
Как распознать текст?
Уже много раз у меня возникала потребность распознать от сканированный текст. В Windows есть мощная программа ABBYY Fine Reader, которая прекрасно справляется с этой задачей. Но незадача в том, что она платная и работает только в Windows. Хотя есть версия и под Linux, но она тоже платная и стоит хороших денег. Но нас волнует вопрос: как можно распознать текст бесплатно?
1. Как распознать текст онлайн?
Это наверное самый просто способ распознать текст. Вот некоторые сервисы для распознавания текста онлайн: onlineocr.ru, finereader.abbyyonline.com, sciweavers.org. В перечисленных трёх есть распознание на русский язык, во многих существующих других русский язык распознать невозможно.
Всем хороши онлайн сервисы для распознания текста, если…если ваш документ МАЛЕНЬКИЙ. Но если у вас журнал Linux Format размером в 100 мегабайт, то распознать онлайн такой документ будет невозможно – сначала нужно переформатировать PDF в графический формат, так как сервисы принимают только отсканированные документы в форматах JPG, BMP, TIF и некоторых других. Без программы, которая могла бы пере конвертировать PDF не обойтись. Но об этом чуть позже.
Поэтому во многих случаях будет лучше, конечно, установить программу для распознания текста, а такая есть и для Linux.
2. Как распознать текст в Linux?
Для этого существует бесплатный движок Cuneiform и графическая оболочка к нему – Yagf. Так же понадобится установить языковые пакеты aspell и aspell-ru. Итак, устанавливаем:
sudo apt-get install cuneiform yagf aspell aspell-ru
Если у вас в репозиториях не оказалось программы Yagf, то вам нужно скачать её с [urlspan]официального сайта[/urlspan]. У меня же она есть в репозиториях ualinux.com. Так же можно подключить дополнительный репозиторий:
sudo add-apt-repository ppa:alex-p/notesalexp
После установки пакетов идём в меню: Приложения – Офис – Yagf и запускаем программу.

Давайте попробуем распознать какой нибудь журнал в PDF формате. К сожалению, программа может распознать только графические файлы форматов JPEG, PNG, BMP, TIFF, GIF, PNM, PPM, PBM и некоторых других.
3. Как распознать PDF в Linux?
Для того, чтобы сконвертировать PDF в графический формат, мы воспользуемся программой Рdfedit. Лично у меня она есть в репозитории ualinux.com
sudo apt-get install pdfedit
Или можно скачать Pdfedit со страницы разработчиков: launchpad.net/ubuntu/+source/pdfedit
После установки программы идём в меню:

Я сохранил одну страницу в формате .PNG, хотя можно и в другой, пока не знаю, какой лучше. Единственный минус, при сохранении у файла почему-то не прописывается расширение, его мне пришлось дописать вручную, иначе программа файл не увидит.
Между прочим это даже хорошо, что распознать текст можно только по одной странице, очень редко нам нужно распознать огромный журнал в PDF, чаще всего всего лишь одну статью. Теперь скормим полученное изображение программе Yagf:

