
PLSQL Developer — Просмотр плана запроса в окне сессий
Главная > Others > PLSQL Developer — Просмотр плана запроса в окне сессийPLSQL Developer — Просмотр плана запроса в окне сессий
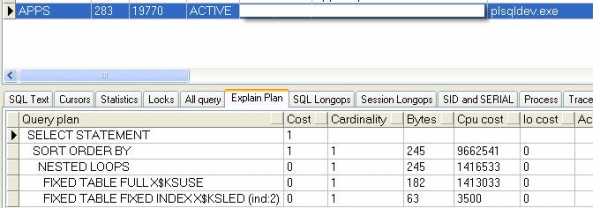
.
В окне сессий жмем на изображение ключа (Define Session Queris), в появившемся окне переходим на вкладку Details
.
.
rudev.wordpress.com
Понимание результатов Execute Explain Plan в Oracle SQL Developer
Результат EXPLAIN PLAN – это отладочный вывод оптимизатора запросов Oracle. COST – это конечный результат оптимизатора затрат (CBO), целью которого является выбор того, какой из множества возможных планов должен использоваться для запуска запроса. CBO рассчитывает относительную стоимость для каждого плана, затем выбирает план с самой низкой стоимостью.
(Примечание: в некоторых случаях СВО не имеет достаточно времени, чтобы оценить каждый возможный план, в таких случаях он просто выбирает план с наименьшей стоимостью найденную до сих пор)
В общем, один из самых больших вкладчиками медленного запроса является количество строк, считанных для обслуживания запроса (точнее, блоков), поэтому стоимость будет основана на в части на количестве строк, которые должны быть прочитаны оценками оптимизатора.
Например, предположим, что у вас есть следующий запрос: (. Колонку months_of_service имеет NOT NULL ограничение на него и обычный индекс на нем)
SELECT emp_id FROM employees WHERE months_of_service = 6;
Есть два основных планов оптимизатору может выбрать здесь:
- План 1: Прочитайте все строки из таблицы «сотрудники», для каждого, проверить, если предикат истинен (
- План 2: прочитать индекс, где
months_of_service=6(это приводит к набору ROWID), затем получить доступ к таблице на основе возвращенных ROWID.
Представим себе, что таблица «сотрудники» имеет 1 000 000 (1 миллион) строк. Предположим далее, что значения для months_of_service варьируются от 1 до 12 и по какой-то причине довольно равномерно распределены.
Стоимость План 1, в котором используется ПОЛНЫЙ СКАНИРОВАНИЕ, будет стоить чтение всех строк в таблице сотрудников, что примерно равно 1 000 000; но поскольку Oracle часто может считывать блоки с использованием многоблочных чтений, фактическая стоимость будет ниже (в зависимости от того, как настроена ваша база данных) – например, давайте представим, что количество отсчетов с несколькими блоками равно 10 – расчетная стоимость полного сканирования составит 1,000,000/10; Общая стоимость = 100 000.
Стоимость плана 2, который включает в себя УКАЗАТЕЛЬ диапазон сканирования и просмотра таблицы по ROWID, будет стоимость сканирования индекса, плюс стоимость доступа к таблице с помощью ROWID. Я не буду вдаваться в то, как сканирование индексов диапазона стоит, но давайте представим, что стоимость сканирования диапазона индексов – 1 на строку; мы ожидаем найти совпадение в 1 из 12 случаев, поэтому стоимость сканирования индекса составляет 1,000,000/12 = 83,333; плюс стоимость доступа к таблице (предположим, что 1 блок считывается за доступ, мы не можем использовать многоблочные чтения здесь) = 83,333; Общая стоимость = 166 666.
Как вы можете видеть, стоимость плана 1 (полное сканирование) меньше, чем стоимость плана 2 (индексное сканирование + доступ по rowid) – это означает, что CBO будет выбирать ПОЛНОЕ сканирование.
