
Тексты с орфографическими ошибками. Русский язык, 4 класс.
Найди и исправь орфографические ошибки.
Время лесных малышей
Пришло теплое лето. На лисной опушки распускаюца колоколчики, незабутки, шыповник. Белые ромашки пратягивают к сонцу свои нежные лепески. Вылитают из уютных гнёзд птинцы. У зверей взраслеет смена. Мидвежата старше всех. Они радились еще холодной зимой в берлоги. Теперь они послушно следуют за строгай матерью. Рыжые лесята весело играют у нары. А кто мелькает в сасновых ветках? Да это лофкие бельчята совершают свои первые высотные прышки. В сумерках выходят на охоту колючии ежата.
Не обижайте лесных малышей. Приходите в лес верными друзями.
(По Н. Надеждиной)
Солнце
Выплыла из-за леса сонце. Повеселела лесная паляна. Капельки расы заиграли в каждом цветке, в каждой травинки.
Но вот набежала тучя и закрыла всё небо. Загрустила природа. Столп пыли полетел к озиру.
Ежи
Унас под крыльцом живут ежы. По вечерам вся семья выходит гулять. Взрослые ежи роют землю маленькими лапами. Они достают корешки и едят. Маленкие ежата в это время играют, резвяца.
Аднажды к старому ежу подбежала сабака. Ёж свернулся вклубок и замер. Собака осторожно покатила ежа кпруду. Ёш плюхнулся в воду и поплыл. Я прогнал сабаку. На следующюю весну остался под крыльцом один старый ёжек. Куда девались остальные? Они переселились в другое место. Старый ёж незахотел пакинуть мой дом.
Летнее утро
Я стою возле цветущива клеверного поля. Разноцветный ковёр его переливаеца, меняет окраску. В самой дали сияет ослепителным блеском залатая кайма.Взлетел жаворонок. Серый камочек в первых лучах солнца стал золотым. Яркие искры заиграли вкаплях расы на цветах.Что за чудестные звуки разлились по земле? Это подлетели пчёлы. Они зажужали над чяшей цветов. Проснулся кузнечик. Понеслась и его скрепучая музыка. Теперь всё поле поёт. Все рады тёпламу летниму утру. Радосно и мне.
Яркие искры заиграли вкаплях расы на цветах.Что за чудестные звуки разлились по земле? Это подлетели пчёлы. Они зажужали над чяшей цветов. Проснулся кузнечик. Понеслась и его скрепучая музыка. Теперь всё поле поёт. Все рады тёпламу летниму утру. Радосно и мне.
Программа для исправления ошибок в тексте
Для чего нужна программа для исправления ошибок в тексте — рассказывать не нужно. Большинство в школе делать это самостоятельно не научились.
Как неприятно читать статьи, посты, письма, комментарии и тому подобное знаем все. Об авторе складывается впечатление однозначное, если он допускает «ляпы».
Чтобы избавиться от этого, существуют даже онлайн сервисы для исправления ошибок, а не только программы.
Сразу замечу, что эффективность последних намного больше, поэтому и будет уделено внимание им здесь. Их несколько.
Есть лучше, хуже, платные и бесплатные. Больше всего заслуживают внимания три: afterscan, орфо и майкрософт ворд. Поскольку последнему (ворду) они уступают, остановлюсь именно на нем.
Поскольку последнему (ворду) они уступают, остановлюсь именно на нем.
Программа для исправления ошибок в тексте — ворд
На сегодняшний день программа ворд, лучше всего исправляет ошибки в тексте, включая запятые. Причем это все происходит мгновенно. Достаточно поместить в него текст и сразу все видно.
У новичков вначале возникают трудности, как вставить текст в ворд. Это просто. Вначале скопируйте его в буфер обмена, откройте «ворд» и нажмите вверху с левой стороны на желтый значок (по средине между вставить и файл).
Сейчас возможно некоторых читателей разочарую, когда скажу, что программ исправляющих ошибки на 100% — нет.
Такого интеллекта они пока они не достигли, а если это станет возможным, то людям на земле будет делать нечего. Ворд с этими задачами справляется процентов на 90, думаю этого вполне достаточно.
Если прочтете в интернете что «орфо» лучше, не верьте, она интегрирована в ворд вследствие чего, быть таковой не может никак. Между этими размотчиками существует договор о совместной разработке.
Программа для исправления ошибок в тексте: как пользоваться
Сразу, как только вы поместите текст в программу ворд, в случае обнаружения ошибки ортографической, внизу слово будет подчеркнуто волнистой линией.
Когда на него нажать правой кнопкой мыши, вам на выбор, будет предложено несколько вариантов заменены.
Если подчеркивания предложения зеленой волнистой линией, тогда в нем находиться пунктуационная ошибка. Смотрите, как показано на рисунках.
Также учтите, в программе могут не находиться все правильные слова. Поэтому вам всегда будет предоставляться возможность внести их в словарь. Я например, на протяжении года внес более сотни.
Также нельзя не упомянуть о еще одной очень хорошей функции этой программы – синонимы. Как только вы нажмете на любое слово, правой мышкой, вам откроется новое окно.
Подведите курсор к опции «синонимы», и вам будет предложен на выбор список слов похожих по смыслу. Это особенно актуально, когда нужно писать уникальные тексты.
На этом буду заканчивать эту короткую заметку, а возникнут вопросы, пишите в комментариях вот этой статьи: «программа для исправления ошибок в тексте для windows».
Как далеко продвинулся алгоритм исправления ошибок в китайском тексте?
Исправление ошибок – это проблема, которая решалась с самого начала Интернета, но она была скрыта как вспомогательная и вспомогательная функция некоторых важных технологий, таких как поисковые системы, такие как горячее интеллектуальное письмо.
Качество отделки!
Задачи по исправлению ошибок в китайском тексте. Типичные ошибки:
- Однотонные слова, такие как парные очки, парные очки
- Запутанные фонетические слова, такие как Wandering Weaver-Cowherd и Weaver
- Порядок слов обратный, такой как Вуди Аллен-Аллен Вуди
- Завершение слова, например, у любви есть воля, если у любви есть воля
- Китайский пиньинь пиньинь, например xingfu-счастье
- Китайское сокращение пиньинь, такое как Шэньчжэнь
- Грамматические ошибки, такие как трудно представить – трудно представить
В настоящее время алгоритм исправления ошибок делится на два направления: на основе правил, модель глубины
Правила решенияКитайское исправление ошибок разделено на два этапа, первый этап – обнаружение ошибок, а второй – исправление ошибок;
Компонент обнаружения ошибок сначала обрезает слово путем заикания китайского средства разбиения по словам.
Часть исправления ошибок состоит в том, чтобы обойти все предполагаемые позиции ошибок, заменить слова в неправильном положении фонетическим и похожим на форму словарем, а затем вычислить степень путаницы предложений с помощью языковой модели, сравнить и ранжировать все результаты набора кандидатов для получения оптимального исправленного слова.
Решение глубокой моделиСквозная глубокая модель позволяет избежать ручного извлечения функций и снизить нагрузку на ручную работу. Модель последовательности RNN обладает сильной способностью соответствовать текстовым задачам. Rnn_attention заняла первое место в конкурсе по исправлению ошибок на английском языке, что доказывает, что эффект приложения хороший;
CRF вычислит условную вероятность глобального оптимального выходного узла, а обнаружение определенного типа ошибки в предложении будет определять ошибку на основе всего предложения. Али принял участие в задаче по исправлению грамматики китайского языка 2016 года и занял первое место, доказав, что эффект приложения хороший;
Али принял участие в задаче по исправлению грамматики китайского языка 2016 года и занял первое место, доказав, что эффект приложения хороший;
Модель seq2seq использует структуру кодер-декодер для решения проблем преобразования последовательностей и в настоящее время является одной из наиболее широко используемых и наиболее эффективных моделей в задачах преобразования последовательностей (таких как машинный перевод, генерация диалогов, текстовая сводка и описание изображений).
Таким образом, автор только недавно прослушал структуру алгоритма исправления ошибок Baidu и разобрал некоторые материалы, которые он слышал и собирал ранее, следующим образом.
Может ссылаться на Baidu исправление ошибок открытой платформы:
https://ai.baidu.com/tech/nlp/text_corrector
Baidu интеллектуальная система исправления ошибок:
Распространенные ошибки делятся на три категории:
- Неправильная формулировка
- Грамматические и синтаксические ошибки
- Ошибка знаний
Общая структура исправления ошибок Baidu:
Основные ключевые шаги:
- 1 Обнаружение ошибок
- 2 Отзыв кандидата
- 3 Сортировка с исправлением ошибок
1 Обнаружение ошибок:
Позиция первая, что может быть неверно в одном предложении!
2 Отзыв кандидата
Шаги: введите предложение, затем определите возможные точки ошибки в предложении, выполните возврат текста на миллиардные данные в соответствии с этими двумя, и выровняйте кандидатов
3 Сортировка с исправлением ошибок
Куча вспомнил, как выбрать, модель W & D
Три основные технологии
Знание языков, модели
Знание вычислительной релевантности
Исправление ошибок на основе графа знаний, основанного на ассоциации
Знание компьютерных текстов
После того, как намерение понято, слот заполняется, и неправильный POI заполняется в соответствии со слотом
Хорошая система исправления ошибок может предложить пользователю ввести слова запроса для исправления ошибок или отобразить правильные результаты непосредственно пользователю, что повышает интеллектуальность поисковой системы.
Для вертикальных поисковых систем, особенно для небольших вертикальных приложений, способы выполнения исправления ошибок запроса в литературе в основном не обсуждаются. Обычная практика заключается в использовании модели исправления ошибок, обученной веб-поиску в коммерческих поисковых системах, для непосредственного воздействия на вертикальную подсистему. Однако в ходе нашего исследования мы обнаружили, что разные вертикальные сервисы имеют разные цели поиска пользователей, что приводит к тому, что исправление ошибок не является универсальным. Например, пользовательский ввод “dispel star”, в музыкальном бизнесе ошибка должна быть исправлена в одну Песня «Маленькая Звезда» на платформе распространения игрового приложения должна быть исправлена в игровом приложении «Устранить Звезду».
В литературных исследованиях существует два типа традиционных исправлений ошибок в тексте:
- Одним из них является тип исправления ошибок для словесных ошибок.
- Другой неправильный тип «словосочетания»
Раннее исправление ошибок обычно является первым, используя расстояние редактирования для близкого поиска;
Второй тип ошибок заключается в определении наличия ошибки путем обнаружения совпадения контекста записи в запросе с использованием шумовых каналов и языковых моделей в качестве основного метода исправления ошибок. Например, «мир» и «кусок» могут использовать «кусок» только в контексте «торт». В английском языке есть также комбинация двух, чтобы предсказать модель обучения, чтобы исправить символы слова.
Например, «мир» и «кусок» могут использовать «кусок» только в контексте «торт». В английском языке есть также комбинация двух, чтобы предсказать модель обучения, чтобы исправить символы слова.
Семантическая корреляция В вертикальных приложениях и веб-страницах данные ресурса не изолированы, но существует определенная связь.
Давайте сначала рассмотрим несколько примеров. В музыкальном приложении певец “Wu Junyu” спел песню “17-летний сезон дождей”. Эти два источника данных являются своего рода “поющими” отношениями; в видео-приложении телеканал “Hunan Satellite TV” создал Файловая развлекательная программа «Измеритель деформации», эти два ресурса данных представляют собой «производственные» отношения.
Точно так же музыкальный бизнес все еще существует, певец «поет» песни, певец «выпускает» альбомы, альбом «содержит» песни и т. Д .; в видеобизнесе режиссер «снимает» фильм, актер «играет роль» в фильме, а актер «играет роль» Развлекательные программы, режиссеры «снимают» сериалы и т.
- Определение 1: Ресурсные данные. В вертикальном бизнесе данные будут разделены на несколько категорий, и каждая категория может отдельно выражать полный смысл записи. Например, в музыкальном бизнесе данные, охватываемые такими категориями, как песни, певцы, альбомы, mv и тексты песен, являются данными ресурсов.
Определение 2. Связь данных. Если существует определенная связь между двумя данными о ресурсах, существует связь между этими двумя данными о ресурсах.
Определение 3: ассоциированный нагрев – частота, с которой два связанных ресурса действуют совместно. Например, количество щелчков по ним или частота появления в одном и том же абзаце в Интернете.
Ассоциация майнинга
Граф традиционных знаний состоит из троек (спо). Самым большим отличием интеллектуального анализа ассоциаций является то, что только два данных, которые имеют определенные отношения, должны быть добыты, и нет необходимости записывать очень четкие отношения. Общий процесс выглядит следующим образом:
Общий процесс выглядит следующим образом:
Одним из них является синтаксический анализ предложения, поиск субъекта (-ов), предиката (p) и объекта (o) в синтаксическом дереве, а также выбор субъекта (-ов) и объекта (o). ) В качестве кандидатов связанных данных;
Второе – объединить вертикальные данные и журналы запросов, чтобы подсчитать кандидатов, и отфильтровать наиболее часто помещаемые в связанный набор данных.
Коррекция ошибок корреляции обнаружила интересное явление при анализе журналов запросов:
Многие строки запроса часто содержат два или более фрагмента ресурса, и доля этих ошибок запроса очень высока. Причиной анализа должно быть то, что пользователь вводит несколько фрагментов, чтобы получить четкий результат, и он не желает получать список результатов;
И более высокая частота ошибок должна быть расплывчатой в памяти пользователя, и я надеюсь использовать два или более фрагмента ресурса, чтобы получить четкий результат. Но если один или несколько фрагментов содержат ошибки, результат будет очень плохим, поскольку эти фрагменты сами могут представлять собой правильный ресурс.
Например, запрос «Метаморфоза спутникового телевидения Хунань» в видео-приложении содержит два фрагмента ресурса: фильм «Метаморфоза» и телевизионная станция «Спутниковое телевидение Хунань». Оба ресурса верны, и эти два ресурса не связаны. В этой ситуации могут быть ошибки. Что пользователь действительно хочет, так это развлекательная программа «Измеритель деформации» «Хунань Спутниковое ТВ». Правильная форма исправления ошибок должна быть «Запись деформации Хунань Спутниковое ТВ» -> «Измеритель деформации Хунань Спутниковое ТВ». Больше примеров в музыкальном приложении:
Коррекция ошибок ассоциации состоит в том, чтобы использовать связь ассоциации между данными, чтобы определить, есть ли ошибки во множественных сегментах ресурсов, введенных пользователем, и затем выполнить обработку исправления ошибок. Поскольку каждый ресурсный сегмент может быть правильным ресурсом, цель исправления ошибок состоит в том, чтобы найти, существует ли семантическая корреляция между множественными сегментами, поэтому этот тип исправления ошибок является новым типом исправления ошибок.
