
Статьи
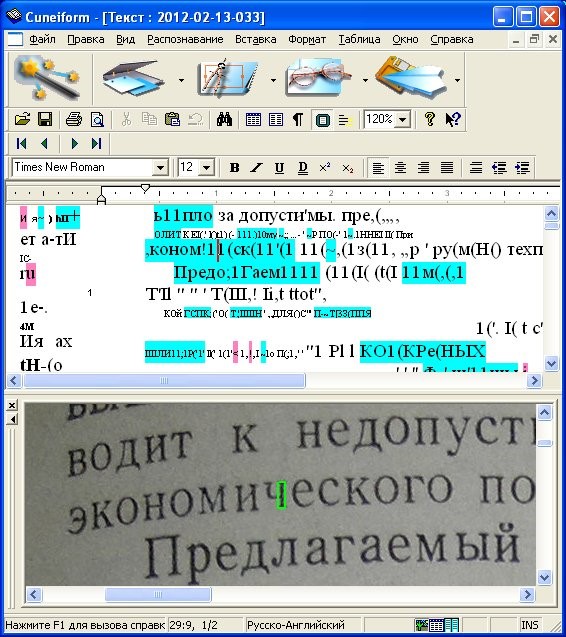
Среди множества услуг, которые мы оказывает своим клиентам, высокой популярностью пользуется услуга распознавания текста. Такое распознавание при необходимости выполняется после сканирования, оно обеспечивает заказчикам преимущества, речь о которых пойдёт далее. Распознавание текста представляет собой процедуру программной обработки графических файлов, получаемых в результате сканирования. Используемые программы работают на основе так называемой технологии OCR (optical character recognition, что в переводе с английского языка означает «оптическое распознавание символов»).
Преимущества распознавания
- быстрый и удобный поиск информации;
- удобство работы и правки;
- сохранность информации.
Поиск информации
Поиск при хранении отсканированных документов в электронном архиве без распознавания может быть осуществлён только по реквизитам (названию документа, его дате, контрагентам и т.
Работа и правка информации
Как и в случае с поиском, в не распознанных документах работа с информацией возможно и ее даже можно править, однако это занимает огромное количество времени и действий. Простейший пример – замена графического другим, уже поправленным, что ведет за собой кучу проблем (распечатать или открыть текстовый файл, внести изменения, отсканировать, и если нужно ввести в базу данных.). Вывод очевиден: проще один раз распознать информацию в документе, чем каждый раз выполнять вышеуказанные действия.
Алгоритмы действия
- анализ файлов;
- сравнение с набором шаблонов;
- стандартизация.

С чего начать
Без определенных знаний и опыта, самому лучше не пытаться делать распознавание документов, иначе это может привести к лишним затратам, а отдачи никакой не будет. Если Вам нужно сделать распознавание документов, лучше всего обратитесь в специализированные организации. Наши сотрудники имеют огромный опыт в работе по распознаванию документов. По всем вопросам, касающимся распознавания документов обращайтесь к нам по телефону +7 (495) 766-23-43, или по почте [email protected]. Наши специалисты с удовольствием ответят Вам.
Распознавание рукописного текста — БИОРГ
На текущий день качественного автоматического распознавания рукописного текста не существует. Для выполнения таких работ необходимо обращаться в компании, которые специализируются на сканировании и обработке (распознавании) документов. Только так можно получить гарантированный желаемый результат.
Сложности распознавания
Существует ряд характерных для преобразования рукописного текста сложностей:
- наличие орфографических ошибок в первоисточнике;
- значительная вариативность написания символов;
- исправления, кляксы, дефекты бумаги;
- специфические особенности написания и т.
 д.
д.
Как улучшить качество
Существует множество способов улучшить преобразование рукописного текста в электронный вид, например, пользоваться структурированными машиночитаемыми формами, такими как бланки или анкеты. Еще одним вариантом является предварительная обработка скана, когда приходится четко выделять интересующие области с текстом, показывая программе, где нужно искать символы. Однако такие способы позволяют лишь увеличить процент правильного распознавания, но никак не дать 100% качество.
Услуги по распознаванию рукописного текста компании Биорг
Компания «Биорг» оказывает услуги по обработке персональных данных. Работая в данной сфере более 18 лет, наша организация успешно реализовала более тысячи проектов. Сегодня мы являемся крупнейшей в России компанией, обрабатывающей свыше 3 миллионов анкет клиентов ежемесячно.
Распознавание рукописного текста опросных листов, бланков, работа с архивными документами при помощи Beorg Processing позволяет верифицировать и оцифровать большие объемы информации с любых бумажных носителей.
Зачастую необходимость преобразования рукописного текста в электронный возникает в организациях, которым требуется обработка значительного количества рукописных документов. Нашими клиентами являются банки, торговые сети, крупнейшие компании российского нефтегазового сектора.
Подробнее о сканировании и обработке анкет
Кроме обработки анкет, ООО «Биорг» предоставляет полный спектр дополнительных услуг:
- доставку документов по всей территории РФ. С этой целью привлекаются курьерские службы, аттестованные подрядчики. Наша компания контролирует сроки доставки, целостность документации, предоставляет финансовые гарантии;
- удаленное сканирование рукописного текста непосредственно на месте сбора документов
- хранение анкет (краткосрочное и долгосрочное) и их утилизация при помощи промышленного шредирования.
 Заказчики могут не беспокоиться о конфиденциальности – специалисты, выполняющие подобные операции, действуют в строгом соответствии с инструкциями, запрещающими передачу информации посторонним лицам;
Заказчики могут не беспокоиться о конфиденциальности – специалисты, выполняющие подобные операции, действуют в строгом соответствии с инструкциями, запрещающими передачу информации посторонним лицам; - архивная обработка документов.
Наша компания ведет деятельность в соответствии с российским законодательством. Клиентам гарантировано оперативное выполнение заказа, конкурентные цены, полная конфиденциальность.
Подробнее об оцифровке архивов
Документ Сервис / Распознавание текста
Приблизительный расчет стоимости
Количество:
Заказать услугу можно быстро и без регистрации
Цена:
Дополнительные услуги
| Тип услуги | Цена |
| Запись на флэшку | 15р |
| Запись на диск CD/DVD (без учета стоимости диска) | 75р |
| Отправка по электронной почте | 75р |
| Цветокоррекция изображения | от 10р |
«Документ-сервис» производит распознавание текста изображений, а так же при необходимости произведет дальнейшую обработку. Благодаря программному распознаванию сканированного текста, предоставляется возможность быстрого преобразования графических файлов в текстовые. Для распознавания текста неважно в каком виде будет предоставлен материал, это могут быть уже отпечатанные документы, либо отсканированные файлы. Полученный результат оператор запишет на диск CD или DVD, либо на флэш-карту, кроме этого возможна отправка на электронную почту.
Благодаря программному распознаванию сканированного текста, предоставляется возможность быстрого преобразования графических файлов в текстовые. Для распознавания текста неважно в каком виде будет предоставлен материал, это могут быть уже отпечатанные документы, либо отсканированные файлы. Полученный результат оператор запишет на диск CD или DVD, либо на флэш-карту, кроме этого возможна отправка на электронную почту.
Копирование и распознавание документов в Туле
Перевод отпечатанного текста в электронный вид отнимает гораздо меньше времени, чем перенабор вручную. Вы можете сохранить в электронном варианте книги, рефераты, курсовые, пособия и т.д.
Полученный результат можно сохранить в любом варианте расширения, в зависимости от того какой потребуется (doc, docx, rtf, txt, xls). Когда текст или графические элементы будут распознаны, можно удалить лишнюю информацию, или наоборот ее добавить. Кроме этого, если Вам необходимы отсканированные материалы без распознавания текста, мы готовы их записать на диск или флэш-карту, либо отправить на электронную почту.
Ознакомиться с нашими работами вы можете здесь. Получить консультацию наших специалистов Вы можете по телефону: (4872) 35-33-85. Обратившись лично в любой из Центров нашей сети, Вы сможете получить развернутую консультацию по интересующим Вас вопросам.
Распознование документов
Профессиональные услуги по распознаванию документов, благодаря наличию современного оборудования, программного обеспечения и невысокой стоимости, стали не только доступными, но и достаточно востребованными. Преобразование различных бумажных документов в электронный формат позволяет значительно упростить работу всей организации, снизить риск потери или порчи документов и избавить всех сотрудников от рутинной бумажной работы.
В первую очередь – это небольшой объем. Хранить всю необходимую информацию можно на компьютере, флешке или же на жестком диске. Кроме того – удобный поиск информации, благодаря чему работа пойдет в два раза быстрее. Также важным преимуществом является простота редактирования информации.
Также важным преимуществом является простота редактирования информации.
Без услуг сканирования и распознавания документов сегодня не обходится практически ни одна отрасль экономики.
Перевод в электронный вид
Зачастую услугами сканирования пользуются с целью перевода в электронный формат различных чертежей, бухгалтерских и юридических документов, книг, журналов, визиток и фотографий. Возможности сканирования и распознавания различных информационных носителей настолько разнообразны и безграничны, что можно легко произвести сканирование не только одного отдельного документа, но и целой библиотеки.
Сканирование документов: распознавание, оцифровка
Сканирование документов – процесс ответственный и кропотливый, ведь часто текстовая документация является ценной и содержит печати, специальные символы и прочее. Качественное воспроизведение невозможно без сканирования, так как ручной набор текста в данном случае даст значительные потери некоторых элементов. К тому же, такой текстовый документ необходимо хранить в специальных условиях, чтобы он не испортил своего внешнего вида. Все эти причины дают повод как физическим, так и юридическим лицам обращаться за услугой сканирования к специалистам. Ведь только они могут отсканировать документ без потери качества и при надобности скорректировать недостатки.
К тому же, такой текстовый документ необходимо хранить в специальных условиях, чтобы он не испортил своего внешнего вида. Все эти причины дают повод как физическим, так и юридическим лицам обращаться за услугой сканирования к специалистам. Ведь только они могут отсканировать документ без потери качества и при надобности скорректировать недостатки.
