
Как скопировать текст с картинки или фотографии. Как перевести текст на картинке или фото? смотреть онлайн видео от R13 в хорошем качестве.
12+
11 месяцев назад
R13675 подписчиков
Это фишка меня постоянно выручает, пользуюсь ей каждый день и Вам советую 😊
Копируем текст с картинки, перевод текст со скриншота без сторонних приложений.
🔗Скачать Объектив с Play Market https://play.google.com/store/apps/details?id=com.google.ar.lens&hl=ru&gl=US
🔗Все фишки Объектива https://youtu.be/c0-KsU5bmt0
=================================
Сотрудничество (cooperation): [email protected]
=================================
Телеграм канал и группа ВК со скидками, промокодами и купонами, короче со всем, что поможет купить намного дешевле
📌Ссылочка на телеграм канал Скидоша 😂 https://t.me/skidka_13
📌Ссылочка на группу в ВК Скидоша https://vk.com/skidosha
Мои Телеграм и YouTube канал с лучшими премиальными темами MIUI, наборами шрифтов, виджетов, и прочими ресурсами кастомизации. https://t.me/tema_MIUI
https://www.youtube.com/channel/UCBw4UGzC0JbKEuNw0RCWh3A
================================
✅ Как удалить системные и предустановленные приложения на ЛЮБОМ ТЕЛЕФОНЕ: ✅ Удали приложение паразит из телефона: ✅ Главные шпионы в телефоне. Удали их: ✅ 6 главных мест где скапливается хлам в телефоне: ✅ Перевод без комиссии с любого банка в любой, включая QIWI
https://youtu.be/-DDf5Ow5w7c
✅ Именно поэтому тебе не хватает памяти. Что хранит ДРУГОЕ? ✅ Как удалить системные и предустановленные приложения ✅ Как вернуть деньги за ПОКУПКУ в GOOGLE PLAY MARKET.
https://youtu.be/xBXf14C10Lc
✅ Как перевести деньги со сбербанка в другой банк без комиссии: ✅Как восстановить удаленную переписку в контакте со смартфона: ✅Как освободить память на телефоне Андроид, без РУТ:
https://youtu.
https://t.me/tema_MIUI
https://www.youtube.com/channel/UCBw4UGzC0JbKEuNw0RCWh3A
================================
✅ Как удалить системные и предустановленные приложения на ЛЮБОМ ТЕЛЕФОНЕ: ✅ Удали приложение паразит из телефона: ✅ Главные шпионы в телефоне. Удали их: ✅ 6 главных мест где скапливается хлам в телефоне: ✅ Перевод без комиссии с любого банка в любой, включая QIWI
https://youtu.be/-DDf5Ow5w7c
✅ Именно поэтому тебе не хватает памяти. Что хранит ДРУГОЕ? ✅ Как удалить системные и предустановленные приложения ✅ Как вернуть деньги за ПОКУПКУ в GOOGLE PLAY MARKET.
https://youtu.be/xBXf14C10Lc
✅ Как перевести деньги со сбербанка в другой банк без комиссии: ✅Как восстановить удаленную переписку в контакте со смартфона: ✅Как освободить память на телефоне Андроид, без РУТ:
https://youtu.
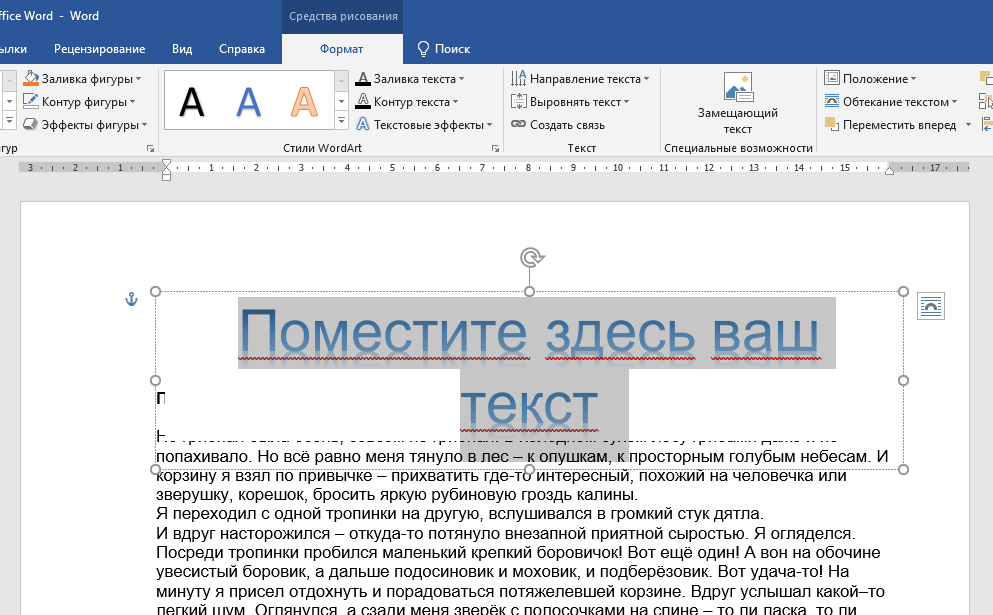
python – С помощью чего можно получить текст с этой картинки?
