
| Как думают компьютеры. Распознавание изображений. (о чём молчит Пенроуз, часть 6.1)
Распознавание изображений – область, пересекающаяся с распознаванием образов, но стоящая от неё несколько особняком. Одно из главных различий состоит в том, что изображения одного и того же образа могут варьироваться своими геометрическими и яркостными характеристиками, но это нам не особо интересно, это исправляется хорошо изученными методами предобработки изображений. Второе из главных различий состоит в том, что изображения одного и того же образа подвергаются нетривиальным деформациям, например, различные ракурсы трёхмерного объекта, направление освещения, изменения позы/мимики/жестикуляция и т.п., которые не укладываются в схему разделения пространства образов. И вот тут начинается самое интересное. Местами я буду вдаваться в подробности распознавания изображений, поскольку тема для меня близкая, и буду выкладывать некоторые идеи и свой взгляд на то, какой должна быть идеальная распознавалка изображений. Подробно многое из этого я когда-то описывал здесь. Не без неточностей, но в целом вменяемо. Там-же указано откуда взяты картинки и точные данные научных статей. Как изображение представляется в системе распознавания образов. Самое простое – каждый пиксель – это ось в пространстве образов, яркость пикселя – положение в этом пространстве. Отсюда сразу напрашивается вывод о том, что распознавалка никак не учитывает двумерный характер изображений, но об этом позже. Есть и другие представления, они тоже основаны на яркостях пикселей, и могут немного лучше (совсем немного!) отражать двумерные взаимосвязи пикселей. Что из такого представления следует. Изменение положения распознаваемого объекта, его поворот в двумерной плоскости, изменение масштаба – это катастрофа для распознавалки. Потому что пиксель, соответствующий, например, кончику носа, уйдёт на край уха, или, с точки зрения распознавалки, входное значение, которое должно попадать на свою ось в пространстве образов, попадёт в совсем другую (непонятно какую!) ось (по другому это называется изменением топологии пространства). И такая перестановка осей напрочь ломает разделительные поверхности в пространстве образов. Можно, конечно, сказать, пусть распознавалка обучится всем положениям и масштабам объекта на изображении. Но, к сожалению, число всевозможных положений настолько огромно, что сделать это нереально. Следующее следствие – изменение яркости изображения отбрасывает весь образ в совсем другую точку в пространстве образов. Хоть здесь оси остаются на месте, всё равно изменение яркости остаётся большой проблемой распознавалки. В итоге распознавалка будет реагировать не столько на содержание образа, сколько на его яркость и размер/положение. Но всё это не так страшно, исправлять геометрию и яркость уже давно умеют средства обработки изображений. (Другой вопрос, сравнимый по сложности и применяемым методам с распознаванием изображения – это определить местоположение и размер объекта на изображении, называется детектированием.) Есть так же преобразования изображений (называемые моментами), коэффициенты которых получаются одинаковыми, для любых положений и размеров объекта. Поэтому один из первых этапов распознавания изображений (которого нет в распознавании образов) – это нормализация изображения, решаемый достаточно простыми средствами обработки изображений. Как это решается в мозге человека – тоже интересный вопрос, посмотрим дальше. Но самое каверзное для распознавалки – это деформации двумерной проекции, связанные с трёхмерной сущностью объекта (изменение ракурса и направления освещения) и изменением самого объекта (поза, жесты, мимика и т.п.). Потому, что эти деформации не исправляются методами обработки изображений, да и вообще для начала надо определить, что за деформация имела место. Поэтому любимые грабли распознавалок, когда они реагируют больше на ракурс, признавая разные объекты в одном ракурсе за один и тот же. С освещением похожий прикол, например, в одном и том же месте, переход с белого на чёрное, при изменении направления освещения на противоположное, станет наоборот, переходом с чёрного на белое, и нормализацией яркости это никак не исправишь. Справедливости ради, стоит отметить, есть способы, когда создаётся большой тренировочный набор с образами, специально взятыми под различными ракурсами и направлением освещения, и тогда, входной образ, если он попадает в границы этих условий, распознаётся хорошо. Причём после такой обширной тренировки в систему можно загонять новые объекты, которые уже не были сняты с такой широкой вариацией ракурсов и освещений. Но такой способ – это частный случай, к тому же достаточно тяжеловесный. И для нас в общем то не интересный, поскольку больше относится к математике и статистике. Другой способ – это восстановление трёхмерного образа по двумерной проекции. Тогда уже ракурс и освещение не играют роли, а изменения позы обрабатываются проще. Правда способ непрост в реализации, и не всё в нём гладко. При восстановлении трёхмерного образа обычно требуется более общая модель объекта (без неё восстановление хоть и возможно, но будет «хромать» и хуже подходит для распознавания), и соотнесение проекции с трёхмерной моделью тоже носит элементы распознавания образов. Но нам это тоже неинтересно, поскольку здесь больше точной математики. «Чистая» распознавалка должна справляться с перечисленными деформациями изображений сама по себе, без точных моделей и специально подготовленных тренировочных наборов. Распознавалка должна оперировать не изображением, как одномерным массивом, а должна понимать, что изображение состоит из двумерных фрагментов, содержание фрагмента может меняться, хотя смысл его остаётся тем-же (пример выше про изменение направления освещения или другое выражение лица), сам фрагмент может сместиться относительно центра изображения и относительно других кусочков (другой ракурс или смена выражения лица), комбинация кусочков может измениться (например, появились очки, изменилась причёска/борода на лице, хотя сам обладатель прежний). Распознавалки, которые показывают хорошие результаты, как раз многое из перечисленного умеют делать, каждая по своему. Но! Если для какой-то области разработана чёткая частная распознавалка, то более общей будет трудно с ней тягаться, хотя общая распознавалка и применима для более широких условий. Например, в распознавании лиц хорошо разработаны методы определения положения лица, нормализации и выделения ключевых признаков, для фотографий, снятых в хорошо контролируемых условиях. И по этим ключевым признакам отлично работают не самые заумные распознавалки, и этого более чем достаточно. Если правильно предобработанное изображение лица подать на вход нейронной сети (многослойного персептрона), то это тоже считается частной распознавалкой, потому, что для не обработанного изображения у такой сети результаты будут плачевными. Как именно распознавалки справляются с вышеперечисленными деформациями изображения. Выделение ключевых точек и их содержания. Например, для лица определяется положение кончика носа, губ, краешков глаза, содержание фрагментов изображения вокруг этих точек, и рассчитываются взаимные расстояния между этими точками. Для рукописных символов это могут быть точки изгиба траектории, угол таких изгибов и расстояние между углами. Частично для поиска этих точек используются методы распознавания образов, частично это логические правила, запрограммированные человеком-экспертом вручную. Потом эти данные подаются на обычную распознавалку. Поскольку двумерные взаимосвязи между точками уже выделены и содержание окрестностей точек найдено, распознавалка уже может справляться с двумерными деформациями с помощью разделения пространства образов. Здесь уже произошёл поиск и сопоставление осей, топология изображения подогнана под топологию пространства образов распознавалки, а расстояния между ключевыми точками позволяют замерить искажения этой топологии, минимизируя различия в ракурсах и обращая внимание на то, какому человеку принадлежит лицо. Причём поиск ключевых точек был:
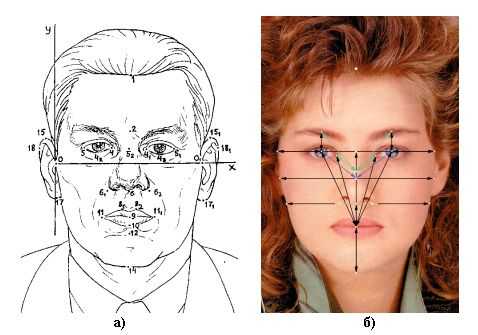 Идентификационные точки и расстояния: а) используемые при криминалистической фотоэкспертизе; б) наиболее часто применяемые при построении автоматизированных систем идентификации. Недостаток такого подхода в том, что анализируется только небольшое число точек, остальное изображение выкидывается, отчего может страдать качество распознавания. Например, если точка найдена неправильно, то это уже фатально, если же анализировать и окрестные области, то ошибку можно минимизировать. Но для отдельных проработанных областей (вроде распознавания лиц) такой подход достаточен. Следующий способ – деформация изображения. На распознаваемое изображение как-бы натягивается решётка, в узлах которой становятся исходные пиксели. Потом решётка искажается (узлы меняют своё положение) и вычисляется искажённое изображение. Между каждым изображением из тренировочного набора и искажённым изображением вычисляется разница. То исходное изображение, которое за некоторое число итераций искажения дало меньшую разницу с искажённым изображением, считается на него больше всего похожим (минимум искажений при максимуме соответствия). Для поиска направления искажения может быть как критерий минимизации на основе исходного и искажаемого изображения (как в оптических потоках), так и случайный поиск, вроде отжига. Деформации бывают эластичными и неэластичными. Эластичные – это значит, что при искажении узлы решётки не могут перепрыгивать друг друга, например, ухо не залезет в средину носа. Неэластичные соответственно разрешают любые перестановки узлов. Какие из них лучше – точных сравнений уже не помню, но интуитивно эластичные деформации приятнее. Искажения могут проходить по методу отжига, описанному в предыдущей части, в результате чего искажение «застынет» в одном из самых похожих тренировочных образов.  Эластичная деформация – совмещение пикселей на исходном и новом изображении  Эластичная решётка, наложенная на изображение, и её искажение Оптический поток (неэластичная деформация). Отображение неизвестного изображения на известное, один и тот же человек. Слева направо: неизвестное изображение, изображение из базы данных, неизвестное изображение, в котором блоки заменены блоками из известного изображения. Оптический поток (неэластичная деформация). Отображение неизвестного изображения на изображение из базы. Изображения разных людей. Качество отображения хуже. 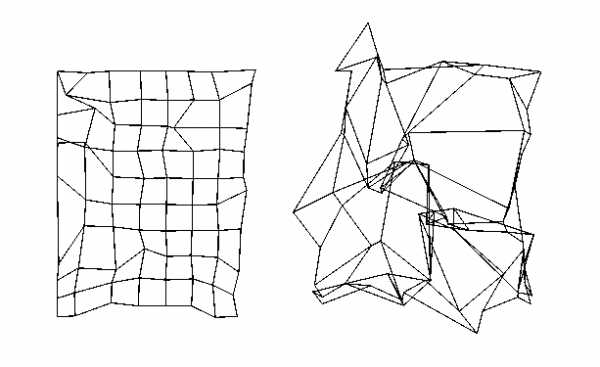 Оптический поток (неэластичная деформация). Искажений решётки изображения при преобразовании одного изображения в другое. Слева – изображения одного человека, справа – разных. Недостаток такого подхода в том, что он тупо деформирует изображение, стремясь минимизировать попиксельную разницу, совершенно без учёта смысла изображения. Например, улыбку одного человека может разгладить в выражение другого человека, оттого, что попиксельная разница меньше. Или другими словами, допускаются любые траектории искажения изображения (пусть даже эластичные), хотя для реальных изображений эти траектории строго фиксированы, и связаны с изменением ракурса, мимики и т.п. Кроме того, непонятно, что будет, если область испытала не искажение, а, например, появились очки, которых в исходном образе не было. Деформация наверно «сойдёт с ума» попытавшись преобразовать очки в глаза 🙂 Другой важный момент – такая деформация ищет только похожесть, не занимаясь выяснением отличительных черт, той разницы, что отличает один объект от другого (как это делает нейронная сеть в предыдущих частях). В итоге возможны приколы, когда такая распознавалка будет ловиться на шикарную одинаковую причёску, проигнорировав небольшие изменения в разрезе глаз (это к слову, хорошие системы распознавания выкидывают причёски и прочие «шумовые» факторы ещё на стадии предобработки изображения). Есть вариация, когда на изображение натягивается не решётка, а более осмысленный каркас, например, для лица включающий такие точки как кончик носа, кончики губ, глаз, ушей, бровей. Такие распознавалки действуют более осмысленно, за счёт того, что им уже подсунули нужные данные. Эти точки даже можно не искать, достаточно задать приближённый каркас, а остальное само найдётся во время деформации. Другое дело, что в тренировочном наборе эти точки должны быть чётко расставлены (а это отдельная и нелёгкая задача, или выполняется частично вручную), и тогда можно сравнить эталонную модель с неизвестной искажённой не только по содержимому точек, но и по характеру искажений решётки. Называется это динамическими графами (или эластичными, не помню точно).  Эластичный граф, покрывающий изображение лица Следующий способ называется Скрытые Марковские Модели (СММ). Суть её описана ниже мутновато (но кратко), зато пример с распознаванием изображений всё проясняет. Грубо говоря, СММ – это матрица вероятностей перехода между состояниями физической системы или сигнала. При попадании в какое-то состояние система выдаёт наружу одно из «значений» из набора «значений» этого состояния. У каждого «значения» этого состояния – своя вероятность выдачи. Причём какие-то «значения» могут быть характерны и для других состояний. Обычно мы не знаем, по каким состояниям проходит процесс сигнала или физической системы, а видим только выдаваемые наружу «значения», поэтому модели и называются скрытыми. 