Распознавание текста
Бывает, что документы плохо читаемы, искажены, поэтому сканирование повсеместно может дополняться услугой распознавания текста. В этом случае информация на каждом листе обрабатывается в индивидуальном порядке. Данная услуга также важна для дальнейшего изменения требуемой информации: оцифрованный текст конвертируется в формат WORD или PDF, что дает возможность заказчику в дальнейшем свободно работать над содержимым документа.
«Архивный Сервис» предлагает свои услуги по оцифровке документов и архивов.
Но современные технологии и программное обеспечение не могут работать сами по себе без участия высококвалифицированных сотрудников. Компания “Архивный Сервис” оказывает полный спектр услуг по работе с различной документацией, среди которых сканирование и распознавание всех необходимых документов.
Компания “Архивный Сервис” оказывает полный спектр услуг по работе с различной документацией, среди которых сканирование и распознавание всех необходимых документов.
Услуги по распознаванию документов
Наша компания предоставляет услуги по распознаванию документов, использую для этого оптическую систему распознавания – OCR, которая позволяет за пару минут преобразовать любую информацию в цифровой формат. Система OCR имеет простейший автоматический режим, при помощи которого можно отсканировать и распознать текс, не имея никаких особых навыков. Но более профессиональная и точная работа требует ручных настроек, которые позволяют не только ускорить процесс обработки данных, но и снизить процент ошибок и каких-либо неточностей.
Автоматические, они же шаблонные настройки, удобны при распознавании более простых документов печатного вида, в то время как структурные или же автоматические настройки, дают возможность преобразовывать в электронный формат различные графики, таблицы и рукописный текст.
Работайте со специалистами
Распознавание документов и другие архивные работы , сотрудники компании “Архивный Сервис” проводят на профессиональном уровне, что говорит о высоком качестве выполняемой работы.
В наших силах не просто выполнить оцифровку документов, мы поможем вам привести в порядок все архивы и расставить все на свои места. Мы обязательно научим вас и ваших сотрудников обращаться с цифровым архивом.
Обращайтесь к нам по телефону: 8 (495) 227-04-94 или [email protected]ABBYY OCR и ПО для сканирования текста
Работа с цифровыми документами
Сочетая наш многолетний опыт и экспертизу с современными требованиями рынка, наши сканеры обеспечивают безопасное, точное и надежное преобразование бумажных документов в цифровой формат. С бизнес-ориентированным функционалом и выдающейся производительностью у всей продуктовой линейки, где бы вам ни потребовался документооборот, со сканерами Brother вы можете быть уверенными в продуктивном старте.
Эффективное сканирование с ABBYY
Чтобы максимально эффективно использовать отсканированные документы, ABBYY предоставляет функциональное программное обеспечение с широкими возможностями, перемещая работу с цифровыми документами на новый уровень.
Кто такие ABBYY?
ABBYY – ведущий поставщик технологий и услуг для распознавания документов, сбора данных и лингвистики. Они разрабатывают ведущее на рынке программное обеспечение для оптического распознавания символов (OCR) и распознавания текста для быстрого и простого преобразования отсканированных бумажных документов, PDF-файлов и цифровых изображений – превращая их в редактируемую информацию с возможностью поиска.
Что такое OCR?
Оптическое распознавание символов – это электронный перевод отсканированных документов в редактируемый текст с возможностью поиска. Это позволяет получить доступ к информации, зашитой в статическом растровом документе, и интегрировать ее в специальное программное обеспечение для бизнеса, такое как бухгалтерские или логистические программы.
Как это может помочь моему бизнесу?
Программное обеспечение для распознавания текста (OCR) позволяет организациям работать с отсканированными бизнес-документами, делая их:
Редактируемыми
- Удалите конфиденциальную информацию перед отправкой отсканированных документов.
- Обновите существующие документы.
- Добавьте к документам аннотации, комментарии по результатам встречи или пометки для внесения изменений.
Доступными для поиска
- Быстрый и простой поиск документов по ключевым словам или соответствующему контенту.
- Организуйте и архивируйте с возможностью мгновенного поиска.
Следующие сканеры поддерживают ABBYY:
N п/п | Наименование процесса, операции. Состав работы | Единица измерения | Норма времени, мин. |
1 | 2 | 3 | 4 |
Оформление и учет документов для оказания услуг: | |||
1 | получение и проверка договоров, заключенных с физическими лицами, читателями библиотеки, по оказанию услуг, связанных с использованием электронных ресурсов (ЭР) и электронных библиотек (ЭБ) | один документ | 60,0 |
2 | выгрузка реестра из автоматизированной системы по сформированным договорам, заключенным с физическими лицами, читателями библиотеки, по оказанию услуг, связанных с использованием ЭР и ЭБ | один реестр | 15,0 |
3 | сверка данных по поступившим договорам, заключенным с физическими лицами, читателями библиотеки, по оказанию услуг, связанных с использованием ЭР и ЭБ, с реестром, выгруженным из автоматизированной системы | одна сверка | 40,0 |
4 | прием заявки от юридического лица на заключение договора по оказанию услуг, связанных с использованием ЭР и ЭБ | один документ | 15,0 |
5 | подготовка текста договора по оказанию услуг, связанных с использованием ЭР и ЭБ | один документ | 15,0 |
6 | согласование договора по оказанию услуг, связанных с использованием ЭР и ЭБ | один документ | 300,0 |
7 | регистрация договора по оказанию услуг, связанных с использованием ЭР и ЭБ | один документ | 60,0 |
8 | заполнение требования на оформление финансового документа к договору по оказанию услуг, связанных с использованием ЭР и ЭБ | один документ | 30,0 |
9 | проверка оформленного финансового документа к договору на оказание услуг, связанных с использованием ЭР и ЭБ | один документ | 15,0 |
10 | подписание документа по оказанию услуг, связанных с использованием ЭР и ЭБ | один документ | 960,0 |
11 | внесение в реестры учета первичных данных о договоре по оказанию услуг, связанных с использованием ЭР и ЭБ | один документ | 30,0 |
12 | сканирование оформленного документа на оказание услуг, связанных с использованием ЭР и ЭБ | один документ | 30,0 |
13 | отправка по электронной почте юридическому лицу сканированной копии документа на оказание услуг, связанных с использованием ЭР и ЭБ | одно сообщение | 40,0 |
14 | подготовка текста документа о внесении изменений в заключенный договор на оказание услуг, связанных с использованием ЭР и ЭБ | один документ | 60,0 |
15 | подготовка текста ценового предложения на оказание услуг, связанных с использованием ЭР и ЭБ | один документ | 60,0 |
16 | подготовка текста акта к договору об оказании услуг, связанных с использованием ЭР и ЭБ | один документ | 60,0 |
17 | проверка данных на официальном сайте государственных закупок о проведении торговой закупки на оказание услуг, связанных с использованием ЭР и ЭБ | одна закупка | 20,0 |
18 | сохранение документации с официального сайта государственных закупок по объявленной торговой закупке на оказание услуг, связанных с использованием ЭР и ЭБ | один файл | 15,0 |
19 | проверка документации торговой закупки на оказание услуг, связанных с использованием ЭР и ЭБ | один документ | 40,0 |
20 | подготовка заявки для участия в объявленной торговой закупке на официальном сайте государственных закупок по оказанию услуг, связанных с использованием ЭР и ЭБ | одна заявка | 150,0 |
21 | визирование заявки в соответствии с регламентом библиотеки | один документ | 360,0 |
22 | подготовка текста договора для оформления по окончанию торговой закупки на официальном сайте государственных закупок по оказанию услуг, связанных с использованием ЭР и ЭБ | один документ | 70,0 |
23 | размещение заявки на официальном сайте государственных закупок | одна заявка | 40,0 |
24 | участие в торговой закупке на официальном сайте государственных закупок по регламенту электронной площадки | одна закупка | 120,0 |
25 | подготовка текстов документов в соответствии с требованиями регламента проведения торговой закупки по оказанию услуг, связанных с использованием ЭР и ЭБ | один документ | 360,0 |
26 | формирование платежного документа в бухгалтерской программе по требованию на оформление финансового документа к договору по оказанию услуг, связанных с использованием ЭР и ЭБ | один документ | 30,0 |
27 | вывод на печать из бухгалтерской программы сформированного платежного документа | один документ | 7,0 |
28 | передача пакета платежных документов на подписание в бухгалтерию | один пакет | 30,0 |
29 | формирование ежедневного отчета о работе по проекту и выполнении услуг, связанных с использованием ЭР и ЭБ | один документ | 60,0 |
30 | контроль сроков выполнения услуг, связанных с использованием ЭР и ЭБ | один документ | 30,0 |
31 | контроль исполнения финансовых обязательств по договору на оказание услуг, связанных с использованием ЭР и ЭБ | один документ | 30,0 |
32 | сверка исполнения обязательств по заключенным договорам на оказание услуг, связанных с использованием ЭР и ЭБ | один документ | 60,0 |
33 | корректировка данных в реестрах учета об исполнении условий договора по оказанию услуг, связанных с использованием ЭР и ЭБ | один документ | 40,0 |
34 | направление юридическому лицу сообщения по электронной почте об исполнении условий договора по оказанию услуг, связанных с использованием ЭР и ЭБ | одно сообщение | 30,0 |
35 | формирование пакета документов для направления юридическому лицу почтовым отправлением | один пакет | 40,0 |
36 | выдача оригиналов заключений и комплектов документов заказчикам на руки | один документ | 60,0 |
37 | подготовка комплекта документов по договорам с полностью выполненными обязательствами оказания услуг, связанных с использованием ЭР и ЭБ, для передачи в бухгалтерию | один комплект | 60,0 |
