
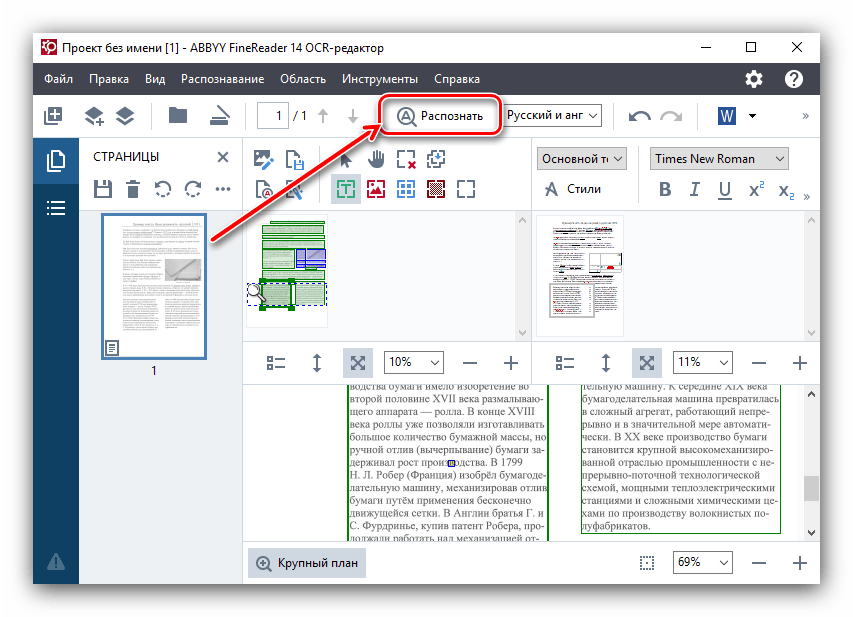
3 варианта использования, которые извлекают текст из программного обеспечения для обработки изображений
Ашутош Сайтвал
28 октября 2022 г.(Последнее обновление: 28 октября 2022 г.)
McKinsey прогнозирует, что автоматизация данных будет выполнять 10-25% бизнес-процессов банка в течение следующих нескольких лет. Это увеличит возможности финансовых институтов. Это также позволит банковским служащим сосредоточиться на более сложных задачах.
Банковские учреждения потребуют комплексного решения проблем и творческого подхода. Извлечение текста из программного обеспечения для изображений будет в его основе.
Сегодня сфера применения OCR в финансовой отрасли, автоматизация данных, касается не только страховых онлайн-платежей или автоматизации счетов. Вместо этого он помогает использовать искусственный интеллект для принятия обоснованных решений. Такие платформы, как KlearStack, обрабатывают обширные данные и обеспечивают пятизвездочную поддержку клиентов, а также доставляют персонализированные уведомления.
McKinsey также считает, что от 75 до 80 процентов транзакционных операций, таких как общие бухгалтерские операции и обработка платежей, могут быть автоматизированы. Вдобавок к этому можно автоматизировать до 40% дополнительных стратегических операций, таких как финансовый контроль и отчетность, анализ, казначейство и финансовое планирование.
Переходя к нашей теме обсуждения в этом блоге, давайте разберемся, что такое OCR. Кроме того, мы рассмотрим варианты использования в бизнесе, а также преимущества.
«OCR» означает оптическое распознавание символов, широко известное как «распознавание текста», популярный метод извлечения текста из изображений. Программа OCR — это инструмент, который извлекает и повторно использует данные из отсканированных документов, изображений с камеры, а также PDF-файлов, содержащих только изображения.
Программное обеспечение OCR использует комбинацию аппаратных средств, таких как оптические сканеры, и программного обеспечения, способного обрабатывать изображения. Для извлечения текста инструменты OCR используют несколько машинных алгоритмов для распознавания образов, чтобы определить наличие и расположение текста в файле изображения.
Для извлечения текста инструменты OCR используют несколько машинных алгоритмов для распознавания образов, чтобы определить наличие и расположение текста в файле изображения.