Если предположения, сделанные здесь оптимизатором, верны, то на самом деле план 1 будет предпочтительным и намного более эффективным, чем План 2, – который опровергает миф о том, что ПОЛНЫЕ сканирования «всегда плохие».
Результаты будут совсем другими, если целью оптимизатора было FIRST_ROWS (n) вместо ALL_ROWS – в этом случае оптимизатор будет поддерживать план 2, потому что он будет часто возвращать первые несколько строк быстрее, ценой менее эффективной для всего запроса.
stackoverrun.com
PL/SQL Developer. Выполнение запросов и редактирование данных. — Way23
Выполнение запросов
После подключения добавляем новое Sql-окно
Пишем запрос, нажимаем F8 или кнопку на панели инструментов и получаем таблицу — результат запроса.
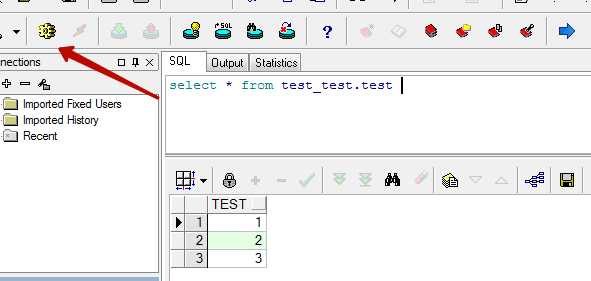
Если в результате запроса возвращается много строк то сразу все они не загружаются. Загружаются столько строк сколько помещается на экране, для загрузки остальных строк становятся активны две кнопки
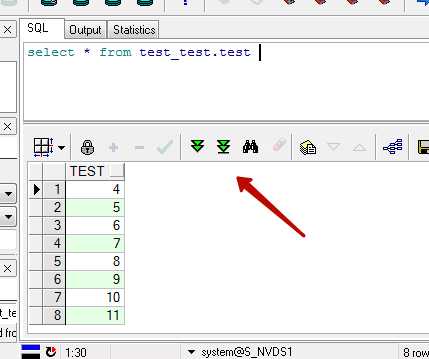
Чтобы загрузить все записи нужно нажать правую.
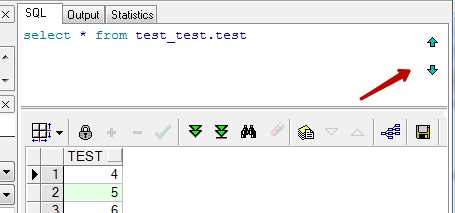
История запросов
Если отправить несколько запросов подряд то справа становятся доступны кнопки по которым можно переключатся по истории запросов. Кнопка «вверх» отобразит предыдущий отправленный запрос, а кнопка «вниз» следующий.
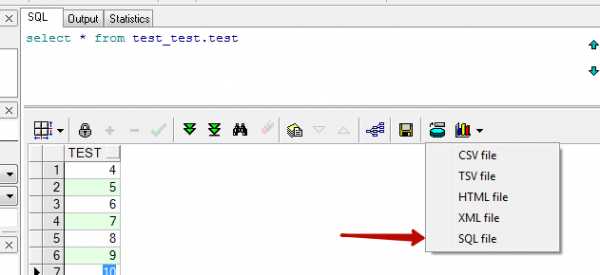
Экспорт результатов запроса
Часто результат запроса нужно экспортировать, для этого есть отдельная кнопка. Экспортировать можно в том числе в виде Sql скрипта который будет содержать insert’ы выбранных записей
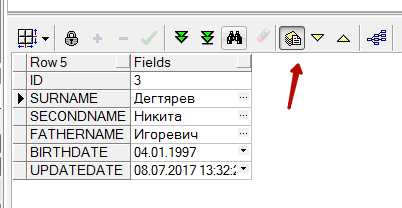
Режим просмотра одиночной записи
В случае если в таблице много полей бывает полезен режим просмотра одиночной записи. В этом случае выводится таблица с двумя столбцами — название поля и значение. Переключение по записям происходит по кнопкам на панели инструментов.