38 | составление реестра комплектов документов, хранящихся в архиве и/или передаваемых в бухгалтерию | один реестр | 60,0 |
39 | составление и оформление архивной папки оригиналов документов | одна папка | 30,0 |
40 | создание архивной электронной копии документов с полностью выполненными обязательствами оказания услуг, связанных с использованием ЭР и ЭБ, передаваемых в бухгалтерию | один документ | 40,0 |
41 | передача документов в бухгалтерию по реестру комплектов документов | один реестр | 40,0 |
42 | формирование отчетов о результатах работы по проекту оказания услуг, связанных с использованием ЭР и ЭБ | один документ | 1200,0 |
Информационная поддержка пользователей по оказанию услуг, связанных с использованием ЭР и ЭБ: | |||
43 | телефонные консультации по оказанию услуг, связанных с использованием ЭР и ЭБ, для юридических и физических лиц | один звонок | 40,0 |
44 | составление сообщений в ответ на входящие электронные письма по оказанию услуг, связанных с использованием ЭР и ЭБ | одно сообщение | 180,0 |
45 | формирование списка клиентов для проведения массовой рассылки по электронной почте по проекту оказания услуг, связанных с использованием ЭР и ЭБ | одна рассылка | 1920,0 |
46 | подготовка документов для проведения массовой рассылки по проекту оказания услуг, связанных с использованием ЭР и ЭБ | одна рассылка | 600,0 |
47 | проведение массовой рассылки по проекту оказания услуг, связанных с использованием ЭР и ЭБ | одна рассылка | 90,0 |
Осуществление услуги предоставления доступа к ЭР и ЭБ: | |||
48 | регистрация новых/активация/деактивация ранее работающих юридических/физических лиц в автоматизированной системе | одна запись | 30,0 |
49 | формирование сообщения представителю юридического лица с данными для активации доступа к ЭР и ЭБ | одно сообщение | 30,0 |
50 | контроль за оказанием услуг, связанных с использованием ЭР и ЭБ, для юридических и физических лиц с ЭР и ЭБ, включая мониторинг нарушения правил оказания услуг | одно юридическое/физическое лицо | 60,0 |
51 | корректировка данных о юридических лицах в автоматизированной системе | одна запись | 30,0 |
52 | внесение изменений в список юридических лиц, размещенный на сайте проекта | одна запись | 30,0 |
Осуществление услуги проверки текстового документа на наличие заимствований из документов в составе ЭБ: | |||
53 | внесение в реестр учета первичных данных о поступившем документе на оказание услуги проверки текстового документа на наличие заимствований из документов в составе ЭБ | один документ | 15,0 |
54 | корректировка данных в реестре учета об этапах выполнения заказа по оказанию услуги проверки текстового документа на наличие заимствований из документов в составе ЭБ | один документ | 15,0 |
55 | распределение документов по экспертам для оказания услуги проверки текстового документа на наличие заимствований из документов в составе ЭБ | один документ | 40,0 |
56 | передача документа эксперту для оказания услуги проверки текстового документа на наличие заимствований из документов в составе ЭБ | один документ | 15,0 |
57 | получение и обработка экспертом документа на оказание услуги проверки текстового документа на наличие заимствований из документов в составе ЭБ | один документ | 40,0 |
58 | изучение экспертом структуры, состава, содержания документа для оказания услуги проверки текстового документа на наличие заимствований из документов в составе ЭБ | один документ | 180,0 |
59 | проверка экспертом документа на наличие приемов, препятствующих распознаванию текста автоматизированной системой и оказанию услуги проверки текстового документа на наличие заимствований из документов в составе ЭБ | один документ | 180,0 |
60 | проведение экспертом первичной проверки документа с использованием автоматизированной системы | один документ | 60,0 |
61 | обработка экспертом отчета автоматизированной системы о первичной проверке документа с целью исключения корректных заимствований | один документ | 480,0 |
62 | анализ экспертом некорректных заимствований, обнаруженных в документе | один документ | 600,0 |
63 | анализ справочно-библиографического аппарата документа, включая сверку источников, указанных в списке литературы | один документ | 480,0 |
64 | формирование текста экспертного заключения по итогу проведенной проверки документа с учетом данных отчета автоматизированной системы | один документ | 120,0 |
65 | проверка текста заключения на предмет соответствия установленным требованиям к результату оказания услуги проверки текстового документа на наличие заимствований из документов в составе ЭБ | один документ | 15,0 |
66 | анализ содержания результатов проверки, указанных в заключении, корректировка формулировок | один документ | 60,0 |
67 | вывод на печать итоговой формы заключения по результату проведенной проверки документа с учетом данных отчета автоматизированной системы | один документ | 15,0 |
68 | подписание заключения | один документ | 240,0 |
69 | сканирование оформленного заключения | один документ | 30,0 |
70 | корректировка в реестрах учета данных о выполнении обязательств по договору и оказанию услуги проверки текстового документа на наличие заимствований из документов в составе ЭБ | один документ | 40,0 |
71 | составление дополнения к заключению по результату оказания проверки текстового документа на наличие заимствований из документов в составе ЭБ | одно письмо | 120,0 |
72 73 | сбор и обработка статистических данных по проектам с использованием ЭР и ЭБ | один запрос | 240,0 |
74 | проведение проверки качества файлов в ЭБ | один файл | 40,0 |
75 | загрузка файлов для включения в ЭБ с простановкой признака доступа | один файл | 30,0 |
76 | резервное копирование файлов ЭБ | одно копирование | 60,0 |
Интеллектуальное извлечение текста и данных с помощью OCR – Ценообразование Amazon Textract – Amazon Web Services
Пример расчета стоимости 1.
 API обнаружения текста документов
API обнаружения текста документовДопустим, вам требуется извлечь текст со 100 000 страниц отчетов об исследованиях при помощи API обнаружения текста документов. Цена за страницу в регионе Запад США (Орегон) составляет 0,0015 USD для первого миллиона страниц, поэтому стоимость обработки 100 000 страниц в месяц составит 150 USD. Посмотрите расчет ниже.
Общее количество обработанных страниц: 100 000
Цена за страницу: 0,0015 USD
Итоговая стоимость в месяц: 0,0015 USD * 100 000 = 150 USD
Пример расчета стоимости 2. API обнаружения текста документов
Допустим, вам требуется извлечь текст из двух миллионов страниц отчетов об исследованиях при помощи API обнаружения текста документов. Цена за страницу в регионе Запад США (Орегон) составляет 0,0015 USD для первого миллиона страниц и 0,0006 USD для последующих, поэтому стоимость обработки двух миллионов страниц составит 2100 USD. Посмотрите расчет ниже.
Посмотрите расчет ниже.
Общее количество обработанных страниц: 2 000 000
Цена за страницу: 0,0015 USD для первого миллиона страниц и 0,0006 USD для второго
Итоговая стоимость в месяц: 0,0015 USD * 1 000 000 + 0,0006 USD * 1 000 000 = 1500 USD + 600 USD = 2100 USD
Пример расчета стоимости 3. API анализ документа (формы и таблицы)
Допустим, вам нужно извлечь текст и структурированные данные из 5000 страниц налоговых форм при помощи API анализа документов. Цена за страницу в регионе Запад США (штат Орегон) составляет 0,015 USD для одного миллиона страниц с таблицами, с формами – 0,05 USD, а общая сумма 325 USD. Посмотрите расчет ниже.
Общее количество обработанных страниц: 5000
Цена за страницу с таблицей: 0,015 USD
Цена за страницу с формой (пара «ключ-значение»): 0,05 USD
Общая стоимость: 0,015 USD * 5000 + 0,05 USD * 5000 = 75 USD + 250 USD = 325 USD
Пример расчета стоимости 4.
 API анализ документа (формы и таблицы)
API анализ документа (формы и таблицы)Допустим, вам нужно извлечь текст, формы и таблицы из двух миллионов страниц налоговых форм при помощи API анализа документов. Цена за страницу в регионе Запад США (Орегон) составляет 0,015 USD для первого миллиона страниц с таблицами и 0,01 USD для последующих. Цена страницы с формой – 0,05 USD для первого миллиона страниц и 0,04 USD для последующих. Общая стоимость составит 115 000 USD. Посмотрите расчет ниже.
Общее количество обработанных страниц: 2 000 000
Цена за страницу с таблицей: 0,015 USD за первый миллион страниц, 0,01 USD за следующий миллион
Цена за страницу с формой (пара «ключ-значение»): 0,05 USD за первый миллион страниц, 0,04 USD за следующий миллион
Общая стоимость: 0,015 USD * 1 000 000 + 0,01 USD * 1 000 000 + 0,05 USD * 1 000 000 + 0,04 USD * 1 000 000 = 15 000 USD + 10 000 USD + 50 000 USD + 40 000 USD = 115 000 USD
Пример расчета стоимости 5.
 API анализ расходов
API анализ расходовДопустим, вам необходимо извлечь данные из 100 000 счетов с помощью API анализа расходов. Цена за страницу в регионе Запад США (Орегон) составляет 0,01 USD для первого миллиона страниц, а вы обрабатываете 100 000 счетов. Общая стоимость составит 1000 USD. Посмотрите расчет ниже.
Общее количество обработанных страниц: 100 000
Цена за страницу: 0,01 USD
Итоговая стоимость в месяц: 0,01 USD * 100 000 = 1000 USD
Пример расчета стоимости 6. API анализ расходов
Допустим, вам необходимо извлечь данные из 1 500 000 счетов с помощью API анализа расходов. Цена за страницу в регионе Запад США (Орегон) составляет 0,01 USD для первого миллиона страниц с таблицами и 0,008 USD для последующих. Общая стоимость составит 14 000 USD. Посмотрите расчет ниже.
Общее количество обработанных страниц: 1 500 000
Цена за страницу: 0,01 USD за 1 миллион страниц и 0,008 USD за следующие 500 000 страниц
Итоговая стоимость в месяц: 0,01 USD * 1 000 000 + 0,008 USD * 500 000 = 14 000 USD
Аутсорсинг услуг оптического распознавания символов
Оптическое распознавание символов или OCR – это механический или электронный перевод данных в текст, автоматически редактируемый машиной. Обычно ввод данных с помощью сканера выполняется быстрее, точнее и эффективнее, чем ввод данных нажатием клавиши.
Обычно ввод данных с помощью сканера выполняется быстрее, точнее и эффективнее, чем ввод данных нажатием клавиши.