Эти инструменты специально обучены определять форму символов или цифр на изображении для распознавания текста. Они могут реконструировать извлеченный текст в машиночитаемом формате, благодаря чему извлеченный текст можно выделить, отредактировать или скопировать и вставить, как обычный текст. Проще говоря, OCR преобразует цифровые данные в формате изображения в редактируемые текстовые документы. Несколько программ и инструментов, работающих в автономном режиме и онлайн, позволяют технологии OCR извлекать текст из изображений, и KlearStack является одним из них!
Основное преимущество технологии OCR заключается в том, что она автоматизирует ручные и трудоемкие задачи ввода данных.
С помощью OCR можно создавать цифровые документы, которые можно редактировать и сохранять в соответствии с требованиями.
Инструмент OCR обрабатывает изображения для идентификации текста и создает скрытый слой текста за изображением. Компьютер может легко прочитать этот дополнительный слой, что делает изображение узнаваемым и доступным для поиска. Это имеет решающее значение для таких отраслей, как банковское дело и страхование, поскольку им приходится ежедневно иметь дело со средствами массовой информации и документами. Вот некоторые важные преимущества оптического распознавания символов и понимания естественного языка для автоматизации извлечения значений из изображений:
- Более быстрая автоматизированная обработка и преобразование бумажных документов в цифровые форматы, что ускоряет рабочие процессы
- Экономит время и уменьшает количество ручных ошибок
- Ограничивает необходимость ручного ввода данных
- Сокращает ввод данных вручную, что указывает на снижение общих затрат для бизнеса
- Экономит бумагу и место для хранения, поскольку больше данных можно преобразовать в электронный формат
Типичным примером использования оптического распознавания символов и понимания естественного языка для извлечения текста из программного обеспечения для работы с изображениями, такого как KlearStack, является обработка форм заявления о медицинском страховании.
Благодаря извлечению текста из изображения программное обеспечение упрощает сравнение страхового возмещения с данными страхователя. Системы, оснащенные OCR, могут помечать любые аномалии в данных соответствующим отделам и предотвращать возможное мошенничество.
Содержание
Теперь давайте рассмотрим варианты использования в бизнесе и преимущества использования понимания естественного языка и оптического распознавания символов (OCR) для автоматизации извлечения текста из графического программного обеспечения:
1. Автоматизация расчетов с поставщиками:
Автоматизация расчетов с поставщиками с помощью естественного языка и оптического распознавания символов для извлечения текста из графического программного обеспечения позволяет настраивать бизнес-правила. Это обеспечивает отслеживание счетов с минимальным выходом и высокой точностью за меньшее время! Он предоставляет доступ к контрольным журналам и служит центральной точкой входа для всех счетов, касающихся отдела кредиторской задолженности.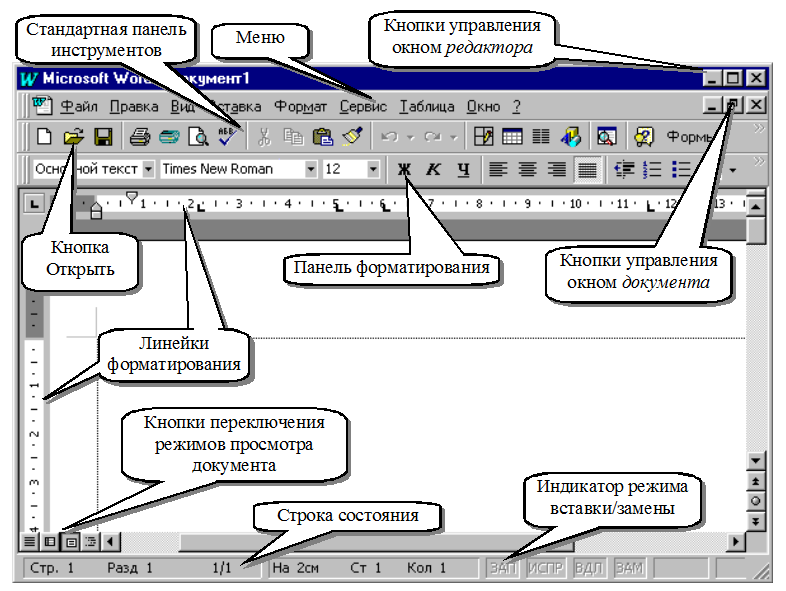
2. Извлечение текста из заявления о госпитализации:
Медицинские документы и карты пациентов, возможно, являются наиболее важными документами, касающимися страхового сектора. Благодаря расширенным функциональным возможностям программного обеспечения, такого как KlearStack, организации здравоохранения могут быть полностью уверены в безопасности извлечения текста.
