
Какие есть программы для распознавания текста рукописного текста?
Оцифровка написанного от руки текста — проблема, которая появилась несколько лет назад и остается актуальной. Почерк очень сильно отличается, поэтому сложно создать программу, которая сможет распознавать любой из существующих. Кроме того, многие люди пишут очень неразборчиво, из-за чего часть букв сливается и становится непонятной утилите. На сегодняшний день не существует ПО, которое с 90-100% вероятностью сможет разобраться написанный от руки текст.
Единственным вариантом является программа для распознавания рукописного текста, доступная по этой ссылке http://idr.in.ua/info/rukopisniy-tekst.html. Обратите внимание, что она платная и распознает только разборчиво написанные слова (примеры приведены по указанной ссылке).
Автор считает, что эти материалы могут вам помочь:
Распознавание отсканированного текста
Если вам необходимо распознать не рукописный, а напечатанный текст, изучите представленный ниже вариант ПО.
ABBYY FineReader Online
ABBYY FineReader более 10 лет поставляет различные утилиты для работы с отсканированным текстом. Первые программы работали не очень качественно, но современные алгоритмы, позволяют распознавать 95-100% отсканированного текста на знакомом программе языке. Утилита работает с самыми популярными языками планеты.
ПО, разрабатываемое компанией ABBYY FineReader платное, но если у вам необходимо распознать всего несколько листов, вы можете воспользоваться пробной версией программы.
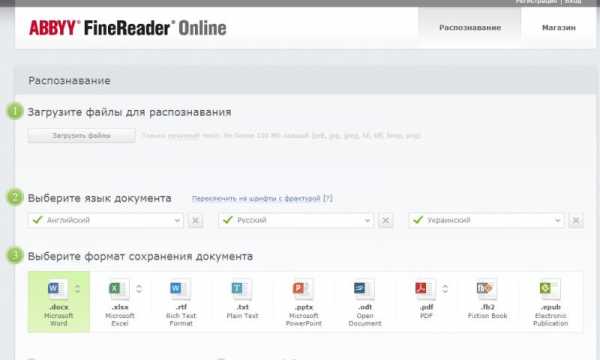
По этой ссылке https://finereaderonline.com/ru-ru, вы можете перейти в онлайн-версию программы для распознавания печатного текста. В пробном режиме обрабатывается не более 5 страницы в месяц, после регистрации добавляется еще 10 страниц. Если вас интересуют большие объемы — приобретайте подписку. Если вам нужно распознать всего около 50-100 страниц можно зарегистрироваться несколько раз.
Для распознавания достаточно загрузить PDF-файл или картинку. После обработки файла, вы получите текст, который можно или скопировать, или выгрузить в одном из доступных форматов.
voprosoff.net
Программа для распознавания рукописного текста
Комментарии: 12
Виктор | 18-05-2018, 10:03
Я давнишний пользователь FineReader. Ни в коем случае не покупайте 14-ю версию — это просто бред сумасшедшего! Они тупо все работающее сломали. И дело не в «особенностях» интерфейса — это Г вообще не работает.. Например, сломали предпросмотр — «автояркость» просто не включается. Хочешь темнее — двигай ползунок яркости в сторону …СВЕТЛЕЕ, и наоборот, хочешь светлее — двигай в сторону …ТЕМНЕЕ ;))) Кнопка ПРОСМОТР запускается только со второго жмака.. подогнать яркость как было раньше — уже никак — только дергай ползунок яркости путем проб (а контрастность вообще убрали) и методом тыка снова сканируй — пока не получится подобрать. Свои форматы областей сканирования больше НЕ СОХРАНЯЮТСЯ!!! И даже заложенные (например, конверт DL) в списке отсутствует, хотя если вводишь размер области ручками — тут же появляется именно как конверт ;)) Ищите версии 10, 11 — это лучшее, что ими было создано (я бы даже и 11-ю не советовал — там много косяков появилось по сравнению с 10-ой). Видимо, новая команда вообще сканерами управлять не умеет… Да, и в целом у них с мозгами что-то творится…
Юра | 1-05-2015, 00:32
При первом запуске удивил интерфейс — как-то поделено всё на зоны-окошки. Потом привык. Программа одна из лучших в своём классе.
Татьяна | 20-01-2015, 10:29
Программа установлена давно, но после смены материнской платы стала очень долго сканировать страницу (по 5 минут каждую), что делать?
Эдуард | 20-10-2013, 21:29
Выдает ошибку Невозможно определить тип изображения
Alekcey | 25-10-2012, 14:09
ABBYY FineReader — есть автоматическое обновление с 10 версии до 11 версии? Или опять покупать?
vk | 18-08-2012, 20:53
Светлана | 16-05-2012, 18:05
Возможно срок действия проги закончился
Виталий | 14-04-2012, 13:44
Прога классная, но на Windows 7 и на новом компе, после того, как даю ей распознать фото, выдает ошибку «Не удалось выполнить обработку. Внутренняя програмная ошибка \Src\Cache\CachedFontFile.cpp.543» Что делать, подскажите, пожалуйста?
ольга | 22-03-2012, 02:37
Если это будет работать, то я вас расцелую!
Дима | 28-01-2012, 11:14
Как активировать? Где взять ключ и номер? Никто не знает?!
karasev | 21-11-2011, 21:51
А где серийный номер? Напишите
Мила | 14-11-2011, 19:06
Сколько стоит она?