Мы делим весь процесс на три этапа:
На первом этапе сегментация делится. Разбейте весь запрос на несколько семантических фрагментов, которые можно выразить независимо, и попытайтесь обеспечить целостность ресурсов в процессе сегментации.
Второй шаг – вычислить, есть ли связь между фрагментами. Если есть отношение ассоциации, выйдите, в противном случае найдите результаты кандидата для каждого сегмента. Алгоритм использует модель канала с шумом.По результатам запроса (O) он угадывает правильные входные данные кандидата (i) и получает наибольшее количество кандидатов с наибольшим количеством баллов.
На третьем шаге результаты кандидатов каждого сегмента объединяются. После объединения может быть несколько строк, оценка рассчитывается с использованием отношения ассоциации, а одна с наивысшей оценкой возвращается в качестве результата исправления ошибок. Алгоритм выражается следующим образом, предполагая, что запрос разбит на два сегмента S1 и S2, соответствующих строкам исправления ошибок <S1, {S11, S12}> и <S2, {S21, S22, S23}>, чтобы вычислить любую оценку комбинации двух-двух, где u (si) и u (sj) представляют оценки, вычисленные S1 и S2 на основе модели канала шума, f (si, sj) представляют тепло si и sj в связанных данных, а f (si) и f (sj) соответственно представляют Си и Сью собственный жар.
 Получите наивысшую оценку в качестве окончательного результата.
Получите наивысшую оценку в качестве окончательного результата.
Сбор данных Мы выбрали вертикальную музыку app-QQ для проверки нашего алгоритма, qq music – крупнейшая музыкальная онлайн-платформа на китайском языке, запущенная Tencent, с объемом поиска около 6000 Вт в день. Произвольно извлекать 3w запросов из журналов запросов за один месяц, получать результаты исправления ошибок поиска на веб-странице baidu и результаты самокоррекции соответственно, взять объединение двух результатов исправления ошибок общим объемом 3.1k и пометить вручную, из которых 200 Существует связанное исправление ошибок как набор данных для эксперимента.
Поймать результаты исправления ошибок веб-поиска baidu, главным образом, чтобы сравнить вертикальную рамку исправления ошибок и эффект исправления ошибок веб-поиска, и baidu является наиболее авторитетным в китайском веб-поиске.
По сравнению с исправлением ошибок веб-страницы в наборе данных 3.1k, ручная оценка увеличила отзыв на 28. 5% и F1 на 0.26. На 200 наборах связанного исправления ошибок наш отзыв метода увеличился на 42,4%, а F1 увеличился на 0,39. Это показывает, что наша универсальная вертикальная структура исправления ошибок (DCQC) и связанный алгоритм исправления ошибок могут значительно выиграть результаты исправления ошибок веб-поиска, Это также доказывает необходимость вертикального бизнеса для создания собственной системы исправления ошибок.
5% и F1 на 0.26. На 200 наборах связанного исправления ошибок наш отзыв метода увеличился на 42,4%, а F1 увеличился на 0,39. Это показывает, что наша универсальная вертикальная структура исправления ошибок (DCQC) и связанный алгоритм исправления ошибок могут значительно выиграть результаты исправления ошибок веб-поиска, Это также доказывает необходимость вертикального бизнеса для создания собственной системы исправления ошибок.
Webpage vs domain (ALL data set)
Semantic Association Correction (small data set)
Клики онлайн-пользователей случайным образом делят сетевой трафик на три точки, каждая из которых представляет алгоритм исправления ошибок, используя для сравнения данные реальных кликов пользователя. Чтобы исключить влияние позиции сортировки, анализируются только данные о кликах по первому результату. Эксперименты показывают, что по сравнению с исходным запросом, после исправления ошибок веб-страницы, процент кликов пользователя увеличивается на 2%, а наша структура может улучшиться на 8,4%, эффект более очевиден.
pycorrector
https://github.com/shibing624/pycorrector
https://shibing624.github.io/pycorrector/
Одно из первоначальных намерений этого проекта – сравнить и поделиться различными методами исправления ошибок в тексте и использовать его в качестве руководства.Если у меня есть немного вдохновения для всех в задаче исправления ошибок в файлах, это мое большое удовольствие.
Четыре типа глубинных моделей в основном используются в задачах по исправлению ошибок текста: rnn_attention, rnn_crf, seq2seq, seq2seq_attention, представленные в предыдущем разделе модели.
Демо-адрес:
https://www.borntowin.cn/product/corrector/
Chinese “spelling” error correction
https://github.com/ccheng16/correction
Особенности:
Существует множество обучающих языковых моделей, согласно введению, все относительно закончено и выглядит высоким. Но код не может быть запущен, и автор не ответил – я изменю код автора позже, чтобы посмотреть, смогу ли я запустить.
Китайское слово автоматическое исправление ошибок Cn_Speck_Checker
https://github.com/PengheLiu/Cn_Speck_Checker
Введение:
Обученные для медицинских данных, основанные на расстоянии редактирования, вы можете тренироваться самостоятельно – эффект общий, статистическая частота слов и информация о совпадениях, не идеальная, возвращает большое количество кандидатов
Особенности:
· Люди обычно более склонны совершать ошибки после этого, поэтому мы можем учитывать положение каждого слова в слове, чтобы придать определенный вес. Этот метод помогает улучшить первый вид «передачи» – «хотя» Случается;
· Подумайте о важности пиньинь. Для китайцев пиньинь обычно верен, когда люди совершают ошибку, но делают неправильный выбор, поэтому кандидаты с одинаковым пиньинь также могут быть выбраны преимущественно.
Jingdong: простая китайская коррекция ошибок и устранение неоднозначности
https://github.com/taozhijiang/chinese_correct_wsd
JD робот обслуживания клиентов для китайского исправления ошибок – ближе к нашему сценарию приложения, в основном для решения проблемы автоматического исправления ошибок для гомофонов, таких как:
Отличная скидка для новичков JD -> Отличная скидка на JD. com
com
Я хочу купить мобильный телефон брата Apple Правильное предложение: я хочу купить мобильный телефон Apple
Однако код не обновлялся в течение четырех лет и в настоящее время не может быть запущен.
Autochecker & autocorrecter for chinese
https://github.com/beyondacm/Autochecker4Chinese
Слова, короткие предложения эффект: 5/13 плохой эффект
Скорость: 2,860311 всего, 0,220023, с печатью
Расширяемость: словарь является расширяемым и не использует собственный корпус для обучения. Расширяемость средняя.
Сяомин НЛП
Обеспечить сегментацию китайского слова, пометку части речи, проверку правописания, анализ текста на пиньинь, анализ настроений, текстовое резюме, радикалы
https://github.com/SeanLee97/xmnlp
Слова, эффект коротких предложений: 3/13 плохой эффект
Скорость: 2.860311 все, 0.220023, без печати: 0: 00: 00.000017 все
Масштабируемость: ни словарь, ни модель не найдены. Плохая масштабируемость
Облачная отладка – интеллектуальная отладка
http://www. yunchacuo.com/
yunchacuo.com/
Ссылки:
Китайский механизм исправления ошибок на основе семантической ассоциации
https://cloud.tencent.com/developer/article/1030059
Алгоритм исправления ошибок в китайском тексте – две или три вещи для исправления опечаток
https://zhuanlan.zhihu.com/p/40806718
пикорректорная документация
https://shibing624.github.io/pycorrector/
Топ-20 программ проверки грамматики и орфографии (для исправления ошибок английского письма)
Опубликовано: 2021-05-24
Что делает текст хорошо написанным? Прежде всего, это ваш опыт и умение создавать понятный, аргументированный, полезный и интересный контент. Кроме того, он должен быть безошибочным и легко читаемым. И не забывайте о стиле. В конце концов, так сложно читать блог о стиле жизни, написанный академическим и сложным языком. Ошибки, неправильный стиль, неправильный выбор слов – они могут заставить читателя отказаться от ваших статей, какими бы полезными они ни были.
Инструменты проверки грамматики и орфографии помогут избавиться от ошибок и без особого труда создавать качественные тексты. Они автоматизируют процесс для всех авторов – от блоггеров до академических писателей. Что еще более важно, они могут быть весьма полезны и для SEO-специалистов. Вы не сможете занять первое место в Google, если будете размещать некачественные тексты с большим количеством грамматических, орфографических и пунктуационных ошибок.
Итак, прежде чем нажимать кнопку « Опубликовать» , проверьте свой текст с помощью одного из этих инструментов.
20 проверенных инструментов для проверки грамматики, пунктуации и стиля.
Испытание
Ценообразование
Проверяет
Языки
Устройства
LanguageTool
Бесплатная и Премиум версии
2 года: 99 долларов 1 год: 59 долларов 3 месяца: 39 долларов 1 месяц: 19 долларов
написание,
пунктуация
стиль
Грамматика
Бесплатная и Премиум версии
1 год: 12 долларов в месяц 3 месяца: 20 долларов в месяц 1 месяц: 30 долларов в месяц
написание,
пунктуация
стиль,
плагиат
Word Online
Бесплатная и Премиум версии
Личные: 5,99 долларов в месяц Семья: 7,99 долларов в месяц
написание,
пунктуация
Английский и другие языки
Scribens
Бесплатная и Премиум версии
1 месяц: 9,90 долларов США 3 месяца: 19,90 долларов США 1 год: 49,90 долларов США Бизнес-пакет: 39,60 долларов США
написание,
грамматика
пунктуация
стиль
Английский,
французкий язык
ReversoSpeller
Бесплатная и Премиум версии
1 месяц: 9,99 доллара в месяц 1 год: 4,99 доллара в месяц
написание,
пунктуация
Английский,
французкий язык
ОнлайнКоррекция
написание,
пунктуация
5 диалектов английского языка: американский,
Британский,
Австралийский,
Новая Зеландия,
Южноафриканский
Белый дым
Интернет: 5 долларов в месяц Премиум: 6,66 долларов в месяц Бизнес: 11,50 долларов в месяц
грамматика
стиль
Более 50 языков,
включая английский
Имбирь
Бесплатная и Премиум версии
1 месяц: 13,99 долларов США 1 год: 89,88 долларов США 2 года: 167,76 долларов США
написание,
грамматика
пунктуация
Английский и 50+ других языков
ProWritingAid
Бесплатная и Премиум версии
1 месяц: 20 долларов 1 год: 79 долларов Пожизненная подписка: 399 долларов
написание,
грамматика
пунктуация
стиль
Переписать
Бесплатная и Премиум версии
Ежемесячно Pro: 21,95 долларов США Ежемесячные команды: 13,95 долларов США Годовые Pro: 8,95 долларов США в месяц Команды 1 года: 7,95 долларов США в месяц
написание,
пунктуация
стиль,
плагиат
PaperRater
Бесплатная и Премиум версии
1 месяц: 14,95 доллара США 1 год: 95,40 доллара США
написание,
пунктуация
стиль,
плагиат
Писатель
Бесплатная и Премиум версии
Начальный срок на 1 месяц: 11 долларов США на год для начала: 99 долларов США
написание,
грамматика
пунктуация
стиль
Linguix
Бесплатная и Премиум версии
Личный: 18,95 долларов в месяц Бизнес: 20 долларов в месяц
написание,
грамматика
пунктуация
стиль
SpellCheckPlus
Бесплатная и Премиум версии
1 год: 14,99 долларов США
грамматика
написание,
пунктуация
NOUNPLUS
написание,
грамматика
Английский,
Корейский язык,
китайский язык
Writefull
Бесплатная и Премиум версии
1 месяц: 15,37 доллара США в месяц 3 месяца: 35,43 доллара США 1 год: 65,52 доллара США
написание,
грамматика
пунктуация
1.
 LanguageTool
LanguageTool- Проверяет: орфографию, пунктуацию, стиль
- Языки: 20 языков, включая английский
- Доступность: бесплатно, 3 премиальных плана с расширенными функциями
LanguageTool помогает пользователям создавать отличные тексты без орфографических, грамматических и пунктуационных ошибок. Средство проверки находит и показывает ошибки, а также предлагает предложения, позволяющие улучшить выбор слов и пунктуацию за считанные секунды. Пользователи также могут добавить его в Chrome и Firefox, чтобы проверять свою электронную почту, сообщения в блогах, социальные сети и т. Д. Инструмент автоматически выделяет ошибки и предоставляет предложения в режиме реального времени.
Кроме того, его также можно интегрировать с MS Word и Google Docs. Обратите внимание, что эта функция доступна только для членов Premium. Среди бесплатных функций – поиск основных грамматических ошибок, ошибок пунктуации и стиля в текстах (до 10 000 символов на фрагмент контента).
2. Грамматика
- Проверяет: орфографию, стиль, пунктуацию, плагиат
- Языки: английский
- Доступность: бесплатная базовая и премиум-версии.
Grammarly помогает пользователям писать безошибочные тексты на английском языке. Инструмент подсказок позволяет найти ошибки и выбрать правильное написание того или иного слова.
Grammarly доступен онлайн: вы можете работать в отдельном окне или установить расширение. С расширением инструмент будет проверять контент, который вы создаете в Интернете: от социальных сетей до электронных писем. Самое лучшее в нем то, что он находит все типы ошибок, будь то неправильно употребленное слово или плохая структура предложения. После регистрации вы сможете добавлять слова в свой личный словарь и выбирать предпочтительный диалект. Те, кто хочет использовать все возможности, могут купить Премиум-версию.
3. Приложение Hemingway
- Проверяет: орфографию, стиль, пунктуацию
- Языки: английский
- Доступность: Бесплатно
В приложении Hemingway может быть меньше инструментов, чем в Grammarly, но у него есть свои уникальные особенности и преимущества. Он также помогает исправить стилистические ошибки и подсказывает, как улучшить контент в целом.
Он также помогает исправить стилистические ошибки и подсказывает, как улучшить контент в целом.
Инструмент позволяет пользователю писать более качественные и четкие тексты, выделяя наречия, пассивный залог, часто используемые фразы и длинные предложения. Также существует расширенная настольная версия. Вы можете использовать функции импорта и экспорта: просто загрузите автономные документы и после редактирования экспортируйте содержимое обратно в Word или PDF.
4. Word Online
- Проверяет: орфографию, пунктуацию, тезаурус
- Языки: английский и другие языки
- Доступность: Бесплатная (требуется авторизация) и Премиум версии.
Это онлайн-версия Microsoft Word, которая также проверяет вашу орфографию и грамматику. Если вы обновитесь до Premium, вы также сможете увидеть предложения по стилю.
Инструменты проверки орфографии будут использовать доступные словари автоматически. Word Online также может предлагать синонимы для выделенных слов и анализировать читаемость текста.