Аутсорсинг услуг оптического распознавания текста и ввода данных поставщикам услуг call-центра является наиболее экономичным решением. Поручите Flatworld Solutions наиболее профессиональную работу с вашими услугами оптического распознавания символов.Благодаря современным технологиям Flatworld Solutions сбор ваших данных будет в надежных руках.
Услуги по очистке OCR
Поскольку производительность программного обеспечения оптического распознавания символов (OCR) зависит от четкости содержания бумажного документа, случайные ошибки неизбежны, если бумажный документ содержит искаженные тексты. Наши службы очистки OCR заботятся об исправлении или замене неправильно прочитанных символов, сравнивая фактический текстовый документ с файлами, отсканированными с помощью программного обеспечения OCR.Мы также проверяем технические данные, такие как графики, таблицы, сноски и т.
 Д.
Д.Услуги по оцифровке документов
Когда мир приближается к безбумажным транзакциям, компаниям может быть настоятельно необходимо присоединиться к этой трансформации. Наши услуги по оцифровке документов – идеальное решение для оцифровки документов, так что становится проще сохранять, тиражировать, совместно использовать и извлекать данные. Наши специалисты проведут вас через весь процесс и обеспечат быстрое и безопасное завершение проекта.И все это с гарантией 98% точности готовых результатов.
Сканирование и преобразование микрофиш
Вы можете сэкономить время и деньги на приобретении специального сканирующего оборудования, отдав нам сканирование и преобразование микрофиш на аутсорсинг. Наша команда будет соблюдать все требования и следить за тем, чтобы информация на микрофише была тщательно преобразована после сканирования. Будь то Jacketed, COM, Rewritable или Step and Repeat, мы обрабатываем все формы преобразования микрофиш.
 Наши услуги позволят вам повысить производительность и прибыль за счет превосходной производительности.
Наши услуги позволят вам повысить производительность и прибыль за счет превосходной производительности.Службы сканирования документов
Преобразование больших и сложных бумажных документов в цифровые изображения может оказаться непрактичным для небольших фирм или крупных корпораций, которым приходится решать другие задачи. Поэтому продуктивным выбором будет делегирование задач нам, в FWS. Мы просканируем все ваши документы в нужном вам порядке и своевременно предоставим отчеты, чтобы вы могли проверять файлы и отслеживать эффективность сканирования.Наши услуги сканирования документов позволят вам управлять отсканированными файлами эффективнее, чем их сортировка и извлечение вручную.
Услуги преобразования OCR
Мы предоставляем комплексные и подробные услуги преобразования OCR (оптического распознавания символов), которые помогут вам преобразовать информацию в ваших бумажных документах в электронный формат. За годы работы по преобразованию OCR мы получили твердое представление о стратегиях преобразования OCR и всегда внедряем новейшие передовые методы преобразования OCR, чтобы обеспечить очень высокое качество преобразования.

Услуги оптического распознавания символов Flatworld Solutions
- Flatworld Solutions отформатирует информацию в легко доступный и удобный файл и сохранит ее в электронной структуре.
- Почти нулевые ошибки ввода данных, ваши данные будут легко интегрированы и легко читаются
- Категории сканеров OCR для ввода текста и захвата данных доступны в Flatworld Solutions Услуги сканера ввода текста
- Flatworld Solutions позволят вам сортировать большие объемы данных, которые можно редактировать позже.
- Сканеры сбора данных могут собирать и настраивать повторяющиеся данные Решения
- Flatworld могут получать информацию из любого существующего формата ваших данных – будь то старые бумажные файлы, формы, приложения или текстовые документы.
- Хорошо обученная и профессиональная команда Flatworld Solutions может круглосуточно справиться с большими объемами работы.
- Услуги OCR, предлагаемые Flatworld Solutions, можно использовать с любой техникой печати.

Передайте услуги оптического распознавания на аутсорсинг Flatworld Solutions и получите услуги ICR!
- Flatworld Solutions также предлагает интеллектуальное распознавание символов или ICR.ICR – это усовершенствованная форма оптического распознавания символов, более конкретная – она предназначена, в частности, для распознавания рукописного текста.
- ICR расширяет возможности служб оптического распознавания текста и обеспечивает 98% точность чтения рукописного текста в структурированных формах.
- Используя автоматизированную обработку форм, полезное изобретение в развитии ICR, Flatworld Solutions предоставляет лучшие в отрасли услуги ICR и OCR.
- Отсутствует трудоемкий ручной ввод, и весь процесс более точен и точен, чем традиционный ввод данных человеком.
- Еще одна услуга, дающая Flatworld Solutions преимущество перед другими, – это услуги распознавания символов с помощью магнитных чернил.Точность достигает 1 ошибки чтения на каждые 30 000 проверок! Только в Flatworld Solutions!
Услуги оптического распознавания символов (OCR) на Филиппинах
O CR сегодня широко используется многими предприятиями для преобразования данных в форматы, редактируемые машиной. Наши услуги оптического распознавания текста на Филиппинах помогут вам преобразовать все ваши бизнес-данные в редактируемые форматы и сохранить их в безопасном и быстром доступе при необходимости.
Наши услуги оптического распознавания текста на Филиппинах помогут вам преобразовать все ваши бизнес-данные в редактируемые форматы и сохранить их в безопасном и быстром доступе при необходимости.
Зачем отдавать услуги OCR на аутсорсинг решениям Flatworld?
- Outsourcing to Flatworld Solutions »гарантирует, что услуги оптического распознавания символов и ввода данных будут в надежных, квалифицированных и опытных руках. Профессиональная команда
- Flatworld Solutions обладает всесторонним пониманием процесса предоставления услуг OCR и ICR, их функционирования и решений, что делает их полезным объединением для вашего бизнеса.
- Руководители отдела аутсорсинга Flatworld Solutions будут управлять вашим центром обработки данных наиболее эффективно Решения
- Flatworld не только принесут вам абсолютное удовлетворение, но и превзойдут ваши ожидания и принесут желаемые результаты.
- В Flatworld Solutions вы получите услуги высочайшего качества по минимальной цене.
 Flatworld Solutions гарантирует рентабельные и высококачественные услуги.
Flatworld Solutions гарантирует рентабельные и высококачественные услуги. - Чтобы изображение было готово к распознаванию текста, мы выравниваем изображения, чтобы улучшить их читаемость.
40% Снижение затрат
8-24 часа Более быстрый ремонт
500+ Довольных клиентов
350+ Квалифицированные данные
Эксперты в области управления
99% Точность
16 лет опыта
Передайте услуги Flatworld Solutions и будьте уверены, что ваши услуги оптического распознавания текста находятся в самых надежных руках.Вы можете легко сосредоточиться на своем бизнесе, не беспокоясь о своей рабочей нагрузке по вводу данных.
Прочтите статью о 9 ключевых преимуществах ввода данных на основе OCR.
Подробнее о службах очистки данных и службах каталогов. Также прочтите о службах очистки OCR.
Если вы хотите передать свою работу по вводу данных в Индию, пожалуйста, заполните форму запроса. Наша команда по работе с клиентами свяжется с вами.
Наша команда по работе с клиентами свяжется с вами.
Услуги оптического распознавания символов – Microform Imaging
Проще говоря, оптическое распознавание символов (OCR) – это процесс обеспечения того, чтобы электронные файлы, которые были отсканированы, были полностью доступны для поиска и редактирования в отношении текста, который в них находится.
После сканирования документы обычно преобразуются в цифровые изображения (например, PDF-файлы), а с преобразованием OCR их можно преобразовать в полностью редактируемые файлы, в том числе:
- PDF-файлы с возможностью поиска
- CSV файлов
- XML-файлов
- файлов Excel
- Файлы Microsoft Word
Как работает OCR?
Как и многие технологии, OCR основывается на двух основных типах алгоритмов, которые создают список возможных символов для распознавания.
Сопоставление символов включает в себя сравнение того, что представлено в файле, с тем, что программа уже знает, и это делается попиксельно; сопоставление шаблонов и сравнение их с сохраненными данными.
Как можно догадаться, чем лучше состояние документа, тем выше точность. Документы хорошего качества и хорошей сохранности часто достигают точности 99% и более, но царапины, потертости и выцветание чернил могут снизить вероятность успеха.
В случае плохого качества документа, файла или архива наши опытные корректоры всегда готовы найти и исправить ошибки в качестве дополнительной услуги.
Какие документы можно преобразовать в OCR?
Здесь, в Microform, мы можем конвертировать массив физических документов в OCR.
Сюда входят:
Что это значит для клиентов
OCR предоставляет предприятиям и организациям множество преимуществ.
Возможно, одним из самых больших преимуществ наличия OCR PDF-файлов и других файлов является то, что компании могут сократить часы и дни, затрачиваемые на поиск отдельных документов и папок в больших архивах.
Поскольку мы работаем с широким кругом клиентов – от медицинских организаций до финансовых учреждений – у нас есть большой опыт сканирования и преобразования конфиденциальных, частных и редких документов в файлы, готовые для распознавания текста.
Более того, после сканирования файлов в наших безопасных помещениях наши клиенты получают мгновенные цифровые резервные копии всех файлов и записей на случай, если что-то пойдет не так.
В то время как физические пленки и бумага изнашиваются со временем, файлы PDF с оптическим распознаванием текста и другие файлы можно сохранять на облачном сервере или в любом количестве мест, где это будет сочтено необходимым.
Почему выбирают нашу программу оптического распознавания текста
Microform была создана более 50 лет и работала с рядом предприятий, организаций и учреждений со всей Великобритании.
Хотя программное обеспечение для цифрового сканирования и оптического распознавания символов не существует так долго, как мы, мы гордимся тем, что нам доверяют возможность предлагать наилучшие результаты для ряда медицинских, академических, финансовых и юридических организаций.
Более того, наши услуги полностью персонализированы, что позволяет нам удовлетворить любые потребности и прихоти клиента.
Это гарантирует не только наилучшие возможные результаты, но также и безопасность всех имеющихся у нас документов, фильмов и файлов.