Кроме того, ручная обработка и копирование — трудоемкие процессы, на которые уходит бесчисленное количество ценных рабочих часов. KlearStack может сократить или даже исключить ручной ввод данных, что сэкономит страховым компаниям много денег. Это помогает многим страховым компаниям высвободить ресурсы для выполнения когнитивных задач.
3. Обработка мандатов NACH: Для транзакций ECS в банках:
Финансовые учреждения используют ECS для списания ежемесячных EMI по кредитам с банковского счета заемщика. Национальная автоматизированная клиринговая палата NACH обрабатывает все процессы дебетования транзакций ECS.
Операции ECS в соответствии с мандатами NACH требуют соблюдения нескольких документов.
Здесь использование программного обеспечения для извлечения текста из изображений помогает быстро заполнить детали с меньшим количеством ошибок.
Вывод: Таким образом, с KlearStack клиенты будут уверены в лучших финансовых возможностях и продуктах. И это творческое решение проблем и разработка новых продуктов и услуг улучшают качество обслуживания клиентов. Другими словами, банки будут выглядеть и чувствовать себя гораздо больше как технологические компании с этим извлеченным текстом из программного обеспечения для изображений.
С помощью KlearStack вы можете извлекать текст из программного обеспечения для работы с изображениями в различных форматах. Это применимо к квитанциям, юридическим документам и многому другому с точностью «человеческого уровня».
Автоматизируйте ручную обработку документов и сократите расходы на 70% с повышением производительности более чем на 200%

Извлечение текста
Ашутош Сайтвал
www.klearstack.com/
Ашутош является основателем и директором отмеченной наградами платформы искусственного интеллекта KlearStack. Вы можете увидеть его выступление на мероприятиях NASSCOM по всему миру, где он выступает и является евангелистом RPA, ИИ, машинного обучения и интеллектуальной обработки документов.
Извлечение текста из изображения — SimpleOCR
Перейти к содержимомуПоиск:
Извлечение текста из файлов изображений с помощью оптического распознавания символов (OCR) и преобразование его в любой формат файла или базу данных SQL. Программное обеспечение OCR для проекта любого размера или бюджета.
Программное обеспечение Modern Forms Processing может использовать основанные на правилах шаблоны для поиска данных в документах на основе ключевых слов меток, типов данных, сопоставления шаблонов регулярных выражений и других методов.
Наиболее распространенным примером в бизнесе является счет-фактура.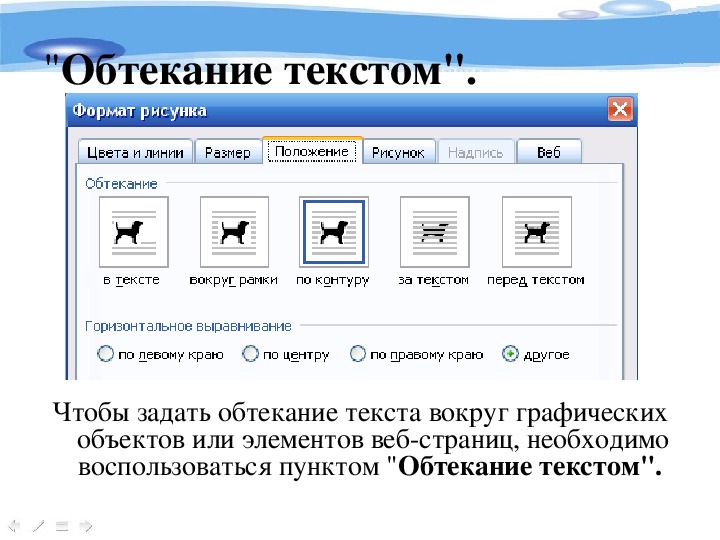 Предприятия получают счета от тысяч разных поставщиков, каждый из которых содержит важную информацию, такую как номер счета, срок оплаты и общую сумму, необходимую для обработки документа, но каждый счет поставщика форматируется немного иначе, чем другие.