Для работы в автономном режиме и использования расширенного форматирования Microsoft предлагает семейные и личные подписки.
5. Документы Google
- Проверяет: правописание
- Языки: английский и другие языки
- Доступность: Бесплатно
Google Docs – одно из лучших приложений для обработки текста для индивидуальной и совместной работы. Кроме того, он может исправить вашу грамматику и орфографию в документах, предложить предложения и включить функцию, которая автоматически исправляет опечатки. Пользователи могут включить автозамену, которая поддерживает определение верхнего и нижнего регистра, ссылок и кавычек. Автозамена доступна на немецком, португальском, французском, английском и испанском языках.
Вы также можете интегрировать сторонние инструменты, такие как Grammarly: при редактировании текста в Документах Google с включенным расширением Grammarly вы найдете слова с красным подчеркиванием, которые необходимо исправить.
6. Писатели
- Проверяет: орфографию, грамматику, стиль, пунктуацию.
- Язык: английский, французский
- Доступность: бесплатные и премиум планы.
Писатели могут найти и исправить более 250 типов ошибок в грамматике, стиле и орфографии. Он работает с пунктуацией, типографикой, омонимами, предлогами, местоимениями и т. Д.
Этот инструмент исправляет избыточность и предоставляет синонимы словам. Кроме того, он улучшает ваш английский с помощью объяснений правил, исправляет в десять раз больше ошибок, чем Microsoft Word, и предоставляет подробную статистику и объяснения.
Его можно интегрировать с MS Office и электронной почтой. Пользователи также могут устанавливать расширения Chrome и Firefox и исправлять тексты в режиме реального времени.
7. ReversoSpeller
- Проверяет: орфографию, пунктуацию
- Языки: английский, французский
- Доступность: бесплатная и премиум версии
ReversoSpeller может исправлять английские и французские тексты. Инструмент использует технологии искусственного интеллекта для выявления и исправления грамматических ошибок, ошибок глагольного времени, неправильных предлогов и опечаток.
Инструмент использует технологии искусственного интеллекта для выявления и исправления грамматических ошибок, ошибок глагольного времени, неправильных предлогов и опечаток.
Ошибки выделяются или исправляются автоматически в зависимости от типа ошибки. Когда пользователь печатает, система использует интерактивные исправления от Ginger Software. Reverso также предлагает варианты стилей и синонимы для слов. Вы можете получить доступ к этому средству проверки через мобильный телефон, веб-браузер или расширение, что делает его удобным онлайн-инструментом.
8. Онлайн-исправление
- Проверяет: орфографию, пунктуацию
- Языки: пять диалектов английского языка
- Доступность: Бесплатно
OnlineCorrection.com проверяет орфографию и предлагает рекомендации по выявлению ошибок. Если есть два или более возможных варианта, вам будет предложено выбрать один из них. Инструмент проверяет тексты, написанные на 5 различных вариантах английского языка, в частности, на американском английском, британском английском, австралийском английском, новозеландском английском и южноафриканском английском.
В целом, это хороший инструмент для поиска орфографических, грамматических и стилевых ошибок в английских текстах.
9. WhiteSmoke
- Проверяет: грамматику, стиль, пунктуацию.
- Языки: более 50 языков, включая английский
- Доступность: платная подписка
WhiteSmoke – отличный инструмент для исправления простых орфографических ошибок, поиска правильных слов в конкретном контексте, исправления ошибок пунктуации и поиска любых стилистических ошибок. Контент анализируется с помощью искусственного интеллекта NLP.
Вы можете воспользоваться встроенным инструментом перевода, а также словарями более чем на 50 языках. Кроме того, вы можете посмотреть видео-уроки, чтобы улучшить грамматику и проверить тексты на плагиат. Сервис совместим с Windows, Mac OS и доступен во всех популярных браузерах.
10. имбирь
- Проверяет: орфографию, грамматику, пунктуацию.
- Языки: английский и более 50 других языков
- Доступность: бесплатная и премиум версии
Ginger – это высококачественный и интуитивно понятный инструмент проверки, который помогает улучшить письмо на английском языке, выявляя грамматические и орфографические ошибки, а также неправильно используемые слова.
Вы можете установить расширение для браузера Ginger, чтобы получать оперативные исправления в Gmail и социальных сетях, загрузить приложение Ginger на свое устройство Android или iOS или использовать настольные версии для Mac и Windows.
Если вы хотите получить доступ к неограниченным исправлениям на основе искусственного интеллекта и перефразору предложений, выберите один из планов Premium. В противном случае вы можете бесплатно проверять текст объемом до 300 слов за раз. Вдобавок ко всему , специальная функция Personal Trainer позволяет вам улучшить свой английский с помощью индивидуального плана, основанного на ваших собственных ошибках. Это еще одна причина, по которой так много людей продолжают его выбирать.
11. ProWritingAid
- Проверяет: орфографию, грамматику, стиль, пунктуацию.
- Английский язык.
- Доступность: бесплатная и премиум версии
ProWritingAid имеет встроенные инструменты проверки грамматики и стиля. Хотя он был разработан, чтобы помочь пользователям улучшить свой стиль письма, в нем также есть отличные средства проверки грамматики и плагиата. Для удобства вы можете включить проверку в реальном времени, чтобы видеть предложения по грамматике, орфографии и стилю по мере ввода.
Хотя он был разработан, чтобы помочь пользователям улучшить свой стиль письма, в нем также есть отличные средства проверки грамматики и плагиата. Для удобства вы можете включить проверку в реальном времени, чтобы видеть предложения по грамматике, орфографии и стилю по мере ввода.
Кроме того, существуют расширения ProWritingAid, которые можно интегрировать с другими инструментами, такими как Word, Google Docs и WordPress. Настольное приложение доступно для пользователей Mac OS и Windows. В большинстве случаев люди используют его для редактирования статей и книг. Авторы, пишущие на английском языке, используют его для корректуры контента, чтобы найти лучшие грамматические решения перед публикацией.
12. Переписать
- Проверяет: орфографию, пунктуацию, стиль, плагиат
- Языки: английский
- Доступность: бесплатная и премиум версии
Outwrite находит грамматические и орфографические ошибки и позволяет пользователям Pro сканировать контент на плагиат. Это средство проверки искусственного интеллекта, поэтому оно имеет расширенную функциональность, которая может помочь перефразировать предложения, улучшить словарный запас и увеличить или уменьшить количество слов.
Это средство проверки искусственного интеллекта, поэтому оно имеет расширенную функциональность, которая может помочь перефразировать предложения, улучшить словарный запас и увеличить или уменьшить количество слов.
Outwrite также доступен как веб-расширение, поэтому вы можете использовать его в любом браузере, в Microsoft Word и Google Docs. Пользователи iOS также могут использовать мобильное приложение.
13. PaperRater
- Проверяет: орфографию, пунктуацию, стиль, плагиат
- Языки: английский
- Доступность: бесплатные и премиум планы.
PaperRater пользуется большим спросом среди студентов и профессиональных писателей. Он может проверять любые типы текстов и точно находить грамматические ошибки с помощью автоматизированного алгоритма. Кроме того, он сравнивает ваш контент с похожими текстами и предлагает предложения по его улучшению за считанные секунды.
PaperRater анализирует и оценивает удобочитаемость. Вы также можете увидеть «оценку» вашего текста. Этот инструмент позволяет проверять тексты на плагиат – он сканирует более 10 миллиардов документов и статей в Google и Bing.
Этот инструмент позволяет проверять тексты на плагиат – он сканирует более 10 миллиардов документов и статей в Google и Bing.
PaperRater анализирует тексты в режиме реального времени, поэтому пользователь может увидеть свою оценку через 5-15 секунд после ее загрузки. Вы можете свободно проверять свой контент даже без регистрации.
14. Писатель
- Проверяет: орфографию, грамматику, пунктуацию.
- Языки: английский
- Доступность: бесплатные и премиум планы.
В отличие от своих конкурентов Writer позволяет пользователям создавать свои собственные правила для редактирования текста и контента на разных платформах. Он также проверяет контент на удобочитаемость, длину, ясность, правильный словарный запас и стиль.
Одна из основных функций – настройка: просто выберите свой бизнес и укажите содержание, термины и фразы, которые отличают вас от конкурентов.
Writer – это инструмент искусственного интеллекта, который делает ваш контент более полезным, безошибочным и легким для чтения. Он сканирует текст на наличие всех типов ошибок: от лишних пробелов до грамматических ошибок, исправляет неправильно использованные глаголы и опечатки.
Он сканирует текст на наличие всех типов ошибок: от лишних пробелов до грамматических ошибок, исправляет неправильно использованные глаголы и опечатки.
15. Изящная запись
- Проверяет: орфографию, грамматику, стиль
- Языки: английский
- Доступность: Бесплатно
Slick Write – это бесплатный инструмент, предназначенный для проверки орфографии и грамматики. Вообще говоря, это очень эффективное решение для тех, кто хочет создавать отличные безошибочные тексты в социальных сетях, сообщения в блогах и контент веб-сайтов. Этот инструмент пользуется большим спросом среди SEO-специалистов, блоггеров, писателей и маркетологов.
Платформа позволяет импортировать текст, который вы хотите проверить, или добавить его в окно веб-сайта. Вы можете настроить проверку в соответствии с вашим типом контента. Например, если вы создаете резюме и у вас есть конкретные рекомендации, инструмент сосредоточится на вашей терминологии.
16. Виртуальный репетитор по письму.

- Проверяет: орфографию, грамматику, пунктуацию.
- Языки: английский
- Доступность: Бесплатно
Virtual Writing Tutor – это бесплатный веб-сайт, предназначенный для помощи пользователям в проверке орфографии, грамматики, пунктуации, структуре текста и подсчете слов.
Все орфографические ошибки выделены красным цветом и могут быть исправлены щелчком левой кнопки мыши по слову.
Virtual Writing Tutor также проверяет грамматику – обнаруживает двойные отрицания, ложные родственные слова, пропущенные вспомогательные слова и орфографические ошибки. Инструмент анализирует ваш словарный запас, стиль и предлагает лучшие варианты, если что-то не так. Кроме того, он проверяет тексты на плагиат, сканируя миллионы статей в Интернете и показывая процент совпадающего текста.
17. Linguix
- Проверяет: орфографию, грамматику, стиль, пунктуацию.
- Языки: английский
- Доступность: 7-дневный бесплатный пробный период и премиум-план
Linguix предлагает предложения с учетом контекста. Это делает предложения грамматически правильными, их легче читать и понимать.
Это делает предложения грамматически правильными, их легче читать и понимать.
Linguix также объясняет ваши ошибки. Люди могут использовать его онлайн или установить расширение для проверки текстов при наборе текста в режиме реального времени.
Кроме того, Linguix отправляет на вашу электронную почту отчеты, содержащие подробную информацию о наиболее часто совершаемых ошибках. Это отличная функция для не носителей языка.
18. SpellCheckPlus
- Проверяет: грамматику, орфографию, пунктуацию.
- Языки: английский
- Доступность: бесплатная и профессиональная версии.
SpellCheckPlus – это онлайн-сервис редактирования, который помогает находить, понимать и редактировать грамматические и орфографические ошибки. Также имеется словарный запас на испанском, английском, французском и китайском языках. Не носители языка и те, кто изучает один из этих языков, могут выполнять упражнения по пополнению словарного запаса и развлекательные упражнения, чтобы улучшить свои навыки.
Инструмент доступен бесплатно, но пользователи могут перейти на версию Pro, которая позволяет работать без рекламы, более плавно, просматривать отчеты, сохранять тексты, выполнять упражнения по грамматике и многое другое.
19. Nounplus
- Проверки: орфография, грамматика, орфография
- Языки: английский, корейский, китайский
- Доступность: Бесплатно
NOUNPLUS был разработан как бесплатный инструмент для проверки грамматики и орфографии. Все функции доступны для не платящих членов. Пользователи могут проверять свои тексты в Интернете, а также загружать приложение, совместимое с устройствами Android и iOS.
NOUNPLUS – отличный инструмент для студентов, писателей и блоггеров, поскольку он был создан для профессиональных и академических целей и работает как для носителей английского языка, так и для тех, для кого английский не является родным. Есть также средства проверки для тех, кто пишет на корейском и китайском языках.
20.
 Writefull
Writefull- Проверяет: орфографию, грамматику, пунктуацию.
- Языки: английский
- Доступность: Бесплатно. Неограниченный доступ для премиум-членов
Writefull – это инструмент проверки, разработанный для студентов и издателей, но также может использоваться блоггерами, авторами и теми, кто хочет, чтобы их тексты были четкими и безошибочными. Его можно использовать в Microsoft Word, редакторе кода Overleaf и Revise. Чтобы начать использовать его, вам необходимо загрузить бесплатное программное обеспечение. Однако для получения неограниченного доступа, просмотра всех предложений и отчетов вам необходимо перейти на Премиум.
Программа обладает некоторыми особенностями: вы можете слышать произносимый текст, находить синонимы определенного слова и улучшать свои навыки письма во многих академических дисциплинах от медицины до социальных наук.
Заключение
Всегда есть возможность улучшить свое письмо и сделать его более последовательным. Вот почему важно использовать средства проверки грамматики, чтобы ваши тексты были как можно более профессиональными и безошибочными. Хотя эти инструменты не могут заменить ручных корректоров, они могут помочь быстро найти и исправить множество ошибок, и многие из них бесплатны.
Хотя эти инструменты не могут заменить ручных корректоров, они могут помочь быстро найти и исправить множество ошибок, и многие из них бесплатны.
Еще одним замечательным достоинством таких инструментов является то, что они делают гораздо больше, чем просто исправляют орфографические и пунктуационные ошибки. Также они могут:
- сканировать контент на плагиат
- предотвратить переполнение ключевыми словами и чрезмерно используемые фразы
- проверить стиль и тон голоса
- подсчитывать слова
Даже если ваши письменные навыки почти идеальны, вы можете что-то упустить, а это может все подорвать. Итак, почему бы не использовать инструменты, чтобы избежать таких сценариев? Кстати, Google также любит SEO-дружественный и безошибочный контент.
Проверка правильности написания на английском языке
Миллионы людей учат английский язык, чтобы соответствовать более высокому уровню на работе. Так или иначе, в процессе трудовой деятельности приходится составлять различные тексты, письма, деловые обращения, резюме. Именно по грамотности их составления партнеры делают обоснованные выводы о подготовленности автора к деловой деятельности.
Так или иначе, в процессе трудовой деятельности приходится составлять различные тексты, письма, деловые обращения, резюме. Именно по грамотности их составления партнеры делают обоснованные выводы о подготовленности автора к деловой деятельности.