Для получения дополнительной информации о наших услугах оптического распознавания символов, о том, как работает этот процесс, или о том, что мы предлагаем, свяжитесь с нами по адресу [email protected] или позвоните нам по телефону 01924 825 700.
секретов веб-службы распознавания текста Google | Эдвард Ма
Оптическое распознавание символов (OCR) – один из способов связать мир реальности и виртуальное слово.Первая система OCR представлена в конце 1920-х годов. Целью OCR является распознавание текста на изображении. Однако добиться очень высокой точности очень сложно из-за множества факторов. В следующей истории я расскажу, как Google создает решение, которое является одним из API Google Cloud Vision для решения этой проблемы.
Говоря об OCR, tesseract – одна из самых известных библиотек с открытым исходным кодом, которую каждый может использовать для выполнения OCR. Tesseract находится в HP, а разработка спонсируется Google с 2006 года.Модель Tesseract 3.x – это старая версия, а версия 4.x построена с помощью глубокого обучения (LSTM). Если вы хотите понять разницу между 3.x и 4.x, вы можете посетить раздел «Совместное использование» для получения более подробной информации.
Tesseract находится в HP, а разработка спонсируется Google с 2006 года.Модель Tesseract 3.x – это старая версия, а версия 4.x построена с помощью глубокого обучения (LSTM). Если вы хотите понять разницу между 3.x и 4.x, вы можете посетить раздел «Совместное использование» для получения более подробной информации.
Поскольку тессеракт реализован в C ++, мы не можем вызывать его как другую библиотеку Python. Действительно, мы можем вызывать C-API в python, но это не совсем удобно для пользователя. Поэтому введена оболочка python pytesseract, чтобы упростить нашу жизнь.
Перед тем, как познакомиться с архитектурным проектированием, необходимо было ввести некоторые определения.
- Скрипт и язык: скрипт отличается от языка. Сценарий относится к системе письма, а язык – к разговорной речи в большинстве случаев. На следующем рисунке «специалист по данным» – это английский язык, написанный латиницей, а «shuju kexuejia» – китайский язык, написанный латиницей.
- Ограничивающая рамка: в отличие от других систем распознавания текста, ограничивающая рамка включает в себя одну строку обнаруженного текста вместо одного символа или одного слова.

- Рассмотрение модели: Помимо точности, при построении модели также учитываются стоимость, универсальность и ремонтопригодность.
Создавая изображение, оно проходит 5 этапов, чтобы получить окончательный результат в Google Vision API.
Архитектура API Google Cloud Vision (Walker et al., 2018)Обнаружение текста
Первым шагом является использование модели на основе обычной нейронной сети (CNN) для обнаружения и локализации строк текста и создания набора ограничивающих рамок.
Идентификация направления
Классифицирует направление по ограничивающей рамке. При необходимости ограничивающая рамка будет отфильтрована, так как ошибочно определяется как текст.
Идентификация сценария
Идентифицирует сценарий для ограничивающей рамки. Предполагается, что на каждую ограничивающую рамку приходится по одному сценарию, но допускается несколько сценариев на изображение.
Распознавание текста
Это основная часть OCR, которая распознает текст с изображения. Он включает не только символьную языковую модель, но также оптическую модель начального стиля и настраиваемый алгоритм декодирования.
Он включает не только символьную языковую модель, но также оптическую модель начального стиля и настраиваемый алгоритм декодирования.
Анализ компоновки
Определение порядка чтения и различение заголовков, заголовков и т. Д.
Как упоминалось ранее, tesseract спонсируется Google. Думаю, это одна из причин, по которой авторы сравнивают результат с тессерактом. Коэффициент символьных ошибок (CER) принят для сравнения моделей. Он определяется как расстояние редактирования, деленное на длину ссылки и масштабируемое на 100. Чем меньше, тем лучше.
Tesseract против Google Cloud Vision API (Walker et al. 2018)Задержитесь, почему этап обработки изображения не включается в конвейер? В документе не упоминается причина. Я считаю, что это связано с тем, что модель нейронной сети уже способна улавливать эти характеристики.
Помимо производительности, еще одним важным фактором является скорость. По моему опыту, Tesseract хорошо распознает, но довольно медленно.
Я специалист по анализу данных в районе залива. Сосредоточение внимания на последних достижениях науки о данных, искусственного интеллекта, особенно в области НЛП и связанных с платформами. Вы можете связаться со мной из среднего блога, LinkedIn или Github.
Уокер Дж., Фуджи Ю., Попат А. С. 2018. Веб-служба OCR для документов.
Fujii Y., Driesen K., Baccash J., Hurst A., Попат А. С. 2017. Идентификация скрипта от последовательности до метки для многоязычного распознавания текста.
Услуги оптического распознавания символов, Услуги оптического распознавания символов
Оптическое распознавание символов Sam studio предлагает услуги оптического распознавания символов (OCR) для файлов различных типов, таких как изображения, письменные документы и файлы PDF, в редактируемые форматы данных, которые доступны для поиска с помощью компьютерных систем.Процесс преобразования или преобразования документов в редактируемую версию документов называется OCR. Причина, по которой услуги OCR были переданы на аутсорсинг Sam Studio, принесет большую пользу бизнесу вашей организации. Если вы хотите без опасений управлять своей деловой информацией, свяжитесь с нашей командой. Мы можем преобразовать ваши файлы в формате изображений или переносимых документов в удобные для чтения и редактирования путем сканирования с помощью компьютерных или компьютерных сканеров и предоставить вам доступные форматы.
Причина, по которой услуги OCR были переданы на аутсорсинг Sam Studio, принесет большую пользу бизнесу вашей организации. Если вы хотите без опасений управлять своей деловой информацией, свяжитесь с нашей командой. Мы можем преобразовать ваши файлы в формате изображений или переносимых документов в удобные для чтения и редактирования путем сканирования с помощью компьютерных или компьютерных сканеров и предоставить вам доступные форматы.
Услуги OCR помогут во многих промышленных целях, таких как выставление счетов, выставление счетов и другие виды юридической обработки бизнеса. Он будет извлекать бизнес-информацию из любых источников и сохранять ее в желаемых базах данных. Это позволяет пользователю конвертировать ваши печатные или электронные форматы в редактируемые текстовые версии. Техника оптического распознавания символов также помогает преобразовать ваши документы на основе изображений в доступные для поиска форматы.
Мы можем преобразовать форматы файлов сканирования на вашем компьютере, используя компьютерные коды ASCII. Этот метод будет полезен как для промышленных, так и для технологических нужд во многих промышленных целях. Если вы хотите упростить свой бизнес с меньшими затратами и выполнить свою работу в кратчайшие сроки, сообщите нам об этом. Мы работаем круглосуточно, мы можем предоставить вам рентабельные услуги в любое время с нашими опытными профессионалами.
Этот метод будет полезен как для промышленных, так и для технологических нужд во многих промышленных целях. Если вы хотите упростить свой бизнес с меньшими затратами и выполнить свою работу в кратчайшие сроки, сообщите нам об этом. Мы работаем круглосуточно, мы можем предоставить вам рентабельные услуги в любое время с нашими опытными профессионалами.
Наши специалисты по управлению данными эффективно понимают компоненты вашего бизнеса и достигают нужных результатов с помощью безопасного программного обеспечения для распознавания текста; мы никогда не используем какие-либо небезопасные или сложные программные инструменты для преобразования ваших данных в доступные для поиска форматы.С помощью наших квалифицированных специалистов по разработке программного обеспечения мы создали специальные инструменты с поддержкой OCR для преобразования ваших электронных файлов или файлов изображений в текстовую версию.
Обычно компании, у которых имеется огромное количество записей исходных данных в печатной форме, а также предстоящие данные, ждут, чтобы заполнить компанию бумажным листом. Вы хотели избежать? Просто обратитесь к нашему аутсорсеру SAM STUDIO, чтобы преобразовать все бумажные записи в электронные копии.Мы используем новейшее программное обеспечение OCR для преобразования всех текстовых форматов, таких как рукописные данные, текст в печатной копии, изображения в электронную копию. OCR – это технология захвата и сканирования текстового формата с помощью сканера и преобразования его в электронный код ASCII. А затем наша высококлассная система оптического распознавания символов автоматически загружает, считывает и сортирует данные. Мы обслуживаем эти услуги для государственных служащих, вспомогательных офисов для больниц, банков, страховых компаний, учебных заведений, ИТ-компаний и т. Д.Благодаря нашей высокоскоростной системе OCR мы предлагаем эту услугу по низкой цене.
Вы хотели избежать? Просто обратитесь к нашему аутсорсеру SAM STUDIO, чтобы преобразовать все бумажные записи в электронные копии.Мы используем новейшее программное обеспечение OCR для преобразования всех текстовых форматов, таких как рукописные данные, текст в печатной копии, изображения в электронную копию. OCR – это технология захвата и сканирования текстового формата с помощью сканера и преобразования его в электронный код ASCII. А затем наша высококлассная система оптического распознавания символов автоматически загружает, считывает и сортирует данные. Мы обслуживаем эти услуги для государственных служащих, вспомогательных офисов для больниц, банков, страховых компаний, учебных заведений, ИТ-компаний и т. Д.Благодаря нашей высокоскоростной системе OCR мы предлагаем эту услугу по низкой цене.
от службы распознавания форм на основе AI-OCR: Hitachi Review
Введение
Инновации в цифровых технологиях, таких как искусственный интеллект (AI) и Интернет вещей (IoT), приносят серьезные изменения в общество. Новая ИТ-стратегия Hitachi предполагает ускорение работы по цифровизации всех слоев общества в качестве средства повышения удобства для населения и повышения эффективности как в государственном, так и в частном секторах (1) .
Новая ИТ-стратегия Hitachi предполагает ускорение работы по цифровизации всех слоев общества в качестве средства повышения удобства для населения и повышения эффективности как в государственном, так и в частном секторах (1) .