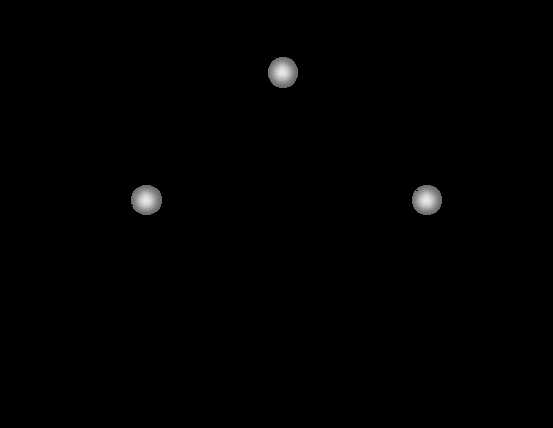 Схема Марковской модели, пример последовательности наблюдений O и последовательности состояний S Для распознавания СММ применяются так. Каждый образ рассматривается как последовательность таких «значений». Для каждого класса вычисляется своя СММ. Потом для неизвестного образа запускаются все имеющиеся модели и среди них ищется та, которая выдаёт самую похожую последовательность «значений». Это называется задачей распознавания, и для её решения есть точная формула. Для задачи настройки моделей по имеющимся образам точных формул нет, но, как и в обучении нейронных сетей, есть эвристические (субоптимальные, разновидность градиентного спуска) методы. Для распознавания изображений хорошо показали себя двумерные СММ. В них за «значение» принимается содержание квадратика изображения со стороной в несколько пикселей. Состояние – это положение этого квадратика на изображении. Изображение плотно покрыто решёткой таких состояний (причём границы соседних квадратиков могут частично перекрываться, что даёт лучший результат распознавания). Матрица переходов построена таким образом, что возможны переходы только между состояниями, которые соседствуют на двумерной решётке изображения. То есть, квадратик с кончиком носа будет искаться между щеками и ртом, но никак не за ухом, и если нос на неизвестном изображении будет найден левее, то левее будут искаться и соседние квадратики – щёки, нос, подбородок и т.п.  Псевдодвумерная скрытая Марковская модель 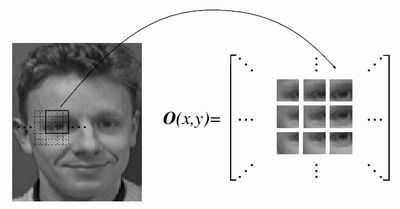 Извлечение участков-образцов наблюдения Сегментация изображения в процессе работы Марковской модели. Линии отмечают области, соответствующие одинаковым состояниям. Есть вариация обучения СММ, когда каждую СММ изначально «натаскивали» на все тренировочные образы, и только потом уточняли «своими», результат распознавания был выше. То есть, СММ обучилась тому, как выглядит и изменяется типичный объект «вообще», и потом донастроилась на вид и изменения конкретного объекта. И это произошло не за счёт знания точной и конкретной физической модели, а за счёт общей процедуры обучения и конкретных примеров из реального мира. Получается, что внутри СММ (касается и свёрточных сетей, см. ниже) строится правдоподобная модель объекта. Это не та модель, которая получается, например, при трёхмерном реконструировании изображения, и не та модель, когда вручную определяют набор ключевых признаков и взаимосвязей между ними. СММ, наоборот, воссоздаёт не точную физическую модель, а правдоподобную модель. Модель, которая выдаёт похожее поведение объекта, но за счёт процессов, ничего не имеющих общего с реальной физикой объекта. При правильной настройке, физическая и правдоподобная модель совпадают в выдаваемых результатах, в тех условиях, в которых мы обучили правдоподобную модель. Но за пределами этих условий начинаются расхождения, иногда имеющие интересные эффекты. Например, человек легко узнаёт по карикатуре другого человека, хотя математически изображение карикатуры ну никак не сопоставимо с оцифрованным изображением лица человека. Легко найти и другие повседневные примеры. Человек в своих действиях руководствуется не точными законами физики, а «наивной» физикой, которая действует в бытовых условиях, но совершенно неприменима, когда мы выходим за границы этих условий. Похожее можно найти и в логическом, и в образном мышлении, отсюда происходят фантазии и творчество, посмотрев на которые, человек может сопоставить им или прочувствовать настоящие физические процессы, которые с научной точки зрения такими фантазиями ну никак не могут быть описаны. И кстати, для таких распознавалок нетрудно обратить их «вспять», чтобы по заданному объекту они выдавали вариации его изменений. Естественно, кроме реальных образов, мы ещё получим кучу «фантазий» от распознавалки, странных на наш взгляд. На этом же основано и определение ключевых участков изображения – тех участков, которые вносят наибольший вклад в распознавание. Но к фантазиям и правдоподобным моделям мы ещё вернёмся, продолжим теперь про распознавание изображений. Таким образом, СММ – это почти идеальная распознавалка изображений:
Но есть у СММ недостаток. СММ не умеют выстраивать разницу между распознаваемыми классами, не умеют находить отличительные характеристики. Нейронные сети, например, говорят «да» распознанному классу и «нет» всем остальным, СММ же говорит «да» всем классам, и из этих «да» выбирается максимальное, которое и считается распознанным классом. И, насколько я понял, СММ не замеряет изменение расстояний между кусочками, что могло бы улучшить результат, а только ищет как бы лучше расположить кусочки на изображении, с учётом их соседства. Хотя было бы интересно найденную таким образом искажённую решётку (в виде расстояний между узлами, где узел – положение кусочка) засунуть в распознавалку.  Выход нейронной сети при распознавании – чётко видна разница между распознанным классом (s11) и всеми остальными. Марковские модели так не умеют. Следующий способ распознавания изображений – это когнитроны, неокогнитроны и свёрточные нейронные сети (СНС). Изначально когнитроны как бы и были придуманы на основе строения нейронов зрительной коры, потом усовершенствованы, а в свёрточных сетях из всей этой структуры было выделено рациональное зерно. Для понимания работы этих сетей надо усвоить самое главное понятие – карты признаков. Представьте, что изображение сканируется небольшим квадратным окном. Положения окна на изображении могут частично перекрываться. В квадрате окна каждому сканируемому пикселю сопоставлен свой вес, и на выход окно выдаёт просуммированное взвешенное значение всех пикселей. Одно-единственное значение. Но поскольку положений окна много, получается двумерная решётка таких значений. Это окошко детектирует наличие какого-то сочетания пикселей (признака) на изображении. В итоге, на выходной решётке получатся высокие значения там, где нужное сочетание пикселей есть, и низкие, там, где содержание ну никак не похоже на то, что мы ищем. Вот эта решётка и называется картой признаков. Причём ищем мы не один признак, а много разных, для каждого из них своё окно со своим набором весов, и в итоге получается несколько параллельных карт признаков на выходе. Каждая карта признаков (как изображение) подаётся на вход своего следующего слоя распознавалки, и тоже получает на выходе ещё несколько параллельных карт. В конечном слое все карты подаются на вход итоговой распознавалки, которая может быть достаточно простой, в оригинале использовался многослойный персептрон. 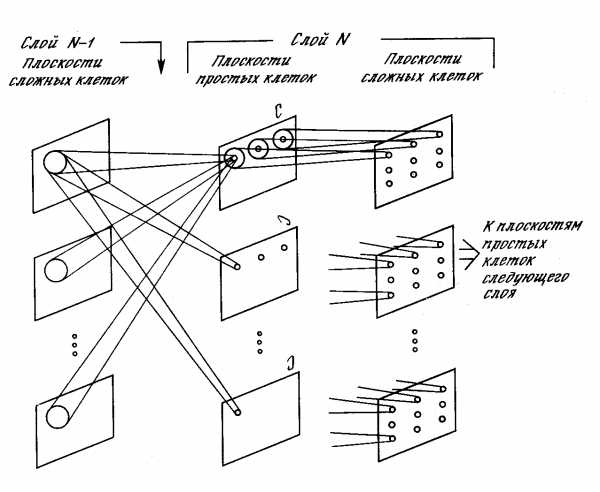 Неокогнитрон Понятно, что такая обработка изображения может учитывать небольшие деформации и сдвиги. Есть вариант, когда карты признаков распараллеливают дальше, добавляя карты, в которых происходит сканирование кусочков, повёрнутых под разными углами. За счёт этого распознавалка может справляться с поворотами. Продолжая мысль в этом направлении, можно сделать много чего интересного, например окошки разных размеров и инвариантность к масштабу изображения. Можно сделать дополнительные связи, которые бы шли не только к предыдущим картам в иерархии, но и к более дальним (пахнет уже интеллектуальным анализом сцены). Интересен ещё вариант, когда карта признаков следующего слоя будет сканировать не на одну предыдущую карту, а сразу все (как это и было в оригинальном неокогнитроне). Обработка сразу становится тяжеловеснее (трёхмерное окно), но и мощнее, к сожалению, не в курсе, исследовался ли такой вариант в свёрточной сети. Или вместо этого хотя-бы на конечную распознавалку подавать выходы не только последней карты, но всех из иерархии. Архитектура свёрточной нейронной сети. Свёрточные (convolutional) и усредняющие (subsampling) слои. За счёт таких карт признаков, у свёрточных сетей получается качественно иная, более мощная обработка изображения (подумайте почему, представьте ход формирования признаков при движении вверх по иерархии). Как видим, и здесь нет длинных логических цепочек вывода и перебора вариантов, поиск короткий и «широкий» (одновременно-параллельный по всем картам признаков). В математике, то, что проделывает окно с исходным набором пикселей, называется свёрткой (разновидность пространственно-частотного преобразования), а веса в окне играют роль фильтра. Поэтому сети и называются свёрточными. Слои это делающие тоже называются свёрточными. Обычно, помимо карт признаков, вводят ещё и усредняющие слои, которые перед подачей карты на следующий слой уменьшают её размер, за счёт усреднения соседних пикселей (как масштабирование изображения), иначе получается огромный объём вычислений, и кроме этого, достигается дополнительное обобщение разных искажений исходного изображения. Как обучаются такие сети. Первый вариант, можно построить топографическую карту встречающихся в исходном изображении кусочков, а потом уже брать значения из этой карты и по ним строить карты признаков. Точно также строятся топографические карты для следующих слоёв в иерархии, но на вход уже подаются карты признаков. Топографическая карта, это значит, что мы составляем как бы словарь из усреднённых кусочков, встречающихся в изображении. Причём кусочки, во-первых, будут упорядочены в n-мерную решётку, где соседи будут похожи, и во-вторых, что самое для нас интересное, кусочки из словаря хорошо подходят для построения карт признаков, поскольку являются характерными и часто встречающимися фрагментами изображения, потому что абстрактные или редко встречающиеся кусочки не попадут в эту карту, а похожие кусочки будут сгруппированы в один усреднённый. В этом варианте обучение идёт без учителя, поскольку для построения топографической карты не нужна ошибка между желаемым и реальным выходом сети, признаки автоматически группируются по их похожести. Обучается с учителем только конечная распознавалка, на которую поступают выходы с карт признаков последнего слоя. Применение карт Кохонена (двумерных) для уменьшения размерности участков изображений лиц. Слева – топографическая карта участков изображений до обучения, справа – после обучения. Второй вариант – веса для карт признаков настраиваются как веса нейронов при обратном распространении ошибки. То есть с выхода сети поступает настройка, которая говорит, какие признаки надо вытаскивать из изображения, чтобы получить результат. В оригинальной работе по свёрточным сетям утверждается, что такая настройка проста, но я бы не стал верить авторам наслово, потому что здесь есть масса вариантов, и далеко не каждый из них даст что-то хорошее. В оригинальном варианте свёрточная сеть обучается и работает очень быстро, и даёт точность, близкую к СММ (но всё-же меньшую). СММ же, при своей потрясающей точности, обучаются очень долго. Какой из вариантов лучше – не знаю. По идее, с учётом того, что конечная распознавалка обучается с учителем, результаты должны быть похожи. Из описания архитектуры свёрточных сетей, посмотрим, что они могут делать:
Чего они не могут делать. Во-первых, наборы признаков составляются для всего изображения целиком. На деле же было бы полезно, чтобы, как и в СММ, для каждой окрестности (точнее даже сказать, для поисковой траектории) были свои наборы признаков. То есть, чтобы в районе глаз, были фильтры исключительно с разными фрагментами глаз, но никак не рта, пусть даже он там никогда не будет найден. Это позволило бы сделать более точный словарь для каждой области, а не усреднённый по всему изображению. Но и одновременно это бы сделало распознавалку более тормозной. Во-вторых (и тесно связанное с первым), чтобы чётко выделялись допустимые траектории каждого фрагмента, и, в процессе распознавания, замерялись изменения расстояний между соседними фрагментами (точнее, поскольку все соседи в решётке связаны, чтобы строились допустимые искажения всей решётки и потом проверялись). Конечно, в каком-то виде свёрточные сети это уже делают, но интуитивно кажется, что это можно сделать оптимальнее. Вариант попроще и побыстрее – сделать локальные карты признаков (с учётом предметной области). Например, области глаз, рта, носа, ушей. Вот и всё с основными способами распознавания изображений (на примере распознавания лиц). Для других видов изображения принципы распознавания те же самые, адаптированные к своей области, к своим наборам признаков. Итог таков. При распознавании изображений сначала производится предобработка изображения, потом вручную и/или автоматически извлекаются признаки, эти признаки подаются на любую распознавалку, самая сложная из которых – это нелинейные разделяющие поверхности в пространстве признаков. Этап извлечения признаков может происходить с привлечением физических моделей, для реконструкции сущности объекта, но это уже точная математика. В правила распознавания может быть заложена логика человека-эксперта в данной области. Другой вид распознавалок (деформации изображения, Марковские модели, свёрточные сети) пытается эвристическими методами воссоздать правдоподобную модель предметной области и наложить её на неизвестный образ. И никаких чудес. Или точные формулы плюс знания человека-эксперта, или тяжёлые и универсальные правдоподобные модели. Упоминание того, как якобы происходит распознавание изображений у человека – это пока больше красивые слова, чем практическое применение. Вторая часть… |

