обеспечения является то, что оно поддерживает 11 языков.
Плюсы
Высокая точность
Многоязычная поддержка
Интуитивно понятный пользовательский интерфейс
Вывод в формате RTF и .
 doc
doc
Минусы
https://www.free-ocr.com/
4. ABBYY FineReader Online
ABBYY FineReader — это программа оптического распознавания символов премиум-класса со всеми необходимыми функциями и функциями. . Это быстро и точно, и может справиться с большими объемами работы. Он имеет расширенную проверку орфографии и другие инструменты исправления. Но это дорого, что делает ABBYY FineReader онлайн хорошей альтернативой.
Онлайн-версия ограничена тем, что позволяет сканировать только 10 страниц в месяц. Но он поставляется со всеми другими функциями премиум-версии. Тем не менее, вы должны зарегистрироваться, чтобы получить доступ к бесплатной онлайн-версии. Он поддерживает очень много форматов входных файлов, и вы можете выбрать выходные форматы, такие как PDF, Word, Excel, PowerPoint и e-Pub.
Плюсы
Поддерживает 193 языка
Сохранение исходящих файлов в облачных хранилищах, таких как Google Drive, Box и OneDrive
Много вариантов вывода
Онлайн-сервис; нет необходимости в установке
Распознает столбцы, таблицы и изображения
Минусы
http://finereaderonline. com/en-us
5. Google Docs
Google Docs более популярен как текстовый процессор, чем как программа для распознавания текста. Google внедрил механизм OCR, который он использует для сканирования онлайн-книг и PDF-файлов в Документах. Возможности распознавания документов ограничены, поскольку вы можете сканировать только загруженные файлы, а не файлы непосредственно со сканера. Используйте кнопку «Загрузить», чтобы импортировать файлы, которые вы хотите использовать для распознавания текста. В диалоговом окне установите флажок «Преобразовать текст из файлов PDF и изображений в документы Google». После завершения загрузки файла он появляется в виде текстового документа, который вы можете редактировать. Все изменения автоматически сохраняются на Google Диске.
Плюсы
Веб-сервис (установка не требуется)
Преобразование неограниченного количества файлов в текст
Высокая точность
Минусы
Нет распознавания макета
Нет автоматизированных функций
Использование лучшего бесплатного программного обеспечения для оптического распознавания текста — это самый простой способ преобразовать книги, журналы и другие печатные и рукописные материалы в цифровой формат. Существует множество программ для оптического распознавания текста, некоторые платные, некоторые бесплатные. Рассмотренные здесь — лучшее бесплатное программное обеспечение для распознавания текста. Все они удовлетворяют основным функциям, необходимым для программного обеспечения OCR. При выборе вам нужно спросить себя: «Что мне нужно, чтобы программное обеспечение OCR делало?»
Подпишитесь на нас и поставьте нам лайк:
Изучение лучшего бесплатного программного обеспечения для оптического распознавания текста в Интернете: KlearStack AI
OCR или оптическое распознавание символов — это технология, позволяющая извлекать редактируемый текст из физических или цифровых документов. Причина, по которой мир нуждается в оптическом распознавании символов сегодня больше, чем когда-либо, заключается в том, что у нас есть тонны данных, хранящихся в разных файлах, но нет простого способа извлечь их для значимых целей. С OCR вся эта процедура автоматизируется. Переписывание текста с изображений — это не тот способ, которым сегодня компании могут справиться с большим потоком документов, и только хорошее программное обеспечение для оптического распознавания символов может спасти вас от этой ситуации. Программное обеспечение также должно быть таким, чтобы потребность в человеческом вмешательстве для исправления ошибок была устранена или сведена к минимуму. Современное программное обеспечение OCR эффективно обеспечивает обе эти функции, и именно поэтому все больше и больше людей обращаются к ним.
Лучшее бесплатное онлайн-программное обеспечение для распознавания текста 2023
● SimpleOCR
SimpleOCR предлагает одну из лучших бесплатных функций распознавания рукописного ввода. Однако эта конкретная функция является частью только 14-дневной бесплатной пробной версии и, конечно же, доступна в их коммерческой версии. Хотя другие функции, такие как машинное распознавание текста, бесплатны для всех. Единственная проблема заключается в том, что программное обеспечение не имеет регулярных обновлений, а его последняя версия читается как SimpleOCR 3.1. Наконец, как следует из названия, программное обеспечение имеет очень простой интерфейс, поэтому у вас не возникнет проблем с извлечением данных с помощью SimpleOCR. Однако его обработка документов со сложными макетами нуждается в значительном улучшении. Это программное обеспечение имеет множество эксклюзивных функций, таких как игнорирование текста, выбор текста, выбор изображения и т. д., поэтому оно попало в наш список лучших бесплатных онлайн-программ для распознавания текста.
Однако его обработка документов со сложными макетами нуждается в значительном улучшении. Это программное обеспечение имеет множество эксклюзивных функций, таких как игнорирование текста, выбор текста, выбор изображения и т. д., поэтому оно попало в наш список лучших бесплатных онлайн-программ для распознавания текста.