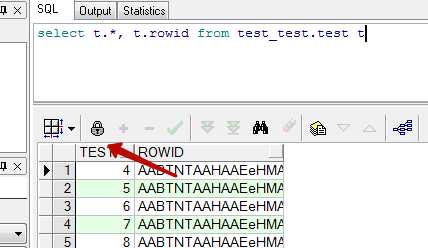
Редактирование данных которые вернул запрос
Для того чтобы отредактировать записи которые попали в выборку, в запрос нужно добавить специальное поле rowid.
Теперь после нажатия на кнопку с замком, активируется режим редактирования, в котором доступны кнопки для добавления и удаления записей.
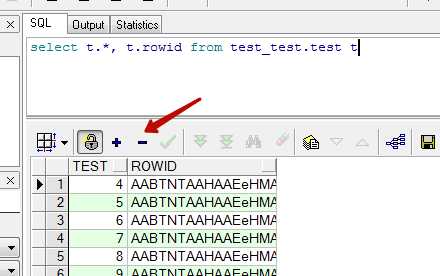
Редактирование осуществляется в самой таблице
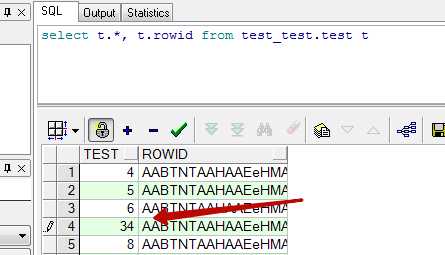
Для сохранения изменений нужно нажать две кнопки — Post и Commit.
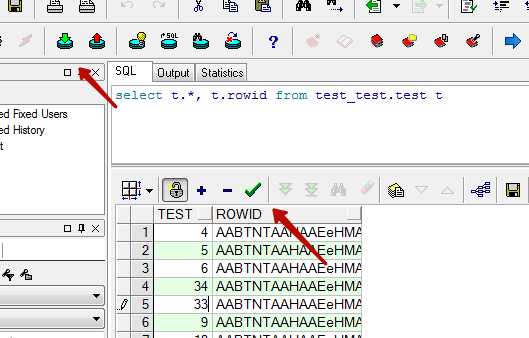
Откатить не зафиксированные изменения можно кнопкой Rollback
Если вы нашли ошибку, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.
[sql-execution-plan] Понимание результатов Execute Explain Plan в Oracle SQL Developer [oracle-sqldeveloper]
Вывод EXPLAIN PLAN – это отладочный вывод оптимизатора запросов Oracle. COST – это конечный результат оптимизатора затрат (CBO), целью которого является выбор того, какой из множества возможных планов должен использоваться для запуска запроса. CBO рассчитывает относительную стоимость для каждого плана, затем выбирает план с самой низкой стоимостью.
(Примечание: в некоторых случаях у CBO не хватает времени для оценки всех возможных планов, в этих случаях он просто выбирает план с самой низкой стоимостью, найденной до сих пор)
В общем, одним из самых больших вкладов в медленный запрос является количество строк, считываемых для обслуживания запроса (точнее, блоков), поэтому стоимость будет частично зависеть от количества строк, которые будут оценены оптимизатором читать.
Например, скажем, у вас есть следующий запрос:
SELECT emp_id FROM employees WHERE months_of_service = 6;
(В столбце months_of_service есть ограничение NOT NULL и обычный индекс на нем.)
Существует два основных плана, которые может выбрать оптимизатор здесь:
- План 1: Прочитайте все строки из таблицы «сотрудники», для каждого проверьте, является ли предикат истинным (
- План 2: Прочитайте индекс, где
months_of_service=6(это приводит к набору ROWID), затем получите доступ к таблице на основе возвращенных ROWID.
Представим себе, что таблица «сотрудники» имеет 1 000 000 (1 миллион) строк. Предположим далее, что значения для months_of_service варьируются от 1 до 12 и по какой-то причине довольно равномерно распределены.