Крайне важно не просто формулировать и правильно выражать свои мысли, их необходимо излагать грамматически верно. Даже при условии участия переводчика не исключены ошибки и неточности. Они существенно искажают суть подготовленного письма. Поэтому чтобы создать действительно грамотный документ на английском языке, рекомендуется использовать интеллектуальный сервис для исправления ошибок. К примеру, Grammarly исправит существующие ошибки, обратит внимание на грамматику и пунктуацию, а также использование тех или иных слов в правильном значении, что особенно важно для тех, кому английский не является родным языком.
В чем особенности данного сервиса
Ресурс
Grammarly проверяет правильность составления любых текстов. При этом его использование имеет свои особенности. Рассмотрим их подробно.
При этом его использование имеет свои особенности. Рассмотрим их подробно.- Представленный сервис отлично работает на любом устройстве. Он отлично адаптирован для ПК, ноутбука или любого другого устройства.
- Ресурс совершенно безопасен для работы компьютера. Его установка и использование не повлечет передачу личных или иных защищенных данных. Передача информации о пользователе осуществляется по новым защищенным протоколам.
- Установка и работа с указанным ресурсом не станет причиной зависания работы компьютера. Программа не вызывает замедления в действии других ресурсов, не влияет на скорость отклика на команды пользователя.
- Указанный ресурс отлично справляется с проверкой любого текста. Например, это может быть описание того или иного продукта или частное резюме. В любом случае пользователь получит качественную проверку.
Таким образом, Grammarly – универсальный ресурс. Он работает по простым и удобным для пользователей правилам. Достаточно скопировать текст и задать его проверку. Программа сама выполнит указанную задачу. При этом проверка текста будет проведена на основании соответствия его классическим требованиям английского языка.
Достаточно скопировать текст и задать его проверку. Программа сама выполнит указанную задачу. При этом проверка текста будет проведена на основании соответствия его классическим требованиям английского языка.
Все допущенные ошибки будут отображены после проверки, и пользователь сможет быстро их устранить. Важно отметить, что проверка отображает ошибки всех типов – синтаксические, грамматические, пунктуационные и др.
Сервис Grammarly для физических лиц
Частная переписка имеет ключевое значение для физических лиц. Данная категория охватывает студентов, тех, кто хочет трудоустроиться за рубежом, желает получить длительную визу или вид на жительство. Кроме того, понятие частной переписки включает отправку документов о покупке объектов недвижимости, переписку с владельцами такой недвижимости в англоязычных странах.
Вне зависимости от конкретных причин написания письма на английском языке его правильность имеет ключевое значение. При неверно сформулированных предложениях, наличии грамматических и иных ошибок будет непонятно, чего именно желает человек. В результате диалог просто не состоится: стороны не смогут понять друг друга.
В результате диалог просто не состоится: стороны не смогут понять друг друга.
Более того, допущение ошибок в переписке, составлении резюме, показывает человека в крайне невыгодном свете. Даже если такие ошибки носят чисто технический характер, они определяют отношение к человеку со стороны адресата. Поэтому шансы на поступление в вуз, устройство на работу или совершение иных важных действий резко снижаются.
Избежать подобных сложностей можно благодаря указанной программе. Пользователю нужно только отправить текст на проверку и исправить выявленные ошибки. В результате его собеседник увидит идеальный с точки зрения ясности и правильности выражения своих мыслей текст, а не истинные знания пользователя, которые зачастую могут быть не на высшем уровне.
В чем преимущества для бизнеса
Деловая переписка отличается целым рядом особенностей. Такие документы, как договоры, соглашения, технические условия, инструкции и пр., как правило, содержат немало специальных терминов. Для правильного понимания их содержания крайне важна верная расстановка слов, отсутствие технических и грамматических ошибок, которые способны существенно исказить смысл отправленного зарубежному партнеру текста. В результате сделка или иное значимое действие может просто не состояться. И при этом вы даже не поймете истинных причин срыва сделки.
Для правильного понимания их содержания крайне важна верная расстановка слов, отсутствие технических и грамматических ошибок, которые способны существенно исказить смысл отправленного зарубежному партнеру текста. В результате сделка или иное значимое действие может просто не состояться. И при этом вы даже не поймете истинных причин срыва сделки.
Чтобы убедиться в том, что документ не имеет ошибок, следует воспользоваться сервисом Grammarly, который является идеальным инструментом для коммерческой деятельности.
Преимущества работы с сервисом следует представить подробнее
- Грамотный английский текст демонстрирует отношение к партнеру. При его прочтении становится очевидно, что компания уважает партнера и очень серьезно относится к деловым контактам. Правильный, без ошибок текст является лучшим показателем ценности и важности коммерческих отношений.
- Благодаря данному сервису удается сократить расходы на оформление деловой переписки.
 Например, нет необходимости обращаться к переводчикам и тратить на это немалые деньги. Сервис позволяет быстро и очень точно проверять готовый текст. Его можно также быстро исправить, устранив ошибки и неточности. Соответственно затраты на подготовку переписки удастся значительно сократить.
Например, нет необходимости обращаться к переводчикам и тратить на это немалые деньги. Сервис позволяет быстро и очень точно проверять готовый текст. Его можно также быстро исправить, устранив ошибки и неточности. Соответственно затраты на подготовку переписки удастся значительно сократить. - За счет скорости обработки текстов сервис дает возможность быстро обмениваться информацией. Не придется тратить время на подготовку ответа. Так, не нужно направлять проект ответа переводчикам или проверять его несколько раз. Достаточно задать проверку на сайте с помощью представленного сервиса Grammarly.
-
Возможность проверки текста
на антиплагиат на английском языке онлайн
Для бизнеса данный ресурс – удобный и простой инструмент организации деловой переписки. Он позволяет избежать излишних расходов на услуги переводчика, временных затрат на подготовку грамотных и понятных для партнеров документов.
Отдельно нужно упомянуть про систему оценки текста, который отправляется на проверку. Тексты оцениваются по нескольким параметрам, и после этого система относит его к одной из трех категорий. При этом пользователь видит, какие именно ошибки он допустил. Соответственно допущенные ошибки можно исправить в короткие сроки.
Тексты оцениваются по нескольким параметрам, и после этого система относит его к одной из трех категорий. При этом пользователь видит, какие именно ошибки он допустил. Соответственно допущенные ошибки можно исправить в короткие сроки.
Кроме того, важным преимуществом представленного ресурса является простая процедура регистрации. Она занимает всего несколько минут. Но весь функционал становится доступным только после указанной процедуры.
Удобство заключается еще и в том, что пользоваться указанным ресурсом можно при помощи всех мессенджеров и социальных сетей.
Как начать пользоваться сервисом проверки английского
Начать
пользоваться сервисом можно бесплатно онлайн.Для этого необходимо добавить в браузере Хром приложение Grammarly (Граммарли), зарегистрироваться. И сервис всегда будет с вами: работаете ли вы с текстовыми документами или ведете переписку в соцсетях.
Если вам понадобится расширить свои возможности в английском или использовать английский для бизнеса, можно воспользоваться «премиальной» подпиской. При этом имеется отдельное предложение «предприятие» для больших компаний со значительным объемом документооборота.
При этом имеется отдельное предложение «предприятие» для больших компаний со значительным объемом документооборота.
Пользователю нужно только выбрать одну из указанных вкладок и перейти к оплате продукта.
Бесплатная онлайн-проверка грамматики – Ginger Software
Избегайте досадных ошибок с помощью первой в мире программы проверки грамматики
Программа проверки грамматики имбиря помогает писать и эффективно исправляет тексты. Основываясь на контексте полных предложений, Ginger Grammar Checker использует запатентованная технология для исправлять грамматические ошибки, орфографические ошибки и неправильно используемые слова, с непревзойденными точность. Грамматика имбиря Программное обеспечение check улучшает ваш текст, как это сделал бы рецензент.
Наслаждайтесь самой обширной онлайн-программой проверки грамматики на рынке.Воспользуйтесь одним
вычитка кликов
где бы вы ни печатали, чтобы улучшить свои навыки письма по-английски, пока вы учитесь на своем
грамматические ошибки.
Правильная грамматика имеет значение!
Как в онлайн, так и в офлайновом мире важно писать, не делая глупые грамматические ошибки, Ошибки синтаксиса английского языка или ошибки пунктуации. Мы все умение общаться – ключевой навык для достижения успеха. Например, в корпоративном мир трудно получить работа без хороших письменных коммуникативных навыков, даже если кандидат преуспевает в своей области.В академическом мире безошибочный английский письмо сильно коррелирует с достижением лучших результатов. В онлайн-мире блоггерам необходимо писать грамматически правильные и беглые тексты, чтобы убедиться, что сообщение, которое они пытаются чтобы передать, правильно достигает своей аудитории. Если у вас есть онлайн-сервис, тогда правильный, безошибочный контент имеет решающее значение. Суть в том, что проверка грамматики перед то, что вы отправляете, может иметь значение между успехом и неудачей.
Больше никаких грамматических ошибок: проверьте грамматику с Ginger
Программа проверки грамматики Ginger Grammar Checker исправляет широкий спектр грамматических ошибок. Большинство
инструменты коррекции грамматики
требуя выполнить проверку грамматики на основе английского языка
грамматические правила не могут выявить большинство грамматических ошибок; следовательно
многие из этих общих
ошибки записи игнорируются. Во многих случаях,
эти бесплатные онлайн-программы проверки грамматики отмечают ошибки, но не предлагают никаких исправлений.
Имбирь использует
революционная технология для определения грамматики и орфографии
ошибки в предложениях и исправлять их с непревзойденной точностью. От единственного числа против
множественные ошибки в большинстве
замысловатые предложения или ошибки в употреблении напряженных слов,
Джинджер замечает ошибки и исправляет их.Проверка грамматики никогда не была
проще и быстрее. С
одним щелчком мыши исправлены множественные ошибки. Ваш
Ошибки больше не будут упущены из виду с помощью средства проверки грамматики Ginger Software.
Большинство
инструменты коррекции грамматики
требуя выполнить проверку грамматики на основе английского языка
грамматические правила не могут выявить большинство грамматических ошибок; следовательно
многие из этих общих
ошибки записи игнорируются. Во многих случаях,
эти бесплатные онлайн-программы проверки грамматики отмечают ошибки, но не предлагают никаких исправлений.
Имбирь использует
революционная технология для определения грамматики и орфографии
ошибки в предложениях и исправлять их с непревзойденной точностью. От единственного числа против
множественные ошибки в большинстве
замысловатые предложения или ошибки в употреблении напряженных слов,
Джинджер замечает ошибки и исправляет их.Проверка грамматики никогда не была
проще и быстрее. С
одним щелчком мыши исправлены множественные ошибки. Ваш
Ошибки больше не будут упущены из виду с помощью средства проверки грамматики Ginger Software.
Грамматика – залог успеха: начинай писать лучше и быстрее
С помощью программы Ginger для проверки грамматики писать программы можно быстро и легко. Вам никогда не понадобится
просить других о помощи
с правилами грамматики английского языка. Используйте программу проверки грамматики имбиря, чтобы исправить
ваши тексты и загрузите полный набор продуктов Ginger, чтобы слушать ваши тексты и
учись у твоего
собственные ошибки, чтобы не повторять их в будущем.
Вам никогда не понадобится
просить других о помощи
с правилами грамматики английского языка. Используйте программу проверки грамматики имбиря, чтобы исправить
ваши тексты и загрузите полный набор продуктов Ginger, чтобы слушать ваши тексты и
учись у твоего
собственные ошибки, чтобы не повторять их в будущем.
Не позволяйте неправильной грамматике мешать вам. Начните использовать Ginger Software сегодня!
Нажмите здесь, чтобы узнать больше о преимуществах
использования
онлайн-проверка грамматики.
Ginger Grammar Checker поможет вам писать лучше английский и исправляйте тексты более эффективно. Используя запатентованную технологию, Ginger Grammar Checker анализирует контекст вашего предложения исправлять грамматические ошибки, неправильно используемые слова и орфографические ошибки с непревзойденной точностью. Программа для исправления грамматики Ginger улучшает ваш текст так же, как рецензент-человек сделал бы это.
Инструмент грамматики Ginger исправляет все типы ошибок
Имбирь исправляет все типы грамматических ошибок, включая темы, которые
адресовано любым другим
программа коррекции грамматики. Вот некоторые примеры:
Вот некоторые примеры:
Предметный глагол согласования
Запах цветов вызывает воспоминания. → Запах цветы навевают воспоминания.
Существительные единственного / множественного числа
Шесть человек погибли в аварии → Шесть человек погибли их жизни в аварии.
Последовательные существительные
Шерил пошла в кассу → Шерил пошла в кассу.
Исправление неправильных слов
Используя свою контекстную проверку грамматики, Ginger распознает неправильно используемые слова в любых предложение и заменяет их с правильными. Я бродил, есть ли новости. → Интересно, есть ли новости.
Контекстная коррекция орфографии
Ginger Spell Checker – это контекстная проверка орфографии, которая определяет
исправление, которое лучше всего подходит
значение исходного предложения.В сочетании с имбирем
Средство проверки грамматики, вы можете исправить целые предложения одним щелчком мыши.
То же неправильно употребленное слово будет иметь другое исправление в зависимости от контекста:
Мраморная статуя образует большую изгородь →
У мраморной статуи была большая голова.
Фонетические орфографические ошибки исправляются, даже если правильное написание очень отличается от того, как они изначально были написаны: Я люблю книги, особенно классику → Мне нравятся книги, особенно классика
Исправлены неправильные спряжения глаголов:
Он прилетел в Ванкувер → Он прилетел
в Ванкувер
Имбирь повышает продуктивность письма
Проверка грамматики еще никогда не была такой простой.После установки на ваш компьютер Ginger Grammar Checker есть только в один клик, где и когда вы нужно это. Исправляйте целые предложения одним щелчком мыши, используя ваш текущий Интернет браузер и письмо, презентационные и почтовые программы.
Исправляйте письменные тексты более эффективно с Ginger
Вместо того, чтобы побуждать пользователей исправлять ошибки одну за другой, Джинджер выявляет и
исправляет каждую ошибку в
вынесенный приговор одновременно; Джинджер даже предлагает альтернативные варианты.
структуры предложений.
С Ginger – вам не нужно тратить время, пытаясь найти правильный способ написать
приговор или придется
передайте свои тексты кому-нибудь на проверку.
глаголов | Что такое глагол?
Что такое глагол?
Глаголы – это слова-действия в предложении, описывающие действия субъекта. Наряду с существительными, глаголы являются основной частью предложения или фразы, рассказывая историю о том, что происходит. Фактически, без глагола невозможно правильно передать полные мысли, и даже в самых простых предложениях, таких как Мария, поет, , , , , есть один.На самом деле, глагол может быть предложением сам по себе с подлежащим, в большинстве случаев подразумеваемым вами, например, Sing ! и Диск !