Предприятия получают счета от тысяч разных поставщиков, каждый из которых содержит важную информацию, такую как номер счета, срок оплаты и общую сумму, необходимую для обработки документа, но каждый счет поставщика форматируется немного иначе, чем другие.
Программное обеспечение, такое как ABBYY FlexiCapture, будет искать ключевые слова, такие как «Номер счета-фактуры» или варианты, такие как «Номер счета-фактуры» и «Номер счета-фактуры». чтобы найти значение номера счета-фактуры в каждом счете-фактуре.
Эти приложения также могут собирать сложные табличные данные и выводить их в такие форматы, как Excel или базу данных SQL, особенно когда они не выстраиваются в обычные столбцы.
В последние годы обучение на основе искусственного интеллекта позволило просто указать и щелкнуть местоположение данных в документах по мере их обработки и автоматически создать эти шаблоны, что значительно снижает потребность в постоянной экспертной помощи, необходимой этим системам.
Приложения Modern Forms Processing имеют обучающие алгоритмы на основе ИИ, которые позволяют пользователям указывать и нажимать на расположение данных в своих документах и автоматически создавать шаблоны OCR.
Это позволяет обойти технические требования по созданию сложных шаблонов OCR, особенно для различных документов, таких как счета-фактуры, где данные не всегда отображаются в одном и том же месте.
Но насколько хороши эти обучающие системы на основе ИИ?
По нашему опыту, они работают хорошо, когда у вас есть:
- Отсканированные изображения хорошего качества
- Четко размеченные данные
- Таблицы с обычными столбцами Изображения низкого качества
- Данные, которые появляются в абзацах
- Таблицы с перекрывающимися столбцами, строками промежуточных итогов и т. д.
Эти типы документов по-прежнему могут быть захвачены с помощью OCR, но для них обычно требуется опытный специалист для ручной настройки шаблона.
Для данных на естественном языке, таких как юридические документы, доступна новая технология искусственного интеллекта под названием NLP (обработка естественного языка). Они работают, пытаясь «понять» язык, используемый в документах, чтобы интерпретировать расположение точек данных на основе значения. ABBYY FlexiCapture также поддерживает обучение этим типам документов на основе НЛП.
Данные, которые повторяются в документе снова и снова, могут быть распознаны в Microsoft Excel, Google Sheets и других форматах электронных таблиц или в базе данных SQL, такой как Access, SQL Server, MySQL и Oracle.
Недорогие продукты OCR для настольных ПК, такие как FineReader, ReadIRIS и OmniPage, могут автоматически преобразовывать данные из таблиц в Excel и другие электронные таблицы, если столбцы являются стандартными и не «перекрываются», так что разные значения полей появляются в одной и той же области столбца, например, когда одна строка каждой записи представляет один набор столбцов, а вторая строка содержит дополнительные данные столбца.
Преобразованные данные потребуют некоторой очистки, прежде чем их можно будет использовать в какой-либо базе данных или программном приложении, и таким способом трудно преобразовать большое количество документов в пакетном режиме. Но это хороший способ получения структурированных данных из больших отдельных отчетов или небольших пакетов аналогичных данных отчетов.
Для более сложных таблиц, таблиц с похожими данными, но в разных форматах в разных документах (например, счетов-фактур), таблиц с вложенной структурой, такой как строки заголовков и сведений, требуется программное обеспечение для обработки корпоративных форм, чтобы преобразовать эти документы в структурированные данные, такие как XML, JSON или Таблицы базы данных SQL.