К сожалению распознание не удалось, и причина оказалась банальной: программа PdfEdit сохраняет PDF в ужасно маленьком разрешении – получилось изображение 89 килобайт. И в настройках программы я не нашёл, как увеличить разрешение. Ну что же, отсутствие результата – тоже результат.
Хорошо, что в арсенале Linux много программ и в репозиториях есть мега-программа, которая может выполнить требуемую задачу, преобразовать PDF в изображение. Это известная всем программа GIMP. Отрываем ей PDF файл и требуемую страницу им экспортируем в формат TIFF.
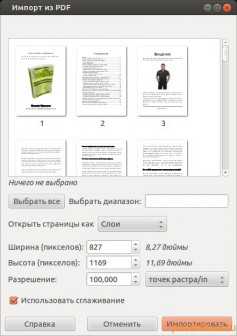
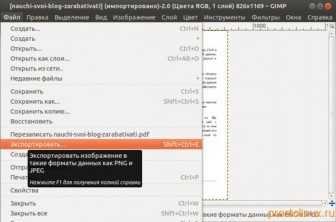
Вот это другое дело, размер той же страницы уже 4 мегабайта!
Ну вот, теперь совсем другое дело! Есть конечно ошибки, но это мелочи, легко исправить.
Во таким нехитрым способом можно распознать текст из PDF в Linux! Есть и другие способы, но думаю я описал самые простые, проверенные лично мной на практике. А практика – это ВСЁ! МОЖЕТ ВЫ ЗНАЕТЕ ЕЩЁ ПРОСТЫЕ И ЭФФЕКТИВНЫЕ СПОСОБЫ РАСПОЗНАТЬ PDF ФАЙЛЫ?
На блоге Seostage.ru проходит акция «Бесплатный обзор блогов всем желающим»
Увы, пока нет комментариев 🙁
Напишите свой комментарий:
prostolinux.ru
Как распознать отсканированный текст при помощи Abbyy FineReader!
Здравствуйте. Сегодня я расскажу о том, как с помощью программы Abbyy FineReader распознать текст c изображения, которое вы могли получить в результате сканирования. Ваш сканированный текст будет полностью в документе Microsoft Word и этот распознанный текст можно будет редактировать! Распознать текст при помощи Abbyy Finereader может пригодиться тем, кто учится, работает с текстами и переводами. Программа, к сожалению, является платной. Как-то доводилось попробовать одну из бесплатных вариантов аналогичных программ, но весьма хорошо отсканированный текст распознается просто ужасно… А распознать текст в Abbyy FineReader получается весьма качественно! Сейчас я покажу как пользоваться программой Abbyy FineReader для быстрого распознавания текста с изображения.
ABBYY FineReader имеет пробную версию на 30 дней с возможностью распознавания до 100 страниц и сохранением не более 3-х страниц из документа. Т.е. в течение этого времени вы можете увидеть возможности программы и принять взвешенное решение — нужна ли она вам, стоит ли её покупать или нет.
Как установить Abbyy FineReader!
Для начала выбираем язык программы. Нажимаем «ОК».
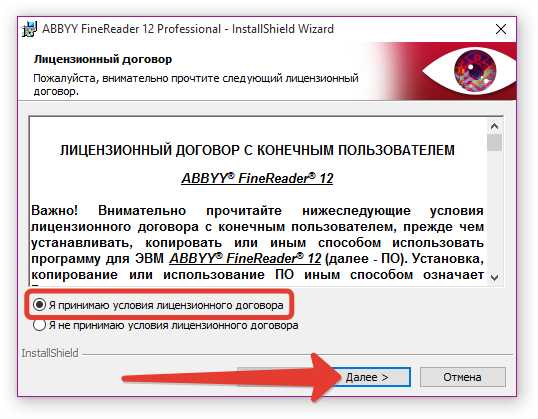
Принимаем условия лицензионного соглашения (при желании можно прочесть лицензионный договор, если вам интересно о чём там речь). Нажимаем «Далее».
Далее вы должны выбрать режим установки. При обычном режиме программа не спросит вас и установит то, что в программе задано по умолчанию, а именно — все компоненты: саму программу Abbyy Finereader для распознавания текста, компонент для программ Microsoft Office и компонент для проводника Windows (позволяющий быстро распознавать изображения, не открывая отдельно программу). Советую отметить выборочную установку чтобы настроить так, как вам нужно. Тем более это не займет и 15 минут 🙂 Внизу указана папка куда установится программа. Желательно оставить выбор по умолчанию, чтобы потом не было никаких проблем при использовании программы. Нажимаем «Далее».

Компоненты программы. Это окно как раз появится в случае, если вы выберите тип установки «Выборочная». Компоненты — это что-то вроде вспомогательных приложений к программе. Первый компонент «Интеграция с программами Microsoft Office и Проводником Windows». Этот компонент будет отображен в меню Microsoft Office и если вы щелкните по изображению у себя на компьютере правой кнопкой мыши, то там будет пункт с этой программой. Вот так будет выглядеть ваше меню в Microsoft Office после добавления этого компонента.
А вот что будет если вы щелкните правой кнопкой мыши по изображению:

Т.е. появится меню, в котором вы можете сделать быстрое распознавание текста с отправкой результатов в Word, Excel или PDF.
Второй компонент позволит вам распознать текст с экрана компьютера. Это значит, что вы сможете сделать скриншот и также распознать текст. Если вы не хотите устанавливать один из этих компонентов, или вовсе не хотите устанавливать оба, то нужно нажать на стрелочку вниз и выбрать «Данный компонент будет недоступен». Тогда компонент установлен не будет. Я оставила оба.
Далее 4 пункта. 1-ый означает то, что сведения о том, как вы пользуетесь программой Abbyy Finereader будут переданы разработчику. Данный пункт советую не отмечать, чтобы программа лишний раз не выходила в интернет ради отправки сведений о работе с ней. Тем более, мало ли какие ещё сведения будут отправляться 🙂 2-ой пункт создает ярлык программы на рабочем столе. 3-ий означает, что программа будет запускаться при включении компьютера, а 4-ый будет проверять обновления программы. Я оставляю только второй и напротив него оставляю галочку. Закрываем все приложения Microsoft Office, потому что так требует установщик и нажимаем «Установить».