dima78.livejournal.com
Распознавание изображений. Алгоритм Eigenface / Хабр
Введение
Я продолжаю серию статей посвящённую тематике pattern recognition, computer vision и machine learning. Сегодня я вам представляю обзор алгоритма, который носит название eigenface.

В основе алгоритма лежит использование фундаментальных статистических характеристик: средних (мат. ожидание) и ковариационной матрицы; использование метода главных компонент. Мы также коснёмся таких понятий линейной алгебры, как собственные значения (eigenvalues) и собственные вектора (eigenvectors) (wiki: ru, eng). И вдобавок, поработаем в многомерном пространстве.
Как бы страшно всё это не звучало, данный алгоритм, пожалуй, является одним из самых простых рассмотренных мною, его реализация не превышает нескольких десятков строк, в тоже время он показывает неплохие результаты в ряде задач.
Для меня eigenface интересен поскольку последние 1.5 года я занимаюсь разработкой, в том числе, статистических алгоритмов обработки различных массивов данных, где очень часто приходится иметь дело со всеми вышеописанными «штуками».
Инструментарий
По сложившейся, в рамках моего скромного опыта, методике, после обдумывания какого-либо алгоритма, но перед его реализацией на С/С++/С#/Python etc., необходимо быстро (насколько это возможно) создать математическую модель и опробовать её, что-нибудь посчитать. Это позволяет внести необходимые коррективы, исправить ошибки, обнаружить то, что не было учтено при размышлении над алгоритмом. Для этого всего я использую MathCAD. Преимущество MathCAD в том, что наряду с огромным количеством встроенных функций и процедур, в нём используется классическая математическая нотация. Грубо говоря, достаточно знать математику и уметь писать формулы.

