
Как распознать текст с помощью ABBYY FineReader: пошаговая инструкция

[contents]
В этот раз расскажу как превращать бумажные документы в электронный вид формата PDF, а также, как бумажный документ перекинуть в компьютер с целью изменить текст. Итак начнем.
У меня на руках бумажный документ.
СКАНИРОВАНИЕ в PDF
Задача: перекинуть в компьютер (перевести в электронный вид) этот документ. Притом нужно сделать именно в таком виде чтобы нельзя было его в будущем изменить (грубо говоря надо сделать фото документа). Потом этот электронный документ нужно переслать по почте на электронный адрес. Притом клиент просит именно в формате pdf.
По этапам:
1) пропускаю документ через сканер
2) сохраняю полученный отпечаток в формате pdf на свой компьютер
3) пересылаю полученный файл по почте
В своей работе я использую для решения такой задачи 2 программы:
Foxit Phantom или ABBYY FineReader. Для понятности прикладываю скриншоты:
В Foxit Phantom при включенном сканере необходимо в главном меню выбрать ФАЙЛ-СОЗДАТЬ PDF-СО СКАНЕРА…
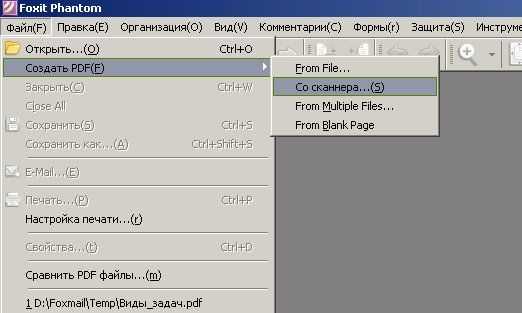
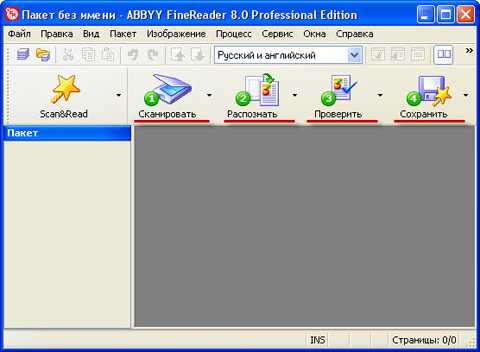
В ABBYY FineReader в панели инструментов есть огромные кнопки. Одна из них называется СКАНИРОВАТЬ в PDF. Её и используем.
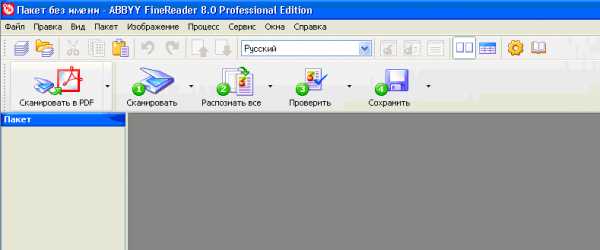
Если же надо отсканировать многостраничный документ то, по этапам:
1) Нажимаем кнопку под номером 1 СКАНИРОВАНИЕ
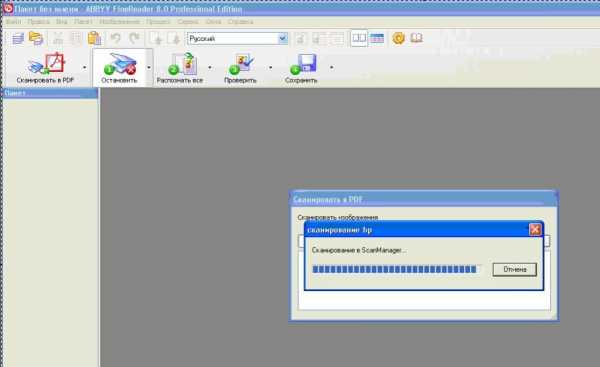
Также сканируем ещё одну страницу (нажимаем ещё раз кнопку под номером 1 СКАНИРОВАНИЕ).
2) Сохраняем в PDF
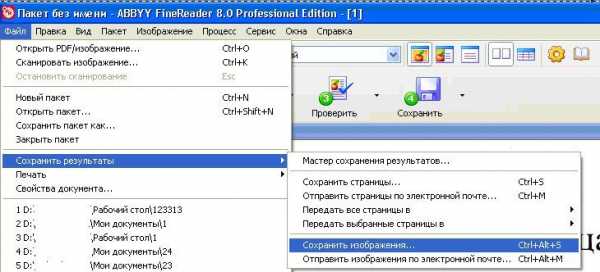
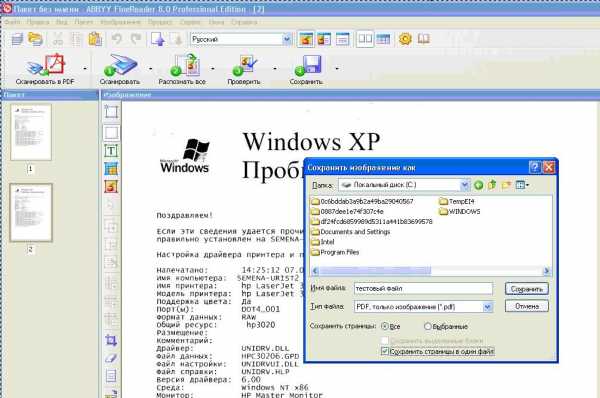
В итоге получаем готовый многостраничный документ в виде файла в формате PDF.
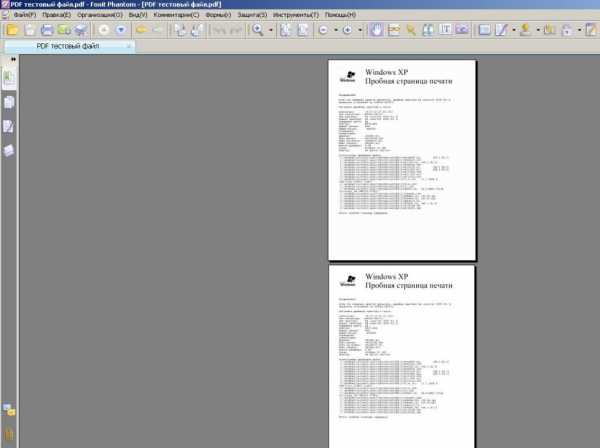
Теперь данный файл можно отправлять по электронной почте.