Стоимость Плана 1 , которая включает ПОЛНЫЙ СКАНИРОВАНИЕ, будет стоить для чтения всех строк в таблице сотрудников, что примерно равно 1 000 000; но поскольку Oracle часто может считывать блоки с использованием многоблочных чтений, фактическая стоимость будет ниже (в зависимости от того, как настроена ваша база данных) – например, предположим, что количество чтения с несколькими блоками равно 10 – расчетная стоимость полное сканирование будет 1 000 000/10; Общая стоимость = 100 000.
Стоимость Плана 2 , которая включает в себя сканирование индексов INDEX RANGE и поиск таблицы по ROWID, будет стоить сканирование индекса, а также затраты на доступ к таблице с помощью ROWID. Я не буду вдаваться в то, как сканирование индексов диапазона стоит, но давайте представим, что стоимость сканирования диапазона индексов – 1 на строку; мы ожидаем найти совпадение в 1 из 12 случаев, поэтому стоимость сканирования индекса составляет 1,000,000 / 12 = 83,333; плюс стоимость доступа к таблице (предположим, что 1 блок считывается за доступ, мы не можем использовать многоблочные чтения здесь) = 83,333; Общая стоимость = 166 666.
Как вы можете видеть, стоимость плана 1 (полное сканирование) меньше, чем стоимость плана 2 (индексная проверка + доступ по rowid), что означает, что CBO будет выбирать ПОЛНОЕ сканирование.
Если предположения, сделанные здесь оптимизатором, верны, то на самом деле план 1 будет предпочтительным и гораздо более эффективным, чем План 2, – который опровергает миф о том, что ПОЛНЫЕ сканирования «всегда плохие».
Результаты были бы совсем другими, если целью оптимизатора было FIRST_ROWS (n) вместо ALL_ROWS – в этом случае оптимизатор предпочтет план 2, потому что он будет часто возвращать первые несколько строк быстрее, ценой менее эффективной для всего запроса ,
code-examples.net
oracle.notes: PL/SQL Developer session window
В окне списка сессий PL/SQL Developer (Tools -> Sessions) можно добавить кучу полезных вкладок, которые будут выполнять скрипты и запросы, получая любое значение из подсвеченной сессии в списке через :[ИМЯ_КОЛОНКИ v$session]. В настоящее время в стоковом PL/SQL Developer (версия 11) есть 5 вкладок:
Cursors
SQL Text
Statistics
Locks
Sql Monitor
Добавлять свои вкладки можно при помощи кнопки с гаечным ключиком -> Details
В настоящий момент я использую
План запроса dbms_xplan
Особое внимание /* concatenate */ из последней строчки – результат будет сцеплен в одно поле, его можно скопировать и вставить в другое окно для детального анализа.
SELECT t.plan_table_output || CHR(10) plan_table_output
FROM table(dbms_xplan.display_cursor(:sql_id, :sql_child_number,format => 'ADVANCED')) t
План запроса из v$
SELECT decode(id, 1, child_number) || decode(:sql_address, '00', '-P') AS c,
output_rows AS tot_r,
last_output_rows AS r,
rpad(' ', depth * 3) || operation || ' ' || options ||
nvl2(object_name, ' -> ', '') || object_name AS op,
cost,
cardinality AS card,
bytes,
access_predicates AS "ACCESS",
filter_predicates AS filter,
round(temp_space / 1024 / 1024) AS temp_mb,
partition_start || nvl2(partition_start, ' - ', '') || partition_stop AS p,
partition_id,
other,
other_tag,
cpu_cost,
io_cost,
distribution,
object_owner,
optimizer,
position,
search_columns,
executions,
last_starts,
starts,
last_cr_buffer_gets,
cr_buffer_gets,
last_cu_buffer_gets,