Краткое описание алгоритма
Как и любой алгоритм из серии machine learning, eigenface необходимо сначала обучить, для этого используется обучающая выборка (training set), представляющая собой изображения лиц, которые мы хотим распознать. После того как модель обучена, мы подадим на вход некоторое изображение и в результате получим ответ на вопрос: какому изображению из обучающей выборки с наибольшей вероятностью соответствует пример на входе, либо не соответствует никакому.
Задача алгоритма представить изображение как сумму базисных компонент (изображений):
Где Фi – центрированное (т.е. за вычетом среднего) i-ое изображение исходной выборки, wj представляют собой веса и uj собственные вектора (eigenvectors или, в рамках данного алгоритма, eigenfaces).
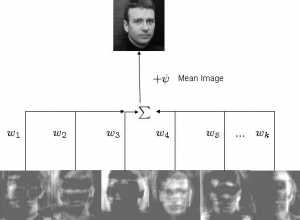
На рисунке выше мы получаем исходное изображение взвешенным суммированием собственных векторов и прибавлением среднего. Т.е. имея w и u, мы можем восстановить любое исходное изображение.
Обучающую выборку необходимо спроецировать в новое пространство (причём пространство, как правило, гораздо больше размерности, чем исходное 2х мерное изображение), где каждая размерность будет давать определённый вклад в общее представление. Метод главных компонент позволяет найти базис нового пространство таким образом, чтобы данные в нём располагались, в некотором смысле, оптимально. Чтобы понять, просто представьте, что в новом пространстве некоторые размерности (aka главные компоненты или собственные вектора или eigenfaces) будут «нести» больше общей информации, тогда как другие будут нести только специфичную информацию. Как правило, размерности более высокого порядка (отвечающие меньшим собственным значениям) несут гораздо меньше полезной (в нашем случае под полезной понимается нечто, что даёт обобщённое представление о всей выборке) информации, чем первые размерности, соответствующие наибольшим собственным значениям. Оставляя размерности только с полезной информацией, мы получаем пространство признаков, в котором каждое изображение исходной выборки представлено в обобщённом виде. В этом, очень упрощённо, и состоит идея алгоритма.
Далее, имея на руках некоторое изображение, мы можем отобразить его на созданное заранее пространство и определить к какому изображению обучающей выборки наш пример расположен ближе всего. Если он находится на относительно большом расстоянии от всех данных, то это изображение с большое вероятностью вообще не принадлежит нашей базе.
За более подробным описанием я советую обращаться к списку External links википедии.
Небольшое отступление. Метод главных компонент имеет достаточно широкое применение. Например, в своей работе я его использую для выделения в массиве данных компонент определённого масштаба (временного или пространственного), направления или частоты. Он может быть использован как метод для сжатия данных или метод уменьшения исходной размерности многомерной выборки.
Создание модели
Для составления обучающей выборки использовалась Olivetti Research Lab’s (ORL) Face Database. Там имеются по 10 фотографий 40 различных людей:
Для описания реализации алгоритма я буду вставлять сюда скриншоты с функциями и выражениями из MathCAD и комментировать их. Поехали.
1.

faceNums задаёт вектор номеров лиц, которые будут использоваться в обучении. varNums задаёт номер варианта (согласно описанию базы у нас 40 директорий в каждой по 10 файлов изображений одного и того же лица). Наша обучающая выборка состоит из 4х изображений.
Далее мы вызываем функцию ReadData. В ней реализуется последовательное чтение данных и перевод изображения в вектор (функция TwoD2OneD):
Таким образом на выходе имеем матрицу Г каждый столбец которой является «развёрнутым» в вектор изображением. Такой вектор можно рассматривать как точку в многомерном пространстве, где размерность определяется количеством пикселей. В нашем случае изображения размером 92х112 дают вектор из 10304 элементов или задают точку в 10304-мерном пространстве.

