Как извлечь текст из изображения с помощью OneNote
OneNote описывает, как вы можете использовать приложение Office для создания, редактирования и сохранения заметок. В дополнение к этому, хранитель примечаний может использоваться для вставки почти любого типа контента, включая таблицу, картинку, ссылку, распечатку файла, видеоклип, аудиозапись и т. Д.
Приложение, если вы не знаете, поддерживает оптический символ Распознавание (OCR), инструмент, который позволяет копировать текст с изображения или распечатки файла и вставлять его в ваши заметки. Это удобно, особенно если вам нужно скопировать информацию с визитной карточки, которую вы сканировали в OneNote. После того, как вы извлекли текст, вы можете вставить его где-то еще в OneNote. Рассмотрим другой пример.
Предположим, вы хотите оцифровать статью в журнале. Если вы не обладаете хорошими знаниями об OCR, вы можете потратить десятки часов на повторный набор, а затем исправить опечатки. Или лучше всего, вы могли бы просто преобразовать все необходимые материалы в цифровой формат через несколько минут, используя программное обеспечение для сканирования и оптического распознавания символов.
Оптическое распознавание символов или OCR – это технология, которая позволяет конвертировать различные типы документов, таких как отсканированные бумажные документы, файлы PDF или изображения, снятые цифровой камерой, в редактируемые и доступные для поиска данные. Давайте посмотрим, как это работает в OneNote 2016/2013.
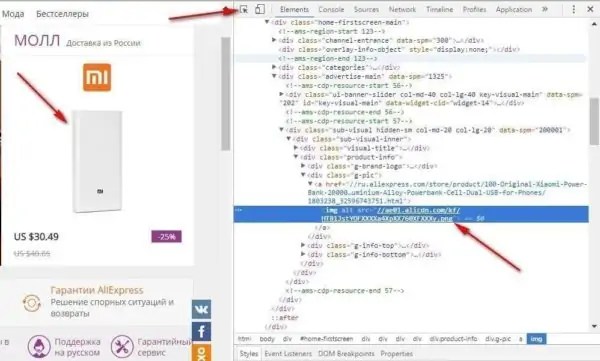
Вы можете скопировать текст из распечатки и вставить его в виде простого текста в OneNote. Чтобы извлечь текст из одного изображения, добавленного в OneNote, щелкните изображение правой кнопкой мыши и нажмите Копировать текст из изображения
Нажмите, где вы хотите вставить скопированный текст, а затем нажмите Ctrl + V.
Чтобы извлечь текст из изображений многостраничного файла (PDF), просто откройте свой pdf-файл, щелкните правой кнопкой мыши кнопку мыши и выберите опцию «Печать».
Далее, под окном, отображаемым на экране вашего компьютера, выберите «Отправить его для печати в OneNote 2013».
Выберите местоположение для файла.
Файл запустит процесс для преобразования и отправки в OneNote.
После преобразования OneNote откроется и покажет вам файл PDF. Щелкните правой кнопкой мыши на нем и выберите «Копировать текст из страниц распечатки».
Теперь вы можете вставить его там, где хотите.
В большинстве случаев можно скопировать текст, в значительной степени без ошибок распечатка с использованием встроенной функции распознавания текста в OneNote. Некоторые шрифты могут представлять проблемы, особенно шрифты с засечками, а так называемые «гротескные шрифты» – шрифты без засечек – например, Arial и Verdana, обычно не создают проблем.
Кроме того, текст копируется точно так, как он появляется. Поэтому, если текст находится в столбцах, вы получите много коротких строк. тем не менее, это можно скорректировать относительно быстро, удалив прерывание строки после каждой строки вручную.