нужно получить текст с обработанного изображения с помощью любых библиотек(кроме нейросетей). На вход подавалась данная картинка , код обработки:
import cv2
from PIL import Image
import pytesseract
pytesseract.pytesseract.tesseract_cmd = r'C:\Tesseract-OCR\tesseract.exe'
im = Image.open("7TXB6Q.png")
im = im.convert("P")
im2 = Image.new("P",im.size,255)
im = im.convert("P")
temp = {}
for x in range(im. size[1]):
for y in range(im.size[0]):
pix = im.getpixel((y,x))
temp[pix] = pix
if pix > 2: # these are the numbers to get
im2.putpixel((y,x),0)
im2.save("output.png")
im = cv2.imread("output.png")
im = im[0:90, 35:150]
cv2.imwrite("output.png",im)
gray = cv2.cvtColor(im, cv2.COLOR_BGR2GRAY)
cv2.imshow("gray",gray)
cv2.waitKey()
size[1]):
for y in range(im.size[0]):
pix = im.getpixel((y,x))
temp[pix] = pix
if pix > 2: # these are the numbers to get
im2.putpixel((y,x),0)
im2.save("output.png")
im = cv2.imread("output.png")
im = im[0:90, 35:150]
cv2.imwrite("output.png",im)
gray = cv2.cvtColor(im, cv2.COLOR_BGR2GRAY)
cv2.imshow("gray",gray)
cv2.waitKey()
 size[1]):
for y in range(im.size[0]):
pix = im.getpixel((y,x))
temp[pix] = pix
if pix > 2: # these are the numbers to get
im2.putpixel((y,x),0)
im2.save("output.png")
im = cv2.imread("output.png")
im = im[0:90, 35:150]
cv2.imwrite("output.png",im)
gray = cv2.cvtColor(im, cv2.COLOR_BGR2GRAY)
cv2.imshow("gray",gray)
cv2.waitKey()
size[1]):
for y in range(im.size[0]):
pix = im.getpixel((y,x))
temp[pix] = pix
if pix > 2: # these are the numbers to get
im2.putpixel((y,x),0)
im2.save("output.png")
im = cv2.imread("output.png")
im = im[0:90, 35:150]
cv2.imwrite("output.png",im)
gray = cv2.cvtColor(im, cv2.COLOR_BGR2GRAY)
cv2.imshow("gray",gray)
cv2.waitKey()
После обработки картинка выглядит так: . Пробовал получить текст с помощью метода image_to_string
data = pytesseract.image_to_string(im, lang='eng', config='--psm 6 --oem 3 -c tessedit_char_whitelist= ABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789') print(data)
Но он выдаёт на выходе строку , FERRE Хотелось бы узнать возможно есть более качественные методы получения текста, или возможно, наболее подходящие для обработки изображений данного типа различные алгоритмы, любая ваша корректировка или совет будут очень ценны для меня, т.к я новичок в данной области
- python
- opencv
- текст
- pil
- tesseract
5
- По возможности хорошо бы увеличить разрешение картинки, текст на которой Вы хотите распознать, тут нужно будет долго провозиться для подбора оптимального увеличения. Я использовал метод resize у CV2, помимо смены разрешения, у него есть такой атрибут “interpolation”, вроде бы правильно написал, так вот хорошим методом при увеличении разрешения является cv2.INTER_CUBIC. Пробовал cv.INTER_LINEAR, но с ним похуже, но с другой стороны пишут, что он быстрее работает.
- Убрать шумы с помощью CV2. Зайдите на оф. сайт CV2 и найдите там уроки по работе, долистайте до раздела работы с картинками, там будет очень много информации по удалении шумов, попробуйте все методы.
- Вы применяете какое-то странное преобразование в черно-белый цвет, у Вас после преобразования BGR-GRAY остается множество различных оттенков. Попробуйте другие методы преобразования. BINARY-метод оставляет только 2 цвета, без оттенков.
 Я использовал метод resize у CV2, помимо смены разрешения, у него есть такой атрибут “interpolation”, вроде бы правильно написал, так вот хорошим методом при увеличении разрешения является cv2.INTER_CUBIC. Пробовал cv.INTER_LINEAR, но с ним похуже, но с другой стороны пишут, что он быстрее работает.
Я использовал метод resize у CV2, помимо смены разрешения, у него есть такой атрибут “interpolation”, вроде бы правильно написал, так вот хорошим методом при увеличении разрешения является cv2.INTER_CUBIC. Пробовал cv.INTER_LINEAR, но с ним похуже, но с другой стороны пишут, что он быстрее работает.Зарегистрируйтесь или войдите
Регистрация через Google
Регистрация через Facebook
Регистрация через почту
Отправить без регистрации
Почта
Необходима, но никому не показывается
Отправить без регистрации
Почта
Необходима, но никому не показывается
Нажимая на кнопку «Отправить ответ», вы соглашаетесь с нашими пользовательским соглашением, политикой конфиденциальности и политикой о куки
DALL·E: Создание изображений из текста
Прочитать код paperView DALL·E — это версия GPT-3 с 12 миллиардами параметров, обученная генерировать изображения из текстовых описаний с использованием набора данных пар текст-изображение. Мы обнаружили, что он обладает разнообразным набором возможностей, включая создание антропоморфных версий животных и объектов, правдоподобное объединение несвязанных концепций, рендеринг текста и применение преобразований к существующим изображениям.
Мы обнаружили, что он обладает разнообразным набором возможностей, включая создание антропоморфных версий животных и объектов, правдоподобное объединение несвязанных концепций, рендеринг текста и применение преобразований к существующим изображениям.
См. также: DALL·E 2, который создает более реалистичные и точные изображения с 4-кратным увеличением разрешения.
Текстовая подсказка
иллюстрация редиски дайкон в балетной пачке, выгуливающей собаку . . . .
изображений, сгенерированных искусственным интеллектом
Изменить подсказку или просмотреть больше изображений
Текстовая подсказка
витрина магазина, на которой написано слово «openai». . . .
изображений, созданных искусственным интеллектом
Подсказка редактирования или просмотр дополнительных изображений
Текст и изображение
подсказка
точно такая же кошка вверху, как и набросок внизу
Сгенерировано искусственным интеллектом
изображений
Подсказка редактирования или просмотр дополнительных изображений
GPT-0002 3 показано, что язык можно использовать для указания большой нейронной сети выполнять различные задачи по генерации текста.
 Image GPT показал, что тот же тип нейронной сети можно использовать для создания изображений с высокой точностью. Мы расширили эти результаты, чтобы показать, что манипулирование визуальными понятиями с помощью языка теперь доступно.