2. Необходимо нормализовать все изображения в обучающей выборке, отняв среднее изображение. Это делается для того, чтобы оставить только уникальную информацию, убрав общие для всех изображений элементы.

Функция AverageImg считает и возвращает вектор средних. Если мы этот вектор «свернём» в изображение, то увидим «усреднённое лицо»:
Функция Normalize вычитает вектор средних из каждого изображения и возвращает усреднённую выборку:

3. Следующий шаг это вычисление собственных векторов (они же eigenfaces) u и весов w для каждого изображения в обучающей выборке. Другими словами, это переход в новое пространство.

Вычисляем ковариационную матрицу, потом находим главные компоненты (они же собственные вектора) и считаем веса. Те, кто познакомятся с алгоритмом ближе, въедут в математику. Функция возвращает матрицу весов, собственные вектора и собственные значения. Это все необходимые для отображения в новое пространство данные. В нашем случае, мы работаем с 4х мерным пространством, по числу элементов в обучающей выборке, остальные 10304 — 4 = 10300 размерности вырождены, мы их не учитываем.
Собственные значения нам, в целом, не нужны, но по ним можно проследить кое-какую полезную информацию. Давайте взглянем на них:
Собственные значения на самом деле показывают дисперсию по каждой из осей главных компонент (каждой компоненте соответствует одна размерность в пространстве). Посмотрите на правое выражение, сумма данного вектора = 1, а каждый элемент показывает вклад в общую дисперсию данных. Мы видим, что 1 и 3 главные компоненты дают в сумме 0.82. Т.е. 1 и 3 размерности содержат 82% всей информации. 2ая размерность свёрнута, а 4ая несёт 18% информации и нам она не нужна.
Распознавание
Модель составлена. Будем тестировать.

Мы создаём новую выборку из 24 элементов. Первые 4ре элемента те же, что и в обучающей выборке. Остальные это разные варианты изображений из обучающей выборки:

Далее загружаем данные и передаём в процедуру Recognize. В ней каждое изображение усредняется, отображается в пространство главных компонент, находятся веса w. После того как вектор w известен необходимо определить к какому из существующих объектов он ближе всего расположен. Для этого используется функция dist (вместо классического евклидова расстояния в задачах распознавания образов лучше применять другую метрику: расстояние Махалонобиса). Находится минимальное расстояние и индекс объекта к которому данное изображение расположено ближе всего.
На выборке из 24 показанных выше объектов эффективность классификатора 100%. Но есть один ньюанс. Если мы подадим на вход изображение, которого нет в исходной базе, то всё равно будет вычислен вектор w и найдено минимальное расстояние. Поэтому вводится критерий O, если минимальное расстояние < O значит изображение принадлежит к классу распознаваемых, если минимальное расстояние > O, то такого изображения в базе нет. Величина данного критерия выбирается эмпирически. Для данной модели я выбрал O = 2.2.
Давайте составим выборку из лиц, которых нет в обучающей и посмотрим насколько эффективно классификатор отсеет ложные образцы.

Из 24 образцов имеем 4 ложных срабатывания. Т.е. эффективность составила 83%.
Заключение
В целом простой и оригинальный алгоритм. В очередной раз доказывает, что в пространствах большей размерности «скрыто» множество полезной информации, которая может быть использована различным образом. Вкупе с другими продвинутыми методиками eigenface может применятся с целью повышения эффективности решения поставленных задач.
Например, у нас в качестве классификатора применяется простой distance classifier. Однако мы могли бы применить более совершенный алгоритм классификации, например Support Vector Machine (Метод Опорных Векторов) или нейросеть.
В следующей статьей речь пойдёт о Support Vector Machine (Метод Опорных векторов). Относительно новый и очень интересный алгоритм, во многих задачах может быть использован как альтернатива НС.
При написании статьи использовались материалы:
onionesquereality.wordpress.com
www.cognotics.com
Материалы:
Лист расчётов для MathCAD 14
UPD:
Я вижу многим непонятна и пугает математика. Тут есть два пути.
1. Если вы хотите понять весь смысл всех действий алгоритма, то следует начать с понимания базовых вещей: ков. матрицы, метода главных компонент, значение и смысл собственных векторов и значений. Если вы знаете, что это, то всё становится понятно.
2. Если вы хотите просто реализовать и использовать алгоритм, то берёте качаете лист расчётов для MathCAD’a. Запускаете, смотрите, меняете параметры. Там расчётов на пол экрана и в них нет ничего сложнее умножения матриц (ну если не считать встроенных функций вычисления собственных векторов, но в это вникать не надо). Вот в помощь реализации на python, matlab, C++.
habr.com
Как Google будет распознавать и ранжировать изображения в ближайшем будущем?
Редактор-переводчик SEOnews
Сканирование изображения и обнаружение в нем объектов — задача № 1 в обработке картинок и компьютерном зрении. Поиск по запросу «автоматическое распознавание изображений» на Google Академии выдаст множество статей со сложными уравнениями и алгоритмами от начала 90-х и до наших дней. Это говорит о том, что указанная проблема занимает ученых с самого появления веб-поиска, но она пока не решена.
Основатель cognitiveSEO Рэзван Гаврилас считает, что в ближайшем будущем Google изменит алгоритмы ранжирования изображений, что повлияет на поиск и фактически на поисковую оптимизацию во всем мире. Эту тему Рэзван развивает в данной статье.
Почему умение распознавать объекты в изображениях важно для мирового digital-сообщества?
По мнению эксперта, обнаружение объектов на картинках станет неким дополнительным фактором ранжирования. К примеру, изображение синей собаки будет неразрывно связано с ключевым словом «синяя собака», а не «рыжая собака».

Для SEO это имеет два важных последствия:
- количество нерелевантных результатов при поиске по определенному ключевому слову будет меньше (в зависимости от того, что находится на изображении),
- распознавание объектов в картинке поможет связать контент страницы с этим изображением. Если на странице много фотографий синих собак и других вещей, связанных с собаками, то рейтинг этой страницы, как посвященной собакам, будет выше.
Ещё один вопрос — станет ли распознавание образов началом «новой эры» для манипуляций с объектами на картинках, как новой теневой техники SEO? Нет, потому что алгоритмы поисковых систем в наши дни легко обнаружат такой вид спама.
Google, искусственный интеллект и распознавание изображений
В 2010 году Стэндфордским университетом был впервые проведен конкурс ILSVRC (ImageNet large-scale visual recognition challenge), в рамках которого программисты демонстрируют возможности разрабатываемых ими систем распознавания объектов на изображении.
ILSVRC включает три основных этапа:
- классификация,
- классификация с локализацией,
- обнаружения.
В первом случае оценивается возможность алгоритма создавать правильные «подписи» к изображению (маркировка), локализация предполагает выделение основных объектов на изображении, похожим образом формулируется и задача обнаружения, но тут действуют более строгие критерии оценки.
В случае с обнаружением алгоритм распознавания должен описать сложное изображение с множеством объектов, определяя их местонахождение и точно идентифицируя каждый из них. Это значит, что если на картинке кто-то едет на мопеде, то программное обеспечение должно суметь не просто различить несколько отдельных объектов (например, мопед, человека и шлем), но и правильно расположить их в пространстве и верно классифицировать. Как мы видим на изображении ниже, отдельные предметы были определены и классифицированы верно.

Любая поисковая система с наличием подобной возможности затруднит, чьи-либо попытки выдать фотографии людей на мопедах за фото водителей Porsche посредством манипуляций с метаданными. Алгоритм, способный распознавать объекты, довольно продвинутый и сможет разобрать любое, в том числе и самое сложное изображение.