РАСПОЗНАВАНИЕ ТЕКСТА
Задача: перевести бумажный документ в электронный вид (в компьютер)
По этапам:
1) Сканирование (кнопка 1 СКАНИРОВАНИЕ)
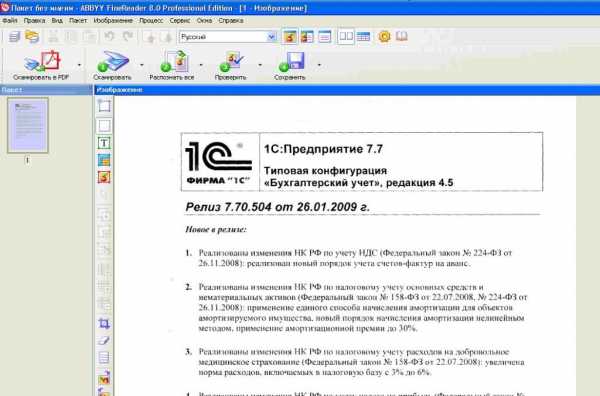
2) Распознавание (кнопка 2 РАСПОЗНАТЬ ВСЕ)
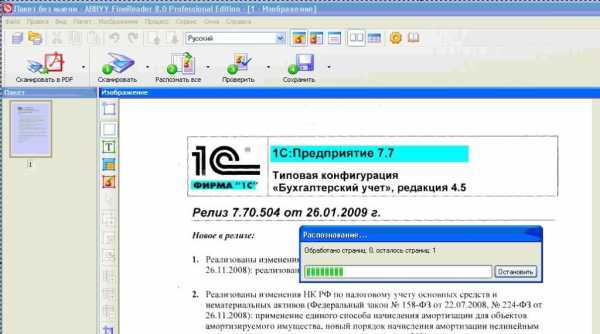
Распознавание нужно понимать как процесс перевода фотографии (картинки) в текст (буквы, цифры, знаки). Если Вы сфотографировали текстовую страницу, то после распознавания 99% текста с бумаги превратиться в текст электронный. Электронный текст уже можно на компьютере менять (редактировать) так, как Вам захочется.
3) Сохранение в текстовый редактор (кнопка 4 Сохранить)
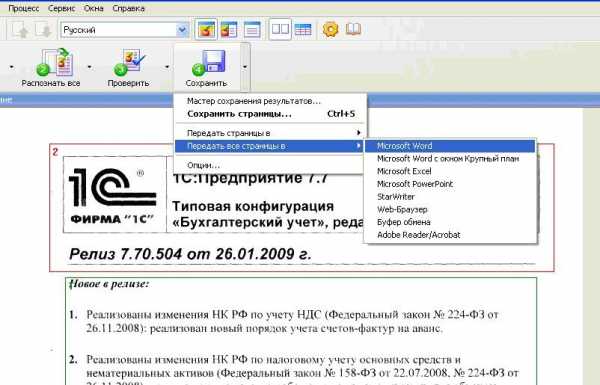
Получаем
Хотелось бы указать на важные моменты при процедуре РАСПОЗНАВАНИЯ. Есть нюансы при работе.
Сразу после распознавания советую поглядеть на результат. Особенно на блоки, которые создает программа FineReader.
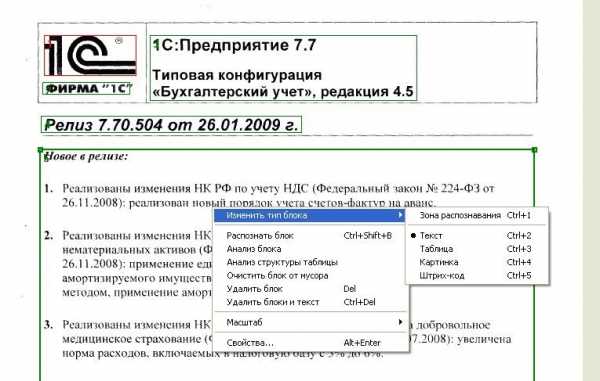
Это области выделенные в прямоугольные рамки. Рамки эти разного цвета. Если красного цвета-то этот блок распознался как КАРТИНКА. Если черного цвета — то ТЕКСТ. Блоки бывают разного типа. Тип блока можно узнать щелкнув на блоке ПРАВОЙ клавишей мыши и выбрав ИЗМЕНИТЬ ТИП БЛОКА.
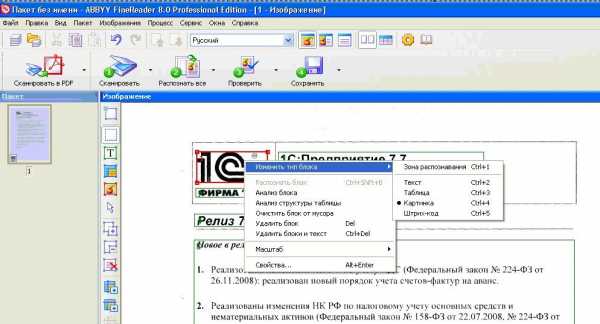
Маленькая хитрость: можно выделить произвольную область и пометить любым типом блок. Например выделим ту часть текста, которая плохо распознается, при помощи левой клавиши мыши (нажимает, удерживаем и тянем, рамка меняет размер).

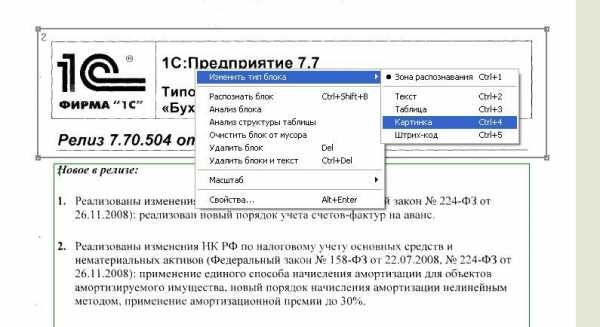

В итоге документ в Word-е будет иметь блок текста и блок картинка. Блок картинка будет иметь абсолютно неизменный вид. Данный способ я использую при сохранении печатей, нестандартных шрифтов, картинок, фотографий.
ЗЫ: Знания и умения работать с PDF, сканировать и распознавать документы очень часто выручают в офисной работе. Знание — экономит Ваше время!
Не пропусти самое интересное!
Подписывайтесь на нас в Facebook и Вконтакте!
minterese.ru
Как распознать сканированный текст
 Данная необходимость возникает при переводе в цифровой формат больших текстовых документов. Небольшие обычно набираются вручную, это не составляет труда, а вот при переводе в «цифру» целой книги или даже библиотеки займет огромное количество времени, что не всегда имеется. Именно в таких ситуациях и приходит на помощь сканер, но сам по себе он только переводи полученное изображение на экран монитора. Что сделать из него полноценный текстовый документ следует использовать дополнительные программы распознаватели.