cu_buffer_gets,
last_disk_reads,
disk_reads,
last_disk_writes,
disk_writes,
round(last_elapsed_time / 1000000, 2) AS last_ela_time,
round(elapsed_time / 1000000, 2) AS elapsed_time,
policy,
estimated_optimal_size,
estimated_onepass_size,
last_memory_used,
last_execution,
last_degree,
total_executions,
optimal_executions,
onepass_executions,
multipasses_executions,
round(active_time / 1000000, 2) AS active_time_avg,
max_tempseg_size,
last_tempseg_size
FROM (SELECT *
FROM v$sql_plan_statistics_all
WHERE address = hextoraw(:sql_address)
AND hash_value = :sql_hash_value
UNION ALL
SELECT *
FROM v$sql_plan_statistics_all
WHERE address = hextoraw(:prev_sql_addr)
AND hash_value = :prev_hash_value) t
CONNECT BY address = PRIOR address
AND hash_value = PRIOR hash_value
AND child_number = PRIOR child_number
AND PRIOR id = parent_id
START WITH id = 1
ORDER BY address, hash_value, child_number DESC, id, positionSQL Workarea
Объем памяти, потребляемой сессией. Правда не очень часто пригождается
SELECT operation_type,
policy,
estimated_optimal_size,
estimated_onepass_size,
last_memory_used,
last_execution,
last_degree,
total_executions,
optimal_executions,
onepass_executions,
multipasses_executions,
active_time,
max_tempseg_size,
last_tempseg_size
FROM v$sql_workarea
WHERE address = hextoraw(:sql_address)
AND hash_value = :sql_hash_valueТаким способом достаточно удобно заниматься troubleshooting’ом, если известа сессия, которая испытывает проблемы. Очень удобный и мощный механизм.
oraclememz.blogspot.com
oracle – Как оптимизировать запрос с помощью PL/SQL Developer?
У меня есть запрос ~ 53 строк кода, и мне нужно его оптимизировать. У меня есть инструмент PL/SQL Developer 7.0 и как его использовать для оптимизации?
Я попытался использовать Explain Plan, но мне ничего не сказано. Я также добавил столбцы времени и времени, но нет ничего интересного, сначала пустое и второе всегда в одно и то же время.
Я попытался использовать тестовое окно, но есть процедура, для которой требуется вставка переменной, и поскольку мой запрос выбирает многие строки, я не могу его использовать.
Итак, вопрос в том, как я могу оптимизировать SQL-запрос с помощью PL/SQL Developer? Где я должен искать, чтобы получить время выполнения запроса для каждого подзапроса? Может быть, есть несколько гидов, но на данный момент я нашел только документацию, но мне не было полезно передо мной? Для моих текущих знаний невозможно оптимизировать такой большой запрос без каких-либо инструментов.
Запрос, требующий оптимизации:
select count(PRODUCT_NUMBER)
from
(select W.SUID,
I.SUID,
W.PRODUCT_NUMBER,
MI.ML_NUMBER,
I.TITLE_TRANSLIT,
I.COUNTRIES,
QTY.REMAINS,
QTY.ACQ_PRICE_USD,
QTY.REMAINS * QTY.ACQ_PRICE_USD as TOTAL
from (select UID_WARE,
QTY as REMAINS,
ACQ_PRICE_USD
from (select UID_WARE,
PRODUCT_NUMBER,
NVL(sum(QTY_ON_STOCK), 0) - NVL(sum(ADD_IN_QTY), 0) + NVL(sum(ADD_OUT_QTY), 0) as QTY,
ACQ_PRICE_USD as ACQ_PRICE_USD
from (select SI.UID_WARE,
W.PRODUCT_NUMBER,
count(distinct STK.SUID) as QTY_ON_STOCK,
sum(case
when 1 = 1 then
DECODE('' , SM.UID_SOURCE_LOCATION, SM.QTY, 0)
else 0
end) as ADD_OUT_QTY,
sum(case
when 1 = 1 then
DECODE('' , SM.UID_DEST_LOCATION, SM.QTY, 0)
else 0
end) as ADD_IN_QTY,
ROUND(ACQ.PRICE_USD, 2) as ACQ_PRICE_USD
from STOCK_MOVEMENTS SM
join STOCK_ITEMS SI on SM.UID_STOCK_ITEM = SI.SUID