При изучении правил грамматики школьников часто учат, что глаголы «делают» слова, то есть они обозначают часть предложения, которая объясняет происходящее действие: Он, , убежал, , она съела шоколадный торт по воскресеньям. , лошади скачут по полям . Ran , eats и gallop – это части этих предложений «действие», следовательно, они являются глаголами. Однако это может сбивать с толку, потому что не все глаголы легко идентифицировать как действие: Я знаю ваше имя, Джек подумал об этом , мы рассмотрели несколько приложений . Это глаголы бездействия, то есть те, которые описывают состояние бытия, эмоции, обладание, чувство или мнение. К другим глаголам бездействия относятся любить, соглашаться, чувствовать, я, и иметь .
, лошади скачут по полям . Ran , eats и gallop – это части этих предложений «действие», следовательно, они являются глаголами. Однако это может сбивать с толку, потому что не все глаголы легко идентифицировать как действие: Я знаю ваше имя, Джек подумал об этом , мы рассмотрели несколько приложений . Это глаголы бездействия, то есть те, которые описывают состояние бытия, эмоции, обладание, чувство или мнение. К другим глаголам бездействия относятся любить, соглашаться, чувствовать, я, и иметь .
Как распознать глагол
Как видно из приведенных выше примеров, ключом, который поможет вам распознать глагол, является его расположение по сравнению с подлежащим. Глаголы почти всегда идут после существительного или местоимения. Эти существительные и местоимения именуются подлежащим. Глагол думал, что идет после существительного Джек, поэтому действие, которое предпринял Джек (субъект), было мышлением (глагол).
Глагол думал, что идет после существительного Джек, поэтому действие, которое предпринял Джек (субъект), было мышлением (глагол).
- Марк быстро съедает свой обед.
- У нас пошли на рынок .
- Вы, , аккуратно пишете в блокноте.
- Они думали, обо всех призах в конкурсе.
Вот еще несколько способов распознать глаголы в предложении:
- Если вы не уверены, является ли слово глаголом, спросите себя: «Могу я сделать ______?»
Могу я думать, гадать, гулять, зевать? Да, это глаголы.
- Вы также можете спросить: «Что происходит?»
В предложении Марк быстро ест, что происходит? Еда происходит, значит есть глагол.
В предложении Подумали обо всех призах , что происходит? Мысль (мышление) происходит, поэтому мысль – это глагол.
Физические глаголы – определение и примеры
Физические глаголы – это глаголы действия. Они описывают конкретные физические действия. Если вы можете создать движение своим телом или использовать инструмент для завершения действия, слово, которое вы используете для его описания, скорее всего, является физическим глаголом. Например, Джо, , сидел в своем кресле , собака дышит быстро после того, как она преследует свой мяч, и должны ли мы голосовать за на выборах? Даже если действие не очень активное, если действие совершается телом или инструментом, считайте это физическим глаголом.
Они описывают конкретные физические действия. Если вы можете создать движение своим телом или использовать инструмент для завершения действия, слово, которое вы используете для его описания, скорее всего, является физическим глаголом. Например, Джо, , сидел в своем кресле , собака дышит быстро после того, как она преследует свой мяч, и должны ли мы голосовать за на выборах? Даже если действие не очень активное, если действие совершается телом или инструментом, считайте это физическим глаголом.
Примеры физических глаголов
Примеры физических глаголов в следующих предложениях выделены жирным шрифтом для облегчения идентификации.
- Давайте пробежим до угла и обратно.
- Я слышу идет поезд.
- Позвоните мне по номеру , когда закончите занятия.
Мысленные глаголы – определение и примеры
Психические глаголы имеют значения, связанные с такими понятиями, как открытие, понимание, мышление или планирование. В общем, мысленный глагол относится к когнитивному состоянию.
В общем, мысленный глагол относится к когнитивному состоянию.
Мысленный глагол – определение и примеры
Психические глаголы имеют значения, связанные с такими понятиями, как открытие, понимание, мышление или планирование. В общем, мысленный глагол относится к когнитивному состоянию.
Примеры мысленных глаголов
Примеры мысленных глаголов в следующих предложениях выделены жирным шрифтом для облегчения идентификации.
- Я знаю ответ .
- Она узнала меня через комнату.
- Вы, , верите всему, что вам говорят?
Состояния глаголов – определение и примеры
Также известные как связывающие глаголы, глаголы состояния описывают существующие условия или ситуации. Состояние бытия глаголы неактивны, так как не выполняется никаких действий. Эти глаголы, формы от до , такие как am, is, are, обычно дополняются прилагательными.
Примеры глаголов состояний
Состояние глаголов в следующих предложениях выделено жирным шрифтом для облегчения идентификации.
- Я студент.
- Мы, , это артист цирка.
- Пожалуйста, – это тихо.
Типы глаголов
Есть много типов глаголов. Помимо основных категорий физических глаголов, мысленных глаголов и глаголов состояния бытия, существует несколько других типов глаголов. На самом деле существует более десяти различных типов глаголов, сгруппированных по функциям.
Список всех типов глаголов
Глаголы действия
Глаголы действия выражают определенные действия и используются каждый раз, когда вы хотите показать действие или обсудить, как кто-то что-то делает.Важно помнить, что действие не обязательно должно быть физическим.
Примеры глагола действия:
- Бег
- Танец
- Слайд
- Перейти
- Думаю
- До
- Перейти
- Стенд
- Улыбка
- Послушайте.
Примеры глаголов действия в следующих предложениях выделены жирным шрифтом для облегчения идентификации.
Я бегаю на быстрее Дэвида.
He делает хорошо.
Она думает о стихах весь день
Переходные глаголы
Переходные глаголы – это глаголы действия, которые всегда выражают выполнимые действия, которые связаны или влияют на кого-то или что-то еще. Эти другие вещи, как правило, являются прямыми объектами, существительными или местоимениями, на которые влияет глагол, хотя некоторые глаголы могут также принимать косвенные объекты, такие как show, take и make. В предложении с переходным глаголом кто-то или что-то получает действие глагола.
Примеры переходных глаголов:
- Любовь
- Респект
- Терпеть
- Верить
- Поддерживать.
Примеры переходных глаголов в следующих предложениях выделены жирным шрифтом для облегчения идентификации.
Гэри съел печенье.
Переходный глагол ate, Gary – подлежащее, потому что ест Гэри, а – cookies. – прямой объект, потому что это печенье, которое едят. Другие примеры:
– прямой объект, потому что это печенье, которое едят. Другие примеры:
Он ударил Джона.
Джон бьет его.
У них продано билет.
Примеры глаголов, используемых как с прямыми, так и с косвенными объектами:
Они продают ему билеты.
В этом предложении билеты являются прямым объектом, а его косвенным объектом.
Мэри испекла своей матери пирог.
В этом предложении пирог является прямым объектом, а ее мать является косвенным объектом.
Непереходные глаголы
Непереходные глаголы – это глаголы действия, которые всегда выражают выполнимые действия.Они отличаются от переходных глаголов тем, что после непереходного глагола нет прямого объекта.
Примеры непереходных глаголов:
- Прогулка
- Смех
- Кашель
- Играть
- Бег
Примеры непереходных глаголов в следующих предложениях выделены жирным шрифтом для облегчения идентификации.
Мы, , проехали в Лондон.
Непереходный глагол travelled , подлежащее we , потому что we совершает путешествие, но London не является прямым объектом, потому что London не получает действие глагола.Другие примеры:
Я чихаю утром.
He прибыл с запасом моментов.
Кэтрин села в стороне от остальных.
Джон съедает перед уходом в школу.
Последний пример показывает, что глагол ест может быть как переходным, так и непереходным, в зависимости от того, есть ли прямой объект или нет. Если предложение гласит: Джон ест печенье перед уходом в школу , ест будет переходным, поскольку существует прямой объект – печенье .
Кстати, некоторые глаголы могут быть как переходными, так и непереходными.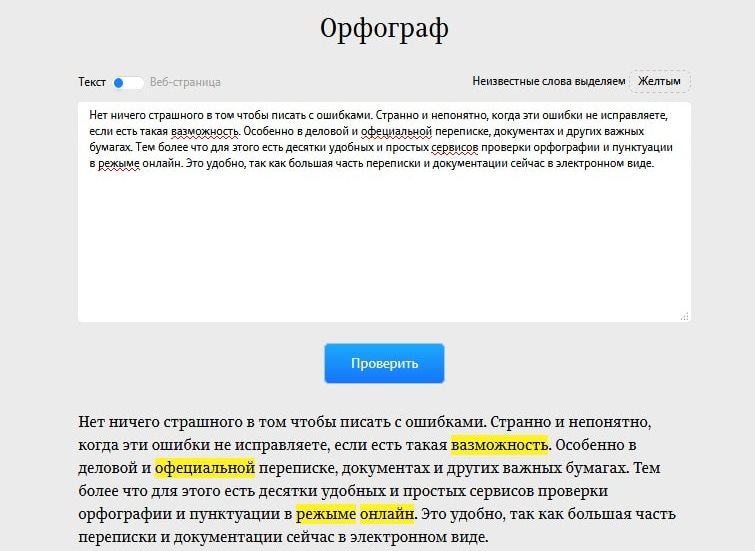 К этим глаголам относятся: начать, уйти, изменить, жить, остановиться.
К этим глаголам относятся: начать, уйти, изменить, жить, остановиться.
Вспомогательные глаголы
Вспомогательные глаголы также известны как вспомогательные глаголы и используются вместе с главным глаголом, чтобы показать время глагола, задать вопрос или отрицать. Общие примеры вспомогательных глаголов включают have, might, will . Эти вспомогательные глаголы придают некоторый контекст основному глаголу, например, позволяя читателю узнать, когда произошло действие.
Примеры вспомогательных глаголов:
- Будет
- Должен
- До
- Банка
- Сделал
- Может
- Май
Примеры вспомогательных глаголов в следующих предложениях выделены жирным шрифтом для облегчения идентификации.
Я поеду домой после футбольной тренировки.
Вспомогательный глагол will сообщает нам, что действие основного глагола go произойдет в будущем – после того, как закончится тренировка по футболу . Если вспомогательный глагол will был удален, мы получим предложение:
Если вспомогательный глагол will был удален, мы получим предложение:
Я иду домой после футбольной тренировки.
В данном случае нет определенных сроков проведения акции. Предложение предполагает, что возвращение домой после футбольной тренировки – это то, что обычно делает субъект I . Другие примеры:
Я могу танцевать с тобой позже.
Мы, , действительно, учли чувства Брайана.
Дженни произнесла свои последние слова.
Кроме того, иногда мы можем использовать вспомогательное слово очень перед местоимением, чтобы задать вопрос:
Может, ты потанцешь со мной позже?
Учитывались ли чувства Брайана?
Дженни произнесла свои последние слова?
Кроме того, вспомогательные глаголы используются для формирования отрицательных утверждений с использованием таких слов, как , а не и , никогда не . Обычно они разделяют вспомогательные и основные глаголы:
Обычно они разделяют вспомогательные и основные глаголы:
Я май Никогда больше не буду танцевать с тобой.
Мы, , действительно, не принимали во внимание чувства Брайана.
Дженни, , не произнесла свои последние слова.
Статические глаголы
Статические глаголы можно распознать, потому что они выражают состояние, а не действие. Обычно они связаны с мыслями, эмоциями, отношениями, чувствами, состояниями и измерениями. Лучший способ думать о глаголах состояния – это глаголы, описывающие вещи, не являющиеся действиями. Все глаголы состояния выражают состояние: состояние сомнения, состояние веры, состояние желания.Эти состояния часто временны.
Примеры глаголов состояния в следующих предложениях выделены жирным шрифтом для облегчения идентификации.
Врач не согласен с вашим анализом.
Не соглашаться – это глагол состояния здесь, так как он описывает состояние врача – несогласие.
Джон сомневается в мнении врача.
Я считаю, что доктор прав.
Она хотела другое мнение.
Модальные глаголы
Модальные глаголы – это вспомогательные глаголы, которые используются для выражения способностей, возможностей, разрешений и обязательств.
Примеры модальных глаголов:
- Банка
- Должен
- Май
- Должен
- Будет
Примеры модальных глаголов в следующих предложениях выделены жирным шрифтом для облегчения идентификации.
He может легко стрелять трехочковым.
Вспомогательный глагол can выражает способность, предполагая, что стрельба из трех точек – это навык, которым обладает субъект.
Обратите внимание, что в случае должно и должно быть в приведенных ниже примерах, модальные глаголы выражают обязательства, тогда как будет и может выражать возможности.
Я должен пойти домой.
Вы, , должны не задерживать.
Салли не рекомендовала бы суши.
Давид , возможно, опоздает.
Фразовые глаголы
Фразовых глаголов – это не отдельные слова; вместо этого они представляют собой комбинации слов, которые используются вместе для получения значения, отличного от значения исходного глагола. Существует множество примеров фразовых глаголов, некоторые из которых имеют разговорные значения, такие как составить, передать, поднять, указать, с нетерпением ждать.Каждый раз, когда глагол берет лишнее слово (а), он приобретает новое значение. Например, make без up означает, что что-то создается, тогда как make up предполагает, что в истории есть какая-то ложь или фантастический элемент, а make может означать либо схватить или увидеть что-то трудное, или страстно поцеловать.
Примеры фразовых глаголов:
- Закончился
- Изо всех сил
- Оформить
- Раздать
- Вывести
- Лицом вверх
- Продумайте
Примеры фразовых глаголов в следующих предложениях выделены жирным шрифтом для облегчения идентификации.
Мэри с нетерпением ждала встречи в старшей школе.
Глагол посмотрел преобразовал вперед до , чтобы стать фразовым глаголом, означающим что-то возбуждать или с нетерпением ждать чего-то.
He снова и снова приносил одни и те же очки.
Лерой, , передал бумажник в полицию.
Я делаю этаж постоянно.
Она указала на ошибку Дональда.
неправильные глаголы
Неправильные глаголы – это глаголы, которые не принимают правильные формы написания простых глаголов прошедшего времени и причастий прошедшего времени. К сожалению, в английском языке есть сотни неправильных глаголов. Но не волнуйтесь, хотя многие из них используются часто, большинство из них не используются – или, если они есть, вы будете использовать их так часто, что быстро их выучите. Некоторые из наиболее распространенных неправильных глаголов включают в себя: сказать, сделать, пойти, взять, прийти, узнать и увидеть.
Примеры неправильных глаголов:
- Есть
- Думаю
- Принесите
- Задержка
- Медведь
- Купить
- Lay
- Улов
- Привод
- Платный
- Чувствую
- Повторить
Примеры неправильных глаголов в следующих предложениях выделены жирным шрифтом для облегчения идентификации.