Данная необходимость возникает при переводе в цифровой формат больших текстовых документов. Небольшие обычно набираются вручную, это не составляет труда, а вот при переводе в «цифру» целой книги или даже библиотеки займет огромное количество времени, что не всегда имеется. Именно в таких ситуациях и приходит на помощь сканер, но сам по себе он только переводи полученное изображение на экран монитора. Что сделать из него полноценный текстовый документ следует использовать дополнительные программы распознаватели.
Выбор программы
Среди них есть явно выделяющиеся лидеры, например, FineReader от ABBYY. Но, дело в том, что он платный и позволить его могут только крупные предприятия, а для домашнего использования он не подойдет. Конечно, как и везде данному софту есть и бесплатная альтернатива, которая отличается по возможностям. Этой альтернативой является CuneiForm. Именно бесплатность данного софта обеспечила потерю некоторых возможностей, по сравнению с предыдущей программой. В первую очередь это несовместимость работы с некоторыми устройствами сканирования, в частности с МФУ сканерами.
Таким образом к использованию будет доступна только стандартная программа сканирования, предоставленная операционной системой. Также «КуниФорм» имеет ограничения в разрешении сканируемого изображения и не сможет работать с документами больше ста килобайт. Но есть и плюсы, ведь качество распознавания намного выше, чем у платного аналога, так что для хорошего результата будет достаточно выставить разрешение в двести dpi. Программа может работать и с большим, но в таком случае есть вероятность ее зависания, поэтому лучше не рисковать.
Языков распознавания у платного аналога, конечно, больше. К тому же в нем есть функция их комбинированного распознавания, но зато в «КуниФорм» есть режим смешанного англо-русского распознавания, чего, чаще всего, достаточно. После сравнительно анализа можно удостовериться в хороших показателях работоспособности бесплатной программы и спокойно начать ее инсталляцию.
Установка программы
Весь процесс очень прост, достаточно лишь запустить установочный файл и программа все сделает сама. «КуниФорм» может устанавливаться на платформы начиная с «Виноус 98» и заканчивая современными версиями. После завершения процесса, в меню «пуск» и на рабочем столе появятся значки запуска программы.
Обзор интерфейса
По сравнению со своим аналогом программа очень проста и интуитивно понятна многим пользователям. Все основные настройки находятся на панели инструментов. Первая кнопка активирует режим работы мастера, но использовать ее можно только при поддержке сканером данной программы. В противном случае кнопка будет не активна.
Следующая кнопка активирует процесс сканирования, но работает она так же только при поддержке сканером программы. Начиная со второй кнопки можно обратить внимание на дополнительные стрелочки по бокам кнопок управления. Они активируют дополнительные возможности настроек.
Работа
Если программа поддерживается сканером, то использую ее получаем изображение. В противном случае загружаем в программу готовый скан с компьютера. «КуниФорм» способна поддерживать множество форматов файлов, включая TIF, JPG, GIF, BMP без проблем. Возможные неполадки могут возникнуть при работе с PNG, но и то не всегда.
После загрузки изображение следует разметить для дальнейшего корректного распознавания. Таким образом программа разделяет текст, таблицы и изображения на разные области, помоченные разными цветами. После этого запускается сканирование, результат которого будет выдан в отдельном окне встроенного редактора. Он немного похож на привычный Microsoft Word. Здесь выделены голубым цветом слова, которые программа не смогла до конца распознать, а розовым возможные ошибки в тексте. После редактирования ошибок текст можно сохранить с помощью последней кнопки, при этом выбрав формат конечного файла. Можно так же напрямую экспортировать документ в другую программу с помощью тех самых боковых стрелочек.
Так же дополнительное меню содержит кнопку «Автомат», которая активирует все выбранные функции в автоматический режим. То есть пользователю вообще не придется ничего делать кроме загрузки документа в программу, все остальное будет происходить автоматически. Стандартные настройки программы полностью удовлетворяют функциональную работу приложения, но по необходимости их можно настроить самостоятельно с помощью меню «Файл» и пункта «общие настройки». Здесь изменяются параметры распознавания языка, форматирования и сканирования документов.
Дополнительная утилита
В состав программы входит еще один компонент, вынесенный отдельно от остальных. Его можно найти в меню «пуск» в папке с основной программой. Она называется «пакетное распознавание». Необходима данная программа для быстрого распознавания больших объемов текста, например, если требуется перевести в цифровой формат целую книгу.
Ведь работая отдельно над каждой страницей, уйдет много времени. Дополнительная программка позволяет всего лишь указать нужные файлы и довольствоваться результатом готовой работы. Для этого необходимо сначала создать новый пакет документов. Затем все делается по подсказкам, лишь на последнем этапе пользователю придется выбирать действие с созданным пакетом. Его можно сохранить в исходном виде, а можно сразу запустить процесс распознавания.
Время работы последнего зависит от количества файлов и от степени видимости текста. После распознавания пользователю откроется список обработанных документов. В левой части основного окна будут находиться две вкладки и обработанными и исходными данными. Все возникшие проблемы при обработке отправляются в отдельную папку ошибок. После всего распределения и исправления важно сохранить внесенные изменения.
Заключение
Данная программа имеет хороший потенциал, но слишком медленно распознает документы, что говорит о ее усердных стараниях. В некоторых случаях можно использовать более ускоренный, но менее качественный способ распознавания с помощью программы «Клептомания».
computerologia.ru
Как распознать текст? Программа для распознавания текста
Функция распознавания текста может понадобиться в тех случаях, когда нужно перевести текст из книжного формата, в физическом варианте, в электронный. Ну, представим такую ситуацию: у нас есть книга на руках, которую нужно перенести на компьютер в файл Ворд, как будто мы её перепечатали сами с клавиатуры.
Здесь есть два варианта, либо сделать все как нужно, перепечатав текст из книги руками самому, и потратив на это уйму времени, либо второй вариант – это воспользоваться специальной программой для распознавания текста. Одна из таких называется ABBYY FineReader. О ней то мы сегодня и будем говорить.
Программа ABBYY FineReader была разработана специально для осуществления возможности распознавания текста, который отсканирован из книги, журнала, газеты и прочих печатных изданий.
Давайте я на реальном примере покажу Вам, как распознать текст после сканирования или после скачивания уже отсканированной книги, в программе ABBYY FineReader.