Цены на программное обеспечение для оптического распознавания символов варьируются от бесплатных до десятков тысяч долларов. Чем объясняется разница между этими приложениями? Вот разбивка:
- Бесплатное ПО OCR использует механизмы SimpleOCR или Tesseract и обеспечивает ограниченные возможности сканирования и форматирования вывода.
 Качество распознавания, как правило, низкое, за исключением изображений документов самого высокого качества.
Качество распознавания, как правило, низкое, за исключением изображений документов самого высокого качества. - Преобразователи PDF OCR обеспечивают высококачественные механизмы OCR, такие как ABBYY, IRIS и OmniPage, но ограничивают вывод доступными для поиска PDF-файлами. Они стоят менее 100 долларов.
- Стандартные приложения оптического распознавания символов стоят от 100 до 200 долларов США и обеспечивают все возможности оптического распознавания символов, включая преобразование отсканированных изображений в Word, Excel, HTML и другие редактируемые форматы.
- Корпоративные приложения OCR добавляют дополнительные функции, такие как автоматическая обработка горячих папок, параллельное лицензирование и другие функции, полезные для бизнес-приложений. Цена на них 200-500$.
- Серверы OCR предоставляют масштабируемые корпоративные службы OCR для обработки очень больших объемов документов или предоставления возможностей OCR пользователям во всей организации.
 Цены начинаются примерно с 1500 долларов и растут в зависимости от объема обработки.
Цены начинаются примерно с 1500 долларов и растут в зависимости от объема обработки. - Приложения для сбора корпоративных данных и обработки форм используются для сбора структурированных данных из сложных документов, таких как формы заявлений на медицинское обслуживание и счета-фактуры, которые включают такие элементы, как таблицы, рукописный ввод, флажки и подвижные зоны. Эти решения могут стоить от 1000 до сотен тысяч долларов в зависимости от объема документов и сложности проекта.
aaron2021-01-24T18:39:02-05:00Теги: Автоматизация кредиторской задолженности, Распознавание кредиторской задолженности, Сканирование счетов AP, Автоматический ввод данных, Распознавание штрих-кода, Пакетное распознавание текста, Пакетное распознавание текста PDF, Лучшее программное обеспечение для распознавания рукописного ввода, Преобразование Изображения в PDF с возможностью поиска, Преобразование изображений в Word, Преобразование PDF в редактируемый Word, Преобразование PDF в Excel, Преобразование PDF в HTML, Преобразование PDF в текст, Преобразование изображения в текст, Сбор данных, Извлечение данных, Управление документами, Программное обеспечение для обработки документов, Извлечение Текст из изображения, обработка форм, распознавание отпечатков рук, ICR, распознавание изображений, программное обеспечение для автоматизации счетов, захват счетов, отображение счетов, OCR счетов, распознавание счетов, программное обеспечение для сканирования счетов, программное обеспечение рабочего процесса счетов, точность OCR, распознавание символов OCR, обработка счетов OCR, OCR PDF, сканер OCR, оптическое распознавание символов, извлечение данных PDF, OCR PDF, сканирование счета-фактуры, OCR сервера, простое программное обеспечение счета-фактуры, распознавание текста |
Подробнее
Как обучить модель машинного обучения NLP
Сегодня разные отрасли сталкиваются с одинаковыми проблемами, пытаясь извлечь информацию из деловых документов, таких как политики, электронные письма и юридические соглашения, и большинство согласны с тем, что это дорого, требует много времени и чревато ошибками при ручном вводе данных.
В этом видео вы узнаете, как обучить модель машинного обучения NLP в FlexiCapture для извлечения сущностей и текстовых фрагментов из договоров аренды.
Преобразование неструктурированных документов в структурированные данные автоматически делает эту информацию доступной для ваших бизнес-приложений, экономя при этом ваше время, деньги и трудозатраты.
Добавление поля, полученного с помощью гибкого макета, в определение документа, обученного NLP
Вы можете добавить новый гибкий макет в качестве дополнительного макета к существующему.