left outer join (select PR.UID_STOCK_ITEM,
DECODE(NVL(CR.RATE, 0), 0, 0, PR.PRICE / CR.RATE) as PRICE_USD
from MV_STOCK_ACQ_PRICES PR,
CURRENCY_RATES CR
where PR.PRICE_DATE = CR.RATE_DATE
and PR.UID_CURRENCY = CR.UID_CURRENCY) ACQ on ACQ.UID_STOCK_ITEM = SI.SUID
join WARES W on W.SUID = SI.UID_WARE
left outer join (select distinct STK.SUID,
STK.QTY_REMAINS
from STOCK_ITEMS STK
where STK.UID_STOCK_LOCATION != 'MS-STL-SALED'
) STK on STK.SUID = SI.SUID
where 1 = 1
group by SI.UID_WARE,
W.PRODUCT_NUMBER,
ACQ.PRICE_USD
) T
group by T.UID_WARE,
T.PRODUCT_NUMBER,
ACQ_PRICE_USD)) QTY
join WARES W on W.SUID = QTY.UID_WARE
join INVENTORY I on I.SUID = W.UID_ISSUE
join MAP_INFO MI on MI.SUID = I.SUID
where REMAINS != 0
and w.UID_SECTION in ('MS-SEC-BOOKS', 'MS-SEC-MAPS'))
qaru.site
Приемы работы с планами выполнения запросов в Oracle / Блог компании Embarcadero (Borland) / Хабр
Это как гвоздь в подошве любимого ботинка. Ходить можно, но все чаще ловишь себя на желании остаться на месте или перепоручить дело другим. Мелкие неудобства не только замедляют нашу работу, но и снижают мотивацию, вносят помехи в процесс, снижают качество результата. И если нашелся друг, который научил вас взять молоток и забить этот гвоздь, вы не только будете благодарны ему за помощь, но и сами поможете другим, избавив их от мелкой, но очень раздражающей помехи. Для этого и нужно общаться, делиться не только глубокими и сокровенными знаниями в форумах и на сайтах вроде Хабра, но и своими простыми трюками и «маленькими хитростями»Как и любой текст, запросы и программы на SQL можно создавать в любом текстовом редакторе. Но если вы профессионал, вы очень много и часто работаете с SQL, то вам уже не будет достаточно наличия подсветки синтаксиса и автоматического переформатирования кода, особенно, если вам приходится переключаться между различными версиями одной СУБД или разными платформами СУБД.
Недавно мне случилось общаться с одним из ведущих профессионалов СУБД Oracle. Он рассказал много интересного про работу с планами выполнения запросов в различных версиях этой СУБД и не постеснялся рассказать всем об используемых им инструментах, приемах и дать немного полезных мелких советов. Я сделал перевод одной из статей в его блоге и хотел бы предложить его вниманию Хабравчан. Несмотря на то, что описанный прием применялся для работы с Oracle, я теперь с успехом применяю тот же подход для MS SQL и Sybase.
Меня зовут Дан Хотка (Dan Hotka). Я директор Oracle ACE. Одной из моих привилегий в этой группе является помощь в распространении информации и полезных технических знаний, связанных с СУБД Oracle. Меня хорошо знают после моих 12 (скоро 14) опубликованных книг и буквально сотен статей. Я регулярно пишу в блоге и собираюсь делать это в дальнейшем. Мы даже могли встречаться на одном из событий или встреч группы пользователей. Я регулярно выступаю на эти темы по всему миру.
Я собираюсь поделиться с вами как техническими знаниями про Oracle, так и тем, как эти знания применяются в решениях Embarcadero.
Я скачал себе «большую тройку» продуктов Embarcadero: Rapid Sql, DBArtisan, DB PowerStudio. Сейчас я хотел бы рассказать о первом впечатлении и некоторых приемах работы с планами выполнения запросов в RapidSQL. (Я установил версию 8.6.1)
Я покажу пару приемчиков для планов выполнения запросов в и вокруг Rapid SQL.