Нужно подождать пару минут чтобы программа загрузилась и нажать «Далее».

Все, установка завершена! Нажимаем «Готово».
Как при помощи Abbyy Finereader распознать текст c отсканированного или любого другого изображения?
Рассмотрим, как пользоваться программой. К примеру, у вас есть отсканированный текст. Теперь, чтобы распознать текст в Abbyy FineReader, открываем программу. Нажимаем «Открыть».

Выбираем нужное нам изображение и нажимаем открыть.
Когда вы откроете нужный документ, Abbyy Finereader начнёт распознавать текст. Чем больше документ, тем дольше будет длиться распознавание. Распознавание одной страницы может занять несколько секунд.
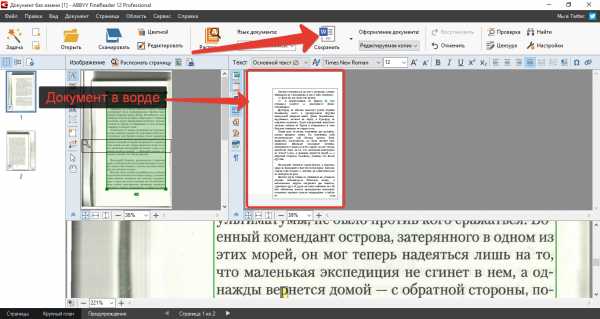
После того как текст распознается вам останется только сохранить результат в документ Microsoft Word, чтобы затем вы могли отредактировать в нём что угодно. Для этого нажмите кнопку «Сохранить» на верхней панели инструментов, после чего выберите в какую папку будет сохранён документ Word и под каким названием.
Если у вас подключён к компьютеру сканер, то вы можете запустить сканирование прямо из программы, и после чего отсканированный документ сразу будет распознаваться. Для этого на верхней панели инструментов нажмите кнопку «Сканировать». Далее действия будут зависеть от программы-драйвера для вашего принтера. Вам нужно только следовать указаниям мастера сканирования.
Как видите, все очень просто и быстро. Теперь вы знаете, как пользоваться Abbyy FineReader для распознавания текста с изображений! Надеюсь, что эта информация очень поможет многим:) Удачи!
serfery.ru
Как распознать текст со сканера с помощью программы ABBYY FineReader | Мой друг