Image GPT показал, что тот же тип нейронной сети можно использовать для создания изображений с высокой точностью. Мы расширили эти результаты, чтобы показать, что манипулирование визуальными понятиями с помощью языка теперь доступно.Обзор
Как и GPT-3, DALL·E представляет собой языковую модель преобразователя. Он получает и текст, и изображение как единый поток данных, содержащий до 1280 токенов, и обучается с использованием максимальной вероятности для генерации всех токенов один за другим. [1] Эта обучающая процедура позволяет DALL·E не только генерировать изображение с нуля, но и регенерировать любую прямоугольную область существующего изображения, простирающуюся до нижнего правого угла, таким образом, чтобы это соответствовало тексту. быстрый.
Мы понимаем, что работа с генеративными моделями может иметь значительные, широкие социальные последствия. В будущем мы планируем проанализировать, как такие модели, как DALL·E, связаны с социальными проблемами, такими как экономическое влияние на определенные рабочие процессы и профессии, потенциальная систематическая ошибка в результатах модели и долгосрочные этические проблемы, связанные с этой технологией.
Возможности
Мы обнаружили, что DALL·E может создавать правдоподобные образы для самых разных предложений, исследующих композиционную структуру языка. Мы проиллюстрируем это с помощью серии интерактивных изображений в следующем разделе. Образцы, показанные для каждой подписи в визуальных элементах, получены путем выбора 32 лучших из 512 после повторного ранжирования с помощью CLIP, но мы не используем никакого ручного выбора, кроме миниатюр и отдельных изображений, которые появляются снаружи. [2]
Управление атрибутами
Мы проверяем способность DALL·E изменять несколько атрибутов объекта, а также количество его появления.
Нажмите, чтобы отредактировать текстовую подсказку или просмотреть больше изображений, созданных искусственным интеллектом
зеленые пятиугольные часы. зеленые часы в форме пятиугольника.
navigationdownwide
navigationupwide
Текстовое приглашение
Созданные AI
изображения
Мы обнаружили, что DALL·E может отображать знакомые объекты в многоугольных формах, которые иногда вряд ли встречаются в реальном мире.
Мы обнаружили, что для некоторых изображений в этом посте повтор подписи, иногда с альтернативными формулировками, улучшает согласованность результатов.
navigationupwide
куб из дикобраза. куб с текстурой дикобраза.
navigationdownwide
navigationupwide
Текстовая подсказка
изображений, сгенерированных искусственным интеллектом
Мы обнаружили, что DALL·E может отображать текстуры различных растений, животных и других объектов на трехмерных телах. Как и в предыдущем изображении, мы обнаружили, что повторение подписи с альтернативной формулировкой улучшает согласованность результатов.
navigationupwide
коллекция очков лежит на столе
navigationdownwide
navigationupwide
Текстовая подсказка
Созданные ИИ
изображений сделать это, но не может надежно сосчитать до трех.
navigationupwide
Рисование нескольких объектов
Одновременное управление несколькими объектами, их атрибутами и их пространственными отношениями представляет собой новую задачу. Например, рассмотрим фразу «ежик в красной шапке, желтых перчатках, синей рубашке и зеленых штанах». Чтобы правильно интерпретировать это предложение, DALL·E должен не только правильно скомпоновать каждый предмет одежды с животным, но и сформировать ассоциации (шапка, красный), (перчатки, желтый), (рубашка, синий) и (штаны, зеленый). ), не смешивая их. [3] Мы проверяем способность DALL·E делать это для относительного позиционирования, укладки объектов и управления несколькими атрибутами.
маленький красный блок, расположенный на большом зеленом блоке
navigationdownwide
navigationupwide
Текстовое приглашение
изображений, сгенерированных ИИ
Мы обнаружили, что DALL·E правильно реагирует на некоторые типы относительных положений, но не на другие. Варианты «сидеть на» и «стоять впереди» иногда работают, а «сидеть внизу», «стоять позади», «стоять слева» и «стоять справа» — нет. DALL·E также имеет более низкий уровень успеха, когда его просят нарисовать большой объект, расположенный поверх меньшего, по сравнению с наоборот.
Варианты «сидеть на» и «стоять впереди» иногда работают, а «сидеть внизу», «стоять позади», «стоять слева» и «стоять справа» — нет. DALL·E также имеет более низкий уровень успеха, когда его просят нарисовать большой объект, расположенный поверх меньшего, по сравнению с наоборот.
navigationupwide
стек из 3 кубов. красный куб находится сверху, сидя на зеленом кубе. зеленый куб находится посередине, сидя на синем кубе. синий куб находится внизу.
navigationdownwide
navigationupwide
Текстовая подсказка
Созданные ИИ
изображений
Мы обнаружили, что DALL·E обычно создает изображение с одним или двумя объектами, имеющими правильные цвета. Однако только в нескольких образцах для каждой настройки обычно имеется ровно три объекта, окрашенных точно так, как указано.
navigationupwide
эмодзи пингвиненка в синей шапке, красных перчатках, зеленой рубашке и желтых штанах обычно создает изображение с двумя или тремя предметами одежды, имеющими правильные цвета. Однако лишь немногие из образцов для каждого окружения, как правило, имеют все четыре предмета одежды указанных цветов.
Однако лишь немногие из образцов для каждого окружения, как правило, имеют все четыре предмета одежды указанных цветов.
navigationupwide
Хотя DALL·E предлагает некоторый уровень контроля над атрибутами и позициями небольшого числа объектов, вероятность успеха может зависеть от того, как сформулирован заголовок. По мере того, как вводится больше объектов, DALL·E склонен путать ассоциации между объектами и их цветами, и вероятность успеха резко снижается. Мы также отмечаем, что DALL·E хрупок в отношении перефразирования подписи в этих сценариях: альтернативные, семантически эквивалентные подписи часто не дают правильной интерпретации.