Между тем бумажные формы, такие как счета-фактуры, по-прежнему используются для записи и передачи информации в правительственные учреждения, компании частного сектора и другие организации, которые занимаются административной работой. Информация в этих формах вводится в компьютерные системы для обработки, а это означает, что, когда эта работа выполняется вручную, есть возможности для повышения эффективности за счет использования оптического распознавания символов на основе искусственного интеллекта (AI-OCR).
В этой статье описываются существующие OCR и AI-OCR, которые объединяют OCR и AI, и приводится пример того, как операционная эффективность была повышена за счет использования службы распознавания форм Hitachi, которая включает AI-OCR. В статье также описываются планы Hitachi по анализу скрытых данных – методике извлечения ценности, скрытой в обычных деловых документах.
В статье также описываются планы Hitachi по анализу скрытых данных – методике извлечения ценности, скрытой в обычных деловых документах.
Переход с OCR на AI-OCR
Обзор OCR и AI-OCR
OCR – это способ чтения текста, содержащегося в данных изображения. Точно так же AI-OCR – это приложение AI для этой цели.Хотя это форма OCR в том смысле, что она извлекает текст из данных изображения, AI-OCR отличается тем, что использует AI при обработке распознавания для преодоления проблем с обычным OCR.
На практике это означает, что он способен читать сложный рукописный текст (например, случайные записи, рукописный текст, не очерченный линованной бумагой, или зачеркнутый текст), такие формы, как счета-фактуры с макетом, который варьируется от от компании к компании, а также документы в произвольном формате, такие как контракты. Точность также можно повысить за счет использования обучения ИИ. Этот метод тесно связан с роботизированной автоматизацией процессов (RPA), с которой его можно комбинировать для расширения объема автоматизации задач в организациях, где это необходимо.
Точность также можно повысить за счет использования обучения ИИ. Этот метод тесно связан с роботизированной автоматизацией процессов (RPA), с которой его можно комбинировать для расширения объема автоматизации задач в организациях, где это необходимо.
Роль AI-OCR в цифровизации общества
В этом разделе рассматривается будущая роль AI-OCR, рынок которого неуклонно растет, и возможности его дальнейшего развития в условиях перехода к безбумажной практике как части цифровизации всего общества.
Прогнозируется, что рынок AI-OCR вырастет с примерно 700 млн иен в 2018 финансовом году до 3,2 млрд иен в 2030 финансовом году (2) . Две основные причины этого заключаются в следующем.
- Рост ожиданий от AI-OCR как средства повышения эффективности за счет использования цифровых технологий для ввода данных с бумажных форм, которые будут по-прежнему использоваться в существующей практике.
Среди факторов, стоящих за этим, – препятствия на пути к безбумажной (цифровой) существующей практики, которые включают в себя необходимость фундаментальной перестройки целых рабочих процессов и их компьютерных систем и другой связанной инфраструктуры, а также необходимость поддерживать целостность документации (подлинность документов, доступность и т. д.) для введенной или архивированной информации на том же уровне, что и бумажные записи. - Продолжающаяся оцифровка архивных бумажных документов и растущий спрос на использование и анализ данных
По этим причинам ожидается, что AI-OCR продолжит играть роль в будущей цифровизации.
Новые приложения стали возможными благодаря переходу от OCR к AI-OCR
Фиг. 1 – Схема того, как переход от OCR к AI-OCR позволяет использовать его в более широком диапазоне задач управления документами Обеспечивая как технические, так и сервисные улучшения, переход от OCR к AI-OCR позволяет технологии адаптироваться к множеству различных характеристик задач. Однако даже по мере того, как AI-OCR будет внедряться, ожидается, что ограничения, налагаемые существующей практикой и другими подобными факторами, приведут к сохранению спроса на вид сканирования с фиксированным форматом, для которого используется обычное OCR.
1 – Схема того, как переход от OCR к AI-OCR позволяет использовать его в более широком диапазоне задач управления документами Обеспечивая как технические, так и сервисные улучшения, переход от OCR к AI-OCR позволяет технологии адаптироваться к множеству различных характеристик задач. Однако даже по мере того, как AI-OCR будет внедряться, ожидается, что ограничения, налагаемые существующей практикой и другими подобными факторами, приведут к сохранению спроса на вид сканирования с фиксированным форматом, для которого используется обычное OCR.
Переход от OCR к AI-OCR расширил круг задач управления документами, в которых можно использовать эту технологию. На рисунке 1 показано, как это работает. AI-OCR предоставил улучшения услуг, а также технические улучшения, связанные с достижениями в области ИТ. Вместо того, чтобы приобретать специальные сканеры специально для сезонных работ, таких как периоды пиковой активности или работы с формами, которые обрабатываются небольшими объемами или во многих различных форматах, как это было в случае с обычным OCR, AI-OCR предоставляется в стандартизированной форме. как облачный сервис.В следующем разделе обсуждается проблема неструктурированных данных, для которых использование AI-OCR затруднительно.
AI-OCR предоставил улучшения услуг, а также технические улучшения, связанные с достижениями в области ИТ. Вместо того, чтобы приобретать специальные сканеры специально для сезонных работ, таких как периоды пиковой активности или работы с формами, которые обрабатываются небольшими объемами или во многих различных форматах, как это было в случае с обычным OCR, AI-OCR предоставляется в стандартизированной форме. как облачный сервис.В следующем разделе обсуждается проблема неструктурированных данных, для которых использование AI-OCR затруднительно.
Повышение эффективности от службы распознавания форм на основе AI-OCR
Прошлые работы Hitachi и обзор службы распознавания форм
Фиг. 2 – Обзор службы распознавания форм на основе AI-OCR Служба оснащена механизмами распознавания как форм фиксированного формата, так и форм свободного формата, таких как счета-фактуры, которые не соответствуют заранее определенному формату. Он использует технику распознавания, которая лучше всего подходит для данной задачи, и обеспечивает очень точные результаты вместе с оценкой достоверности, указывающей на точность распознавания.
2 – Обзор службы распознавания форм на основе AI-OCR Служба оснащена механизмами распознавания как форм фиксированного формата, так и форм свободного формата, таких как счета-фактуры, которые не соответствуют заранее определенному формату. Он использует технику распознавания, которая лучше всего подходит для данной задачи, и обеспечивает очень точные результаты вместе с оценкой достоверности, указывающей на точность распознавания.
Hitachi разрабатывает технологии OCR с тех пор, как эта практика впервые вошла в коммерческое использование в настоящее время AI-OCR, и продолжает делать это с расчетом на будущее. Эта работа началась в 1968 году с выпуска оптического считывателя символов Hitachi H-8252, первой такой универсальной системы оптического распознавания символов, производимой в Японии (3), (4) . Разработка технологии продолжалась, кульминацией которой стала существующая облачная служба AI-OCR для сканирования широкого спектра бизнес-форм, использующая глубокое обучение и другие подобные методы. Используя деловые и технические ноу-хау, накопленные за многие годы, Hitachi стремится разрабатывать новые услуги для мира будущего, которые позволят решить проблемы на рабочем месте, с которыми сталкиваются ее клиенты.
Разработка технологии продолжалась, кульминацией которой стала существующая облачная служба AI-OCR для сканирования широкого спектра бизнес-форм, использующая глубокое обучение и другие подобные методы. Используя деловые и технические ноу-хау, накопленные за многие годы, Hitachi стремится разрабатывать новые услуги для мира будущего, которые позволят решить проблемы на рабочем месте, с которыми сталкиваются ее клиенты.
Hitachi в настоящее время предоставляет свою услугу распознавания форм в первую очередь финансовым учреждениям, используя ее как средство перехода на безбумажную практику.Служба распознавания форм, подходящая для задач ввода данных в широком спектре отраслей, включает сервисную платформу, на которой ряд различных механизмов AI-OCR используют AI для выполнения высокоточного распознавания текста с возможностями, которые включают сканирование фиксированных и формы свободного формата, печатный и рукописный текст, а также двухмерные штрих-коды. Он также оснащен запатентованным алгоритмом Hitachi, который вычисляет показатель достоверности для точности распознавания, обеспечивая простой способ идентифицировать данные, которые могли быть отсканированы неправильно.Эти технические особенности обеспечивают плавную интеграцию сервиса с другими бизнес-приложениями, что позволяет автоматизировать широкий спектр работ по обработке форм. На рисунке 2 показан обзор службы распознавания форм.
Он также оснащен запатентованным алгоритмом Hitachi, который вычисляет показатель достоверности для точности распознавания, обеспечивая простой способ идентифицировать данные, которые могли быть отсканированы неправильно.Эти технические особенности обеспечивают плавную интеграцию сервиса с другими бизнес-приложениями, что позволяет автоматизировать широкий спектр работ по обработке форм. На рисунке 2 показан обзор службы распознавания форм.
Технологические и сервисные подходы к повышению эффективности
Фиг.3 – Технологический подход к использованию службы распознавания форм для повышения эффективности Для повышения эффективности различных типов обработки форм служба распознавания форм использует AI-OCR и другие подобные технологии для сканирования форм как фиксированного, так и свободного формата с помощью высокие показатели распознавания, а также оценка достоверности, помогающая сократить объем работы, необходимой для проверки вывода OCR.
Способы использования службы распознавания форм для повышения эффективности можно в общих чертах разделить на следующие два подхода.
(1) Технологический подход
Служба распознавания форм решает проблемы с приложениями, в которых использование OCR затруднено по техническим причинам. На Рисунке 3 показан обзор.
- Снижение рабочей нагрузки за счет использования службы для обработки широкого спектра форм
Если AI-OCR должен снизить рабочую нагрузку на персонал по вводу данных, он должен иметь возможность непрерывного улучшения скорости распознавания символов и использования для чтения широкого спектра различных форм. формы.В случае форм свободного формата, таких как счета-фактуры, где расположение денежных сумм отличается от компании к компании, AI-OCR также должен иметь возможность работать без необходимости заранее указывать расположение этих полей данных формы.