Покажу как это сделать быстро и качественно на примере программы Abbyy FineReader версии 8.0. Принципы, изложенные здесь, можно с успехом применить и в любой другой программе распознавания текста, и в любой другой версии программы FineReader. FineReader на пост-советском пространстве – самая распространённая и успешная программа для этой задачи.
Итак, для того чтобы получить отличный результат нам нужно качественно сосканировать оригинал. Легче всего этого достичь с листов формата А4, распечатанных на принтере, труднее с книг, журналов, газет. Качество сканирования – основа, от которой будет зависеть дальнейший успех работы.
Несколько слов об автоматизации процессов распознавания. Хотя от версии к версии авторы программы FineReader улучшают алгоритмы автоматического распознавания сложных макетов (Scan&Read – когда достаточно запустить программу и нажать одну кнопку, а остальное программа сделает за Вас сама, и Вам остаётся лишь насладиться результатами процесса), эти алгоритмы срабатывают не всегда корректно. Искусственный интеллект ещё не скоро заменит человеческую смекалку и здравый смысл. Причиной чего и послужило написание этой статьи.
Сканирование текста
Запускаем программу Abbyy FineReader, нажимаем кнопочку «Сканировать», ложим наш оригинал в сканер и делаем пробное сканирование. Для оптимальной скорости и качества сканирования в драйвере сканера достаточно выставить режим сканирования «Чёрно-белое» и разрешение 300 точек на дюйм.
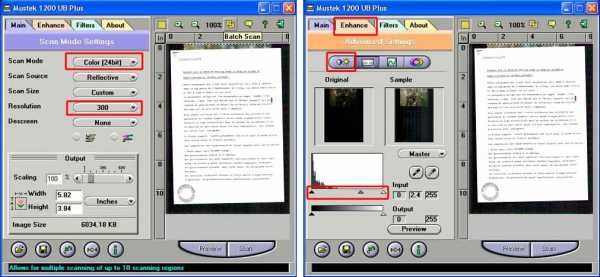
Если мы используем для сканирования twain-драйвер Mustek точно так же выбираем режим сканирования «Чёрно-белое» (Black-white) и выставляем разрешение 300 dpi. При необходимости понижаем уровень шума регулирование яркости-контрастности либо уровнями
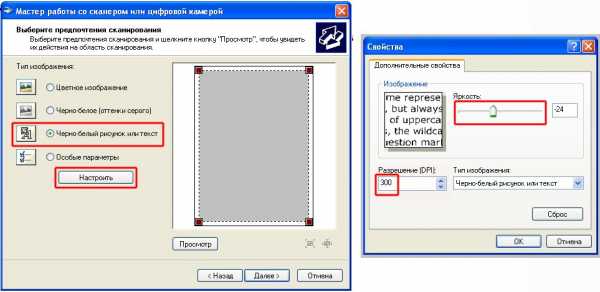
Если мы используем для сканирования «Мастер работы со сканером или цифровой камерой» — выбираем «Чёрно-белое изображение», а в Настройках — «разрешение» , в свойствах «Мастера работы со сканером или цифровой камерой» выставляем разрешение и регулируем яркость
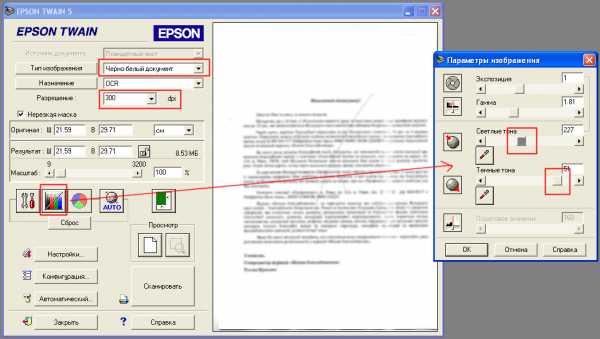
Если у нас сканер Epson, либо какой-то другой, в twain-драйвере точно так же ищем пункты «Тип изображения» («Image Type») — чёрно-белое (black-white, b/w), Разрешение («Resolution») — выставляем 300dpi и при необходимости регулируем «Яркость-контрастность», либо «Уровни», либо «Светлые и тёмные тона»
Режимы «Оттенки серого» и «Цветное изображение» тоже подходят, но от этого увеличивается время сканирования и возможно, пострадает качество распознавания текста (Серый или цветной фон, особенно если он неоднородный может существенно ухудшить качество распознавания текста). В идеале нам нужно добиться чтобы на белом фоне были чёрные буквы и больше никаких посторонних объектов. Смотрим на результат, если он нас устраивает: буквы видно отчётливо, шума, грязи практически нет, то продолжаем сканирование далее, если шума много (такое бывает, например, если оригинал отпечатан на жёлтой бумаге) – ползунками яркости и контрастности двигаем так, чтобы шум максимально пропал, а буквы стало видно более отчётливо, делаем ещё несколько пробных сканирований пока не добьёмся нужного результата. Как только приемлемый результат получен – приступаем к основному сканированию. Если нам нужно сканировать одновременно участки текста из разных источников (несколько книг, журналов, газетных вырезок), то такую калибровку для достижения приемлемого результата часто приходится делать для каждого источника отдельно.
Поворот страниц.
В программу FineReader встроен механизм автоматического определения ориентации страниц и автоматического же их поворота. В простых случаях этот механизм отлично работает и не требует от нас никакого участия, но если текст видно не очень отчётливо, либо если разные страницы отсканирываны под разными углами, здесь мы получаем сбой и в результате получаем вместо текста абракадабры. Потому имеет смысл осуществлять поворот вручную.
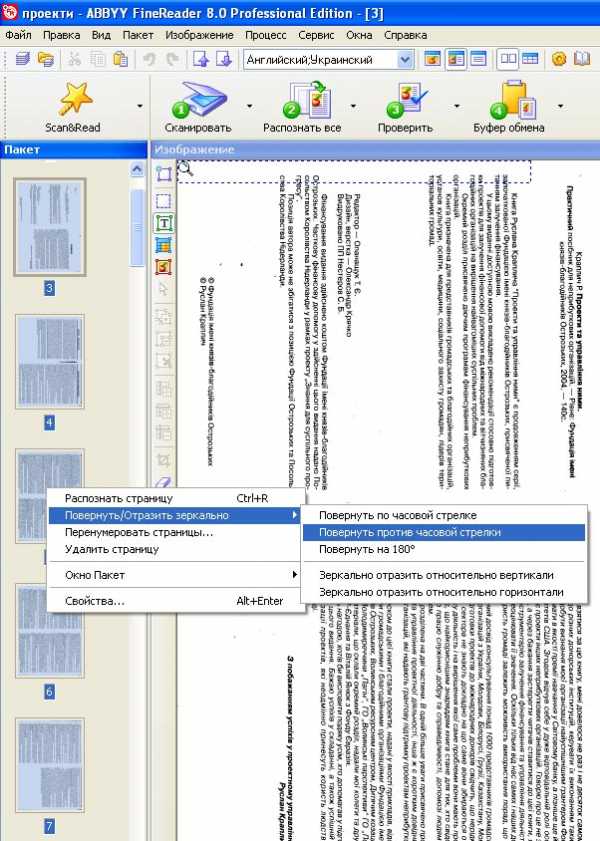
Выделяем несколько страниц, повёрнутых в одинаковую сторону с зажатой клавишей «Ctrl» и поворачиваем при помощи меню правой кнопки мыши
Распознавание текста