Визуализация перспективы и трехмерности
Мы обнаружили, что DALL·E также позволяет управлять точкой обзора сцены и трехмерным стилем, в котором визуализируется сцена.
очень крупный план водосвинки, сидящей в поле
navigationdownwide
navigationupwide
Текстовая подсказка
изображений, сгенерированных искусственным интеллектом разные взгляды. Некоторые из этих видов, такие как «вид сверху» и «вид сзади», требуют знания внешнего вида животного с необычных ракурсов. Другие, такие как «крайний план», требуют знания мелких деталей кожи или меха животного.
Некоторые из этих видов, такие как «вид сверху» и «вид сзади», требуют знания внешнего вида животного с необычных ракурсов. Другие, такие как «крайний план», требуют знания мелких деталей кожи или меха животного.
navigationupwide
капибара из вокселей, сидящая в поле животных в соответствии с выбранным 3D-стилем, таким как «глиняный» и «сделанный из вокселей», и визуализировать сцену с правдоподобным затенением в зависимости от положения солнца. «Рентгеновский» стиль не всегда работает надежно, но он показывает, что DALL·E иногда может ориентировать кости внутри животного в правдоподобных (хотя и не анатомически правильных) конфигурациях.
navigationupwide
Чтобы продвинуться дальше, мы проверяем способность DALL·E многократно рисовать голову известной фигуры под каждым углом из последовательности равноотстоящих углов и обнаруживаем, что можем восстановить плавную анимацию вращения глава.
фотография бюста Гомера
navigationdownwide
navigationupwide
текстовая подсказка
графическая подсказка
сгенерированные AI
изображения область изображения, показывающая шляпу, нарисованную под определенным углом. Затем мы просим DALL·E завершить оставшуюся часть изображения с учетом этой контекстной информации. Мы делаем это неоднократно, каждый раз поворачивая шляпу еще на несколько градусов, и обнаруживаем, что можем восстановить плавную анимацию нескольких хорошо известных фигур, при этом каждый кадр соответствует точным спецификациям угла и окружающего освещения.
Затем мы просим DALL·E завершить оставшуюся часть изображения с учетом этой контекстной информации. Мы делаем это неоднократно, каждый раз поворачивая шляпу еще на несколько градусов, и обнаруживаем, что можем восстановить плавную анимацию нескольких хорошо известных фигур, при этом каждый кадр соответствует точным спецификациям угла и окружающего освещения.
navigationupwide
DALL·E может применять некоторые типы оптических искажений к сценам, как мы видим с опциями «вид объектива «рыбий глаз»» и «сферическая панорама». Это побудило нас исследовать его способность генерировать отражения.
простой белый куб, смотрящий на свое отражение в зеркале. простой белый куб, смотрящий на себя в зеркало.
navigationdownwide
navigationupwide
Текстовое приглашение
Графическое приглашение
изображений, созданных искусственным интеллектом
Подобно тому, что было сделано ранее, мы предлагаем DALL·E заполнить нижние правые углы последовательности кадров, каждый из которых содержит зеркало и отражающий пол. Хотя отражение в зеркале обычно напоминает объект за его пределами, оно часто не передает отражение физически правильным образом. Напротив, отражение объекта, нарисованного на отражающем полу, обычно более правдоподобно.
Хотя отражение в зеркале обычно напоминает объект за его пределами, оно часто не передает отражение физически правильным образом. Напротив, отражение объекта, нарисованного на отражающем полу, обычно более правдоподобно.
navigationupwide
Визуализация внутренней и внешней структуры
Образцы в стиле «крайний крупный план» и «рентген» позволили нам дополнительно изучить способность DALL·E отображать внутреннюю структуру с помощью поперечных сечений и внешнюю структуру с помощью макрофотографий.
вид грецкого ореха в разрезе
navigationdownwide
navigationupwide
Текстовая подсказка
изображений, созданных искусственным интеллектом
Мы обнаружили, что DALL·E может рисовать внутренности нескольких различных типов объектов.
navigationupwide
макрофотография мозгового коралла
navigationdownwide
navigationupwide
текстовая подсказка
сгенерированные искусственным интеллектом
изображений объекты. Эти детали видны только при близком рассмотрении объекта.
Эти детали видны только при близком рассмотрении объекта.
navigationupwide
Определение контекстных деталей
Задача преобразования текста в изображения недостаточно конкретизирована: одна подпись обычно соответствует бесконечному количеству правдоподобных изображений, поэтому изображение не определяется однозначно. Например, рассмотрим подпись «картина с изображением капибары, сидящей в поле на восходе солнца». В зависимости от ориентации водосвинки может возникнуть необходимость нарисовать тень, хотя эта деталь никогда не упоминается явно. Мы изучаем способность DALL·E устранять недочеты в трех случаях: изменение стиля, обстановки и времени; рисование одного и того же объекта в различных ситуациях; и создание изображения объекта с написанным на нем определенным текстом.
рисунок водосвинки, сидящей в поле на восходе солнца
navigationdownwide
navigationupwide
Текстовая подсказка
изображений, созданных искусственным интеллектом стилей и может адаптировать освещение, тени и окружающую среду в зависимости от времени суток или времени года.
navigationupwide
витраж с изображением синей клубники
navigationdownwide
navigationupwide
Текстовое приглашение
Созданные ИИ
изображений
Мы обнаружили, что DALL·E может гибко адаптировать представление объекта в зависимости от среды, на которой он рисуется. Для «фрески», «банки содовой» и «чашки» DALL·E должен изменить способ рисования объекта в зависимости от угла и кривизны поверхности рисования. Для «витража» и «неоновой вывески» он должен изменить внешний вид объекта по сравнению с тем, каким он обычно выглядит.
navigationupwide
витрина магазина, на которой написано слово «openai». фасад магазина, на котором написано слово «openai». фасад магазина, на котором написано слово «openai». Фасад магазина «Опенай».
navigationdownwide
navigationupwide
Текстовое приглашение
Созданные AI
изображения
Мы обнаружили, что DALL·E иногда может отображать текст и адаптировать стиль письма к контексту, в котором он появляется. Например, «пакет чипсов» и «номерной знак» требуют разных типов шрифтов, а «неоновая вывеска» и «надпись в небе» требуют изменения внешнего вида букв.