Мне нравится инструмент. Конечно, это прекрасный инструмент, если у вас есть разные типы СУБД различных производителей, поскольку этот инструмент поддерживает около дюжины разных СУБД. Единый интерфейс для освоения всех БД! Мои приемчики относятся к Oracle. Но приемы для инструментов Embarcadero должны сработать вне зависимости от того, к какой СУБД вы подключились.
При просмотре планов выполнения я люблю видеть план выполнения и сам запрос одновременно.
Этого легко достигнуть.
Для начала, загрузите свой SQL запрос в окно редактора ISQL (используя кнопку Open), затем включите кнопку Explain Plan (отмечена в красном круге). Кнопка останется активированной.
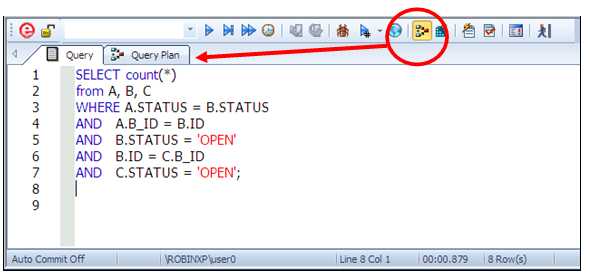
Запустите запрос на выполнение, и появится закладка Query Plan, заполненная планом выполнения.
Поместите курсор мыши на любой из узлов на диаграмме и появится дополнительная полезная информация, относящаяся к этому шагу выполнения из плана запроса!
По умолчанию, Rapid SQL показывает план выполнения в графическом виде. Я вышел из старого мира оптимизации…. Предпочитаю текстовую версию, поэтому нажимаю правую кнопку мыши в окне с планом и выбираю “View as Text”.
Предпочитаю видеть текст запроса и план одновременно.
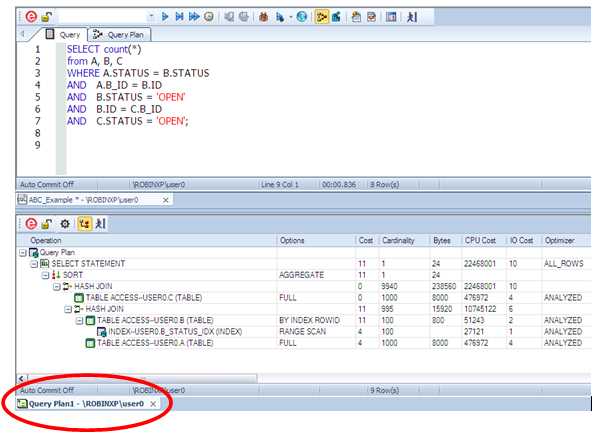
Это легко сделать. Видите закладки окон ISQL внизу главного окна? Для начала мы должны настроить Rapid SQL, чтобы он выдавал план в отдельном окне.
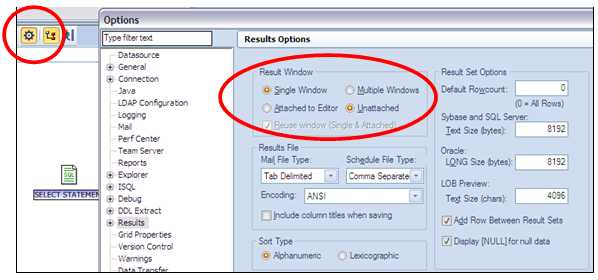
Нажмите кнопку Options (левый красный кружок) и затем установите опцию ‘Unattached’ для Result window. Это приведет к созданию двух отдельных закладок внизу Rapid SQL, после запуска запроса на выполнение. Просто протащите немного это окно за закладку и появится прямоугольник, куда можно переместить это окно.
Или можно воспользоваться пунктом Tile windows из главного меню программы
И еще: все это так же работает и в DBArtisan — решении для администраторов баз данных.
via
habr.com