Для достижения высокого уровня точности распознавания, не зависящего от конкретных особенностей почерка разных людей, AI-OCR сочетает глубокое обучение с расширенной обработкой естественного языка. Высокоточное распознавание рукописного ввода ИИ было достигнуто за счет использования глубокого обучения для изучения различных вариаций в таких вещах, как форма символов и интервалы, встречающиеся в почерке.Точно так же низкий уровень ошибок распознавания был достигнут за счет использования расширенной обработки естественного языка для оценки вероятности появления различных символов на уровне слов и, таким образом, для оценки точности AI распознавания рукописного ввода, а также для расчета оценок достоверности, обсуждаемых ниже.
Служба распознавания форм также повышает точность распознавания текста за счет выбора оптимального механизма AI-OCR для форм фиксированного или свободного формата из множества вариантов, которые включают сторонние технологии, а также собственную технологию распознавания Hitachi. Услуга также включает возможность обучения для обновления модели распознавания, чтобы постоянно улучшать показатели распознавания символов. Между тем, в случае форм свободного формата, сервис может использоваться для чтения широкого спектра из них независимо от того, как они расположены, имея возможность определять, где находятся обязательные поля в форме, без необходимости указывать это в продвигать. Вместо этого все, что нужно, – это указать, какую информацию необходимо извлечь для конкретной выполняемой задачи.
Услуга также включает возможность обучения для обновления модели распознавания, чтобы постоянно улучшать показатели распознавания символов. Между тем, в случае форм свободного формата, сервис может использоваться для чтения широкого спектра из них независимо от того, как они расположены, имея возможность определять, где находятся обязательные поля в форме, без необходимости указывать это в продвигать. Вместо этого все, что нужно, – это указать, какую информацию необходимо извлечь для конкретной выполняемой задачи. - Снижение рабочих нагрузок за счет использования оценок достоверности для оценки точности распознавания
Поскольку ожидание 100% точности распознавания нереально, отсканированная информация должна проверяться людьми. Различение между задачами, которые могут быть автоматизированы с помощью RPA (обработка, которая может быть делегирована машинам), и задачами, для которых требуется проверка, выполняемая человеком, является важным фактором при определении того, насколько можно уменьшить объем этой проверки.
Служба распознавания форм обеспечивает оценку достоверности точности AI-OCR, которая рассчитывается с помощью собственного алгоритма Hitachi. Таким образом, риск неправильного ввода данных из-за того, что AI-OCR не может сканировать текст или неправильно его распознавать, может быть уменьшен путем применения правил проверки для конкретных задач (проверки таких вещей, как формат или количество цифр) к выходным данным OCR и связанным с ними оценка уверенности и принятие корректирующих мер. Это позволяет выявить случаи неправильного распознавания AI-OCR в рамках рабочей процедуры.
Это обеспечивает большую автоматизацию обработки форм, в то же время снижая риск неправильного ввода данных, например, позволяя OCR с высокой степенью достоверности работать автоматически без проверки, и только люди будут проверять экземпляры со средней или низкой оценкой . Бизнес-риск, связанный с вводом неверных данных, также можно дополнительно минимизировать, сравнивая данные OCR с данными из других систем и используя это для корректировки оценки достоверности.
Фиг.4 – Сервисный подход к использованию службы распознавания форм для повышения эффективности Служба распознавания форм является облачной, чтобы обеспечить масштабируемость в соответствии с индивидуальными требованиями, включая сезонную работу, когда наблюдается пик рабочей нагрузки, или работа с формами, которые обрабатываются в небольших объемах или во многих различных форматах.
(2) Сервисный подход
Служба распознавания форм также решает проблему приложений, в которых обычное распознавание текста возможно, но непрактично по соображениям рентабельности.На Рисунке 4 показан обзор.
- Использование в приложениях, которые обрабатывают небольшие объемы форм или много разных форматов.
В некоторых приложениях, где используются формы, подходящие для сканирования с помощью OCR, характер работы таков, что объем обрабатываемых форм невелик или их форматы сложны. Обычное распознавание текста в подобных случаях может оказаться непрактичным из соображений рентабельности, например, когда требуются специальные сканеры.
Поскольку служба распознавания форм является облачной, напротив, она не требует специальных сканеров и может использовать устройства, которые у компаний уже есть на месте.Услуга обеспечивает постоянное повышение точности распознавания и включает обучение выполнению. Более того, его можно установить и использовать с меньшими затратами, чем обычные локальные системы. Он также разработан для работы с широким кругом предприятий, не беспокоясь о формах или устройствах для конкретных задач. - Использование для сезонных задач с высокой краткосрочной нагрузкой
Существует множество случаев, когда формы, используемые в бизнесе, обрабатываются в основном в определенное время года.Рабочие нагрузки в это напряженное время могут быть во много раз или даже на порядок выше, чем в остальное время года.
Поскольку служба распознавания форм работает на платформе служб в облаке, ее можно масштабировать в соответствии с особыми требованиями, такими как периоды высокой рабочей нагрузки.
Заявление на ввод и проверку данных в Процессинговом центре
Фиг.5 – Пример приложения службы распознавания форм (повышение эффективности в процессинговом центре) Ввод данных формы в процессинговом центре выполняется персоналом вручную, а введенные данные визуально сверяются с исходной формой. Показатель достоверности, предоставляемый службой распознавания форм (высокий, средний или низкий), может использоваться для определения того, требуется или не требуется ввод данных вручную.
Обработка денежных переводов – одна из трех основных форм деятельности финансового учреждения. Это относится к осуществлению платежей или других перемещений денег с одного счета на другой без использования наличных денег и может принимать различные формы, такие как банковские переводы, денежные переводы или перемещение средств между счетами.Он включает в себя банковские отделения, которые принимают различные типы форм переводов от клиентов и передают их в процессинговый центр, где вводятся данные в форме и проверяется ввод данных. Поскольку эти центры обрабатывают такое большое количество форм, высокая рабочая нагрузка на персонал и трудности с наймом являются одними из проблем, с которыми они сталкиваются. Хотя они могут справиться с этим, делегируя обработку денежных переводов службам аутсорсинга бизнес-процессов, это не отменяет задачи ввода и проверки данных.
Служба распознавания форм предлагает способ выяснить, как обеспечить устойчивость бизнеса и сократить накладные расходы за счет снижения нагрузки на ввод и проверку данных в центрах обработки. На рис. 5 перечислены проблемы и преимущества внедрения службы распознавания форм.
Обработка форм – это то, что происходит не только в финансовых учреждениях, но и во многих отраслях, таких как обработка государственными органами заявок от населения или обработка грузовых перевозок различных форм, которые она создает каждый день.Целью службы распознавания форм является поддержка обработки форм в различных отраслях промышленности путем сканирования большого количества этих форм и оценки точности извлеченной информации.
Планы на будущее
Одно из приложений, где AI-OCR все еще испытывает трудности, – это чтение и анализ плохо отформатированных бизнес-документов, таких как контракты или каталоги продуктов (неструктурированные данные).
Необходимым условием для чтения форм свободного формата с использованием AI-OCR является то, что степень изменчивости формата аналогична, например, степени изменчивости поля общей суммы в счете-фактуре, где существует степень единообразия в том, где расположена эта информация. , хотя и с небольшими различиями между разными компаниями. Соответственно, этот вид формы иногда называют частично свободным форматом.
Термин неструктурированные данные используется для документов, в которых отсутствует структура, характерная для реляционной базы данных, без согласованности в том, где поля расположены относительно друг друга и где одно и то же поле может быть выражено по-разному от одного документа к другому, как есть дело во многих деловых документах.Примеры неструктурированных данных включают текст, изображения, видео и аудио.
Еще одно ключевое слово – «темные данные». Это относится к стоимости, скрытой в бизнес-документах, созданных в ходе корпоративной деятельности, и называется так потому, что примерно 80% сгенерированных данных никогда не используются повторно (5), (6) . Термин «темные данные» имеет широкое значение, охватывающее как структурированные, так и неструктурированные данные.
Один из примеров анализа темных данных может включать в себя желание извлечь итоговые суммы продаж из финансовых отчетов, составленных разными компаниями. Эта задача усложняется компаниями, использующими разные термины, такие как «выручка от строительства» или «общий объем продаж».Несмотря на эти различия в терминологии, эту информацию можно идентифицировать, генерируя общий объем продаж, финансовый период и другие значения характеристик из иерархических форматов (таблиц, столбцов и т. Д.), Используемых в этих финансовых отчетах.
Hitachi рассматривает возможность применения этой новой технологии к неструктурированным данным, которые в настоящее время трудно сканировать и анализировать.
Выводы
В этой статье описаны улучшения эффективности, обеспечиваемые службой распознавания форм на основе AI-OCR.Ожидается, что приложения для AI-OCR выйдут за рамки простого чтения текста и обеспечат дополнительную операционную эффективность за счет интеграции с RPA. В будущем Hitachi намерена и дальше стремиться к повышению эффективности, привнося инновации в рабочее место бизнеса с использованием таких технологий, как AI-OCR.
Всем, кто хочет узнать больше о службе распознавания форм, рекомендуется посетить японский веб-сайт Hitachi (7) .
ССЫЛКИ
- 1)
- Стратегическая штаб-квартира по продвижению общества передовых информационных и телекоммуникационных сетей, «Декларация о статусе самой продвинутой цифровой нации в мире: Базовый план по развитию использования данных в государственном и частном секторах», с изменениями (июн.2019) на японском языке
- 2)
- Fuji Chimera Research Institute, Inc. Пресс-релиз, «Резюме бизнес-исследования искусственного интеллекта 2019 г. (март 2019 г.)» (июнь 2019 г.) на японском языке
- 3)
- Компьютерный музей Общества обработки информации Японии (IPSJ), «OCR: Краткая история»,
- 4)
- Компьютерный музей IPSJ, «[Hitachi] H-8252 Optical Character Reader»,
- 5)
- Gartner, Inc., «Темные данные», .
- 6)
- IBM Big Data & Analytics Hub, «Познание и будущее маркетинга» (сентябрь 2016 г.)