Например, «пакет чипсов» и «номерной знак» требуют разных типов шрифтов, а «неоновая вывеска» и «надпись в небе» требуют изменения внешнего вида букв.
Как правило, чем длиннее строка, которую DALL·E предлагается записать, тем ниже вероятность успеха. Мы обнаружили, что вероятность успеха повышается, когда части подписи повторяются. Кроме того, вероятность успеха иногда повышается по мере снижения температуры выборки изображения, хотя образцы становятся проще и менее реалистичными.
navigationupwide
С различной степенью надежности DALL·E обеспечивает доступ к подмножеству возможностей механизма 3D-рендеринга с помощью естественного языка. Он может независимо контролировать атрибуты небольшого числа объектов и в ограниченной степени, сколько их и как они расположены по отношению друг к другу. Он также может управлять положением и углом, с которого визуализируется сцена, и может генерировать известные объекты в соответствии с точными спецификациями угла и условий освещения.
В отличие от механизма 3D-рендеринга, чьи входные данные должны быть указаны однозначно и во всех подробностях, DALL·E часто может «заполнить пробелы», когда заголовок подразумевает, что изображение должно содержать определенную деталь, которая явно не указана.
Применение предыдущих возможностей
Далее мы рассмотрим использование предыдущих возможностей для моды и дизайна интерьера.
Композиционная природа языка позволяет нам объединять концепции для описания как реальных, так и воображаемых вещей. Мы обнаружили, что DALL·E также может комбинировать разрозненные идеи для синтеза объектов, некоторые из которых вряд ли существуют в реальном мире. Мы исследуем эту способность в двух случаях: перенос качеств различных концепций на животных и создание продуктов, черпая вдохновение из несвязанных концепций.
улитка из арфы. улитка с текстурой арфы.
navigationdownwide
navigationupwide
Текстовое приглашение
Созданные AI
изображения
Мы обнаружили, что DALL·E может генерировать животных, синтезированных из различных понятий, включая музыкальные инструменты, продукты питания и предметы домашнего обихода. Хотя это и не всегда удается, мы обнаруживаем, что DALL·E иногда принимает во внимание формы двух объектов, решая, как их объединить. Например, когда ему предлагается нарисовать «улитку, сделанную из арфы», он иногда связывает столб арфы со спиралью раковины улитки.
Хотя это и не всегда удается, мы обнаруживаем, что DALL·E иногда принимает во внимание формы двух объектов, решая, как их объединить. Например, когда ему предлагается нарисовать «улитку, сделанную из арфы», он иногда связывает столб арфы со спиралью раковины улитки.
В предыдущем разделе мы видели, что чем больше объектов вводится в сцену, тем чаще DALL·E путает ассоциации между объектами и их заданными атрибутами. Здесь мы видим иной вид отказа: иногда вместо того, чтобы привязать какой-либо атрибут заданного понятия (скажем, «кран») к животному (скажем, «улитке»), ДАЛЛ·И просто рисует их как отдельные предметы.
navigationupwide
Иллюстрации животных
В предыдущем разделе мы исследовали способность DALL·E комбинировать несвязанные концепции при создании изображений объектов реального мира. Здесь мы исследуем эту способность в контексте искусства для трех видов иллюстраций: антропоморфные версии животных и предметов, химеры животных и смайлики.
иллюстрация редиски дайкон в балетной пачке, выгуливающей собаку
Мы обнаружили, что DALL·E иногда может передавать некоторые виды человеческой деятельности и предметы одежды животным и неодушевленным предметам, таким как продукты питания. Мы включили «пикачу» и «владение синим световым мечом», чтобы изучить способность DALL·E использовать популярные медиа.
Мы включили «пикачу» и «владение синим световым мечом», чтобы изучить способность DALL·E использовать популярные медиа.
Нам интересно, как DALL·E адаптирует части человеческого тела к животным. Например, когда его просят нарисовать редис дайкон, сморкающийся, потягивающий латте или катающийся на одноколесном велосипеде, ДАЛЛ·И часто рисует платок, руки и ноги в правдоподобных местах.
navigationupwide
Профессиональная высококачественная иллюстрация химеры черепахи-жирафа. жираф, имитирующий черепаху. жираф из черепахи.
navigationdownwide
navigationupwide
Текстовое приглашение
Созданные AI
изображения
Мы обнаружили, что DALL·E иногда может комбинировать различных животных правдоподобным образом. Мы включаем «пикачу», чтобы исследовать способность DALL·E использовать знания популярных медиа, и «робот», чтобы исследовать его способность создавать животных-киборгов. Как правило, черты второго животного, упомянутого в подписи, имеют тенденцию быть доминирующими.
Мы также обнаружили, что вставка фразы «профессиональное высокое качество» перед словами «иллюстрация» и «эмодзи» иногда улучшает качество и согласованность результатов.
navigationupwide
профессиональные высококачественные смайлики влюбленной чашки боба
navigationdownwide
navigationupwide
Текстовая подсказка
Созданные AI
изображений
и неодушевленные предметы, такие как продукты питания. Как и в предыдущем изображении, мы обнаружили, что вставка фразы «профессиональное высокое качество» перед «эмодзи» иногда улучшает качество и согласованность результатов.
navigationupwide
Zero-Shot Visual Reasoning
GPT-3 может быть проинструктирован выполнять многие виды задач исключительно на основе описания и подсказки для получения ответа, предоставленного в его подсказке, без какого-либо дополнительного обучения. Например, на запрос фразы «вот предложение «человек, выгуливающий свою собаку в парке», переведенное на французский язык:», GPT-3 отвечает: «un homme qui promène son chien dans le parc». Эта способность называется рассуждениями с нулевым выстрелом. Мы обнаружили, что DALL·E расширяет эту возможность до визуальной области и может выполнять несколько видов задач преобразования изображения в изображение при правильном запросе.