Подготовьте программу: найдите её, скачайте, установите, запустите. Подготовьте текст, который вам нужно распознать. Отсканируйте его, если нужно.
А теперь давайте запустим программу ABBYY FineReader. Процесс распознавания текста я буду показывать на примере последней, 11-ой, на данный момент версии.
Распознавание текста в программе ABBYY FineReader
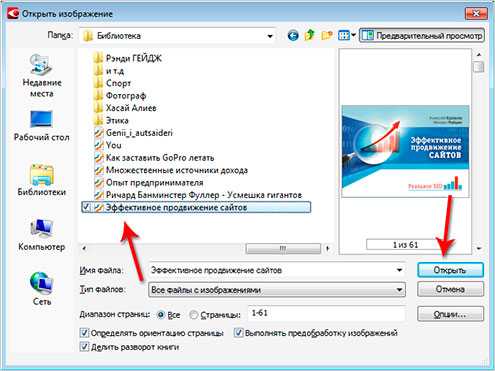
Например, нам нужно книгу в PDF формате конвертировать в обычный текст в страницы Word. Для этого в открывшемся окне программы выбираем задачу «Файл (PDF/изображение) в Microsoft Word».

Нам сразу же предлагают указать на компьютере PDF файл для распознавания текста, который в нём имеется.
В течение нескольких минут выбранный файл будет открываться. Мы можем наблюдать за процессом.
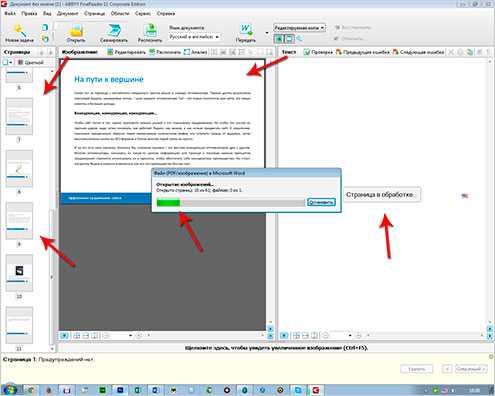
Затем произойдет распознавание текста и по окончанию весь текст программа FineReader переместит в Word файл и откроет его.
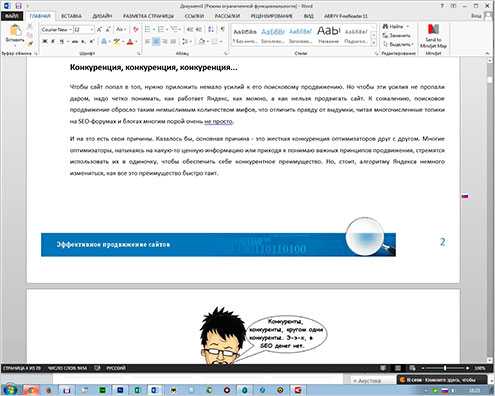
Нам остается только исправить некоторые ошибки, если они будут, и сохранить файл в любое место на своем компьютере.
Кроме этого мы можем сами в программе распознанный текст передать или даже сразу сохранить в Ворд файл.
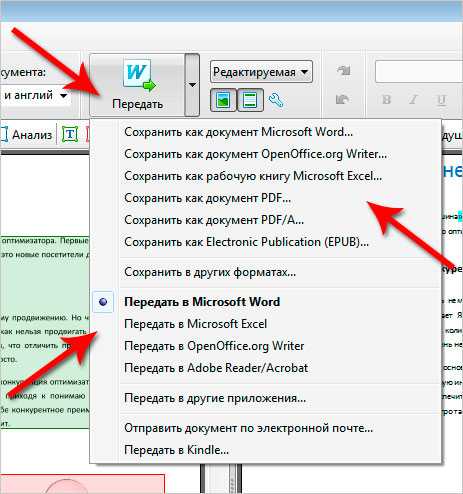
Также в программе ABBYY FineReader можно распознать текст сразу со сканера, то есть кладем печатный вариант в сканер и в программе выбираем чтобы она сразу распознавала текст.
Есть и другие варианты.
Надеюсь эти примеры по распознаванию текста в программе ABBYY FineReader вам понятны и с другими способами вы уже разберетесь сами.
Ранее я уже писал урок про то, как распознать текст, но там мы использовали не программу FineReader, а онлайн сервис. Впрочем, если вам эта тема интересна, то рекомендую почитать этот урок: Как распознать текст онлайн.
Удачи!
Тут был блок “Поделись в соц. сетях”
Интересные статьи по теме:
www.inetkomp.ru
Распознать сканированный текст в word — Финансовая жизнь
Здравствуйте. Сейчас я поведаю, как сканировать текст в документ Word. Для чего это следует сделать?
Ответ очевиден, для предстоящего редактирования текста. Так как изображение не так отредактировать. Что лучше применять, программы либо онлайн сервис для перевода сканированного текста в документ Word?
Об этом я поведаю ниже в статье.
Для того что бы максимально ускорить и упростить задачу. я искал сайты, на которых онлайн возможно преобразовать сканированный документ в формат Word. Для этого мне было нужно сперва сканировать, а после этого уже преобразовать. Сходу сообщу, что многие сайты ограничивают количество переводов в Word, а что бы не ограничено преобразовать необходимо заплатить.
Мне удалось отыскать несколько сайтов, каковые не ограничено решают эту задачу, но делится не буду, поскольку преобразовать сканированный текст в Word онлайн выяснилось безлюдной тратой времени. Процент распознания текста низкий. несложнее было бы перепечатать документ с нуля.
В таком случае, если онлайн инструменты сейчас не хорошо переводят сканированный документ в Word. то как же сделать это максимально как следует? Просматривайте об этом дальше в статье, я приведу понятную инструкцию.
Погулив ещё пара мин., отыскал программу, именуется ABBYY FineReader
Professional. Точно Вы уже слышали про неё. Скачал её тут http://nnm-club.me/forum/viewtopic.php?t=851116. легко устанавливается и превосходно трудится.
ABBYY FineReader может перевести сканированные документы не только в Word, но и в PDF и многие другие текстовые и журнальные форматы.
Пользоваться ею весьма легко. Устанавливаете и запускаете. На мониторе должны заметить вот такое окно, как ниже не скриншоте.