Для этого откройте редактор определения документа, перейдите в свойства раздела и загрузите новый макет как дополнительный FlexiLayout.
FlexiLayout: как захватить таблицу с помощью повторяющейся группы, если заголовок таблицы находится на каждой странице Таблица элемент. В таких случаях мы обычно используем элемент Repeating Group .
В таких случаях мы обычно используем элемент Repeating Group .
Но что, если мы столкнемся с многостраничным документом, на каждой странице которого есть заголовок таблицы?
Мы можем использовать два следующих метода для захвата такой таблицы с помощью повторяющихся групп.
Использование абсолютных ограничений области поиска
Чтобы ограничить область поиска областью таблицы, чтобы она не захватила ненужный текст за пределами таблицы, мы можем использовать Абсолютные ограничения области поиска на вкладке Ограничения поиска .
Вы можете измерить площадь с помощью инструмента Измерить прямоугольник .
Использование вложенных повторяющихся групп
Иногда использование0079 Абсолютные ограничения области поиска метод, потому что другие таблицы, использующие этот макет, могут иметь другое положение и длину элементов, что делает использование метода неудобным, потому что вам придется каждый раз заново измерять площадь.
В таком случае вы можете использовать метод вложенной повторяющейся группы .
- Создайте первую, «основную» повторяющуюся группу, которая будет включать в себя верхний и нижний колонтитулы таблицы.
- Затем создайте вложенный RG в первом RG. Соотношения следующие:
- Это основные шаги, остальные элементы в RG не требуют особых настроек и должны проектироваться в соответствии с требуемыми результатами.
Дополнительная информация
FlexiLayout: захват таблицы с помощью повторяющейся группы элементы, основанные на абсолютных смещениях, могут пропустить […]
How to create a PDF from Microsoft® Word, Excel, or PowerPoint
How to convert emails to PDF
How to Split a PDF
Create FineReader PDF 15 легко объединяет новые PDF-документы или отдельные PDF-документы в один.
Узнайте, как легко разбивать PDF-файлы и извлекать страницы.
Как создавать и редактировать интерактивные PDF-формы
Посмотрите это видео и узнайте, как быстро и легко редактировать и создавать интерактивные формы PDF.
Редактор форм в FineReader PDF 15 позволяет создавать и редактировать заполняемые PDF-формы с текстовыми полями и полями даты, выпадающими списками, списками, флажками, переключателями, полями подписи и кнопками действий. Собирайте информацию и создавайте эффективные шаблоны документов с легкостью!
Как извлечь текст из отсканированных PDF-файлов
Как извлечь таблицы
Как проверить, действительна ли цифровая подпись?
Если вы откроете документ с действующей цифровой подписью в FineReader, вы увидите зеленое уведомление Valid на левой панели ABBYY FineReader PDF 15:
документ с существующим текстовым слоем Распознавание в FineReader PDF 15
- Открыть FineReader PDF 15;
- Перейдите к Инструменты > Параметры > OCR ;
- В режиме распознавания PDF выберите Используйте параметр OCR :
- Нажмите OK ;
- Распознайте документ еще раз.

Как преобразовать документ в доступный PDF/UA
Сделайте ваши смешанные документы — PDF, отсканированные, сфотографированные или бумажные — цифровыми и доступными.