Эта способность называется рассуждениями с нулевым выстрелом. Мы обнаружили, что DALL·E расширяет эту возможность до визуальной области и может выполнять несколько видов задач преобразования изображения в изображение при правильном запросе.
точно такой же кот вверху, как набросок внизу
navigationdownwide
navigationupwide
Текстовое приглашение
Графическое приглашение
Сгенерированные ИИ
изображений
Мы обнаружили, что DALL·E может применять несколько видов преобразования изображений к фотографиям животных с разной степенью надежности. Самые простые из них, такие как «фотография, окрашенная в розовый цвет» и «фотография, отраженная вверх ногами», также, как правило, являются наиболее надежными, хотя фотография часто не копируется или не отражается точно. Преобразование «животное в очень крупном плане» требует, чтобы DALL·E распознал породу животного на фотографии и воспроизвел ее с соответствующими деталями. Это работает менее надежно, и для некоторых фотографий DALL·E генерирует правдоподобные завершения только в одном или двух случаях.
Это работает менее надежно, и для некоторых фотографий DALL·E генерирует правдоподобные завершения только в одном или двух случаях.
Другие трансформации, такие как «животное в солнечных очках» и «животное в галстуке-бабочке», требуют размещения аксессуара на нужной части тела животного. Те, которые изменяют только цвет животного, такие как «животное окрашено в розовый цвет», менее надежны, но показывают, что DALL·E иногда способен отделить животное от фона. Наконец, трансформации «набросок животного» и «чехол для мобильного телефона с животным» исследуют использование этой возможности для иллюстраций и дизайна продукта.
navigationupwide
точно такой же чайник сверху с надписью «gpt» снизу E может применять несколько различных видов преобразования изображений к фотографиям чайников с разной степенью надежности. Помимо возможности изменять цвет чайника (например, «синий цвет») или его рисунок (например, «с полосами»), DALL·E также может отображать текст (например, «с надписью «gpt» на нем» ) и расположите буквы на изогнутой поверхности чайника правдоподобным образом. С гораздо меньшей надежностью может вытянуть и чайник меньшего размера (для варианта «малюсенький») и в разбитом состоянии (для варианта «разбитый»).
С гораздо меньшей надежностью может вытянуть и чайник меньшего размера (для варианта «малюсенький») и в разбитом состоянии (для варианта «разбитый»).
navigationupwide
Мы не ожидали, что эта возможность появится, и не вносили никаких изменений в нейронную сеть или процедуру обучения, чтобы поощрять ее. Вдохновленные этими результатами, мы измеряем способность ДАЛЛ-И решать задачи на рассуждения по аналогии, проверяя ее на прогрессивных матрицах Равена — визуальном тесте IQ, который широко использовался в 20-м веке.
последовательность геометрических фигур.
navigationdownwide
navigationupwide
Текстовое приглашение
Пример подсказки изображения
изображений, созданных искусственным интеллектом
Вместо того, чтобы рассматривать IQ-тест как задачу с множественным выбором, как предполагалось изначально, мы просим DALL·E заполнить нижний правый угол каждого изображения, используя выборку argmax, и считаем его завершение правильным, если оно близко визуально соответствует заданному. оригинал.
оригинал.
DALL·E часто может решать матрицы, которые включают в себя продолжающиеся простые шаблоны или базовые геометрические рассуждения, например, в наборах B и C. Иногда он может решать матрицы, которые включают в себя распознавание перестановок и применение логических операций, таких как те, что в наборах B и C. набор D. Экземпляры в наборе E, как правило, самые сложные, и DALL·E почти ни один из них не дает правильного ответа.
Для каждого из наборов мы измеряем производительность DALL·E как на исходных изображениях, так и на изображениях с инвертированными цветами. Инверсия цветов не должна создавать дополнительных трудностей для человека, но в целом ухудшает работу DALL·E, предполагая, что его возможности могут быть непредсказуемыми.
navigationupwide
Географические знания
Мы обнаружили, что DALL·E узнал о географических фактах, достопримечательностях и окрестностях. Его знание этих понятий удивительно точно в одних отношениях и ошибочно в других.
фото китайской кухни
navigationdownwide
navigationupwide
Текстовое приглашение
изображений, сгенерированных искусственным интеллектом Хотя DALL·E успешно отвечает на многие из этих вопросов, например, о национальных флагах, он часто отражает поверхностные стереотипы в отношении таких вариантов выбора, как «еда» и «дикая природа», в отличие от представления всего разнообразия, встречающегося в реальном мире.
navigationupwide
фотография площади Аламо, Сан-Франциско, с улицы ночью некоторых мест в Сан-Франциско. Для мест, знакомых авторам, таких как Сан-Франциско, они вызывают чувство дежа вю — жуткие симулякры улиц, тротуаров и кафе, которые напоминают нам об очень конкретных местах, которых не существует.
navigationupwide
фотография моста “Золотые ворота” в Сан-Франциско
navigationdownwide
navigationupwide
Текстовая подсказка
Подсказки к изображениям На самом деле, мы даже можем указать, когда была сделана фотография, указав первые несколько рядов неба. Например, когда небо темное, DALL·E распознает ночь и включает свет в зданиях.
Например, когда небо темное, DALL·E распознает ночь и включает свет в зданиях.
navigationupwide
Знания о времени
В дополнение к изучению знаний DALL·E о концепциях, которые меняются в пространстве, мы также изучаем его знания о концепциях, которые меняются во времени.