Перейдите сюда для получения дополнительных советов и советов Microsoft OneNote 2013. Вы также можете посмотреть эти сообщения:
Вы также можете посмотреть эти сообщения:
- SkyDrive обеспечивает поддержку OCR; теперь может извлекать текст из изображений
- Как копировать или извлекать текст из изображений
- Freeware для извлечения изображений из файлов PDF
- Копировать текст из открытых окон с помощью GetWindowText
- Копировать коды ошибок и сообщения из диалоговых окон в Windows 8 | 7.
Как извлечь текст из изображения с помощью OneNote
Приложение, если вы не знаете, поддерживает Оптическое распознавание символов (OCR), инструмент, который позволяет копировать текст из распечатки изображения или файла и вставлять его в заметки.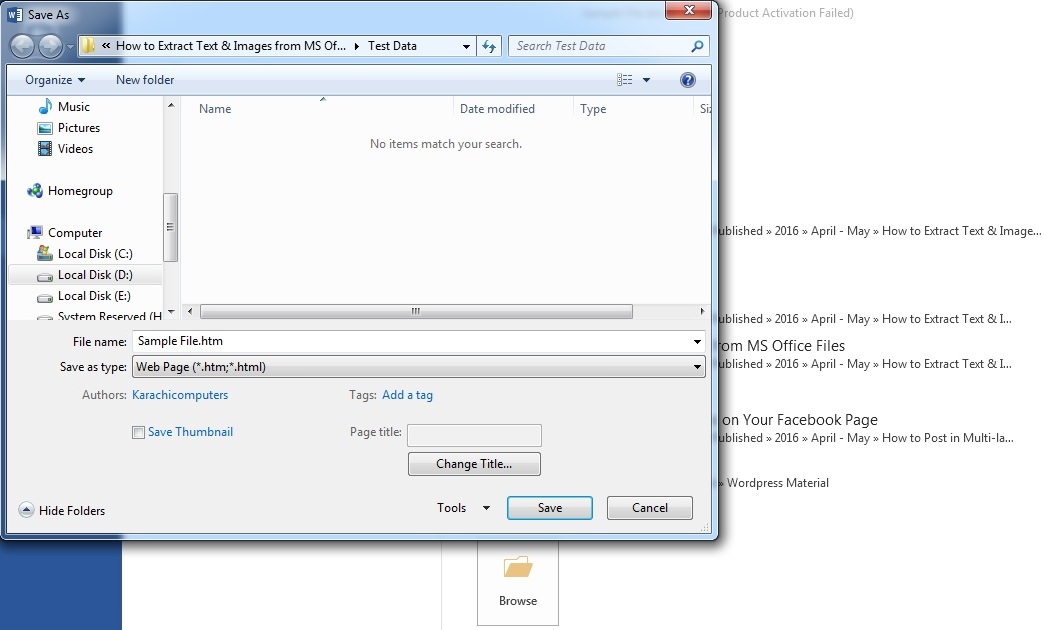 Это удобно, особенно когда вам нужно скопировать информацию с отсканированной визитной карточки в OneNote. После того, как вы извлекли текст, вы можете вставить его в другое место в OneNote. Давайте рассмотрим другой пример.
Это удобно, особенно когда вам нужно скопировать информацию с отсканированной визитной карточки в OneNote. После того, как вы извлекли текст, вы можете вставить его в другое место в OneNote. Давайте рассмотрим другой пример.
Предположим, вы хотите оцифровать статью в журнале. Если вы не обладаете достаточными знаниями об оптическом распознавании символов, вы можете потратить десятки часов на перепечатывание и исправление опечаток. Или, что лучше, вы могли бы просто конвертировать все необходимые материалы в цифровой формат за несколько минут, используя сканер и программное обеспечение для оптического распознавания символов.
Оптическое распознавание символов или оптическое распознавание символов – это технология, позволяющая преобразовывать различные типы документов, например отсканированные бумажные документы, файлы PDF или изображения, снятые цифровой камерой, в редактируемые и доступные для поиска данные. Давайте посмотрим, как это работает в OneNote 2016/2013.