В 2014 году конкурс ILSVRC выиграла команда GoogLeNet. Название образовано из слов Google и LeNet — одна из реализаций свёрточной нейронной сети. Подобная сеть может быстро обучаться, а также выдавать результаты даже при наличии небольшого объёма памяти за счёт более чем десятикратного сокращения числа параметров, по сравнению с большинством других моделей компьютерного зрения.
В планах Google — создать открытое программное обеспечение, на основе которого будет разработана технология распознавания изображений. Предполагается, что разработки исследовательской команды GoogLeNet будут внедрены в некоторые визуальные сервисы Google, в частности поиск по изображениям и YouTube, а также в Self-Driving Car — систему автоматического управления транспортным средством.
Отметим, что на ILSVRC 2014 предложено множество идей для распознавания объектов, причем они более «продвинутые», чем 2 года назад. В 2014 году число распознанных изображений составило 457 000, тогда как в 2013 году 395 000. В нынешнем году собрали более 60 000 новых изображений, которые были распределены по 200 категориям объектов.
На ILSVRC 2014 была отмечена нейронная сеть DistBelief (с 11-ю уровнями нейронов), которая может идентифицировать объекты независимо от их размера и расположения на картинке. Сеть DistBelief способна к обучению. Именно её Google использует для выявления семантического смысла понятий.
Как действительно происходит распознавание изображений?
В чем принцип работы вышеупомянутой инфраструктуры DistBelief? Она позволяет обучать нейронные сети в распределенной манере, и основана на принципах Хебба и масштабной инвариантности.
Под термином «нейронные сети» подразумеваются искусственные нейронные сети (ИНС), являющиеся вычислительными моделями, основанными на принципах обучения и распознавания образов. Пример работы алгоритма обнаружения объекта приведен ниже:

Команда GoogLeNet использует определенный тип ИНС — сверточную нейронную сеть, принцип работы которой заключается в том, что отдельные нейроны реагируют на разные (но перекрывающиеся) области в поле зрения. Эти области можно сопоставить воедино, чтобы получить более сложный образ. По словам Рэзвана Гавриласа, это напоминает работу со слоями в редакторе изображений.
Одним из плюсов сверточной нейронной сети является хорошая поддержка перевода — любого типа движения объекта из одного пространства в другое. Инфраструктура DistBelief умеет выделять объект независимо от того, где он находится на картинке.
Ещё одна полезная возможность инфраструктуры — масштабная инвариантность, согласно которой, свойства объектов не меняются, если масштабы длины умножаются на общий множитель. Это означает, что инфраструктура DistBelief должна четко распознавать изображение, к примеру, «апельсина», независимо от того, большой ли он (на обоях для рабочего стола) или крошечный (на иконке). В обоих случаях объект оранжевый и классифицируется как «апельсин».
Необходимо сказать и о принципе Хебба, согласно которому происходит обучение искусственных нейронных сетей. В книге «Организация поведения: нейропсихологическая теория» постулат Хебба звучит следующим образом: «Если аксон клетки А находится достаточно близко, чтобы возбуждать клетку B, и неоднократно или постоянно принимает участие в ее возбуждении, то наблюдается некоторый процесс роста или метаболических изменений в одной или обеих клетках, ведущий к увеличению эффективности А, как одной из клеток, возбуждающих В».
Рэзван Гаврилас немного упрощает цитату: «Клетки, которые возбуждаются вместе, связываются вместе». В случае с ИНС «клетки» стоит заменить на «нейроны». Выстраивая дальнейшую аналогию, можно сказать, что программное обеспечение будет в состоянии обучать себя, чтобы постоянно совершенствоваться.
Google рекрутирует специалистов в области искусственного интеллекта и распознавания изображений
Собственную технологию распознавания образов Google создает на основе сторонних разработок, например, для этого была приобретена компания-стартап DNNresearch, занимающаяся исследованиями в области распознавания объектов и голоса. DNNresearch представляет собой стартап, на момент поглощения в его штате числились три человека, автоматически ставшие сотрудниками Google. Им выделен грант на поддержку работы в области нейронных сетей. Новые технологии Google может применить для улучшения качества поиска по картинкам.
Согласно стратегии компании Google, многие решения с открытым исходным кодом остаются доступны для других компаний. Это делается для развития рынка. Как считает Рэзван, зачем душить конкурентов, когда вы можете позволить себе купить его спустя некоторое время?

Ещё одно интересное приобретение Google — компания DeepMind, в которую инвестировано 400 миллионов долларов. Это и многие другие приобретения направлены в первую очередь на то, чтобы привлечь в Google квалифицированных специалистов, а не какие-то готовые решения. Подобные шаги по покупке компаний — свидетельство гонки Google, Facebook и других интернет-компаний за «мозгами» для дальнейших разработок в области искусственного интеллекта.
Google+ уже использует обнаружение объектов в картинках. На очереди Google Поиск?
На самом деле, алгоритм обнаружения изображений на основе нейронной сети уже больше года работает в Google+. Часть кода программного обеспечения представленного на ILSVRC, использовалась для улучшения алгоритмов Google+, а именно — для поиска конкретных типов фотографий.

Технология распознавания изображений от Google имеет следующие особенности:
- Алгоритм Google учитывает соответствие объектов на веб-изображениях (крупный план, искусственное освещение, детализация) с объектами на естественных фотографиях (средний план, естественный свет с тенями, разная степень детализации). Другими словами — цветок должен оставаться цветком даже на изображениях с другим разрешением или условий освещения.
- Некоторые специфические визуальные классы выведены за рамки общих единиц. Например, в большом списке из наименований цветов, которые различает алгоритм, отмечены некоторые отдельные растения, например, гибискус или георгин.
- Алгоритму распознавания изображений Google также удалось научиться работать с абстрактными категориями объектов, выделяя то или иное количество картинок, которые могли бы быть отнесены к категориям «танец», «еда», «поцелуи». Это занимает куда больше времени, чем простое выявление соотношений «апельсин — апельсин».

Классы с разным значением также обрабатываются хорошо. Пример — «автомобиль». Это точно снимок автомобиля, если на нём мы видим весь автомобиль? Считается ли изображение салона машины фотографией автомобиля или уже чем-то другим? На оба вопроса мы бы ответили утвердительно, также поступает и алгоритм распознавания Google.
Нельзя не отметить, что система распознавания изображений пока ещё недоработана. Однако даже в «сыром» виде алгоритм Google на голову выше всех предыдущих разработок в сфере компьютерного зрения.
Технология распознавания изображений — часть Графа знаний Google?
Новый алгоритм Google — часть «машинного обучения», которое отчасти реализовано в Графе знаний. В нем находятся entities — объекты, предназначенные для замещения символов, которые не могут встречаться в «чистом» виде в HTML-тексте, например, символа «
Каждый объекты и каждый класс объектов получают уникальный код, благодаря чему животное «ягуар» никогда не перепутается с одноименной маркой автомобиля. На основе этих кодов алгоритм распознавания может пользоваться базой знаний. Фактически Google создает «умный поиск», который понимает и переводит ваши слова и изображения в реальные символьные объекты.
Как технология обнаружения объекта в изображениях может повлиять на SEO?
Возможность распознавания изображений может быть полезна везде, где требуется узнать, что находится на картинке.
С точки зрения обычного SEO умение распознавать изображения является огромным шагом вперед. Это способствует повышению качества контента, так как обмануть поисковик с помощью неверной маркировки фотографий или их огромного количества становится почти невозможно.
Хороший визуальный контент (то есть высокое качество изображения, четко видимые объекты, актуальность фото), вероятно, будет играть важную роль во всем, что касается визуального поиска.
Если вы хотите, чтобы ваш рисунок был первым среди изображений по запросам «Yellow Dog», то оптимизацию придется начать с указания типа вашего снимка и перечисления содержащихся в нем объектов.
Заключение
Способность человека распознавать множество объектов и распределять их по категориям является одной из самых удивительных возможностей зрительного восприятия, компьютерных аналогов которой пока не придумано. Однако Google уже делает шаги вперед, например, ему уже принадлежит патент на автоматическое масштабное видеораспознавание объектов с 2012 года.
Итак, по мнению Рэзвана Гавриласа, органические результаты поиска Google в ближайшем времени подвергнутся изменению. Поисковик перейдет «от строк к вещам», фактически интегрировав в поисковый ландшафт свой Граф знаний. Изменятся и алгоритмы поиска, которые, вероятно, будут связаны с фактическими объектами в содержании и определении того, как эти объекты будут связаны друг с другом.
www.seonews.ru
Google Goggles – визуальный поиск и распознавание объектов
Категория: работа
Цена: бесплатно
Версия: 1.9
Описание: На сегодня Google Goggles пока еще единственное приложение для визуального распознования объектов для Android
Русский интерфейс: да
Технические требования: Android версии 2.2 и выше
Особенности: обработка изображений
Root/Jailbreak: нет
Установка на флэш-карты: да
Скачать: Google Play
QR-код:
При первом запуске Goggles запрашивает у пользователя разрешения синхронизироваться с его аккаунтом в Google. После разрешения пользователю открывается окно приветствия со ссылкой на страницу, где можно ознакомиться с советами Google относительно того, какие именно изображения лучше всего распознает Goggles. В этот список вошли книги и DVD, ориентиры, логотипы, визитки, картины, компании, товары, штрихкоды, текст. Хорошие результаты не гарантируются, если для распознания выбрано изображение мебели или животного. Здесь же Goggles предлагает функцию перевода текста, который распознается на изображении. Внизу странички находится опция выбора вида подключения к интернету (wi-fi или мобильный инетернет), при котором будет осуществляться поиск изображения с помощью видеокамеры.