фотография телефона 20-х годов
navigationdownwide
navigationupwide
Текстовая подсказка
Подсказки с изображениями
Созданные искусственным интеллектом
изображений десятилетия. Технологические артефакты, по-видимому, проходят через периоды взрывного изменения, резко меняясь в течение десятилетия или двух, а затем меняясь постепенно, совершенствуясь и совершенствуясь.
navigationupwide
Резюме подхода и предыдущей работы
DALL·E — это простой преобразователь только для декодера, который получает и текст, и изображение как единый поток из 1280 токенов — 256 для текста и 1024 для изображения — и моделирует все из них авторегрессивно. Маска внимания на каждом из 64 слоев внутреннего внимания позволяет каждому маркеру изображения уделять внимание всем текстовым маркерам. DALL·E использует стандартную причинно-следственную маску для текстовых токенов и разреженное внимание для токенов изображения со строкой, столбцом или сверточным шаблоном внимания, в зависимости от слоя. Мы предоставляем более подробную информацию об архитектуре и процедуре обучения в нашей статье.
Маска внимания на каждом из 64 слоев внутреннего внимания позволяет каждому маркеру изображения уделять внимание всем текстовым маркерам. DALL·E использует стандартную причинно-следственную маску для текстовых токенов и разреженное внимание для токенов изображения со строкой, столбцом или сверточным шаблоном внимания, в зависимости от слоя. Мы предоставляем более подробную информацию об архитектуре и процедуре обучения в нашей статье.
Синтез текста в изображение был активной областью исследований со времен новаторской работы Reed et. al, чей подход использует GAN, основанный на встраивании текста. Вложения создаются кодировщиком, предварительно обученным с использованием контрастных потерь, мало чем отличающихся от CLIP. StackGAN и StackGAN++ используют многомасштабные GAN для увеличения разрешения изображения и улучшения визуальной точности. AttnGAN объединяет внимание между текстовыми и графическими функциями и предлагает контрастную характеристику текста и изображения, соответствующую потере, в качестве вспомогательной цели. Это интересно сравнить с нашей переоценкой с помощью CLIP, которая выполняется в автономном режиме. Другая работа включает в себя дополнительные источники наблюдения во время обучения для улучшения качества изображения. Наконец, работа Nguyen et. аль и Чо и др. al исследует основанные на выборке стратегии для генерации изображений, в которых используются предварительно обученные мультимодальные дискриминационные модели.
Это интересно сравнить с нашей переоценкой с помощью CLIP, которая выполняется в автономном режиме. Другая работа включает в себя дополнительные источники наблюдения во время обучения для улучшения качества изображения. Наконец, работа Nguyen et. аль и Чо и др. al исследует основанные на выборке стратегии для генерации изображений, в которых используются предварительно обученные мультимодальные дискриминационные модели.
Подобно выборке отклонения, используемой в VQVAE-2, мы используем CLIP для переранжирования 32 лучших выборок из 512 для каждой подписи во всех интерактивных визуальных элементах. Эту процедуру также можно рассматривать как своего рода языковой поиск, и она может оказать существенное влияние на качество выборки.
иллюстрация редиски дайкон в балетной пачке, выгуливающей собаку [заголовок 1, лучшие 8 за 2048 год]0003
Повторное ранжирование выборок из DALL·E с помощью CLIP может значительно улучшить согласованность и качество выборок.
navigationupwide
Как использовать Google Keep OCR и исправить неработающий текст Google Keep Grab Image
Google Keep — это онлайн-программа для создания заметок, во многих аспектах напоминающая Microsoft OneNote. Он доступен в Интернете, на Android и iOS. В то время как Google Keep OCR, аналогичный OneNote OCR, предлагается для извлечения текста из файла изображения, поэтому пользователи могут напрямую создавать или делать заметки из текстов изображений.
В этом посте мы расскажем, как использовать Google Keep OCR для изображений или файлов PDF, а также поделимся с вами исправлениями, когда Google Keep не работает захват текста изображения.
- Как использовать Google Keep OCR для преобразования изображения в текст на Mac/Windows/Android/iOS
- Текст изображения Google Keep Grab не работает? Исправить это
- Основы распознавания текста Google Keep
Как использовать Google Keep OCR для преобразования изображения в текст на Mac/Windows/Android/iOS
Google Keep может работать на мобильных устройствах и персональных компьютерах, шаги по использованию Google Keep OCR на Mac/Windows очень похожи на это на Андроиде/Айфоне.
Как использовать Google Keep OCR для преобразования изображения в текст на Mac/Windows?
Версии для настольных компьютеров Mac или Windows не существует, но вы можете бесплатно пользоваться этой службой онлайн, войдя в свою учетную запись Google.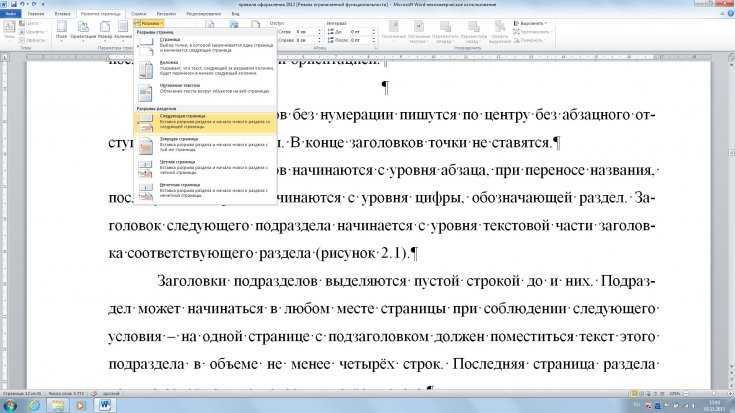
- Войдите в свою учетную запись Google.
- Перейти в Google Keep.
- Нажмите «Новая заметка с изображением», чтобы загрузить один или несколько файлов изображений.
- После загрузки изображений щелкните значок с тремя точками и выберите «Захватить текст изображения», чтобы запустить распознавание символов Google Keep.
- После OCR тексты изображений будут отображаться как примечания, которые можно скопировать и вставить в Google Docs или другой процессор документов.