Вы можете скопировать текст из распечатки и вставить его в виде обычного текста в OneNote. Чтобы извлечь текст из одного изображения, которое вы добавили в OneNote, нажмите на изображение правой кнопкой мыши и нажмите Копировать текст из изображения .
Чтобы извлечь текст из одного изображения, которое вы добавили в OneNote, нажмите на изображение правой кнопкой мыши и нажмите Копировать текст из изображения .
Нажмите, куда вы хотите вставить скопированный текст, а затем нажмите Ctrl + V.
Чтобы извлечь текст из изображений файла распечатки многостраничного файла (PDF), просто откройте файл PDF, щелкните правой кнопкой мыши и выберите параметр «Печать».
Затем в появившемся окне на экране компьютера выберите «Отправить его на печать в OneNote 2013».
Выберите местоположение для файла.
Файл запустит процесс преобразования и отправки в OneNote.
После преобразования OneNote откроет и покажет вам файл PDF. Щелкните правой кнопкой мыши по нему и выберите «Копировать текст со страниц распечатки».
Теперь вы можете вставить его туда, куда хотите.
В большинстве случаев текст можно распечатать практически без ошибок из распечатки, используя встроенную функцию распознавания текста в OneNote.
Кроме того, текст копируется в точности так, как он выглядит. Так что, если текст в столбцах, вы получите много коротких строк. тем не менее, это можно исправить относительно быстро, удалив разрыв строки после каждой строки вручную.
Дополнительные сведения о советах и рекомендациях по Microsoft OneNote 2013. Вы также можете посмотреть на эти сообщения:
- SkyDrive поддерживает OCR; теперь можно извлекать текст из изображений
- Как скопировать или извлечь текст из изображений
- Бесплатное программное обеспечение для извлечения изображений из файлов PDF
- Копировать текст из открытых окон с помощью GetWindowText
- Копировать коды ошибок и сообщения из диалоговых окон в Windows 8 | 7.
Python Извлечение текста из изображения с примерами кода
Python Извлечение текста из изображения с примерами кода
На этом занятии мы попробуем решить головоломку Python Извлечение текста из изображения с помощью компьютерного языка.
img = cv2.imread('image.png')
текст = pytesseract.image_to_string(img)
печать (текст)
Точная проблема Python Extract Text From Image может быть решена с помощью альтернативного метода, который описан в следующем разделе вместе с некоторыми примерами кода для справки.
// установить tesseract с помощью -> pip install pytesseract из изображения импорта PIL из pytesseract импортировать pytesseract # Определение путей к tesseract.exe # и изображение, которое мы будем использовать path_to_tesseract = r"C:\Program Files\Tesseract-OCR\tesseract.exe" image_path = r"csv\d.jpg" # Открытие изображения и сохранение его в объекте изображения img = Image.open(image_path) # Предоставление тессеракта # расположение исполняемого файла в библиотеке pytesseract pytesseract.tesseract_cmd = путь_к_тессеракту # Передача объекта изображения в # функция image_to_string() # Эта функция будет # извлечь текст из изображения текст = pytesseract.image_to_string(img) # Отображение извлеченного текста печать (текст [:-1])

Как мы видели, проблема Python Extract Text From Image была решена с использованием нескольких различных экземпляров.
Как извлечь текст из изображения?
Чтобы извлечь текст из изображения,
- Перейти на imagetotext.info (бесплатно).
- Загрузите или перетащите свое изображение.
- Нажмите кнопку «Отправить».
- Скопируйте текст или сохраните текстовый файл на своем компьютере.
Как извлечь текст из изображения с помощью Tesseract?
Создайте сценарий тессеракта Python. Создайте папку проекта и добавьте в нее новый файл main.py. Как только приложение предоставит доступ к файлам PDF, его содержимое будет извлечено в виде изображений. Затем эти изображения будут обработаны для извлечения текста. 18 апреля 2022 г.
Что такое OCR в Python?