В этом […]
Екатерина2022-06-21T13:05:31-04:00Теги: Автоматический ввод данных, Пакетное распознавание текста, Пакетное распознавание текста PDF, Преобразование изображений в PDF с возможностью поиска, Преобразование изображений в Word, Преобразование PDF в редактируемое слово , Преобразование PDF в Excel, Преобразование PDF в HTML, Преобразование PDF в текст, Преобразование изображения в текст, Сбор данных, Извлечение данных, Управление документами, Программное обеспечение для обработки документов, Извлечение текста из изображения, Обработка форм, ICR, Распознавание изображений, Knoxville TN OCR Решения, OCR PDF, извлечение данных PDF, PDF OCR, извлечение текста PDF, конвертер PDF в TXT, OCR сервера, распознавание текста |
Подробнее
aaron2022-06-21T10:50:47-04:00Теги: Пакетное распознавание текста, Пакетное распознавание текста в формате PDF, Программное обеспечение для пакетного распознавания текста, Лучшая загрузка для распознавания текста, Лучшее программное обеспечение для распознавания текста, Лучшее программное обеспечение для распознавания рукописного текста, Лучшее программное обеспечение для оптического распознавания символов , Лучшее программное обеспечение для создания форм, Сравнение программного обеспечения OCR, Преобразование изображений в PDF с возможностью поиска, Преобразование изображений в Word, Преобразование PDF в редактируемое слово, Преобразование PDF в Excel, Преобразование PDF в HTML, Преобразование PDF в текст, Преобразование изображения в текст, Excel OCR , Извлечение текста из изображения, Распознавание изображений, OCR PDF, OCR в Excel, Оптическое распознавание символов, Преобразователи PDF, Извлечение данных PDF, OCR PDF, Извлечение текста PDF, Преобразование PDF в TXT, Сканирование в Excel |
Подробнее
Основная цель оптического распознавания символов — быстрое и автоматическое преобразование отсканированных изображений машинопечатного (набранного) текста, которые для компьютера представляют собой набор пикселей не более, чем любое другое изображение, например пейзажную фотографию — в фактические текстовые данные, которые вы можете искать и изменять.

Программное обеспечение OCR бывает разных типов, которые различаются по цене в зависимости от их функций, скорости и точности. Одним из основных качеств, которые производители OCR используют для дифференциации своей продукции, является объем документов, которые OCR позволит вам обработать. Это может быть немного нелогично, но функции, необходимые для обработки сотен, тысяч или миллионов страниц в год, довольно разные.
В случае нескольких сотен страниц (квитанции, чеки, медицинские, налоговые или юридические формы, личные памятные вещи) вам необходимо отсканировать для личного использования, вам понадобится легкое, универсальное, простое в использовании, недорогое программное обеспечение, которое будет конвертировать изображения просто в смс. В нем может не быть функций автоматизации, и дальнейшая обработка данных будет осуществляться вами вручную. Это не так сложно, так как объем документов не очень большой и вы можете работать с каждым из них в отдельности.
Пользователи малого бизнеса обычно обрабатывают тысячи страниц в год и нуждаются в некоторых функциях автоматизации.
 Изображения необходимо преобразовать не только в текст, но и в электронные таблицы для дальнейшей обработки. После настройки системы предполагается, что она будет работать без особых помех, и люди, отвечающие за обработку документов, смогут сделать это с определенной легкостью.
Изображения необходимо преобразовать не только в текст, но и в электронные таблицы для дальнейшей обработки. После настройки системы предполагается, что она будет работать без особых помех, и люди, отвечающие за обработку документов, смогут сделать это с определенной легкостью.Более крупным компаниям, обрабатывающим миллионы документов, требуется гораздо более высокий уровень автоматизации, когда каждая небольшая, точно настроенная функция может сэкономить тысячи рабочих часов в долгосрочной перспективе. Несколько машин будут обрабатывать документы […]
aaron2022-06-24T14:11:28-04:00Теги: Пакетное распознавание текста, Пакетное распознавание текста PDF, Пакетное распознавание текста, Преобразование изображений в PDF с возможностью поиска, Преобразование изображений в Word, Преобразование PDF в редактируемое слово, преобразование PDF в Excel, преобразование PDF в HTML, преобразование PDF в текст, преобразование изображения в текст, управление документами, программное обеспечение для обработки документов, распознавание текста в Excel, извлечение текста из изображения, распознавание PDF, сканирование OCR, распознавание текста, распознавание текста в Excel, конвертеры PDF, извлечение данных из PDF, распознавание текста в PDF, извлечение текста из PDF, конвертер PDF в TXT, сканирование в Excel, распознавание текста |
Подробнее
Два способа преобразования изображения в ExcelДанные решают все.