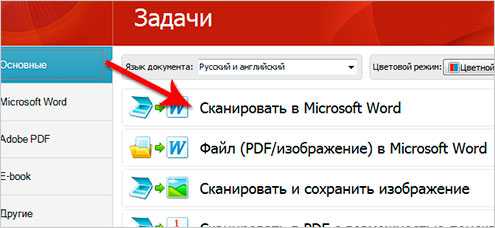
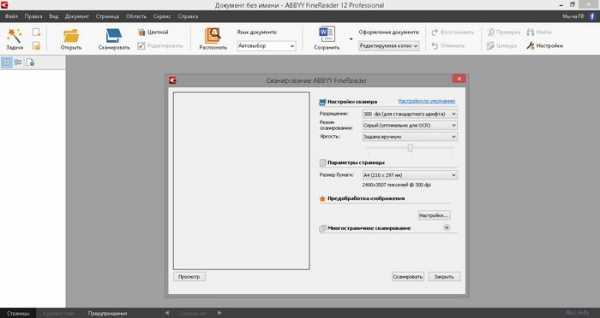
Тут ничего сложного, интуитивно ясно, что необходимо надавить в нашем случае на «Сканировать в Микрософт Word». После этого заметим окно настроек сканирования, в котором возможно ничего не поменять.
Поставим программе не несложную задачу — сканировать и выявить страницу книги. Кладем книгу либо каждый документ на сканер и нажимаем сканировать. Программа начинает сканирование, а после этого обязана машинально выявить документ. В случае если автоматического распознания не случилось. то надавите правой кнопкой на сканированный документ и надавите «Выявить».
Ниже на скриншоте видно какой итог оказался у меня.
Потом нажимаете на значок Word вверху и документ сохранится в текстовый формат документа Микрософт Word. Очевидно необходимо учитывать, что выявленный текст необходимо в обязательном порядке перечитывать, поскольку в любом случае вероятны неточности.
Задавайте вопросы, пишите комментарии. Благодарю за внимание.
Источник: fikc.info
Как бесплатно распознать отсканированный текст
Интересные записи
Похожие статьи, которые вам, наверника будут интересны:
Как преобразовать текст из формата pdf в doc средствами word 2013?
Любому пользователю, трудящемуся с документами в электронном виде на разных устройствах, будь то ноутбук, планшет и тд, довольно часто попадаются PDF…
Как конвертировать pdf в word (doc и docx)
Это также возможно Вам весьма интересно: В данной статье мы разглядим сходу пара способов безвозмездно преобразовать документ PDF в формат Word для его…
Как скопировать иконвертировать изображения jpg в microsoft office word?
Текстовый процессор Микрософт Office Word есть универсальной программой для документов, которая до сих пор остается самым востребованным пользователями…
Как конвертировать pdf в doc (word)
Опубликовано: Сентябрь 4, 2015. Автором: Игорь Приветствую, вас дорогие отечественные читатели. Думаю, вам не требуется растолковывать, что на сегодня…
Методы конвертации файлов pdf в word
Многие из компьютерных пользователей точно неоднократно сталкивались с таковой проблемой. Часто на протяжении работы появляется необходимость выбрать…
Как преобразовать pdf в word в режиме онлайн и оффлайн?
Посредством каких онлайн сервисов и-программ возможно преобразовать PDF в Word? Любому человеку, хоть раз, но приходилось преобразовать PDF в Word….
kbrbank.ru
Как распознать сканированный текст
Компьютер уже уверенно вошел в жизнь рядового гражданина. Когда надо получить сравнительно небольшой объем печатной информации, проще всего набрать этот текст вручную при помощи текстового редактора. Однако иногда надо «переписать» целую книгу. В таких случаях рациональнее всего использовать сканер. Но сам по себе сканер делает только фотокопию текста, которую никак нельзя редактировать. Для того чтобы изменить информацию на полученном изображении, следует провести распознавание документа.
Бесспорным лидером в этом деле является система OCR (англ. optical character recognition – оптическое распознавание текста) от ABBYY -FineReader. Но стоит она довольно дорого и не каждый может позволить себе иметь в своем арсенале такой инструмент. Сегодня мы познакомимся с бесплатной альтернативой Файн Ридера – программой CuneiForm. Приведу сравнительную таблицу возможностей обеих пакетов (табл. 1) Как видим, если хочется бесплатно распознавать текст, придется кое в чем уступить. Первое, с чем придется смириться – неумение CuneiForm работать с некоторыми сканерами (в особенности сканерами МФУ). Поэтому придется сканировать документ при помощи стандартных функций Windows. Второе – надо следить за разрешением сканирования. Это связано стем, что CuneiForm не может обрабатывать большие файлы (свыше 100 Кбайт), а чем выше разрешение, тем больший размер файла-скана. Зато качество распознавания текста в программе намного выше, чем у платного конкурента, а поэтому оптимальным вариантом параметров скана будет 200 dpi (можно и больше, но тогда есть вероятность, что программа просто зависнет). Количество языков тоже невелико, но основные есть. Более того, хоть комбинировать языки и нельзя, зато в CuneiForm есть смешанный англорусский режим распознавания! На этом минусы заканчиваются. Можно начинать установку.
Скачать ABBYY FineReader 11.0.102.583
Установка CuneiForm
Скачать CuneiForm
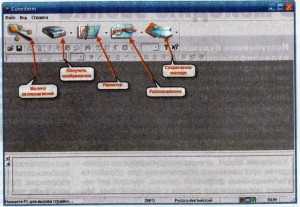 Здесь сложностей нет, поскольку вам поможет инсталлятор. Просто запускайте установочный файл и следуйте инструкциям. После установки в меню «Пуск» появится новый раздел. Открываем его и запускаем CuneiForm.
Здесь сложностей нет, поскольку вам поможет инсталлятор. Просто запускайте установочный файл и следуйте инструкциям. После установки в меню «Пуск» появится новый раздел. Открываем его и запускаем CuneiForm.
Интерфейс CuneiForm намного проще, чем у Fine Reader, и почти не требует настройки. Программой можно полностью управлять благодаря кнопкам на панели инструментов.
Программа может работать в режиме мастера, который активируется первой кнопкой. Но если CuneiForm не поддерживает ваш сканер, то от этого режима стоит отказаться. Следующая кнопка запускает процесс сканирования (опять же, если есть поддержка сканера). На этой и следующих кнопках вы можете заметить небольшие стрелочки. Нажав на них, мы получим доступ к некоторым дополнительным функциям.
Теперь давайте опробуем CuneiForm на практике. Если программа поддерживает ваш сканер, то первой кнопкой, которую следует нажать, будет «Получить изображение». Если же такой возможности нет, то откроем уже готовый скан (поддерживаются форматы JPG, GIF, BMP, PNG (не всегда корректно), а также TIF (в полной мере)).