● Microsoft OneNote OCR
Расширенное и обновленное программное обеспечение OCR, позволяющее извлекать данные как из печатных, так и из рукописных документов. Вам просто нужно просмотреть и открыть отсканированный документ или изображение в приложении Microsoft OneNote. Затем просто щелкните правой кнопкой мыши изображение или отсканированное изображение и выберите параметр «Копировать текст с изображения». Таким образом, текст в документе или изображении будет автоматически скопирован в буфер обмена. Качество извлечения данных зависит в первую очередь от качества распечатки или изображения. По этой причине многие пользователи жаловались на неточные результаты при использовании Microsoft OneNote для рукописных документов. Если в таких случаях у приложения есть сомнения, общая производительность достаточно хороша, чтобы держать его в нашем списке лучших бесплатных программ для оптического распознавания текста.
Если в таких случаях у приложения есть сомнения, общая производительность достаточно хороша, чтобы держать его в нашем списке лучших бесплатных программ для оптического распознавания текста.
● Capture2Text OCR
Что может быть лучше, чем иметь приложение для Microsoft, которое дает вам горячие клавиши для извлечения OCR? Программное обеспечение не требует какой-либо специальной установки, и для доступа к технологии OCR будет достаточно использовать сочетания клавиш по умолчанию. Преобразованное изображение документа автоматически появится в виде всплывающего окна при нажатии сочетания клавиш. Далее оцифрованный текст также будет скопирован в буфер обмена. Поскольку оно использует механизм OCR от Google, приложение поддерживает более 100 языков, и его точность также велика.
● Google Docs OCR
Если вы хотите воспользоваться преимуществами облачных вычислений и OCR, попробуйте встроенную функцию распознавания документов Google Docs. Эта функция OCR от Google распознает текст в файлах различных форматов, таких как JPG, GIF, PDF, DOCX и т. д. Кроме того, это предложение OCR от Google Drive также способно распознавать язык текста. Единственный недостаток, однако, заключается в том, что размер файлов, из которых вы хотите извлечь данные, не должен превышать 2 МБ.
Эта функция OCR от Google распознает текст в файлах различных форматов, таких как JPG, GIF, PDF, DOCX и т. д. Кроме того, это предложение OCR от Google Drive также способно распознавать язык текста. Единственный недостаток, однако, заключается в том, что размер файлов, из которых вы хотите извлечь данные, не должен превышать 2 МБ.
● FreeOCR
Приличное программное обеспечение для оптического распознавания символов, специально созданное для Windows, FreeOCR оснащено оптическим распознаванием Google. Интерфейс программного обеспечения только добавляет удовольствия от использования FreeOCR. Как и любое хорошее программное обеспечение для распознавания текста, FreeOCR позволяет извлекать как файлы PDF, так и изображения. Другие функции, такие как многократная пакетная обработка и сохранение извлеченных или отсканированных файлов непосредственно в формате PDF, являются заметными предложениями программного обеспечения FreeOCR.
Безопасно ли использовать бесплатное программное обеспечение OCR?
Ценность любого программного обеспечения для оптического распознавания символов не полностью зависит от точности результатов, которые оно обеспечивает. Определенно, вам нужен точный вывод, чтобы процесс действительно занимал меньше времени. Однако вы также хотели бы, чтобы ваши данные оставались в безопасности, когда происходит вся эта обработка. Для любого бесплатного программного обеспечения OCR наиболее важным фактором с точки зрения безопасности является то, соответствует ли поставщик услуг GDPR (Общий регламент по защите данных) и ISO 27001 или нет. Эти соответствия чрезвычайно важны для подтверждения того, что поставщик бесплатных услуг оптического распознавания символов неукоснительно соблюдает правила и нормы безопасности данных. Суть в том, что любой бесплатный поставщик услуг OCR, который не соответствует этим правилам, небезопасен для извлечения данных из ваших конфиденциальных и секретных данных.
Определенно, вам нужен точный вывод, чтобы процесс действительно занимал меньше времени. Однако вы также хотели бы, чтобы ваши данные оставались в безопасности, когда происходит вся эта обработка. Для любого бесплатного программного обеспечения OCR наиболее важным фактором с точки зрения безопасности является то, соответствует ли поставщик услуг GDPR (Общий регламент по защите данных) и ISO 27001 или нет. Эти соответствия чрезвычайно важны для подтверждения того, что поставщик бесплатных услуг оптического распознавания символов неукоснительно соблюдает правила и нормы безопасности данных. Суть в том, что любой бесплатный поставщик услуг OCR, который не соответствует этим правилам, небезопасен для извлечения данных из ваших конфиденциальных и секретных данных.
KlearStack OCR Advantage
Klearstack — одно из самых известных имен в области программного обеспечения OCR на сегодняшний день. Наше строгое соблюдение всех правил, касающихся безопасности данных, делает программное обеспечение OCR KlearStack одним из самых безопасных для работы с конфиденциальными бизнес-данными.