Я беру мое время, когда я хожу в магазины (настоящее время)
Я взял мое время, когда я пошел в магазины (прошедшее время)
Джули делает торт для школы (настоящее время)
Джули сделала торт для класса (прошедшее время)
Она видит силуэт в форме человека в окне (настоящее время)
Она увидела силуэт в форме человека в окне (прошедшее время)
Ср., , каждый год к тете Джейн на День Благодарения (настоящее время)
Мы, , каждый год приходили к тете Джейн на День Благодарения (прошедшее время).
Также следует помнить, что вспомогательные глаголы «делать» и «иметь» также являются неправильными глаголами:
Я да согласен.
He делает это часто.
Мы, , заранее выполнили домашнее задание.
Они делают домашнее задание по пятницам.
У меня есть подозрение на фран
Fran имеет искривленный вид.
У нас нет денег.
У них было кашель дважды за эту зиму.
Исправление грамматических ошибок: Машины понимают и исправляют ошибки в тексте! | Айшани Басу | Аналитика Vidhya
На графике выше показаны облака слов, позволяющие определить наиболее часто встречающиеся слова в грамматически правильных и грамматически неправильных предложениях, которые в чем-то похожи (подумай, сегодня, друг и т. Д.).
Мы также можем создать собственный набор данных, добавив ошибки в текст, полученный из любого источника. Вот простой код, использующий для этого Spacy.
Вот простой код, использующий для этого Spacy.
Мы используем замаскированную разреженную категориальную кроссэнтропию потерю в качестве функции потерь.
Метрики:Оценка Fbeta (с бета = 0,5) используется в качестве показателя обучения, а баллов BLEU для оценки окончательной производительности.
Для базовой модели я внимательно обучил ванильную модель декодера кодировщика и модель декодера кодировщика.
Encoder Decoder and Attention model Представленный Sutskever et.al., кодер-декодер модели , широко используемый для преобразования последовательности в последовательность, в основном состоит из двух блоков, кодировщика и декодера, где кодировщик кодирует входной вектор в вектор контекста , в то время как декодер , декодирует этот вектор контекста в выходной . Предполагается, что вектор контекста захватит сущность входных данных , которые, по сути, являются выходными данными кодировщика. RNN широко используются в качестве кодировщика и декодера, поскольку они очень хорошо фиксируют последовательную информацию.
Предполагается, что вектор контекста захватит сущность входных данных , которые, по сути, являются выходными данными кодировщика. RNN широко используются в качестве кодировщика и декодера, поскольку они очень хорошо фиксируют последовательную информацию.
Модель кодера-декодера работает очень хорошо, но имеет проблемы с улавливанием сути, когда входной вектор начинает удлиняться. Для решения этой проблемы был введен механизм внимания Bahdanau et. al. улучшить модель кодировщика-декодера, чтобы обеспечить успешный перевод более длинных входных предложений.
Интуитивно понятно, что механизм внимания принимает вектор контекста, а выходные данные кодировщика для каждого отдельного временного шага и вычисляют весовой коэффициент внимания для каждого временного шага кодировщика. Этот вес сообщает нам , какое значение придавать каждому выходному сигналу кодировщика , и умножается на выходной сигнал кодировщика для каждого временного шага и передается в декодер на каждом временном шаге. Таким образом, декодер знает, какому входному слову следует уделять максимальное внимание при определении выходных данных декодера на каждом временном шаге .Следующее изображение объясняет сеть внимания.
Таким образом, декодер знает, какому входному слову следует уделять максимальное внимание при определении выходных данных декодера на каждом временном шаге .Следующее изображение объясняет сеть внимания.
Синие блоки в левом нижнем углу, обозначенные полосой hs, представляют выход кодировщика для всех временных шагов. Мы можем представить, что пять синих блоков представляют вход кодировщика или, другими словами, пять слов (при условии перевода на уровне слов), которые подавались в блок кодировщика на каждом временном шаге, давая нам выходные данные кодировщика на каждом временном шаге.
Бордовые блоки справа внизу, обозначенные ht, представляют скрытое состояние декодера на каждом временном шаге, поэтому для простоты предположим, что последний блок декодирует второе слово входного предложения.
Как показано на левом изображении, при декодировании для каждого шага из выходных данных кодировщика создается контекстный вектор , ct. Если используется глобальное внимание , для создания этого вектора используются все выходы кодировщика (то есть на всех временных шагах). Этот вектор на самом деле является просто суммой умножения каждого из выходных данных на с весом внимания . at обозначает вектор, содержащий все веса внимания для каждого временного шага.
Если используется глобальное внимание , для создания этого вектора используются все выходы кодировщика (то есть на всех временных шагах). Этот вектор на самом деле является просто суммой умножения каждого из выходных данных на с весом внимания . at обозначает вектор, содержащий все веса внимания для каждого временного шага.
Чтобы получить этот вес внимания, мы используем функции оценки и применяем их к выходным данным кодировщика и скрытым состояниям декодера.Например, если мы используем функцию оценки скалярного произведения, мы просто берем скалярное произведение состояний кодировщика и скрытого состояния декодера, чтобы получить вес внимания. Этот вес говорит нам, насколько важное значение или контекст придает нам каждое состояние кодера для текущего состояния декодера.
Для местного внимания , как показано справа, мы используем только состояния кодировщика в непосредственной близости от временного шага, на котором находится декодер.
Наконец, мы объединяем текущее скрытое состояние ht декодера с вектором контекста ct и передаем его декодеру, чтобы получить следующее скрытое состояние декодера ht ~.
Обучение :Я обучил модель с помощью оптимизатора Adam со скоростью обучения 0,01. Для встраиваний я использовал вложения FastText со ссылкой на этот github. Я использовал максимальную длину предложений до 15 для достижения наилучших результатов.
Результаты:
Графики внимания:
Результаты перевода:
Итоговая оценка BLEU: 0,68
Спасибо за чтение!
Весь код доступен здесь.
Существует множество возможностей для улучшения существующих подходов за счет использования мощи современных архитектур NLP, таких как архитектуры GPT, BERT и т. Д. GAN также оказались кардинальными для многих приложений NLP. и может еще больше улучшить результат.
Исправление грамматических ошибок с помощью глубокого обучения | by PUSHAP GANDHI
- Введение
- Определение проблемы
- Предварительные требования
- Источник данных
- Понимание данных
- Исследовательский анализ данных
- Предварительная обработка данных
- Подготовка данных и решение для конвейера данных Тестовый кодер
- Механизм внимания
- Монотонное внимание
- Вывод (жадный поиск VS поиск BEAM)
- Результаты и сравнение моделей
- Развертывание модели и прогнозы
- Будущие работы
- Репозиторий Github и исправление ошибок в Linkedin Справочник по Github
- Название предполагает, что процесс обнаружения и исправления ошибки в тексте.
 Проблема кажется легкой для понимания, но на самом деле она сложна из-за разнообразия словаря и набора правил в языке. Кроме того, мы собираемся не только выявить ошибку, но и исправить ее.
Проблема кажется легкой для понимания, но на самом деле она сложна из-за разнообразия словаря и набора правил в языке. Кроме того, мы собираемся не только выявить ошибку, но и исправить ее.Приложение:
- У этой проблемы есть множество приложений, поэтому письмо является очень распространенным средством обмена идеями и информацией. Это может помочь автору ускорить свою работу с минимальной вероятностью ошибки.
- Более того, может быть много людей, которые не владеют определенным языком.Таким образом, эти типы моделей гарантируют, что язык не станет препятствием в общении.
Теперь мы определим поставленную задачу в задачу машинного обучения. Проблема, с которой мы имеем дело, является разновидностью проблемы NLP (обработки естественного языка). НЛП – это область машинного обучения, которая занимается взаимодействием между человеческими языками и компьютерами. Я бы рекомендовал просмотреть этот документ, чтобы узнать о прогрессе подходов, используемых для решения проблемы.

Подход, который мы собираемся изучить, – это модель от последовательности к последовательности.Короче говоря, модель глубокого обучения получит последовательность (в данном случае неверный текст) и выведет другую последовательность (в данном случае исправленный текст).
Показатель производительности
Теперь, когда мы определили нашу проблему как задачу машинного обучения, есть еще одна очень важная идея, с которой необходимо разобраться, – показатель производительности. Показатель производительности – это математическая мера, которая помогает понять эффективность нашей модели машинного обучения.
Очень популярная метрика производительности для задач НЛП – это баллов BLEU (двуязычная оценка дублера) , поэтому мы собираемся использовать ее и для нашей модели.Вы можете обратиться к этому видео, чтобы узнать больше о показателях BLEU.
Прежде чем мы углубимся в детали этого тематического исследования, я предполагаю, что читатели знают концепции машинного обучения и глубокого обучения.
 Если быть точным, идеи LSTM, кодировщиков-декодеров, механизма внимания должны быть вам знакомы.
Если быть точным, идеи LSTM, кодировщиков-декодеров, механизма внимания должны быть вам знакомы.Я постараюсь дать несколько хороших рекомендаций по пути.
Как я уже упоминал выше, с проблемой трудно справиться, одной из причин которой является недоступность набора данных хорошего качества.В своем исследовании я нашел некоторые из них полезными и рассмотрел следующие два набора данных.
- Lang-8 Dataset
- NUS Social Media Text Normalization and Translation Corpus
Оба этих набора данных общедоступны, если вы хотите поработать с ними.
5.1 Lang-8 Dataset
Это японский веб-сайт, предназначенный для изучения языков. Пользователи могут публиковать сообщения на языке (ах), который они изучают, и эта публикация будет видна носителям этого языка для исправления.Набор данных с этого веб-сайта содержит данные в следующем столбце, разделенном \ t:
- Номер исправления
- Серийный номер
- Номер предложения
- 0 – это заголовок
- Предложение, написанное изучающим английский язык
- Исправленные предложения ( Если существует)
Из этого мы извлекли входных предложений и исправили пар предложений для тех точек данных, для которых существуют оба этих предложения.

5.2 NUS Корпус нормализации и перевода текста социальных сетей
Это набор данных Национального университета Сингапура (NUS), который представляет собой текстовые данные социальных сетей.Размер набора данных составляет 2000 точек данных. Данные в необработанном виде содержат по три строки для каждой точки данных.
- Первая строка – это текст социальной сети
- Вторая строка – это правильный официально переведенный текст на английский язык
- Третья строка – это данные, переведенные на китайский язык.
Из них мы можем использовать первые две строки каждой точки данных для нашей задачи.
После того, как мы извлекли данные в требуемой форме, теперь это очень важный шаг, который представляет собой исследовательский анализ данных, который дает возможность понять и развить хорошее представление о наборе данных.
Я извлек и предварительно обработал набор данных в требуемой форме, которая будет обсуждаться в следующем разделе.

6.1 Базовая статистика
Сначала мы соберем общую информацию о наборе данных, такую как количество точек данных, типы данных, средние или медианные значения числовых данных и т. Д.
# TOTAL DATAPOINTS
df.shape
# CHECK FOR NULL ЗНАЧЕНИЯ
df.info ()Итак, имеется около 500 тыс. Точек данных, а нулевые значения отсутствуют.
У нас есть два столбца в наборе данных: один является входным, а другой – выходным или целевым.Давайте посмотрим один за другим анализ для каждого столбца.
6.2 Анализ распределения длины текста и количества слов
Неверный текст
Ввод – это текстовая функция, мы можем проанализировать распределение длины текста и распределение количества слов.
- Распределение длины символов и количества слов во входных данных сильно искажено.
- Оба распределения почти следуют одному и тому же образцу.
- Количество символов во вводе может достигать 2000, а количество слов до 400 слов.

- Соотношение большей длины слов или символов значительно меньше.
- Более 99 процентов входных данных имеют количество символов меньше 200 и количество слов меньше 50.
Исправленный текст
То же самое сделано и для выходного текста.
И что удивительно, наблюдения для входного текста верны и для выходного текста.
6.3 Анализ облака слов для неправильного и исправленного текста
Облако слов – отличная визуализация, позволяющая узнать наиболее часто встречающиеся слова в общем тексте.
Облако слов для ввода текста Облако слов для вывода текстаНаиболее распространенные слова в обоих текстах:
- думаю
- хочу
- сегодня
- Япония
- Английский
6.4 Анализ неправильных и исправленных слов
Здесь неправильных слов – это те слова, которые присутствуют во вводе, но не присутствуют в целевых предложениях, а Исправленные слова – это те слова, которые присутствуют в целевых предложениях, но не присутствуют во вводимых предложениях.
 Я извлек все эти слова и провел анализ облака слов.
Я извлек все эти слова и провел анализ облака слов.- Наблюдая за неправильными и исправленными изображениями слов, мы можем наблюдать изменение формы используемого глагола.
пошел ==> пошел
пошел ==> пошел
исследование ==> изучение
использование ==> с использованием6.5 POS Tagging
В этой части анализа мы свяжем слова с их частями речи и составьте 10 наиболее часто встречающихся частей речи.Ниже приведены графики:
Top 10 POS для входного текста Top 10 POS для выходного текста- Это показывает, что часть речи, используемая максимальное количество раз, – это существительное (NN), за которым следует предлог (IN).
- Общее количество частей речи остается неизменным для входных и выходных предложений, но цифры различаются в NNS (существительное, множественное число) и PRP (личные местоимения)
Теперь мы увидим, как удалить нежелательные данные из нашего набора данных . Мы знаем, что данные представлены в текстовом формате, поэтому необходимо удалить все специальные символы, ненужные пробелы и выполнить деконракцию сокращенных слов.
 Мы также собираемся преобразовать весь текст в нижний, чтобы упростить задачу. Следующий код используется для выполнения всех вышеупомянутых операций:
Мы также собираемся преобразовать весь текст в нижний, чтобы упростить задачу. Следующий код используется для выполнения всех вышеупомянутых операций:После этого мы также можем выполнить некоторые другие операции, такие как удаление нулевых значений и дедупликация, которые доступны в библиотеке pandas.
Перед тем, как передать наши данные в модель DL, их необходимо преобразовать в форму, понятную машине. Итак, для этой проблемы мы собираемся использовать токенизацию и заполнение, чтобы преобразовать набор данных в последовательность целых чисел одинаковой длины.
При формировании конвейера данных для модели мы собираемся дополнить последовательность, чтобы сформировать длину всех точек данных равной. Максимальная длина, используемая для заполнения, составляет 99-й процентиль распределения количества слов.
Data Pipeline
Данные необходимо преобразовать в пакеты, чтобы ввести их в модель глубокого обучения. Следующий код используется для формирования конвейера для набора данных
В качестве эталонного решения я перейду к ванильной модели последовательности в последовательность, которая также известна как модель кодировщика-декодера.