Теперь следует произвести раз-метку. Она помогает определить блоки, из которых состоит страница. Поддерживается распознавание блоков в виде текста (синяя рамка), рисунков (зеленая рамка) или таблиц (оранжевая рамка) (автоматическую разметку можно доработать вручную, используя контекстное меню блока).
Когда текст обозначен, самое время провести его распознавание. Для этого нажимаем следующую кнопку. По окончании процесса распознавания в рабочем окне отобразится текст, который можно редактировать в небольшом встроенном текстовом редакторе похожем на Microsoft Word. При этом вы сразу сможете увидеть те слова, в которых программа «не уверена» (голубая подсветка) и в которых есть ошибка (сомнительная буква – розовая).
И, наконец, после успешного редактирования можно сохранить результат нашей работы. Кликаем последнюю кнопку на панели инструментов и сохраняем текст как RTF, HTML или ТХТ-файл.
Если же вы желаете большего, то, нажав на стрелочку сбоку, вы сможете выбрать опции экспорта в одну из предложенных программ (Microsoft Word, Excel или Евфрат).
Наверняка вы обратили внимание, что в дополнительных меню кнопок, начиная с «Разметки» и заканчивая «Сохранением», есть в конце пункт «Автомат». Активирование этой опции освобождает вас от нажатия выбранной кнопки. То есть можно автоматизировать процесс обработки скана до того, что вы будете лишь открывать новый документ. Все остальное CuneiForm сделает сама!
Программа изначально настроена самым оптимальным образом, но если вы что-то захотите изменить, просто зайдите в меню «Файл» и выберите опцию «Общие параметры».
Это может пригодиться для смены языка и некоторых других параметров распознавания, форматирования и сканирования текстов.
Пакетное распознавание
На этом можно было бы и закончить, если бы в пакет CuneiForm не входила еще одна утилитка. Откройте «Пуск» снова и в папке с программой обнаружите еще одно приложение – «Пакетное распознавание». Представьте, что вы отсканировали целую книгу и теперь надо ее распознать. Если открывать каждый файл-скан по отдельности, на это уйдет уйма времени, пакетный же режим представляет возможность указать нужные файлы, а об остальном программа позаботится сама.
Для начала нужно создать новый пакет файлов. Нажимаем соответствующую кнопку и следуем подсказкам запустившегося мастера.
На последнем этапе мы можем либо просто сохранить наш пакет, либо начать немедленное распознавание. В последнем случае запустится режим распознавания, который может затянуться на несколько минут (в зависимости от количества файлов-сканов).
По окончании распознавания вы сможете увидеть в основном окне все распознанные документы. Если распознавание прошло успешно, то в левой боковой панели вы обнаружите активными только два списка: «Исходные» и «Обработанные». Если же будут файлы, которые не удалось распознать, их мы найдем в разделе «Ошибки».
Теперь остается только сохранить полученные файлы и радоваться жизни. Потенциал у CuneiForm явно хороший, однако разработка ведется довольно медленно. Несмотря на открытый исходный код, компания Cognitive, видимо, очень требовательна к разработчикам, раз прогресс так долго не появляется. Остается только надеяться, что дело сдвинется с мертвой точки и программа станет еще лучшей, а пока довольствуемся малым. Но такое ли уж оно и малое… Выбор за вами!
Вам также может пригодиться еще одна довольно занятная программа. Kleptomania, пусть и не полноценная система распознавания, но может помочь вам захватить текст и графику с экрана для последующей обработки.
Руслан ТЕРТЫШНЫЙ
vse-o-kompyutere.ru
Как распознать текст с фото или сканированного документа – Софт
Как распознать текст с фотографии или сканера?
Не зависимо от того опытный Вы пользователь или же новичок, рано или поздно каждый сталкивается с необходимостью распознания текста с фото или сканера. Дело в том, что это очень удобно! Например у Вас есть отпечатанный, нужный Вам документ, но к сожалению, как это часто бывает, он у Вас только в одном экземпляре и конечно электронного варианта у Вас тоже нет, и тут Вы нашли в тексте ошибку, что же делать, перепечатывать весь текст из-за одной буквочки? Кстати, многие так и делают, они даже и не догадываются о том, что это все можно сделать на много проще, а главное, примерно в 100 раз быстрее!!!
Показываю как распознать текст с фото или сканера
Для начала нам нужна программка которая называется ABBYY FineReader. Дело в том, что эта программа не бесплатна и не активировав её, Вы просто не сможете распознать текст, так как эта функция будет просто заблокирована. По этому идем сюда и качаем полностью рабочую версию.
После того как Вы установили программу и активировали её, у Вас появится главное окно программы:
Я
взял фото страницы с книжки на котором покажу Вам весь процесс от А до Я. Итак,
начнем.
Нажимаем кнопку Scan&Readв программе:
После этого у Вас появится окошко:
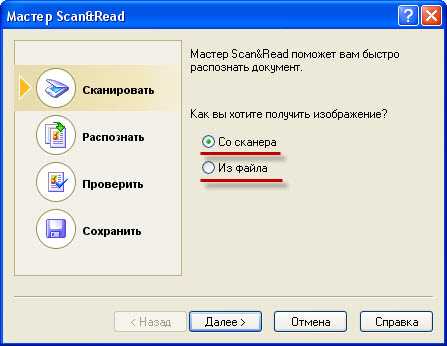
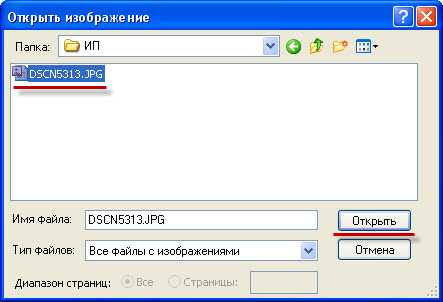
Здесь Вам предлагают выбрать источник информации, со сканера или из файла. Если Вы сканируете, то выбираете “Со сканера”, если у Вас уже есть отсканированное или сфотографированное изображения, как у меня, то выбираем “Из файла” и жмем “Далее”. Если Вы выбрали сканер, значит у Вас начнется сканирование документа, а если из файла, то появится окно, в котором нужно будет указать Ваш подготовленный файл:
После добавления или сканирования документа, появится предложение выполнить следующий шаг – Распознание:
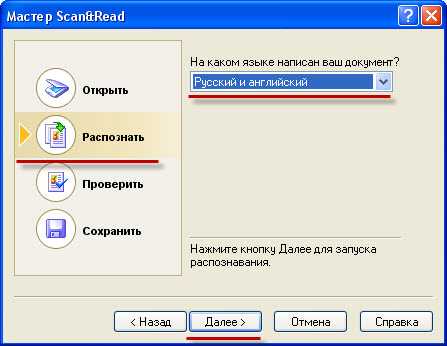
В появившемся окне Вам нужно будет указать параметр “На каком языке написан Ваш документ”, выбираем преимущественно используемые языки в Вашем документе и жмем “Далее”. Программа начнет распознавать Ваш документ. Появится шкала выполнения:
После завершения распознания текста, переходим в программу и смотрим на качество распознания (распознанный текст находится справа в главном окне программы).