Как использовать Google Keep OCR для преобразования изображения в текст на Android/iPhone?
Приложение Google Keep доступно в Google Play и Apple AppStore. Пользователи Android и iPhone могут загрузить и установить это приложение на свое мобильное устройство для распознавания текста в Google Keep.
- Загрузите и установите Google Keep OCR на свой Android или iPhone.
- Запустите приложение, коснитесь значка изображения, чтобы сделать снимок или загрузить существующее изображение.
- После импорта изображения в Google Keep коснитесь значка с тремя точками и выберите «Захватить текст изображения».
- Теперь Google Keep OCR распознал текст изображения, при необходимости отредактируйте или скопируйте и вставьте.

Google Keep Grab Image Text не работает? Fix It
1. Google Keep OCR не захватывает текст изображения?
Иногда мы загружаем изображение, но опция Захватить текст изображения остается серой и неактивной, что делать?
Все, что нам нужно сделать, это переделать OCR в Google Keep.
- Сначала закройте файл.
- Затем перейдите к изображению, щелкните значок с тремя точками> возьмите текст изображения, перезапустите Google Keep OCR.
2. Все еще не работает или результат OCR Google Keep неточный? Используйте альтернативы
Google Keep OCR отлично справляется с распознаванием простых и четких файлов изображений, но если ваши изображения имеют сложную компоновку и форматирование или не очень четкие, результаты OCR Google Keep не будут точными. Чтобы получить точные и хорошо отформатированные результаты OCR, вам рекомендуется найти альтернативу Google Keep OCR.
Чтобы получить точные и хорошо отформатированные результаты OCR, вам рекомендуется найти альтернативу Google Keep OCR.
Лучшая альтернатива программе оптического распознавания символов Google Keep для Mac
Cisdem PDF Converter OCR — это программа оптического распознавания текста для Mac, позволяющая распознавать тексты как с изображений, так и из PDF-файлов. Он не может преобразовывать изображения и отсканированные PDF-файлы в тексты, но также экспортирует их в форматы PDF с возможностью поиска, редактируемые Word, Excel, PowerPoint, Keynote, Pages, ePub, HTML, Text и RTFD. Cisdem работает и с исходным PDF, помогая пользователям конвертировать исходный PDF в 16 популярных форматов. Пользователю также разрешено конвертировать несколько файлов одновременно.
Основные характеристики Cisdem PDF Converter OCR
- OCR изображения и PDF
- Экспорт изображений и отсканированных PDF-файлов в файлы PDF с возможностью поиска, Word, Excel, PPT, ePub и т. д.
- Пакет поддержки OCR
- Точное и расширенное распознавание символов
- Преобразование собственного PDF в 16 форматов (Word, PPT, Keynote, Pages, ePub, Image и т. д.)
- Создание PDF из изображения, Word, PowerPoint и т. д.
 д.
д.Как использовать Cisdem PDF Converter OCR?
- Загрузите и установите Cisdem PDF Converter OCR на свой Mac.
Скачать бесплатно - Добавьте изображение или отсканированный файл PDF в программу.
- Измените настройки OCR.
Для изображений функция OCR включена по умолчанию; для PDF-файлов необходимо включить функцию OCR. Выберите язык файла и выберите вывод в соответствии с вашими потребностями. - Щелкните Преобразовать в файлы OCR на Mac.
Лучшая альтернатива программе OCR для Google Keep для Windows
Icecream PDF Converter Pro — это рекомендуемая программа распознавания текста Windows для замены Google Keep OCR. Хотя он поддерживает только OCR PDF, с его функцией создания вы можете сначала сохранить изображения в формате PDF, а затем добавить их для OCR. Это позволяет пользователям Windows конвертировать PDF в Word, изображения, WMF и HTML, а также позволяет пользователям настраивать выходные файлы.
Это позволяет пользователям Windows конвертировать PDF в Word, изображения, WMF и HTML, а также позволяет пользователям настраивать выходные файлы.
Как использовать Icecream PDF Converter Pro?
- Загрузите и установите Icecream PDF Converter Pro на свой ПК с Windows.
- Выберите из интерфейса PDF.
- Добавьте файлы PDF в программу, выберите вывод в формате Word или других поддерживаемых форматах.
- Нажмите кнопку Преобразовать и ИСПОЛЬЗОВАТЬ OCR.
Основы OCR Google Keep
Кроме того, вот несколько основных вещей, которые вы должны знать о OCR Google Keep, чтобы убедиться , что эта служба соответствует вашим требованиям.
Поддержка ввода Google Keep OCR
- GIF
- JPEG
- JPG
- PNG
- ВЕБП
Как видите, Google Keep OCR поддерживает только 5 форматов изображений. Если вам нужно распознавать изображения в других форматах с помощью Google Keep, сначала преобразуйте их в поддерживаемые форматы изображений, а затем загрузите их для захвата текста.
Google Keep OCR Output
- Захват текста и отображение в Google Keep Note
- Копировать в Документы Google
Google Keep OCR не может позволить пользователям экспортировать текст изображения в текстовый или другие форматы, вы можете только извлечь текст из изображения, а затем скопировать и вставить в заметку Google Keep или в Документы Google.
Размер файла и ограничения по пикселям
Google Keep позволяет загружать файлы размером менее 10 МБ и 25 мегапикселей. Перед загрузкой для OCR проверьте, соответствуют ли ваши файлы требованиям, если нет, сожмите или измените их.
Может ли Google Keep OCR преобразовывать рукописный текст в текст?
Да, может распознавать рукописный текст, но результат зависит от того, насколько сложным и четким будет загруженное вами изображение, чем проще и понятнее, тем точнее будет результат.
Как использовать Google Keep OCR PDF?
Google Keep не поддерживает PDF-файлы, для PDF-файлов Google Keep OCR вам придется сохранять PDF-файлы в форматах изображений (GIF/JPEG/JPG/PNG/WEBP).