Изображение из бумаги Эффективные подходы к нейронному машинному переводу на основе внимания Эта модель принимает входные данные в виде последовательности и предсказывает другую последовательность в качестве выходных данных. Благодаря этому он имеет множество применений в задачах машинного перевода.
Эта модель принимает входные данные в виде последовательности и предсказывает другую последовательность в качестве выходных данных. Благодаря этому он имеет множество применений в задачах машинного перевода.Следующий код используется для формирования слоев кодировщика-декодера в модели.
Это действительно хороший блог, чтобы получить представление о моделях кодировщика-декодера.
Я пробовал много вариантов моделей Vanilla Encoder-Decoder, например, с использованием предварительно обученных внедрений Word2Vec и FastText, вы можете проверить их в моем профиле GitHub.
Поэкспериментировав с этими моделями, я обнаружил, что в моем случае обучаемые вложения работают лучше, чем предварительно обученные, поэтому они будут использоваться для расширенных моделей.
СИНЯЯ оценка, полученная для Encoder-Decoder для нашего набора данных, составляет 0,4603.

Механизм внимания – это очень гениальная идея машинного обучения, которая клонирует гуманистический способ получения информации. Более того, у простой модели кодировщика-декодера есть определенные недостатки, которые преодолевает модель внимания.Некоторые из популярных техник механизмов внимания, используемых сегодня, – это «Механизм внимания Бахданау», «Механизм внимания на отдыхе».
Позвольте мне вкратце рассказать об этапах механизма «Loung Attention», который я широко использовал в своем тематическом исследовании. Если быть точным, эта идея известна как механизм глобального внимания .
Изображение из бумаги Эффективные подходы к нейронному машинному переводу на основе вниманияКодер остается таким же, как обычный кодер-декодер, который выводит скрытые состояния входной последовательности.Теперь в части декодера для каждого временного шага мы должны вычислить нечто, называемое вектором контекста . Этот вектор контекста содержит релевантную информацию от кодировщика о словах, которые должны быть предсказаны на этом временном шаге.
 Это может показаться сложным, но как только вы узнаете, как это вычисляется, все встанет на свои места.
Это может показаться сложным, но как только вы узнаете, как это вычисляется, все встанет на свои места.- Во-первых, когда мы достигаем всех скрытых состояний кодировщика (ht) и декодируем предыдущие скрытые (hs) из RNN, мы находим альфа-значения ().
В статье Loung и другие предложили три альтернативы для вычисления оценки.
- После вычисления альфа-значений вектор контекста вычисляется как средневзвешенное значение по всем скрытым состояниям кодировщика с весовыми коэффициентами, являющимися альфа-значениями.
- Для заданного целевого скрытого состояния и вектора контекста на стороне источника слои простой конкатенации, если они используются для объединения информации из обоих векторов для создания скрытого состояния внимания, следующим образом:
- Вектор внимания h˜t затем подается через слой softmax для создания следующего слова в последовательности.
Этот тип механизма внимания называется механизмом глобального внимания, потому что все скрытые состояния кодера учитываются на каждом временном шаге декодера для создания вектора контекста.

В этом примере я реализовал механизм Loung Attention с нуля через создание подклассов модели. Ниже приведен код слоя «Внимание» для оценки типа Dot . Полный код можно найти в моем профиле GitHub.
Показатели производительности моделей Attention значительно лучше, чем у наших эталонных моделей.
Оценка BLEU
Оценка в точках 0,5055
Общая оценка 0,5545
Оценка Concat 0,5388Прежде чем мы перейдем к деталям для монотонного внимания, давайте рассмотрим некоторые недостатки простого механизма внимания и необходимость монотонного внимания.
Мы знаем, что в механизмах внимания на каждом временном шаге декодера необходимо ссылаться на все скрытые состояния кодера. Это создает квадратичную временную сложность , что препятствует его использованию в онлайн-настройках .
Поэтому, чтобы преодолеть этот недостаток, вводится концепция монотонного внимания, которая просто говорит о том, что нет необходимости проверять все веса внимания на каждом временном шаге.
 Мы собираемся проверить скрытые состояния в определенном порядке (слева направо на английском языке), и одно из скрытых состояний выбирается в качестве вектора контекста на каждом временном шаге. После проверки конкретной записи она не будет проверяться на следующем временном шаге.
Мы собираемся проверить скрытые состояния в определенном порядке (слева направо на английском языке), и одно из скрытых состояний выбирается в качестве вектора контекста на каждом временном шаге. После проверки конкретной записи она не будет проверяться на следующем временном шаге.
Softmax Внимание: Изображение из этого блога Монотонное внимание: Изображение из этого блогаСамым важным преимуществом этого подхода является линейная временная сложность, поэтому его можно использовать для онлайн-настроек.
Здесь мы собираемся реализовать очень простой тип монотонного внимания, как описано в этом блоге и статье. Следует иметь в виду, что изменения будут происходить только на уровне внимания, но уровень кодера и декодера останется прежним. Это шаги для монотонного внимания:
- Учитывая предыдущие скрытые состояния, мы собираемся вычислить оценку или энергию, для которой мы собираемся использовать те же методы, которые использовались выше в механизме внимания Лунга.

- После вычисления оценки она преобразуется в вероятности с помощью сигмоидной функции.
- Внимание для текущего временного шага вычисляется по этой формуле:
- Как только мы получаем веса внимания, мы выполняем аналогичные шаги по вычислению взвешенной суммы, чтобы получить вектор контекста и объединить его со скрытым состоянием декодер, чтобы пройти через слой softmax.
В этом тематическом исследовании я реализовал только одну вариацию слоя монотонного внимания.Для получения дополнительной информации см. Блог и код Колина Раффеля, где он дал полную реализацию этого уровня.
Выполнение монотонного внимания сравнимо с простым вниманием, но, как упоминалось в статье, оно дает некоторое преимущество во временной сложности.
Если вы знаете о моделях от последовательности к последовательности, то вы должны знать о том, что мы должны внести определенные изменения в модель, чтобы предсказать требуемый результат во время логического вывода.

Опять же, у нас есть две опции, одна известна как жадный поиск, а другая – поиск луча.Давайте посмотрим на них обоих по очереди.
Жадный поиск
При жадном поиске для каждого временного шага мы рассматриваем токен с максимальной вероятностью и игнорируем все оставшиеся токены, даже если они имеют сопоставимые значения вероятностей после слоя softmax.
В коде вы можете увидеть функцию argmax на выходе плотного слоя активации softmax.
Прогнозы с жадным поискомУ этого есть недостаток, потому что, если какое-либо из предсказанных слов на временном шаге неверно, это также повлияет на результат будущих временных шагов.
Поиск BEAM
Лучшим способом прогнозирования является поиск BEAM, в котором на каждом временном шаге предоставляется выбор для наиболее вероятных маркеров с номерами, равными Ширина BEAM , а общая оценка для каждой из прогнозируемых последовательностей равна равняется произведению вероятностей для каждого слова в последовательности.

В этом примере я взял ширину луча равной 3. Для получения дополнительной информации вы можете просмотреть этот блог.
Ссылка на код.Прогнозирование с помощью BEAM SearchДля этого тематического исследования я испробовал в общей сложности 12 моделей с определенными вариациями. Ниже приведены результаты.
- Результаты механизма внимания лучше, чем у простого кодировщика-декодера, и среди моделей внимания производительность не сильно отличается.
- Мы также можем заметить, что оценка BLEU для лучевого поиска лучше, чем жадный поиск, как ожидалось.
Я выполнил развертывание модели для модели Monotonic Attention , которая вычисляет оценку с помощью скалярного произведения .Ознакомиться с моделью можно по этой ссылке.
Вот некоторые из прогнозов для вышеупомянутой модели:
- Для будущей работы я хотел бы поработать с другими вариациями механизма монотонного внимания.
- Если лучший набор данных доступен публично, это действительно может улучшить производительность модели.

Я попытался кратко рассказать о работе, которую я проделал в этом проекте. Если вы хотите увидеть полный подробный код, в котором я прокомментировал каждую строку, загляните в мой репозиторий Github.Не стесняйтесь подключаться к Linkedin.
Если вы уже достигли этого, помогите мне улучшить содержание, оставив комментарий. Для меня это много значит 🙂
Исправление ошибок в тексте | SpringerLink
Бил, К. Р. (1990). Развитие навыков оценки и редактирования текстов, Развитие ребенка 61: 247–258.
Google Scholar
Бил, К. Р., Гаррод, А. К. и Бонитатибус, Г.Дж. (1990). Развитие у детей навыков повторения ошибок посредством обучения мониторингу понимания, Journal of Educational Psychology 82: 275–280.
Google Scholar
Bracewell, R. (1983). Изучение контроля навыков письма. В: П. Мозенталь, Л.
 Тамор и С. А. Уолмсли (ред.), Исследование письма: принципы и методы . Нью-Йорк: Лонгман.
Тамор и С. А. Уолмсли (ред.), Исследование письма: принципы и методы . Нью-Йорк: Лонгман.Google Scholar
Брансфорд, Дж.Д. и Джонсон, М. К. (1972). Контекстуальные предпосылки для понимания: некоторые исследования понимания и запоминания, Journal of Verbal Learning and Verbal Behavior 11: 717–726.
Google Scholar
Баттерфилд, Э. и Ферретти, Р. (1987). К теоретической интеграции гипотез об интеллектуальных различиях среди детей. В: Дж. Г. Борковски и Дж. Д. Дэй (ред.), Познание у особых детей (стр.195–234). Норвуд, Нью-Джерси: Ablex.
Google Scholar
Кьези, Х. Л., Спилих, Г. Дж. И Восс, Дж. Ф. (1979). Получение информации, относящейся к предметной области, в отношении высоких и низких знаний предметной области, Journal of Verbal Learning and Verbal Behavior 18: 257–274.

Google Scholar
Daiute, C. & Kruidenier, J. (1985). Стратегия самоанализа для увеличения количества проверок молодых писателей, Прикладная психолингвистика 6: 307–318.
Google Scholar
DeRemer, M. & Bracewell, R. (1989). Использование студентами семантической структуры при пересмотре своего письма. Документ представлен на ежегодном собрании Американской ассоциации исследований в области образования.
Энглерт, К. С., Хиберт, Э. Х. и Стюарт, С. Р. (1988). Выявление и исправление несоответствий в мониторинге пояснительной прозы, Journal of Educational Research 81: 221–227.
Google Scholar
Файгли Л. и Витте С. (1981). Анализирующая редакция, Состав и коммуникация колледжа 32: 400–414.
Google Scholar
Финчер-Кифер Р.
 , Пост Т., Грин Т. и Восс Дж. (1988). О роли предварительных знаний и требований задач в обработке текста, Journal of Memory and Language 27: 416–428.
, Пост Т., Грин Т. и Восс Дж. (1988). О роли предварительных знаний и требований задач в обработке текста, Journal of Memory and Language 27: 416–428.Google Scholar
Фицджеральд Дж. (1987). Письменное исследование по исправлению ситуации, Обзор исследований в области образования 57: 481–506.
Google Scholar
Флавелл, Дж. Х. (1979). Метапознание и когнитивный мониторинг: новая область когнитивного исследования развития, Американский психолог 3: 906–911.
Google Scholar
Цветок, L., Хейс, Дж. Р., Кэри, Л., Шрайвер, К., и Стратман, Дж. (1986). Выявление, диагностика и стратегии пересмотра, Состав и коммуникация колледжа 37: 16–55.
Google Scholar
Халл, Г. (1987). Письменный процесс редактирования: исследование эффективности более квалифицированных и менее квалифицированных писателей из колледжа, Research in the Teaching of English 21: 8–29.

Google Scholar
Келлог, Р.Т. (1987). Влияние знания темы на распределение времени обработки и когнитивных усилий на процессы письма, Память и познание 15: 256–266.
Google Scholar
McCutchen, D. (1986). Знания в предметной области и лингвистические знания в развитии навыков письма, Journal of Memory and Language 25: 431–444.
Google Scholar
Маккатчен, Д., Халл, Г. А. и Смит, В. Л. (1987). Стратегии редактирования и исправление ошибок в основах письма, Письменное общение 4: 139–154.
Google Scholar
Средство, М. Л. и Восс, Дж. Ф. (1985). Звездные войны: развивающее исследование структур знаний экспертов и новичков, Journal of Memory and Language 24: 746–757.
Google Scholar
Скардамалия, М.
 И Bereiter, C. (1983). Развитие оценочных, диагностических и лечебных способностей в детском сочинении. В: M. Martlew (ed.), Психология письменной речи: подход к развитию, (стр. 67–95). Лондон: Джон Вили и сыновья.
И Bereiter, C. (1983). Развитие оценочных, диагностических и лечебных способностей в детском сочинении. В: M. Martlew (ed.), Психология письменной речи: подход к развитию, (стр. 67–95). Лондон: Джон Вили и сыновья.Google Scholar
Соммерс, Н. (1980). Стратегии пересмотра студентов-писателей и опытных взрослых писателей, College Compostion and Communication 31: 378–388.
Google Scholar
Спилич, Г. Дж., Везондер, Г. Т., Кьези, Х. Л. и Восс, Дж. Ф. (1979). Обработка текста предметной информации для людей с высокими и низкими знаниями в предметной области, Journal of Verbal Learning and Verbal Behavior 18: 275–290.
Google Scholar
Сталлард, К. К. (1974). Анализ поведения хороших студентов-писателей, Research in the Teaching of English 8: 206–218.
Google Scholar
Восс, Дж.
 Ф., Везондер, Г. Т. и Спилич, Г. Дж. (1980). Генерация тестов и их повторение специалистами с высоким и низким уровнем знаний, Journal of Verbal Learning and Verbal Behavior 19: 651–667.
Ф., Везондер, Г. Т. и Спилич, Г. Дж. (1980). Генерация тестов и их повторение специалистами с высоким и низким уровнем знаний, Journal of Verbal Learning and Verbal Behavior 19: 651–667.Google Scholar
Уотерс, Х. С. (1990). Развитие навыков ревизии. Документ, представленный на ежегодном собрании Американской ассоциации исследований в области образования в Бостоне.
Фреймворк для обнаружения, выделения и исправления грамматических ошибок в тексте на естественном языке.
Привет, я использую ваш код последние несколько дней. Внезапно он начал вылетать.