OCR = оптическое распознавание символов. Другими словами, системы оптического распознавания символов преобразуют двумерное изображение текста, которое может содержать напечатанный или написанный от руки текст, из графического представления в машиночитаемый текст. OCR как процесс обычно состоит из нескольких подпроцессов, которые должны выполняться максимально точно.09-Авг-2022
OCR как процесс обычно состоит из нескольких подпроцессов, которые должны выполняться максимально точно.09-Авг-2022
Может ли OpenCV извлекать текст?
Да, OpenCV выводит компьютерное зрение на новый уровень, теперь машины могут обнаруживать, извлекать и читать текст из изображений.
Что такое Tesseract-OCR Python?
Python-tesseract — это инструмент оптического распознавания символов (OCR) для Python. То есть он распознает и «прочитает» текст, встроенный в изображения. Python-tesseract — это оболочка для Google Tesseract-OCR Engine.
Могу ли я преобразовать изображение в текст?
Image to Text — это онлайн-инструмент для извлечения текста из файлов изображений. Он оснащен новейшей технологией оптического распознавания символов (OCR) для точного преобразования фотографий в текст. Он может извлекать текст из любого формата изображения, например: PNG.
Хорошо ли Tesseract OCR?
Tesseract выполняет различные внутренние операции по обработке изображений (используя библиотеку Leptonica) перед выполнением фактического оптического распознавания символов.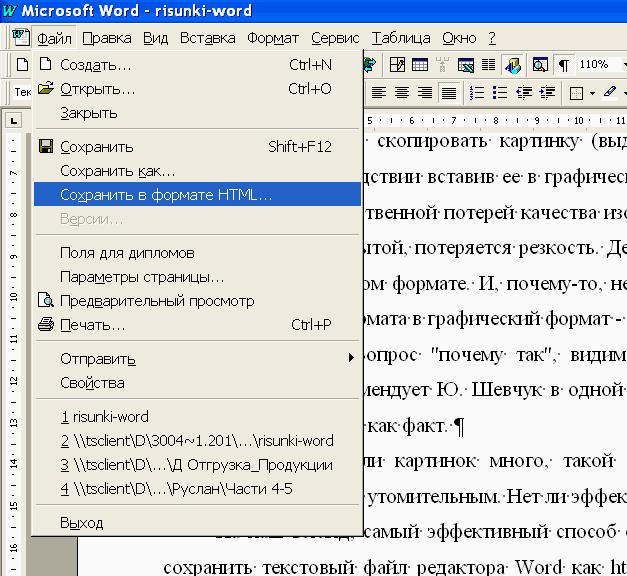 Как правило, он делает это очень хорошо, но неизбежно будут случаи, когда он недостаточно хорош, что может привести к значительному снижению точности.
Как правило, он делает это очень хорошо, но неизбежно будут случаи, когда он недостаточно хорош, что может привести к значительному снижению точности.
Как обучить OCR в Python?
Установите это в системный путь, например «C:\Program Files\Tesseract-OCR». Перейдите в настройки и добавьте этот путь к переменным среды. Перейдите в командную строку и введите «tesseract.exe», чтобы проверить установку. Если это не выдает никаких ошибок, то вуаля, ваша установка tesseract python прошла успешно! 26 сентября 2022 г.
Как работает тессеракт OCR?
Tesseract проверяет текстовые строки, чтобы определить, имеют ли они фиксированный шаг. Там, где он находит текст с фиксированным шагом, Tesseract разбивает слова на символы с использованием шага и отключает измельчитель и ассоциатор для этих слов на этапе распознавания слова.
Как преобразовать изображение в текст в Python?
изображение в текст питон
- от os import closerange.
- из импортного изображения PIL.

- импортировать pytesser действовать как tess.