- 7)
- Hitachi, Ltd., «Служба распознавания форм» на японском языке
Сравнение облачных решений для оптического распознавания символов (OCR) | Владислав Клековкин | Deelvin Machine Learning
Оптическое распознавание символов (OCR) – это механическое или электронное преобразование изображений рукописного, набранного или напечатанного текста в текстовые данные, используемые для представления символов на компьютере (например, в текстовом редакторе).
В этой статье мы сравниваем точность алгоритмов OCR, предлагаемых тремя облачными сервисами – Google Cloud Platform, Amazon Web Services, Microsoft Azure как наиболее популярными среди провайдеров OCR.
Облачная платформа – это набор служб и разрешений, предлагаемых разработчиками. Они предоставляют пользователям (частным пользователям и крупным компаниям) доступ к вычислительным ресурсам и аналитическим инструментам, а также хранилищам данных, серверам, программному обеспечению и т. Д.
В настоящее время наиболее популярными являются следующие услуги:
1. Amazon Web Services (AWS) была основана в 2006 году и в настоящее время предоставляет услуги IaaS, PaaS, SaaS и другие. Он также предлагает более 70 ресурсов с расширенным охватом в четырнадцати регионах мира.
2. Azure – продукт Microsoft, выпущенный в 2010 году. Сегодня платформа предлагает широкий спектр различных вспомогательных инструментов, языков программирования и фреймворков. Работает в Microsoft Windows и Linux. В настоящее время на платформе доступно около 60 сервисов и центров обработки данных в более чем 38 точках по всему миру.Среди клиентов Azure такие известные имена, как Johnson Controls, Fujifilm, HP, Apple, а также несколько других крупных компаний.
3. Google Cloud Platform – самая молодая облачная платформа среди этих трех. Он был запущен в 2011 году и предлагает множество услуг, включая IaaS, PaaS и Serverless, а также поддерживает большие данные и IoT. Провайдеры используют более 50 ресурсов и имеют в своем распоряжении 6 глобальных центров обработки данных.
Google Cloud
В нашем сравнении мы использовали Cloud Vision API.Полная информация о регистрации и использовании Cloud Vision API для OCR доступна здесь.
В этом и следующих примерах представлен код Python. Для обработки мы использовали картинку с локального компьютера. Переменная ответа содержит обнаруженный текст, координаты блока и метаинформацию.
Ниже приведен пример работы с Cloud Vision API:
import os
from google.cloud import visionos.environ [
"GOOGLE_APPLICATION_CREDENTIALS"] = "ВАШИ УЧЕТНЫЕ ДАННЫЕ"image_path = "PATH TO IMAGE"
клиент = видение.ImageAnnotatorClient ()
с open (image_path, 'br') как image_file:
content = image_file.read ()image = vision.Image (content = content)
response = client.text_detection (image = image)
Amazon Web Services
Amazon Rekognition используется для задачи распознавания текста. Более подробная информация об этом доступна здесь.
Пример ниже демонстрирует, как работать с Amazon Rekognition:
import boto3image_path = "ПУТЬ К ИЗОБРАЖЕНИЮ"
client = boto3.client ('rekognition')
с open (image_path, 'br') как image_file:
content = image_file.read ()response = client.detect_text (Image = {'Bytes': content})
Microsoft Azure
Мы будем использовать продукт Azure Cognitive Services и Computer Vision S1. Вы можете узнать больше об этой услуге здесь.
Функция resize () доводит изображение до минимально допустимого размера (50 пикселей по высоте и ширине). Функция get_image_file_object () создает файловый объект из изображения.Обе функции необходимы для правильной работы со службой компьютерного зрения.
Вот пример работы с Azure Cognitive Services:
время импорта
из PIL импорт изображения
из io import BytesIOиз azure.cognitiveservices.vision.computervision import ComputerVisionClient
из msrest.authentication import CognitiveServicesCredentials" ВАШ КЛЮЧ "
image_path =" ПУТЬ К ИЗОБРАЖЕНИЮ "
endpoint =" ВАША КОНЕЧНАЯ ТОЧКА "def resize (img):
_format = img.format
size = tuple (max (val, 50) для val в img.size)
img = img.resize (size)
img.format = _formatreturn img
def get_image_file_object (image_path):
byte_arr = BytesIO ()
img = Image.open (image_path)
img = resize (img)
img.save (byte_arr, img.format)
byte_arr.seek (0)return byte_arr
computervision_client = ComputerVisionClient ( CognitiveServicesCredentials (подписка_ключ))
mage = get_image_file_object (image_path)
job = computervision_client.read_in_stream (image = image, raw = True)operation_id = job.headers ['Operation-Location']. split ('/') [- 1]
image_analysis = computervision_client.get_read_result (operation_id)в то время как image_analysis.status in ['notStarted', 'running']:
time.sleep (1)
image_analysis = computervision_client.get_read_result (
operation_id = operation_id)response = image_analysis.as_dict ()
В нашем тестировании мы использовали следующее 3 набора данных, содержащих изображения и аннотации:
1. IIIT5K :
Набор данных IIIT5K состоит из 5000 изображений. На изображениях показаны отдельные слова, вырезанные из фотографий рекламных щитов, вывесок, номеров домов и постеров с фильмами.
Загрузить.
2. IC13 :
Набор данных IC13 содержит 1015 обрезанных изображений с текстом. Слова с не буквенно-цифровыми символами удаляются из набора.
Загрузить.
3. SVHN :
Набор данных SVHN состоит из 600 000 изображений номеров домов, снятых с помощью Google Street View.
Загрузить.
Streaming OCR с Google Vision API и OpenCV
Цели и Предварительные требования :К концу статьи вы узнаете, как:
- Применить OCR (объект Распознавание символов) с помощью Google Vision API.
- Примените API для потоковой передачи видео с веб-камеры.
Перед началом вам потребуется:
- Базовый опыт программирования на Python.
- Некоторое понимание техники компьютерного зрения на высоком уровне.
Сложность: начальный / средний
Итак, что такое Google Computer Vision API и почему я должен его использовать?Google выпустил API, который может очень точно извлекать информацию из изображений. В этом API есть много функций, но сегодня я хочу сосредоточиться на извлечении текста из изображений. Этот продукт настолько мощный, что может читать текст изображения с использованием разных шрифтов, языков и даже ориентации (боком, вверх ногами).По этой причине он лучше любого ПО с открытым исходным кодом, которое я пробовал.
Какие есть приложения? Это может быть невероятно полезно для:
- Вытягивание значимого текста из отсканированных документов вместо его расшифровки вручную.
- Извлечение информации из стопки визитных карточек вместо ручного ввода данных в базу данных.
- Получите полезную информацию с рекламного щита.
По сути, с помощью этого API можно автоматизировать многие утомительные задачи, и его можно применять в широком спектре контекстов.Дополнительным преимуществом является то, что стоимость его использования относительно невысока. За этим продуктом стоят годы исследований и испытаний Google, так зачем изобретать велосипед?
Вы можете попробовать это здесь: https://cloud.google.com/vision/
Есть много способов использовать этот API, но сегодня я собираюсь показать вам, как запустить оба API Google Vision. и возможность потоковой передачи в реальном времени с OpenCV, фантастическим пакетом Python для обработки изображений. Код будет обращаться к вашей веб-камере, позволяя вам махать различными объектами с текстом, такими как обертка шоколадного батончика, квитанция или даже слова на футболке.В вашем терминале командной строки он будет показывать текст, который появляется в изображениях, покадрово.
Прежде, чем мы приступим к работе- Вам нужно будет выполнить несколько предварительных установок:
- «Pip install» следующих пакетов:
- opencv-python – импортировано как cv2 в код Python
- google- cloud-vision
- Pillow – импортировано как PIL
- «Pip install» следующих пакетов:
- Вам также потребуется зарегистрироваться в облачной платформе Google:
1. Vision API Setup:
Сначала перейдите на вкладку API и службы и щелкните учетные данные. Нажмите кнопку «Создать учетные данные» и выберите «Ключ учетной записи службы». Для роли выберите «Владелец» и «Полный доступ ко всем ресурсам». После настройки вы можете загрузить свой ключ API в виде файла JSON. Я решил, что лучше всего хранить ключ API и код Python в одном каталоге. Наконец, вы хотите зайти в панель поиска и найти Vision API. Как только вы его найдете, нажмите кнопку «Включить».2. Код Vision API: Этот код основан на исходном коде из руководства Vision API, которое я немного изменил.
# export GOOGLE_APPLICATION_CREDENTIALS = kyourcredentials.json import io импорт cv2 из PIL импорта изображения # Импортирует клиентскую библиотеку Google Cloud из google.cloud импортировать видение из типов импорта google.cloud.vision # Создает экземпляр клиента client = vision.ImageAnnotatorClient () def detect_text (путь): "" "Обнаруживает текст в файле." "" с io.open (путь, 'rb') как файл_образа: content = image_file.read () image = types.Image (content = content) response = client.text_detection (изображение = изображение) тексты = response.text_annotations строка = '' для текста в текстах: строка + = '' + текст.описание строка возврата
3. Код OpenCV: Этот код основан на коде OpenCV Stream.
cap = cv2.VideoCapture (0)
в то время как (Истина):
# Захватить покадрово
ret, frame = cap.читать()
file = 'live.png'
cv2.imwrite (файл, фрейм)
# распечатать текст OCR
print (detect_text (файл))
# Отобразить получившийся фрейм
cv2.imshow ('рамка', рамка)
# Когда все будет сделано, отпустите захват
cap.release ()
cv2.destroyAllWindows () - Важно отметить, что функция cv2.VideoCapture () имеет вход 0, который активирует веб-камеру. Вход обычно представляет собой ссылку на статическое видео или прямую трансляцию видео.
- Теперь вы можете сохранить всю часть кода в формате.py и дайте ему любое имя.
4. Код в действии: Теперь откройте терминал, в котором вы сохранили свой код и ключ API, и запустите следующий код.
экспорт GOOGLE_APPLICATION_CREDENTIALS = yourAPIkey.json сначала в командной строке
- Затем сразу же после этого запустите файл Python (YOUROCRFILE.py) в командной строке.
Как видите, исходная функция detect_text () ранее была встроена в цикл while.