Если в распознанном тексте у вас есть буквы или слова подсвечены бирюзовым оттенком, то это означает, что эти области нужно отредактировать, так как из-за плохого качества оригинала программе не удалось точно распознать букву, цифру и т.п. Для редактирования нажимаем левой кнопкой мыши по подсвеченном участке в распознанном тексте и программа сразу же в нижней части главного окна, показывает нам этот участок на сканированном документе или фото, то есть на оригинале. Смотрим на документ и исправляем ошибки в тексте. Обычно, если оригинал качественный (текст четкий, сильно не размазанный, сильно не затертый) то ошибок в распознании может не быть вообще. После редактирования, выделяем текст и копируем его в Wordили Блокнот, в общем, куда хотите.
Важно: (Если после распознания, весь текст у Вас подсвечен как неправильно распознанный, вернитесь и правильно установите параметр “На каком языке написан Ваш документ”).
Да, кстати, не забудьте исправить опечатку, из-за которой все это было затеяно! УДАЧИ!!!
www.vashmirpc.ru
Программа для сканирования и распознавания текста с картинки Capture2Text
Привет!
Сегодня я расскажу о программе, которая способна распознавать текст с любого изображения, сохранять его в буфер обмена, сразу же переводить на нужный язык, отображать и даже произносить вслух. Программа называется Capture2Text, она совершенно бесплатна, не требует установки (портативная), поддерживает распознание около 90 языков, и позволяет сразу переводить выделенный фрагмент .Как скачать Capture2Text
Можете сразу скачать Capture2Text с моего Яндекс Диска архивом (для Windows 32bit):
Скачать Capture2Text
Также можете зайти на официальный сайт разработчика capture2text.sourceforge.net, и скачать Capture2Text, это будет гарантированно самая свежая версия программы. Для этого нажимаем Download в оглавлении страницы, или прокручиваем ее до нужного пункта:
Там кликаем по ссылке:
В появившемся окне можно нажать на зеленую кнопку для скачивания последней версии (на Windows 64-битной разрядности), либо выбрать верхнюю папку из списка:
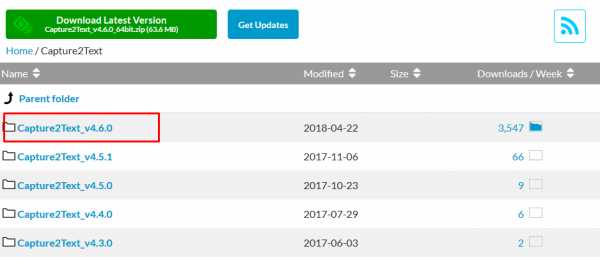
В папке находится два файла Capture2Text: для 64-битных и 32-битных разрядных систем. Как узнать, какая у вас Windows — 32 или 64 бит, читайте в статье по ссылке. Кликаем по архиву с нужной системой и загрузка начнется автоматически (возможно, через несколько секунд).
Дальше процесс загрузки стандартный – программа сохранится по умолчанию в папке «Загрузки».
Оттуда разархивируем файлы в подходящую папку на нужном диске. Открываем эту папку и кликаем по ярлыку с названием программы.
Она сразу же должна попасть в трей и отображаться там в виде такого вот значка:
Программа сразу же становится активной, и ей можно уже пользоваться.
Как пользоваться Capture2Text
Чтобы распознать текст с картинки при помощи Capture2Text, вам необходимо направить указатель мыши в крайнюю точку выделяемого отрывка и нажать на комбинацию клавиш (Win + Q). Протягиваем указатель до противоположного угла текста и нажимаем на левую кнопку мыши. Вы также можете перетащить выделенную площадку, нажав раньше правую кнопку мыши.
Появится вот такое окошко, в котором будет написан наш отсканированный с фотографии, картинки или pdf-файла текст. Также этот текст поместится в буфер обмена. Поэтому вы сможете его вставить в любой текстовый документ, например, Word.
Как видно на скрине, последнее слово программа отобразила неправильно из-за маленького расстояния между буквами на фото. Это можно исправить в настройках.
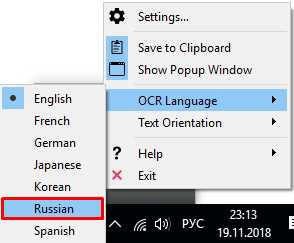
Если вы выделили отрывок русского текста, скорее всего, программа вам покажет белиберду. Это все из-за того, что по умолчанию стоит английский язык распознания. Чтобы его изменить, нажимаем правой кнопкой мыши по значку Capture2Text , из раскрывшегося меню выбираем OCR language и кликаем по нужному языку (русский).
Настройки Capture2Text
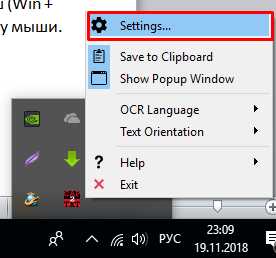
Настроек в этой программе для распознания текста на картинках jpg достаточно много. Рассмотрим лишь основные, которые наиболее важны при использовании Capture2Text. Итак, для начала заходим в настройки, кликнув правой кнопкой мыши по значку программы и выбрав Settings:
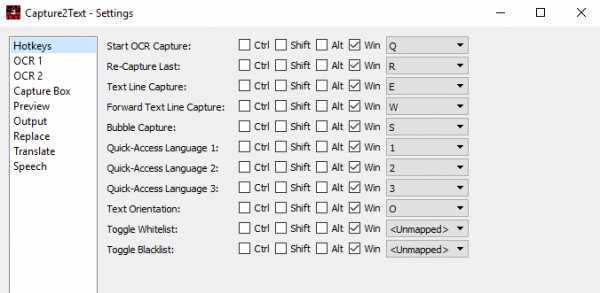
- В окне Hotkeys можно настроить горячие клавиши для активации различных функций программы.