После регистрации, пользователю открывается основной экран, с которым ему предстоит работать. Вверху находится панель инструментов, где расположены всего три кнопки с иконками. Кнопка с фотоаппаратом включает камеру устройства. Для улучшения фотографий можно включить вспышку – ее иконка находится внизу слева, справа расположена иконка кадрирования.
Кнопка с камерой расположена в центральной части панели управления. При ее нажатии, Goggles отсылает пользователя к справочной информации. Здесь указана информация о большом объеме данных, который передается приложением и сервис рекомендует использовать данный режим при тарифном плане с безлимитным интернетом.

В правой верхней части находится иконка изображения. Тапнув по ней, пользователь может выбрать любую картинку или фотографию из личной коллекции, которая хранится на его устройстве, для дальнейшей обработки и анализа.

Сам процесс распознавания любого изображения – будь то уже существующая картинка или только что полученная фотография – выглядит одинаково. По экрану через все изображение проходит вертикальная полоса синего цвета. На экране в нижнем левом углу при этом указывается «Анализ». Если изображение будет идентифицировано, пользователю откроется страничка, на которой вверху будет находиться подпись изображения (при этом в левом углу будет примечание «похожее изображение»), ниже – изображение Google maps с отмеченным местом его расположения, а дальше ссылки Google на сайты с информацией и изображениями самого предмета. В случае, когда Goggles не может распознать изображение, появляется соответствующая надпись и два ряда картинок «товары в похожих категориях» и «похожие изображения».