Нияз | 12-10-2011, 20:35
Юлия | 22-09-2011, 03:50
Программа класс!
База знаний
Вот только демо просит ключ…
Я | 10-09-2011, 16:00
Все хорошо, вот только версия — демо…
Галина | 11-08-2011, 05:45
Программа отличная, только вот установила ее на новом компьютере, но она не работает. Помогите! Выдает ошибку: невозможно установить тип изображения. Это что-то с настройками, или, может, потому что сканер подключен через сеть?
Владимир | 26-07-2011, 12:31
Отлично
Roer | 2-06-2011, 13:06
Программа слабовата в подготовке скана к распознанию. Дополнительно нужен графический редактор или БукРесторер. Если нужно распознать текст в схеме, то лучше использовать 8 версию. Если нужно распознать заляпанный текст, без графического редактора точно не обойтись. Разделение скана на 2 листа не всегда корректно. Прога откровенно тупит. Кстати, написание графических фильтров можно было отдать на откуп народу, если самим лениво. Ну и совсем добивает, когда размер выходного файла больше входного графического. Поэтому сохраняться лучше в txt с ручным форматированием.
Ирина Лапта | 17-05-2011, 15:49
Классная программа
veaceslav | 6-04-2011, 13:55
хорошая программа
Комментарии: 12
Создание технологии распознавания рукописного текста (обновлено) / Хабр
 В связи с дельной критикой хабрахабровцев, я кардинально переделал пост. Надеюсь, такой вариант будет оценен более положительно.
В связи с дельной критикой хабрахабровцев, я кардинально переделал пост. Надеюсь, такой вариант будет оценен более положительно.Я почти два года работаю в компании, которая занимается оцифровкой архивных и библиотечных фондов. Сканирование информации у нас поставлено на поток и в сутки мы получаем десятки тысяч графических образов, которые необходимо распознать и выгрузить заказчику. Моя задача состоит в создании конвейерной технологии для распознавания информации с графических образов.
В этом посте я хочу поделиться полученным опытом и рассказать о технологии распознавания рукописного текста.
Тестирование автоматического распознавания
Печатный текст
ABBYY FineReader является безоговорочным лидером в данном сегменте. Программы распознавания разрабатываются с уклоном на стандартную документацию компаний, которые является основными потребителями софта. Они не рассчитаны на нестандартные форматы, поэтому программы не могут дать уровень достоверности выше 80%.
При обработке библиотечных карточек десяти-двадцатилетней давности, ABBYY FineReader не может дать результат выше 60% достоверности. Смотрите скриншот ниже.

У ABBYY FineReader есть версии программы, где, после обучения, она должна распознавать текст. Суть проста – продукт представляет собой пустую нейронную сеть. Пользователю необходимо ее наполнить вручную. Если пользователь пытается распознать несколько почерков, программа не сможет выдать результат. Потратив неделю времени на обучение такого программного решения, в итоге, мы не получили положительный результат.
Применение автоматизированных программ для распознавания рукописного текста на сегодняшний день почти невозможно. Ввод оператором информации с графического образа является единственным способом получения оцифрованной информации. Смотрите скриншот ниже.
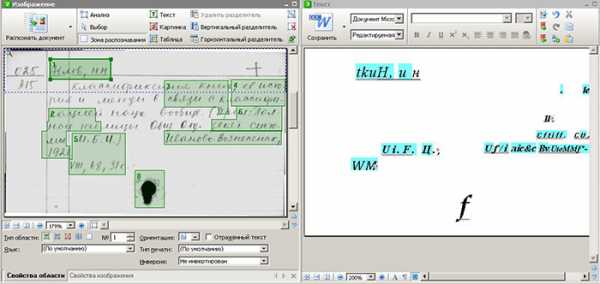
Создание технологии ручного распознавания
Далее пойдет речь о технологии, которую необходимо было создать. Был алгоритм, на реализацию которого ушло полгода. Ниже приведен порядок действий для получения распознанного текста:
- Сканирование – потоковый сканер выполняет сам.
- Разделение массива графических образов по признаку на подкатегории — это и все дальнейшие этапы выполняет человек. Этот этап позволяет повысить КПД ввода.
- Проверка работы сделанной на предыдущем этапе.
- Ввод данных. Вся информация логически разделяется на поля и заполняется частями. Каждый массив данных имеет свою специфику и свои правила ввода:
- если информация конфиденциальная — изображение автоматически режется на части, и каждый оператор получает для ввода только часть информации;
- при большом количестве полей — поля одной карточки делятся между несколькими операторами.
- Проверка данных ввода. Наличие ошибок влияет на оплату труда людей, которые вводят данные.
- Проводится ряд общих автоматизированных проверок по базе.
- Отгрузка законченных частей массива заказчику.
Проект получил название «Центр удаленного трудоустройства» и начал набирать обороты. Первый месяц приходилось постоянно исправлять ошибки, которые вылезали при обкатке. Далее процесс наладился, и софт стал стабильно работать и выгружать готовые массивы данных.
Весь проект был реализован при поддержке Министерства культуры и туризма Украины, подробнее можно почитать по ссылке.
Кратко о системе
Язык программирования: PHP.
База данных: MySQL.
CMS, Framework: отсутствуют, разработка велась с нуля.
Напоследок
Для тех, кому интересно увидеть различные варианты результатов работы ABBYY FineReader, я опубликовал дополнительные скриншоты по ссылке.
habr.com