 Неважно, в какой сфере работает ваша компания, ведь все будет перегоняться в цифры данных и накапливаться в базе данных для обработки, хранения, перепрофилирования и пересборки снова, снова и снова. У всех организаций есть база данных, которая служит хранилищем всей их информации. И вы можете выжить с ручным вводом данных или использованием электронных таблиц или просто папок с документами в течение некоторого времени, но в конечном итоге просто огромное количество данных станет непосильным.
Неважно, в какой сфере работает ваша компания, ведь все будет перегоняться в цифры данных и накапливаться в базе данных для обработки, хранения, перепрофилирования и пересборки снова, снова и снова. У всех организаций есть база данных, которая служит хранилищем всей их информации. И вы можете выжить с ручным вводом данных или использованием электронных таблиц или просто папок с документами в течение некоторого времени, но в конечном итоге просто огромное количество данных станет непосильным.К счастью, для вашей базы данных есть множество решений. Вы можете выбирать между решениями SQL (MySQL, Access, Postgres, …) или NoSQL (Mongo, AWS, …) для хранения и обработки данных, но всегда будет проблема того, как необработанные цифры превращаются из изображений или текстов в более структурированные. форме вашей базы данных. Идентификация и передача всех этих данных может оказаться непростой задачей. Неправильное прочтение данных или несоответствие данных полям может легко повредить вашу систему обработки данных.
 Таким образом, точность распознавания символов данных становится существенной.
Таким образом, точность распознавания символов данных становится существенной.Одно из решений — разделить эти процессы сканирования и передачи данных. Вы можете использовать одно программное обеспечение для распознавания символов и переноса данных из изображения в PDF или текстовый документ. А затем использовать конвертеры PDF (или текста) в базу данных, чтобы извлечь эти данные в формат вашей базы данных. Очень очевидным недостатком этого подхода является то, что он добавляет целый дополнительный шаг к обработке ваших данных. Вы начнете накапливать дополнительные ошибки, добавите время на настройку дополнительной конвертации, добавите время на обработку данных и добавите время на неизбежное выявление ошибок и исправление ошибок. Это может работать для небольших компаний, но на уровне крупного предприятия становится непомерно дорогим.
Другим решением является прямой подход OCR к базе данных. […]
Nikita2022-06-21T12:22:43-04:00Теги: Автоматизация ввода данных, Пакетное распознавание текста, Пакетное распознавание текста, Преобразование PDF в Excel, Сбор данных, Извлечение данных, Электронный ввод данных, Excel OCR, Извлечение текста из изображения, решения Knoxville TN OCR, программное обеспечение OCR Form, библиотека OCR, решение OCR, таблицы OCR, OCR в Excel, извлечение данных PDF, сканирование в Excel, серверное распознавание, извлечение таблиц, зональное распознавание, зональное распознавание |
Подробнее
Специалисты по распознаванию символов для любого проекта Наша уникальная команда специалистов по распознаванию текста готова помочь с проектами по распознаванию текста любого размера и сложности. У нас есть специалисты по поддержке, которые могут удаленно настроить настольные решения за считанные минуты, и опытные системные интеграторы с многолетним опытом программирования, проектирования баз данных и автоматизации роботизированных процессов.
У нас есть специалисты по поддержке, которые могут удаленно настроить настольные решения за считанные минуты, и опытные системные интеграторы с многолетним опытом программирования, проектирования баз данных и автоматизации роботизированных процессов.
Воспользуйтесь нашим интернет-магазином, чтобы заказать приложения OCR для настольных компьютеров, и наши сотрудники будут рады ответить на ваши вопросы по настройке по электронной почте или в веб-чате.
Услуги удаленной настройки и обучения с использованием GotoMeeting доступны по низкой почасовой ставке.
Позвольте нам OCR, который для васВы сделали разовое преобразование и не хотите возиться с программным обеспечением? Загрузите отсканированный документ к нам, и мы отправим обратно преобразованные файлы. Дополнительная служба проверки исправляет ошибки распознавания и проблемы с макетом за низкую почасовую ставку.
Обработка данных для форм, отчетов, справочников и других документов также доступна с выводом в CSV, Excel, XML, JSON, SQL и т.