Сосканировав все листы документа можно приступать к его распознаванию. Выбираем язык распознаваемого документа. Это важно потому что буквы в разных языках разные и если, например мы будем распознавать украинский текст как русский, то в конечном результате в распознанном тексте будет распознано практически всё более-менее правильно, но украинские буквы «і», «ї» «є» не будут распознаны и FineReader заменит их на что-то более-менее похожее и в конце прийдётся все эти огрехи выправлять вручную. То же самое бывает когда в русском тексте встречаются адреса электронной почты, сайтов, какие-то слова, набранные на иностранном языке, а мы текст распознаём как «русский», то эти символы FineReader заменит на что-то более-менее похожее из русского алфавита. В таком случае перед распознаванием нужно FineReader-у указать, что текст состоит из нескольких языков, отметив нужные галочками. Не стоит также злоупотреблять выбором языков, отметив все возможные какие есть. В этом случае мы тоже можем в результате получить «катавасию» из всех возможных символов вместо искомого результата.
Следующий пункт после выбора языка распознавания – анализ макета, то есть нам нужно разобрать страницы нашего документа на составляющие: текстовые блоки, таблицы и изображения. В случае если мы имеем дело с простым текстом, набранным на листах формата А4, то этот пункт можно смело пропускать. Программа FineReader отлично справится с этим и сама. В противном случае нужно ещё немного поработать ручками. В данном случае я запускаю процесс автоматического анализа макета всех страниц и по его окончании просматриваю результаты, и в случае неправильного анализа вручную его поправляю. Программа не всегда правильно различает области текста, иногда таблицы путает с текстом, картинки с текстом, текст с картинками, иногда области с тенями, пятнами воспринимает как текст, не всегда нам в конечном результате нужно чтобы присутствовали номера страниц, колонтитулы исходного материала и т.д. Наша задача – выправить эти огрехи ещё на стадии подготовительных работ. Сейчас это сделать намного легче, чем править уже на последнем этапе работ.
Когда макеты разобраны можно приступать непосредственно к самому процессу распознавания. То есть нам нужно просто нажать на кнопочку «Распознать» и, откинувшись в кресле, дождаться окончания процесса распознавания. А по его окончании, бегло глянув на распознанные страницы, убедиться что тексты, таблицы и прочие объекты распознаны корректно, т.е. процентов на 90-95 (в идеале конечно на все 100) и можно приступать к завершающему этапу работ: постбоработке и сохранению результатов.
Несмотря на все наши предыдущие старания огрехи распознавания будут, и их количество зависит от того, на сколько старательно мы выполняли предыдущие этапы. FineReader помогает нам в этом, подсвечивая участки, в качестве распознавания которых он не уверен, синим цветом. На них мы обращаем внимание в первую очередь и если эти участки распознаны неверно – поправляем их.
Сохранение результатов распознавания можно сделать двумя способами: непосредственно в текстовый редактор (например Microsoft Word) или через буфер обмена. Первый способ нам может пригодиться когда нам нужно максимально сохранить исходное форматирование документа: заголовки, шрифты, взаимное расположение текстовых колонок и графических элементов. Но иногда исходное форматирование нам не нужно и более того, вредно, потому что в текстовом редакторе потом бывает очень сложно потом разобраться что за чем идёт и почему, и как, как сделать по другому, так как нам это будет нужно. При передаче текста через буфер обмена мы избегаем этих моментов и на выходе имеем чистый текстовый массив, который можем уже обрабатывать форматировать на наше усмотрение. И уже в Ворде мы выполняем последний этап работ: убираем лишние детали: множественные пробелы, пробелы перед запятыми, точками, знаки табуляции, исправляем кавычки, знаки тире, исправляем неправильно распознанные участки текста и т.д.
Ну и завершающий этап работ – собственно для чего это всё и затевалось: толи нам нужен был просто распознанный текст, толи нам нужно в него внести изменения для дальнейшей работы.
Похожие записи:
www.1st.rv.ua