- Start OCR Capture – выделение отрывка текста для сканирования и распознания.
- Re-Capture Last – повторяет предыдущий распознанный текст.
- Text Line Capture – выделяет сразу всю строчку. Для этого нужно поставить указатель мыши на начало выделяемой строчки и нажать комбинацию клавиш (по умолчанию: (Win+E).
Остальные функции горячих клавиш, я думаю, вы сможете сами понять, воспользовавшись хотя бы переводчиком для текста на фотографии Capture2Text. Как им пользоваться, читайте дальше.
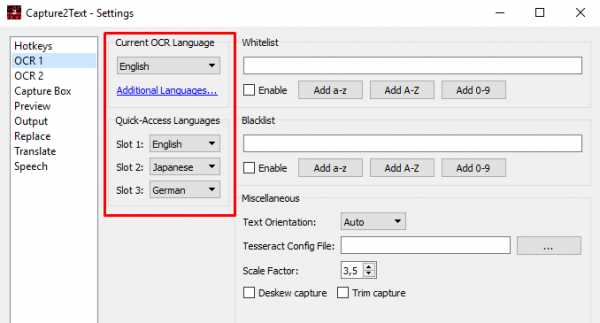
- OCR Здесь наиболее важные настройки – это текущий язык (вверху выделения), а также быстро переключающиеся языки. Вы можете выбрать любые три языка, между которыми легко переключаться с помощью горячих клавиш. Назначение этих клавиш мы можем изменить в предыдущей вкладке Hotkeys, для пунктов Quid-Access Language 1,2,3.
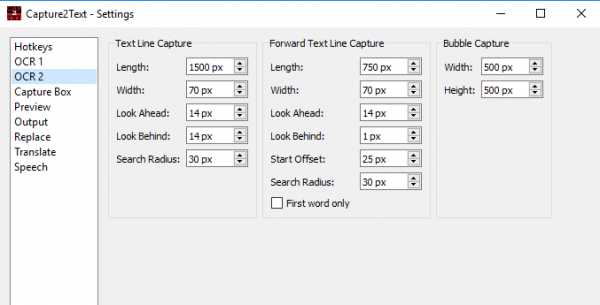
- OCR 2 – здесь можно настроить различные параметры выделения и распознания.
- Capture Box – настраиваем цвет рамки, которой выделяются части текста на картинке, а также цвет фона этой рамки.
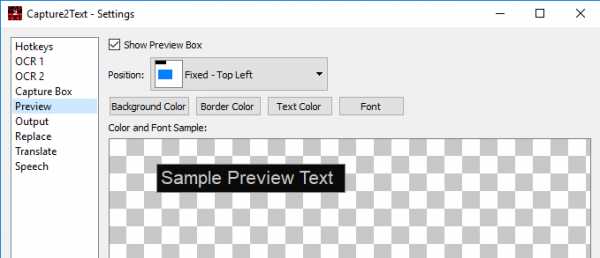
- Preview – настройка вида и положения окна предпросмотра. Его можно вообще убрать, сняв галочку с пункта Show Preview Box.
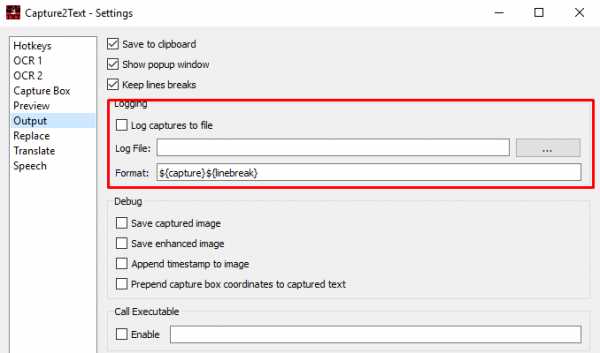
- Output. Здесь наиболее важной является возможность сохранения отсканированного текста в указанную папку (log file) в определенном формате (format). Также можно настроить сохранение выделенных картинок.
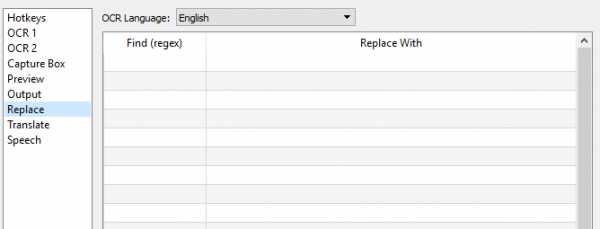
- Во вкладке Replace можно настроить автоматическую замену слов, букв или символов на другие элементы.
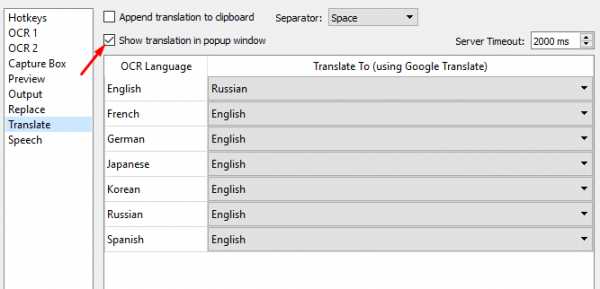
- Translate – поставьте галочку напротив Show translation in popup window, чтобы во всплывающем окне отображался перевод отсканированных отрезков текста. В первой колонке стоит изначальный язык, во второй – тот, на который его нужно перевести.
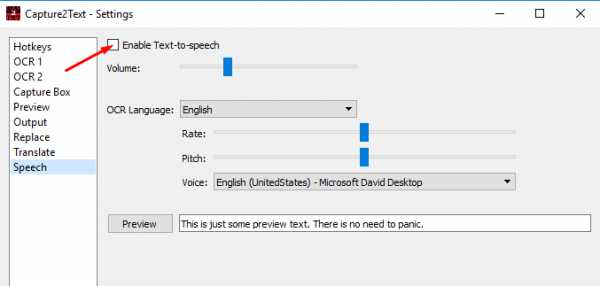
- Speech – отметьте галочкой пункт Enable Text-to-speech чтобы выделенные тексты произносились вслух. Тут можно настроить голос диктора, скорость, громкость.
Пожалуй, на этом я завершу обзор программы для распознания текста на фото и картинках Capture2Text. Понимаю, что не раскрыл полностью все возможности этой замечательной программки, но, думаю, что основные ее функции все же описал. Если у вас возникнут вопросы по настройке или использованию Capture2Text, задавайте их в комментариях.
comp-doma.ru