- тесс. питессеракт. tessetact_cmd = r’укажите ПУТЬ К TESSETACT.EXE’
- image = r’полный путь к файлу изображения’
- текст = тесс. image_to_string(Image.open(image), lang=”eng”)
- печать(текст)
Извлечение текста из любого изображения с помощью этого приложения для macOS
Извлекайте текст из любого изображения с помощью этого приложения для macOS
TextSniper для Mac работает с фотографиями, видео, PDF-файлами и многим другим всего за 3,9 доллара США.9.
Мы можем получать компенсацию от поставщиков, которые появляются на этой странице, с помощью таких методов, как партнерские ссылки или спонсируемое партнерство. Это может повлиять на то, как и где их продукты будут отображаться на нашем сайте, но поставщики не могут платить за влияние на содержание наших обзоров. Для получения дополнительной информации посетите нашу страницу «Условия использования».
Изображение: StackCommerce
Для получения дополнительной информации посетите нашу страницу «Условия использования».
Изображение: StackCommerceКогда кто-то отправляет вам файл Word, достаточно легко внести изменения, но что, если вы получите печатный документ, PDF-файл или текст в изображении? Один из вариантов — паниковать; вместо этого мы рекомендуем установить TextSniper для Mac.
Это мощное, но легкое приложение OCR может извлекать текст практически из любого цифрового файла, и вы даже можете подключить свое устройство iOS для извлечения текста из печатных материалов. Прямо сейчас вы можете получить пожизненную подписку на TextSniper всего за 3,99 доллара США в Академии TechRepublic. Это впечатляющая скидка 42% от обычной цены!
Независимо от того, работаете ли вы над дизайн-проектом или пытаетесь получить важную информацию для своих заметок, программное обеспечение OCR может быть действительно полезным. К сожалению, большинство приложений в этой нише довольно дорогие.
TextSniper для Mac предлагает идеальную золотую середину, доступную по цене и обладающую множеством полезных функций. Приложение использует передовую технологию OCR для извлечения текста из изображений, видео и PDF-документов за считанные секунды. На самом деле, вы можете подобрать практически любой текст, который появляется на вашем дисплее. Результаты обычно точны, а TextSniper работает на нескольких языках — даже когда вы не в сети.
Но на этом функциональность не заканчивается. Это приложение может экспортировать редактируемый текст или превращать ваши слова в речь. Он также может сканировать текст, штрих-коды и QR-коды с помощью камеры на портативных устройствах Apple.
Закажите сейчас всего за 3,99 доллара США, чтобы получить пожизненную лицензию TextSniper со скидкой 42% от полной стоимости.
Цены и наличие могут быть изменены.
Академия TechRepublic
Опубликовано: Изменено: Увидеть больше Программное обеспечение Поделиться: извлекайте текст из любого изображения с помощью этого приложения для macOS.- Программного обеспечения
Выбор редактора
- Изображение: Rawpixel/Adobe Stock
ТехРеспублика Премиум
Редакционный календарь TechRepublic Premium: ИТ-политики, контрольные списки, наборы инструментов и исследования для загрузки
Контент TechRepublic Premium поможет вам решить самые сложные проблемы с ИТ и дать толчок вашей карьере или новому проекту.
Персонал TechRepublic
Опубликовано: Изменено: Читать далее Узнать больше - Изображение: Nuthawut/Adobe Stock
- Изображение: WhataWin/Adobe Stock
Безопасность
Основные угрозы кибербезопасности на 2023 год
В следующем году киберпреступники будут как никогда заняты. Готовы ли ИТ-отделы?
Мэри Шеклетт
Опубликовано: Изменено: Читать далее Узнать больше Безопасность - Изображение: Андрей Попов/Adobe Stock
- физкес / iStock
- Изображение: Bumblee_Dee, iStock/Getty Images
Программного обеспечения
108 советов по Excel, которые должен усвоить каждый пользователь
Независимо от того, являетесь ли вы новичком в Microsoft Excel или опытным пользователем, эти пошаговые руководства принесут вам пользу.