Посмотрите на код и ошибку, приведенные ниже:
Код(ссылка: https://huggingface.co/prithivida/grammar_error_correcter_v1):
от gramformer import Gramformer
импортный фонарик
def set_seed (семя):
torch.manual_seed (семя)
если torch.cuda.доступен():
torch.cuda.manual_seed_all (семя)
set_seed (1212)
gf = Gramformer (models = 2, use_gpu = False) # 0 = детектор, 1 = маркер, 2 = корректор, 3 = все
Influent_sentences = [
«Матовый, как рыба»,
"сборник писем оригинально использовался древними римлянами",
«Нам нравятся фильмы ужасов»,
«Анна и Майк собираются кататься на лыжах»,
«Я иду в магазин и купила молоко»,
«Мы все едим рыбу, а потом готовим десерт»,
«Съеду на обед рыбу и молоко напьюсь»,
"по какой причине все уходят из компании",
]
для Influent_sentence в Influent_sentences:
corrected_sentence = gf. правильно (Influent_sentence)
print ("[Ввод]", influent_sentence)
print ("[Исправление]", исправленное_предложение [0])
print ("-" * 100)
правильно (Influent_sentence)
print ("[Ввод]", influent_sentence)
print ("[Исправление]", исправленное_предложение [0])
print ("-" * 100)
Ошибка
404 Ошибка клиента: не найдено для URL: https://huggingface.co/prithivida/grammar_error_correcter/resolve/main/config.json
-------------------------------------------------- -------------------------
HTTPError Traceback (последний вызов последним)
/usr/local/lib/python3.7/dist-packages/transformers/configuration_utils.py в get_config_dict (cls, pretrained_model_name_or_path, ** kwargs)
491 use_auth_token = use_auth_token,
-> 492 user_agent = user_agent,
493)
7 кадров
/usr/local/lib/python3.7/dist-packages/transformers/file_utils.py в cached_path (url_or_filename, cache_dir, force_download, proxies, resume_download, user_agent, extract_compressed_file, force_extract, use_auth_token, local_files)
1278 use_auth_token = use_auth_token,
-> 1279 local_files_only = local_files_only,
1280)
/ usr / local / lib / python3. 7 / dist-packages / transformers / file_utils.py в get_from_cache (url, cache_dir, force_download, proxies, etag_timeout, resume_download, user_agent, use_auth_token, local_files_only)
1441 r = requests.head (URL-адрес, заголовки = заголовки, allow_redirects = False, прокси = прокси, тайм-аут = etag_timeout)
-> 1442 г. raise_for_status ()
1443 etag = r.headers.get («X-Linked-Etag») или r.headers.get («ETag»)
/usr/local/lib/python3.7/dist-packages/requests/models.py в raise_for_status (self)
942, если http_error_msg:
-> 943 поднять HTTPError (http_error_msg, response = self)
944
HTTPError: 404 Ошибка клиента: не найдено для URL: https: // huggingface.co / prithivida / grammar_error_correcter / resolve / main / config.json
Во время обработки вышеуказанного исключения произошло другое исключение:
OSError Traceback (последний вызов последним)
7 / dist-packages / transformers / file_utils.py в get_from_cache (url, cache_dir, force_download, proxies, etag_timeout, resume_download, user_agent, use_auth_token, local_files_only)
1441 r = requests.head (URL-адрес, заголовки = заголовки, allow_redirects = False, прокси = прокси, тайм-аут = etag_timeout)
-> 1442 г. raise_for_status ()
1443 etag = r.headers.get («X-Linked-Etag») или r.headers.get («ETag»)
/usr/local/lib/python3.7/dist-packages/requests/models.py в raise_for_status (self)
942, если http_error_msg:
-> 943 поднять HTTPError (http_error_msg, response = self)
944
HTTPError: 404 Ошибка клиента: не найдено для URL: https: // huggingface.co / prithivida / grammar_error_correcter / resolve / main / config.json
Во время обработки вышеуказанного исключения произошло другое исключение:
OSError Traceback (последний вызов последним)
в
10
11
---> 12 gf = Gramformer (models = 2, use_gpu = False) # 0 = детектор, 1 = маркер, 2 = корректор, 3 = все
13
14 Influent_sentences = [
/usr/local/lib/python3. 7/dist-packages/gramformer/gramformer.py в __init __ (self, models, use_gpu)
14
15, если модели == 2:
---> 16 сам.Correction_tokenizer = AutoTokenizer.from_pretrained (Correction_model_tag)
17 self.correction_model = AutoModelForSeq2SeqLM.from_pretrained (Correction_model_tag)
18 self.correction_model = self.correction_model.to (устройство)
/usr/local/lib/python3.7/dist-packages/transformers/models/auto/tokenization_auto.py в from_pretrained (cls, pretrained_model_name_or_path, * inputs, ** kwargs)
400 кварг ["_ from_auto"] = Верно
401, если не isinstance (config, PretrainedConfig):
-> 402 config = AutoConfig.from_pretrained (pretrained_model_name_or_path, ** kwargs)
403
404 use_fast = kwargs.pop ("use_fast"; Истина)
/usr/local/lib/python3.7/dist-packages/transformers/models/auto/configuration_auto.py в from_pretrained (cls, pretrained_model_name_or_path, ** kwargs)
428 "" "
429 кваргс ["_ from_auto"] = Верно
-> 430 config_dict, _ = PretrainedConfig.
7/dist-packages/gramformer/gramformer.py в __init __ (self, models, use_gpu)
14
15, если модели == 2:
---> 16 сам.Correction_tokenizer = AutoTokenizer.from_pretrained (Correction_model_tag)
17 self.correction_model = AutoModelForSeq2SeqLM.from_pretrained (Correction_model_tag)
18 self.correction_model = self.correction_model.to (устройство)
/usr/local/lib/python3.7/dist-packages/transformers/models/auto/tokenization_auto.py в from_pretrained (cls, pretrained_model_name_or_path, * inputs, ** kwargs)
400 кварг ["_ from_auto"] = Верно
401, если не isinstance (config, PretrainedConfig):
-> 402 config = AutoConfig.from_pretrained (pretrained_model_name_or_path, ** kwargs)
403
404 use_fast = kwargs.pop ("use_fast"; Истина)
/usr/local/lib/python3.7/dist-packages/transformers/models/auto/configuration_auto.py в from_pretrained (cls, pretrained_model_name_or_path, ** kwargs)
428 "" "
429 кваргс ["_ from_auto"] = Верно
-> 430 config_dict, _ = PretrainedConfig. get_config_dict (pretrained_model_name_or_path, ** kwargs)
431, если "model_type" в config_dict:
432 config_class = CONFIG_MAPPING [config_dict ["тип_модели"]]
/ usr / local / lib / python3.7 / dist-packages / transformers / configuration_utils.py в get_config_dict (cls, pretrained_model_name_or_path, ** kwargs)
502 f "- или '{pretrained_model_name_or_path}' - правильный путь к каталогу, содержащему файл {CONFIG_NAME} \ n \ n"
503)
-> 504 поднять EnvironmentError (msg)
505
506, кроме json.JSONDecodeError:
OSError: не удается загрузить конфигурацию для 'prithivida / grammar_error_correcter'. Убедись в том, что:
- 'prithivida / grammar_error_correcter' - правильный идентификатор модели, указанный на 'https: // huggingface.co / models '
- или 'prithivida / grammar_error_correcter' - это правильный путь к каталогу, содержащему файл config.json
! [Скриншот от 2021-07-01 18-36-07] (https://user-images.githubusercontent.com/4704211/124133526-5a9da900-da9b-11eb-9733-61df46ab01e1.
get_config_dict (pretrained_model_name_or_path, ** kwargs)
431, если "model_type" в config_dict:
432 config_class = CONFIG_MAPPING [config_dict ["тип_модели"]]
/ usr / local / lib / python3.7 / dist-packages / transformers / configuration_utils.py в get_config_dict (cls, pretrained_model_name_or_path, ** kwargs)
502 f "- или '{pretrained_model_name_or_path}' - правильный путь к каталогу, содержащему файл {CONFIG_NAME} \ n \ n"
503)
-> 504 поднять EnvironmentError (msg)
505
506, кроме json.JSONDecodeError:
OSError: не удается загрузить конфигурацию для 'prithivida / grammar_error_correcter'. Убедись в том, что:
- 'prithivida / grammar_error_correcter' - правильный идентификатор модели, указанный на 'https: // huggingface.co / models '
- или 'prithivida / grammar_error_correcter' - это правильный путь к каталогу, содержащему файл config.json
! [Скриншот от 2021-07-01 18-36-07] (https://user-images.githubusercontent.com/4704211/124133526-5a9da900-da9b-11eb-9733-61df46ab01e1. png)
png)
Возможное решение:
Переименуйте эту ссылку из: https://huggingface.co/prithivida/grammar_error_correcter/ в: https://huggingface.co/prithivida/grammar_error_correcter_v1/
Пожалуйста, помогите мне это исправить.спасибо
Синтетический набор данных C4_200M для исправления грамматических ошибок
Авторы: Феликс Штальберг и Шанкар Кумар, ученые-исследователи, Google Research Исправление грамматических ошибок (GEC) пытается моделировать грамматические и другие типы ошибок письма, чтобы предоставить грамматические и орфографические предложения, улучшая качество письменного вывода в документах, электронных письмах, сообщениях в блогах и даже неформальных чатах. За последние 15 лет произошло существенное улучшение качества GEC, что в значительной степени может быть связано с преобразованием проблемы в задачу «перевода».Например, когда этот подход был введен в Google Docs, он привел к значительному увеличению количества принятых предложений по исправлению грамматики.
Однако одна из самых больших проблем для моделей GEC – это разреженность данных. В отличие от других задач обработки естественного языка (NLP), таких как распознавание речи и машинный перевод, для GEC доступны очень ограниченные обучающие данные, даже для таких языков с высокими ресурсами, как английский. Распространенным средством от этого является создание синтетических данных с использованием ряда методов, от случайных искажений на уровне слов или символов на основе эвристики до подходов на основе моделей.Однако такие методы имеют тенденцию быть упрощенными и не отражают истинное распределение типов ошибок от реальных пользователей.
В статье «Генерация синтетических данных для исправления грамматических ошибок с использованием тегированных моделей коррупции», представленной на 16-м семинаре EACL по инновационному использованию НЛП для создания образовательных приложений, мы представляем маркированных моделей коррупции . Вдохновленный популярной техникой синтеза данных с обратным переводом для машинного перевода, этот подход позволяет точно контролировать генерацию синтетических данных, обеспечивая получение разнообразных выходных данных, которые в большей степени соответствуют распределению ошибок, наблюдаемых на практике. Мы использовали модели коррупции с тегами, чтобы создать новый набор данных из 200 миллионов предложений, который мы выпустили, чтобы предоставить исследователям реалистичные данные до обучения для GEC. Интегрировав этот новый набор данных в нашу программу обучения, мы смогли значительно улучшить базовые показатели GEC.
Мы использовали модели коррупции с тегами, чтобы создать новый набор данных из 200 миллионов предложений, который мы выпустили, чтобы предоставить исследователям реалистичные данные до обучения для GEC. Интегрировав этот новый набор данных в нашу программу обучения, мы смогли значительно улучшить базовые показатели GEC.
Tagged Corruption Models
Идея применения традиционной модели коррупции к GEC состоит в том, чтобы начать с грамматически правильного предложения, а затем «испортить» его, добавив ошибки.Модель искажения можно легко обучить, переключив исходное и целевое предложения в существующих наборах данных GEC. Предыдущие исследования показали, что этот метод может быть очень эффективным для создания улучшенных наборов данных GEC.
Обычная модель искажения генерирует нетрадиционное предложение (красный цвет) на основе чистого входного предложения (зеленый цвет). |
Модель помеченного повреждения, которую мы предлагаем, основывается на этой идее, принимая чистое предложение в качестве входных данных вместе с тегом типа ошибки, который описывает тип ошибки, которую нужно воспроизвести.Затем он генерирует неграмматическую версию входного предложения, содержащего данный тип ошибки. Выбор разных типов ошибок для разных предложений увеличивает разнообразие искажений по сравнению с традиционной моделью искажения.
| Помеченные модели повреждения генерируют искажения (красный) для чистого входного предложения (зеленый) в зависимости от тега типа ошибки. Ошибка определителя может привести к отбрасыванию «а», тогда как ошибка склонения существительного может привести к неправильному множественному числу «овцы». |
Чтобы использовать эту модель для генерации данных, мы сначала случайным образом выбрали 200 миллионов чистых предложений из корпуса C4 и присвоили каждому предложению тег типа ошибки, чтобы их относительная частота соответствовала распределению тегов типа ошибки небольшого набора разработчиков BEA-dev. Поскольку BEA-dev – это тщательно подобранный набор, охватывающий широкий спектр различных уровней владения английским языком, мы ожидаем, что его распределение тегов будет репрезентативным для ошибок записи, встречающихся в дикой природе.Затем мы использовали модель помеченного искажения, чтобы синтезировать исходное предложение.
Поскольку BEA-dev – это тщательно подобранный набор, охватывающий широкий спектр различных уровней владения английским языком, мы ожидаем, что его распределение тегов будет репрезентативным для ошибок записи, встречающихся в дикой природе.Затем мы использовали модель помеченного искажения, чтобы синтезировать исходное предложение.
| Генерация синтетических данных с помеченными моделями повреждения. Чистые предложения C4 (зеленые) соединены с искаженными предложениями (красные) в синтетическом корпусе обучения GEC. Поврежденные предложения генерируются с использованием помеченной модели коррупции, следуя частотам типов ошибок в наборе для разработки (гистограмма). |
Результаты
В наших экспериментах модели помеченного повреждения превосходили немаркированные модели коррупции на двух стандартных наборах разработки (CoNLL-13 и BEA-dev) более чем на три F0. 5 баллов (стандартная метрика в исследовании GEC, сочетающая в себе точность и отзывчивость с большим весом в точности), продвигая передовые достижения по двум широко используемым академическим наборам тестов, CoNLL-14 и BEA-test.
5 баллов (стандартная метрика в исследовании GEC, сочетающая в себе точность и отзывчивость с большим весом в точности), продвигая передовые достижения по двум широко используемым академическим наборам тестов, CoNLL-14 и BEA-test.
Кроме того, использование помеченных моделей коррупции не только дает преимущества по сравнению со стандартными наборами тестов GEC, но и позволяет адаптировать системы GEC к уровням квалификации пользователей. Это может быть полезно, например, потому что распределение тегов ошибок для авторов-носителей английского языка часто значительно отличается от распределения для тех, для кого английский не является родным.Например, носители языка склонны делать больше пунктуационных и орфографических ошибок, тогда как ошибки определителей (например, отсутствующие или лишние статьи, такие как «а», «ан» или «the») чаще встречаются в тексте от авторов, не являющихся носителями языка.
Заключение
Модели нейронных последовательностей, как известно, требовательны к данным, но аннотированные обучающие данные для исправления грамматических ошибок встречаются редко.