Приложение сохраняет историю визуального поиска. Предусмотрена возможность поиска по истории. Если пользователь считает, что у него есть изображение распознаваемого предмета лучше, чем предложенный Goggles вариант, он может внести информацию про объект (название, выбрать один из 7 типов, к которым он будет отнесен, и дать описание), после чего оправить.
Данная версия приложения лучше всего распознает широко известные предметы и объекты.
Обсудить приложение в конференции
www.almodi.org
распознавание одежды на фотографии с помощью мобильного приложения / Блог компании Anetika / Хабр
Не так давно мы решили сделать проект, который позволял бы искать одежду в различных интернет-магазинах по фотографии (картинке). Идея проста — пользователь загружает изображение (фото), выделяет интересующую его область (футболку, штаны и т.п.), указывает (опционально) уточняющие параметры (пол, размер и т.п.), и система ищет похожую одежду в наших каталогах, сортируя ее по степени схожести с оригиналом.Сама идея не то что бы новая, но качественно никем не реализованная. На рынке уже несколько лет есть проект www.snapfashion.co.uk, но релевантность его поиска очень низкая, подбор происходит в основном по определению цвета изображения. Например, красное платье он сможет найти, но платье с определенным фасоном или рисунком уже нет. Аудитория этого проекта, к слову, не растет, мы это связываем с тем, что поиск определенно низкой релевантности и, по сути, ничем не отличается, если вы выберете на сайте магазина цвет при поиске по их каталогу.
В 2013 году появился проект www.asap54.com, и здесь поиск чуть лучше. Упор стоит на цвет и некоторые небольшие опции, указываемые вручную из специального каталога (короткое платье, длинное платье, платье средней длинны). Этот проект, столкнувшись с трудностями визуального поиска, слегка завернул в сторону социальных сетей, где модники могут делиться своими «луками» в одежде, из «шазама для одежды» в «инстаграм для модников».
Несмотря на то, что проекты в этой области существуют, определенно остается непокрытой потребность поиска по картинке, очень актуальная сегодня. И решение данной проблемы созданием мобильного приложения, как это сделали SnapFashion и Asap54, наиболее отвечает тенденциям e-commerce рынка: по различным прогнозам доля мобильных продаж в США с 11% в 2013 году может вырасти да 25-50% в 2017. Такой стремительный рост мобильной торговли предвещает и рост популярности самых разных приложений, помогающих совершать покупки. И скорее всего магазины будут сами вкладываться в разработку, продвижение подобных приложений, а также активно сотрудничать с ними.
Проанализировав конкурентов, мы решили, что нужно попробовать самим разобраться с этой темой и запустили проект Sarafan www.getsarafan.com.
Фирменный стиль изначально хотели сделать ярким. Проработали множество вариантов:
В итоге остановились на стиле с яркими красками.
Для старта выбрали клиент под iOS (под iPhone). Дизайн в виде красок, работает через Rest-сервис, на главном экране приложения выбор: сделать фотографию или выбрать из галереи.
Это, пожалуй, было самым простым из всего проекта. А тем временем на передовой backend-разработки все складывалось не так радужно. И вот история наших поисков: что мы делали и к чему пришли.
Визуальный поиск
Нами было опробовано несколько подходов, но ни один из них не дал результатов, которые позволили бы сделать высокорелевантный поиск. В этой статье мы расскажем, что попробовали, и что и как сработало на разных данных. Надеемся, что данный опыт окажется полезным всем читателям.
Итак, главная проблема нашего поиска – это так называемый семантический разрыв (semantic gap). Т.е. разница между тем, какие изображения (в данном случае изображения одежды) считают похожими человек и машина. Например, человек хочет найти черную футболку с коротким рукавом:
Человек без труда скажет, что в списке ниже это второе изображение. Однако машина, скорее всего, выберет изображение 3, на котором женская футболка, но сцена имеет очень похожую конфигурацию и одинаковое цветовое распределение.
Человек ожидает, что результатом поиска будут позиции с тем же типом (футболка, майка, джисы …), приблизительно того же фасона и приблизительно с тем же цветовым распределением (цвет, текстура или рисунок). Но на практике обеспечить выполнение всех трех условий оказалось проблематично.
Начнем с самого простого, изображение со схожим цветом. Для сравнения изображений по цвету чаще всего используют метод цветовых гистограмм. Идея метода цветовых гистограмм для сравнения изображений сводится к следующему. Все множество цветов разбивается на набор непересекающихся, полностью покрывающих его подмножеств. Для изображения формируется гистограмма, отражающая долю каждого подмножества цветов в цветовой гамме изображения. Для сравнения гистограмм вводится понятие расстояния между ними. Существует много разных методов формирования цветовых подмножеств. В нашем случае их разумно было бы формировать из нашего каталога изображений. Однако даже для такого простого сравнения требуется выполнения следующих условий:
— Изображения в каталоге должны содержать одну только вещь на легко отделимом фоне;
— Нам нужно эффективно различать фон и интересующую нас область одежды на фотографиях пользователя.
На практике первое условие не выполняется никогда. О попытках решить эту проблему мы расскажем позже. Со вторым условием сравнительно проще, т.к. выделение интересующей области на изображении пользователя происходит с его активным участием. Например, существует довольно эффективный алгоритм удаления фона – GrabCut (http://en.wikipedia.org/wiki/GrabCut). Мы исходили из соображения, что интересующая нас область на изображении находится ближе к центру обведенной пользователем области, чем к ее границе и фон в данной области изображения будет относительно однородным по цвету. С использованием GrabCut и некоторых эвристик, удалось получить алгоритм, работающий корректно в большинстве случаев.
Теперь о выделении интересующей нас области на изображениях каталога. Первое что приходит в голову – сегментировать изображение по цвету. Для этого подойдет например алгоритм watershed (http://en.wikipedia.org/wiki/Watershed_(image_processing)).
Однако изображение красной юбки в каталоге может иметь несколько вариантов:
Если в первом и втором случае сегментировать интересующую область сравнительно легко, то в 3-м случае в мы выделим еще и пиджак. Для более сложных случаев этот метод не сработает, например:
Стоит отметить, что задача сегментации изображений полностью не решена. Т.е. не существует методов, которые позволяют выделить интересующую область одним фрагментом, как это может сделать человек:
Вместо этого изображение разбивается на суперпиксели (superpixel), тут стоит посмотреть в сторону алгоритмов n-cuts и turbopixel.
В дальнейшем используют их некоторое сочетание. Например, задача поиска и локализации объекта сводится к поиску сочетания суперпикселей, принадлежащих объекту, вместо поиска ограничивающего прямоугольника.
Итак, задача разметки изображений каталога свелась к поиску сочетания суперпикселей, которые соответствуют вещи данного типа. Это уже задача машинного обучения. Идея была следующая, взять множество размеченных вручную изображений, обучить на ней классификатор и классифицировать различные области сегментированного изображения. Область с максимальным откликом считать интересующей нас областью. Но тут надо снова определиться, как сравнивать изображения, т.к. простое сравнение по цвету гарантированно не сработает. Придется сравнивать форму или некий образ сцены. Как казалось на тот момент, для этих целей подойдет дескриптор gist (http://people.csail.mit.edu/torralba/code/spatialenvelope/). Дескриптор gist – это некая гистограмма распределения краев в изображении. Изображение делится на равные части сеткой какого-либо размера, в каждой ячейке считается и дискретизируется распределение краев разной ориентации и разного размера. Полученные в результате n-мерные вектора мы можем сравнивать.
Была создана обучающая выборка, вручную было размечено множество изображений разных классов (около 10). Но, к сожалению, даже при кросс-валидации не удалось добиться точности классификации выше 50%, меняя параметры алгоритма. Частично виной тому является то, что рубашка с точки зрения распределения краев будет мало чем отличаться от куртки, частично то, что обучающая выборка была недостаточно большая (обычно gist применяется для поиска по очень большим коллекциям изображений), частично то, что для данной задачи он, возможно, вообще не применим.
Еще один метод сравнения изображений – сравнение локальных особенностей. Его идея в следующем – выделить значимые точки на изображениях (локальные особенности), каким-либо образом описать окрестности данных точек и сравнивать количество совпадений особенностей у двух изображений. В качестве дескриптора использовали SIFT. Но сравнение локальных особенностей так же дало плохие результаты, большей частью из-за того, что данный метод предназначен для сравнения изображений одной и той же сцены, снятой с разного ракурса.
Таким образом, не получилось разметить изображения из каталога. Поиск по неразмеченным изображениям с использованием вышеописанных методов иногда давал приблизительно похожие результаты, но в большинстве случаев в результате не было ничего похожего с точки зрения человека.
Когда стало понятно, что разметить каталог у нас не получилось, мы попытались сделать классификатор для изображений пользователя, т.е. автоматически определять тип вещи которую хотел найти пользователь (футболка, джинсы и т.п.). Главная проблема – это отсутствие обучающей выборки. Изображения каталога не подходят, во-первых из-за того что они остались не размечены, а во-вторых они представлены в довольно ограниченном наборе пространственных представлений и нет гарантии что пользователь предоставит изображения в похожем представлении. Чтобы получить большой набор пространственных представлений для вещи мы снимали человека в этой вещи на видео, затем вырезали вещь и строили обучающую выборку по набору кадров. При этом вещь была контрастная и легко отделялась от фона. 
К сожалению, этот подход быстро отклонили, когда стало понятно, сколько видео нужно снять и обработать, чтобы охватить все возможные фасоны одежды.
Компьютерное зрение — это очень обширный сегмент, но нам (пока что) не удалось прийти к желаемому результату с высокорелевантным поиском. Мы не хотим сворачивать в сторону, добавляя дополнительные побочные функции, а будем биться, создавая поисковый инструмент. Мы будем рады услышать любые советы и комментарии.
habr.com
система распознавания лиц и анализа фото онлайн
В последнее время очень популярной стала тематика сервисов, которые распознают лица по фотографиям, а конкретнее, возраст, пол, эмоции и т.д. Недавно мы писали о проекте How-Old.net определяющим возраст по фото, а сегодня расскажем о похожем, но более функциональном решении. Это инновационный сервис Rekognition, который предлагает широкие технология распознавания лиц по фото. Найдете их в данном разделе.
Пока что сайт работает в тестовом режиме, и не все его возможности доступны для пользователей. Также временно закрыта регистрация новых юзеров. Скорее всего, опция полной регистрации на сервисе будет включена после завершения всех работ.
Однако ознакомиться с функциями проекта все же можно — просто пройдите по этой ссылке. На странице сайта, слева, в верхнем углу расположены три основные пункта меню:
- Concept Recognition — для анализа фотографии.
- Face Detection — система распознавания лиц по фото онлайн.
- Face Verification — функция проверки/сравнения лиц.
Анализ фотографии
Пункт меню Concept Recognition позволяет произвести полный анализ фотографии онлайн с определением того, что находится на изображении, неважно, человеческое ли это лицо, или просто фото природы. Чтобы сделать распознавание фотографии, просто нажмите на кнопку «Upload your image» в верхнем левом углу, и загрузите картинку со своего ПК.

На данный момент функция анализа фотографии онлайн в сервисе Rekognition работает с изображениями, расширение которых не превышает 800×800 пикселей. После завершения обработки картинки в основной части экрана выдается графический результат в виде с ключевых слов, которые связаны с данным изображением, и то, как эти слова «взаимодействуют» друг с другом. Очень круто!
Распознавание выражений лица
Следующая функция раздела называется Face Detection. Она позволяет осуществить полное распознавание лица по фото, определив разные его параметры. Система укажет ширину и высоту глаз, носа и рта, расу, пол, наличие одетых очков, а также проведет распознавание эмоций по выражению лица человека на фото.
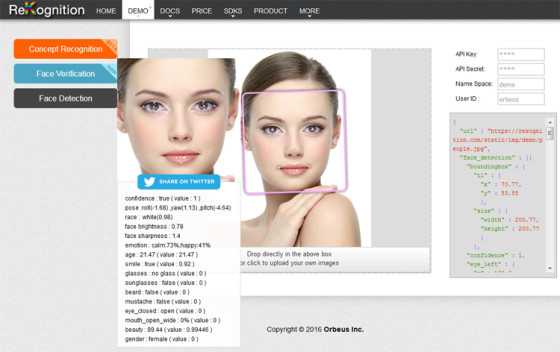
Загрузить свою фотографию можно кликнув непосредственно под главной рабочей областью (которая находится в центре интерфейса) по английскому тексту «Drop directly in the above box or click to upload your own images». Через несколько секунд увидите результат.
Вообще, сервис распознавания лиц по фото онлайн фотографий очень интересен в плане своей уникальности и широких возможностей. Ему можно найти разное применение от развлекательных целей до сферы безопасности. Справа на станице отображается некий код и функции, — я так понимаю это приготовили разработчикам. Интересная, короче, штука для всех пользователей интернета.
Сравнение лиц по фото
Еще одна фишка системы распознавания лиц — Face Verification. Она позволяет загрузить 2 изображения человеческого лица, и сделать их сравнительный анализ. Для этого в центральной части интерфейса нужно для под каждой картинкой нажать клавишу «Upload».

После загрузки изображений сервис осуществит автоматическое распознавание лиц по фото и их сравнительный анализ. Первая фотография, которая будет расположена левее, будет считаться базовой, и по отношению к ней и будет проведено сравнение.
В целом проект Rekognition интересный. Функция анализа фотографии онлайн открывает широкие возможности для веб-разработчиков, точно также как и технология распознавание лиц по фото. Эти фишки могут применяться в разных сферах — от систем безопасности до, скажем, устройств умного дома.
www.web2me.ru